
DBSCAN 和逻辑回归混合策略方法在锅炉燃烧故障诊断中的应用
2022-07-06 15:02谢春
应用科技 2022年3期
谢春
上海电气集团股份有限公司 中央研究院,上海 200070
在二元分类问题中经常会出现样本不平衡问题,样本不平衡是指一个类的实例(多数类)明显多于另一个类(少数类)。而在实际应用中,正确识别少数类实例往往更有价值,例如,在故障诊断中,正常状态远远多于故障状态,但是正确识别故障状态更有意义。目前绝大多数的机器学习算法针对的是平衡样本集,因此,用常规学习算法来训练不平衡样本集往往产生的是次优模型,其性能和泛化能力较弱[1-2]。
针对二分类问题中的样本不平衡问题,已经提出了很多解决办法,常用的方法有通过抽样的方法重新平衡样本集,如上采样技术;自主选择更有价值的子样本集训练模型,使用其他示例提高模型的性能[3-4];通过调整算法使得学习到的模型更倾向于正确分类少数类实例,如两阶段规则学习方法和单类学习方法[5-9]。
本文将基于密度的噪声应用空间聚类算法(density-based spatial clustering of applications with noise,DBSCAN)和逻辑回归相结合,提出一种针对不平衡样本集二分类问题的混合策略方法。该方法通过DBSCAN聚类算法对多数类样本集进行重新分类,添加标签,增强样本集的线性可分性,可有效提高不平衡样本集的分类准确率。
1 混合策略方法
1.1 方法概述
基于DBSCAN和逻辑回归的混合策略针对的是不平衡样本的二分类问题。该方法首先使用DBSCAN算法将多数类划分为k个子簇,并给每个子簇添加标签(0,1,···,k-1),然后和少数类实例(少数类实例的类别标记为k)重新组合为一个新的样本集,即新样本集中有k+1个类别。
为保证重新划分后不同类别的样本数基本保持一致,k值的选择可以以多数类样本数和少数类样本数的倍数关系来决定,即满足:

式中:N0为多数类样本数,N1为少数类样本数,ceil表示向上取整函数。
通常情况下,逻辑回归算法只能解决二分类问题,针对多分类问题,可采用“一对一”(one-vsone)策略。针对含有k+1个类别的样本集,onevs-one策略会选择两两配对的方式组合分类器,这样组合将生成m=个逻辑回归分类器,对测试集进行分类时,将依次利用m个逻辑回归分类器来预测分类,每进行一次分类会进行一次投票记录。当所有分类器预测完成后,选择票数最多的类别为该测试样本的分类结果[10-13]。
通过one-vs-one多分类的测试集样本有k+1个类别,其中标签为0~k-1的为多数类样本,标签为k的为少数类样本,此时将所有非k样本标签重置为0,将所有k样本标签重置为1,即将多分类问题重新划归为二分类问题。
所述方法流程如图1所示。

图1 混合策略方法流程
1.2 分类问题评价指标
评价指标是评估一个算法是否有效的重要手段,对于二分类问题,少数类标记为1,多数类标记为0,分类模型正确和不正确的示例数目的混淆矩阵详见表1。

表1 二分类模型混淆矩阵
在分类问题中,常用准确率(accuracy)、召回率(recall)、精确率(precision)和F1分数等作为评估算法性能好坏的重要指标,定义为
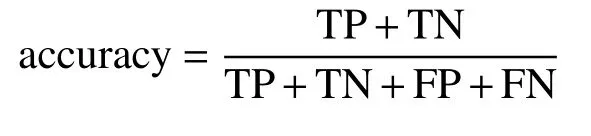

一般情况下仅仅通过一个指标来评价算法存在着一定的局限性,可采用若干指标来评估算法性能,一个好的算法需要在提高召回率和F1分数的同时不降低准确率。
2 实验案例
2.1 样本集概况
选取某电厂2020年3月~2020年5月锅炉监测数据作为样本集来验证混合策略的分类方法。该样本集包括锅炉各个受热面上的温度、蒸汽压力及历史故障数据,其中历史故障数据中切圆偏斜故障是指采用四角切圆燃烧方式的锅炉,运行中发生气流偏斜导致火焰贴墙,引起偏烧及燃烧不稳定的现象,该故障数据表现为明显的样本不平衡,因此以该故障数据作为原始样本集,出现切圆偏斜故障的样本标签置为1,非切圆偏斜故障的样本标签置为0。
经分析可知多数类样本数(即标签为0)约为少数类样本数(标签为1)的9倍,根据式(1),为将数据集划分为较为平衡的样本集,采用DBSCAN聚类模型,选取合适的划分半径(eps)和半径范围内的最小样本数(min_samples),使得DBSCAN簇数k=9。
在本案例中DBSCAN划分半径(eps)为0.1~0.9,以0.1递增选择,同时确定半径范围内的最小样本数(min_samples)在2~10以1递增选择,不同的eps和min_samples的组合参数对应不同的k值,当k值等于指定的数值,即k=9时,以此时对应的eps和min_samples组合参数作为DBSCAN模型的最优参数,将多数类样本进行重新划分,和少数类样本组合为新的样本集D。
D中各个类别的数量对比关系如图2所示。

图2 样本集D中各个类别数对比
图2中新样本集D中共有k+1个类别,其样本不平衡性已被明显弱化,可用于逻辑回归onevs-one多分类建模。
2.2 分类模型构建和预测
基于新样本集D中的k+1个类别,任意选取其中2个类别的样本数据建立逻辑回归模型,即建立m=个逻辑回归分类器,对每一个测试样本均会输出m个预测类别,m个模型预测结果的部分数据详见表2。

表2 one-vs-one预测结果
表2中可知,对测试样本1,标签为0和标签为1的两类样本(即0,1)构建的逻辑回归模型预测标签为0;标签为1和标签为2的两类样本(即1,2)构建的模型预测标签为1,以此类推,测试样本1的最终预测标签为所有m个结果中出现次数最多的标签。
将多分类结果进行标签重置,获得最终的二分类结果,其混淆矩阵如图3所示。
图3(a)为原始样本集用逻辑回归模型进行分类后预测结果的混淆矩阵;图3(b)为样本集经混合策略分类预测的多分类(k+1个类别)的混淆矩阵。图3(c)为将图3(b)对应的样本进行标签重置,k+1个类别重置为2个类别后的混淆矩阵。
对比图3(a)和图3(c)可以看出,经混合策略处理后的预测结果,其FP值(即真实值为0,预测值为1)明显下降,而TP值(即真实值为1,预测值为1)则上升。
为作为对比,对原始数据采用常规的上采样方法重新平衡数据集,分别采用了上采样中的随机朴素上采样(random)、合成少数类(smote)上采样和自适应综合(adasyn)上采样方法[14-15],并对平衡后的样本集分别进行逻辑回归分类预测,其结果混淆矩阵如图4所示。
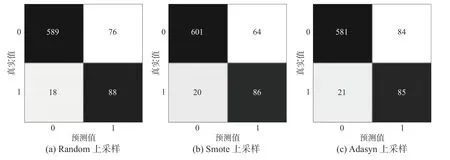
图4 上采样分类结果混淆矩阵
从图4和图3(c)的对比可知,常规上采样方法处理的样本集建立的模型,其分类性能要明显差于经混合策略后获得的分类模型。
2.3 模型评估
基于原始样本(raw)、上采样处理后样本(random、smote、adasyn)及经混合策略(mix)处理的样本集构建的逻辑回归模型在锅炉切圆偏斜故障预测中的评估指标详见表3。根据表3绘制的经不同方法处理后的分类指标柱状图如图5所示。从表3和图5中可直观看出,相比未经处理的原始样本(raw)建立的模型,混合策略(mix)方法建立的模型其precision、accuracy、recall和F1均有明显提高,其中accuracy达到0.97,而相比常规上采样方法(random、smote、adasyn)处理的模型,混合策略方法在precision、F1及accuracy上也有较为明显的优势,表明通过DBSCAN处理的样本集弱化了数据不平衡性,可以提高逻辑回归在不平衡样本集上的分类性能。

表3 模型性能评估指标

图5 模型的分类评估指标
3 结论
基于DBSCAN和逻辑回归的混合策略方法可用来解决样本不平衡问题,将该方法应用于锅炉切圆偏斜故障的分类预测上,可得出以下结论:
1)相比原始样本和经常规上采样方法建立的模型,混合策略方法建立的模型具有更优的评估指标;
2)基于DBSCAN和逻辑回归的混合策略方法可应用于锅炉燃烧故障诊断中,可有效提高锅炉燃烧的智能化运营效率;
3)针对DBSCAN的聚类簇数k,本文选择多数类样本数和少数类样本数的比值,后续研究中可深入研究该参数对分类结果的影响;
4)当多数类样本数和少数类样本数的比值处于动态变化的时候,可通过调整算法的参数(如划分半径和半径范围内的最小样本数)由DBSCAN聚类算法根据样本分布,自动确定多数类样本合理的划分簇数,后续将会对该问题进行更深的研究。
猜你喜欢
法律方法(2022年2期)2022-10-20
中学生百科·大语文(2021年11期)2021-12-05
纺织科学研究(2021年7期)2021-08-14
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
海峡姐妹(2018年3期)2018-05-09
37°女人(2017年11期)2017-11-14
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
