
基于深度学习的Webshell检测*
2022-06-23 03:10车生兵张光琳
计算机工程与科学 2022年6期
车生兵,张光琳
(中南林业科技大学计算机与信息工程学院,湖南 长沙 410004)
1 引言
AWD(Attack with Defence)是一种将解题与攻防2种模式相结合的CTF(Capture The Flag)赛制。该模式具有攻防兼备的特点,参赛队利用其它队伍漏洞获取分数的同时还需要修补自己的环境漏洞。该赛制下队伍得分多者获胜,投入大量时间在攻击部分成了最优选,防御部分仅使用一些传统检测工具草草了事,并且传统检测工具对经过混淆变形后的Webshell检测效率并不理想。随着深度学习技术的发展,其在越来越多的领域得到应用。本文将深度学习与Webshell检测相结合,基于AWD比赛环境的背景研究检测结果最优时的检测模型和特征提取方法。
2 研究现状
当前Webshell检测工作多从流量检测、文件检测和日志检测3方面入手。基于流量检测的方法,可能会错误拦截主办方用于检测队伍环境的数据包,导致队伍被误以为处于宕机状态,从而扣除分数。基于日志的检测方法存在响应时间过长的问题。因此,本文选用基于文件的方法进行Webshell的检测研究。
近年来基于机器学习的检测方法流行起来。Sun等[1]提出了基于矩阵分解的分类检测模型;朱魏魏等[2]提出了NN-SVM(Nearest Neighbor Support Vector Machine)检测模型;胡建康等[3]提出了结合Boosting算法的决策树分类检测方法;易楠等[4]提出了基于语义的检测方法。上述基于机器学习的检测方法确实提高了Webshell的检测效率,但是其研究工作多在代码文本层面开展,对混淆后的Webshell检测结果并不理想。于是基于Opcode操作码的文件检测研究成为了研究人员新的关注方向。胥小波等[5]通过PHP(Hypertext Preprocessor)编译工具提取PHP样本源码的Opcode操作码,并使用词频与逆向文件频率TF-IDF(Term Frequency-Inverse Document Frequency)对Opcode操作码进行处理获取向量特征,最后结合多层感知机MLP(MultiLayer Perceptron)进行检测研究,检测结果较为理想。同时期Guo等[6]也验证了PHP操作码和TF-IDF特征提取模型的可行性。傅建明等[7]提出了使用操作码和词汇表的特征提取方法。张涵等[8,9]提出了利用word2vec与Opcode相结合提取特征的方法,分别使用多层感知机和卷积神经网络检测,效果更好。Lü等[10]对Webshell检测卷积网络中各超参数进行了对比实验。周龙等[11]通过TF-IDF提取词频矩阵,使用LSTM(Long Short-Term Memory)进行检测,验证了循环神经网络RNN(Recurrent Neural Network)检测的可行性。
为了探究AWD背景下的Webshell检测问题,在已有研究成果的基础上,本文主要做了如下工作:
(1)根据实际参赛经验,对随机获取的Webshell样本进行了长度处理,使其在本文特定背景下更具有针对性。
(2)由于实验环境因素的差异性,不同研究人员的方法及其实验结果并不能直接用来进行对比。本文针对具体应用背景,使用特定数据集,将现有模型在同环境下进行对照实验,寻找检测结果最好、效率最高的Webshell检测模型和特征提取方法,并对模型进行了优化。
(3)考虑到攻击代码有着全局稀疏、局部紧密的特点,本文使用了双卷积结构,并将卷积核模板的高度分别设计为3,4和5,而且攻击向量垂直方向关联特征明显,水平方向相对稳定,考虑到特征向量在传递过程中规模会减小,增加了补零选项。
(4)经过大量实验发现,深度学习训练算法Adam对AWD攻击向量的训练不太适应,本文对其进行了改进。
(5)探索了双卷积和GRU(Gate Recurrent Unit)相结合的检测模型。实验结果显示,基于词汇表的双卷积GRU模型最终检测精确率为98.7%,基于word2vec的双卷积GRU模型最终检测准确率为98.8%,并且训练曲线收敛得更快更平滑。验证了该模型在检测中的有效性和可行性。
3 相关工作
3.1 Webshell样本获取及精简
本文的数据集通过GitHub上的开源收集项目获取,合计收集恶意样本代码文件1 805个,白样本为用于PHP应用开发的常用开源框架,合计4 137个。编写批量Opcode处理脚本程序将所有PHP文件转换为Opcode。在比赛中“小马”由于其体积小、更容易修改的特点,成为比赛队伍常用的攻击手段。因此,本文仅保留Opcode个数在0~1 000的样本,这对检测“大马”影响较小,且不影响对“小马”和“一句话木马”的检测。
3.2 Opcode可行性分析
图1a为混淆后的Webshell文本代码。变形后的代码中已经看不到可理解的函数名,只有重复的无意义的函数名,这表示属性描述中多数特征已无法再作为检测的标准,如敏感eval、exec函数调用、系统函数调用数量和各种操作等。基于上述原因,混淆变形后的代码会对输入特征值产生较大影响,导致算法识别率下降。

Figure 1 Obfuscated code and Opcode after conversion图1 混淆后的文本代码和转换后的Opcode操作码
将图1a中的文本代码转换为Opcode操作码后的内容如图1b所示,可以发现混淆变形Webshell文本代码的Opcode操作码仍可以正常获取,并且操作码可以看作包含时序的特征值,编译后获取的操作码序列也没有其他因素的干扰,如注释等。该种特征提取方式能克服恶意文件加密混淆伪装后不能被正确识别的缺点,不含噪声,提高了数据质量,有利于后续的检测工作。
3.3 Opcode特征提取方案
3.3.1 利用N-gram和TF-IDF提取Opcode特征
N-gram和TF-IDF方法在本文实验对照组中。
N-gram方法将相邻的Opcode划分为一个词组单元,并使用词频向量表示单个样本。针对Opcode序列性强、上下文联系密切的特点,将4个以内的相邻Opcode划分到一个词组中,以此来生成词频向量。该方式会产生数量巨大的操作码词组,因此需要进行精简。本文去掉频率低于 10% 的词组,去掉频率等于 100%的词组,将剩下的操作码词组作为词频矩阵。
词频与逆向文件频率TF-IDF是自然语言处理领域的另外一种常用的特征提取方法。该方法认为词在当前文档的重要性同时被其在当前文档中出现的频率和其在语料库中出现的频率所影响。
3.3.2 利用词汇表提取Webshell特征
词汇表方法在本文的实验对照组中。词汇表方法生成的向量保留了句子的词序特征,该特征能更好地学习到Opcode操作码的序列信息,因此本文决定同时采用词汇表方法提取Opcode操作码的特征向量并进行检测实验。
首先,提取所有Opcode样本的词袋,词袋中词的数量N为166;然后,利用词袋将每一个Opcode表示成一个向量,向量长度为所选取的最大文档长度。由于样本中Opcode最长为1 000,此处最大文档长度也为1 000。
3.3.3 利用word2vec词向量提取Webshell特征
word2vec在本文的实验对照组中。使用Gensim开源工具包训练word2vec词向量的功能。本文中word2vec方法中模型的训练设置如下:词向量维度为100,窗口大小设置为10,最小词频为10,迭代训练次数为 100 次,采用CBOW(Continuous Bag of Words)模型进行训练。通过TSNE(T-distributed Stochastic Neighbor Embedding)算法将生成的词向量降至2维,并进行可视化,结果如图2所示。从图2中可以看到,Opcode表现出分布的特点,即通过词向量可以明显区分功能不同的Opcode,这也表明了使用Opcode进行检测的可行性。

Figure 2 Dimension reduction visualization of word vector by TSNE图2 TSNE词向量降维可视化
3.4 深度学习实验模型设计
3.4.1 多层感知机模型设计
多层感知机网络结构如图3所示,2个隐藏层分别包含5个节点和2个节点,选择随机梯度下降算法对各节点权值进行调整,输出层选择Sigmoid作为激活函数,其它层选择ReLU函数。

Figure 3 Structure of multilayer perceptron 图3 多层感知机结构
3.4.2 卷积神经网络模型设计
文本分类中常用的经典一维卷积处理模型TextCNN如图4所示[12],Webshell检测也属于文本二分类问题,所以本文采用该模型进行Webshell检测。

Figure 4 Structure of TextCNN图4 TextCNN结构图
在超空间利用模糊C均值聚类分析发现了攻击向量全局稀疏、局部紧密的特点,本文在使用经典模型作为实验对照的同时,考虑到文本的稀疏性,还对经典模型进行了改进,添加了双卷积层,如图5所示。由于一次攻击与相邻的2~4次操作紧密相关,卷积核模板的高度分别设计为3,4和5,而且攻击向量垂直方向关联特征明显,水平方向相对稳定,考虑到特征向量在传递过程中规模会减小,增加了补零选项。

Figure 5 Double convolution model图5 双卷积模型
调参工作选用本文改进后的Adam算法[13]。经过大量实验发现,深度学习训练算法Adam对AWD攻击向量的训练不太适应,本文把学习率learning_rate修改为0.000 2,矩估计的指数衰减率参数beta1修改为0.5,程序中的变量epsilon_t修改为epsilon,不但消除了训练的Loss曲线中的锯齿,还使得训练曲线按照指数规律下降,迅速得到了需要的训练结果,且在测试数据集上的分类成功率很高,优于同类算法的分类结果。Adam算法随机变量修正值快速计算公式证明在附录中给出。
3.4.3 循环神经网络模型设计
LSTM是一种效果比较好的递归神经网络,能够很好地解决长记忆时间序列问题[14,15]。GRU是LSTM网络的一种变体结构,比LSTM更加简单,且训练效果也很好。通常来说,GRU和LSTM在很多任务上不分伯仲,GRU参数少更容易收敛,但当数据样本很大时LSTM表现性能更好。本文设计2种模型结构进行LSTM和GRU检测性能对比。调参工作选用本文改进后的Adam算法,设置Dropout=0.5。在RNN中分别使用LSTM单元和GRU单元进行对比,如图6所示。

Figure 6 RNN network model图6 RNN网络实验模型
4 综合实验设计与对比
4.1 评价指标
为了准确对比各检测方法的性能,本文使用4种指标度量各方法的性能:精确率(Precision)、准确率(Accuracy)、召回率(Recall)和F1(F1-sore)指标。
4.2 初步实验结果
(1)多层感知机实验。
分析4种特征提取方法在MLP中的实验结果。4种对应的检测方法如下所示:
①特征提取使用词袋和TF-IDF,基于MLP进行的分类检测。
②特征提取使用词汇表,基于MLP进行的分类检测。
③特征提取使用N-gram,基于MLP进行的分类检测。
④特征提取使用word2vec,基于MLP进行的分类检测。
上述方法中的一些参数设置如下:
词袋+TF-IDF:通过对比实验可知,使用4-gram、最大特征数为100时检测结果最好。
N-gram:通过对比实验可知,使用4-gram、最大特征数为100时检测结果最好。
词汇表:通过对比实验可知,最大文本长度为100时检测结果最好。
word2vec:通过对比实验可知,词向量维度为100、最大文本长度为500时检测结果最好。
实验结果如表1所示。从表1中可以看出,多层感知机模型的检测结果不理想,比不上其他深度学习模型的检测结果(其他深度学习模型检测结果见后文)。因此,本文不再考虑多层感知机模型。

Table 1 MLP check results
(2)卷积对照实验。
分析不同特征提取方法在TextCNN模型和双卷积模型中的实验结果。对照检测方法如下所示:
①特征提取使用N-gram,基于TextCNN模型进行的分类检测。
②特征提取使用词汇表,基于TextCNN模型进行的分类检测。
③特征提取使用word2vec,基于TextCNN模型进行的分类检测。
④特征提取使用N-gram,基于双层卷积模型进行的分类检测。
⑤特征提取使用词汇表,基于双层卷积模型进行的分类检测。
⑥特征提取使用word2vec,基于双层卷积模型进行的分类检测。
上述方法中的一些参数设置如下:
N-gram:通过对比实验可知,使用4-gram、最大特征数为20时检测结果最好。
习近平在北京师范大学师生代表座谈时指出办好教育事业的任务艰巨性[13],我国教育事业所面临的问题与挑战,构成了教育体制机制改革阶段的基本特征。在习近平主持召开的中央全面深化改革领导小组第三十五次会议上,《关于深化教育体制机制改革的意见》获得审议通过,明确提出要“统筹推进育人方式、办学模式、管理体制、保障机制改革”[14],进一步明确了深化教育体制机制改革的目标、要求和任务。
词汇表:通过对比实验可知,最大文本长度为1 000时检测结果最好。
word2vec:通过对比实验可知,词向量维度为100、最大文本长度为500时检测结果最好。
实验结果如表2所示,训练阶段损失下降情况如图7所示。从提取样本特征方法来看,使用词汇表和word2vec的方法在卷积网络中都表现出不错的检测效果,N-gram特征提取方法的检测结果不太理想。从Loss曲线收敛情况可以看出,使用词汇表和word2vec检测方法的曲线收敛较快,说明包含了全局时序特征的样本输入能让卷积网络获得更好的学习能力。N-gram损失了全局时序特征,仅保留一定的局部时序特征,因此检测结果不理想。从模型的角度来看,3种不同的特征提取方法在双层卷积模型中的检测效果都得到了提升。
(3)RNN对照实验。
分析3种特征提取方法在LSTM和GRU中的实验结果。对照检测方法如下所示:
①特征提取使用N-gram,基于LSTM进行的分类检测。

Table 2 Convolutional network check results

Figure 7 Loss curve of convolution group in the training phase图7 卷积组训练阶段Loss曲线
②特征提取使用词汇表,基于LSTM进行的分类检测。
④特征提取使用N-gram,基于GRU进行的分类检测。
⑤特征提取使用词汇表,基于GRU进行的分类检测。
⑥特征提取使用word2vec,基于GRU进行的分类检测。
上述方法中的一些参数设置如下:
N-gram:通过对比实验可知,使用4-gram、最大特征数为20时检测结果最好。
词汇表:通过对比实验可知,最大文本长度为1 000时检测结果最好。
word2vec:通过对比实验可知,最大文本长度为500、词向量维度为100时在LSTM模型中检测结果最好,词向量维度为1 000时在GRU中检测结果最好。
实验结果如表3所示。训练阶段损失下降情况如图8所示。从提取样本特征方法来看,使用包含了全局时序特征的词汇表和word2vec的方法检测结果较好,使用N-gram的检测结果不太理想。由图8可以看出,使用word2vec检测方法的曲线收敛最快最好;使用词汇表检测方法的曲线前期波动较为明显,虽然最后检测结果不错,但是学习效率不如使用word2vec的;相比使用词汇表方法,使用N-gram的方法能更快地收敛,但实际识别效果很差,出现了过拟合的问题。从模型的角度来看,GRU和LSTM以词汇表作为特征提取方法时,GRU收敛得更快更好,效率更高。从表3中也可以看出,针对小样本时,GRU的检测结果比LSTM的稍好一些。
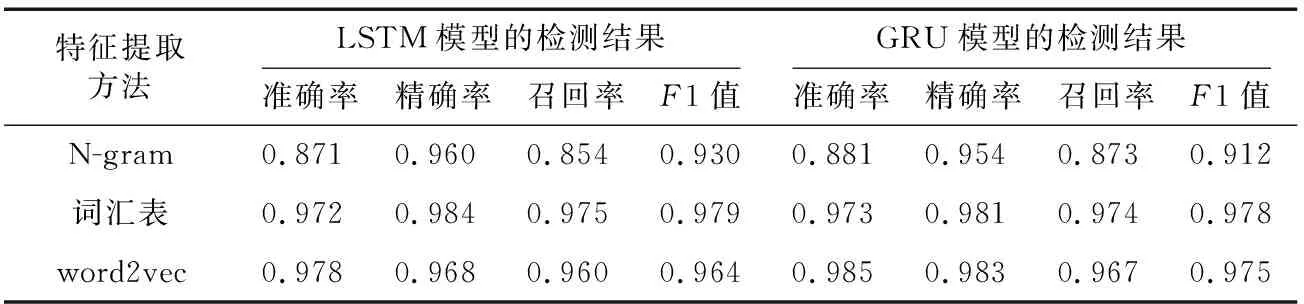
Table 3 RNN check results

Figure 8 Loss curve of RNN in the training phase图8 RNN组训练阶段Loss曲线
4.3 双卷积GRU模型实验结果
从初步的实验结果分析可知,双卷积模型收敛快且平滑,但是以词汇表作为特征提取方法时检测结果不如GRU模型的;GRU综合检测结果比双卷积模型要好,但是以词汇表作为特征提取方法时Loss曲线收敛较慢,波动较大。因此,本文整合其优点,提出双卷积GRU模型,期望得到进一步优化。双卷积GRU模型结构如图9所示,设计对照组检测方法验证3种特征提取方法在双卷积GRU中的检测结果。采取的3组检测方法分别是:

Figure 9 Double convolution GRU model图9 双卷积GRU模型
(1)特征提取使用N-gram,基于双卷积GRU进行的分类检测。
(2)特征提取使用词汇表,基于双卷积GRU进行的分类检测。
(3)特征提取使用word2vec,基于双卷积GRU进行的分类检测。
上述方法中的一些参数设置如下:
N-gram:通过对比实验可知,使用4-gram、最大特征数为20时检测结果最好。
词汇表:通过对比实验可知,最大文本长度为1 000时检测结果最好。
word2vec:通过对比实验可知,词向量维度为100、最大文本长度为500时检测结果最好。
将双卷积层GRU模型的检测结果与卷积对照组和RNN对照组中表现最好的双卷积模型和GRU模型的检测进行对比。双卷积层GRU模型训练阶段损失下降情况如图10所示,综合损失下降对比情况如图11所示,综合检测结果对比如表4所示。

Figure 10 Loss curve of double convolution GRU model图10 双层卷积GRU Loss曲线

Figure 11 Comprehensive comparison of Loss curve based on vocabulary and word2vec图11 基于词汇表和word2vec的Loss曲线综合对比

Table 4 Comprehensive comparison
从检测结果来看,基于词汇表和word2vec的特征提取方法在3种模型中都有很好的表现。使用词汇表特征提取方法的双卷积GRU模型检测结果最好,其精确率为0.987,是所有模型中最高的,F1值为0.983,也是所有模型中最高的。使用word2vec特征提取方法的双卷积GRU模型检测结果最好,其准确率为0.988,是所有模型中最高的,召回率为0.982,也是所有模型中最高的。从收敛曲线来看:当使用词汇表特征提取方法时,双卷积GRU模型的曲线收敛得最好(图11a中②号曲线),GRU模型曲线收敛最慢(图11a中③号曲线);当使用word2vec特征提取方法时,双卷积GRU模型和双卷积模型的曲线均收敛很好(图11b中①和②号曲线),GRU模型收敛最慢(图11b中③号曲线)。
通过以上分析可知,双卷积GRU模型成功结合了GRU模型和双卷积模型的优点,在训练效率和检测结果上都达到了最优,验证了该模型的可行性。因此,在后续应用工作中将采取词汇表或word2vec的特征提取方法,同时结合双卷积GRU模型进行检测工作。
5 结束语
本文基于AWD攻防竞赛背景进行了PHP Webshell的检测研究。为了适应比赛背景,对Opcode数据集的长度进行了处理,使用特定的数据集,将现有模型在同环境下进行了对照实验,并对模型进行了优化。基于该背景的数据集,优化了Adam算法提高了训练效率。通过词袋、TF-IDF、N-gram、词汇表和word2vec等方法提取特征,与深度学习多层感知机网络MLP、卷积神经网络CNN和循环神经网络RNN相结合,设置对照实验。在特征提取方法上,实验结果表明基于包含全局时序特征的词汇表和word2vec在CNN和RNN神经网络中的检测性能更好。双卷积层模型检测效果优于单卷积层模型,GRU模型相比LSTM模型训练效率更高。双层卷积GRU模型成功地结合了卷积神经网络和GRU网络的优点,成为本次研究中的最优模型。实验结果显示,基于词汇表的双层卷积GRU模型最终检测精确率达到98.7%,基于word2vec的双层卷积GRU模型最终检测准确率达到98.8%,验证了该模型在检测中的有效性和可行性。
附录AAdam算法随机变量修正值快速计算公式
的证明
证明
根据Adam算法给出的θt计算公式,有:

□
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
双语时代(2009年3期)2009-09-24
