
基于分解的自适应邻域替换策略的特征选择算法
2022-08-04 05:40马璐,苏华
长春师范大学学报 2022年6期
马 璐,苏 华
(天津工业大学计算机科学与技术学院,天津 300387)
0 引言
如今各种技术飞速发展,数据呈爆发式增长,数据集中通常存在很多无关特征和冗余特征,这会降低数据精度。特征选择是提高特征数据集质量最有效的方法之一。对于一个分类问题来说,特征选择的目的是提取具有高识别能力的小部分特征子集[1]。然而,由于特征之间具有复杂的相互作用,随着特征数量的增加,搜索空间呈指数增长,特征选择越来越具有挑战性。
目前已有很多优秀的多目标优化方法被提出,例如,DEB等[2]提出的非支配排序遗传算法NSGA-II,ZITZLER等[3]提出的增强Pareto进化算法SPEA2,ZHANG等[4]提出的基于分解的多目标优化算法MOEA/D。各类算法在解决不同类型的特征选择问题上有着不同的特点和优势。相比之下,MOEA/D算法可以将复杂的多目标优化问题分解为多个子问题来求解,具有更好的搜索能力。
传统的MOEA/D算法通过计算所有权重向量之间的Euclidean距离给每个子问题划分对应的邻域,利用邻域内其他的子问题来完成协同进化[5]。但是在进化过程中,使用固定规模的邻域会使种群进化缓慢,从而影响分类性能。因此,为了确保早期搜索阶段的种群多样性,并使搜索将重点放在后期的开发上,本文提出了一个基于分解的自适应邻域替换策略(Adaptive Replacement,AR),在种群进化的不同时期,动态地为种群提供不同规模的邻域,以平衡种群的多样性和收敛性,提高进化效率,得到更优秀的特征子集。
1 相关工作
1.1 相关定义
特征选择是指从一个数据集中选择一组最优特征的过程[6]。相比于单目标,多目标特征选择可以很好地权衡多个相互冲突的目标,如降低特征数量和分类错误率[7]。通过多目标优化技术利用进化算法,同时优化两个目标,最终可以得到一组多目标最优解。再通过进一步分析,选择出特征数量较少且分类错误率相对较低的特征子集[8]。
本文将特征数量f1和分类错误率f2作为两个优化目标,研究多目标特征选择问题,定义如下:
minF(x)=[f1(x),f2(x)],
(1)

(2)
(3)
在式(2)中,f1表示特征集合M中被选中的特征个数。
在式(3)中,P和N表示真实样本是否属于某个类别,T和F表示预测结果,该样本的观察和预测结果一致为T,否则为F,该计算值f2就是分类错误率。
1.2 算法思想
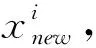
对于一个解x,如果子问题j满足以下条件,则称子问题j是最适合x的子问题:
(4)
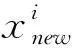
为了简单起见,替换策略并不限制被新解所取代的解的数量,所有的Tr相邻解都有可能被相同的新解所取代,因此,Tr是控制收敛性和多样性平衡的一个关键参数。在不同的进化阶段需要不同的Tr值。在种群进化的早期搜索阶段,应设置一个较小的Tr值,以保持良好的种群多样性;但在种群进化后期,应设置一个较大的Tr值,以提高种群收敛速度。因此,应在种群进化期间增加Tr值,本文采用如下方式来增加Tr值。
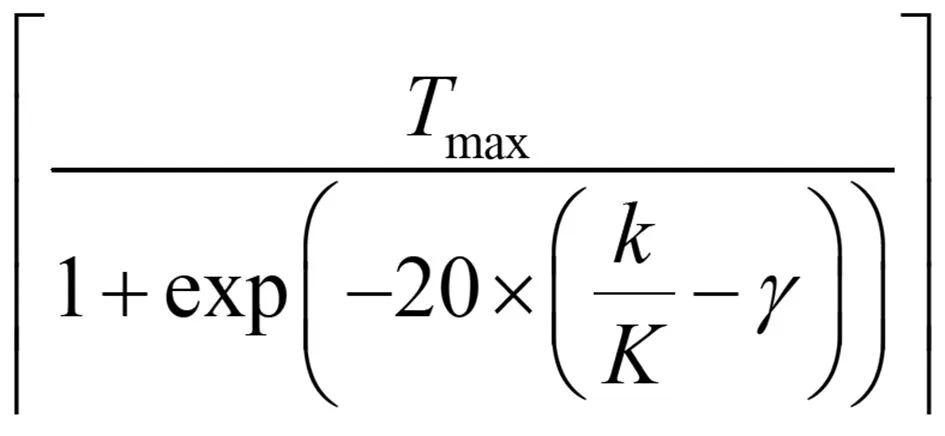
(5)
其中,「·⎤是上限函数,Tmax是Tr的最大值,k是当前代数,K是最大代数,γ是一个控制参数,γ∈[0,1),确定Tr随着搜索的进行而增加的方式。
2 基于分解的自适应邻域替换策略
基于分解的自适应邻域替换策略(MOEA/D-AR)的特征选择算法执行过程如下:
输入:原始数据集OTD;种群规模N;均匀分布的权重向量W={λ1,…,λN};邻域大小T,变异概率Pm,交叉概率Pc;最大迭代代数Maxgen;种群规模pop;
输出:非支配特征子集的特征数和分类错误率;
Step1 初始化;
Step1.1 计算任意两个权重向量之间的Euclidean距离,为每个权重向量选出最近的T个权重向量作为其初始邻域。设B(i)={i1,i2,…,iT},i=1,2,…,N,其中,λi1,λi2,…,λiT是距离λi最近的T个权重向量;
Step1.2 初始化种群P,并计算初始个体xi的函数值Fi(f1,f2);
Step1.3 初始化理想点Z*={min(f1),min(f2)};
Step2 更新:fori=1 toN,do
Step2.1 在每代更新之前计算每代的选择邻域Bm(i),计算替换邻域Tr值,计算Br(i);
Step2.2 繁殖:从Bm(i)中随机选择两个邻居xk,xl,通过遗传算子由xk,xl进行交叉变异生成新解;
Step2.3 修正:应用问题特定的启发式的改进策略作用于y生成y′;
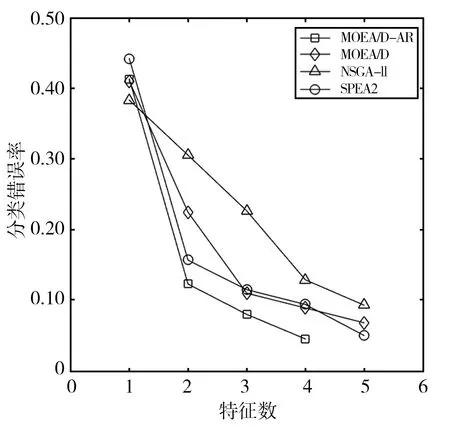
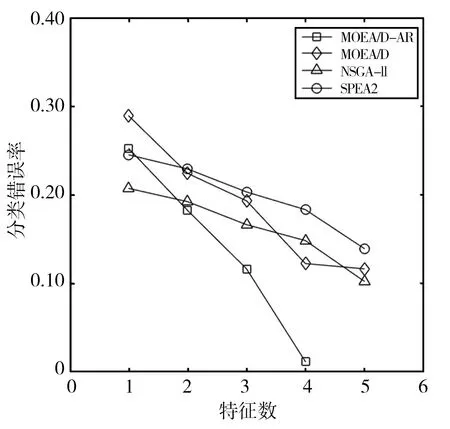
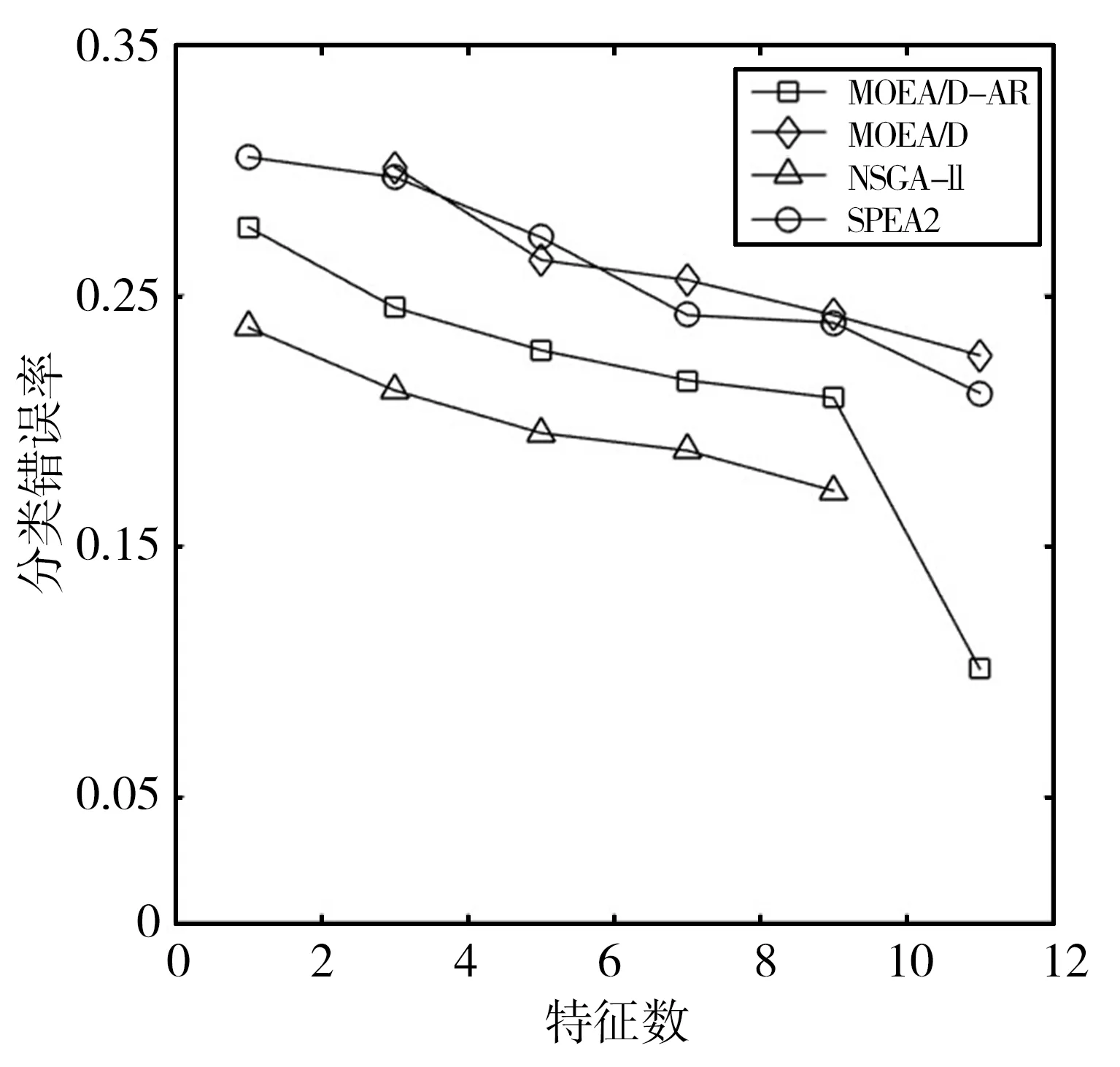
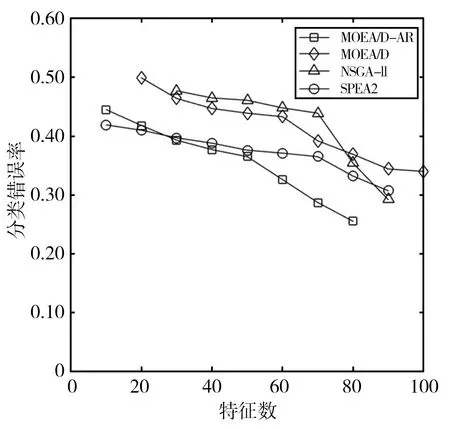
Step2.4 更新Z*:若Zj Step2.5 更新解:采用更新函数更新Z*,Br(i),y,P,W; Step3 停止判断:当达到最大迭代次数时,则输出Pareto非支配解,否则返回Step2继续执行; Step4 选择PF(Pareto Front)中合适的非支配解作为特征子集; Step5 计算特征子集中个体的特征数和分类错误率并作为结果返回。 本文在UCI machine learning repository[12]中选取了表1所示的5个数据集。并将所提出的MOEA/D-AR算法分别与如下3种著名的多目标算法进行了比较:标准的MOEA/D[4]、NSGA-II[2]、SPEA2[3]。在测试中,所有算法都采用十折交叉验证的KNN[13]计算训练集的分类误差率。然后在测试集上对进化的特征子集进行评估,以获得其测试精度。KNN中的近邻数设为5,以避免出现冗余的实例,同时保持其效率。最大迭代次数为20次,种群大小为50,阈值θ设置为0.6,用来决定特征是否被选中。所有的算法都在测试中独立运行30次,然后在测试集上对进化的特征子集进行评估,以获得其测试精度。 表1 数据集及参数设置 本文算法和其他3种算法在各数据集上的最优非支配解集对应的帕累托前沿如图1所示。MOEA/D-AR在5个数据集上得到的分类错误率,不仅明显优于使用全部特征时的分类错误率,而且相较于3个对比算法, MOEA/D-AR在大多数情况下都更优于其他算法。 (a)Wine (b)Australian (c)Zoo (d)Ionosphere (e)Hill-valley图1 各算法在不同数据集上最优非支配解集对应的Pareto前沿 在Wine数据集中,MOEA/D-AR算法只需要选取15%的特征数,也就是13个特征里面选择了2个就能达到比使用全部特征更小的分类错误率。在Australian中,MOEA/D-AR算法只选取了21%的特征,即14个特征中选择了3个,得到的分类错误率就小于总分类错误率。在Zoo中,MOEA/D-AR选择了24%的特征数,即17个中选择了4个,就能得到比使用全部特征更小的分类错误率。在Hill-valley中,MOEA/D-AR只选择了总特征数的10%,就使分类错误率低于使用全部特征时的分类错误率。在Ionosphere数据集中,MOEA/D的性能略低于NSGA-II,排名第二,选择了30%的特征,即34个中选择了10个,就使分类错误率低于总分类错误率,选取的特征数比排名第一的NAGA-II仅高4%。 表2给出了5种算法在测试结果中分类错误率低于使用所有特征时的最小特征数和对应的分类错误率。由表2可以看出,除了Ionosphere数据集,MOEA/D-AR在其他4个数据集中,都能得到更小的特征数目;且当所选取的特征数目相等时,MOEA/D-AR所选取的特征子集的分类错误率也更低。研究结果表明,MOEA/D-AR可以选取出性能更优的特征子集。 表2 分类错误率低于使用全部特征时各算法所对应的最小特征数及分类错误率 为了避免使用经典的MOEA/D算法进行特征选择时,由于邻域规模固定而导致种群丧失多样性且进化效率低,从而产生过多冗余数据的问题,本文提出了一种基于分解的自适应邻域替换策略(MOEA/D-AR)的特征选择算法,该算法根据进化过程中邻域规模的大小,自适应地替换邻域解,并保证每个解都对应其最合适的子问题。实验结果表明,本文提出的算法可以得到特征数目少且分类错误率更低的优秀特征子集。 同时该算法也存在一定的缺陷,例如,使用的固定参数较多,这些参数大多不可以自主学习,在一定程度上影响了算法性能。在今后的工作中将对以上问题加以改进,使这些固定参数也可以随着迭代过程进行动态调整,进一步优化算法。

3 实验结果与分析
3.1 数据集与参数设置

3.2 实验结果


4 结语
猜你喜欢
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
南京大学学报(数学半年刊)(2020年1期)2020-03-19
新课程·上旬(2019年1期)2019-03-18
吉林大学学报(理学版)(2018年4期)2018-07-19
教师·中(2017年3期)2017-04-20
电子制作(2017年23期)2017-02-02
试题与研究·教学论坛(2016年27期)2016-08-11
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
都市丽人(2015年4期)2015-03-20
