
基于深度学习的视频异常检测方法综述*
2022-09-21 08:36李慧斌
计算机工程与科学 2022年9期
何 平,李 刚,李慧斌,2
(1.西安交通大学数学与统计学院,陕西 西安 710049;2.大数据算法与分析技术国家工程实验室,陕西 西安 710049)
1 引言
面对日常生活中不断涌现的各类安全威胁和时刻存在的突发状况,以视频监控为工具进行安防的举措已凸显出强大优势。近年来随着社会经济的快速发展与视频传感技术的不断普及,监控系统已被广泛应用于地铁、社区和校园等各类公共场所[1]。然而,规模快速增长的视频监控系统所产生的海量视频数据对基于人工判读的视频异常事件检测带来了巨大挑战。传统依靠人工观看事后监控影像记录从而发现异常的方式不仅消耗了大量人力资源,而且还可能会造成无法及时弥补的错误或遗漏[2]。因此,开发一种不依赖大量人力,能自动从监控视频中分析并发现异常情况的技术显得至关重要,这种技术即为视频异常检测技术。

Figure 1 General process of video anomaly detection method图1 视频异常检测方法的一般流程
视频异常通常指视频中出现不正常的外观或运动属性,或在不正常的时间或空间出现正常的外观或运动属性[3]。由于异常样本的稀缺性和多样性,视频异常检测方法通常仅对正常样本分布进行建模,测试时将偏离正常样本分布的视频帧或视频片段视为异常[4]。从异常类型而言,外观异常通常指空间异常,包括像素级别的局部异常与帧级别的全局异常;运动异常通常指时间异常,即与时序相关的上下文异常。视频异常检测任务即为检测出视频中存在的时间异常和空间异常[5]。由于特定场景下监控视频的背景往往固定不变,所以监控视频为典型的单一场景视频,基于单一场景的视频异常检测研究也是本文综述的重点内容。
目前,监控视频异常检测领域主要有以下综述文献:Popoola等人[6]介绍了针对人类行为的异常检测方法,将方法划分为聚类法、动态Bayes和主题模型法,但由于提出时间较早,对深度学习方法覆盖较少;Kiran等人[7]从建模角度出发,将深度学习方法划分为重构、预测及生成方法,但文中缺少对这些方法异常检测效果的对比分析;彭嘉丽等人[8]从学习范式角度出发,总结了有监督、弱监督及无监督视频异常检测方法;胡正平等人[9]将视频异常检测方法分为有监督、半监督和无监督3类,但文献[8,9]引用的文献较少,综述不够详尽;王志国等人[10]从事件提取、表示及建模角度进行了综述,但对深度学习方法建模描述较少。
针对以上不足,本文从区分正常视频和异常视频的基本原理出发,对基于深度学习的监控视频异常检测方法进行全面和系统的综述。本文主要贡献如下所示:
(1)从基本概念、方法流程、任务类型及学习范式等方面系统阐述了视频异常检测的基本内涵,并侧重强调了面向实际需求时检测精度与检测效率之间的平衡问题。
(2)从正常与异常判定的基本原理出发,将基于深度学习的视频异常检测方法分为基于重构的方法、基于预测的方法、基于分类的方法及基于回归的方法4类。系统综述了各类方法的基本思想、代表性文献及其优缺点。
(3)全面总结了现有单场景视频异常检测数据集与评价指标,对比分析了代表性方法的性能,并从数据集、方法以及评估指标3个方面对异常检测研究的未来发展方向进行了展望。
2 视频异常检测概述
视频异常检测任务流程如图1所示。对于给定的某一特定场景下的正常视频数据样本,首先从中提取视频帧或视频窗内图像的运动及外观特征,并建立模型对正常样本的分布进行学习。测试时,将提取的测试样本特征输入模型,模型依据重构误差、预测误差、异常分数和峰值信噪比等指标对其进行异常判定。
2.1 视频异常检测的基本类型
视频异常检测的基本类型可分为以下2种:
(1)局部异常和全局异常:局部异常通常指在适度或密集拥挤环境中某个个体的活动明显偏离其相邻个体;全局异常是指特定场景下整体异常,也许局部个体的活动可能是正常的。
(2)时间异常和空间异常:时间异常是指与运动信息相关的异常,反映视频帧之间的变化规律;空间异常是指与位置相关的异常,反映视频帧内部的异常信息。
2.2 视频异常检测的学习范式
视频异常检测主要有4种学习范式,分别为有监督、无监督、弱监督和自监督。
(1)有监督学习:有监督学习是指已知数据样本和其一一对应的标签,通过模型训练,将所有数据样本映射到不同类别标签的过程。对于视频异常检测,即指使用正常样本和异常样本以及相应的标签,训练一个二分类器进行异常检测。但是,由于异常视频的稀缺性,使得基于有监督学习的视频异常检测方法较为少见。
(2)无监督学习:基于无监督学习的异常视频检测是指不依赖视频标注信息,依靠样本数据之间的相似性对正常样本进行学习、聚类或分布建模,测试时把远离正常样本的视频看作异常,进而实现异常检测。使用无监督学习范式进行视频异常检测通常需要提供充足的正常视频数据。
(3)弱监督学习:基于弱监督学习的视频异常检测是指仅依赖视频级标注信息进行建模,在测试时可进行逐帧或视频片段的异常检测。基于弱监督学习的视频异常检测方法对于数据的标签依赖大幅降低,不再依赖逐帧标签,很大程度上降低了数据的标注工作量,方便使用大规模数据集,进而可增强检测方法对不同场景的适应能力,以及对不同异常类型的检测性能。
(4)自监督学习:基于自监督学习的视频异常检测是指模型直接从无标签数据中自行学习,无需标注数据。自监督学习不再依赖标注,而是通过学习数据各部分之间的联系,从大规模的无标签数据中挖掘自身的监督信息生成的标签,用于指导自身进行训练。自监督视频异常检测方法通常考虑的是一种更具有挑战的实验设置,即不依赖任何训练数据。
2.3 视频异常检测的评价方式
视频异常检测主要有2种评价方式,分别为精度优先和效率优先。
(1)精度优先:精度优先的视频异常检测方法要求对异常的检测和定位有较高的精度和较低的虚警率。该类方法的目的是通过使用所有可用的训练数据集视频、固定的模型参数和预定义或微调的异常阈值来保证高精度,但很难保证模型的实时性。
(2)效率优先:效率优先的视频异常检测方法旨在以最快的帧处理速度获得具有竞争力的精度来检测和定位视频异常。该类方法的目的是使视频异常检测方法能够具有较快的实时处理速度,满足在线检测的需求,因而更适合实际应用。
3 基于深度学习的视频异常检测方法
不同于大多基于学习范式和建模流程的分类策略,本文从区分正常视频和异常视频的基本原理出发,将基于深度学习的视频异常检测方法分为基于重构的方法、基于预测的方法、基于分类的方法和基于回归的方法。
3.1 基于重构的方法
基于重构的视频异常检测方法的核心思想是通过训练正常视频数据来获得正常数据的分布表示。在测试过程中,正常测试样本会具有较小的重构误差,而异常样本的重构误差则较大,从而实现视频的异常检测。若令x代表一个视频片段或视频帧,g代表重构x的神经网络,f()代表计算x与g(x)之间重构误差的函数,ε代表重构误差,基于重构的深度学习方法可以看作是在极小化式(1)中的重构误差。
ε=f(x,g(x))
(1)
一种常用的重构方法为自编码器。Xu等人[11]提出了一种外观运动深度网络AMDN(Appearance and Motion Deep Net),能够同时提取视频的外观和运动信息,并使用多个单类支持向量机SVM(Support Vector Machine)预测每个输入的异常得分,最后集成分数用于最终的异常检测。Hasan等人[12]提出了2种基于自编码器的方法,首先利用传统手工方法提取时空特征,并在其上学习一个全连接的自编码器;其次建立一个全卷积前馈自编码器学习局部特征和分类器作为端到端的学习框架,使其能够在很少或者无监督的情况下进行视频异常检测。但是,由于深度神经网络的学习能力较强,导致自编码器有时不仅能将正常样本重构得较好,同时也使得异常样本具有较小的重构误差。针对这一问题,Gong等人[13]提出了一种改进的自编码器,称为记忆增强自编码器MemAE(Memory-augmented AutoEncoder)。当给定输入时,该方法首先从编码器获取编码,然后使用它作为查询检索最相关的记忆项进行重构。Park等人[14]在Gong等人[13]的研究工作基础上,使用一个具有更新方案的记忆模块,使得记录数据原型模式的项可以不断更新,以更好地记住正常样本,并在公开基准数据集上取得了可以媲美当时最先进方法的异常检测效果。
基于重构的视频异常检测的另一种常用方法为稀疏编码,其思想主要是通过构造一组能够表达正常视频的字典,使得正常视频能够通过该字典很好地重构出来,而异常的视频则会变得模糊甚至无法重构。假设输入的视频特征X=[x1,x2,…,xk],其中每个xi代表正常的视频帧特征,基于稀疏编码方法的目标是找到一个最优字典D,从而能够通过稀疏系数α=[α1,α2,…,αk]将X重构出来,其中D和α通过交替迭代优化获得。其目标函数如式(2)所示:
(2)
Zhao等人[15]早在2011年提出了一种无监督的动态稀疏编码方法检测视频中的异常事件,该方法首先对输入视频序列提取时空兴趣点,并依据上下文视频数据学习字典,在测试过程中依据字典基底能否重构出查询事件来判定异常。考虑到字典的大小会影响模型的计算复杂度,Cong等人[16]设计了一种具有稀疏一致性约束的字典选择方法,通过引入稀疏重构代价SRC(Sparse Reconstruction Cost)达到压缩字典的目的。此外,Luo等人[17]指出基于字典学习的异常检测方法在稀疏系数迭代优化过程中非常耗时,于是提出一种时间相干稀疏编码TSC(Temporally-coherent Sparse Coding)网络,用于约束相邻帧以相似的重构系数进行编码,并使用一种特殊类型的堆叠递归神经网络sRNN(stacked Recurrent Neural Network)映射TSC,从而实现参数的加速优化。Luo等人[18]在文献[17]的基础上对TSC进行了改进,在TSC的sRNN上再叠加一层,以减少优化过程中字典和稀疏系数交替更新计算成本。考虑到视频异常检测实时性的重要性,Wu等人[19]提出一种双流神经网络提取隐藏层的时空融合特征STFF(Spatial-Temporal Fusion Features),并对STFF使用快速稀疏编码网络FSCN(Fast Sparse Coding Network)来构建一个字典,FSCN与传统网络相比,不仅测试速度快了数百倍,而且精度也达到了先进水平。
3.2 基于预测的方法
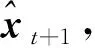
(3)
Liu等人[20]提出了一种基于预测模型进行视频异常检测的框架,使用U-Net(U-shaped Network)作为生成器用于生成未来帧,并使用强度损失、梯度损失和光流损失共同约束生成的未来帧质量,再通过判别器判断生成帧的真假,以强化预测模型的预测能力。受LSTM(Long Short-Term Memory)处理时序数据的启发,Medel等人[21]提出了一种复合的Conv-LSTM(Convolutional LSTM),对视频序列进行建模,通过对解码过程进行约束,能够重构过去帧和预测未来帧,进而实现视频的异常检测。Lu等人[22]将VAE(Variational AutoEncoder)与Conv-LSTM相结合,提出Conv-VRNN(Convolutional Variational Recurrent Neural Network)网络结构,用于生成视频未来帧。考虑到预测过程中均方差损失函数可能造成的未来帧模糊现象,Mathieu等人[23]使用一种卷积网络,通过交替卷积和矫正线性单元ReLU(Rectified Linear Unit)生成未来帧,并提出将多尺度结构、对抗训练和图像梯度差异3种不同的特征学习策略进行融合的方法来生成清晰的未来帧。此外,Ye等人[24]提出了一种深度预测编码网络AnoPCN(A novel deep Predictive Coding Network)来解决异常检测问题,该网络由预测编码模块PCM(Predictive Coding Module)和误差细化模块ERM(Error Refinement Module)组成,将PCM设计成Conv-LSTM网络结构用于生成未来帧,引入ERM重构预测误差,通过将重构和预测方法统一到端到端的框架中实现异常检测。
3.3 基于分类的方法
虽然目前主流模型主要依赖基于重构和未来帧的预测方法,但仍然有一些研究工作将该问题看作是分类问题。这种分类方法可以用一个通用的公式描述:令x代表输入视频帧或视频片段,h()代表通过网络训练得到的映射函数,y表示相应的所属类别,公式如式(4)所示:
y=h(x),y∈R
(4)
基于分类的视频异常检测方法主要分为单分类和多分类2种。基于单分类方法的视频异常检测的主要思想是通过正常视频数据训练一个单类分类器,在测试过程中分类器只需要判别给定数据是否属于该类即可。Sabokrou等人[25]受GAN(Generative Adversarial Network)在无监督和半监督环境中训练深度模型的启发,提出了一种基于单分类的视频异常检测方法。在此基础上,Wu等人[26]提出了一种深度单分类神经网络结构,使用堆叠的卷积编码器生成低维的高级表示信息,并通过结合对抗机制与解码器,能够在仅给定正常样本的前提下训练得到紧凑的单类分类器,进而实现异常检测。对于多分类的视频异常检测方法,Narasimhan等人[27]提出了一种利用局部特征和全局特征的方法,对于局部特征,在视频立方体块上使用图像相似度来表示时间和空间特征,使用训练后的自编码器的特征向量来表示全局特征,再将特征送入高斯分类器进行二分类异常检测。Ionescu等人[28]将异常检测问题转化为一个单对剩余类的二分类问题,在卷积自编码器生成的特征上使用聚类,训练一个单对剩余类分类器来区分聚类。在测试过程中若通过分类器得到的最高分类分数为负数,则表明该样本不属于任何聚类,即将其标记为异常。除二分类外,Xu等人[29]提出一种自适应帧内分类网络AICN(Adaptive Intra-frame Classification Network),将视频异常检测任务转化为多分类问题。该网络接受原始输入,将提取的运动和外观特征分为若干个子区域,并对每一个子区域进行分类。在测试过程中若该子区域的测试分类结果与真实分类不同,则被视为异常。
3.4 基于回归的方法
除了上述提到的基于重构、基于预测和基于分类的方法以外,一些研究人员也将该问题定义为回归问题。其主要思想是将异常得分作为评估指标,设置适当的阈值,若异常得分高于阈值,则将其视作异常,否则便为正常。令x代表输入的视频帧,k()代表输入x的函数,实数z表示输出的异常分数,如式(5)所示:
z=k(x),z∈R
(5)
Sultani等人[30]提出了一种主要在弱监督条件下训练的多示例学习方法,首先将每一个训练视频分成数量相等的片段,分别构成正例包(只包含正常视频帧)和负例包(至少包含一帧异常视频帧),使用C3D(Convolutional 3D)对每个视频片段提取时空特征;再将特征输入神经网络进行打分,从正例包和负例包中分别挑出得分最高的片段用于训练模型参数;最后通过铰链损失使得模型对异常样本输出高分,而对正常样本输出低分,在测试时依据模型输出的异常得分进行判定。在此基础上,Kamoona等人[31]指出文献[30]使用的铰链损失函数是不光滑的,在优化过程中可能会面临梯度消失的风险,提出了一种新的损失函数,从而使得模型对输出异常得分具有鲁棒性。由于提取视频特征对于输出异常得分至关重要,Zhu等人[32]放弃使用C3D,改为计算光流信息,再将计算得到的光流信息输入到时间增强网络输出异常得分。这一方法显著提高了异常检测的性能。考虑到手工标注正常/异常视频数据的复杂性,Pang等人[33]设计了一种端到端可训练的视频异常检测方法,该方法可以在无需手工标记正常/异常数据的基础上进行表示学习并输出异常得分,进而实现视频的异常检测。
3.5 小结
本节主要从区分正常视频和异常视频的基本原理出发,将基于深度学习的视频异常检测方法分为基于重构、基于预测、基于分类及基于回归4类方法。这4类方法的对比、归纳和总结如表1所示。

Table 1 Comparison and summary of different kinds of methods
基于重构和基于预测的方法对提取的视频帧特征依赖性很高,具有较高的空间复杂度和时间复杂度,对异常较少的视频数据检测效果较好,适用于视频数量较少的数据集,能够对帧级别的异常进行有效的时空检测与定位。基于分类的方法适用于具有充足正常视频的数据集,从而有利于更好地学习到正常视频模式的分布,但也需要更多的训练时间,能够检测并定位到视频帧级别的异常。上述基于重构、基于预测和基于分类的方法通常采用无监督的学习范式,适用于对视频进行帧级别的检测定位。作为对比,基于回归的方法通常与弱监督学习方法相结合,适用于视频数量较多的大型数据集,主要对视频级别或视频片段级别进行异常检测,能够检测定位到视频中的视频片段是否包含异常。
4 视频异常检测数据集
表2列出了目前常用的6个单场景异常检测数据集的具体信息。
(1)UMN数据集。
UMN数据集[34]共有11个视频,包含校园草坪、室内和广场3个不同场景。该数据集属于全局异常行为的数据集。由于此数据集包含的视频数量较少,使用重构方法能够充分捕捉到全局特征并进行帧级检测定位。目前基于深度学习方法在该数据上的异常检测准确率已经达到99.7%,研究人员逐渐不再使用此数据集。
(2)Subway数据集。
Subway数据集[35]包含地铁入口处(Entrance)和出口处(Exit)2类视频。该数据集包含的视频数量较少,使用重构的方法能充分捕捉到视频中的位置异常,进而进行帧级别的异常检测定位。由于该数据集包含的异常数量较少且异常种类相对单一,可泛化性相对较差,因此现阶段的研究人员较少使用。
(3)UCSD Pedestrain数据集。
UCSD行人数据集[36]的拍摄场景为某大学校园人行道。该数据集属于局部异常行为数据集,数据集中视频数量相对充足,适合基于重构、基于预测和基于分类等方法。目前在UCSD Ped1和UCSD Ped2数据集上达到的帧级别异常检测准确率分别为97.4%和97.8%。虽然准确率相对较高,但由于该数据集异常数量和异常种类相对充分,其目前仍是较受欢迎的几个基准数据集之一。
(4)CUHK Avenue数据集。
CUHK Avenue数据集[37]的拍摄场景为某大学校园主干道路。该数据集包含的视频数量适中,适于基于重构、基于预测和基于分类等方法。目前在CUHK Avenue数据集上达到的帧级别异常检测准确率为90.4%,还具有很大的提升空间,是目前使用较多的几个基准数据集之一。
(5)Street Scene数据集。
Street Scene数据集[38]的拍摄场景为某城市街道。该数据集是于2020年提出的,具有相对充足的视频数量,适合基于重构、基于预测和基于分类等方法。目前使用此数据集的论文较少,但考虑到其包含的异常数量和异常类型的多样性,在实际城市街道中会具有较好的泛化性能,后续应该会被众多研究人员使用。
(6)IITB Corridor数据集。
IITB-Corridor数据集[39]是Rodrigues等人在2020年创建的大型数据集。该数据集适合采用回归的方法,结合弱监督学习范式,进行视频级别或视频片段级别的异常检测定位。虽然目前使用较少,但考虑到该数据集包含充足的异常数量和异常种类,在实际人类活动中具有很好的泛化能力,后续应该会被众多研究人员使用。

Table 2 Commonly used single-scene anomaly datasets
5 视频异常检测性能评估
5.1 方法性能评价
(1)混淆矩阵。
当异常样本被预测为异常时,称为真阳性TP(True Positive);当正常样本被预测为正常时,称为真阴性TN(True Negative);当正常样本被预测为异常时,称为假阳性FP(False Positive);当异常样本被预测为正常时,称为假阴性FN(False Negative)。综合上述4个指标可以评价分类方法性能,即为混淆矩阵。
(2)ROC曲线。
ROC(Receiver Operating Characteristic)曲线是基于真阳率TPR(True Positive Rate)和假阳率FPR(False Positive Rate)绘制的曲线,ROC曲线包含的面积AUC(Area Under Curve)通常用于评价方法的性能。
(3)等错误率。
等错误率EER(Equal Error Rate)定义为当真阳率TPR与假阳率FPR相等时,错误分类视频帧所占的百分比。EER值越小,表明异常检测方法性能越好。
5.2 方法性能比较
表3展示了近5年来基于深度学习的视频异常检测方法在UCSD、CUHK Avenue和Subway 3个代表性单场景数据集上的性能。由表3可知:
(1)从整体上看,基于重构的方法在UCSD Ped1数据集上的异常检测效果最好。基于预测和分类的方法在UCSD Ped2数据集上总体表现较好,使用持续学习的回归类方法在该数据集上获得了最高检测精度。相比之下,现有方法在CUHK Avenue数据集上的AUC普遍较低,基于卷积自编码器的分类方法的检测精度最高。而Subway Entrance和Subway Exit数据集相对使用较少。

Table 3 Performance comparison of video anomaly detection methods based on deep learning
(2)基于自编码器的深度学习模型在基于重构、基于预测、基于分类和基于回归4类方法中均被广泛采用。其原因在于大多视频异常检测方法均采用无监督学习范式训练模型。而基于编码-解码表示学习的自编码器在无监督学习范式下可有效学习高维数据的低维表示。
(3)由于表中单场景视频异常检测数据集UCSD、Subway和CUHK Avenue的训练集均为正常视频,且视频中背景相对固定不变,只有前景发生变化,因此适合采用无监督的视频异常检测方法,通过学习正常视频的分布表示可获得较高的检测精度。
6 挑战与展望
6.1 挑战
目前基于深度学习方法的视频异常检测研究主要面临着以下挑战和问题:(1)正常视频和异常视频之间的数据不平衡性。(2)缺乏异常视频的注释,对异常定义模糊。随着现实生活中使用端到端的深度学习方法进行异常检测的部署,一些旧的数据集(如UMN、Subway或UCSD等)已经无法满足深度学习对于训练数据的需求,从而严重阻碍了端到端可训练深度学习模型的发展[56]。(3)基于深度学习方法进行视频异常检测的计算成本较高。(4)深度学习模型对于视频异常检测尚不具有普适性。
6.2 展望
基于上述视频异常检测研究面临的挑战和问题,本文对其未来的研究方向提出了以下展望。
6.2.1 构建更多的数据集
考虑到视频异常检测在实际生活中的应用,从泛化角度出发,未来应该构建更多大规模的、具有丰富异常数量和异常种类并且带有详细异常标签的数据集。现有的视频异常检测数据集大多为单场景数据集,虽然无监督方法在其上取得了较高的异常检测准确率,但是在实际应用中的泛化性还远远不够。例如,对于城市交通监控视频,期望异常检测方法能够对城市内所有交通道路的监控视频进行异常检测而不局限于某一固定街区的道路监控视频。近年来,多场景视频异常检测问题逐渐受到关注,现已发布了UCF Crime[30]、Shanghaitech[57]和XD Violence[58]等包含多个场景的数据集。但是,对于未来的发展,仍需要包含更多异常种类和异常数量的大型数据集。
6.2.2 设计更好的方法
虽然许多先进的深度学习方法都没有对处理速度进行说明,但通过调查发现,尽管目前大多数的方法都能够取得较高的异常检测准确率,但大多数都还不能够实时性部署,其中一个关键原因在于深度学习方法提取视频有效特征的时间成本过高。从实际应用的角度考虑,及时准确地发现异常能够有效降低异常事件造成的损失,所以未来需要设计新的方法进行高效的视频数据预处理和特征提取,进而突破处理速度的限制,使得这些系统能够用于实时的检测场景。
6.2.3 提出更可靠的评估指标
目前绝大多数研究对于视频异常检测的评估均使用帧级别的异常检测评估指标。但是,从实际的应用角度考虑,视频异常检测更应该确定到帧内的异常区域。一些研究人员尝试使用像素级指标,但其使用的像素级指标仍在计数真阳性帧和假阳性帧,而不是真阳性异常区域和假阳性异常区域。现有的像素级评估指标将检测到的异常区域与真实的异常区域重合度超过40%的视为真阳性帧,将检测到至少包含1个像素的异常区域与真实标签为不存在异常区域的现象视为假阳性帧[38]。但这种评估指标既不会奖励局部异常区域的紧凑性,也不会惩罚局部异常区域的松散性。因此,未来需要提出更可靠的评估指标,以评估精准检测到的局部异常区域。
猜你喜欢
哈尔滨工业大学学报(2022年5期)2022-04-19
摄影世界(2022年1期)2022-01-21
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·高一版(2021年2期)2021-03-19
中国生殖健康(2020年7期)2020-12-10
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
领导决策信息(2018年16期)2018-09-27
初中生世界·七年级(2017年9期)2017-10-13
商周刊(2017年6期)2017-08-22
少儿科学周刊·儿童版(2017年3期)2017-06-29
