
电能表贴标机异常贴标图像识别方法研究
2022-06-24 10:36洪巧文张荔鹃周厚源苏东升黄大荣马争锋
自动化仪表 2022年4期
洪巧文,张荔鹃,周厚源,王 姣,苏东升,黄大荣,马争锋
(1.国网福建省电力有限公司营销服务中心,福建 福州 350003;2.北京南瑞捷鸿科技有限公司,北京 100093;3.重庆交通大学信息科学与工程学院,重庆 400074)
0 引言
近年来,随着国家电网公司自动化建设的发展,省级计量中心建设全面展开。电能表的自动化检定系统建成并投入运行后,大幅降低了人员成本,全面提升了检定效率和检定质量。完成电能表自动检定后,会由自动生产线上的贴标机为合格电能表进行自动贴标。然而,在贴标机长时间工作中,难免会出现标签信息打印模糊、打印不完整、信息打印偏移和重复贴标签等问题。贴标之后如果不能及时发现问题标签,检定通过的电能表就会入库,然后被配送到各地。这些贴标信息不完整的电能表是不能给用户安装的。如果在安装时再逐一排查或者回收,会造成巨大的人工和运营成本的损耗。因此,如何能在电能表贴标后自动辨识出不合格的贴标标签,是解决实际生产的重要基础。
针对图像识别问题,国内外学者分别从特征提取、机器学习等方面开展了研究,并取得了一系列研究成果。在计算机算力比较有限的时候,研究者们往往先手动提取图像的特征,再进行图像识别。在图像特征提取方面,局部二值模式 (local binary pattern,LBP)、梯度直方图 (histogram of oriented gradient,HOG)和哈尔特征(Haar like features,HL)等算法的应用非常广泛。LBP主要通过比较图像中任意像素点灰度值与以该像素点为中心的矩形邻域内其他像素点灰度值的大小,确定该像素点的LBP码[1]。 HOG 算法的基本思想是:局部目标的表象和形状能够被梯度强度在梯度方向上的分布很好地描述[2]。这些特征提取算法结合机器学习的模型,在图像识别方面取得了很好的效果,应用非常广泛。例如:丁飞等[2]提出了基于一种改进的方向梯度直方图-支持向量机(histogram of oriented-support vector machine,HOG-SVM)的红外视频图像人形检测方法,在3 m之内对人形姿态的识别率达到了95%,且运行时间短;原晓佩等[3]提出了一种基于滑窗原点信息的阈值自调节改进哈尔特征和局部二值模式(improved Haar like-local binary pattern,IHL)特征提取算法。该算法对行人和车辆目标的识别率可达到94%以上,检测准确性相比其他方法也有显著提升。特征提取的方法经过改进之后,都具有一定的鲁棒性,在实际应用中也取得不错的效果。然而,这些算法对于原图像的拍摄条件有比较严格的要求,如果获取的图像光照不均匀,就会大大影响算法结果。另外,特征算法本身也存在着一些缺陷。例如,HOG算法本身不具有尺度不变性。
近年来,随着计算机算力的增强,神经网络模型从理论变为了现实。而其在各个领域对于不同数据的学习能力,使得这一技术得到了飞速的发展。神经网络模型目前在自然语言、计算机视觉和其他大数据处理的相关领域得到了非常广泛的应用[4-6]。Lecun Y等[5]描述了神经网络这种多处理层的计算模型。这种深度学习模型能够发现大数据中的复杂结构,可以在语音识别、视觉目标识别、目标检测以及基因学等方面发挥巨大的作用。Krizhevsky A[7]等提出了经典的卷积神经网络(convolutional neural networks,CNN)框架。其中:Alexnet模型引入了全新的深层结构和dropout方法,大幅降低了图像识别的错误率,让CNN模型在图像识别领域大放异彩。此后,该领域的研究和应用很多都是基于该模型的改进和优化[8-9]。残差网络(residual networks,ResNet)是深度学习领域的又一进展,在一些图像识别和检测任务中取得了显著的成果[10-11]。与同等的CNN相比,ResNets能达到更高的精度,并能使训练过程更快,表现出比深度前馈网络更好的泛化性能。
自动生产线工作具有快速、高效的特点,因此电表自动检定完成后,要在贴标机贴标工作后实时检测每个电表的贴标是否合格。这对检测速度提出了非常高的要求。同时,工厂现场作业环境比较复杂的,要求检测标签的方法对于采集的图像光照、角度等具有较强的鲁棒性。此外,在实际生产过程中,异常标签实际上是很少的。这会造成建立训练数据库时样本不均衡的情况。
为了解决样本不均衡的问题,同时高效、准确地对不合格贴标进行检测,本文对样本数据库作了均衡样本的处理:通过分析几种高效算法原理、对比它们对标签特征识别情况,确定了应用ResNet模型来实现不合格标签的快速、准确辨识。
1 样本预处理
数据集样本采用贴标机实际工作中产生的正常贴标和异常贴标图像作为正、负样本。在实际生产线中,标签异常情况很少,采集负样本难度很大,会出现数据集中正、负样本比例不均衡的情况。由于数据决定了机器学习模型的最终效果,要想模型对异常标签有很好的识别效果,就先要解决样本不均衡问题。在实际试验中,解决样本不均衡问题通常有以下两种方法。
①欠采样。
欠采样是通过减少多数样本的样本数量来达到正、负样本均衡的目的。一种比较简单的做法是直接随机去除一些多数样本,直到数据集中正、负样本比例接近。这种方法的缺点是不仅会造成信息丢失,还会减少总样本量,难以满足深度学习模型对样本数量的要求,导致模型学习不充分、影响识别效率。
②过采样。
过采样是通过增加样本中少数类来达到正、负样本均衡,提高模型表现。较为简单的方式是直接复制一定数量的少数类样本来增加少数类占比,并增大样本总量,以满足模型训练需求。这种方法的缺点是数据单一,模型存在较大过拟合风险。
针对图片数据,本试验采用数据增强的方式增加少数类样本比例。在计算器视觉领域,数据增强是一种扩大样本数量的常用方式。一般而言,神经网络模型需要确定大量的参数,而使得这些参数可以正确工作则需要大量的数据进行训练。在实际样本缺乏的情况下,图像数据增强不仅可以增加训练数据、提高模型泛化能力,还能人为添加噪声数据,从而提高模型的鲁棒性。在电能表贴标机异常贴标图像识别中,使用图像翻转、图像旋转、图像缩放、图像剪裁、图像平移和图像加噪来进行图像增强,以增加少数样本。
原始样本与数据增强样本如图1所示。

图1 原始样本与数据增强样本Fig.1 Original sample and data enhanced sample
2 电能表贴标图像识别方法
2.1 HOG+SVM模型
HOG算法通过计算和统计图像局部区域的HOG来构成特征。HOG特征结合SVM分类器已经被广泛应用于图像识别中[2]。
HOG特征提取步骤如下。
①对图像进行灰度化处理。
②采用Gamma校正法对输入图像进行颜色空间的标准化。校正的目的是调节图像的对比度、降低图像局部的阴影和光照变化所造成的影响,同时抑制噪音的干扰。
③计算图像每个像素的梯度(包括大小和方向)。这一步主要是为了捕获轮廓信息,同时进一步弱化光照的干扰。
④将图像划分成小细胞单元(cells)。
⑤统计每个cell的梯度直方图,即可形成每个cell的特征。
⑥将每几个cell组成一个块像素(block)。每个block内所有cell的特征串联起来,就是该block的HOG特征。
⑦将图像内所有block的HOG特征串联起来,可以得到目标图像的HOG特征。
电能表不合格标签会出现信息打印模糊、不完整、信息打印偏移等问题。而电能表标签本身具有较大的色差,纹理清晰,局部目标的图像和形状能够被梯度或边缘的方向密度分布很好地描述。因此,HOG能够准确反映图像特征,体现标签间的信息差异,可用于训练模型寻找异常标签。
支持向量机(support vector machine,SVM)是机器学习中应用非常广泛的一类模型。它在样本数据中找出一个最大边际超平面对应的决策边界,并利用这个决策边界对数据进行分类。对于非线性数据,SVM会对数据进行升维变换,在高维空间中可以找到一个合适的决策边界再变换到原始维度。
正是由于HOG方法对图像特征的高效提取与SVM在线性与非线性数据上的良好表现,本文应用HOG+SVM方法对电能表贴标异常图像进行识别,并作为基本对照试验组。
2.2 基于深度神经网络模型的标签分类
作为深度学习的代表算法之一,CNN可以直接将图像数据作为输入,不仅无需人工对图像进行预处理和额外的特征提取等复杂操作,而且具有独特的细粒度特征提取方式。因此,CNN在图像识别、物体检测、图像描述等计算机视觉领域有广泛应用。
称取0.100g铝合金标准样品于烧杯中,加入5mL 30%氢氧化钠溶液、几滴30%双氧水,加热至溶解完全,加1mL硝酸(1+1)加热蒸至近干,加水溶解,定容于50mL容量瓶中。移取适量试液于25mL容量瓶中,加入各1mL 1g/L酒石酸钾钠溶液和20g/L硫脲溶液后按实验方法测定,结果见表1。
CNN主要由输入层、卷积层、池化层、全连接层和输出层这5部分组成[4]。对输入图像的特征提取主要通过卷积层实现。卷积的计算公式为:
(1)
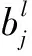
电能表合格贴标标签与异常贴标标签的主要差别在于信息打印的位置以及模糊程度。要想训练出精度高的分类模型,在提取图像特征时,算法就必须准确提取标签中的文字信息。用包含4层卷积、9个卷积核的CNN特征提取可视化结果如图2所示。
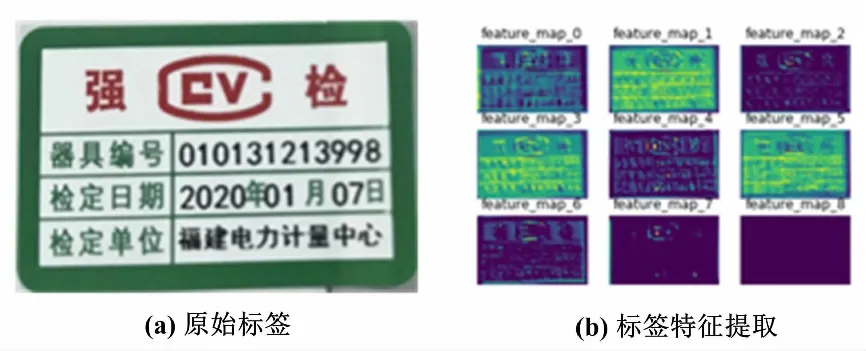
图2 CNN特征提取可视化结果Fig.2 Results of CNN feature extraction visualization
由图2可知,在压缩图像维度的同时,除了对文字信息的准确提取,特征图中还包含了标签的轮廓、颜色特征,并且随着模型的加深,提取的特征更具有代表性。所以,利用CNN提取的图像特征训练标签分类模型更加准确。
随着深度学习技术的发展,神经网络模型越来越深。与此同时,反向传播误差梯度消失、模型退化等问题也影响着模型表现。作为CNN模型的代表算法,视觉几何组网络(visual geometry group networks,VGGNet)与ResNet在计算机视觉领域都有广泛的应用。VGGNet探索了CNN深度与性能之间的关系,并证实了随着网络深度增加,可以在一定程度上提升模型的性能[8-9]。
VGG-16模型结构如图3所示。

图3 VGG-16模型结构Fig.3 VGG-16 model structure
VGG-16网络模型包含了13个卷积层和3个全连接层。其中,卷积层每2个或者3个为1组,堆叠为1个卷积单元;设置滑动步长为1,加入边界填充以保证前后维数一致。在每个卷积单元之后加入1个2×2的最大池化层,设置步长为2,用于特征图降采样以及获得图像平移不变性。全连接层由3个连续的全连接组合,前两层通道数均为4 096,第三层通道数为1 000。模型的最后为1个具有1 000个标签的SoftMax输出层。
然而,随着网络的深度的进一步增加,存在信息传递梯度消失的情况,会造成网络效果下降的退化现象。为解决这个问题,ResNet网络通过加入残差块方式堆叠网络层[10-11],在模型加深的同时保证模型效果能够有所提升,并在多个数据集中证实ResNet效果好于VGGNet。在残差块结构中,“+”表示将残差块的原始输入和输出相加。
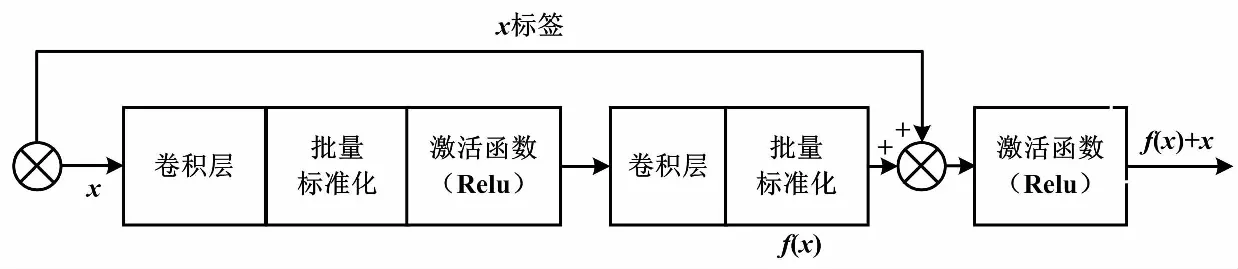
图4 残差块结构Fig.4 Residual block structure
残差块的设计改变了单层网络的拟合目标,将目标函数变为期望输出与输入之间的残差:
y=f(x,wi)+x
(2)
式中:y为残差块目标输出;x为输入;f(x,wi)为残差单元需要学习到的映射。
在模型训练过程中,残差块可以通过网络的输入与输出判断该层网络是否学到了有效信息。若该层网络无法学到有效信息或者影响模型的性能,也就是f(x,wi)<0,残差块会直接将网络的输入作为输出结果,即y=x。这可以保证在网络变深的同时,模型性能不会因此降低,使设计的每一层网络都对整个模型的精度有贡献。
然而,为了保证原始输入x与残差单元学习映射f(x)最后可以合并,残差块中要求x与f(x)具有相同的特征图个数。这也限制了卷积层提取更多有效特征。为此,改进的模型中单独设计了如图5的卷积残差块,即对输入x作与残差块同等的卷积映射,保证在特征图加深的同时,x与f(x)具有相同的维度。根据贴标图像自身的特征复杂度,采用了ResNet-50模型,网络中分为5个stage,先由12个残差块和4个卷积残差块提取输入的标签图像特征,再由全连接层输出预测结果。
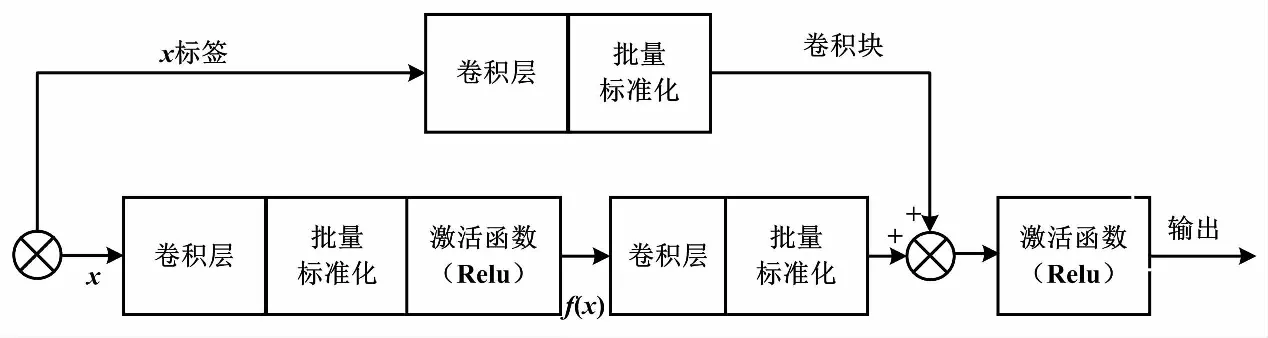
图5 卷积残差块结构Fig.5 Convolution residual block structure
ResNet-50模型结构如图6所示。
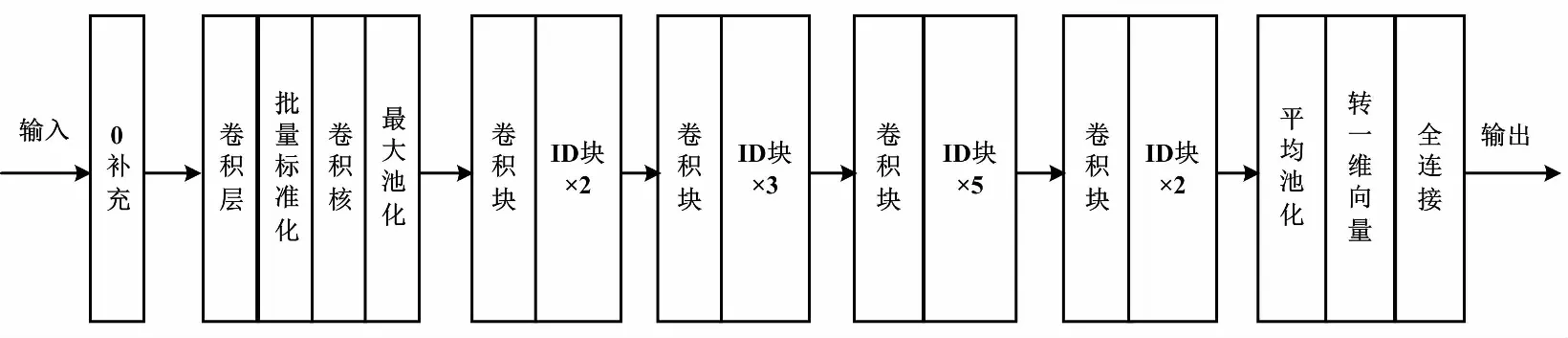
图6 ResNet-50模型结构Fig.6 ResNet-50 model structure
3 算例与分析
在电能表贴标机实际运作过程中,由于贴标机的长时间工作和环境因素,会导致打印标签信息模糊、不完整、信息打印偏移等问题。异常标签的电能表按规定不能出售。若是不能在出厂前识别出异常标签,将会造成人力与物力资源的消耗。
异常标签如图7所示。

图7 异常标签Fig.7 Exception labels
为验证基于ResNet的标签识别模型效果,以电能表生产企业现场采集的标签为数据集,并利用翻转、旋转、缩放等数据增强方法进行样本均衡,将数据集划分为1 600个训练集和400个测试集。图像增强后的样本中含有合格标签1 100张、异常标签900张。
样本数据构成如表1所示。
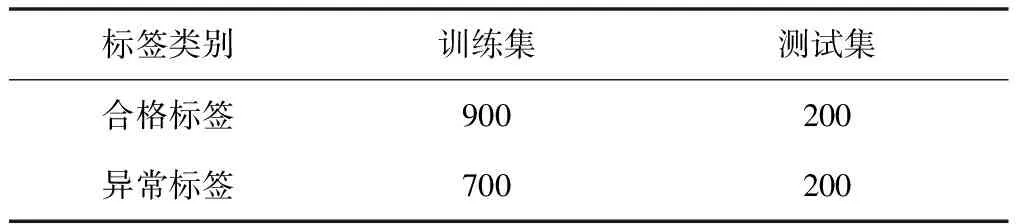
表1 样本数据构成 Tab.1 Sample data composition /张
由于数据集中样本有限,在进行ResNet训练时:首先,采用了迁移学习的方法,以ImageNet预训练的ResNet来初始化模型参数;然后,在训练中优化,最后用测试集测试模型性能。
训练共进行了10次迭代,得到如图8所示的ResNet学习与误差曲线。

图8 ResNet学习与误差曲线Fig.8 ResNet learning and error curves
同时,为了进一步反映ResNet的辨识效果,把上述试验与SVM+HOG、VGG-16两组模型的试验结果进行了对比。试验结果对比如表2所示。
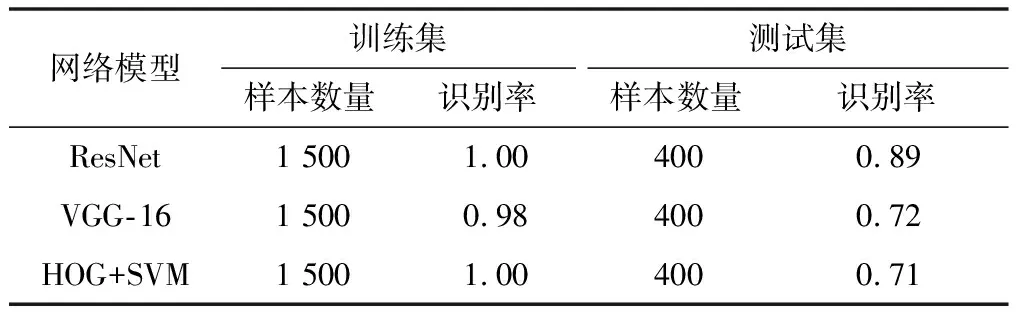
表2 试验结果对比
由表2可知,3组模型在训练集样本中都有很好的识别效果。但在测试集中,ResNet的识别效果要远远高于其他2组模型,达到了89%,证明了该方法的有效性。
4 结论
针对自动线生产环境中的自动贴标标签识别问题,以生产现场采集的图像为数据集,进行了数据集样本均衡,并以HOG+SVM作为基本对照试验,使用VGG-16和ResNet模型在平衡后的数据集中进行了模型训练和样本识别的试验。试验结果表明,在训练与测试阶段,ResNet都有最好的识别效果,测试集识别率保持在89%,具有实际的应用价值。但由于样本量的不足,模型还存在轻微过拟合现象,且在实际的流水线中,需要准确、高效的标签辨识模型。在后续的研究中,将针对工程需求,进一步提高模型的准确率、识别速度,以及降低过拟合风险。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
数学小灵通(1-2年级)(2021年11期)2021-12-02
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
电子制作(2019年13期)2020-01-14
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
消费导刊(2017年20期)2018-01-03
