
基于线性判别分析的决策融合脑电意识动态分类
2022-07-12 06:48付荣荣
计量学报 2022年5期
付荣荣, 李 朋, 刘 冲, 张 扬
(1.燕山大学 电气工程学院,河北 秦皇岛 066004; 2.东北大学 机械工程与自动化学院,辽宁 沈阳 110819; 3.沈阳机床(集团)有限责任公司 设计研究院,辽宁 沈阳 110142)
1 引 言
脑-接口(brain-computer interface, BCI)检测由大脑活动产生的电信号,并转换为输出,将用户的意图传达给外界[1,2]。研究表明肢体运动的想象可以改变脑电活动,并且可以在特定运动想象任务下获得不同的脑电图(electroencephalography, EEG)模式[3]。脑机接口研究中广泛应用的EEG信号主要有3种类型:事件相关电位、稳态视觉诱发电位、运动想象电位(motor imagery potentials, MIs)。本文主要针对的是基于MI对BCI性能的研究。
为了从MI信号中解码受试者的意图,人们提出了各种方法来对MI信号进行识别并分类等,如线性判别分析(LDA)、高斯分类器(Gaussian classifier)、概率神经网络(probabilistic NN)。LDA的基本思想是通过一个线性映射将测试样本的数据映射到特征空间,使同类模式样本间距离较近,不同模式样本间距离较远[4],在对新样本进行分类时,将其投影到同样的直线上,再根据投影点的位置来确定新样本的类别。QDA获得二次边界,其中二次曲面将可变空间划分为区域[5]。QDA允许区分具有显著不同的类特定协方差矩阵的类,并为每个类形成单独的方差模型,而类群表示具有相同均值的多元正态分布[6]。RDA是LDA和QDA之间的折中,是一种正则化技术,因此更适用于存在许多潜在相关特征的情况。最近均值分类器是将最接近观测量的训练样本类别的标签分配给观测量。加权最近均值分类器是其类权重与类内测量变量的平均方差成反比。由于这些方法提供了不同的决策,融合多种方法整合[7]不同决策是一种可行的方法,以提高整体分类准确率。
在一些脑机接口研究中,融合方法的测量包括整合脑电图模式、信号特征或分类决策。Liu等人将BCI决策与计算机版本相结合,实现了对目标图像的高精度分类[8]。万柏坤等人采用二维时频分析结合Fisher分析的方法特征提取[9]。这些研究已经证明了融合方法优越性。王瑞敏等人用短时傅里叶变换分解转变成多频段的时频信号[10],然后采用CSP[11]结合支持向量机(SVM)方法对单个导联上的运动想象脑电信号分类识别,但在减少导联时,识别正确率大幅下降。
本文的主要目的是整合两种不同方法的决策协议,以提高脑-机接口系统的分类准确率。考虑到每次试验脑电图数据的分类结果,两种方法通常给出不同的决策。通过识别一个错误判断而另一个正确判断的试验,可以提高分类性能。融合他们的决策是提高整体性能的有效方法,基于这一思想,本文提出了一种新的决策选择器(DS, decision selector),整合两种基于LDA的算法选择更有可能是准确的决策。本研究实现了BCI研究中常用的5种基于LDA的分类算法,即LDA、QDA、RDA、最近均值、加权最近均值,并评估所提出的DS方法的综合性能。
2 实验介绍以及分类方法
2.1 EEG的采集
为了评估DS方法的性能,通过离线实验来获得基准数据集。试验在隔音效果良好的房间内进行,实验设备采用Emotiv头盔采集受试者14导(AF3,F7,F3,FC5,T7,P7,O1,O2,P8,T8,FC6,F4,F8,AF4)的脑电信号,其电极分布采用10~20国际标准导联定位,采样频率为128 Hz。试验数据通过USB接口传送到计算机。本试验共10名(6男,4女)健康参与者参与试验,排除标准是视觉、神经或精神疾病或任何现有药物的任何历史,所有受试者均阅读并签署了知情同意书。每位受试者共进行6个线下实验区块,每个区块包含120个实验,左手和右手各为60。
正式采集之前,受试者均完成了练习试验,以确保熟悉并正确理解任务。试验时,受试者保持放松,尽量避免眼动,坐在距离眼睛约60 cm的舒适的LED显示器前面并有数字键盘放置在受试者面前。在试验过程中,受试者需要完成边界回避任务,这是一种高难度的感觉运动任务,受试者需在规定的范围内操纵虚拟的呈有小球的碗,若碗从右侧B位置超出边框范围,并且整个过程球未溢出碗则任务成功;若碗从左侧A位置超出边框范围,或者在这个过程中球从碗中溢出,则任务失败。碗-球的初始位置在A位置。针对本试验的特点,截取下述两组数据进行分析处理。假设在一段时间内对碗施加一个方向向左的力,在受到这个力之前碗是向右移动的,而球相对于碗会向左;由于惯性的作用,一段时间之后碗才会向左移动,反之亦然。分别截取这一段时间内的前1 s和后1 s的数据。
2.2 基于LDA的算法
2.2.1 LDA
LDA基本思想是:将数据在低维度上进行投影,投影后希望最大化类间散度矩阵,同时最小化类内散度矩阵[12~15]。具体过程如下:
(1) 计算每类样本的均值向量μj
(1)
式中:j=1,2;μj为第j类样本的均值;Xj为第j类样本的集合;Nj是第j类样本的个数,即每次实验的数据点数。
(2) 计算样本的协方差矩阵∑j
(2)
可得到类内散度矩阵Sw为:
Sw=∑1+∑2
(3)
同时定义类间散度矩阵Sb为:
Sb=(μ1-μ2)(μ1-μ2)T
(4)
(3) 优化目标为J(w)
(5)
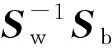
y=wTX
(6)
2.2.2 LDA方法的扩展
QDA旨在找到输入特征的变换,它能够最好地区分数据集中的类。QDA的基本思想如下:假设样本数据服从多元高斯分布,其概率密度函数为:
(7)
式中:x是一个p维向量。
多元分类判别是将样本归于求对数后验概率,对公式两边同时求对数简化就可以得到QDA判别公式:
(8)
式中:|∑i|是广义方差值;P(ωi)是先验概率;μi是均值向量;∑i是第i个类别中所取样本的每个特征之间的协方差所构成的协方差矩阵:
(9)
RDA思想,分类目的是根据从每个对象或观察获得的一组测量值X=(X1,X2,…,Xn)将对象分配给几个(K)组类中的一组。在训练数据中,数据类别是已知的,因此类别k的先验概率和平均值为:
(10)
(11)
式中:ω是样本总数;ωk是类别k的样本数;c是类别总数;xn是样本点。类别k的协方差矩阵为:
(12)
在LDA中,每一类的协方差矩阵是相等的,即∑k=∑。正则判别分析(RDA)通过修改奇异协方差值来改善多重共线性的影响。每个类别的样本协方差估计如下:
(13)
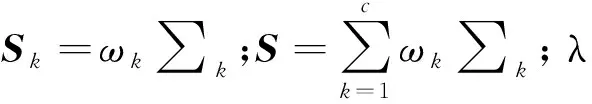
通过引入收缩参数γ进一步调整协方差矩阵。
(14)
式中:p是自变量的维数;I是单位矩阵。
类判别得分可以记为:
ln|∑k(λ,γ)|-2 ln(πk)
(15)
最近均值分类器与Rocchio算法的相关性反馈相似,又称为Rocchio分类器,基本原理是将最接近观测量的训练样本类别的标签分配给观测量[16,17]。假设一组样本为{(x1,y1),…,(xn,yn)},其中xi是p维度量空间的一个特征向量,标签yi=[-1,+1],用f(x)表示样本x的预测标签,具体过程如下:
(1) 计算每一类样本的均值μn:
(16)
式中:Cn是属于类n∈Y的样本索引集。
(2) 分配给一个样本x的类别是
(17)
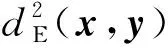
(18)
式中:p是特征向量的维度。
加权最近均值分类器是最近均值分类器的扩展,其类权重与类内测量变量的平均方差成反比[18]。在此假设和第一步与上述最近均值分类器的相同,则分配给一个样本x的类别是:
(19)
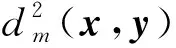
(20)
式中:M是一个对角阵,mjj=mj≥0,mj是特征或维度j的加权因子。加权最近均值的训练定义为在必须正确分类所有训练对象的条件下为给定训练数据集找到适当的权重。形式上可以写成:
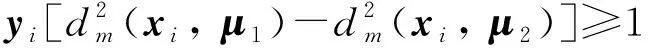
(21)
2.3 DS的方法
在上文中对这些基于LDA的算法性能进行了研究和比较,其中QDA和RDA算法最为优秀。但是,考虑到M1和M2两种算法对所有试验的分类结果,在很多试验中M1决策是错误的,而M2决策是正确的,应该通过识别这些试验并为它们选择M2决策来提高分类性能。基于此思想,本文提出了一种DS方法,通过从M1和M2算法中选择更有可能准确的决策来提高基于MI的BCIs的分类精度。使用两种算法对同一试验的脑电图数据进行分类,就受试者的意图做出了两个独立的决定。DS方法判断哪个决策更可能是准确的。为了训练DS方法,根据M1和M2算法的分类结果,将训练试验分为both-true、both-false、M1-false和M2-false共4类。在一次双对试验中,这两种算法做出了相同且正确的决定。在双假试验中,两种方法的决定都与被试的意图不一致。所提出的从两个错误决策中选择一个的DS方法也会给出一个错误的结果。结果,M1-false和M2-false试验被用来训练DS方法。
DS方法主要是由特征提取、分类和决策选择等3个模块组成,如图1所示。DS方法输入M1和M2算法的决策和相关系数,输出更有可能是正确的决策。测量每一个决策的概率,提取模块提取M1和M2的相关系数并生成一个特征向量F如下:
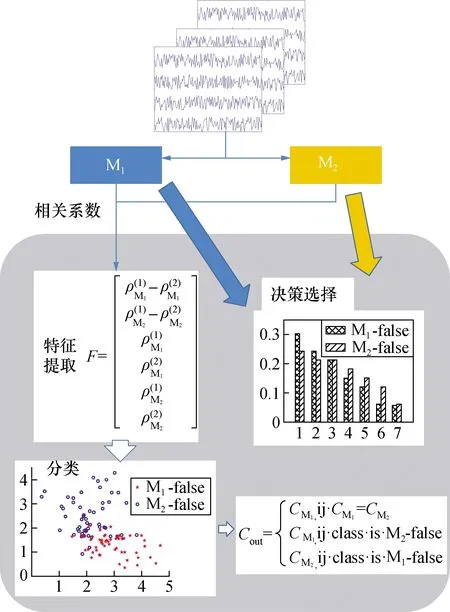
图1 DS方法图Fig.1 DS method chart
(22)
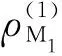
分类模块使用线性SVM分类器将特征向量F分为M1-false和M2-false两类。SVM分类器的目标是将特征向量F投影为标量值,具体如下:
(23)
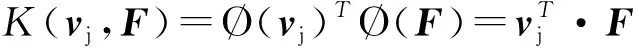
(24)
式中:δj是松弛变量,表示样本vj是否在边缘内,需要调节程度;C是控制宽度和误分类权衡的调节系数。
决策选择模块根据分类结果选择M1或M2算法的决策输出,如式(25)所示。如果得到一个M1-false结果,则输出M2决策。否则,输出M1决策。
(25)
2.4 DS的评估
图2说明了所提DS方法的训练和测试的过程。在训练阶段,使用另一个交叉验证来提取M1-false和M2-false特征。具体来说,M1和M2算法使用训练数据集中的4个块进行训练,并在每一轮中对剩余的块进行分类。根据分类结果,在每个训练周期的5轮中提取并记录M1-false和M2-false试验的DS特征F,即总共测试200次试验。利用记录的M1-false和M2-false特征来训练DS方法。
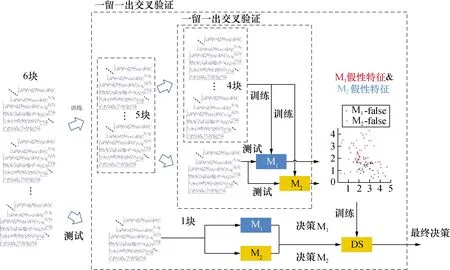
图2 DS方法的训练和测试Fig.2 Training and testing of DS method
在测试阶段,使用所提出的DS方法对LDA、QDA、RDA、最近均值、加权最近均值5种基于LDA的分类算法进行了综合。估计了所有组合的分类准确率。估计了所有组合的分类准确率和信息传递率(ITR)。以bit/min为单位的ITR定义如下:
(26)
式中:P为准确率;N为类数(即本研究中N=120);T为一次选择所需的时间。
3 结 果
综合LDA、QDA、RDA、最近均值、加权最近均值5种基于LDA的分类算法,所提DS方法的分类准确率如表1所示。性能以1 s的数据长度进行评估。结果数据由5行5列组成,每一行对应一个分类算法。主对角线单元格表示各算法的平均精度,其他单元格表示将两种相应算法集成在一起的DS方法的平均精度。在表1的DS结果中,加粗表示的单元格表示DS方法的性能优于两种算法,余下的单元格表示DS方法比两种算法的精度第二高。例如,数据长度为1 s的DS-QDA&LDA方法的准确率为90.56%,高于LDA方法的86.36%,但低于QDA方法的93.70%。然而,QDA和LDA方法的准确率有7.34%的差异。表1中的测试结果也表明,将QDA或RDA算法与低精度算法相结合的DS方法性能下降。本研究计算了两种算法在各DS组合前后的分类精度。这些结果表明,DS法融合两种算法精度相差很大时候不提高整体分类准确率。而结合两种性能比较接近的算法的DS-QDA&RDA方法,在数据长度为1 s时,准确率最高为94.21%。本研究采用DS-QDA&RDA方法作为进一步分析的代表性方法,并通过不同参数对其性能进行评估:数据长度(即s)、子带数(即m)、训练块数(即t)。
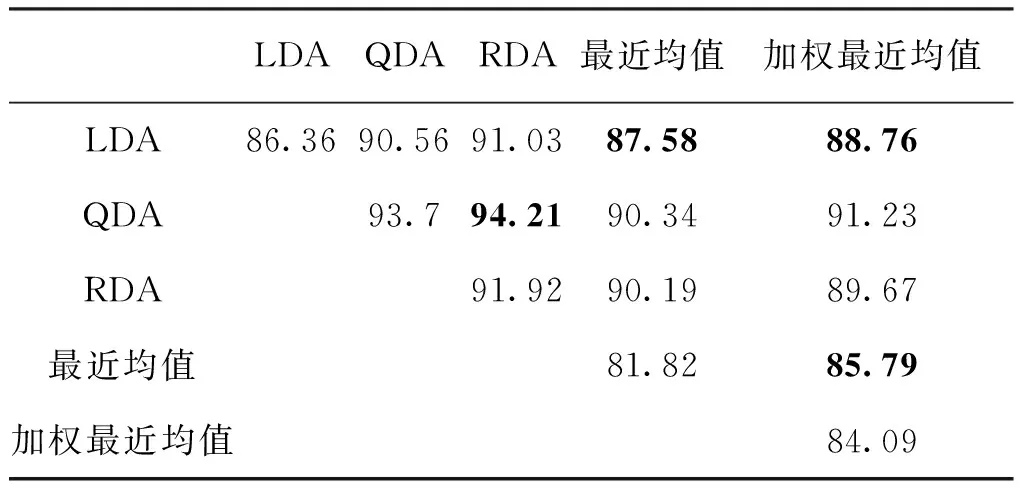
表1 DS后的分类准确率Tab.1 Classification accuracy after DS (%)
图3(a)显示了DS-QDA&RDA方法受试者中的平均分类准确率。使用1.1~2 s之间的不同数据长度(间隔为0.1 s)评估性能。结果表明,提出的DS-QDA&RDA方法获得了最高的精度,与数据长度无关。配对t检验显示,DS-QDA&RDA方法的准确率显著高于QDA方法(p<0.01),数据长度为1.3~2 s的准确性显著高于RDA方法(p<0.001)。在数据长度为1.2 s时,DS-QDA&RDA与RDA的分类精度之间无显著差异。图3(c)显示了用于训练DS的QDA-false和RDA-false试验的百分比。这些数值反映了所提出的DS方法在理论上可以取得理想的性能改善。
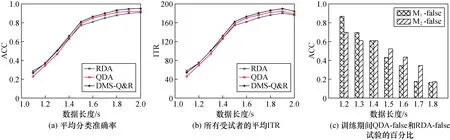
图3 DS-QDA&RDAFig.3 DS-QDA&RDA
图4比较了不同子带数和不同训练块数的3种方法的分类准确率。数据长度设置为1 s,其中DS-QDA&RDA方法获得的ITR最高。配对t检验显示,无论子带数目如何,DS-QDA&RDA方法的分类准确率均显著高于RDA方法(p<0.001)。如图4(b)所示,无论训练块数多少,3种方法每对之间均有显著性差异(p<0.05)。值得注意的是,训练块由1块用于测试QDA-false和RDA-false试验,其他块用于训练QDA和RDA方法。如图2所示,当训练块数为5时,QDA和RDA方法实际上使用的是4块数据集进行训练。

图4 平均分类准确率Fig.4 The average classification accuracy
4 讨 论
4.1 DS方法的性能
本文提出了一种新的DS方法,通过在决策层融合两种基于LDA的算法来提高性能。为了验证其在增强基于MI的BCI方面的有效性,本文实现了BCI研究中常用的5种算法,即LDA、QDA、RDA、最近均值、加权最近均值,并评价了DS方法对这些算法的综合性能。实验结果表明,DS方法结合了精度相近的算法对,提高了分类性能。如表1所示,验证了所提出的DS方法可以提高多对基于LDA算法的性能。其中,DS-QDA&RDA方法在数据长度为1 s时的准确率最高,为94.21%。本研究采用DS-QDA&RDA作为实验方法,在不同参数下,其准确性均优于QDA和RDA算法。
虽然得到了较好结果,但DS方法也显示出将精度相差很大的算法集成在一起的局限性。如数据长度为1 s的DS-LDA&QDA方法在综合低精度的LDA算法(86.36%)后,综合后(90.56%)精度比QDA算法(93.70%)低。实验结果表明,LDA和加权最近均值算法的准确率相对接近,融合后也有提升(分别为86.36%和84.09%)。
4.2 QDA-false和RDA-false试验的DS特征
提出了基于LDA的两种不同分类决策方法的DS方法。提高DS性能的关键问题之一在于评估每个决策的不确定性。对QDA和RDA算法提取相对应的综合相关系数ρn。为了训练DS方法,提取了两种方法的最大和第二大组合相关特征。
图5(a)和图5(b)是用于训练DS-QDA&RDA方法的DS特征,在所有10名受试者的QDA-false和RDA-false试验中获得。红色圆圈点表示QDA错误试验的特征,蓝色五边形点表示RDA错误试验的特征。

图5 和的特点及和特点Fig.5 The characteristics of and and
本文中构造了如式(2)所示的特征向量,并训练了一种用于分离QDA-false和RDA-false特征的DS-QDA&RDA方法。如图3所示,DS-QDA&RDA显著提高了分类精度和ITR。这些结果表明,本文提出的DS特征能有效地集成QDA和RDA等不同方法,提高基于MI的BCI的分类准确率。
4.3 与其他的分类方法比较
为了显示DS-QDA&RDA分类方案的有效性,将其与几种现有的分类方法进行比较:1) 基于k-NN的方法。如果一个样本在特征空间中的k个最相似样本中的大多数属于某个类别,则该样本也属于这个类别。2) 基于Tree的方法。通过把样本集数据从根节点分裂到叶子节点来对样本实现分类。在提取脑电特征之后,分别用上述方法进行分类,结果显示在表2。
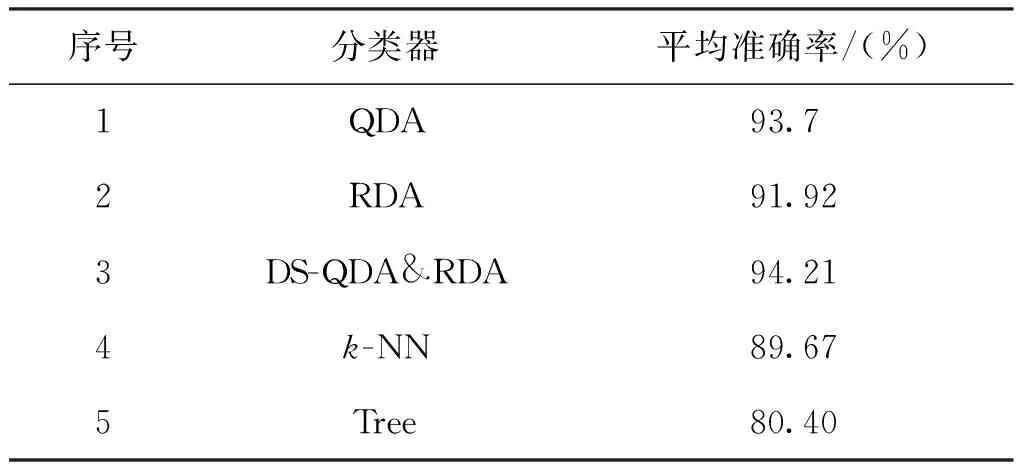
表2 DS方法与k-NN和Tree的性能比较Tab.2 Performance comparison of DS method with k-NN and tree
表2中,k-NN,Tree(使用MATLAB 2016a中的工具箱Classification Learner)和本文的DS-QDA&RDA方法以及集成前的两种方法做比较。平均而言,本文提出的基于DS-QDA&RDA的方法所获得的准确度比现有两种方法获得的准确度均要高,这表明提出的方案具有显著的优越性能。
5 结 论
本文提出了一种基于集成线性分析的决策融合分类方法,针对有约束的动态复杂对象控制任务中的脑电信号进行了分类研究,利用本文提出的方法结合试
验任务的特点,将获取的EEG信号进行预处理、提取,将得到的特征信息分别采用5种基于LDA的算法以及其融合后的方法法进行模式分类。尤其是DS-QDA&RDA,得到了较好的分类结果平均准确率为0.942 1±0.021 3,且均高于融合前的两种方法的准确率。研究结果表明,融合后,分类效果有所提高,且两种方法的分类效果越接近,提高的幅度越明显。为了说明本文所提方法的有效性,与现有的几种方法k-NN,Tree进行了比较。结果显示,本文提出的基于集成线性分析的决策融合的方法所获得的准确度比现有的两种方法获得的准确率均要高,在参数优化方面更加灵活,这表明提出的方案具有显著的优越性能。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
计算机系统应用(2021年2期)2021-02-23
电子技术与软件工程(2019年18期)2019-11-18
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
中国交通信息化(2018年5期)2018-08-21
数学大世界(2018年35期)2018-02-22
电子技术与软件工程(2017年14期)2017-09-08
