
融入时空显著性的高精度视频稳像算法
2022-08-24 06:30尹丽华康亮朱文华
计算机应用 2022年8期
尹丽华,康亮,朱文华
(上海第二工业大学工程训练中心,上海 201209)
0 引言
手机、数码相机等手持设备凭借便携性已成为人们日常拍摄的首选,然而,拍摄的视频不可避免地存在画面抖动的问题,不仅影响视觉效果,而且容易导致误判或漏判。因此,将这些视频信号转化为高质量的稳定视频具有重要的意义。电子稳像技术具有体积小、质量轻、精度高、灵活性强等优势,已经成为当前的研究热点[1-2]。
电子稳像技术的基本思想是通过运动估计获取帧间运动,并通过各种滤波方法(如高斯滤波、卡尔曼滤波、粒子滤波等)平滑相机路径,最后通过反向补偿得到稳定图像[3]。然而,在实际的拍摄场景中,不可避免地会存在各种类型的运动前景(比如行人、车辆等),而运动前景的存在容易混入局部运动分量,降低运动估计的精度,进而影响稳像的精度。因此,剔除运动前景的干扰对进一步提高稳像精度至关重要。目前,主要通过随机抽样一致性(RANdom SAmple Consensus,RANSAC)算法进行多次迭代[4];采用最小二乘法迭代或者采用背景/前景分割技术。例如,邱家涛[5]在稳像算法中结合RANSAC 算法剔除错误匹配点,但是仅能排除部分前景区域对抖动估计的影响,效果不理想。朱娟娟等[6]提出采用基于块的三帧间差分,利用时空一致性快速剔除运动前景区域,但是该算法只利用了时域内的运动特征,不适用大范围场景情况;Liu 等[7]利用子空间约束平滑运动路径,但是单个子空间无法处理包含较大前景运动的视频;谢亚晋等[8]采用基于最小生成树的特征点迭代筛选算法,一定程度上避免了局部运动分量的影响,但是该算法仅利用特征点的距离,剔除效果有限。
后来,杨佳丽等[9]提出结合陀螺仪进行参数估计,并利用李群流形上的卡尔曼滤波进行平滑,但该算法的稳像精度容易受设备精度的限制。Zhao 等[10]提出RTVSM(Robust Traffic Video Stabilization Method assisted by foreground feature trajectories),该算法综合利用了前景和背景的特征轨迹实现视频的稳定,但仅适用于交通场景,对复杂场景的适用性较差。随着深度学习在计算机视觉方面的迅速发展,Wang等[11]提出基于StabNet 神经网络结构的稳像模型,但是该方法需要依赖大量的数据集,而稳像数据的获取仍比较困难。
综上可知,传统稳像算法对简单场景的适用性较好,处理有大范围和多个运动前景的情况时,仍有一定的局限性。目前,视觉显著性技术[12-14]已在计算机视觉任务方面得到了应用,基本思想是利用计算机模拟人眼的视觉注意选择机制,检测图像中密度、颜色、形状等与周围有显著差异的区域,相较于背景区域,运动前景更容易被筛选出来。2006 年Zhai 等[15]提出了LC(Luminance Contrast)模型,在空域和时域内分别求解空间显著图和时间显著图,最后通过融合得到时空显著图,该模型能充分利用空间特征信息和时域运动信息,适合解决在动态场景下的运动目标检测问题。
结合时空显著性在运动目标检测方面的独特优势,本文提出了一种融入时空显著性的高精度视频稳像算法,本文的主要工作体现在:一方面通过时空显著性检测技术识别运动目标;另一方面结合多网格的运动路径进行运动补偿。
1 基本原理
1.1 算法流程
本文算法的主要步骤如下:
步骤1 SURF(Speeded Up Robust Features)特征点提取与匹配。输入不稳定视频后,先对相邻帧提取SURF 特征点;然后,采用BBF(Best Bin First)搜索策略和RANSAC 算法实现特征点由粗到精的匹配[5],得到初始的特征点匹配对集合。
步骤2 显著性目标检测。首先,利用上一步中检测出的SURF 特征点集,生成时间显著图;然后,利用各像素点在图像上的颜色对比度,生成空间显著图;接着,通过融合生成时空显著图;最后,对时空显著图进行二值化和阈值处理,从而识别出运动目标。
步骤3 剔除显著性目标对应的特征点匹配对。根据视觉显著性的检测结果,剔除显著性运动目标所对应的特征点匹配对。
步骤4 网格划分与运动矢量计算。将视频帧划分成M×N的网格,然后计算每个网格所对应的运动矢量。
步骤5 运动轨迹生成。对所有时间点的运动矢量进行累乘,得到每个网格所对应的运动轨迹。
步骤6 多路径平滑。采用多路径平滑策略,实现运动路径的平滑。
步骤7 反向补偿。利用平滑后的路径,对图像进行反向补偿,从而输出稳定视频。
1.2 显著性目标检测
时空显著性目标检测是该稳像算法[15]的核心环节,综合利用特征点的时间和空间对比度信息,提高了运动目标识别的准确率,而剔除运动目标干扰后能提高稳像环节中运动估计的精度,进而影响后续的稳像精度,因此,该算法比传统的稳像算法更有优势。
1.2.1 利用特征点之间的运动对比度,生成时间显著图
鉴于一幅图像中通常包含前景和背景目标,而它们的特征点运动对比度不同。因此,利用基于特征点之间的运动对比度信息的时间显著图,能初步实现前景和背景目标的有效分割,过程如下:
1)采用RANSAC 算法将特征将匹配集合G1划分为不同的内点集,并利用内点集(要求内点集数目≥4)估算出对应的矩阵H。
假设相邻两帧图像中的特征点对为{p,p′},其坐标分别为p(x,y)和p′(x′,y′)。如果特征点对{p,p′}属于内点集,则应满足如下关系:

否则,如果不属于内点集,则特征点p与其他特征点间的运动对比度ε(p,H)定义为:

其中:H=,单应性矩阵H中共包含8 个待求的未知参数a1~a8。
2)计算所有特征点所对应的时间显著值。将特征点p与其他特征点间的运动对比度叠加,得到该特征点的时间显著值SalT(p),公式如下:
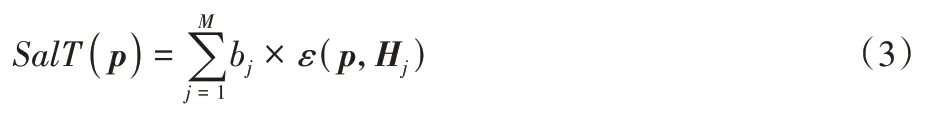
其中:M表示该场景中单应矩阵H的数量;Hj代表第j个单应性矩阵。bj表示由第j个单应性矩阵H包含的内点集所围成的矩形区域占总图像的比例,即:
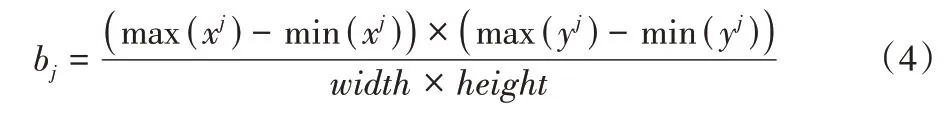
其中:bj∈[0,1];(xj,yj)表示第j个单应性矩阵H所对应的内点集中的坐标位置;width、height分别表示图像宽度和高度。
3)计算图像中非特征点的时间显著值。鉴于同一矩形区域内所有的图像像素应该具有相同的时间显著值,所以将矩形区域内所有特征点的时间显著值的平均作为该矩形区域内像素点的时间显著值,即

其中:SalT(I)表示整个图像I所对应的时间显著值;num表示该矩形区域内包含的特征点总数;k表示特征点的编号;SalT(pk)表示第k个特征点所对应的时间显著值。如果该像素被多个矩形区域覆盖,则为它分配多个时间显著值中的最大值;否则,将它的时间显著值设置为0。
图1 为时间显著图的示例。从图1(b)可以看出:利用时间显著图能较好地识别出运动目标,但是识别的目标不完整,主要因为时间显著图仅利用了相邻帧的运动特征信息。

图1 时间显著图示例Fig.1 Example of temporal saliency map
1.2.2 利用像素点在图像上的颜色对比度,生成空间显著图
图像I中某像素Ik对所应的空间显著值SalS(Ik),等于该像素与所有像素在颜色上的距离之和,将具有相同颜色值an的像素归到一起,则该像素对应的空间显著值为:

其中:fn表示颜色值an在图像中出现的概率;n∈[0,255]。
对于图像帧I,通过计算每个像素的空间显著值即可得整个图像对应的空间显著图SalS(I),即:

图2 为空间显著图的示例。从图2(b)、(c)中可以看出:通过空间显著图可以识别运动目标,但部分非运动目标也会被识别出来,识别准确率有限,主要因为空间显著图只利用了空间的颜色信息,而缺乏运动特征信息。
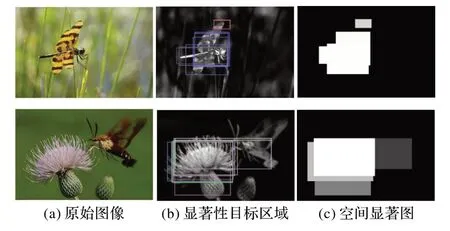
图2 空间显著图示例Fig.2 Example of spatial saliency map
1.2.3 将空间显著图和时间显著图融合,生成时空显著图
将空间显著图和时间显著图进行融合后,得到最终的时空显著图Sal(I):

其中:Max、Median 分别为最大值和中值;Sal(I)为图像帧I的时空显著图。
1.2.4 时空显著图二值化,识别出运动目标所对应的像素点
如果特征点位于运动目标上,则把该特征点对应的匹配对剔除,否则继续保留,并将其用于后续的运动矢量求解。对于特定像素点Pm,判断其时空显著值Sal(Pm)与阈值T的关系,确定该像素点是否为运动目标,即
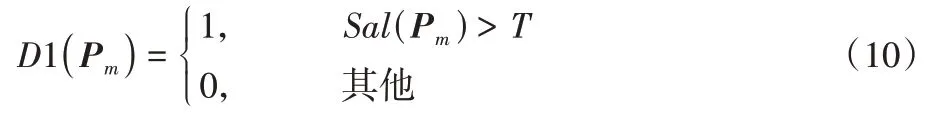
其中:T表示阈值。D1(Pm)表示二值化的结果,如果D1(Pm)为1,则说明该像素点位于运动目标上;否则,说明该像素点位于背景上。
1.3 剔除显著性目标对应的特征点
根据1.2 节中获得的二值化结果,如果特征点Pm位于运动目标上,则将该特征点对应的匹配对剔除;否则将继续保留。最终生成新的匹配对集合G2,并将其用于后续运动矢量求解。
1.4 网格划分与运动矢量的计算
1)利用1.3 节中获得的匹配对集合G2,计算单应性矩阵并将它作为全局的运动矢量,t代表图像的帧号。
2)将视频帧划分为M×N的网格,通常M=N=16,要求遍历每个网格,如果某网格内的特征点匹配对数≥4,则利用该网格中的特征点匹配对,计算该网格对应的局部运动矢量Fi′(t),最终运动矢量Fi(t)即为全局和局部运动矢量的乘积:

其中:i表示网格的编号,i∈[1,M×N]。
3)如果某网格内的特征点匹配对数<4,则最终运动矢量Fi(t)即为全局的运动矢量。
1.5 轨迹生成与多路径平滑
利用1.4 节中得到的每个网格在不同时刻的运动矢量Fi(t),对所有时间点的运动矢量进行累乘,得到每个网格对应的运动路径Ci(t),计算公式如下:

其中:Fi(0),Fi()1,…,Fi(t-1)为第i网格在不同时刻运动矢量。
各网格的原始运动路径C(t),通过最小化目标函数实现路径的平滑,得到最优路径P(t),即
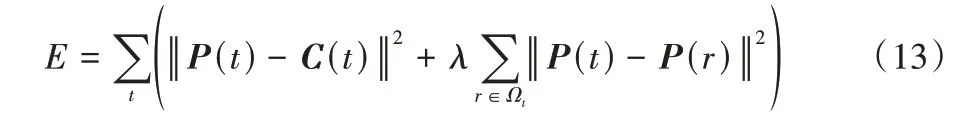
其中:E代表目标函数;λ为学习系数;r表示变量;Ωt表示第t帧的相邻帧。
运动轨迹生成如图3 所示。
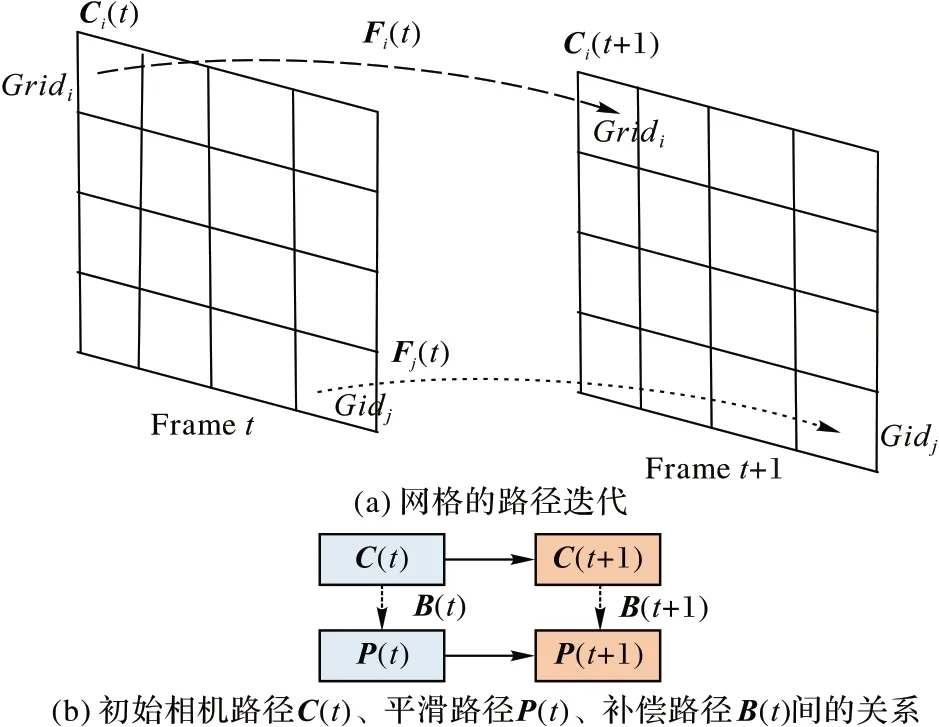
图3 运动轨迹生成Fig.3 Motion trajectory generation
1.6 反向补偿
利用每个网格的最优路径Pi(t)和运动路径Ci(t),计算图像中每个网格单元的补偿量Bi(t),公式如下:
然后,通过补偿量Bi(t)对该网格单元的像素进行反向补偿,得到稳定图像,最终生成稳定的视频。
2 实验与结果分析
2.1 实验环境与稳像评价指标
2.1.1 数据集与实验平台
实验是在Intel Core i5-5200U CPU 2.20 GHz,8 GB 内存,64 位Windows 10 系统上进行,利用Matlab2016a 软件实现算法程序,并结合“ffmpeg”多媒体处理工具对视频/图像数据进行转化,本文的验证实验采用了如下的数据集:
1)数据集1。
Testing Set1 数据集,该自建数据集包含9 个视频序列,其中每个视频序列中都包含前景目标,比如包含移动的车辆或行人等。
2)数据集2。
Testing Set2 数据集[7],该数据集为公共稳像数据集,图像分辨率为640×320,包含了7 种不同的拍摄情况:①Simple类,摄像机的运动比较简单;②Rotation 类,摄像机存在大幅的旋转运动;③Zooming 类,摄像机存在大幅的缩放运动;④Parallax 类,摄像机进行扫描拍摄;⑤Driving 类,利用基于车载摄像机拍摄;⑥Crowd 类,拍摄的场景存在运动前景;⑦Running 类,利用快速前进的摄像机拍摄。
2.1.2 稳像指标
目前常用的评价方法[16]分为:
1)主观评价。主要评估视频序列的展示性效果,视频过渡越平滑,说明视频的稳像效果越好。
2)客观评价。能反映视频稳定质量的度量标准。Battiato 等利用相邻帧间的峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)衡量稳定后视频的帧间保真度,PSNR 反映了参考图像和当前图像间的峰值信噪比。定义如下:

其中:Imax是最大亮度值;MSE(I1,I0)表示连续帧间的均方差。PSNR 值越大,说明帧间的灰度差越小,图像稳定效果越好。
后来,佘建国等[4]又提出采用三个指标定量地评价和度量视频稳像结果:
1)裁剪率(Cropping)指标。主要衡量稳定后图像帧剩余的有效区域占原图像帧的比例,值越大,说明视频的稳像效果越好,整个视频的裁剪率=average{所有视频帧裁剪率}。
2)失真率(Distortion)指标。主要衡量稳定后视频的失真程度,值越大,说明视频的稳像效果越好,整个视频的失真率=min{所有帧图像的失真率}。
3)稳定度(Stability)指标。衡量稳定后视频的稳定度,值越大,说明视频的稳像效果越好。采用频率分析法对视频中的运动进行估算,基于假设:运动分量中低频分量所占的越多,则说明视频越稳定。
2.2 基于时空显著性的运动目标识别结果
2.2.1 多组视频下时空显著性目标的识别结果
为了验证基于时空显著性的运动目标识别优势,从Testing Set1 数据集中选出了两组含有运动目标的视频,并进行时空显著性目标检测实验。
图4 为基于时空显著图的运动目标检测结果。从图4(e)中可以看出:利用时空显著图能很好地将图中的运动目标识别出来,因为时空显著图不仅利用了运动特征信息,而且充分结合了空间颜色对比度,因此,运动前景识别的准确率更高。
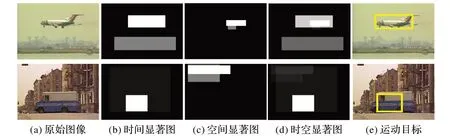
图4 基于时空显著图的运动目标检测结果Fig.4 Moving target detection results based on spatio-temporal saliency maps
2.2.2 时空显著性目标的识别准确率评估
为了验证时空显著图的优势和算法的鲁棒性,本文从数据集1 中选出了包含大范围运动前景的视频Video1 和包含多复杂运动前景的视频Video2 开展实验,并分别对比了采用时间显著图、空间显著图、时空显著图的运动目标识别准确率,表1 为三种显著图下的运动目标识别准确率结果。
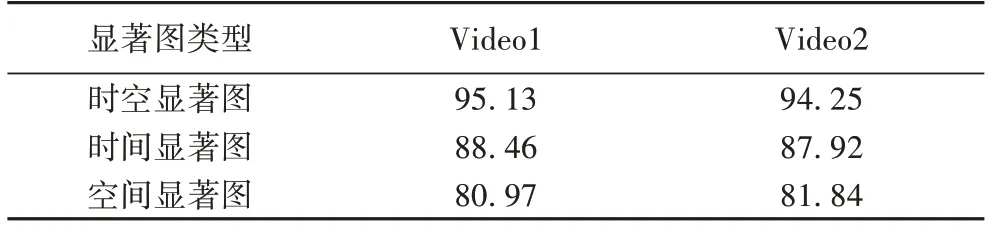
表1 三种显著图下的运动目标识别准确率对比 单位:%Tab.1 Comparison of moving target recognition accuracy with three saliency maps unit:%
由表1 中的数据可以看出,在两组视频下,利用时空显著图比其他两种显著图的运动目标识别准确率更高,充分说明了本文算法具有较好的鲁棒性优势。
为了能进一步验证利用时空显著图对运动目标的识别更具优势,分别从数据集1(Testing Set1)和数据集2(Testing Set2)中选出两组包含复杂运动前景的视频,采用时空显著图进行实验。根据主观评价将运动目标的识别结果分为三类:满意的、可接受的、失败的,并统计每一类下结果占比,基于不同数据集的运动目标识别结果如表2 所示。通过表2 可以看出,本文算法在数据集1 和数据集2 上都获得不错的运动目标识别结果,也说明该算法具有较好的鲁棒性。

表2 不同数据集上的运动目标识别结果Tab.2 Moving target recognition results on different datasets
2.3 各算法的稳像结果对比
为验证本文算法在对于运动前景干扰视频的稳像优势,从数据集中2 选出了三组稳像测试视频,如图5 所示,其中:第一组为包含简单运动前景的视频;第二组为包含大范围运动前景的视频;第三组为包含多运动前景的视频。同时,将本文算法与四种传统的稳像算法即Subspace[17]、Epipolar[18]、Bundled-paths[7]、RTVSM[10]进行稳像精度比较。

图5 稳像测试视频Fig.5 Image stabilization test videos
由图6 所示的三组视频下各算法的稳像精度对比可以看出,在三组测试视频中,相较于传统算法,本文算法在Cropping、Distortion 指标上略占优势,但在Stability 指标方面表现突出。如图6(b)所示,在第二组测试视频中,本文算法和RTVSM[10]的Stability 值分别为0.91 和0.83,Stability 指标提高了约9.6%;如图6(c)所示在第三组测试视频中,本文算法和Bundled-paths[7]的Stability 值分别为0.9 和0.85,Stability 指标提高了约5.8%。综上可以得出结论,本文算法对于复杂运动前景干扰的情况,稳像性能表现更为突出,说明了本文算法能有效避免复杂运动目标的干扰,保证视频的稳定度。

图6 三组视频下各算法的稳像精度对比Fig.6 Comparison of image stability accuracy of different algorithms in three videos
另外,为了能更加直观地说明本文算法的稳像优势,图7 列出了三组视频下本文算法与Bundled-paths 算法的稳像视觉结果对比,图中标识出的交叉直线主要是为了便于比较、观察。
由图7(a)中可以看出,对于包含简单运动前景的视频,采用Bundled-paths 算法、本文算法后虽然结果比较接近,但是本文算法的边缘区域更少。
由图7(b)和(c)可以看出,相较于传统的Bundled-paths算法,本文算法对包含大范围和多运动前景视频的稳像效果更好,稳像后视频过渡更加平滑,图像边缘区域更少,说明了本文算法的有效性。

图7 三组视频下各算法的稳像视觉结果对比Fig.7 Comparison of visual image stabilization results of different algorithms in three videos
3 结语
为了解决运动前景干扰的视频稳像问题,同时鉴于时空显著性检测算法在运动目标检测方面的独特优势,本文提出了一种融入时空显著性的高精度视频稳像算法。该算法的创新点主要在于:通过时空显著性检测技术识别运动目标,同时结合多网格的运动路径进行运动补偿,剔除运动前景的干扰。实验结果表明,相较于传统的算法,本文算法在稳定度指标方面表现突出。对于大范围运动前景干扰的视频,本文算法相较于RTVSM 的Stability 指标提高了约9.6%;而对于多运动前景干扰的情况,本文算法比Bundled-paths 算法的Stability 指标提高了约5.8%,这充分说明了本文算法对复杂场景的稳像优势。
猜你喜欢
四川党的建设(2022年8期)2022-04-28
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机仿真(2021年7期)2021-11-17
今日农业(2021年7期)2021-07-28
建材发展导向(2021年6期)2021-06-09
小学生学习指导(低年级)(2020年11期)2020-12-14
中国外汇(2019年11期)2019-08-27
电子制作(2019年24期)2019-02-23
中国知识产权(2018年12期)2018-12-29
作文大王·低年级(2018年10期)2018-12-06
