
基于图注意力和单中心损失的语音鉴伪*
2022-08-23 01:53沈宜,杨捍,石珺,贾宇
通信技术 2022年7期
沈 宜,杨 捍,石 珺,贾 宇
(深圳市网联安瑞网络科技有限公司,广东 深圳 518042)
0 引言
语音鉴伪是为了检测伪造音频,随着深度学习技术的应用,说话人验证被广泛地应用在人机交互领域,其准确率也在不断地提升。然而,基于深度学习的文字到语音的转换技术,以及声音转换技术也能够生产足以媲美真实语音的合成音频,以至于人耳也难以鉴别,因此,对现有的说话人声真伪验证应用造成了安全威胁,而检测利用深度合成技术生成的音频也逐渐引起工业界和学术界的重视。为了提高语音鉴伪在面临不断更新的合成与转换技术攻击时的有效性和准确率,在2019 年的ASVspoof挑战赛上,官方放出了2 类数据,分别为LA 数据集和PA 数据集。LA 数据集是由不同的语音合成技术和语音转换技术生成的合成语音,而PA 数据集是通过录音、物理回放等手段合成的语音片段。本文主要针对利用语音合成技术与转换技术合成的语音进行鉴伪。
语音鉴伪的整体流程大致如图1 所示,具体可以分为数据增强、音频提取前端、特征提取主干网络、损失函数等流程。数据增强是为了让模型具有更好的泛化性,从而设计的不同方法;音频前端处理是针对原始语音片段所设计的音频特征的提取方法;特征提取主干网络是在音频前端提取的特征的基础上,进行后续特征提取处理,目的是提取信息更加丰富的高层次特征;最小化损失函数则是为了让所设计的语音鉴伪网络学习到更强大的鉴别能力。
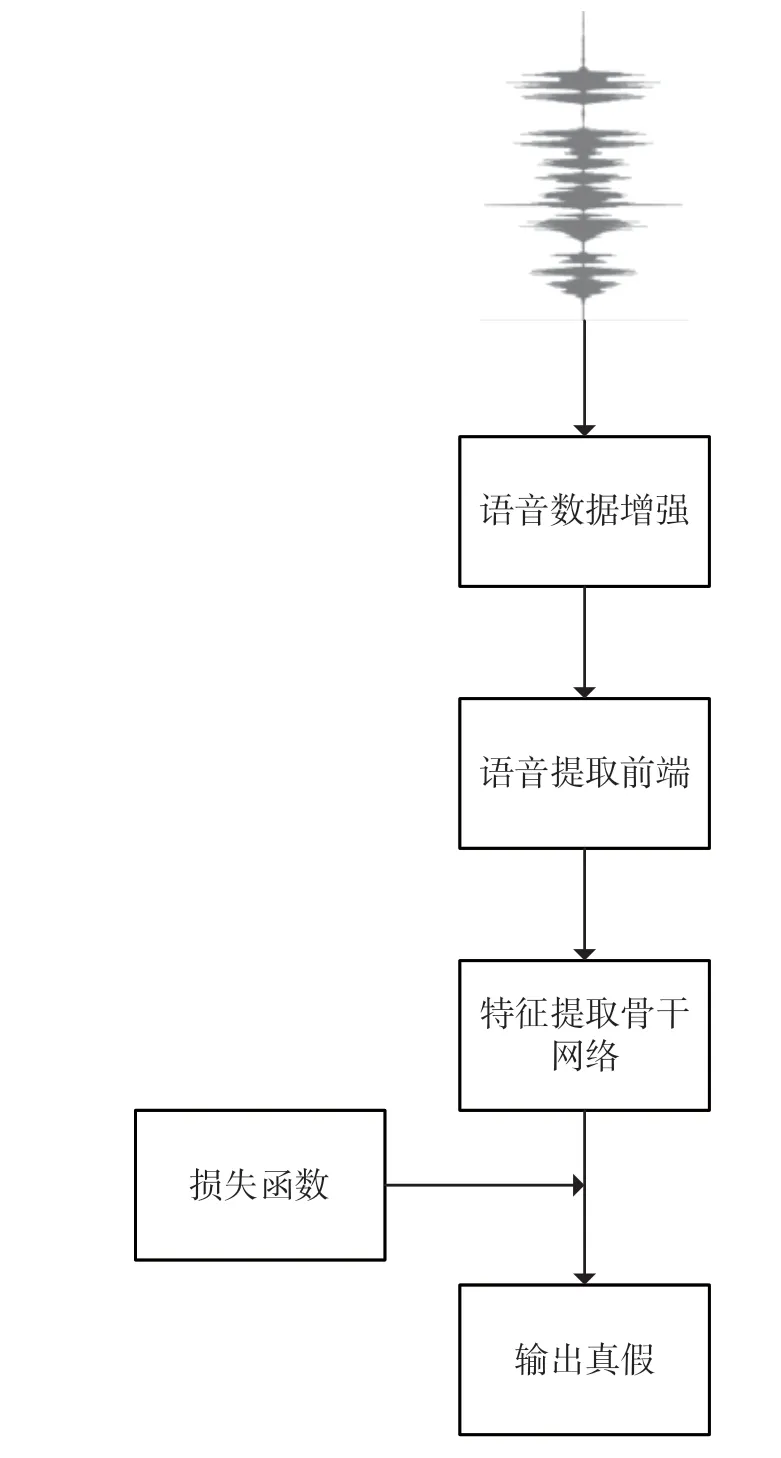
图1 语音鉴伪流程
通常音频处理前端提取的音频大多是长度较长的一维的音频向量,此外,根据音频的采样率的不同,每1 s 中包含的语音采样点数不同,例如,16 kHz采样率的音频在1 s 内有16 000 个采样数值。为了减少音频处理的长度,针对音频文件常采样压缩后的特征,如梅尔倒谱系数特征(Mel-Frequency Cepstral Coefficients,MFCC)、线性频率倒谱系数(Linear Frequency Cepstral Coefficient,LFCC)、常量q 系数(Constant Q Cepstral Coefficient,CQCC)等基于人工设计的倒谱系数,然而人工设计的特征并不能完全代表各领域中分类的显著特征,尤其是可学习的特征,该特征在最近的分类任务[1]中表现得比人工设计的特征更为出色。
语音鉴伪中,特征网络提取目前使用的主流方案仍是基于卷积神经网络、循环神经网络等。但在最近几年里,图神经网络的出现吸引了大量的注意,尤其是图卷积网络[2]和图注意力网络[3],比如在一些工作中已经出现了利用图神经网络来建模语音相关的任务[4–7],例如,文献[4]将图注意网络作为骨干网络应用于说话人验证中;文献[5]在少样本音频分类任务上,利用图卷积神经网络来提高鉴别不同类别语音的能力;文献[7]利用图卷积神经网络来建模不同声道的空间关系,从而提高音频的质量。语音鉴伪属于二分类任务,常用的损失函数为分类交叉熵损失。
1 整体流程
针对语音鉴伪,本文从语音数据增强、语音特征提取、特征提取网络主干、损失函数这4 个方面进行实验。本文设计方案整体流程如图2 所示。图中SCL 为单中心损失(Single Center Loss),BCE 为二分类交叉熵损失(Binary CrossEntropy),SincNet 为利用SincNet[8]提取音频特征的方法,ResBlock 为残差模块

图2 基于图注意力和单中心损失语音鉴伪流程
1.1 语音数据增强
为了提高语音鉴伪模型的泛化能力,本文采用了增加高通滤波器、增加背景噪声、增加随机的音频剪切这3 种不同的数据增强方式。图3 展示了原始的音频频谱和语音波形,以及利用3 种不同方式进行数据增强后的频谱和语音波形。
1.2 语音特征提取
针对语音提取前端,区别于只采用人工设计的音频特征的方案,本文将1D 卷积神经网络直接作用于音频波形转换后的梅尔倒谱频率系数[8],这种方法在收敛和稳定性方面具有一定的优势。本文将音频波形转换为梅尔特征后,利用SincNet[8]进行特征提取,对梅尔特征进行特征提取的1D 卷积部分在整个网络是可学习的,而SincNet[8]的输出特征在增加一个维度后,转换为结合了时域和频域的初级特征表示。后续采用残差模块对初级特征进一步提取,从而得到高层次特征H(S,F,T),S表示特征的通道数,F表示频域长度,T表示时域长度,每个残差块包含批量归一化(Batch Norm,BN)模块和ReLU 激活函数,以及最大池化。
1.3 特征提取网络主干
针对特征网络主干部分,区别于常用的卷积神经网络等方法,本文采用基于自注意力机制的图注意力网络进行特征提取,具体是利用图注意力模块,并将高层次特征作为注意力模块的输入,从而挖掘语音信号中更丰富的鉴别信息。本文采用2 个图注意力模块分别从高层次特征中挖掘频域和时域信息,并利用图注意力的结构,提取不同频域和时域特征间的联系,再对经过图注意力模块后的频域和时域特征进行融合得到融合特征。针对不同的损失函数,对融合特征进行后续操作。
如图4 所示,图注意力网络会从自注意力机制中学习到图中相邻2 个节点的信息,并分配对应的权重。假设图网络中有6 个节点,δ表示不同节点间的权重,如δ12表示节点h1和节点h2之间的权重。具有更丰富信息的节点间通过自注意力机制,会得到更大的权重值,而权重越大,表示相邻节点间联系越紧密,即有更丰富的信息。

图4 节点h1 与各节点权重关系
经过图注意力后,图节点根据最小化损失函数被映射成其他特征表示,其表达式为:

式中:Mout为将每个节点向量映射为标量的映射矩阵;σn为图注意力网络中每个节点的输出特征;∂表示整个图。σn的计算公式为:

式中:BN表示批量归一化[9];Matt为将每个节点聚合后的信息映射到固定维度的映射矩阵;Mres为将残差输入映射到固定维度的残差映射矩阵;βn为通过自注意力机制整合的相邻节点信息。βn的计算公式为:
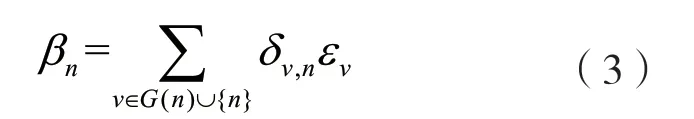
式中:G(n)为图中节点的邻接节点集合,当图中节点数为6 时,如图4 所示,节点n,v可为h1到h6中的任意节点;δv,n为2 节点间的注意力权重;εv为节点v的输出特征。注意力权重的计算方式如下[3]:

式中:Mmap为可学习的点乘矩阵;⊙表示逐元素点乘。
经过自注意力图计算以及图池化后,频域特征和时域特征的节点数以及节点对应的维度都将减小,如图5 所示,图特征中节点数量,以及每个节点对应的特征维度都将减少。自注意力机制的图计算将减少每个节点中的维度,图池化操作减少图中的节点数量,o1表示节点h1经过图计算、图池化操作后得到的特征。同理,o3和o5分别表示节点h3和节点h5。GAT(N,D)表示整个图,N表示节点个数,D表示每个节点对应的特征维度。poolout(Nout,Dout)表示自注意力图计算以及图池化后的输出。

图5 图网络中特征维度变化
通过筛选掉部分图节点,图池化操作能产生更具有判别性的图节点,可通过设置图池化中的减少比率来控制图节点的减少数量。
本文中采用的图池化操作来自文献[10],图池化操作流程描述如图6 所示,用一个可学习的映射向量q(D,1),高层次特征经过频域或时域网络时,得到图特征feature,与映射向量q做乘积后得到图中每个节点的scores,大小为(N,1),N表示图特征feature中节点的数量。如图5 中有6 个节点。根据设置的减少率,选取topk个最大得分的图节点。图中减少率设置为0.5,则对应设置的topk数为3,得到scores´(topk,1),根据topk对应的节点id选取feature中对应的节点特征featuretopk,与经过激活函数sigmod的scores´矩阵逐元素做点积得到图池化的输出poolout。

图6 图池化操作流程
本文中整个音频鉴伪流程是端到端的,从音频特征提取模块到高层次特征提取模块、图注意力模块、时域和频域模块以及到最后的全连接层,整个网络都是端到端的。
1.4 损失函数
对于常用的二分类问题,采用的损失函数常见于交叉熵损失函数,但由于随着音频合成技术的不断突破,出现了越来越多的新兴合成技术,使得鉴别的难度也越来越大。因此,为了提高模型的泛化性,除了音频的特征提取,主干网络的选取和损失函数的选择也至关重要。本文除了采用二分类交叉熵损失,还采用了文献[11]针对人脸鉴伪采用的SCL 函数,如图7 所示。该损失函数将网络提取的真人特征拉近一个中心,将假的人脸、合成的人脸特征远离真人特征中心。因此无论采用哪种方式合成的人脸,只要是假的都会被单中心损失拉远与单中心间的距离,针对未在训练集出现过的合成人脸方式,则具有更高的泛化性。

图7 单中心损失
本文将该损失函数引入音频鉴伪领域。同样的,将真实的语音经过图注意力网络提取后得到的频率域特征与时域特征融合,此时将会汇集到一个中心,而通过合成技术得到的语音音频所提取的特征将被推离该中心。在一批量训练数据中,包含了N个语音样本,xi∈X,对应的标签yi∈{0,1}。这N个语音样本,会通过频域特征和时域特征融合后得到D维度特征,fi表示第i个样本经过融合后的D维度特征。单中心损失的计算公式为:

式中:Mgenuine为在一批量数据中真实的音频特征与单中心C之间的平均欧式距离;Mfake为一个批量数据中合成语音特征与单中心C之间的平均欧式距离;Ωfake和Ωgenuine分别为批量数据中虚假音频的集合和批量数据中真实音频的集合。单中心损失使得提取的真实音频聚焦在单中心C中,同时也使得提取的假音频特征最大限度地远离单中心C。
最后将融合后的特征输入到单中心损失中,由于融合后特征经过全连接层再结合交叉熵损失,因此整个损失函数部分包含了单中心损失和交叉熵损失,其表达式为:

式中:Lsoftmax为二分类损失;Ltotal为总的损失;λ为损失函数的平衡系数,设定为0.05。
2 实验对比
实验数据集为ASVspoof2019 中的LA[12]数据集,该数据集包含了3 个部分,分别为训练集、验证集、测试集。虚假音频采用了不同的语音合成技术和声音转换技术,使用指标串联检测代价函数(Tandem Detection Cost Function,t-DCF)[13-14]和等错误率(Equal Error Rate,EER)[15]作为衡量指标,两种指标均是越小代表性能越好。
实验中,本文选用了LFCC 特征结合混合高斯模型(Gaussian Mixture Model,GMM)的LFCCGMM[16]方案,以及与本文一致的特征前端提取方法Rawnet2[17]作为对比。实验结果如表1 所示,表中加粗的方法是本文提出的试验方案,其中GAT表示采用基于图注意力的网络、BCE 表示损失函数中采用了二分类交叉熵损失、FS 表示采用随机遮挡的数据增强方式、BS 表示采用增加背景噪声的数据增强方式、HPF 表示采用高通滤波的数据增强方式、SCL[11]表示单中心损失。

表1 实验结果
通过对比实验可知,基于图注意力网络结构,结合3 种数据增强、单中心损失函数,以及二分类交叉熵损失的方案实现了最佳的效果。对比基准方法LFCC+GMM[16],该方案在EER 指标上低1.66,在t-DCF 指标上低0.044。
3 结语
本文通过端到端的形式直接对原始语音进行鉴伪,利用提取的高层次特征,在基于图注意力的基础上,分别得到频域特征和时域特征,经过特征融合后,结合单中心损失以及二分类交叉熵损失,同时在原始语音数据上,新增3 种数据增强的组合。相较于其他方案,所提方案在ASVspoof2019 中的LA 数据集上实现了更好的指标。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
甘肃教育(2020年22期)2020-04-13
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
电子制作(2017年9期)2017-04-17
第二课堂(课外活动版)(2016年2期)2016-10-21
人间(2015年8期)2016-01-09
