
基于BERT-PFMM的软件缺陷预测方法*
2022-08-31 09:02汤怡佳王丽侠韩建民叶荣华曹小倩
浙江师范大学学报(自然科学版) 2022年3期
汤怡佳, 王丽侠, 韩建民, 于 娟, 叶荣华, 姚 鑫, 曹小倩
(1.浙江师范大学 数学与计算机科学学院,浙江 金华 321004;2.浙江师范大学 行知学院,浙江 兰溪 321100)
0 引 言
随着软件规模及复杂度的增加,软件缺陷的发现变得愈发困难,软件缺陷预测技术也受到广泛的关注.软件缺陷预测能够判断一个软件模块是否有缺陷,从而帮助测试人员更好地分配测试资源,安排测试过程,进而改进软件产品的质量.因此,近年来,软件缺陷预测方法的研究成为软件工程领域的热门课题.
早期的软件缺陷预测以人工提取软件特征为基础[1].人工提取的软件特征主要包含:项目源代码的行数、复杂度、耦合度等[2-4].然而,人工提取的软件特征,仅代表代码的统计特征,忽略了潜藏在代码中的结构和语义信息.这无疑会造成软件缺陷预测性能的降低.而抽象语法树以树状的形式表示源代码,能够更准确地表达程序模块的语法结构和语义信息.研究表明,利用抽象语法树可以更准确地预测软件缺陷[5].
近年来,研究人员将深度学习技术运用到软件特征提取和软件缺陷预测中[6],典型的基于深度学习的软件特征提取技术有:深度信念网络(deep belief network,DBN)[7]、长短期记忆网络(long short-term memory,LSTM)[8]、卷积神经网络(convolutional neural network,CNN)[9].DBN学习的是数据和标签之间的联合分布,但忽略了源代码的结构信息;CNN模型可以很好地提取局部语义特征,但是无法捕获长文本间的语义信息;LSTM网络具备长时记忆的能力,能够捕获长文本间的语义信息,但是训练中需要大量的数据和计算时间.这些方法的共同问题是使用上下文无关的词嵌入方法对文本数据进行编码,忽略了单词在不同上下文中表示的语法和语义的差异,表示能力存在不足.
为解决上述不足,本文提出一种结合预训练模型BERT(bidirectional encoder representations from transformers)和感知特征混合模型PFMM(perceptual features mixing model)的软件缺陷预测方法BERT-PFMM.BERT利用注意力机制,可以充分理解和动态获取上下文相关的语义信息[10],从中自动提取软件特征;PFMM网络架构可以以较小的计算代价将BERT提取的特征映射到更容易分类的空间,使PFMM的输出与标签的对应关系更强.相对其他深度学习方法,BERT-PFMM可以更充分理解文本语义信息,自动提取软件特征,优化词向量表示;PFMM网络可以增强特征与模型输出的关系,以提升软件缺陷预测的准确性.
具体而言,本文主要工作包括:
1)利用抽象语法树对源代码进行解析,进而生成节点向量;
2)引入BERT模型动态获取节点间的上下文信息,提取出语义特征;
3)提出了PFMM模型,PFMM将BERT提取的特征映射到更容易分类的空间,提升了软件缺陷预测的效果;
4)对Promise存储库的7个项目进行实验,实验结果表明,所提出的BERT-PFMM模型与现有的软件缺陷预测方法相比,具有更好的性能.
1 相关工作
1.1 基于传统机器学习的软件缺陷预测方法
早期的软件缺陷预测研究工作,大多通过建立软件度量与缺陷之间的关系来构建缺陷预测模型.Okutan等[11]通过贝叶斯网络来检验软件度量和缺陷倾向之间的关系,研究表明,类响应、代码行数和源代码质量是最有效的度量指标;Lee等[12]提出了基于微交互度量的软件缺陷预测方法,研究表明,微交互度量可以显著提高缺陷预测的准确性;Arar等[13]采用朴素贝叶斯方法过滤冗余特征,选择合适的特征;Wang等[14]提出了基于多核集成学习的软件缺陷预测方法,研究表明,多核集成学习可以更好地表示高维特征空间中的缺陷数据,并通过组装一系列弱分类器来减少数据不平衡问题.
虽然目前已有多种软件度量用来衡量软件特性,但是软件度量作为一种统计学特征不能很好地反映源代码的语法和语义,导致软件缺陷预测的准确性偏低.
1.2 基于深度学习的软件缺陷预测方法
近年来,深度学习被用于挖掘软件源代码中的非线性特征.Wang等[15]利用DBN从源代码自动提取出语义特征用于缺陷预测,从而提升了软件缺陷预测性能;Jian等[16]将CNN从源代码提取出的局部特征与静态特征相结合,并进行软件缺陷预测,F1的平均值比基于DBN的模型[15]提高了12%;Phan等[17]为了更好地探究程序的语义特征,尝试通过卷积神经网络从程序流程图中进行学习,提出了基于图的卷积神经网络的预测模型;Liang等[18]提出了Seml方法,该方法结合词嵌入和深度学习进行缺陷预测;Fan等[19]提出了一种基于注意力的递归神经网络方法,该方法利用RNN,从抽象语法树提取的节点向量中提取语义特征,然后使用注意力机制生成关键特征,从而提高软件缺陷预测模型的性能;Deng等[20]利用LSTM学习源代码的语义,提取上下文特征,最后使用这些特征来确定软件模块是否有缺陷;Zhou等[21]将双向长短期记忆网络和树状长短期记忆网络相结合,从源代码中获取语义特征进行软件缺陷预测;Zheng等[22]为了提取出软件中关键的语义和语法特征,提出了一种基于Transformer的软件缺陷预测方法.
尽管基于深度学习的软件缺陷预测已有很多研究成果,但现有的基于深度学习的方法需要大量的数据,否则难以训练出很好的缺陷预测模型,从而影响预测结果的准确性.
2 基于BERT-PFMM的软件缺陷预测模型
2.1 总体框架
本文总体工作流程如下:
1)预处理:将源码文件解析为抽象语法树,再对抽象语法树进行深度优先遍历,选取其中具有表征性的节点,生成节点向量,每一个源码文件生成一个节点向量;
2)特征提取:BERT模型利用词嵌入将节点向量进行编码,并从中提取出具有上下文信息的全局语义特征;
3)特征加强及分类:将BERT模型提取出的全局语义特征输入PFMM模型,利用PFMM的权重矩阵将输入的全局语义特征映射到更容易划分边界的高维空间,利用分类器进行软件缺陷预测.
图1所示为本研究的软件缺陷预测框架的整体流程图.

图1 基于BERT-PFMM的软件缺陷预测模型框架图
2.2 抽象语法树及节点向量的生成
以Java项目作为研究对象,利用Python依赖包Javalang构造Java源代码的抽象语法树.
构造好源代码的抽象语法树后,使用深度优先遍历(depth first search,DFS)算法遍历该抽象语法树,生成源代码的节点向量.为降低向量维度,在遍历抽象语法树时,只选择对源代码有意义的节点,选择的依据有:1)方法调用和类创建节点,将方法名和类名作为节点表示;2)声明节点,包括方法声明、类型声明、接口声明、枚举声明等;3)控制流节点,如条件控制、循环控制、异常控制等;4)其他节点:其他重要的节点.所选用的节点如表1所示.

表1 本文选取的AST节点
由于节点向量中的分量命名因不同的程序而有所不同,为了加强不同项目中提取的节点向量间的联系,按如下方式对每一个分量进行处理并过滤不重要的信息:
1)将字符串组合分量分割成子串.利用正则表达式找到以驼峰命名法或者下划线构成的组合分量,将其分割成完全小写的子串.例如toString被分割为[to,string].
2)对子串进行排序,然后使用下划线拼接构成新的分量.例如[to,string]被拼接为string_to.
3)过滤掉不重要的信息:停用词及编程中的关键字.例如main和args.
本文将所有节点向量所生成的样本数据长度截断为256个节点,不足的后面补零.
图2给出了从源代码到节点向量的全部流程.

图2 从源代码到节点向量的全部流程
2.3 BERT模型
BERT模型主要目的是从输入文本中提取出特征向量,通过遮蔽语言建模和下一个语句预测2个预训练任务,获取词级和句子级特征.BERT模型是由多层双向Transformer编码器构成,能够学习到词级、句级及全局的语义信息.图3为BERT结构图,其中Trm为Transformer模型名称缩写,符号⊕为求和运算符,Ei,Ti分别表示第i个词的嵌入向量和特征向量,EA表示该词属于句子A,Ewi表示第i个词的词向量,Epi表示第i个词的位置编码向量.
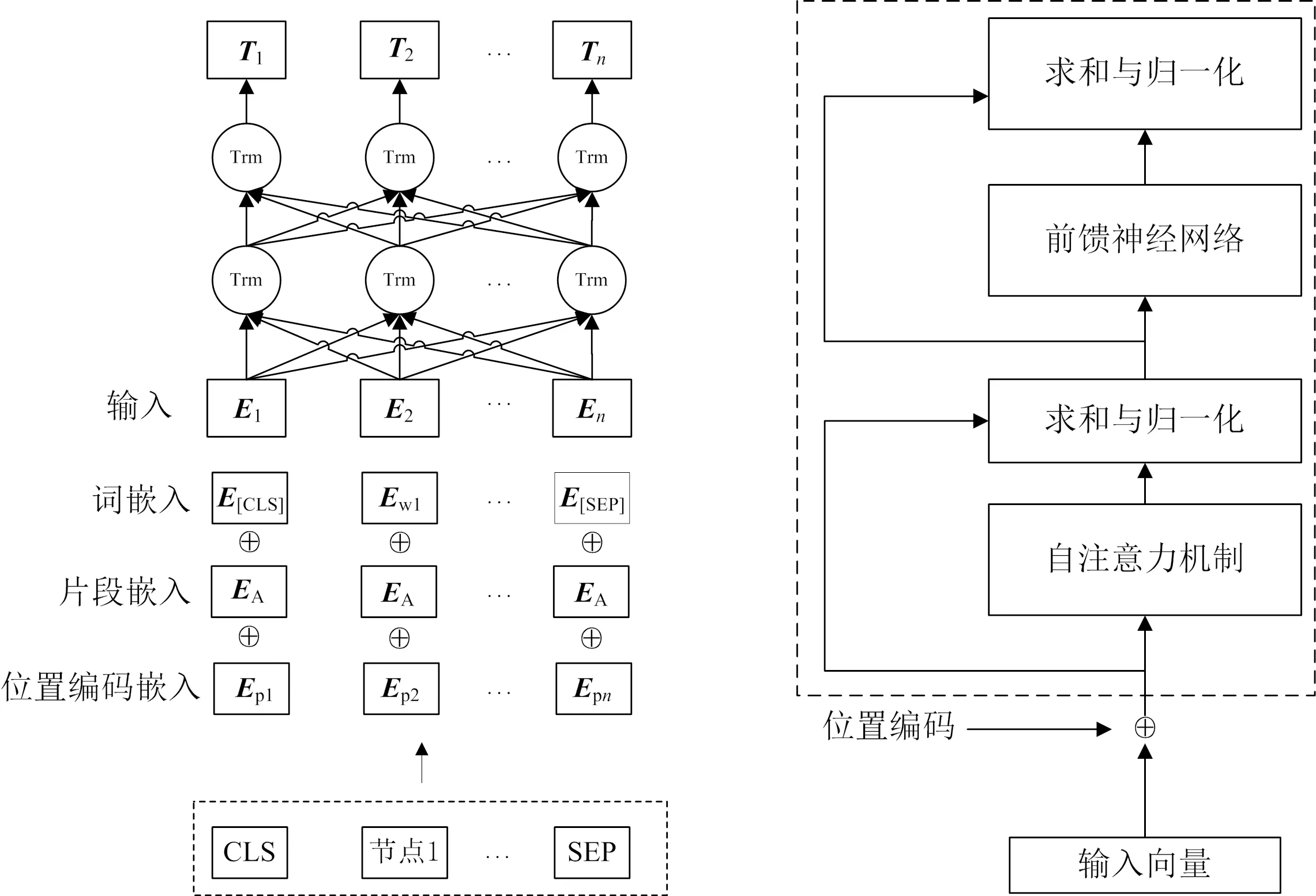
图3 BERT结构图[10] 图4 Transformer编码器[23]
在软件缺陷预测任务中,将节点向量作为一个句子输入到BERT模型中.BERT模型首先将词序列中的词进行分词,在句子开头添加一个CLS标记用于表示整个句子的语义信息,句子间使用SEP标记进行分隔,以此区分2个句子的句间关系.再将由词嵌入、片段嵌入和位置编码嵌入3种方式得到的向量相加,输入到Transformer编码器[23]进行特征提取,最终生成包含语义信息的特征.图4为Transformer编码器结构图.
在每个单元中都有自注意力机制和前馈神经网络,在它们之后还连接着求和与归一化,其中自注意力机制是编码器的核心,通过句子中词与词之间的关系调整权重系数矩阵,用于学习句子中词与其他词之间的关系.由于Transformer不能获取词在句子中的位置信息,为解决这个问题,BERT内的所有Transformer均需要增加位置编码,并与输入向量相加,从而加入了句子中每个字的相对位置信息.可以说,词嵌入和片段嵌入是BERT模型引入的,而位置编码则是Transformer模型自带的.
相比于其他的语言模型,BERT模型通过引入大量的外部知识信息进行预训练并从输入的上下文提取词的语义信息,最后获得词的更加完整的语义信息.
2.4 PFMM网络结构
为了充分利用BERT提取的语义特征,本研究设计了PFMM网络结构,将BERT提取的特征利用PFMM的权重矩阵映射到更容易划分决策边界的高维空间.
PFMM网络结构如图5所示,由3个部分组成:增强层、全局平均池化层和分类层.

图5 PFMM结构图
1)增强层:该层如图6所示,将BERT的输出向量作为增强层的输入.首先将输入数据进行层归一化(layer normalization),从而防止模型过拟合,然后经过多层感知机(multilayer perceptron,MLP)将特征转换到更加容易分类的空间,最后使用跳连接[24]来缓解网络过深导致的梯度消失问题,增强层的变换函数如式(1)所示.

图6 增强层
U=A+W2σ(W1fLayerNorm(A)).
(1)
式(1)中:U为增强层输出的结果;A为增强层的输入;W1,W2为MLP的权重;fLayerNorm为层归一化,能够保证数据特征分布的稳定性,加速模型的收敛;σ是一个非线性激活函数GELU(Gaussian error linerar units)[25],如式(2)所示.
σ=fGELU(x)=
(2)
2)全局平均池化层:负责对增强层的输出进行均值池化,以便进行特征压缩,保留显著特征,减少模型参数量,从而降低模型的计算成本.
3)分类层:分类层包含2个部分,第1部分通过全连接神经网络对全局平均池化层输出的压缩特征进行加权求和,第2部分通过softmax函数输出软件缺陷预测结果.
3 实验分析
下面对BERT-PFMM模型进行性能评估,对比模型包括:原BERT模型及最近提出的用于软件缺陷预测模型.
3.1 实验环境及实验数据集
BERT-PFMM网络采用深度学习框架PyTorch (1.9.0) 实现,其他对比方法主要基于scikit-learn(0.21.2)和Python 3.8实现.所有实验均在Windows工作站上运行,具体配置为:NVIDIA GeForce RTX 3090 GPU,Intel E5-1620 v2 CPU,32 GiB 内存.
使用的缺陷预测数据集来自 tera-Promise Repository.表2给出了从中选择的7个项目的详细信息,包括项目名称、版本、平均文件数量和平均缺陷率.此外,对比实验中还采用了Feng等[26]提供的以上7个项目的20个传统缺陷预测特征.本研究选择同一项目的2个版本,版本号小的用于训练模型,版本号大的用于评估.

表2 Java项目信息
3.2 实验参数设置
本文实验中,BERT预训练模型采用“BERT-base,Uncased”模型.该模型总参数量为110×106.使用Adam(adaptive moment estimation)进行模型优化.具体参数设置如表3所示.

表3 参数设置
3.3 基线方法
为了比较上下文语义特征和静态代码度量对软件缺陷预测性能的影响,本文选择了两大类共6种对比方法与BERT-PFMM模型进行比较:
随机森林(random forest,RF):基于20个静态代码度量的随机森林方法.
逻辑回归(logistic regression,LR):基于20个静态代码度量的逻辑回归方法.
深度森林(deep forest,DF)[27]:基于树的集成学习方法.
CNN:一种基于文本序列卷积的深度方法,最终利用全连接网络进行分类.
DBN:使用DBN从源代码中提取特征,利用全连接网络进行分类.
BERT:使用BERT的预训练模型自动提取语义特征,利用全连接网络完成分类.
其中,BERT,DBN和CNN是深度学习方法,其他为传统方法.深度神经网络生成的输入数据与BERT-PFMM模型生成的输入数据相同.
3.4 评价指标
采用4个常用的评估指标评估BERT-PFMM模型的性能:精确度(precision,P),召回率(recall,R),F1值(F1-score,F1)和ROC曲线下面积(area under ROC curve,AUC).计算公式如下:
P=NTP/(NTP+NFP);
(3)
R=NTP/(NTP+NFN);
(4)
F1=2PR/(P+R).
(5)
式(3)~式(5)中:NTP为所有预测结果中真正类(true positive)的实例数,即真实类别和预测类别均为正类;NFN为假负类(false negative)的实例数,即真实类别为正类,预测类别为负类;NFP为假正类(false positive)的实例数,即真实类别为负类,预测类别为正类.
精确度P为查准率,P值越高,表明将无缺陷样本错误标记为有缺陷样本的可能性越小.召回率R为查全率,R值越高,模型标记出的真实缺陷样本越多.单独使用P或R很难准确评估模型性能.F1值是为了克服P和R的不足而提出的一种调和平均值,是综合衡量P和R的一个指标.
AUC表示受试者工作(receiver operating characteristic,ROC)曲线下的面积,适用于评估类不平衡的数据集.为了绘制ROC曲线,首先需要将测试样例按照预测模型给出的正例概率降序排序;然后逐步改变划分正例样本和反例样本的概率阈值,并计算出真正例率和假正例率,用作ROC曲线上的点.AUC取值范围为0~1,值越高越好.
3.5 实验结果
3.5.1 深度学习方法与传统方法的性能比较
深度学习方法,包括BERT-PFMM,DBN和CNN,统一使用抽象语法树算法对代码提取语义信息生成特征数据集.传统方法利用LR和RF,以及一个新的基于树的集成学习方法DF,通过对20个手动提取出的静态代码度量挑选出有效特征,为了结果的有效性,对不平衡数据集进行了SMOTE过采样操作.
实验结果如表4和表5所示,其中包括7个项目名称、3个深度学习方法、2个传统方法和深度森林方法的实验结果.表4的结果数据展示的是F1值,其值越大表明模型的性能越好.表5的结果数据展示的是AUC,其值越大表明模型的分类能力越好;“W/D/L”统计了在7个项目中,本文提出的模型比其他模型有更好、相等及更差性能的项目数.表4和表5中评价指标较高的数值用黑体显示.

表4 BERT-PFMM与基线模型的性能比较(F1值)

表5 BERT-PFMM与基线模型的性能比较(AUC)
从表4和表5可以看出,在绝大多数情况下深度学习方法优于传统方法.例如,在Lucene项目上使用BERT-PFMM,DBN,CNN方法后F1值分别为0.842,0.630,0.743.而在Lucene项目上使用LR,RF,DF后F1值只有0.598,0.610,0.655.从实验数据可以看出,使用深度学习方法提取语义信息之后模型对于判别软件模块是否存在缺陷的能力优于传统方法,具有一定的提升.从表4的最后一行所展示的所有模型在不同数据集上的平均结果也可以看出,深度学习方法比传统方法具有更高的F1值,对于缺陷预测的性能更好.表5列出了每个项目上的AUC值.在大多数情况下,深度学习方法的AUC值要高于传统方法.从表5的最后一行展示的7个项目的平均值可以看出,深度学习方法提高了对有缺陷代码和无缺陷代码的识别能力.
几种深度学习方法中,BERT-PFMM方法较DBN和CNN方法具有很大的提升,在平均结果上F1值分别提升了12.4%和10.3%,AUC值分别提升了15.7%和11.6%.说明BERT-PFM方法更具优势,也表明了使用根据上下文提取语义信息提高了模型识别代码模块中潜在缺陷的能力.
3.5.2 BERT-PFMM模型与其他方法比较
从深度学习方法和传统方法的对比实验中可以看出,使用深度学习方法更具优势.BERT-PFMM模型与选用的基线方法相比,分类能力具有显著提升.
本研究还选用了4个其他方法进行对比,实验对比结果如表6所示.从表6可以看出,BERT-PFMM方法比其他4种方法具有显著优势,例如,Camel项目在使用BERT-PFMM,GH-LSTM,DP-Transformer,Seml,Fences方法后的F1值对应为0.661,0.454,0.526,0.463,0.540,可以看出,BERT-PFMM具有最大值.从不同数据集的平均结果上看,本文提出的方法更具有优势,相比于其他4个方法而言分别提升了8.5%,6.0%,9.6%和7.9%.从而可以表明BERT-PFMM方法的有效性和优势.

表6 BERT-PFMM与别的方法的性能比较(F1值)
3.5.3 BERT-PFMM模型与BERT模型性能比较
为了验证PFMM的有效性,将BERT-PFMM与原始的BERT模型进行对比,实验结果如表7所示.从整体上看,BERT模型的精确度比BERT-PFMM模型要好,但召回率、F1值和AUC普遍低于BERT-PFMM模型.从不同项目的平均结果来看,BERT-PFMM模型与BERT模型的F1值相比提高了3.0%,AUC相比提高了1.9%.从表7可以看出,BERT-PFMM模型在BERT模型基础上加入PFMM模块是有效的.

表7 BERT-PFMMM模型与BERT模型的性能比较(精确度、召回率、F1值和AUC)
4 结 语
为了解决带标签样本缺乏和现有工作未充分利用上下文语义信息的不足,提出了BERT-PFMM模型,以提高软件缺陷预测的准确率,降低测试成本.BERT-PFMM模型可以将BERT提取的特征利用PFMM的权重矩阵映射到更容易划分决策边界的高维空间.使用预先从大量无标签语料库训练好的BERT模型,将训练后的参数应用到缺陷预测中进行优化,从而缓解数据集缺乏导致训练不充分的问题.为提取深层上下文语义信息并加以充分利用,在BERT模型上增加了PFMM模块使其输出与标签的对应关系更强.在7个开源项目上的实验结果表明,BERT-PFMM的F1值与DBN相比平均提高了12.4%,与CNN相比平均提高了10.3%,与最近提出的GH-LSTM方法相比平均提高了8.5%,与BERT模型相比平均提高了3.0%.另外,BERT-PFMM的AUC与DBN相比平均提高了15.7%,与CNN相比平均提高了11.6%,与BERT模型相比平均提高了1.9%.
在今后的研究中,为验证BERT-PFMM在缺陷预测任务上的通用性,考虑在更多项目及各种编程语言(例如,Python,C++)环境下进行实验.此外,还可以尝试将静态代码度量结合到BERT-PFMM中,检测二者结合是否能够进一步提高软件缺陷预测的能力.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
现代信息科技(2021年21期)2021-05-07
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
开放教育研究(2020年2期)2020-03-31
计算机应用(2017年10期)2017-12-14
世界汽车(2016年9期)2016-09-29
高中生学习·高三版(2016年9期)2016-05-14
长江学术(2016年4期)2016-03-11
新高考·高二数学(2015年11期)2015-12-23
