
基于文本增强的民航安全信息自动分类
2022-08-03 01:30崔振新张卓言
中国民航大学学报 2022年3期
崔振新,张卓言
(中国民航大学飞行技术学院,天津 300300)
随着中国民航业的高速发展,公众对航空安全水平的期望越来越高,而安全管理水平的提升依赖于行业安全信息。航空安全信息是民航实施安全风险控制和事故预防的基础,对提高航空安全水平具有重要作用,在整个安全管理系统中具有超前和预防意义[1]。
随着民航安全工作中广泛应用的不安全事件报告信息(简称安全信息)管理的规范化,安全信息量越来越大,在数据驱动管理阶段,深入分析安全信息的需求增加,需要针对现有或新的分类维度重新分类信息。因此,利用现有系统中较长的事件信息描述部分基于机器学习构建分类器,实现信息自动分类,提高现有信息系统的利用价值。
实现信息自动分类首先要对信息数据进行人工标注,标注的信息量越少,人工成本越低。此外,还有一些事件类型发生概率不高,如空中相撞,在处理时必然会存在数据量不足的问题,因此,本文结合数据增强技术解决上述问题。
为提高数据利用率,数据增强在可用数据量不足时成为必要手段。数据增强多用于计算机视觉领域,通过改变图片像素颜色、尺寸、方向等方法,增加数据噪点,同时可以增加数据集规模,提高模型的泛化能力。在自然语言处理方面,可以对数据进行加噪处理,也可以对文本数据进行增强。Zhang 等[2]利用英文同义词词典进行同义词替换,直接修改文本中的词,但会存在没有同义词的词语,对原句的修改幅度有限;Kobayashi[3]使用双向循环神经网络进行数据增强,在去掉一个词后,通过上下文预测该词,将预测出的词替换原词,虽然相比使用同义词替换有更多增强的可能性,但在分类任务中,难以保证增强后的数据标签保持不变;回译是将文本翻译成其他语言再翻译回原文,生成新的文本[4],但对专业词汇的翻译不一定准确,可能会影响原意。针对以上方法的不足,拟采用简单数据增强(EDA,easy data augment)方法综合增强文本数据。
应用于机器学习的文本需要使用语言表示模型,将非结构化的文本表示为结构化的数学形式,同时保持数据标签不变。词袋模型作为经典语言模型,将文本视为相互独立的词语组合,以词为基本处理单元得到向量化表示。随着互联网的发展,大量无标注数据产生,由此产生基于连续词袋(CBOW,continuous bag of words)模型和连续跳跃元语法模型(Skip-Gram,continuous skip-gram model)的浅层神经网络模型Word2vec[5],该模型以词袋模型产生的稀疏向量作为模型输入,将其映射为稠密向量,同时保留词序信息。
相比Word2vec,Peters 等[6]提出的基于语言模型的词向量(ELMo,embedding from languagemodels)模型,利用双层双向的长短期记忆网络(LSTM,long short term memory networks)提取特征,利用上下文进行表征。Radford 等[7]提出的生成式预训练模型(GPT,generative pretraining model)使用Transformer 作为特征提取网络,性能优于ELMo;Devlin 等[8]提出的双向编码器表示技术(BERT,bidirectional encoder representations from transformers)模型结合了上述两个模型的优势,基于Transformer 的双向表示,在自然语言处理任务上的性能有大幅提升,在某些任务上甚至超过了人类的处理水平,开启了自然语言处理领域的新时代。
综上,为实现数据量不足时民航安全信息自动分类,以中国民用航空安全信息分类系统(中国民航官方收集不安全事件强制报告信息的工作平台)中的不安全事件信息为样本,因此,文中使用BERT 预训练模型进行文本表征,从事件类型分类维度分析文本增强在民航领域小数据集上的适用性,以及在民航不安全事件信息自动分类方面的有效性。
1 安全信息自动分类
1.1 模型及算法
1.1.1 语言表示模型
BERT 模型对自然语言进行处理的环节包括:建立基于大型语料库的训练模型,并对此模型微调以适用下游任务。
BERT 模型所使用的特征提取器为Transformer,Transformer 是一个带有自注意力机制的Seq2seq 模型,由若干编码器和解码器堆叠形成,编码器用于将语料转化为特征向量,编码器的输出以及已经预测的结果为解码器的输入,用于输出最后结果的条件概率。
BERT 网络结构示意如图1 所示,其中:Ei表示输入的一个词向量表示;Trm 表示Transformer 编码器,Ti表示输入的一个上下文表示,即对应的特征向量;M表示输入个数。

图1 BERT 结构示意图Fig.1 Structure of BERT model
BERT 模型的输入以字符为单位,经过词、位置和句子(segment)3 种信息的3 层向量表示(embedding),得到Trm 的输入向量。
BERT 在预训练时主要完成2 个任务:①遮蔽语言模型,随机对15%的词进行处理,在这些词中,有80%的词被遮挡,使用[MASK]代替,10%的词替换为另一个随机词,剩余10%的词保持不变,然后根据该词的左右语境预测该词;②预测下一句,理解句子之间的关系。结合以上2 个任务的训练得到的深层双向模型,一定程度可实现不同文本任务的通用性。
传统的文本处理方法依赖于人工选取数据特征,但民航事件信息类型多样,不同类型所包含的特征信息也不尽相同,人工提取事件信息的公共特征费时费力,准确率得不到保证,也不利于持续处理新事件信息。与人工规则构造特征的方法相比,利用大数据来学习特征,可使文本处理方法具备自动抽取和组织信息的能力,更能够刻画数据的丰富内在信息。
BERT 模型的训练是基于大型语料库进行的,使用BERT 模型可以省去中间处理过程,实现从输入文本到输出向量表示的端到端方法。BERT 模型因其庞大的训练数据集和较多的网络层数,为现阶段最好的通用语言表示模型。
1.1.2 分类算法
支持向量机[9](SVM,support vector machine)通常用于二元分类场景,是将数据的特征向量映射为空间中的点,通过监督学习(利用带标签的数据进行学习)确定一条最能将两类数据区分开的线,该线受样本局部扰动影响最小,对未知数据的泛化能力最强。
SVM 算法分类原理示意如图2 所示,其中,分割线表示为


图2 SVM 算法原理示意图Fig.2 The principle of SVM algorit hm
两条虚线为两类样本的边界线,在该线上的样本称为支持向量,当分割线与两条边界线的距离相等且最大时,为最优分割线。通过计算间隔,寻找分割效果最佳时分割线的权重w 和b。
两条边界线的间隔为两类支持向量的差在w 上的投影,即

式中:x+为正支持向量;x-为负支持向量。由于支持向量在边界线上,可以表示为

得到

代入式(2)中,可得

根据间隔最大化,得到

式中m 为待分类的样本数。为计算方便,转化为

在二维空间中,数据为线性可分(可以找到一个线性函数将两类样本分开)时,由1 条一维直线分割,该直线距离两类数据的决策边界距离最远。在二维以上的多维空间中,SVM 将数据映射到更高维的空间,将线性不可分转化为线性可分的情况,进而确定分割位置。
SVM 是对数据边界进行决策,一定程度上可以防止模型过拟合。
1.1.3 数据增强算法
通过对几种数据增强算法的比较,采用Wei 等[10]提出的EDA 算法,除同义词替换方法外,首次提出对一句话中的词进行插入、交换、删除的方法,对文本数据具有一定的通用性。EDA 方法对一句话中词(不包含停用词)的处理包含以下4 种方法:
(1)同义词替换(SR,synonym replacement),随机选择n 个词,再随机选择每个词的一个同义词替换该词;
(2)随机插入(RI,random insertion),随机选择一个词,再随机选择该词的一个同义词,插入句中随机位置,重复n 次;
(3)随机交换(RS,random swap),随机选择两个词,交换其在句中的位置,重复n 次;
(4)随机删除(RD,random deletion),对句中每个词以概率p 删除。
方法中涉及的变量及相互关系如下

式中:N 为一个样本的每种增强技术执行次数;Naug为增强的样本数,即增强后从每个原样本扩充的新样本数量;n 为每次增强所变动的词的个数;⎿⎿为向下取整;L 为一个样本中词的总数;α 为变动词占比(%),即每种增强技术在一个样本中所改动的词数占该样本总词数L 的比例。
上述4 种方法等同于对样本数据进行了加噪处理,减少数据过拟合情况,虽然从语义上会存在不通顺情况,但保持了较高的相似度,尽量保留了样本原标签。
文献[10]在同义词替换方法中使用Python 的nltk库中的语义词典Wordnet 获取英文同义词。本文基于增强方法[11]增强中文数据,采用中文近义词工具包Synonyms 获取同义词。
在使用EDA 算法过程中,选词的随机性会导致选中的词可能没有同义词以及原词包含在自己的同义词集合中等情况,在增强后的集合中可能存在重复数据。基于该情况增加了对一句话的循环增强,直至所有在设定参数下的增强数据及原数据不完全相同,对数据进行最大化加噪。
1.2 自动分类设计
1.2.1 实验框架
为便于观察,本实验根据一个事件类型下的事件信息数量的数量级,从原数据集中划分出3 个数据子集,每种事件类型的事件数分别为十数量级、百数量级和千数量级,在各子集下划分出训练集和测试集,前者用于数据增强以及模型的训练,后者用于模型测试,最后评价分析。实验流程如图3 所示。

图3 实验流程图Fig.3 Experimental flow chart
具体步骤如下:
步骤1将初始数据集转存为.csv 格式文件,整理后的第1 列数据内容为“事件类型”,第2 列数据内容为事件信息的“简要经过”,作为原数据集;
步骤2初始数据集中,各事件类型的事件数量最少为4,最大为12 209,为了降低不同类型下事件数量差别对模型性能的影响,依据一个事件类型所包含的事件信息数量的数量级,将原数据集划分为3 个数据子集,各子集对应的事件信息数量级分别为十、百、千数量级;
步骤3将3 个数据子集各采用分层采样的方式按7 ∶3 的一般比例划分为训练集和测试集(即每个事件类型的不同数量级的事件信息都按7∶3 的比例划分,再各自组为整体的训练集和测试集),分别用BERT 模型表示为数组形式,训练模型并判断模型性能,该部分作为基准实验,与后续实验作对照;
步骤4针对3 个数据子集,设定不同的测试集比例,对训练集进行EDA 增强处理,增强后的数据在表示为高维向量形式后作为新的训练集,未增强的测试集数据在表示为高维向量形式后,作为新的测试集,观察不同测试集占比对模型性能的影响;
步骤5按照步骤4 的方法,判断文本增强涉及的参数α 和Naug对不同数量级子集模型性能的影响;
步骤6从十数量级经增强后的数据中选取达到百数量级的数据子集,从千数量级中选取数据组成百数量级子集,从百数量级子集经增强后的数据中选取达到千数量级的数据子集,计算各自增强后的性能,并分别与原十数量级子集、百数量级子集和千数量级子集增强后性能进行对比,判断不同事件类型按相同数量级划分所得结果的通用性。
1.2.2 评价指标
本实验采用的评价指标如下。
1)加权准确率
加权准确率计算如下

式中:ni为第i 个事件类型包含的事件信息数量;Ne为要评价的模型包含的所有事件信息数量;k 为事件类型数;Ai为第i 个事件类型对应的准确率,准确率计算如下

式中:TP 为将正类预测为正类的事件数量;FN 为将正类预测为负类的事件数量;FP 为将负类预测为正类的事件数量;TN 为将负类预测为负类的事件数量(所关注的类为正类,其他类为负类)。
2)加权F1
加权F1计算如下

式中:F1i为第i 个事件类型的F1,F1为精确率和召回率的调和平均数,F1越高,模型越稳健,F1计算如下

式中:P 为精确率又称查准率,表示模型不将负样本标记为正样本的能力,即

R 为召回率又称查全率,表示模型找到所有正样本的能力,即

1.3 实验环境
实验环境整体配置较简单,具体环境如表1 所示。

表1 实验环境Tab.1 Experimental environment
1.4 数据准备
数据来源为中国民用航空安全信息系统事件库中的事件信息,使用“事件类型”及“简要经过”2 个数据内容,选择系统中2013 年6 月7 日(该系统中事件信息数据最早记录的日期)至2020 年5 月14日之间的所有事件信息数据,其中:①去除“其他”事件类型;②系统中存在不同时间上报同一事件的情况,如两条上报信息“发生时间”不同,但其他信息相同,只关注“简要经过”和“事件类型”2 个内容,因此对“简要经过”和“事件类型”存在重复的事件信息进行去重,保留其一,保留所述事件相同,但“简要经过”表述不完全相同的事件信息;③去除导出文件中“事件类型”和“简要经过”字符串中的空格。
经过上述处理,共得到包含74 个事件类型的43 297 个初始数据,每个数据包含“标签”和“内容”2部分。
1.5 模型参数
实验选择BERT 模型中的“BERT-Base,Chinese”模型[12],神经网络包含12 个隐藏层,每个隐藏层的大小为768 维,共有1.1×108个参数。
2 实验结果分析
实验主要观察不同数量级子集的测试集和增强后的训练集所对应的Aw和F1w,以及各子集下的实验运行总耗时(包括数据增强、模型训练及模型评价的运行耗时)。实验结果如表2 所示。

表2 基准实验的Aw、F1w 和耗时Tab.2 Aw,F1w and elapsed time of benchmark experiment
(1)由表2 可得,在未增强的基准试验中,千数量级子集可以直接获得85%以上的性能,相比千数量级子集,百数量级子集性能较低,有提升空间,而十数量级子集所得性能较差。
(2)相同测试集比例下,不同子集性能增量程度不同,性能增量(ΔF1w)如图4 所示。

图4 文本增强对模型性能的影响示意图Fig.4 Abridged general view of the impact of text enhancement on model performance
图4 中黑色部分为在测试集比例为0.30,Naug=4时,3 个子集对应的基准实验的测试集F1w值,灰色部分为经过增强后的性能增量。
(3)各事件类型数量级在不同测试集比例(0.05,0.10,0.20,0.30,0.50,0.70,0.90)下得到的模型性能增量如图5 所示。
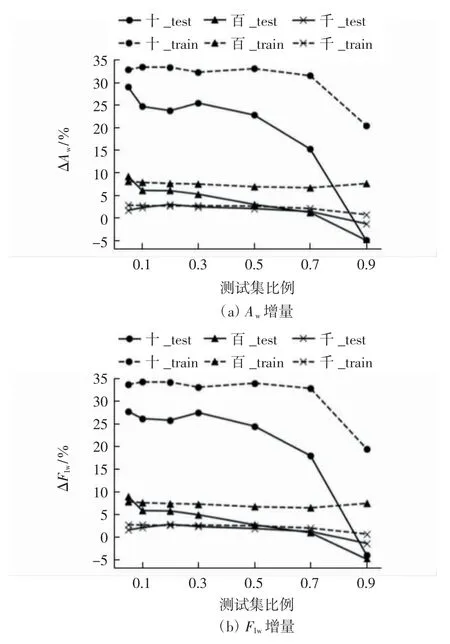
图5 3 个数量级子集在不同测试集比例下性能增量Fig.5 Performance increments of three subsets under different test set ratios
由图5 可得:百数量级和千数量级子集的测试集比例分别在0.05 和0.20 时性能较好;十数量级子集因原数据集各事件类型的事件数量较少,增强后模型性能增量较大,随着测试集占比增加,性能下降明显;十数量级子集测试集比例在0.05 和0.30 的性能增量都相对较高。在测试集比例为0.05 时,每个类型的测试数据样本数都在个位数,且Aw和F1w为1 的事件类型较多,同时也存在性能指标为0 的情况,即该参数下,虽然性能增量较高,但模型性能表现较为极端,不具有代表性;测试集比例为0.30 时,性能指标不存在为0 的情况,运行时间也比测试集比例为0.05 时短,ΔF1w与测试集比例为0.05 时基本相同。因此在数量级为十时,测试集比例为0.30 较好。
(4)各事件类型数量级在不同的变动词数占比α=0.05,0.10,0.15,0.20,0.25 下得到的模型的性能增量如图6 所示。
由图6 可得:随着α 的增加,训练集性能下降,可能因为一句话中变动词数增加,影响了一个事件信息原本的特征,而训练集中增强后的语句占比较大,因此,在数据量较大的情况下,整体识别能力有所下降,但测试集中的事件信息特征保留相对完整,性能相对稳定。

图6 3 种事件数量级在不同α 下的性能增量Fig.6 Performance increments of three subsets under different α
(5)千数量级子集在测试集比例为0.7 以下时,性能变化小,选择比例为0.6 进行下一步实验。各数量级在不同增强样本数Naug=4,8,12,16,20,24 下的模型性能增量如图7 所示。

图7 3 种事件数量级在不同Naug 下的性能增量Fig.7 Performance increment of three subsets under different Naug
由图7 可得,随着Naug的增加,十数量级子集和千数量级子集性能逐渐增加,但速度变缓,在Naug=8 时,百数量级子集性能最大,千数量级子集性能增幅最大。
(6)从十数量级子集中选取增强后达到百数量级子集的数据,与原来的百数量级子集进行对比;从千数量级子集中选取部分数据作为新的百数量级子集,并与原来的百数量级子集采用相同的增强参数,观察性能结果;再从百数量级子集中选取增强后达到千数量级子集的数据,与原来的千数量级子集做对比,结果如表3 所示。
由表3 可得:模型性能与事件类型的事件数量级相关;十数量级子集模型因原数据集小,增强后性能增量较大但性能相对较低;百数量级子集的模型性能相对较好,不论是原数据集、从千数量级子集中选择部分数据,还是将其增强至千数量级,性能都相对较好。具有不同特征的事件类型对模型结果影响不大,说明BERT 语言表示模型能较好地表示出民航不安全事件信息类型的特征。
各子集模型局部最优参数及性能如表4 所示。
3 结语
针对民航不安全事件信息的特点,通过对比分析不同量级的事件类型经过文本增强后再实现自动分类的模型性能,结论如下:
(1)在数据量相对较少的情况下,采用文本增强技术,分类器性能提升明显,事件类型的事件信息数量级为十数量级时,F1w提升31.21%,百数量级时,F1w提升9.66%,千数量级时,F1w提升3.35%;
(2)事件数量为百数量级的数据集时,模型性能相对较好,因此在实际应用中,人工标注至百数量级再完成下游任务即可;
(3)在经典机器学习方法SVM 的基础上进行文本增强,获得的模型Aw和F1w可以达到85%以上,属于可接受范围,可以应用。
下一步研究将考虑不安全事件信息的多标签属性,探索提高性能的其他技术,提高模型的泛化能力。
猜你喜欢
分子催化(2022年1期)2022-11-02
今日农业(2022年14期)2022-09-15
中学生数理化(高中版.高一使用)(2021年9期)2021-12-02
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
纺织科技进展(2021年5期)2021-07-22
家庭影院技术(2019年8期)2019-08-27
阅读(低年级)(2019年2期)2019-04-19
文理导航·科普童话(2015年6期)2015-07-29
数学教学通讯·初中版(2015年5期)2015-06-17
都市丽人(2015年4期)2015-03-20
