
基于双区块链结构的高维光谱离群数据挖掘
2022-07-02 13:55程雅琼
电脑知识与技术 2022年15期
关键词:数据挖掘
程雅琼

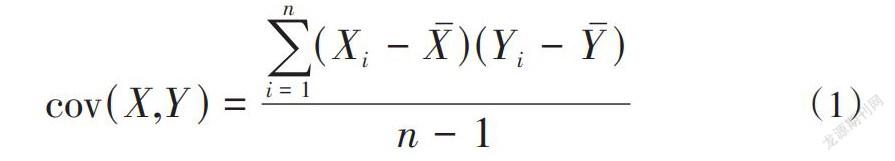

摘要:在对高维光谱数据集中的离群数据进行分类和挖掘时,由于传统基于逆k近邻计数的挖掘方法在应用中极易受到宇宙背景噪声、光线衰弱等因素影响,使得成功挖掘出的离群数据点数量少,最终会严重影响挖掘精度。针对这一问题,在引入双区块链结构的基础上,开展高维光谱离群数据挖掘方法设计研究。通过基于双区块链结构的高维光谱数据获取、高维光谱数据离群点检测、基于离群分数的三元组挖掘样本选择和高维光谱离群数据分离,提出一种全新的挖掘方法。通过实验证明,新的挖掘方法可有效解决上述问题,促进挖掘精度的不断提升。
关键词:双区块链结构;离群数据;高维光谱;数据挖掘
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2022)15-0017-02
当前科学技术的快速發展也在一定程度上促进了天文领域的发展,同时也使得天文数据呈现出爆炸式的增长趋势。目前世界上光谱获取率最高的望远镜是LAMOST望远镜,在夜晚观测条件下能够获取到数万条的光谱,能够为天文领域的相关研究提供更加可靠的依据和素材,对于促进天文领域的完善和快速发展而言都有着十分重要的意义。针对高维光谱的分类是从上千维的光谱数据当中,选择或提取能够实现更精准识别的特征,并将各个特征汇总构建一个特征空间[1]。同时,在对高维光谱进行分类的过程中,光谱数据集当中通常会存在一部分离群分布的数据,由于其特征与已知的天体特征区别较大,因此常常被划分为一类未知的光谱数据类别。这些离群数据在高维数据集当中存在的主要原因,是由于宇宙背景噪声、光线衰弱等因素对光谱数据造成了严重的污染,进而使得这一部分数据无法实现准确识别[2]。针对这一问题,该领域研究人员对其进行了不断探索,并逐步提出多种对高维光谱离群数据进行分类识别的挖掘方法。但由于针对这一问题的研究起步较晚,因此目前大部分挖掘方法在实际应用中都存在训练时间长、识别精度低的问题。因此,针对上述论述,本文在引入双区块链结构的基础上,开展对高维光谱离群数据挖掘方法的设计研究。
1 基于双区块链结构的高维光谱离群数据挖掘方法设计
1.1 基于双区块链结构的高维光谱数据获取
在高维光谱数据集中,由于数据量巨大,因此为了确保后续挖掘的效率和精度,在挖掘前需要从不同的文件当中获取待挖掘的数据,并在完成对数据的提取后,针对其不同维度进行预处理。预处理的内容主要包括对数据的标准化处理和对其主成分的降维分析处理。针对占用空间较大,并且分布在不同文件中的高维光谱数据,采用直接读取文件的方式会消耗大量的时间,因此针对这一问题,本文将原始数据根据高维光谱数据ID存入MySQL数据库当中,并在后续挖掘的过程中,随机抽取少部分数据,并将其存入到h5文件当中,将其视为训练集和测试集,以此提高对高维光谱离散数据挖掘的效率[3]。同时,在后期完成挖掘后,也可通过这一操作,采用随机数获取表格ID的方式,使用MySQL数据库当中的数据,进一步提高数据的利用价值。通过上述操作获取到的高维光谱数据可以实现由于序号造成数据片面化的问题,进而使整个数据集的特性得到更充分地发挥[4]。在完成对高维光谱数据的获取后,基于其海量数据特点,引入双区块链结构,将获取到的数据进行存储。图1为基于区块链结构的高维光谱数据存储结构示意图。
在图1所示的存储结构基础上,可确保在挖掘过程中更精准地获取需要进行挖掘的数据集,进一步为离群数据的挖掘提供依据。同时,存储在上述结构当中的数据集为经过PCA降维处理后的数据。在处理的过程中,可结合协方差矩阵对其进行降维,协方差矩阵表达式为:
[cov(X,Y)=i=1n(Xi-X)(Yi-Y)n-1] (1)
公式(1)中,[cov(X,Y)]表示为两个高维随机变量度量结果;[X]和[Y]表示为均值;[Xi]和[Yi]表示为某组数据i当中的数据。根据上述公式(1)完成对所有高维光谱数据的PCA降维处理[5]。协方差矩阵的实质是实现对两个随机变量关系的度量统计,通过协方差矩阵计算后,数据集当中存在的高维光谱数据能够实现降维处理,从而为后续挖掘提供便利条件。
1.2 高维光谱数据离群点检测
根据上述论述内容,在完成对基于双区块链结构的高维光谱数据获取后,并实现对数据的PCA降维处理,需要对数据集当中所有离群点进行检测。通过随机选择某一数据集当中的子集,选择某一数据点到数据子集之间最近的三个点,并计算求解得出其平均数值,通过不断重复上述操作,最终得到该组数据的离群分数,其表达式为:
[χ=rm] (2)
公式(2)中,[χ]表示为某一组数据的离群分数;[r]表示为某一数据点到数据子集之间最近的三个点,并计算求解得出其平均数值;[m]表示为重复操作次数。在这一数据的基础上,引入正态分布,对数据点到随机子集之间的距离进行分析,并将与该数据中心距离较远的两侧数据作为离群值[6]。具体而言,在进行离群点检测的过程中,其流程可大致分为以下四个步骤:第一步,随机选择高维光谱数据集当中的抽取数据子集;第二步,计算待挖掘的数据到该数据子集之间的欧氏距离;第三步,计算求解多个点之间欧氏距离的平均值,并按照公式(2)完成对离群分数的计算;第四步,设置阈值,并按照如下公式,找出相应数据点:
[r>μ+ασ] (3)127CF405-BA7B-47CF-A338-3B3B5F1F764A
公式(3)中,[μ]表示为均值;[σ]表示为常数。若检测点相关参数代入到上述公式(3)中成立,则说明该检测点为离群点;若检测点相关参数代入到上述公式(3)不成立,则说明该检测点不是离群点。按照上述四个步骤,完成对高维光谱离群点的检测。
1.3 基于离群分数的三元组挖掘样本选择
在完成对高维光谱数据离群点检测后,为了能够进一步提高挖掘的精度,引入表示学习理论,针对数据集当中的所有离群数据点进行获取,并结合上述离去分数的计算结果,实现对三元组挖掘样本的选择,并通过该样本完成对本文挖掘方法的迭代训练[7]。具体而言,在选择过程中應当首先根据上述公式(2)计算的结果,从高维光谱内部候选集当中抽取多个需要进行查询的对象,并以此获取到训练样本。假设需要进行挖掘的数据对象被抽样成为查询对象的概率为P,并且这一数据的变化与其异常值恰好呈现出反比例变化关系,根据上述论述,得出P的表达式为:
[P=Z-rit=1i(Z-rt)] (4)
公式(4)中,[Z]表示为所有高维光谱数据集内部异常值的总和;[r]表示为某一待挖掘的数据对象对应的离群值分数;[rt]表示为高维光谱数据集内部候选集合异常值。结合上述公式,完成对P值的计算后,根据均匀概率从内部候选集当中选择出内部数据的正样本。最后,再从异常候选集中获取到离群数据的负样本,选择最可能为异常值的数据作为负面实例的最高概率,通过给定该数据的变化范围,确定其负面实例出现的概率,并将上述得出的所有结果构成一个完整的三元组样本,以此为挖掘训练提供可靠的挖掘样本。
1.4 高维光谱离群数据分离
在完成对样本的选择后,通过不断迭代训练促进挖掘方法的精度提升,在完成挖掘后,还需要对高维光谱数据当中已经被找出的离群数据进行分离。引入浅层表示学习网络,采用一层双向长短期记忆层和一层全连接层的结构,对上述获取到的三元组挖掘样本进行大量计算,并在进行预处理后结合深度学习方法,以此增加时间开销,并得到精度更高的挖掘结果。在浅层表示学习网络当中将缩减数据集、稀疏度系数阈值等作为输入,将最终得到的局部离群数据分离结果作为输出。在该网络结构当中,根据子节点的数量和缩减数据集的条数,计算得出各个子节点需要进行计算的数据子集个数,即缩减数据集条数/节点数目。在主节点通过表示学习网络搜索后,对其挖掘任务进行编号,并依次完成对所有子集中数据节点的编号。按照上述离群点检测流程,将所有符合公式(3)的数据子集汇总,并输出,从而实现对离群数据的分离。
2 对比实验
通过本文上述论述,在明确了基于双区块链结构的挖掘方法基本应用思路后,为了进一步验证这一挖掘方法的应用效果。选择以天文领域当中的某一高维光谱数据集作为研究对象,分别利用本文提出的基于双区块链结构的挖掘方法和传统基于逆k近邻计数的挖掘方法对该数据集当中的离群数据进行挖掘和分离。在实验过程中,为了确保实验的客观性,首先需要对高维光谱数据集进行预处理,实现对其归一化,并通过PCA实现对高维光谱数据集的降维处理,以此也能够进一步简化实验过程。为了方便论述,将本文提出的挖掘方法设置为实验组,将传统基于逆k近邻计数的挖掘方法设置为对照组。在本文实验选择的数据集当中,其维数为50,光谱数据集分别含有5263(6M)、36448(42M)、71562(101M)、78596(112M)条。将上述所有数据统一存储在E4546CPU数据库当中,在实验过程中使用两台512MB内存计算机作为子节点,将其中一台作为主节点。在实验过程中,设置高维光谱离群数据的稀疏度为-1,将其稀疏因子设定为0.2,分别设置一种单机环境和一种并行环境,应用两种挖掘方法对实验数据集中的离群数据进行挖掘。对比实验组和对照组挖掘方法通过挖掘后得到的离群数据点个数,挖掘到离群数据点越多,则说明该挖掘方法更有效,更能够实现对高维光谱离群数据的准确识别;反之,挖掘到的离群数据点越少,则说明该挖掘方法利用价值越低,无法实现对高维光谱离群数据的准确识别。根据上述论述,记录实验组和对照组两种挖掘方法的应用效果,并绘制成表1。
从表1中得出的实验结果可以看出,实验组在单机环境下和并行环境下挖掘出的离群数据点个数均明显多于对照组挖掘离散数据点个数。同时,通过表1中数据进一步分析得出,对照组单机环境下对离散数据点的挖掘数量明显多于并行环境,其主要原因是并行环境中复杂因素较多,由于对照组挖掘方法没有能够抵抗外界干扰因素影响的能力,因此使得最终实验结果不理想,而实验组并没有出现这一问题,设置在对第一组数据和第三组数据进行挖掘时,并行环境的挖掘效果优于单机环境。因此,综合上述论述能够证明,本文提出的基于双区块链结构的挖掘方法在应用到对真实高维光谱数据集进行挖掘时,能够实现对其中大量离群数据点的准确挖掘,挖掘精度与以往基于逆k近邻计数的挖掘方法相比得到明显提高。
3 结束语
针对高维光谱数据集当中的离群数据,实现对其充分挖掘,对于后续高维光谱数据集的使用和天体数据分类处理而言,具有十分重要的作用。针对此,本文在引入双区块链结构的基础上,提出了一种全新的挖掘方法,并结合实验验证了该方法的可行性。但由于研究能力有限,在研究过程中,本文采用的数据处理方法在时间复杂度上过高,虽然能够确保最终挖掘结果的精度,但挖掘效率仍然有待进一步提升。因此,针对这一问题,在后续的研究当中,还将引入多种不同的算法和分类器,对本文挖掘方法进行不断完善,从而设计出一种更加适合用于对高维光谱中离群数据进行挖掘的方法,提高高维光谱数据的利用价值。
参考文献:
[1] 唐伟宁,刘颖,于旭,等.基于离群数据挖掘的低压窃电行为辨识方法研究[J].电子设计工程,2021,29(23):56-59,64.
[2] 尚福华,曹茂俊,王才志.基于人工智能技术的局部离群数据挖掘方法[J].吉林大学学报(工学版),2021,51(2):692-696.
[3] 田文祥.基于离群数据挖掘技术的高校学生学业预警研究[J].黑龙江科学,2021,12(7):54-56.
[4] 李林睿,常舒予,乔一鸣.基于表示学习的高维光谱离群数据挖掘[J].电脑知识与技术,2021,17(22):90-93.
[5] 马洋,赵旭俊,苏建花,等.基于核密度估计的离群数据挖掘[J].太原科技大学学报,2020,41(6):456-462,469.
[6] 罗念华,陶佳冶,刘俊荣.依赖大数据离群数据挖掘算法的业务系统间权限异构监控研究[J].自动化与仪器仪表,2019(5):179-182.
[7] 朱云丽,张继福.基于逆k近邻计数和权值剪枝的离群数据挖掘算法[J].小型微型计算机系统,2019,40(8):1627-1632.
【通联编辑:张薇】127CF405-BA7B-47CF-A338-3B3B5F1F764A
猜你喜欢
中国交通信息化(2020年1期)2020-07-27
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
河南科技(2014年23期)2014-02-27
河南科技(2014年19期)2014-02-27
电子设计工程(2014年18期)2014-02-27
电子设计工程(2014年18期)2014-02-27
智能系统学报(2013年1期)2013-01-28
智能系统学报(2013年2期)2013-01-28
