
协同移动边缘计算分层资源配置机制
2022-08-24 06:30王界钦林士飏彭世明贾硕杨苗会
计算机应用 2022年8期
王界钦,林士飏,彭世明,贾硕,杨苗会
(山东理工大学交通与车辆工程学院,山东淄博 255000)
0 引言
智能交通系统(Intelligent Transportation System,ITS)的三层式架构,利用道路感知器侦测交通流量信息后,通过网络将信息上传至云中心进行运算,再依据运算的结果进行支配决策,以提升交通安全水平。随着生活质量的不断提高,汽车的各类云端增值业务(车载视频、语音播报、卫星定位等)与应用服务(智能导航、自动驾驶等)也在不断扩展,增加了传输数据量与计算量。因此,伴随车联网行业的发展以及ITS 的需求,云中心的大数据处理面临成本高、传输性能差、即时性能低等诸多挑战。移动边缘计算(Mobile Edge Computing,MEC)服务器布置在移动网络边缘能减轻云中心计算负担,例如构建ITS 的MEC 分散式应用服务,以边缘云的计算能力完成车联网所需要的大量运算任务,减少车载端的运算时间。
考虑到MEC 服务器计算资源的有限性、网络负载分布的非均衡性,本文提出了一种MEC 分层协同资源配置机制(Hierarchical Resource Allocation Mechanism of cooperative MEC,HRAM)。主要工作如下:
1)提出一种MEC 分层协同资源配置方案,实现多跳内的MEC 服务器计算资源共享;针对负载过大的MEC 服务器,能够减缓计算压力,加速卸载任务响应,高效利用有限的计算资源。
2)提出基于层次分析法的目标节点选择策略,综合考虑服务能力、响应时间、车流密度、方向一致性四项要素,统筹决策卸载任务的目标MEC 服务器。
3)提出动态权值任务路由策略,考虑同一转发路径下,多个卸载任务间的影响、资源竞争,通过动态调整路径权值,以避免重复路径的多次选择,调用整体网络的通信能力,有效减少时延。
1 相关研究
为解决MEC 服务器资源分配问题,文献[1]中提出一种新的整数规划(Integer Programming,IP)和JOR-MEC(Joint Offloading and Resource allocation-MEC)算法,并通过仿真证实算法能降低MEC 服务器的平均能耗。文献[2]中,作者将计算任务分解,提出一种在线任务卸载算法,将最优卸载到云中心与启发式负载平衡卸载到云中心分别用于顺序任务和并行任务。
近几年来,深度强化学习(Deep Reinforcement Learning,DRL)和机器学习(Machine Learning,ML)在MEC 服务器任务卸载和资源分配上大放光彩。文献[3]采用深度强化学习、考虑移动用户设备(User Equipment,UE)在基站间的移动性,提出了一种MEC 环境下自适应任务卸载和资源分配算法。对比其他算法,在减少任务平均响应时间和系统总能耗,提高系统效用方面表现最佳,满足用户和服务提供商的利益。与文献[3]相似,文献[4]基于深度Q 网络(Deep-Q Network,DQN)提出了一种MEC 任务卸载和资源分配算法——联合任务卸载决策和带宽分配优化,最小化能耗成本、计算成本和延迟成本的算法,将非凸优化问题转化为强化学习问题,采用DQN 找寻最优解。文献[5]基于深度强化学习和联邦学习(Federated Learning,FL)提出了一种智能资源配置模型,以解决在多变MEC 环境中网络资源和计算资源合理分配的问题,仿真显示,该模型在最小化系统平均能量消耗、最小化平均服务延迟、均衡资源分配方面有显著表现。文献[6]提出利用工业物联网进行资源分配的强化学习(Reinforcement Learning,RL)解决方案。基于动态规划和多目标蚁群优化算法,解决终端用户间资源精确分配问题。为了实现MEC 服务器更高的能源效率和更好的用户体验,最大化上行通信中卸载任务数量,同时保证MEC 服务器的计算资源在一个可接受的水平,文献[7]指出基于深度神经网络(Deep Neural Network,DNN)的联合边缘设备的任务协同运作是降低延迟的有效方法,提出动态资源分配优化方案,自动选择最佳分区点以最小化所有车辆的整体延迟。为了进一步降低系统开销,文献[8]提出V2X(Vehicle-to-X)的卸载和资源分配问题,并给出最优卸载决策、传输功率控制、子信道分配和计算资源分配方案。首先采用层次分析法选择初始卸载节点,然后采用无状态Q 学习法对传输功率、子信道和计算资源进行分配。
随着无线能量传输技术的发展,无线电和MEC 计算资源的联合分配备受关注。文献[9]研究具有多个能量收集装置的MEC 系统中无线电和计算资源分配的新方法,提出时间平均计算速率最大化(Time Average Computation Rate Maximization.TACRM)算法,动态决策每个时间块内无线设备的最优带宽、发送功率、时间分配和本地CPU 频率,通过大量仿真实验说明TACRM 算法能够有效提高系统的数据处理速度。而文献[10]在多用户场景下联合考虑计算资源、无线电资源以及数据安全,以最小化整个系统的时间和能耗为目标,提出具有数据安全的多用户资源分配和计算卸载模型,对比局部执行和完全卸载方案,能够显著提高整个系统的性能。文献[11]考虑一种具有双天线混合接入点(Hybrid Access Point,HAP)和单天线移动装置的无线移动边缘计算系统(Wireless Powered Mobile Edge Computing,WP-MEC),用于能量传输和数据传输;针对系统平均计算速率最大化问题,提出在线服务速率最大化(Online Service Rate Maximization,OSRM)算法。
文献[12]提出一种高效、低复杂度的启发式算法,以较低的时间成本提供接近最佳的解决方案,并给出最优传输功率与MEC 服务器计算资源的关系;结果表明,在不同场景下,所提方案能实现更高的任务成功卸载次数。文献[13]针对5G 通信网络难以完成密集任务的问题,提出5G 边缘计算中基于多用户网络系统模型的计算密集型任务处理模式,包括本地计算、雾节点计算和边缘节点计算三种计算模式,将任务的卸载问题转化为时延和能耗联合优化问题,用户设备可根据计算任务的特点和系统状态选择处理计算任务的最佳方式,并通过仿真验证方案在减少时延和能耗、提高任务处理效率和终端用户体验上的优势。文献[14]为了实现用户能源效率最大化,提出多用户多MEC 服务器任务卸载模型,在仿真分析下,该模型可以减少单链路通信的压力,保证用户体验和网络性能,还能减少链路信令开销。
虽然目前的相关研究从多方面着手解决车联网中MEC服务器任务卸载和资源分配问题,但并未考虑众多MEC 服务器间的协同以及合理分配问题,且不同方案的应用场景各有不同。本文聚焦车联网在5G 环境下多车辆、多任务构成的MEC 通信小区组成的复合MEC 系统场景。考虑MEC 服务器服务能力有限、负载差异大,同时为了能够更好地满足车辆的服务需求,提出一种移动边缘计算分层协同资源配置方案。当本地端MEC 服务器因忙碌而无法满足多余卸载任务的计算需求时,通过层次分析法进行多因素综合考虑,从候选端中挑选合适的目标节点,让多余的卸载任务分配到适当的MEC 服务器进行运算,再借由动态权值任务路由,达到合理分配与有效利用MEC 服务器的运算资源,减少不同MEC 服务器之间的数据多跳转发时延,优化卸载任务请求时延的目标。
2 系统模型
2.1 场景描述
图1 为本文交通仿真场景。道路设施单元(Road Side Unit,RSU)部署在道路交接处,相邻RSU 的覆盖区域不重叠,且每个RSU 均配备MEC 服务器,形成独立的通信小区。车辆单元(Vehicle Unit,VU)行驶过程中因自动驾驶不断与周边环境进行交互,产生大量计算任务,而大多数任务具备一定的时效性,车载终端计算能力有限,难以满足众多任务的需求,因此考虑将任务卸载到MEC 服务器上处理,分流上载云端所需的数据至云中心,最后将计算结果返回至车辆单元。
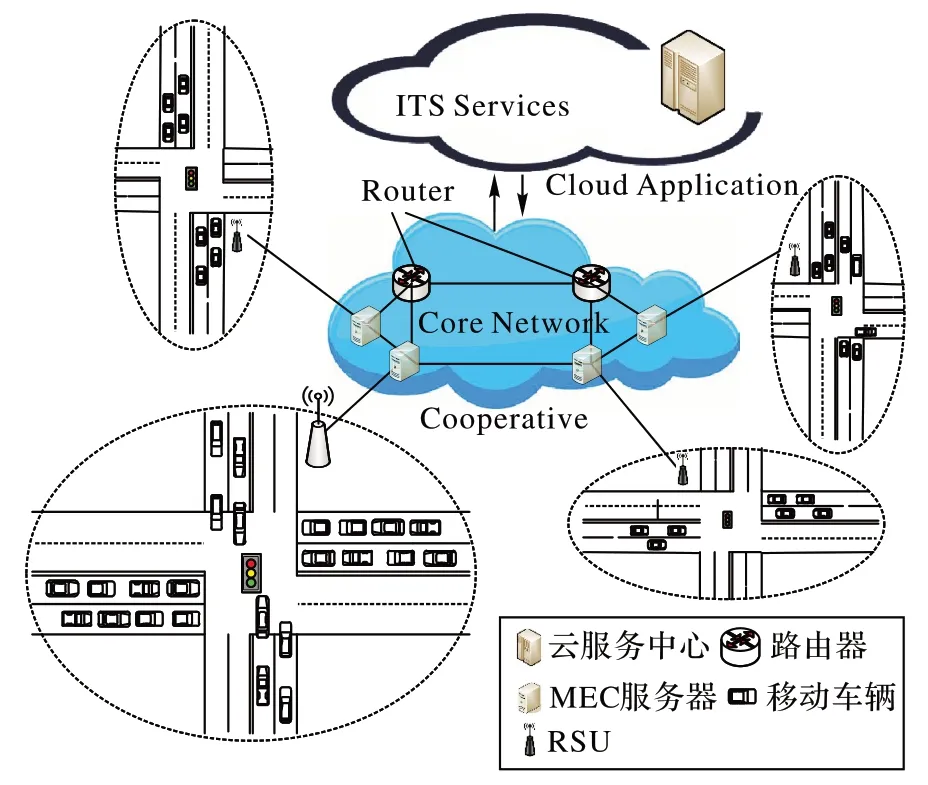
图1 交通情景Fig.1 Traffic scenario
本文将请求任务卸载的车辆单元表示为集合VUs={VU1,VU2,…,VUi}。每个车辆单元有一个或多个卸载任务,所有任务不可切分、相互独立、互不影响,用集合TASKj={Task1,Task2,…,Taskj}表示。卸载任务的属性描述为一个三元组Taski,j={RTL,size,Tmax}。其中,Taski,j表示第i个车辆单元的第j个任务,RTL表示卸载任务的所属车辆实时位置,size表示卸载任务的数据量,Tmax表示卸载任务最大可容忍时延。
通信小区中所属的MEC 服务器称为本地MEC 服务器,即本地端LN(Local Node),重点研究本地端移动车辆的任务卸载策略。定义其他通信小区所属MEC 服务器为候选端(Candidate Node,CN),并根据MEC 服务器间信息传递次数(层数)n,定义集合CN={MEC1,1,MEC1,2,…MECn,m},其中n∈Nhop,m表示n层的MEC 服务器编号。
RSU 作为车辆单元和MEC 服务器之间传输数据的媒介,除传输请求任务封包和返回数据外,还需定期收集车辆单元的信息(如:实时位置RTLi、车速vi、车辆任务)、检测通信小区的车流密度MEC 服务器周期性地交换本地/邻近服务器的相关信息,实现数据共享。现对数据信息进行分类定义:
定义1本地信息流(Local Stream,LS)。
在一个通信小区内,MEC 服务器位置信息、空闲服务能力、RSU 采集的车辆单元信息为本文研究的基础信息,能直观体现通信小区状态,定期更新、存储于本地端,是不同通信小区信息交流的重要信息。简记为本地信息流。
定义2邻居节点信息流(Neighbors Stream,NS)。
不同通信小区间需要周期性地交换数据,即MEC 服务器发送/接收Nhop 范围内的LS,建立、维护邻居数据表。对接收端而言,所有接收的LS 均非描述本端状态的信息,因此,定义该类信息流为邻居节点信息流。
定义3卸载转移信息流(Upload Transfer Stream,UTS)。
当本地端未能满足卸载任务的服务需求时,卸载任务需要转移。本地端首先根据选择策略,确定候选端中合适的MEC 服务器作为目标节点;随后,本地端根据给定的目标节点,结合路由策略确定转发节点、转发路径。该类计算数据及卸载任务所属车辆信息描述了任务的整体状态,在本地端、转发节点、目标节点间进行传输,为便于后文描述,定义为卸载转移信息流。
2.2 通信模型
在本模型中,车辆单元的卸载任务需要从车载端通过无线信道传输到RSU,再上载至本地MEC 服务器。同一通信小区内,RSU 通常位于MEC 服务器附近,因此忽略RSU 到MEC 服务器的通信时延[15]。载波聚合(Carrier Aggregation,CA)作为5G 增强技术之一,聚合多个载波单元进行传输,从而大幅度提高上下行传输性能,以满足5G 车联网的通信需求。根据3GPP(3rd Generation Partnership Project)协议TS38.306 规范,对于5G 新空口(New Radio,NR)技术,计算给定的频带载波近似聚合速率VCA[16]为:
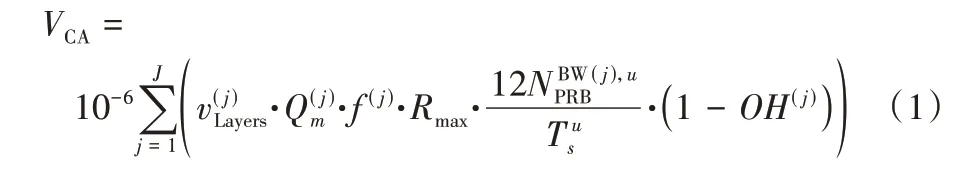
各参数说明如表1 所示。

表1 参数名及意义说明Tab.1 Parameter names and meanings
移动用户的空口速率一般按上、下行分开测试和表示,表示为数据的吞吐量。5G NR 峰值数据吞吐速率受网络对上下行时隙的分配比例、网络环境、用户数、网络侧和终端侧的能力等因素影响。本文把VUs 的上行传输速率以5G NR Uu 接口的速度计算,采用频率范围为FR1,根据基础配置下终端数据理论吞吐率,确定上行传输速率Vuplink的范围在309.1 Mb/s~618.1 Mb/s。由于本文考虑的卸载任务为计算密集型任务,输出相较于输入非常小,因此本文不考虑从MEC 服务器返回VUs 的下行传输时延[17]。
2.3 执行方式决策模型
在一个周期内,VUs 的卸载任务由车载端依次上载至本地端,受本地端有限服务能力约束,不能满足所有卸载任务的时延要求,本地端需决策任务执行方式,令typei,j∈{0,1}。当typei,j=0 时,表示Taski,j将在本地端执行;反之,Taski,j将转移至候选端执行。
为了能充分利用本地端的计算资源,同时满足卸载任务最大可容忍时延,提出找寻本地端临界服务状态的方案,明确卸载任务的执行方式。
执行方式决策算法的伪代码如算法1 所示。车载端首先上载所有卸载任务至本地端,按从小到大的顺序存储于本地端中,并以数据大小为索引,存储任务来源及具体编号。默认所有任务执行方式为候选端执行,即初始化数组type=1。本地端可提供的服务能力将由所有分配至本地端的卸载任务均分,分配值Nloc由1 开始迭代,直至分配任务中存在任务的处理时间与上行时间之和超出最大任务响应时间,或者分配值迭代至卸载任务总数Numtotal,此时可以确定于本地端执行的卸载任务数Nloc-1,数组type(1)~type(Nloc-1)更新为0,从而确定了本地端与候选端各需执行的任务。按照任务大小进行排序,使计算量高的任务被分配到计算能力更好的候选端上,减少时延;而本地端有限的服务能力也能够在保证时延的前提下被轻量级任务合理利用。
算法1 执行方式决策算法。


2.4 计算模型
本文在进行任务卸载计算时主要考虑到处理时延(processing delay)、传输(发送)时延(transmission delay)和传播时延(propagation delay)。
2.4.1 本地端计算
当卸载任务Taski,j确定在本地端执行时,卸载任务的时延主要包括传输时延和处理时延。令表示本地端可以提供的计算能力(CPU 周期数),per表示单位bit 所需CPU 周期数,则Taski,j由车载端上载至本地端的传输时延在本地端的处理时延分别为:

2.4.2 候选端计算
当卸载任务Taski,j确定转移到候选端执行时,卸载任务的时延主要包括传输时延、传播时延和处理时延。由本地端发送卸载任务的传输时延为:

由本地端到目标节点MECtarget的传播时延为:

卸载任务Taski,j在目标节点上的处理时延为:

其中:rdata表示数据发送速率;d1,m表示当目标节点处于1 hop时,本地端与编号为m的目标节点之间的通信链路距离;rf表示传播速度;Δdu-1表示当目标节点处于nhop 时,目标节点与转发节点之间、转发节点与转发节点之间的通信链路距离表示目标节点执行卸载任务Taski,j所分配的计算能力(以CPU 周期数表示)。
3 目标节点选择与路由
3.1 基于层次分析法的目标节点选择策略
本地端周期性接收NS 维护邻居数据表,以保证数据信息的时效性,为目标节点选择提供基础。对typei,j=1 的卸载任务,本文利用层次分析法(Analytic Hierarchy Process,AHP)选择较为合适的目标节点,根据多因素的权重系数,确定候选端的优先级(preference)。层次分析法是一个多标准决策(Multiple Criteria Decision Making,MCDM)/多属性决策(Multiple Attribute Decision Making,MADM)模型,包括目标层、准则层和方案层,应用于诸多领域,是一种合理解决优先级调度的手段[17]。
本文主要考虑候选端状态以及移动车辆信息,整理为四项影响因素,建立层次结构模型如图2 所示。下面详细分析所选影响因素。

图2 层次分析法结构模型Fig.2 Analytic hierarchy process structure model
3.1.1 服务能力
受交通流量在时间和空间上的不均匀分布影响,不同通信小区的服务压力不尽相同。本文的研究目的之一就是要降低通信小区间的服务压力,减少资源浪费和非必要时延,因此候选端的服务能力是选择目标节点的重要因素之一。本文以候选端CPU 的负载率表示服务能力,记为。
3.1.2 响应时间
在本文研究中,决定卸载任务是否在不超出Tmax的条件下完成的主要依据是:卸载任务的响应时间是否满足Tmax,即满足条件:
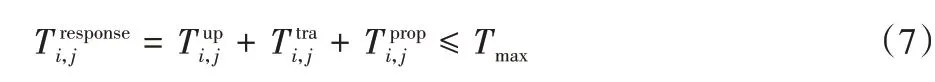
3.1.3 车流密度
候选端中,对于车流密度较小的通信小区,其对应的MEC 服务器服务压力较低;反之,对于车流密度较大的通信小区,对应的MEC 服务器服务压力较大,甚至会“溢出”。车流密度会间接影响候选端的服务能力,可作为考量因素之一,记为
3.1.4 方向一致性

3.1.5 权重分析
为了确定目标节点,需要确定影响因素两两之间的尺度关系。对卸载任务而言,保证时效性具有重要意义,甚至影响车辆行驶安全。因此,在本文层次分析模型中,响应时间最重要,服务能力因影响卸载任务的执行时间而间接影响响应时间,重要程度次之,车流密度比方向一致性重要,构造层次分析判断矩阵其中:
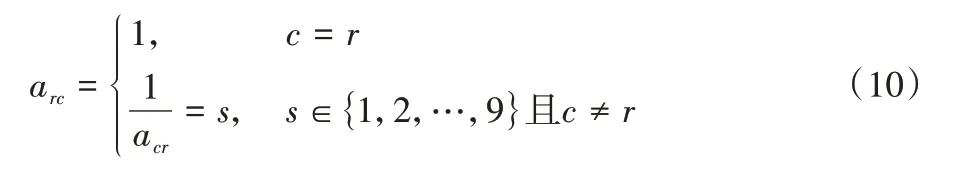
其中:c为任务数量;r为车辆数量;s为该项分数。接着构建判断矩阵见表2。
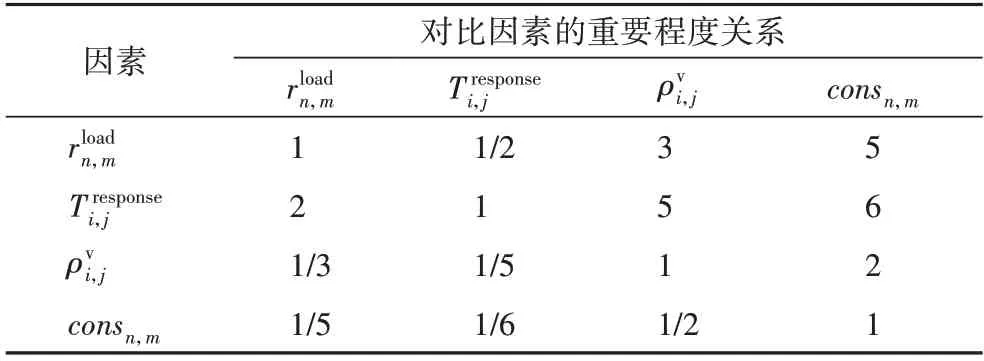
表2 判断矩阵Tab.2 Judgment matrix
根据构造的判断矩阵计算最大特征值λmax,求出对应的归一化特征向量,即四项因素的指标权重Δ如下:

权重的分配的合理性需通过一致性检验。见式(12):

其中:CI表示一致性指标。RI表示平均一致性指标(4 阶矩阵为0.90)。CR表示判断矩阵的随机一致性比率,当CR<0.1 时,判定判断矩阵A具有满意的一致性;否则需要调整判断矩阵A直至满意的一致性为止。计算显示,CR值小于0.1,满足一致性检验要求,确定权重可信。
在进行数据分析之前,通常需要对数据进行标准化处理(normalization),本文选用z-score 标准化方法,基于均值和标准差对所有卸载任务构成的基础数据集BD=进行标准化处理,如式(13)所示:

其中:Zk∈[0,1],表示第k个因素的标准化结果;Mk表示第k个因素样本均值;σk表示第k个因素样本标准差;BD(k)为基础数据集BD中的第k个元素值。
最终,以标准化后的各因素与对应权重的乘积和作为目标节点的选择依据。卸载任务Taski,j选择目标节点MECtarget见式(14):

3.2 动态权值任务路由策略
本节的主要工作是确定卸载任务Taski,j的转发路径,特别是当目标节点在多层(如2 hop、3 hop、…)时,途经的MEC服务器节点,即转发节点。
Dijkstra 算法[18]作为典型的单源最短路径算法之一,常用于求解给定起始节点、目标节点之间路径的最优解问题;基本原理是基于广度优先搜索(Breadth First Search)思想,以起始节点S为中心向外层层延伸,直至到达目标节点O。该算法总能求出给定S、O之间的最短路径最优解。对于通信网络来说,找寻请求端到服务端之间的最小时延能够减少数据的响应时间,更好地保证时效性。对于单个卸载任务来说,应用Dijkstra 算法能够找到卸载任务从本地端转发至目标节点的最短响应时间;但本文研究为多个卸载任务同时卸载至多个目标节点,传统Dijkstra 算法并不适用,因此,本文基于Dijkstra 算法面向单起始节点、多卸载任务、多目标节点提出一种动态权值任务路由策略。
顶点集合V={LN,CN}={v0,v1,1,v1,2,…,vn,m};

对于不同的卸载任务,其数据大小存在差异。由式(15)可知,对同一有向边,权值会随卸载任务大小的改变而改变;同时,在同一周期内存在多个卸载任务由本地端转发至多个目标节点,虽然可以应用Dijkstra 算法,将多个卸载任务独立化处理,转化为多次的单起始节点、单卸载任务、单目标节点问题,以确定最优转发路径。然而,根据其原理分析,同一转发节点、同一转发路径会被多次重复选择,资源竞争不可避免,因而卸载任务间的影响不可忽略,传统Dijkstra 算法并不适用。
在本节的研究中规定:转发节点的转发能力、同一路径节点间的传播能力会被途经该转发节点、该路径的卸载任务均分,使得有向边的权值增大,以降低同一转发路径多次选取的频率。式(15)变更为:
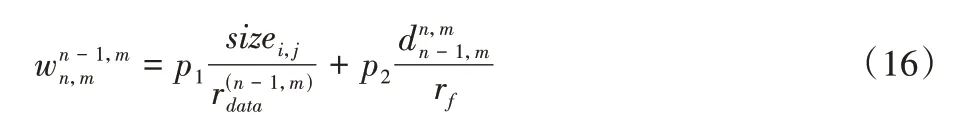
其中:p1表示途经转发节点vn-1,m的卸载任务数;p2表示途经节点vn-1,m、vn,m通信链路的卸载任务数。
本节所提面向动态权值任务转发策略如算法2 所示。首先构建本地端、候选端的邻接矩阵,并将算法1 求得转移卸载任务编号倒序,即按由大至小的顺序对卸载任务进行转发路径选择,使计算量高的任务被分配到发送时延和转发时延较低的转发节点,以缩小卸载任务间的时延差距。然后基于Dijkstra 算法思想,根据卸载任务顺序以及基于AHP 确定的对应目标节点得到转发节点。但不同任务因大小及执行顺序的不同,邻接矩阵会随之改变,因此在分配任务b的转发节点前,都应由式(16)确定独有的邻接矩阵。
算法2 动态权值任务路由策略。
输入CN及相对计算资源fc、Tmax、per、size、w、LN、MECtarget,转移的卸载任务数Numtransfer及任务编号。
输出卸载任务的转发节点Nodes。

由算法2 可得到所有转移卸载任务选择的转发节点,将转发节点依序相连即构成转发路径。
综上,HRAM 算法示意图如图3 所示。

图3 HRAM算法示意图Fig.3 Schematic diagram of HARM algorithm
4 仿真实验及性能分析
4.1 实验环境
本文的仿真实验是在内存为12 GB、处理器为Intel Core i5-6300HQ,频率为2.30 GHz,Windows 10 操作系统下进行,仿真工具为Matlab R2019b,实验的具体参数配置见表3。
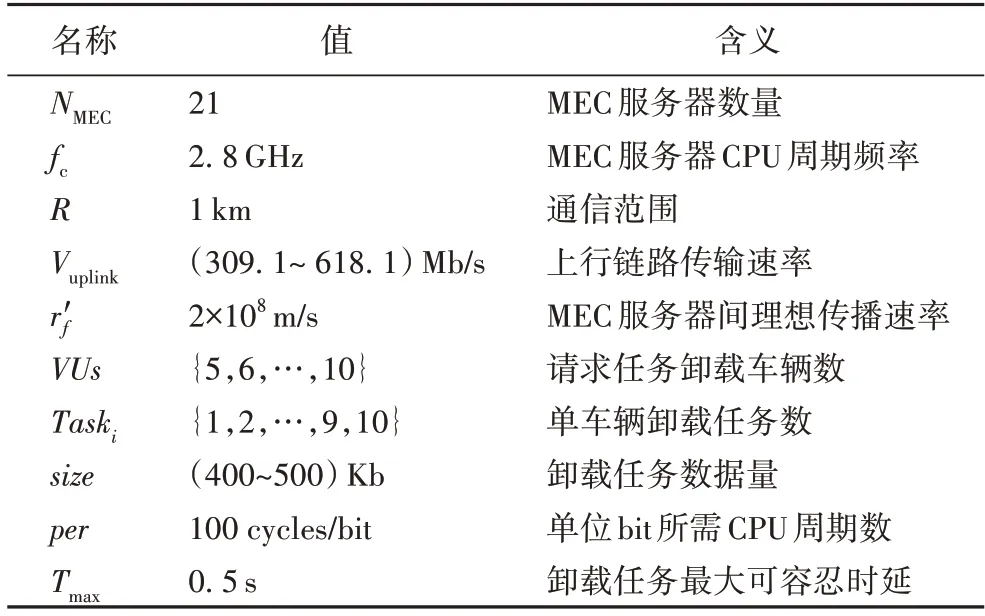
表3 参数配置Tab.3 Parameter configuration
本文以三层式(N=3 hop)为例,仿真验证本文方案。除本地端外,按照4、8、8 的结构方式分三层放置MEC 服务器,作为候选端,如图4 所示。

图4 MEC服务器部署示意图Fig.4 Schematic diagram of MEC server deployment
4.2 对比算法
为了验证本文提出的HRAM 算法的性能,下面与其他算法进行分析比较。
RATOS 算法:任务卸载单层式(1 hop)资源分配(Resource Allocation of Task Offloading in Single-hop)算法。该算法的处理思想是仅考虑近端1 hop 通信范围内的MEC 服务器,将计算资源均匀分配给所有的卸载任务。
RATOM 算法:任务卸载多层式(Nhop)资源分配(Resource Allocation of Task Offloading in Multi-hop)算法。该算法考虑Nhop 通信范围内的MEC 服务器,根据计算资源量,按比例分配卸载任务,以最小化任务计算时间为目标,转发路径规则遵循Dijkstra 算法。
4.3 复杂度分析
算法复杂度是衡量算法运行效率的标尺,质量的优劣会影响到算法甚至程序效率。考虑最坏情况,对于算法1 而言,步骤7)~15)的循环次数取决于Nloc的值,当Nloc=Numlocalmax+1 循环结束;随着Nloc的迭代,内嵌for 循环、确定最大任务响应时间的执行次数均取决于Nloc。因此,在忽略常量、低次幂和最高次幂的系数后,计算得出算法1 的时间复杂度为,主要取决于本地端承载的最大卸载任务数。
同样,对算法2 而言,步骤5)~8)的执行次数为r;步骤10)~22)的执行次数取决于Numtransfer,并且随着Numtransfer的迭代,内嵌while 循环的执行次数为r,伴随每次pb数组的求和,存储、更新最短路径和确定最小权值的执行次数均为r。因此,算法2 的时间复杂度为O(r2×Numtransfer),主要取决于转移任务数、服务节点数;为了能够找到最适转发路径,执行过程中时间成本会随服务节点相较于本地端的层次分布(hop 的增加)成倍数增长,因此,算法2 的时间复杂度实际会受到转移任务数量、服务节点数以及hop 的影响,候选端应限制在合理hop 内。
4.4 逻辑分析
参考图3,对于算法1 执行方式决策算法,当存在任务的响应时间超出Tmax时,确定本地端的可承载的最大任务数为Nloc-1,此时对于按由小到大顺序排列的任务来说,前Nloc-1 个任务将分配给本地端执行,其他任务则择优选择目标节点执行。算法2 中,任务会遍历所有从本地端连通至目标节点的所有路径,如v1,1—v2,1—…—vm,1、v1,2—v2,2—…—vm,2、…、v1,n—v2,n—…—vm,n,计算每条路径的权值和,选择权值和最小的路径作为该任务的转发路径,其他路径舍弃,并且根据式(16)更新有向图权值。
4.5 实验结果及分析
对于多个卸载任务选择同一目标节点的情况,本文以实例说明。如图5 所示,有编号为1、2 的卸载任务需从本地端v0转发至目标节点v3,1,数据封包大小分别为425 Kb、475 Kb。首先,根据任务1 的数据封包大小计算出任务1 从本地端v0到目标节点v3,1之间所有有向边的权值,如图5(a)所示,确定最优转发路径为v0—v1,2—v2,2—v3,1。对比图5(a)、(c)并结合式(15)可知,对不同大小的卸载任务而言,最优转发路径始终唯一,为v0—v1,2—v2,2—v3,1,这显然是不合理的,因为当有足够多的卸载任务途经同一转发路径,会造成转发节点发送饱和,卸载任务之间竞争资源。对比图5(a)、(b),确定任务1 的转发路径后,为降低再次选择的可能性,更新转发路径途经v0—v1,2—v2,2—v3,1的有向边权重。观察图5(b)、(c)、(d),受任务1 转发路径选择以及任务数据封包大小变化的影响,图(d)中有向边权值发生变化,任务2 的最优转发路径更新为v0—v1,1—v2,1—v3,1。由此可见,本文提出的动态权值任务路由策略降低单一通信线路重复选择的概率,有效调用整体网络的通信能力,而非固定于同一路由,能降低整体网络拥塞(network congestion)。
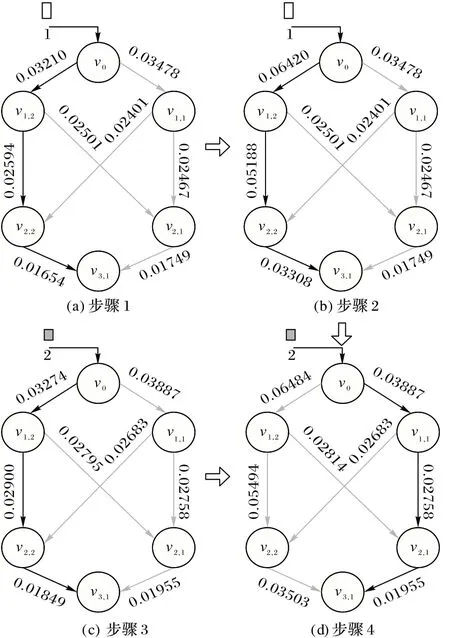
图5 转发路径选择Fig.5 Forwarding path selection
图6 显示控制卸载任务数量(卸载任务数为16)不变,卸载任务平均时延随候选端平均服务能力变化的情况。图6(a)表示在三种算法下,16 个卸载任务在目标节点完成计算的平均处理时延随服务能力的变化。经观察发现,卸载任务的平均处理时延随着服务能力的升高而降低,并且降低的幅度减小。三种算法下卸载任务的平均处理时延也趋于稳定,主要是因为MEC 服务器的计算资源从匮乏到充足,卸载任务间的资源竞争关系减弱。图6(b)表示三种算法下,16 个卸载任务由本地端发送,传输到目标节点经历的平均转发时延。观察发现,RATOS 算法平均转发时延最低,RATOM 算法的平均转发时延最高,这是因为RATOS 算法的目标节点仅为1 hop MEC 服务器,RATOM 算法和HRAM 算法还会选择Nhop 的MEC 服务器作为目标节点,卸载任务需层层发送、传输到目标节点,因而RATOM 算法和HRAM 算法的平均转发时延会高于RATOS 算法;此外,RATOM 算法和HRAM 算法均基于Dijkstra 算法,但HRAM 算法考虑卸载任务间路径选择的相互影响,路径权值会动态变化,降低选择重复转发路径的可能,所以时延低于RATOM 算法。
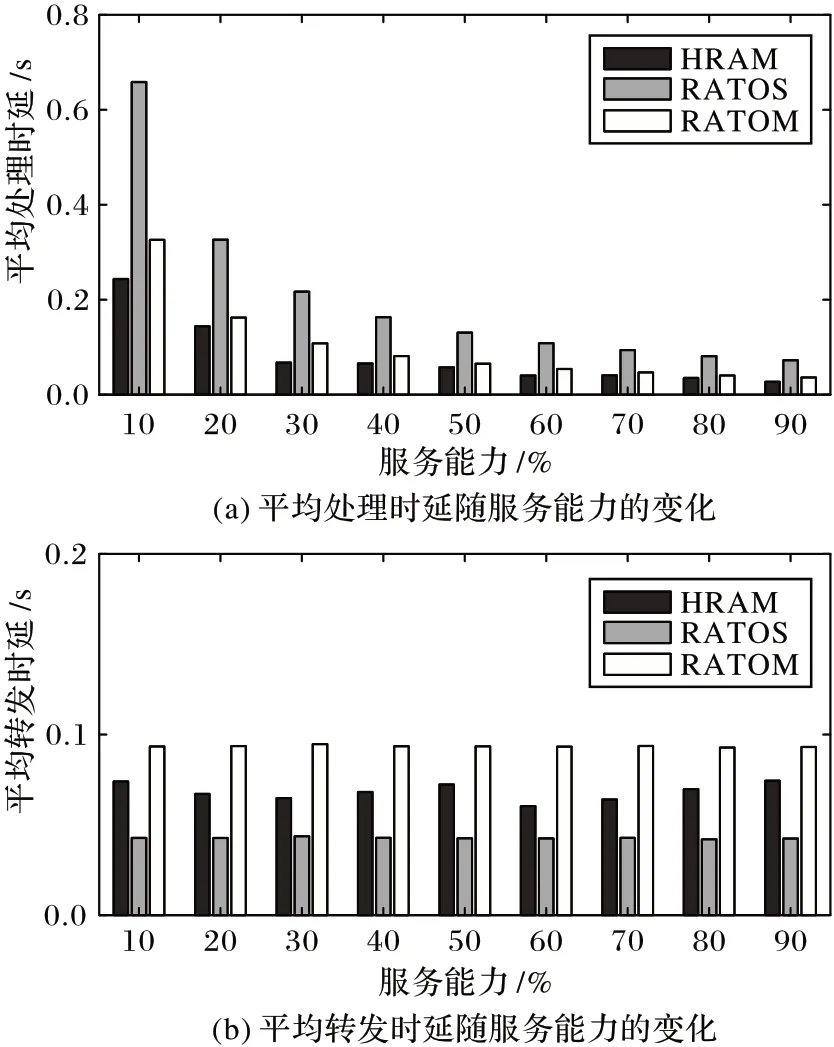
图6 服务能力对卸载任务平均处理时延、转发时延的影响Fig.6 Influence of service capability on average processing delay and forwarding delay of offloading tasks
图7 表示16 个卸载任务在不同算法下,本地端发送UTS到目标节点,完成卸载任务计算的任务请求时延随服务能力的变化曲线。整体来看,随着服务能力的增加,三种算法下卸载任务的请求时延均有降低,并且差异性变小。当MEC服务器的服务能力较低时,RATOS 算法的时延相较于HRAM算法和RATOM 算法的时延较高,因为RATOS 算法仅考虑了1 hop 内的目标节点,服务能力有限,而卸载任务众多,资源竞争大,导致时延明显增高;而HRAM 算法和RATOM 算法在本文实验中考虑了3 hop 及以内的目标节点,可选择目标节点较多,在服务能力有限的情况下,能明显缩短任务请求时延。实验结果表明,HRAM 能够更加充分使用MEC 服务器的服务能力,实现高效响应任务请求。当服务能力达到60%左右时,RATOS 算法逐渐优于RATOM 算法。通过对比分析图6 发现,造成该现象的原因是:随着MEC 服务器服务能力的增加,不同算法下卸载任务的处理时延愈发接近,但RATOS 算法和RATOM 算法的平均转发时延保持稳定,从而造成RATOS 算法在充足MEC 服务器服务能力下,相较于RATOM 算法有较低的时延。HRAM 算法在不同服务能力下始终保持最低的卸载任务请求时延,究其原因,与RATOS 算法相比,HRAM 算法考虑更多的候选端,在目标节点选择上更具优势;与RATOM 算法相比,HRAM 算法考虑卸载任务间的影响,尽可能规避重复转发路径,使其具有更低的平均请求时延。本实验中HRAM 算法相较于RATOS 算法降低40.16%的任务请求时延,相较于RATOM 算法降低19.01%的任务请求时延。实验证实了HRAM 算法在降低任务请求时延上具有一定的优势。
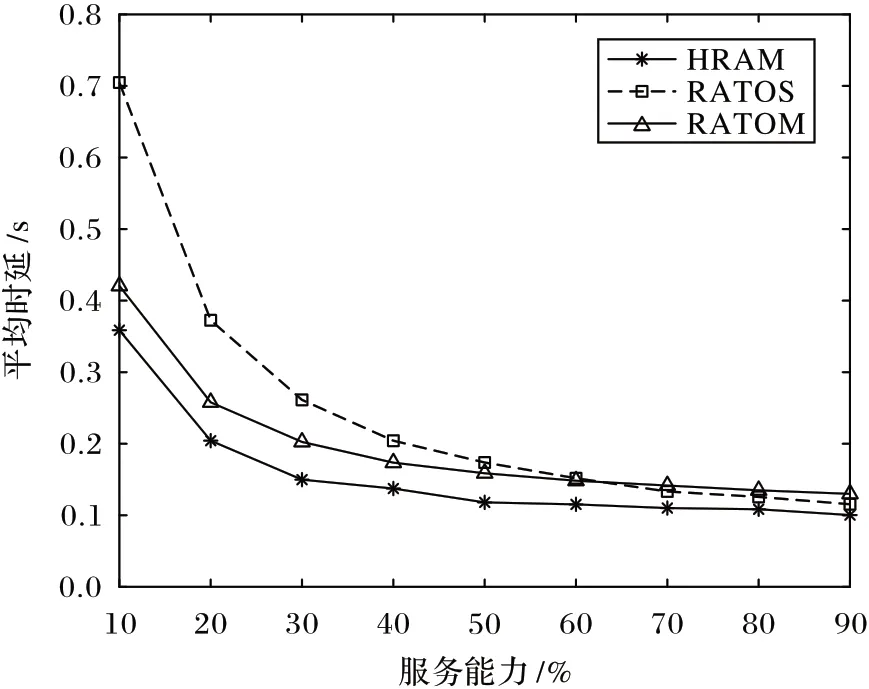
图7 服务能力对卸载任务平均时延的影响Fig.7 Influence of service capability on average delay of offloading tasks
图8 显示在不同算法下,卸载请求的总时延随卸载任务数量变化的关系曲线。从整体来看,三种算法的总时延与卸载任务呈正相关;同时,增长速度有明显提高。RATOS 算法的总时延变化最大,主要是由于仿真环境中1 hop 的MEC 服务器所能提供的计算资源有限,随卸载任务的增多会出现不能及时响应的现象,卸载任务需要排队执行,使得卸载请求的总时延大幅增加;HRAM 算法的总时延变化最小,主要原因是调整路径权值,避免转发节点多次重复选择的现象。节点的发送速率固定,多次重复选择会造成数据发送不及时、数据拥塞;同时,多个任务于同一路线同时转发,会共享传播速度,增加传播时延,这也是HRAM 算法与RATOM 算法随着卸载任务数量增加,总时延差距增大的主要原因。

图8 卸载任务请求总时延Fig.8 Total delay of offloading task requests
本文以卸载任务的时效性作为另一个评估算法的指标。将卸载任务的请求时延不超出最大可容忍时延视为卸载成功,卸载成功的卸载任务数占卸载任务总数的比值即为卸载成功率。图9 显示在满足卸载任务最大可容忍时延前提下,不同算法在不同卸载任务总数下的卸载成功率对比。整体来看,三种方案随卸载任务数的增加,卸载成功率均呈现降低趋势。仿真环境中,当卸载任务为30 时,RATOS 算法失效,此时卸载任务的请求时延均超出最大可容忍时延,任务量的需求完全超出1 hop MEC 服务器可提供的服务能力。因为随着卸载任务总数的增加,从本地端向1 hop 目标节点转发卸载任务时,会出现发送饱和;另外,MEC 服务器节点间的传输能力以及目标节点的服务能力均由卸载任务所均分,都会造成卸载任务响应时间的增大,使得卸载成功率降低。对比HRAM 算法和RATOM 算法,HRAM 算法体现出同样有限的服务能力,能够满足更多卸载任务计算需求的优秀性能。究其原因,HRAM 算法中面向动态权值的任务转发策略充分调用整体网络的通信能力,降低重复转发路径的选择可能,较RATOM 算法缩短卸载任务的发送时延和传输时延。
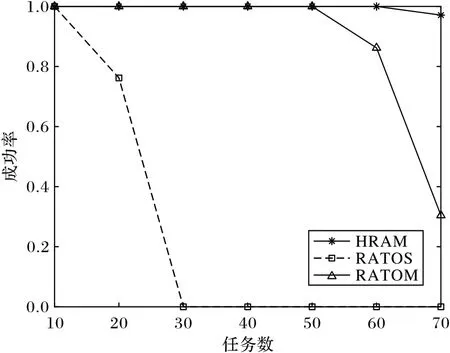
图9 卸载成功率Fig.9 Offloading success rate
5 结语
为了更好地合理分配、有效利用MEC 服务器有限资源,减少数据多跳转发时延,优化卸载任务请求时延,本文提出移动边缘计算分层协同资源配置方案,对本地端无力满足的卸载任务,通过层次分析法,综合考虑多因素,选择合理的MEC 服务器目标节点来完成。
在多层式的目标节点的环境下,基于Dijkstra 算法研发随卸载任务增加动态更新路径权重值算法,优化转发路径,减少多卸载任务、重复转发路径的情況。实验结果表明,HRAMCM 算法在满足任务最大可容忍时延的同时,能够减少卸载任务的请求时延;在有限的服务能力内,能够为更多的卸载任务提供服务。在今后的研究中,将会考虑更加复杂的车联网下MEC 场景。例如:增加同一车辆任务的关联性,扩大MEC 服务器部署规模等。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
电脑知识与技术(2021年22期)2021-09-14
电脑知识与技术(2021年22期)2021-09-14
邮电设计技术(2021年2期)2021-03-13
计算机与数字工程(2019年11期)2019-11-29
花火B(2019年3期)2019-04-27
电子制作(2019年23期)2019-02-23
中国计算机报(2018年12期)2018-10-08
科技视界(2016年1期)2016-03-30
网络与信息(2009年4期)2009-04-26
