
基于协同训练的低资源电商领域上下位实体关系获取
2022-07-02 12:23阮义彰
电脑知识与技术 2022年15期
阮义彰




摘要:上下位关系获取对于下游电商至关重要。由于产品更新频繁,大规模手动获取关系是不切实际的。文章主要研究从低资源电商文本中自动获取下位关系。与开放领域不同,电商领域中标记的上下位词对是有限的,且电商领域产品描述中的句式特殊,使传统的基于序列的模型无效。为此,文章提出了基于Transformer的协同训练方法,通过理解产品描述探索潜在的高置信度词模式。实验结果与最先进的方法相比,F1和召回率显著提高。
关键词:电商领域;上下位关系;对抗训练;半监督学习;负样本提取
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2022)15-0079-03
1 引言
产品与类别上下位关系的自动获取是电商应用中的一项关键任务。上下位词显示了通用类别(即上位词)和它的特定实例(即下位词)之间的关系,例如电器和冰箱。获取上下位关系有助于构建产品类别系统,本文主要研究如何从产品描述中自动获取上下位关系。
2 相关背景
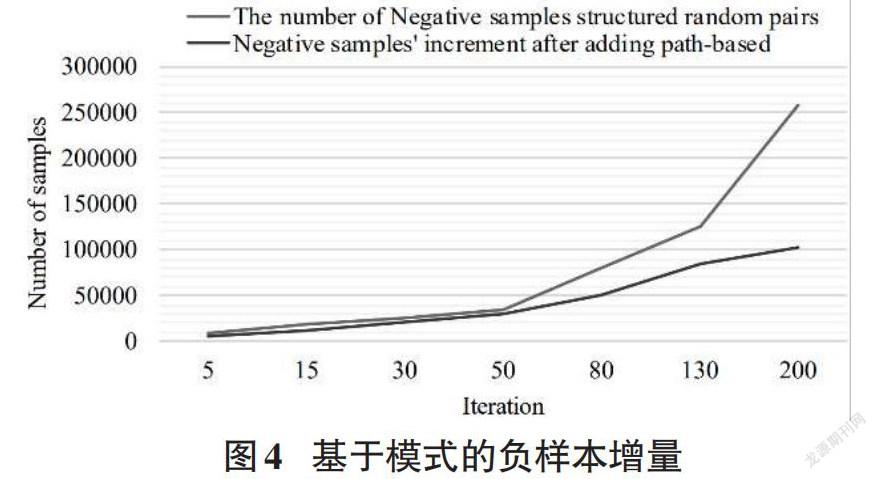
现有方法通常利用文本上下文来提取上下位关系,包括基于模式的方法[1-6]和表示学习方法[7-8]。然而,在电商领域,这两种方法往往是无效的。首先,产品描述通常由形容词和各种产品属性组成,而不是实例、动词和类别或概念等固化模式。表1中商品描述“2019新款冬季男士衣物韩版修身保暖厚羽绒服外套”完全没有动词,缺乏清晰的模式使得依赖基于模式的方法无效。其次,可以看到表1中的描述没有遵循良好的自然语言结构,它们是一组描述产品属性和销售特征的短语。因此,基于句子结构特征(如依赖树和词典句法路径)的方法,通常在电商领域无效。再次,表示学习方法依赖于大量训练样本,此外,高质量负样本也是必不可少的。传统的负采样方法通常是构造低质量的样本,对训练过程贡献不大。例如,随机抽样的一对(外套、水果)很容易区分,它们甚至不会一起出现在一个产品描述中。如图1所示,当随机采样的负对数为258,462时,现实世界的电商文本语料库(即产品描述)中仅出现200对。因此随机负样本会导致很容易识别出很少出现在产品描述中的负样本。
为了应对上述挑战,提出以下两点:1)利用Transformer网络理解中间词语义,从而获取嵌入空间中的上下位关系;2)通过设计协同训练框架迭代丰富训练样本,并使用开发的基于模式的负样本进行挖掘。本文将电商下位关系获取建模为二分类问题,并提出一种半监督分类器(Semi-supervised Transformer net,ST)。其输入是一个词对和包含该词对的产品描述,其输出是1(存在上下位关系)或0(不存在上下位关系)。ST从训练样本中学习显式“路径”(即中间词序列)知识和从训练样本中学习隐性的“嵌入”(即空间变换)知识。一方面,ST派生的“路径”知识用于获得更多高质量的训练样例(尤其是反例);另一方面,ST学习到的“嵌入”知识用于区分语义并准确产生分类结果。最后,本文从真实数据集中获得了实验结果。
3 半监督Transformer网络
3.1 概述
本文将具有高预测置信度的样本标记为监督数据,并以迭代方式(即使用协同训练过程)训练分类器。首先生成负样本(即基于模式的负样本和随机样本)以及正样本。然后根据预训练的词嵌入将这些样本转换为向量表示,再分别使用这两个样本集训练两个Transformer分类器。每次迭代中,从一个分类器中选择具有高置信度的预测结果作为监督,输入另一个分类器进行进一步训练。算法1给出了协同训练过程。
以下为两个内部分类器的最小化均方误差函数:[L=12Xx∈X(yx-f(x))2]。其中[yx]表示[x]的真实标签,[x]是训练样本集。
算法1 联合训练过程
[输入:文本语料库T,预训练单词嵌入W,最大迭代次数I
1. 对T进行数据预处理,提取两类训练样本[Xp]和[Xd],前者为基于模式的样本,后者为随机样本;
2. 使用单词嵌入W将每个训练样本转换为向量表示;
3. [X'p←∅] ,[X'd←∅], 将 [X'p] 和 [X'd] 表示新标注的训练样本集合;
4. for [i=1,2,…,I] do;
5. 用基于词模式的方法训练集合[fp]和[fd],将样本[Xp∪X'p ]和[Xd∪X'd]循环迭代;
6. 对未标记样本进行预测,选择具有高置信度的样本作为新的训练样本来扩展 [X'p] 和 [X'd];
7. 如果 [X'p] 和 [X'd] 都在本次迭代中没有收到新的标签样品,那么停止。 ]
3.2 基于Tansformer的分类器
1)预处理
对于产品描述片段,首先删除了“\%”“*”和“\&”等特殊字符;然后使用'.''!''?'';'作为分隔符将文本片段分割成一组句子S;然后每个标记都被视为实体的候选标志,并尝试将标记链接到实体。一个句子中两个链接之间的标记列表被视为对应实体之间的单词模式。本文用[e1,p1,p2,p3…pn-1,pn,e2]来表示链接标记和之间的标记,其中[e1]是頭实体,[e2]是后方实体,[p1,p2,p3…pn-1,pn]表示词模式。
2)嵌入查找
在模型中用向量表示每个标记,为了查找向量表示的单词模式和实体,使用了带有负采样的模型Skip-gram[8]从大型文本语料库(例如百度百科)中预训练单词嵌入[9]。对于词嵌入,本文将标记[p]转换为用向量表示的[p], [p=(p1,p2,…,pn)]用[n]表示[p=p1⊕p2⊕p3⊕p4] ,这里[⊕]表示串联,[p]是单词模式[p]的最终向量表示。对于一个简单的训练样本[s=(e1,p,e2)],用向量表示为: [s=e1⊕p⊕e2](这里[⊕]表示串联操作)。
3)内部分类器
如上所述,关键词填充和悬空词在产品描述中很常见,因此使用基于Tansformer的模型作为内部分类器。如图3所示,把[p]作为第一个输入,并将位置信息构造成一个矩阵作为第二个输入。然后,添加第一个和第二个输入作为嵌入输入,结果为多头注意力的输入。在多头注意力层中,通过线性变换得到词向量的序列,键向量和值向量的序列为[qi=W1pi], [ki=W2pi], [vi=W3pi],其中[W1,2,3]表示变换矩阵。前馈层是一个全连接网络,对每个位置向量进行相同的操作,包括线性变换和ReLU激活输出,再将最后一层与e1 和e2组合经过sigmoid,输出表示为b。当[bi≤0.5]时,标签预测为0,当[bi>0.5]时,标签预测为1。
3.3 训练样本构建
为了训练上述分类器,在实践中,可以很容易收集正训练样本。因此,本文主要研究如何在协同训练过程中构建负样本。文章提出两种负采样方法,即随机和基于模式的方法,用于构建负样本。
1)随机负采样
隨机负采样通过用随机采样的实体替换上下位词对中的一个实体来生成负样本。例如,可以基于正样本(苹果,水果)构造一个负样本(苹果,动物),使用负样本和正样本,可以收集一组下位实体对,表示为[X={x1,x'1,x2,x'2,x3,x'3,…,(xn,x'n)}]。
2)基于词模式的负采样
该方法使用单词模式作为挖掘负样本的关键,这些模式捕获了为什么两个实体没有下位关系。例如,给定一个否定对(苹果,动物),从包含这两个实体的句子中提取一个词模式:
……动物与苹果的首字母相同……
本文使用基于随机的负采样来生成负对,并排除包含“这”“那”和“一”等的负词对。与基于随机的负采样相同,不仅选择了下位词对的集合,而且还选择了这些对之间的单词模式。然后将这些对表示为[S={Sx1,x'1,Sx2,x'2,Sx3,x'3,…,S(xn,x'n)}],对之间的路径表示为[p=(p1,p2,…,pn)]。通过提取这些随机样本的单词模式并匹配训练数据集(即产品描述),通常会获得更多的负样本。例如,使用具有相同首字母的路径,可能会在训练数据集中找到以下负对(火龙果,紫色)。
S=(……火龙果与紫色的首字母相同……)
显然,实体对(火龙果,紫色)是非同义词对,反过来可以依靠(火龙果,紫色)来发现更多的负对及其路径。本文只考虑路径的长度(即路径中的标识数)不超过[102]。
4 实验
4.1 上下位词对数据集
本文使用开源中文语料库作为通用领域文本数据,其中包含超过一百万个结构良好的中文句子;并使用来自真实电商公司的产品描述,其中包括超过10亿个非结构化商品详细信息。同时还收集了大约200,000个上下位词对,通过电商产品描述,总共获得了44,263对电商上下位词对。具体由以下部分组成。
4.2 实验设置
将提出的方法与以下方法进行比较。
1)根据Snow的方法,总结出了一些电商领域的依赖路径,根据每个模式训练一个二元分类器,不同路径的数量为7,080。经过筛选,选择了其中5000条具有高可靠性的不同路径作为训练样本。
2)在预处理后,HypeNET用标记模式标记每个不同路径。结合下位词和嵌入作为分类器的训练样本来确定是否上位词。
本文还考虑了一些基线,它们的参数设置如下:
①GBDT二分类模型采用如下参数设置:树数:500;收缩率:0.05;采样率:0.6; 特征比:0.3;最大叶数:32;最小叶样本数:500;特征分割值最大尺寸:500。
②MLP模型采用如下参数设置:每层神经元数:500,100,2;学习率:0.001;最大迭代轮次:1000;批量大小:100。
③逻辑回归(LR)模型采用以下参数设置:最小收敛误差:0.000001;最大迭代轮次=:1000。
④随机特征 (R) 仅包括上下位词对的向量。
⑤半监督Transformer(ST,本文提出的方法):Transformer参数设置:学习率:0.001;单词辍学=0.2。
4.3 实验结果
基于模式的负采样的效果:如图1所示,随机抽样的负对很少出现在产品描述中。基于词模式的方法不仅强化了负样本的意义,而且对负样本的构建也有帮助。如图2所示,随着负样本数量的增加,随机词对的需求呈指数增长。然而,使用基于词模式负采样方法后,所需的随机词对的数量显著减少。
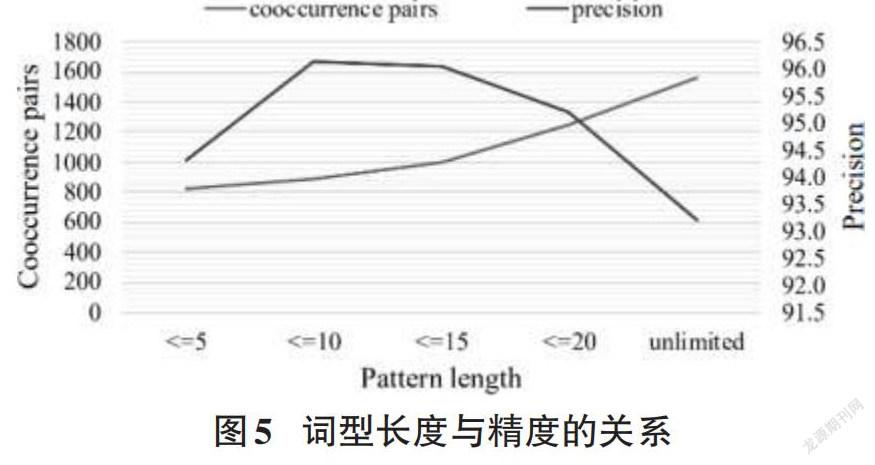
词型长度与精度的关系:在数据处理过程中,需指定词对之间的模式长度,原因是一方面需要提高样本的召回率,另一方面需要保证准确性。图3中,长度为10时,准确率最高;随着词型长度的增加,模型的准确率会逐渐降低。
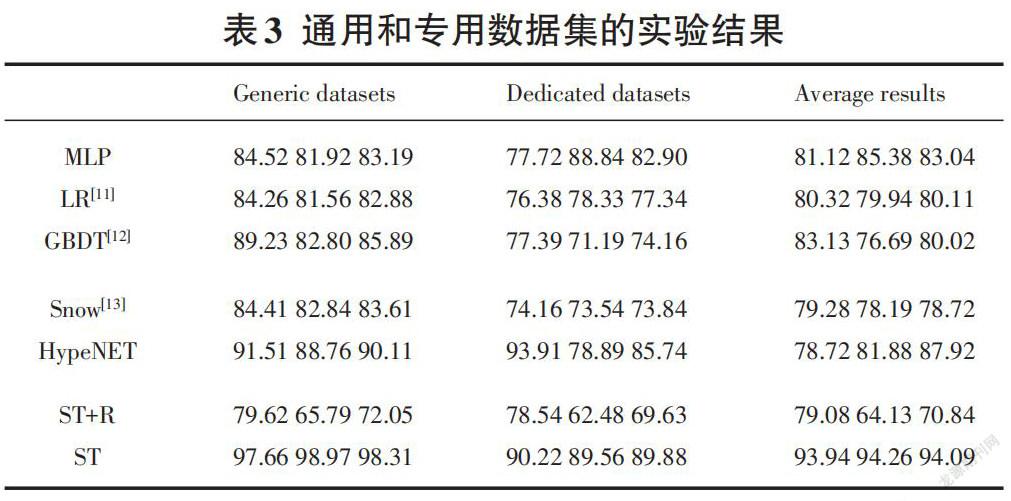
整体比较:如表3所示,所有模型在通用域数据集上的性能都不错,但在专用数据集上的性能变差了,是由电商语料库的特殊性造成的。而ST方法更擅长对抗特定文本,为了进一步验证文本复杂度对模型的影响,测试了Snow方法、DNN、LR、GBDT 和 LSTM。结果表明,ST经过多次迭代后,在复杂文本中仍能保持良好的分类效果。
案例分析:如表4所示,ST能够正确提取关系;相比之下,其余的包括Snow方法、HypeNET、MLP、LR和GBDT都无法产生正确的关系预测。这是因为悬空词和关键字填充出现在它们的词模式中,而本文提出的模型达到了很好的分类效果。
5 结束语
本文提出了协同训练框架 ST用于从电商产品描述中获取上下位关系。基于词模式的负采样方法为其带来了许多有意义的负样本,且Tansformer模型有助于准确理解产品语义的描述。实验结果表明ST取得了最先进的性能。
参考文献:
[1] Carlson A ,Betteridge J,Kisiel B,et al. Toward an Architecture for Never-Ending Language Learning[C].Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence (AAAI-10) Toward an Architecture for Never-Ending Language Learning,2011.
[2] Hearst M A.Automatic acquisition of hyponyms from large text corpora[C]. Proceedings of the 14th International Conference on Computational Linguistics,1992:539-545.
[3] Nakashole N,Weikum G,Suchanek F M.PATTY:a taxonomy of relational patterns with semantic types[C]// Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning.Jeju,2012:1135-1145.
[4] Riedel S,Yao L M,McCallum A,et al.Relation extraction with matrix factorization and universal schemas [C]//Stroudsburg, PA:Proceedings of the 2013 Conference of the North American Chapterof the Association for Computational Linguistics(HLT NAACL 2013),2013:74-84.
[5] Shwartz V,Goldberg Y,Dagan I.Improving hypernymy detection with an integrated path-based and distributional method[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers).Berlin,Germany.Stroudsburg,PA,USA:Association for Computational Linguistics,2016.
[6] Snow R,Jurafsky D,Ng A.Learning syntactic patterns for automatic hypernym discovery [C]//Vancouver:Advances in Neural Information Processing Systems 17,2004:1297-1304.
[7] Jana A,Goyal P.Network features based co-hyponymy detection [C]//LREC 2018,2018.
[8] LIN D.An Information-Theoretic Definition of Similarity [C]//Proc. international Conf. on Machine Learning,1998.
[9] Mikolov T,Chen K,Corrado G,et al.Efficient estimation of word representations in vector space Scottsdale,AZ:Proceedings of the International Conference on Learning Representations (ICLR 2013),2013:1-12.
[10] Mikolov T, Sutskever I, Chen K, et al.Distributed Representations of Words and Phrases and their Compositionality[C]//Advances in Neural Information Processing Systems (NIPS).Massachusetts,USA:MIT Press,2013:3111-3119.
[11] Cheng W W,Hüllermeier E.Combining instance-based learning and logistic regression for multilabel classification[J].Machine Learning,2009,76(2/3):211-225.
[12] Crestan E,Pantel P.Web-scale table census and classification[C]// Hong Kong,China:Proceedings of the fourth ACM international conference on Web search and data mining - WSDM '11.New York:ACM Press,2011.
[13] Shwartz V,Goldberg Y,Dagan I.Improving hypernymy detection with an integrated path-based and distributional method[C]//Berlin,Germany:Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers). Stroudsburg,PA,USA:Association for Computational Linguistics,2016.
【通聯编辑:谢媛媛】
