
采用最小二乘支持向量机的部分相依函数型线性模型估计与应用
2022-07-19 09:41苏梽芳周煜李气芳
华侨大学学报(自然科学版) 2022年4期
苏梽芳, 周煜, 李气芳
(1. 华侨大学 经济与金融学院, 福建 泉州 362021; 2. 闽南师范大学 数学与统计学院, 福建 漳州 363000)
随着数据采集、处理和存储技术的快速发展,越来越多的数据可被连续观测且在本质上呈现出明显的函数曲线特征,Ramsay等[1]将这类数据定义为函数型数据,函数型数据分析已经广泛应用到气象学、生物学、经济学等领域[2-5]
函数型线性模型是函数型数据分析的重要工具,Cardot等[6-7]基于函数型主成分分析和惩罚样条的估计方法研究估计量的相关渐进性质.Yao等[8]考虑观测值为稀疏离散情况下的函数型线性模型的估计方式.文献[9-11]采用平滑样条方法估计函数型斜率参数,研究估计量的大样本性质.
为进一步提高函数型线性模型的预测能力和可解释性,Zhang等[12]将向量型解释变量引入函数型线性模型中,提出部分函数型线性模型.Shin[13]运用函数主成分分析方法估计模型,并证明参数估计量的渐进正态性和函数系数估计量的最优收敛速度.Zhou等[14]将模型的函数系数利用样条基展开,进一步通过最小二乘法得到估计量.王晓光等[15]基于核函数构造一类部分函数线性回归模型,研究模型参数的渐进正态性和非参数的收敛速度.
现有的这些估计方法一般都假设函数型数据服从独立同分布(i.i.d),而没有考虑函数型数据的相依特征.现实生活中,股票数据、温度数据、空气污染物数据等函数型数据明显存在相依结构,如果运用独立同分布条件下的函数型数据分析方法重构这些数据,必然会出现误差,从而对后续模型的估计造成影响.对此,文献[16-18]利用长期协方差函数替代独立同分布条件下的协方差函数,证明长期协方差函数收敛于总体长期协方差函数.然而,长期协方差函数的估计涉及核函数和窗宽的选择易受人为因素的影响.李气芳[19]在文献[20]的研究基础上,提出基于无截断 Bartlett 核的长期协方差函数估计方法,避免了核函数和窗宽的误选导致的估计误差.综上,本文针对具有相依特征的函数型自变量,将独立同分布条件下的部分函数型线性模型拓展到相依情形.
1 模型与估计
1.1 部分相依函数型线性回归模型
针对自变量中同时含有标量型和函数型变量的情况,Zhang[9]提出了部分函数型线性回归模型,即观测数据{(X1(t),Y1,Z1),(X2(t),Y2,Z2),…,(Xn(t),Yn,Zn)}满足如下形式,即

(1)
式(1)中:Xi(t)为函数型变量,是L2[0,1]中的随机过程;β(t)为回归系数函数;Zi为p维标量型自变量;γ为p维回归系数向量;εi表示均值为0,方差为σ2的随机误差项,且与(Zi,Xi(t))独立;Yi为标量型应变量.
若函数型数据Xi(t)满足函数
Cov[Xi(t),Xi+h(s)]=E{[Xi(t)-μ(t)][Xi+h(s)-μ(s)]}≠0,h≠0,
则称Xi(t)为相依函数型数据.当Xi(t)为相依函数型数据时,可以把式(1)推广为部分相依函数型线性回归模型.
1.2 相依函数型数据的重构
函数型数据分析的首要任务是把函数型数据重构成函数曲线,其主要方法有外生基法(Fourier基,B-Spline基等)和内生基法(函数主成分基),越来越多学者青睐函数主成分基的重构方法.在独立同分布条件下,通过计算协方差函数得到函数主成分,但当函数型数据具有相依特征时,样本协方差函数不再是总体协方差函数的一致估计量,计算得到的函数主成分不准确.Hörmann等[18]基于长期协方差函数计算函数主成分的方法,面临核函数和窗宽的选择问题.Kiefer等[19]在研究多元回归模型中长期协方差估计问题时,构造基于无截断Bartlett核的长期协方差估计统计量,不需要选择核函数和窗宽.李气芳[19]把文献[20]的估计思想推广到长期协方差函数的估计中.因此,采用基于无截断Bartlett核的长期协方差函数估计方法,避免核函数和窗宽的选择问题.

(2)

借鉴文献[19]中基于无截断Bartlett核的估计方法,把式(2)变为
根据文献[21-22]对动态函数型主成分的定义,样本长期协方差函数的特征值与特征函数满足
(3)
基于Karhunen-Loeve展开,使用前m个函数主成分重构相依函数型数据,以达到降维的目的,即
(4)
1.3 基于最小二乘支持向量机估计方法的系数估计
由式(4)得到的m个函数主成分对回归系数函数β(t)进行逼近,有
(5)
把式(4),(5)代入部分相依函数型线性模型,即
则有

定义如下函数
(6)
令Y=(Y1Y2…Yn)T,A=(γ1…γpa1a2…am)T,
那么,式(6)可以改成线性回归模型的形式,即
根据最小二乘法估计式,可得
(7)
最小二乘法对样本容量要求较大且对异常值较敏感,而支持向量机算法引入了损失函数,允许一些样本点出错,寻找的超平面只由少量支持向量决定,具有良好的鲁棒性.最小二乘支持向量机估计方法是基于平方损失构建的一种支持向量机,其回归问题最终归结为等式约束下的线性方程组的求解问题,降低了计算的复杂度.因此,运用最小二乘支持向量机算法,构造如下优化问题,即


引入拉格朗日乘子μi,构建如下方程,即
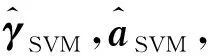
(8)
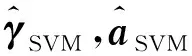
(9)
2 数值模拟
2.1 模拟数据生成
样本数据由如下模型生成,即
上式中:系数向量γ=(2.0 -1.0 1.5 5.0 -1.7)T,随机向量Zi=(Z1Z2Z3Z4Z5)T,其与N(0,I5)同分布;随机误差εi~N(0,0.52).
回归系数函数β(t)有如下3个情形.
情形(Ⅰ):β(t)=0.


2.2 模型参数估计的算法
模型参数估计的算法有如下7个步骤.
步骤2由给定的γ,β(t),Zi,Xi(t),εi结合回归模型(1)生成应变量Yi,得到数据集,把后0.2n个样本作为样本外预测集.


步骤5通过留一交叉验证(CV)选取平滑参数λ,有


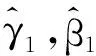
2.3 模拟结果分析


由表1~4可知:两种估计方法的偏误与方差非常接近且随着样本量的增大而减小,这说明两种估计方法在3种情形下都能取得较好的效果且性能表现近似.

表1 三种情形下的估计偏差与方差(n=50)Tab.1 Deviation and variance of estimated in three situations (n=50)

表2 三种情形下的偏差与方差(n=100)Tab.2 Deviation and variance of estimated in three situations (n=100)
表3 三种情形下的偏差与方差(n=200)Tab.3 Deviation and variance of estimated in three situations (n=200)
表4 回归系数函数β(t)估计得到的偏差与方差(n=500)Tab.4 The deviation and variance of estimated regression coofficiont fuction of β(t) (n=500)


图1 情形(Ⅰ)的某次模拟中β(t)观测曲线及其估计曲线Fig.1 Observed and estimated curve of β(t) in a simulation situation (Ⅰ)

图2 情形(Ⅱ)的某次模拟中β(t)的观测曲线及其估计曲线 图3 情形(Ⅲ)的某次模拟中β(t)的观测曲线及其估计曲线Fig.2 Observed and estimated curves ofβ(t) in simulation situation (Ⅱ) Fig.3 Observed and estimated curves of β(t) in simulation situation (Ⅲ)

表5 的平均偏离平方和的均值与方差Tab.5 Mean and variance of sum of mean deviation squares of

由图3可知:当回归系数函数β(t)设定为情形(Ⅲ)时,LSSVM的估计曲线在头部和尾部更贴近观测曲线,其余两种方法估计相近都能较好地拟合观测曲线.结合表5情形(Ⅲ)中的结果可知:当n=50,200时,LSSVM比OLS优势较大.

回归系数函数β(t)样本外预测值的RMSPE,如表6所示.由表6可知:在每个样本容量下,LSSVM的样本外预测误差比OLS小;在同一回归系数函数设定下,两种方法的预测误差随着样本量的增加略微上升,且LSSVM比OLS表现好.这说明LSSVM在系数估计上具有优势,有效提高了样本外预测的准确度.

表6 样本外预测值的RMSPETab.6 RMSPE of out-of-sample predicted values
3 实例分析
3.1 数据预处理
以上证指数当日交易量和当日1 min高频交易价格数据作为次日上证指数开盘价的影响因素.由于每日的交易量数据过大,因此,将其取对数后作为离散型自变量Zi,当日1 min高频交易数据作为相依函数型自变量Xi(t),次日的开盘价作为标量型应变量Yi+1,构建部分相依函数型线性模型,即
实例数据来源于锐思数据库,选取2018年1月至2018年12月的上证指数交易数据,包含次日开盘价、当日的交易量、及当日1 min高频交易数据.2018年共有243个交易日数据,删去最后1 d的交易日数据得到242个交易日数据,每个交易日有242个1 min高频交易价格数据.
3.2 上证指数开盘价预测
将前200个交易日数据作为训练样本,剩余42个交易日数据作为预测样本.分别使用文中提出的考虑函数型数据相依性的最小二乘支持向量机方法与未考虑相依性的最小二乘估计方法预测次日开盘价.预测结果与绝对误差的比较,如图4所示.

图4 预测结果与绝对误差的比较Fig.4 Comparison of prediction results and absolute error
由图4可知:除个别交易日外,LSSVM估计的开盘价的绝对误差均OLS估计的开盘价的绝对误差,因此,文中方法的泛化能力更强.
为了综合比较预测效果,文中选取最大误差、最小误差、平均绝对误差、均方预测误差平方根评价方法的预测能力.两种方法预测结果的综合评价,如表7所示. 表7中:Emax为最大误差;Emin为最小误差;MAE为平均绝对误差.由表7可知:LSSVM较好地预测次日的开盘价,其最大误差、最小误差、平均绝对误差、均方预测误差平方根均好于OLS,由此证明LSSVM得到的预测效果优于OLS的预测效果.

表7 两种方法预测结果的综合评价Tab.7 Comprehensive evaluation of prediction results of two methods
4 结束语
考虑到函数型数据的相依性结构特征,提出一种基于最小二乘支持向量机的部分相依函数型线性模型.不同于其他的参数估计方法,利用无截断Bartlett核估计长期协方差函数,并将长期协方差函数所得到的特征函数对函数系数进行基展开,从而把函数系数的估计转化为参数向量的估计问题,随后运用最小二乘支持向量机给出了模型参数的估计.通过数值模拟可知,与未考虑函数型数据相依性特征的最小二乘估计法相比,文中方法对向量系数的估计更加准确稳健,有效提高了样本外预测的准确度.最后,将文中的参数估计方法应用于上证指数次日开盘价的预测中,进一步证明使用文中模型及参数估计方法的有效性和优越性.
猜你喜欢
中等数学(2021年9期)2021-11-22
中学生数理化·高一版(2021年2期)2021-03-19
舰船电子工程(2020年3期)2020-06-11
音乐天地(音乐创作版)(2020年2期)2020-04-18
歌海(2019年5期)2019-12-19
密码学报(2019年3期)2019-07-16
计算机应用与软件(2019年2期)2019-04-01
经济研究导刊(2018年19期)2018-07-24
卷宗(2018年14期)2018-06-29
特别文摘(2016年18期)2016-09-26
