
基于近红外光谱技术的赣南茶油掺假快速鉴别
2022-07-01 02:21沈乐丞曾秀英温志刚张远聪刘贤标范伟华
中国油脂 2022年6期
沈乐丞,曾秀英,温志刚,张远聪,刘贤标,王 玫,刘 婷,范伟华,邹 辉
(国家油茶产品质量监督检验中心/赣州市产品质量监督检验所,江西 赣州 341000)
油茶籽油,又名茶油、木籽油、山茶油,取自山茶科山茶属油茶树种子,是我国特有木本植物油之一[1]。油茶籽油富含油酸、亚油酸等不饱和脂肪酸[2],其脂肪酸组成与橄榄油非常相似[3],被称为“东方橄榄油”[4]。
油茶籽油既可以食用也可以入药,市场上的价格比普通植物油高5~10倍。随着人们生活水平的提高和健康意识的增强,油茶籽油受到消费者的关注[5]。一些不法经营者以高额利润为目标,在油茶籽油中混入相对便宜的普通植物油作为纯油茶籽油出售,严重损害了消费者和合法经营者的正当权益。目前,油茶籽油的掺假鉴别方法主要有气相色谱法[6-7]、气质联用法[8-10]、液相色谱法[11]、核磁共振法[12-13]、电子鼻[14-15]、电子舌[16]等方法。这些方法对仪器设备要求较高,需要大型、昂贵的设备或复杂的预处理[17],因此整个检测过程耗时、复杂且成本高,无法满足快速鉴别掺假油茶籽油的要求。近红外光谱技术近年来发展迅速[18],其不需要任何处理,可以直接测试[19],具有高效率、高速、无损耗、绿色等特点,还可以同时测定几种不同的成分[20-21]。目前,已经报道了一些应用近红外光谱技术检测掺假油茶籽油的研究[22-24]。上述研究方法一般采用整个光谱的数据或吸收峰附近的一些光谱数据作为研究对象,导致数据的冗余或缺失,从而无法有效地提取对建模有用的信息,同时主成分数对模型效果的影响研究很少,目前也没有线性建模方法和非线性建模方法对油茶籽油掺假鉴别的比较研究。
针对上述问题,本文以赣南茶油为研究对象,通过掺入不同植物油如玉米油、花生油、菜籽油、葵花籽油和大豆油等制备掺假油茶籽油,应用近红外光谱技术采集其光谱特征信息,对比不同预处理方法和主成分数,并结合线性和非线性建模方法建立油茶籽油掺假鉴别模型,研究快速无损鉴别掺假油茶籽油的可行性,为准确识别油茶籽油真伪提供一种快速鉴别方法,也为后续开发便携式掺假油茶籽油检测仪提供基础数据。
1 材料与方法
1.1 试验材料
1.1.1 试验样品
本试验共选取5个赣南茶油样品,为保证样品真实性,均来源于赣州本地油茶籽自榨。模拟掺假的植物油有玉米油、葵花籽油、花生油、菜籽油、大豆油,各类植物油均来自3个不同产地,模拟掺假的植物油样品共计15个。准备样品时,将这15个模拟掺假的植物油样品掺入5个赣南茶油样品中,掺假比例分别为1%、3%、6%、10%、15%和20%,每份样品约10 g,共得到450份掺假油茶籽油样品。另外,按混合比例10%、20%、40%、80%、100%将5个纯油茶籽油样品两两混匀,共获得45份不同的纯油茶籽油样品。
试验用油均由国家油茶产品质量监督检验中心提供,经检验均符合相关国家标准。试验期间,所有样品均在保质期内。
1.1.2 试验仪器及软件
DS2500型近红外光谱仪(配备浆状杯),福斯分析仪器有限公司;近红外光谱仪自带的光谱分析软件WinSI;Matlab2019软件,美国The MathWork公司。
1.2 试验方法
1.2.1 近红外光谱采集
利用DS2500型近红外光谱仪采集样品的近红外漫反射光谱。测试参数为:光谱扫描范围833~2 500 nm(12 000 ~4 000 cm-1);扫描次数32次;光谱分辨率3.5 nm;采集温度为室温(23~25 ℃)。每个样品测试3次,取平均值作为该样品的最终光谱。
1.2.2 光谱预处理
采集的近红外光谱含有丰富的信息,主要反映的是含氢基团的合频吸收以及倍频吸收特征。另一方面,这些信息中存在信噪比低、谱带重叠激烈、频谱信息的专业属性差等影响模型预测效果的要素。因此,在建模前需要对采集的原始光谱进行预处理。典型的光谱预处理方法有均值中心化(MC)、标准正态变量变换(SNV)、多元散射校正(MSC)、一阶微分(FD)、二阶微分(SD)等。MC可以将每个数据矩阵减去平均值,简化和稳定后续数据处理单元的计算;SNV和MSC可以消除表面散射、固体颗粒尺寸和光程变化对近红外漫反射光谱的影响,实现噪声去除效果;FD、SD等导数预处理方法可以降低由系统内部引起的随机噪声,并且可以提高处理后信号频率的分辨率[25]。选择上述几种方法对光谱进行预处理。
1.2.3 建模方法和评价指标
油茶籽油掺假信息与近红外光谱数据之间的关系是线性的还是非线性还有待研究,因此在本试验中,尝试用线性判别分析(LDA)和人工神经网络(ANN)构建茶油掺假鉴别模型。详细建模过程如图1所示。
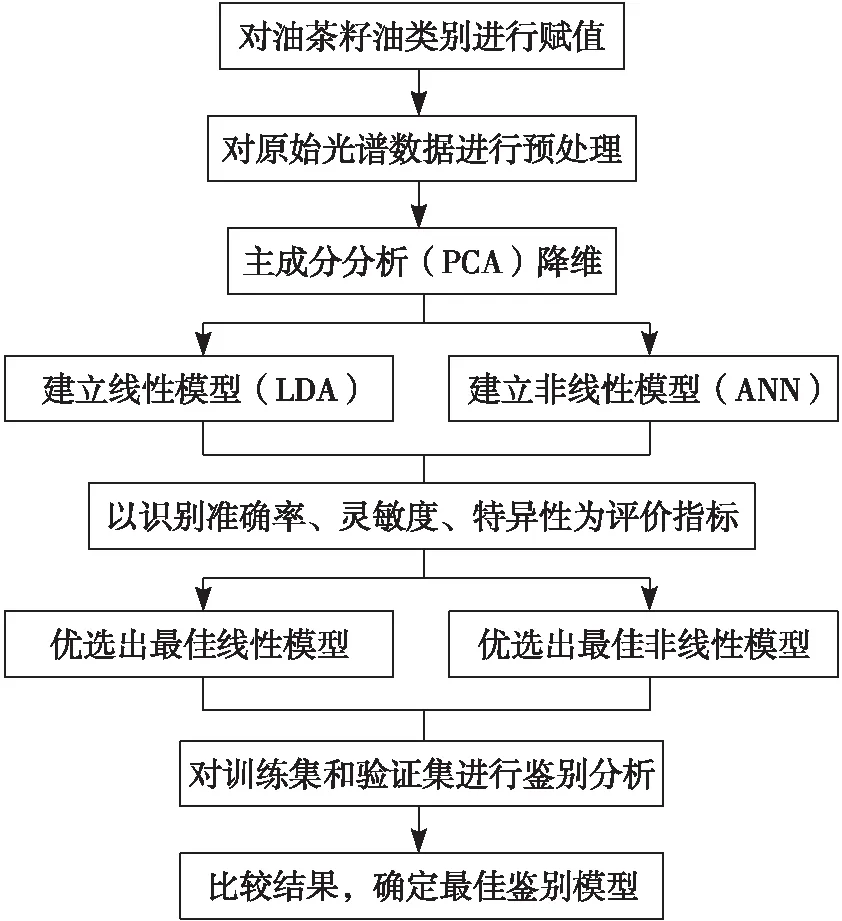
图1 油茶籽油掺假鉴别模型构建过程
由图1可见,油茶籽油掺假鉴别模型构建具体过程为:①将不同掺假比例油茶籽油进行赋值,即纯油茶籽油为1,非纯油茶籽油为2,此为分类变量Yt;②对原始光谱进行预处理,既去除噪声影响又增强光谱特征;③主成分分析(PCA)降维,简化模型;④采用LDA和ANN分别构建分类变量与光谱之间的线性和非线性模型,以识别准确率(纯油茶籽油样品和掺假油茶籽油样品被正确判别的比例)、灵敏度(纯油茶籽油样品被正确判别为纯油茶籽油的比例)、特异性(掺假油茶籽油样品被正确判别为掺假油茶籽油的比例)作为油茶籽油掺假鉴别模型的评价指标,分别优选出最佳模型;⑤以该模型预测训练集和验证集样本,得到预测值Yp,并判别其真假。具体判别依据:分类变量预测值Yp,真实分类变量Yt,当Yp-Yt=0,则属于该类别,判别正确;当Yp-Yt=-1,则属于将非纯油茶籽油判别为纯油茶籽油,判别错误;当Yp-Yt=1,则属于将纯油茶籽油判别为非纯油茶籽油,判别错误。
2 结果与分析
2.1 光谱分析
本研究共采集到495份纯油茶籽油和掺假油茶籽油样品的近红外光谱图,所有样品的原始近红外光谱如图2所示。
图2 所有样品的原始近红外光谱

2.2 LDA油茶籽油掺假鉴别模型的建立
2.2.1 样本划分与主成分数的确定
将 495 份样本随机划分为训练集和验证集,训练集为 330 份样本(掺伪油茶籽油和纯油茶籽油分别为300份和30 份),验证集为165份样本(掺伪油茶籽油和纯油茶籽油分别为150份和15 份)。
选用合理的主成分数不仅可以提高模型的稳定性和精密度,还可以减少运算时间[27]。在本研究中,使用交叉验证法[28]确定鉴别模型的最佳主成分数,主成分数从1至10,每隔一个数分别试建LDA模型,以训练识别准确率和交叉验证识别准确率作为评价指标,确定LDA模型的最佳主成分数。LDA模型在不同主成分数下训练和验证的结果如图3所示。
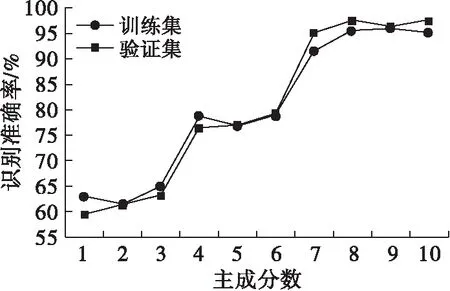
图3 LDA模型在不同主成分数下训练和验证的结果
由图3可知,主成分数对LDA识别模型的预测结果有较大影响,当主成分数小于8时,随着主成分数的增加,训练集和验证集模型的识别准确率都迅速上升,当主成分数达到8时,验证集识别准确率达到最高,为97.58%,对应的训练集识别准确率为95.45%,随后验证集识别准确率随着主成分数的增加总体下降。良好的识别模型不仅需要高训练集识别准确率,而且需要较高的验证集识别准确率,通常后者更重要。因此,本研究选择8作为LDA识别模型的最佳主成分数。
2.2.2 不同预处理方法的LDA模型预测结果
选择前述主成分数进行LDA建模,不同预处理方法下 LDA 建模的预测结果见表1。
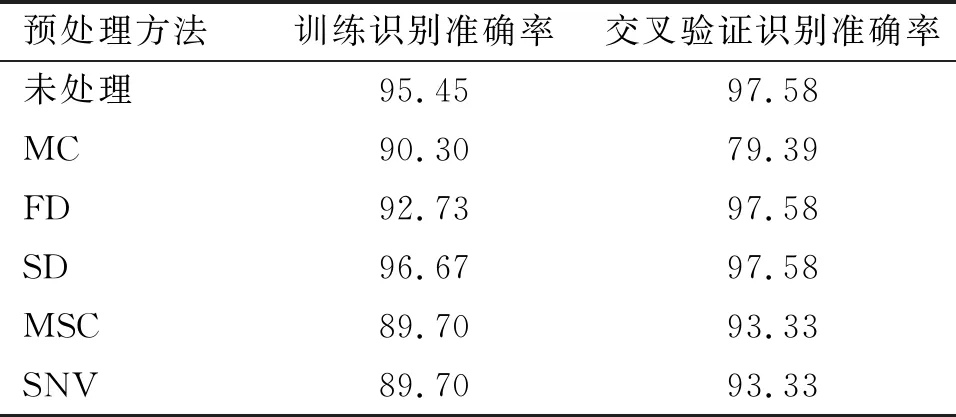
表1 不同预处理方法下 LDA 建模的预测结果 %
从表1可以看出,经SD预处理后,LDA模型的训练识别准确率与未处理相比上升了1.22百分点,其他4种预处理方法的模型训练识别准确率与未处理相比均有不同程度的降低,可能是由于SD消除了基线的旋转和背景干扰引起的数据偏差,而MC、FD、MSC、SNV在去除基线漂移和减少样本信号噪声影响的同时也丢失了一部分有用信息。经SD预处理后所有样品的近红外光谱图如图4所示,其所建模型的训练识别准确率和交叉验证识别准确率在5种预处理方法中最高,分别为96.67%和97.58%。因此,SD联合LDA建模的效果更好。
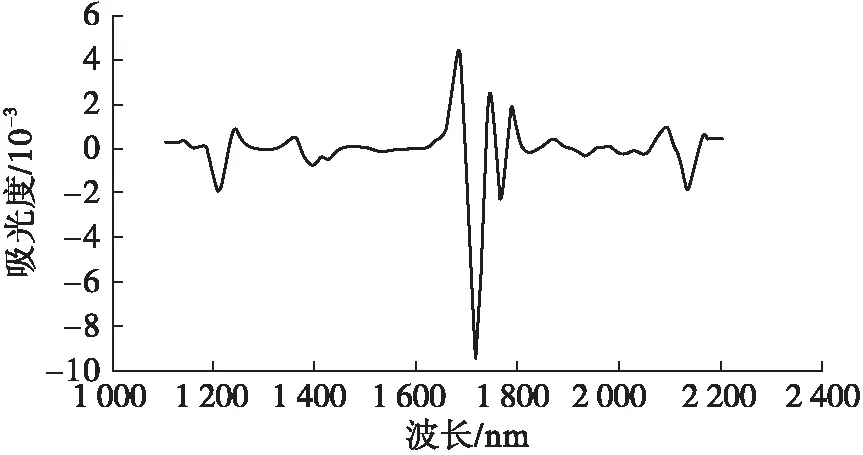
图4 经SD预处理后所有样品的近红外光谱图
2.2.3 LDA模型对油茶籽油掺假鉴别与分析
应用SD联合LDA模型,对训练集和验证集样本进行判别分析,SD-LDA模型鉴别油茶籽油掺假统计结果见表2。

表2 SD-LDA模型鉴别油茶籽油掺假统计结果
由表2可知,该模型对训练集和验证集的误判个数分别为11、 4。在训练集的样本鉴别过程中,将2个纯油茶籽油误判为掺假油茶籽油,9个掺假油茶籽油误判为纯油茶籽油,灵敏度和特异性分别为93.33%和97.00%;在验证集样本鉴别过程中,将纯油茶籽油全部识别正确,4个掺假油茶籽油误判为纯油茶籽油,灵敏度和特异性分别为100%和97.33%。SD-LDA模型对训练集和验证集的识别准确率分别为96.67%、97.58%。
2.3 ANN油茶籽油掺假鉴别模型的建立
2.3.1 样本划分与主成分数的确定
将 495 份样本按3∶1∶1随机划分为训练集、验证集和测试集,训练集为 297 份样本,验证集为99份样本,测试集为99份样本,其中测试集样本不参与建模,只供最后测试模型性能用。
原始光谱数据维数较高,若将其直接作为神经网络的输入变量,模型太复杂、运算时间过长。本研究选用 PCA提取主成分,通过降维处理,以提高建模速度和准确度。不同主成分数的累积贡献率如图5所示。
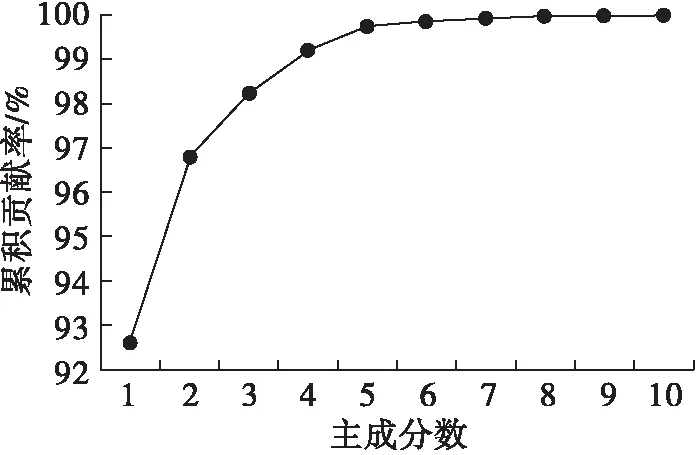
图5 不同主成分数的累积贡献率
由图 5可知,前 8 个主成分累积贡献率已达到99.96%,说明前 8 个主成分包含了原始 315个波长中 99.96%的信息,满足建模需求,故本次ANN油茶籽油掺假鉴别模型的最佳主成分数确定为8。
2.3.2 不同预处理方法的ANN模型预测结果
本试验采用两层前馈神经网络,将上述8个主成分作为输入层神经元,选用 sigmoid 和 softmax 作为隐藏层和输出层的转换函数,训练函数选用 trainscg。网络训练时,最大训练步数为 1 000,当验证样本的交叉熵误差增加时,停止训练。根据多次训练结果确定隐含层节点数为10,神经网络构造图如图6所示。不同预处理方法下 ANN 建模的预测结果见表 3 。
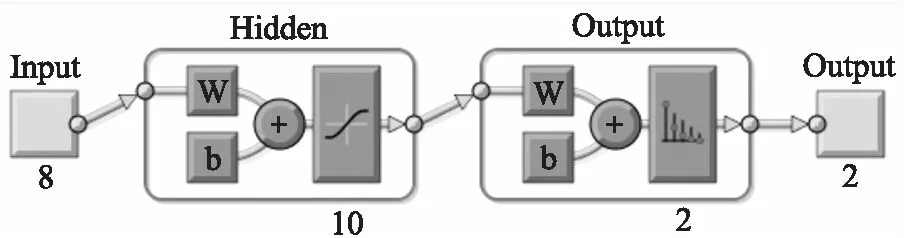
图6 神经网络构造图
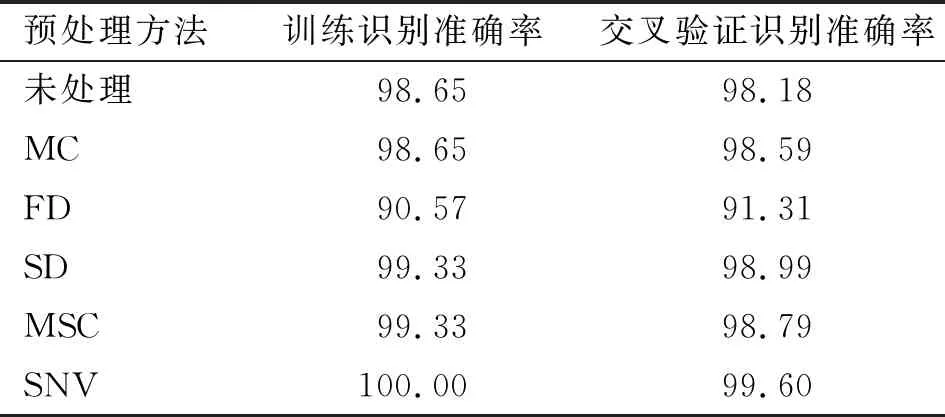
表3 不同预处理方法下 ANN 建模的预测结果 %
从表3可以看出,不同预处理方法的交叉验证识别准确率在 91.31%~99.60%范围内,与未处理相比,除了FD,其余4种预处理方法交叉验证识别准确率均有不同程度提高。经SNV预处理后所有样品的近红外光谱图如图7所示,其建模效果最优,训练识别准确率和交叉验证识别准确率分别为 100%和99.60%。
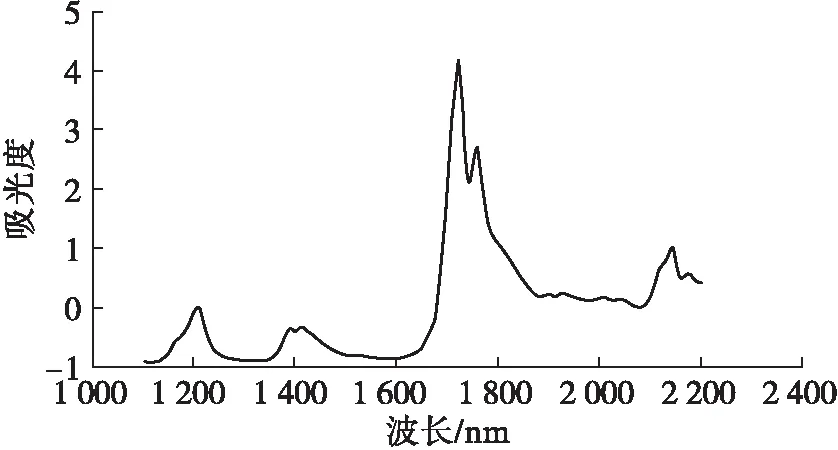
图7 经SNV预处理后所有样品的近红外光谱图
2.3.3 ANN模型对油茶籽油掺假鉴别与分析
应用SNV联合ANN模型,对训练集和验证集样本进行判别分析,SNV-ANN模型鉴别油茶籽油掺假统计结果见表4。
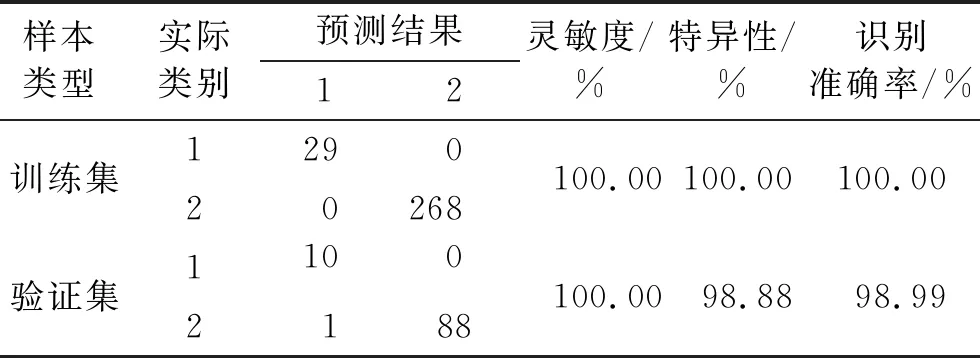
表4 SNV-ANN模型鉴别油茶籽油掺假统计结果
从表4可以看出,该模型对训练集和验证集的误判个数分别为0和1。在训练集样本的鉴别过程中,模型能完全识别纯油茶籽油和掺假油茶籽油,灵敏度和特异性均为100%;在验证集样本鉴别过程中,将纯油茶籽油全部识别正确,1个掺伪油茶籽油误判为纯油茶籽油,灵敏度和特异性分别为100%和98.88%。SNV-ANN模型对训练集和验证集的识别准确率分别为100%和98.99%。
2.4 建模方法及建模结果比较
根据表1和表3对两种模型性能进行比较后可知,除FD外,其他预处理方法下所建LDA模型的训练识别准确率和交叉验证识别准确率均比ANN模型的低,说明ANN模型性能更强。根据表2和表4对两种建模方法所得的最优模型的灵敏度、特异性进行比较,发现SD-LDA模型和SNV-ANN模型对纯油茶籽油识别能力相当,对掺假油茶籽油识别能力后者更强,说明非线性模型更适于油茶籽油掺假判别。此外,两个模型的输入主成分数只有 8 个,对于模型的简化、操作时间的减少、快速识别目的的实现以及随后的便携式掺假油茶籽油检测设备的开发具有重要的意义。
3 结 论
本研究利用近红外光谱技术采集了不同模拟掺假油茶籽油的光谱数据,比较不同的预处理方法和主成分数,进行了线性和非线性建模,结合线性和非线性建模方法,开展了油茶籽油掺假快速鉴别问题研究,结果表明: SD联合线性判别分析(SD-LDA)、SNV联合人工神经网络(SNV-ANN)分别为最优线性和非线性模型,其训练识别准确率和交叉验证识别准确率分别为96.67%、97.58%和100%、98.99%。SD-LDA模型与SNV-ANN模型对纯油茶籽油识别能力相当,后者对掺假油茶籽油识别能力更强,说明非线性模型在油茶籽油掺假判别方面更具有优势。因此,SNV-ANN 可以更准确地鉴别油茶籽油是否掺假。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
材料与冶金学报(2022年2期)2022-08-10
温州大学学报(自然科学版)(2022年2期)2022-05-30
黑龙江大学自然科学学报(2022年1期)2022-03-29
健康之家(2021年19期)2021-05-23
空间科学学报(2021年1期)2021-05-22
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
建材发展导向(2021年23期)2021-03-08
健康体检与管理(2021年10期)2021-01-03
