
基于可解释机器学习的水平井产能预测方法
2022-08-15 06:08马先林周德胜蔡文斌李宪文何明舫
西南石油大学学报(自然科学版) 2022年4期
马先林 ,周德胜,蔡文斌,李宪文,何明舫
1.西安石油大学石油工程学院,陕西 西安 710065 2.西部低渗--特低渗油藏开发与治理教育部工程研究中心,陕西 西安 710065 3.中国石油长庆油田公司油气工艺研究院,陕西 西安 710018
引言
传统的多段压裂水平井产能预测模型,大多采用机理驱动的方式建立,建模方法包括解析、半解析及数值模拟方法等。解析法基于均质储层、单相渗流及简单平板状双翼对称裂缝等假设,以油气渗流力学为基础,应用压力叠加原理和位势能理论等得出产能计算公式,计算效率高[1-5];而对于非均质较强、多相渗流、复杂裂缝网络的储层,应用油气藏数值模拟法进行产能预测,在精细油气藏描述的基础上,应用连续介质或离散模型描述人工裂缝和天然裂缝,通过模拟油气在储层中渗流过程,计算分段压裂水平井的产能[6-9]。
传统的产能预测方法对储层特征和复杂缝网几何形态表征不但存在较强的不确定性,而且还引入了一些理想化假设和计算上的简化,使得产能预测结果可能偏离实际。另外,在渗流方程求解时,大多数采用网格加密及迭代计算等手段,导致建模周期长,计算效率低下。事实上,分段压裂水平井的生产规律受到地质、钻完井、压裂施工及生产制度等诸多因素的影响,因此,过多的理想化假设以及求解方法的复杂性限制了机理驱动产能预测方法在现场的应用与推广。
随着人工智能的兴起,特别是机器学习技术为多级压裂水平井产能预测提供了新的途径。与传统的机理驱动方法相比,该方法通过对油气大数据的挖掘,建立压裂井产能与储层、钻完井和压裂施工等参数之间的相关模型,能够迅速地对压裂效果进行评价,从而进行压裂优化设计。基于数据驱动的建模方法已经在致密油气藏开发中得到了初步的应用[10-14],体现了在产能预测方面独特的优势。但所建立的预测模型大多是“黑盒子”模型,即输入一组相关参数值能够获得产能的预测值,却不能解释模型内部的预测机制,从而降低了模型的可信度与实用性。为此,许多学者对提高机器学习模型可解释性进行了研究,并提出了一些解释方法[15]。机器学习产能建模是纯数据驱动的方法,预测精度依赖于样本数据的个数和质量,小样本会导致预测失真和泛化能力降低。
本文首先介绍致密气藏水平井产能预测机器学习建模流程和机器学习原理,其次讨论对预测模型进行解释的SHAP(SHapley Additive exPlanations)方法原理,并以苏里格气田东区分段压裂水平井为例,对方法的有效性和实用性进行验证。
1 水平井产能预测机器学习建模流程
利用机器学习建立致密气藏分段压裂水平井产能预测模型,包括6 个步骤,如图1 所示。

图1 水平井产能机器学习建模流程图Fig.1 Workflow for modelling horizontal well productivity using machine learning
(1)原始数据收集。数据集包括主要影响参数及其压裂后水平井的产能评价指标,其中,影响参数包括地质、工程等因素,产能可以是无阻流量或产气量等。
(2)数据预处理。先进行数据清洗、缺失数据插补、数据降维及数据转换等[16],再将预处理后的数据集划分为训练集和测试集,划分比例一般取70%~30%或80%~20%。
(3)机器学习建模。应用训练集数据建立产能模型,主要寻找机器学习模型中最优的超参数取值,常用的优化方法包括网格搜索、多折交叉验证及自动学习等。
(4)产能预测模型评价。利用测试集数据评估产能预测模型精度,常用精度评价指标包括决定系数(R2)、平均绝对误差(MAE)及均方误差(MSE)。根据评价指标,选择在测试集上具有最高预测性能的机器学习算法所建立的产能预测模型。
(5)模型解释。基于建立的最优产能预测模型,利用SHAP 方法对产能预测进行全局和局部解释。
(6)模型应用。应用建立的产能预测模型,评价压裂效果,优化新井的压裂参数设计。
2 机器学习原理
2.1 机器学习方法
机器学习是一门多领域交叉技术,其本质是一种特殊的算法。通过分析大数据,发现数据内部潜在的模式并应用这些模式进行预测[17]。假设一个训练数据集D包含n个学习样本,每个样本有m个影响参数和一个输出参数,即

选择相应的机器学习算法在此数据集建立一个预测模型ˆy=f(x,θ),优化算法的超参数θ,使得以下误差函数值最小

式中:f--某一机器学习算法建立的模型;θ--该算法的超参数;L(yi,f(xi,θ))--误差函数。
典型的机器学习算法包括人工神经网络、支持向量机、决策树及随机森林及梯度提升树等。
2.2 机器学习模型的可解释性
机器学习模型可解释性为用户提供了理解机器学习模型一个接口,既是机器学习模型的代理,又是一种解释模型的方法[18-19]。模型可解释性分为两类:事前可解释性和事后可解释性。事前可解释性是指在建模时,采用可解释性好的模型或设计有解释能力的模型,使模型自身具有解释能力。事后可解释性是对已建立的机器学习模型进行解释,独立于机器学习建模过程,灵活性较强。根据可解释的范围,事后可解释性又分为全局和局部两种,全局可解释用于理解模型内部的工作原理,对模型整体能力的解释[20];局部可解释用于理解机器学习模型针对单个样本的预测过程和依据,对样本的预测结果进行解释[21]。
本文是对建好的水平井产能模型预测结果进行解释,属于事后可解释性,应用SHAP 可解释技术。SHAP 法通过计算每一个输入变量对预测的贡献值进行模型解释,是一种加性解释方法。比如,使用SHAP 法解释样本x*的机器模型预测值ˆy=f(x*)时,预测值f(x*)可以分解成

式中:φ0--预测模型f(x) 在数据集上的平均预测值;--第j个输入变量对样本x*预测的贡献值,即SHAP 值;M--输入变量的数量。
对于3 个输入变量的预测问题,式(3)的示意流程见图2,红色表示SHAP 值是正的,蓝色则表示SHAP 值是负的。图2 表明,SHAP 值表示某一个样本的预测值各个输入变量的贡献大小[22],φ1表示变量1 用于预测后引起当前预测值的变化,是正影响,导致预测值增加,同理,φ2为变量2 加入后当前预测值的增加量,但是,当变量3 加入预测后,导致当前预测值减少,减少量为φ3。

图2 3 个输入变量SHAP 方法Fig.2 SHAP method with three input variables
3 应用实例
3.1 数据收集
收集的原始数据包括苏里格气田东区598 口分段压裂水平井,产能影响参数包括7 个地质和完井参数以及15 个压裂施工输入参数,输出参数为无阻流量,具体参数描述见表1。

表1 产能影响参数Tab.1 Influential parameters of well productivity
由于大部分水平井没有进行测井,不能分析孔隙度、渗透率、杨氏模量及泊松比等参数对产能的影响。
3.2 数据预处理
3.2.1 缺失值处理
在数据集中,储层水平段长度的缺失值多达25.00%,破裂压力有13.00% 的数值缺失,远大于5.00% 安全最大阈值插补的要求,因此,这些变量在建模时不予以考虑。其他变量缺失值的分布如图3所示。由图3a 可以看出,大部分变量的缺失值低于2.00%。
图3b 显示了变量缺失值的分布,其中,最上面的红色竖条表示入井总液量有0.25%数值缺少,第二行的红竖条表示液氮量缺失0.50%,第三行的两个红竖条表示液氮量和施工最高压力同时缺失达1.26%,第四行的红竖条表示垂深缺失2.02%,最下行表示95.97%数据没有缺失。由于数据缺失较少,故决定删除数据表中有缺失值的那些井,剩余水平井数量为574 口。

图3 变量缺失值分析Fig.3 Missing data analysis
3.2.2 异常值处理
原始数据中若存在不合理的值,会影响模型预测精度。采用基于箱线图的异常值检测方法,利用数据中的上、下四分位数(Q3、Q1)及四分位距(IQR),四分位距定义为上四分位数与下四分位数的差值,即IQR=Q3-Q1,变量的值大于Q3+1.5IQR和小于Q1-1.5IQR为异常值。在剔除数据集中的异常值后,用于机器学习建模的水平井为532 口。
3.2.3 描述性数据分析
描述性数据分析采用图表等方式对数据进行统计性描述,是建模的重要内容。
图4 显示了2012--2020 年平均无阻流量和主要压裂施工参数的变化趋势,随着平均最大排量、加砂量和压裂段数的增加,水平井分段压裂后的增产效果明显。

图4 平均无阻流量和压裂施工参数的变化趋势Fig.4 Trend analysis of average absolute open flow potential and hydraulic fracturing treatment
图5 给出了主要压裂参数与无阻流量的箱线图,从图中可以看出,无阻流量与水平段长度、压裂段数、加砂量、排量和入井总液量均存在正相关关系,采用水力桥塞分段压裂工艺后显著地提高了水平井的产能。

图5 压裂参数影响无阻流量的箱线图Fig.5 Boxplots for effect of hydraulic fracturing treatment parameters on AFOP
3.2.4 相关性分析
若同时使用相关性较强的输入参数,建模不仅会增加模型训练的时间,而且影响模型可解释性。
图6 给出了变量间的Pearson 相关系数,与无阻流量正相关最强的参数是加砂量(R=0.50),其次是有效储层段长度、压裂段数及入井总液量等参数。完井井深与水平段长具有极强的线性正相关性(R=0.92),表明完井较深的水平井具有较长的水平段长度;水平段长同有效储层水平段长、压裂段数、入井总液量也具有较强的线性正相关;砂量与入井总液量也具有很强的线性相关性(R=0.91)。

图6 Pearson 相关系数矩阵Fig.6 Pearson correlation matrix
为减少变量间的线性相关性,建立以下输入参数:(1)段间距=水平段长度/压裂段数,不再使用压裂段数;(2)加砂强度=砂量/水平段长度,代替加砂量;(3)用液强度=入井总液量/水平段长度,代替入井总液量。
采用逐步向后回归,对输入参数进行了选择,确定建模的输入参数为水平井水平段长、有效储层水平段长、完井井深、段间距、加砂强度、用液强度、改造工艺及最大排量。
3.3 产能预测模型的构建
经过预处理后的数据集按80%~20% 的比例随机划分成训练集与测试集,采用人工神经网络(ANN)、支撑向量机(SVM)、随机森林(RF)和梯度提升树(GBDT)算法在训练集学习,构建无阻流量预测模型。
3.3.1 模型超参数优化
采用网格搜索和十折交叉验证方法,在训练集上对4 种机器学习算法的超参数进行优化。以GBDT 算法为例,GBDT 中的主要超参数有决策树的棵数、决策树的深度和决策树的深度。首先确定这些超参数的范围,再应用十折交叉验证方法进行验证,超参数决策树的棵数、决策树的深度及决策树的深度取值分别为43、8 和2。GBDT 模型预测结果如图7 所示。
由图7 可以产出,无阻流量小于100×104m3/d时,模型预测值比较接近实际值。然而,当无阻流量大于100×104m3/d 时,模型预测精度不理想,主要原因是水力桥塞分段压裂水平井只占数据集的19%,而在这些井中无阻流量大于100×104m3/d 的达57%,增加水力桥塞分段压裂水平井数据有助于改进模型预测精度。

图7 GBDT 模型预测结果Fig.7 Prediction results of GBDT model
3.3.2 模型评价
由于目前没有一个机器算法能够绝对优于其他算法,主要通过评价机器学习模型在测试数据集的预测性能,选择最适合的算法,为此,应用建立的机器学习模型对测试集中的106 口水平井的无阻流量进行了预测,表2 是这些模型的预测性能对比。
平均绝对误差和均方误差越小,模型预测值与实际值越接近;决定系数越接近1,模型预测值与实际值越接近。由表2 可以看出,GBDT 算法在测试集上的预测结果优于其他几种学习算法,故对用GBDT 建立的预测模型进行解释。

表2 机器学习模型性能对比Tab.2 Comparison of performances of machine learning model
3.4 产能预测模型解释
3.4.1 模型全局解释
图8 给出了GBDT 模型的解释,压裂施工参数中,改造工艺和最大排量对无阻流量的影响最显著,2018 年以前,苏里格气田采用裸眼封隔器和水力喷砂分段压裂改造工艺,排量大部分集中在2~4 m3/min,施工排量低,而且施工段数受限。2018年以后,改用水力桥塞分段压裂改造方式,排量提高到6~10 m3/min,施工段数也有所增加,无阻流量大于100×104m3/d 的水平井明显多于其他两种改造工艺。有效储层段长度和完井井深对无阻流量也有较大的影响,井越深,储层压力越大。
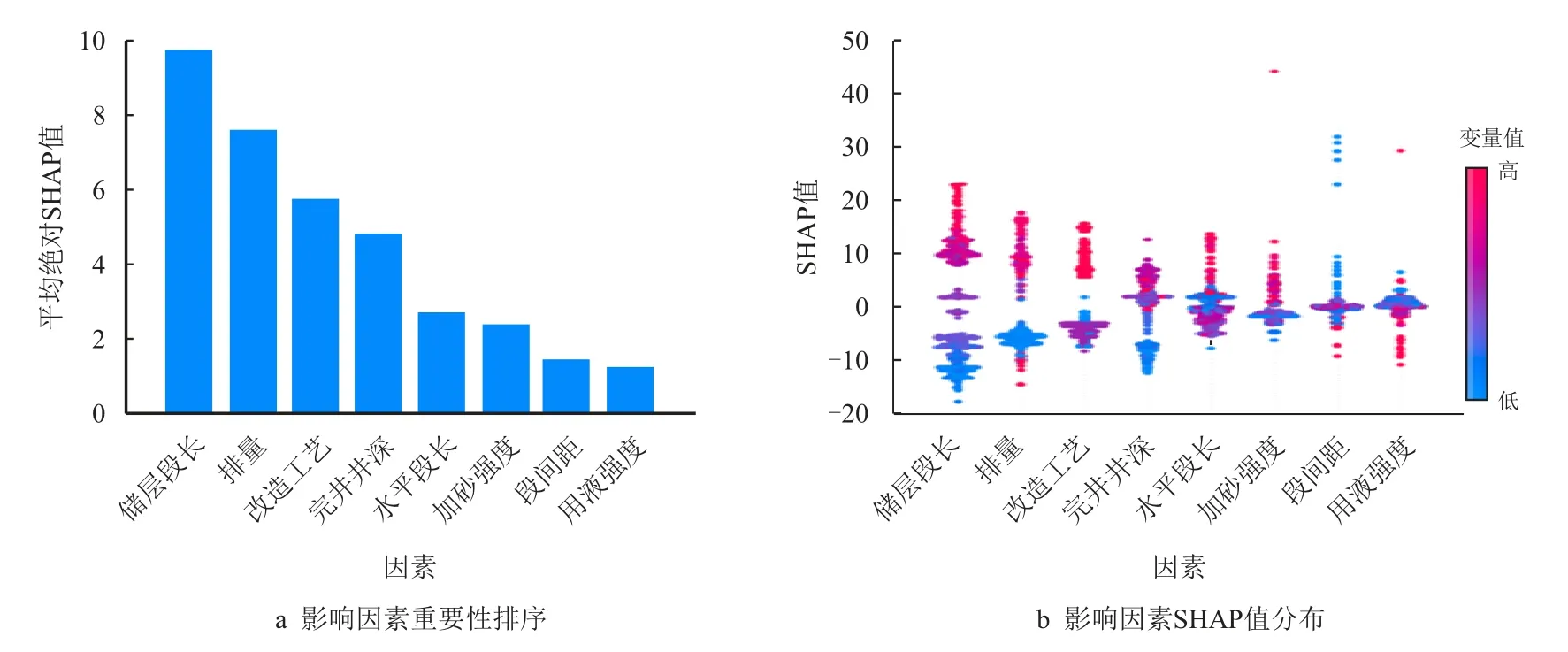
图8 影响因素重要性全局分析Fig.8 Global interpretation of input variables
图8b 展示了每个影响因素SHAP 值的分布,图中,每个数据点代表一口压裂水平井,颜色表示变量的值,从蓝色到红色表示变量数值由低到高的变化。
正(负)的SHAP 值表示影响参数与无阻流量呈正(负)相关,例如,增大排量,排量的SHAP 值会变大,导致无阻流量增大;而无阻流量则随着段间距增加而减少。
3.4.2 模型局部解释
图9 给出了一口水平井的局部解释。该井的无阻流量是所有输入参数贡献的总和,基准值为GBDT 模型预测的无阻流量平均值,等于50.88×104m3/d。红色导致该平均值增加,而蓝色表示使其下降。有效储层段长、完井井深和用液强度的SHAP 值分别为9.891,5.294 和1.578;最大排量、改造工艺和加砂强度的SHAP 值分别是-6.898,-5.582 和-1.745,段间距和水平段长的影响也是负的,它们的SHAP 值太小,在图中无法显示。最终,该压裂水平井的无阻流量预测值为53.03×104m3/d,接近实际值59.93×104m3/d。

图9 某水平井无阻流量预测结果解释Fig.9 Local interpretation of a fractured horizontal well
3.4.3 变量相关解释
SHAP 方法还能揭示输入变量之间相关性对无阻流量的影响。
如图10a 所示,当采用水力桥塞分段压裂工艺时,改造工艺的SHAP 值迅速增加,说明水力桥塞分段压裂工艺与无阻流量呈正相关;而且随着压裂水平段增长,进一步增加水力桥塞分段压裂工艺的SHAP 值,因此,采用长压裂水平段的桥塞分段压裂能够增加无阻流量。

图10 变量相关性解释Fig.10 Interpretation of variable correlation
图10b 表明,当段间距小于100 m 时,段间距的SHAP 值迅速增加,导致无阻流量增大,而且提高加砂强度有助于段间距的SHAP 值增大,进一步增加无阻流量。但是,随着段间距的增大,却引起其SHAP 值减少,因此,段间距与无阻流量呈负相关。
4 结论
(1)提出了一种基于机器学习算法进行致密气藏分段压裂水平井产能预测以及模型解释的方法,该方法是对现有机理驱动产能预测方法的有效补充,具有多类型数据综合和较强的预测能力,能够有效地提高分段压裂水平井产能预测效率和精度,实用性强。
(2)学习模型全局可解释性有助于理解梯度提升树算法产能预测机制,明确影响苏里格气田东区分段压裂水平井无阻流量主要压裂施工参数是排量和改造工艺。
(3)SHAP 值不仅有助于分析单一压裂水平井产能的影响因素,还能理解输入变量之间的交互作用对产能的影响。
(4)首次应用可解释机器学习算法对苏里格气田东区分段压裂水平井产能评价,可为该区的压裂优化设计和开发方案制定提供依据。
猜你喜欢
科学家(2022年3期)2022-04-11
数理化解题研究·综合版(2021年11期)2021-12-22
山西教育·招考(2021年8期)2021-12-17
小学教学研究(2021年5期)2021-09-29
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
语数外学习·高中版上旬(2020年5期)2020-09-10
科学导报·学术(2020年79期)2020-09-06
初中生世界·九年级(2020年2期)2020-04-10
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
