
基于改进型粒子群优化算法的CFB锅炉床温建模
2022-06-24 10:36雷彦云李丽锋
自动化仪表 2022年4期
王 琦,雷彦云,赵 静,李丽锋
(1.山西大学自动化与软件学院,山西 太原 030013;2.山西大学数学科学学院,山西 太原 030006;3.山西河坡发电有限责任公司,山西 阳泉 045011)
0 引言
床温是衡量火电厂循环流化床(circulating fluidized bed,CFB)锅炉是否安全、稳定、经济运行的重要指标之一[1]。床温过高,会使锅炉的承压部件超温,降低金属部件的热强度和热稳定性,缩短锅炉寿命。床温过低,则会使得锅炉运行效率和运行经济性变低。长时间低温运行,还会导致汽温过低,影响汽轮机安全运行。此外,床温控制不当还会使得机组脱硫、脱硝反应不在最佳反应温度范围内进行,进而影响SO2和NOX的脱除。
CFB锅炉床温的动态模型建立和动态特性分析对实现床温的自动控制及优化有重要的意义。许多学者对CFB锅炉床温动态特性和模型建立进行了大量的研究。文献[2]对CFB锅炉床温特性、影响因素进行研究,并提出了通过调整燃料量、一次风量、二次风量比例来控制床温的方法。文献[3]采用智能辨识算法建立了以燃料量和一次风量为输入、以床温和主蒸汽压力为输出的两输入两输出模型;文献[4]通过机理分析得到了锅炉内多个动态平衡方程,并给出了动态模型。
在前人研究的基础上,本文通过分析CFB锅炉床温动态特性的影响因素,确定了燃料量、一次风量、二次风量和床温之间的动态模型,包括其结构和参数范围。针对CFB锅炉在运行过程中床温波动频繁、影响因素众多等特点,以山西某350 MW CFB机组实际运行数据为基础,采用自适应惯性权重粒子群优化(particle swarm optimization,PSO)算法对床温模型进行系统辨识[5-6]。
首先,建立了以燃料量、一次风量、二次风量为系统输入,以床温为系统输出的多输入单输出床温动态模型。然后,通过仿真及计算误差函数,证实了该模型具有较高的准确性。最后,采用现场运行数据对该模型进行了验证。验证结果表明,该模型能够基本反映输入变量和床温之间的动态关系。
1 床温辨识模型
1.1 床温影响因素
CFB锅炉正常运行时,床温要严格控制在允许范围内。由于CFB锅炉燃烧系统是一个多输入多输出、非线性、强耦合的复杂系统,导致锅炉床温受诸多因素影响,例如锅炉负荷、燃料量、一/二次风量及其配比、炉内物料循环、煤质、煤粒径、锅炉床压、排渣量、返料量、返料温度和石灰石量等。其中,最主要的影响因素是锅炉负荷、燃料量、一次风量和二次风量。
1.2 床温动态特性
1.2.1 燃料量扰动下的床温动态特性
由于CFB锅炉独特的燃烧方式,炉内循环床料较多。增加燃料量后,新入炉燃料量占总料量的比重很小,炉内热惯性较大,床温起初变化较小。随着后续入炉煤燃烧放热,床温会呈现上升趋势。因此,可以通过减少或增加燃料量来调节床温。但是该系统反应迟缓,存在大时延特性。
1.2.2 一次风量扰动下的床温动态特性
一次风量对床温有明显的影响:一次风量增加,引起的床温变化为先上升后下降;一次风量减少,引起的床温变化为先下降后上升,表现为一个具有滞后、惯性、自平衡能力的逆向响应系统。此外,床温的变化幅度与一次风量的增减量有关。
1.2.3 二次风量扰动下的床温动态特性
二次风量的调节范围为(6~40)×104N·m3/h,大于一次风量的调节范围。二次风量在总风量中的占比一般小于一次风量的占比。在氧量不变的前提下,改变一次风量和二次风量的比例可调节床温:增大一次风量、减小二次风量,床温将降低;反之,床温将升高。
1.3 床温多变量系统模型
因影响床温的各变量之间耦合严重,本文拟采用闭环辨识方法,建立以燃料量、一次风量、二次风量为输入变量,以床温为输出变量的三输入单输出系统数学模型。该多输入单输出(multiple input single output,MISO)控制系统,可视为多个单输入单输出(single input single output,SISO)系统的叠加[7-8]。3×1的待辨识系统如图1所示。

图1 3×1的待辨识系统Fig.1 3×1 system to be identified
2 多变量系统辨识模型原理
智能辨识算法原理如图2所示。
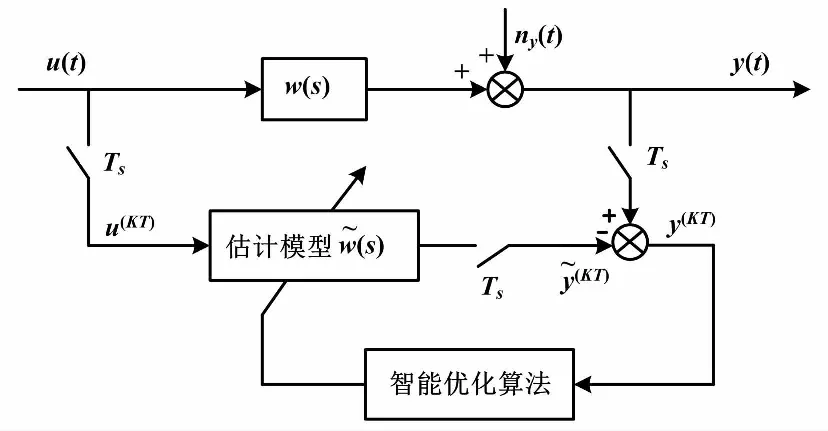
图2 智能辨识算法原理框图Fig.2 Principle block diagram of intelligent identification algorithm
多输入多输出系统需要辨识的参数很多,传统辨识算法难以满足其辨识要求。因此,需采用智能优化算法对模型参数进行辨识。具体做法为:根据采集到的输入/输出数据,运用辨识方法对参数进行寻优,寻求与实际系统参数特性较为一致的模型。首先,根据要辨识系统的动态特性,选择一个适合的估计模型;然后,将采集到的输入数据分别施加到待辨识系统与估计模型中,计算得到待辨识系统和估计模型的输出差值;最后,由优化算法根据两者之间的差值对模型的参数进行优化,直到待辨识系统和估计模型的输出差值达到最小。此时,估计模型可以很好地接近待辨识系统[9]。K、T为辨识出的模型增益和时间常数。
2.1 基本粒子群优化算法

基本PSO算法流程如图3所示。

图3 基本PSO算法流程图Fig.3 Flowchart of basic PSO algorithm
设定参数运动范围:种群规模为m;最大进化代数为N;粒子在整个解空间中的位置信息和速度信息分别为Xi=[xi1,xi2,…,xiN]、Vi=[vi1,vi2,…,viN],i=1,2,…,m;学习因子为c1和c2。
粒子的位置更新为:
(1)
粒子的速度更新为:
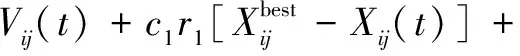
(2)
式中:t为当前时刻;c1为认知因子;c2为社会因子;i为第i个粒子,i=1,2,…,m;j为第i个粒子的进化代数,j=1,2,…,N;r1、r2为[0,1]之间的随机整数。
寻优结束的条件为迭代次数达到最大进化代数或者寻优精度达到要求。
2.2 带惯性权重的改进型粒子群优化算法
随着PSO算法迭代次数的不断增加,模型辨识过程中求解细节也会发生变化,容易陷入局部最优。改进PSO算法是在速度算式(2)中引入惯性权重w,即:
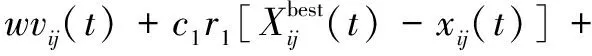
(3)
式中:w为惯性权重。
惯性权重代表了上一时刻速度信息在当前速度信息中所占的比例,而惯性权重的引入能够增强算法的动态搜索性能,避免陷入局部最优。惯性权重较大时,有利于全局搜索;惯性权重较小时,有利于局部搜索[11-12]。
2.2.1 线性递减惯性权重策略
惯性权重采用线性递减的策略,前期便于算法在整个问题空间寻优,后期便于算法的收敛。线性递减惯性权重wl的计算式为:
(4)
式中:wl max和wl min分别为wl的最大值、最小值;Tl max为最大的迭代数;t为当前的迭代数。
2.2.2 自适应惯性权重策略
对于线性递减惯性权重策略,当处于寻优初期时,惯性权重较大,容易在全局范围内寻找到较优值;当处于寻优后期时,如果算法有较小的惯性权重,有利于算法快速收敛,找到最优值。而采用线性递减策略的惯性权重不利于快速收敛。为此,本文采用一种非线性自适应惯性权重策略对w进行调整,以解决辨识过程中的快速收敛问题。在这个策略中,惯性权重、迭代次数和每个粒子的适应度值都有关。自适应惯性权重算式为:
(5)

当Qi≤Qavg时,当前粒子的适应度值优于当前所有粒子的平均适应度值,与之相对应的惯性权重较小,有利于局部搜索,以此保护该占优粒子。当Qi>Qavg时,该粒子惯性权重值为wmax,具有更强的全局搜索能力。
3 床温动态模型辨识
3.1 可辨识性分析
由于分布式控制系统(distributed control system,DCS)和厂级监控信息系统(supervision information system,SIS)的存在,使得现代大型火电机组生产过程中的大量运行数据可被方便地保存和查看。这些数据均为没有断开反馈回路在闭环控制状态下产生的数据,为系统的闭环辨识提供了有利条件。机组在长时间的运行过程中储备了大量的、不同工况下的数据,因此,闭环辨识过程中存在大量的、利于系统辨识的激励状态。此外,根据现有经验,只要数据信噪比足够大,床温控制系统就具有系统闭环辨识的可行性。
PSO算法可以不用考虑输入信号源的形式,根据输入/输出数据拟合出系统的传递函数。本文采用带有自适应惯性权重的改进型PSO算法,对多变量输入床温动态模型进行辨识。
3.2 数据的筛选与预处理
筛选山西某350 MW CFB机组在某一时间段内燃料量、一次风量、二次风量和平均床温的现场运行数据。电厂运行数据曲线如图4所示。
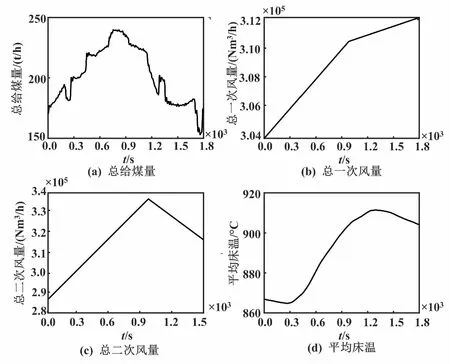
图4 电厂运行数据曲线Fig.4 Power plant operation data curves
由图4可知,床温从稳态开始有较大的起伏,然后趋于稳定。截取该时间段内的数据,作为辨识的原始数据。由于实际的现场数据存在较多不确定因素,直接使用这些数据进行模型辨识,会导致辨识出的模型存在较大误差,不能有效表征床温的动态特性,所以需要对这些数据进行预处理。
选取前10个点平均值作为初始值,对数据进行零初始值处理。
对于某些没有明显函数规律但存在前后关联的时间序列,进行零初始值处理后,还需要进行一阶指数平滑处理。算式如下:
y′t+1=a×yt+(1-a)×y′t
(6)
式中:a为平滑系数,a∈[0,1];yt为t期的实际值;y′t为t期的预测值;y′t+1为(t+1)期的预测值。
零初始值处理和一阶指数平滑处理可以将工业现场热工过程实际零点与系统平衡点区分开,消除测量噪声。零初始值处理和一阶指数平滑后的数据曲线如图5所示。
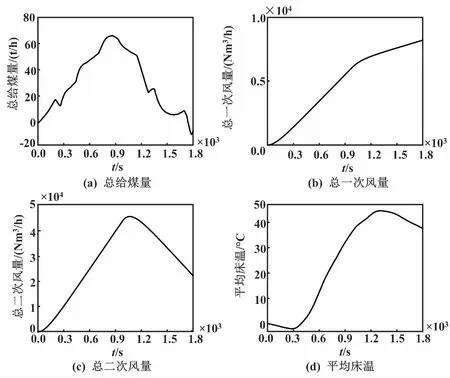
图5 零初始值处理和一阶指数平滑后的数据曲线Fig.5 Data curves after zero initial value processing and first-order exponential smoothing
3.3 模型辨识
采用自适应惯性权重PSO算法对床温模型进行辨识,设置参数如下:粒子数为200;训练迭代次数为100;适应度函数为均方误差函数;学习因子为c1=2、c2=2;惯性权重为wmax=1.2、wmin=0.8;粒子速度为Vmax=1、Vmin=-1。
燃料量与床温的动态模型选用以下含纯迟延的高阶惯性环节的传递函数:
(7)
式中:K1∈(0.01,10);T1∈(100,400);τ1∈(50,150);n1∈(1,4)。
一次风量与床温的动态模型选用具有自平衡能力的逆向响应结构的传递函数:
(8)
式中:K21∈(0,10);T21∈(100,400);τ21∈(0,50);n21∈(1,4);K22∈(0,50);T22∈(100,400);τ22∈(50,200);n22∈(1,4)。
二次风量与床温的动态模型选用含纯迟延的高阶惯性环节的传递函数为:
(9)
式中:K3∈(-5,5);T3∈(100,300);τ3∈(1,100);n3∈(1,4)。
采用线性递减惯性权重策略PSO算法和自适应惯性权重策略PSO算法,对上述三个模型进行辨识。床温动态模型辨识结果如图6所示。

图6 床温动态模型辨识结果Fig.6 Identification result of bed temperature dynamic model
对两种辨识结果进行误差分析,误差函数算式如下:
(10)
(11)
(12)

由图6和表1可知,两种辨识模型的误差值均较小。采用自适应惯性权重策略时,PSO算法辨识所得模型的各项误差指标均优于采用线性递减惯性权重策略的PSO算法,所得模型精度更高。辨识所得的各传递函数如式(13)~式(15)所示。
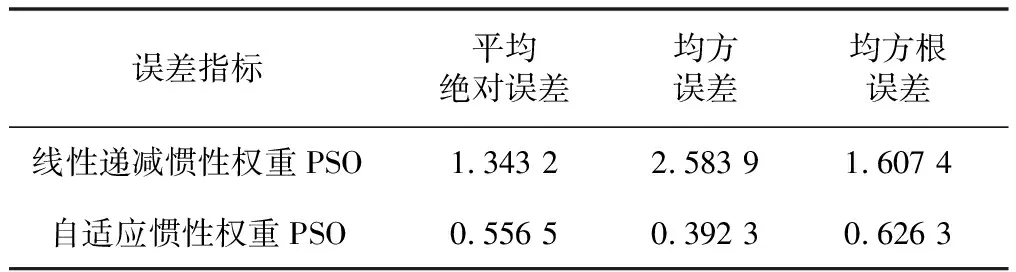
表1 两种辨识结果的误差指标
燃料量的传递函数模型为:
(13)
一次风量的传递函数模型为:

(14)
二次风量的传递函数模型为:
(15)
3.4 模型验证
将截取后的数据代入所得模型中,验证模型的准确性。辨识模型验证结果的误差指标如下:平均绝对误差为0.439 7%;均方误差为0.355 7%;均方根误差为0.596 4%。
辨识模型的验证结果如图7所示。

图7 辨识模型的验证结果Fig.7 Verification results of the identification model
由图7可知,曲线的拟合程度较好,各项误差值较小,辨识结果具有较高的精度。所以该系统模型可以反映床温在燃料量、一次风量和二次风量扰动下的动态特性。
4 结论
针对CFB锅炉床温波动频繁、影响因素众多等特点,筛选山西某350 MW CFB机组现场运行数据,采用自适应惯性权重PSO算法建立以燃料量、一次风量、二次风量为系统输入,以床温为系统输出的多变量单输出床温动态模型。
仿真及计算误差函数证明,与线性递减惯性权重策略的PSO算法相比,自适应惯性权重策略的PSO算法在辨识动态模型时更具有优势。该算法收敛速度更快,所得模型精度更高、误差更小,能够基本反映输入变量和床温之间的动态关系。该研究在CFB锅炉的床温自动控制及优化方面具有一定指导意义。
猜你喜欢
西安工程大学学报(2022年4期)2022-08-27
汽车实用技术(2022年12期)2022-07-05
中学生数理化·八年级物理人教版(2022年3期)2022-03-16
电力与能源(2021年4期)2021-09-07
中学生数理化·八年级物理人教版(2021年3期)2021-07-22
东北电力技术(2020年7期)2020-12-13
应用能源技术(2019年11期)2019-12-03
山东工业技术(2018年6期)2018-03-26
海峡科技与产业(2017年12期)2018-01-18
应用能源技术(2015年1期)2015-02-27
