
基于级联CNNs的非约束车牌精确定位*
2022-09-21 08:36徐光柱万秋波雷帮军吴正平马国亮
计算机工程与科学 2022年9期
徐光柱,匡 婉,万秋波,雷帮军,吴正平,马国亮
(1.湖北省水电工程智能视觉监测重点实验室(三峡大学),湖北 宜昌 443002;2.三峡大学计算机与信息学院,湖北 宜昌 443002;3.宜昌市公安局交通警察支队,湖北 宜昌 443002)
1 引言
车牌自动定位的精确程度决定着后续车牌识别的成败。目前约束场景下的车牌定位技术已经比较成熟,但在开放场景下,因受天气、摄像头角度、拍摄距离、物体遮挡和运动造成的拍摄模糊等不利因素影响,使得这类非约束性车牌的定位问题仍具较大挑战,是近年来智能交通相关领域研究人员关注的热点问题[1 - 6]。
车牌定位常用技术可分为2大类:传统计算机视觉方法和基于深层卷积神经网络CNN(Convolutional Neural Network)的目标定位方法。传统车牌定位方法多采用人工设计的中低层特征,而对于非约束场景下的车牌定位问题,需要应对各种因素,因此需要综合图像的高层语义特征做出判断,传统方法在这个方面有较大局限性。而深层CNN则可以充分利用大数据同步实现层次化特征与相应分类器的学习,理论上具有拟合各类高维空间分类面的能力,因此在图像分析领域得到了广泛关注,越来越多的研究人员开始尝试将CNN用于车牌定位。基于CNN的车牌定位方法根据它们是否需要候选区域获取网络可粗分为单阶段与多阶段2大类:
(1)单阶段[7 - 10]方法通过一个端到端模型直接预测车牌区域。Li等人[7]提出了一种CNN模型,并结合滑动窗口策略对车牌定位,该方法能检测各种类型车牌,具有较高的精度和较快的运行速度,但其训练数据来源于固定摄像头拍摄的图像,车牌倾斜角度变化不大,模型的泛化能力有待评估。Kurpiel等人[8]提出了一种基于CNN的车牌定位方法,该方法通过建模函数为每个图像子区域产生一个分数,并结合稀疏重叠区域的结果来预估车牌位置,该方法在具有挑战性的数据集上精度达到了0.87,召回率达到了0.83。为了解决复杂场景下车牌定位问题,Tian等人[9]提出了一种基于CNN的车牌定位方法,将目标检测问题转化为二值分类问题。该方法使用选择性搜索算法在滑动窗口上生成候选区域,并利用车牌候选框与真实框之间的交并比IoU(Intersection-over-Union)确定正负样本,最后使用支持向量机进行分类。与传统机器学习中的车牌定位方法相比,基于CNN的方法在检测精度上具有明显优势,特别是在复杂场景中的定位精度有了显著提高。Xu等人[10]提出了一种基于CNN的车牌定位与识别模型RPnet(Roadside Parking net),该模型通过共享特征图进行检测和识别,并将检测与识别部分的损失合并进行优化,在所构建的CCPD(Chinese City Parking Dataset)数据集上,多种检测和识别模型的对比评估结果表明,该模型在精度和速度上均具有优势。
(2)多阶段[11 - 14]方法先确定车牌候选区域,再在该区域内定位车牌。为了解决车牌在图像中占比小而不易定位的问题,Kim等人[11]提出了一种多阶段方法:首先,采用基于区域的快速卷积神经网络算法检测车辆区域;然后,结合车牌尺度信息,利用分层采样方法提取候选车牌区域;最后,使用深度卷积神经网络过滤非车牌区域。所提出的方法在Caltech数据集[15]上的准确率为98.39%,召回率为96.83%,优于传统方法。Lin等人[12]也使用基于CNN的方法,先检测车辆,再从车辆中提取车牌,从而减少车牌定位的误报情况。
YOLO(You Only Look Once)[16]是一种通用的能够兼顾准确率与计算速度的目标检测模型,在车牌定位领域得到广泛关注。针对YOLO直接定位车牌效果不佳的问题,Hsu等人[17]通过对模型输出特征图尺寸进行扩大,设置每个网格单元仅预测一个边界框,调整模型预测类别为2类(车牌和背景)等方式,提升了模型在车牌定位上的性能。Montazzolli等人[18]提出一种基于YOLO的CNN网络并以级联方式运行,用于检测汽车前视图和车牌,提高了车牌定位精度,但该方法对倾斜角度大的车牌定位泛化能力还有待提升。当车牌倾斜角度较大时,上述方法获取的车牌区域内会包含大量冗余区域,不利于后续车牌识别。为此,Xie等人[19]提出了一个基于CNN的多方向车牌定位框架,利用旋转角度预测机制确定车牌的精确旋转矩形区域。该方法在定位精度和计算复杂度上均具有优势,但只适合处理平面内的旋转问题,对于三维空间内的倾斜车牌仍然无法精确定位。
虽然基于深层神经网络的非约束车牌定位精度相对于传统方法有了较大提升,但由于这些视觉目标检测方法通常是通过矩形框对车牌进行定位,这在有约束的场景下面向正面角度拍摄的车牌图像有效,但在非约束场景下拍摄角度的多样性会造成车牌无法通过简单的矩形拟合,所获取的车牌区域常包含冗余信息,极大地影响着后续车牌识别的准确度。若能利用CNN直接获取准确的车牌顶点或边界位置信息,则可更加精确地定位车牌。因此,针对非约束场景下的车牌精确定位问题,本文提出了一种基于级联CNNs的由粗到精的车牌精确定位方法,粗定位阶段使用YOLOv3[20]获取图像中所有车牌候选区域,精定位阶段利用改进的MobileNetV3网络[21]将车牌4个顶点的检测问题转换为回归问题,实现精确定位。
2 相关技术介绍
2.1 YOLOv3
如前所述,YOLO是一种主流的单阶段目标检测深层卷积神经网络,该网络通过采用更为有效的骨干网、全卷积方式及多级输出实现了兼顾精度与速度的端到端目标检测。目前应用最为广泛的是YOLOv3[20]、YOLOv4[21]和YOLOv5[22],虽然后两者在YOLOv3的基础上通过增设更多的训练策略、插件模块及后处理方法等技巧进一步提升了性能,但结构更加简洁且直观的YOLOv3仍然是目前使用最为广泛的。
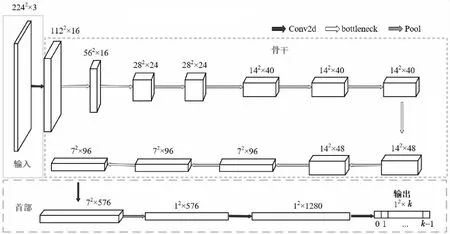
Figure 1 Diagram of MobileNetV3-Small network图1 MobileNetV3-Small网络结构图
YOLOv3网络模型通常包括实现特征提取的骨干、用于特征综合与转换的颈部及用于输出的首部。YOLOv3的骨干网络为Darknet-53模块的前52层,该模块使用大量的残差结构来增加网络深度,提升了模型对深层次特征的提取效果。在卷积神经网络中,深层次特征的表达效果优于浅层次特征,类金字塔模块利用该特点,将主干网络不同层的特征进行融合,提升了目标检测的效果。
2.2 MobileNetV3
MobileNetV3[23]是一种典型的轻量级网络,常用于解决图像分类、语义分割等分类问题。MobileNetV3包括Large和Small 2种网络结构,Small网络相比Large更具速度优势,因此本文在车牌精定位环节选用轻量级Small网络进行改进,使其能够适用于车牌4个顶点相对坐标的回归问题。Small网络模型包含输入、骨干和首部3部分(如图1所示),输入部分包括1个卷积层;骨干由若干个卷积层组成,用于提取特征;首部由3个卷积层和1个池化层组成,用于实现特征综合及输出。
3 基于级联CNNs的非约束车牌定位
为克服以YOLOv3为代表的单阶段目标检测网络所采用的矩形检测框无法准确地拟合非约束场景下车牌区域的问题,同时为了保持YOLOv3模型在车牌定位中的速度优势,本文设计了一种将目标检测网络与顶点定位网络级联的由粗到精的双阶段车牌区域提取系统。通过对轻量级CNN网络MobileNetV3-Small进行适当调整,增加输入卷积层并改变网络输出方式,将车牌4个顶点的精定位问题转换为回归问题,并作为YOLOv3网络输出的后处理模块,以实现车牌精定位,最后利用几何变换实现车牌区域的准确提取。
3.1 基于YOLOv3的车牌区域粗定位
在车牌粗定位阶段,本文选用了能够兼顾速度与精度的YOLOv3网络,所用训练参数如表1所示。网络训练过程中辅以数据增广操作,使得模型能够具有较好的泛化能力,以应对非约束场景下多种不利因素带来的影响。另外,根据定位结果所获得的以车牌区域为主体的感兴趣区域还可有效减少其他非车牌区域对后续精定位阶段的影响,确保轻量级精定位网络的精度和速度。
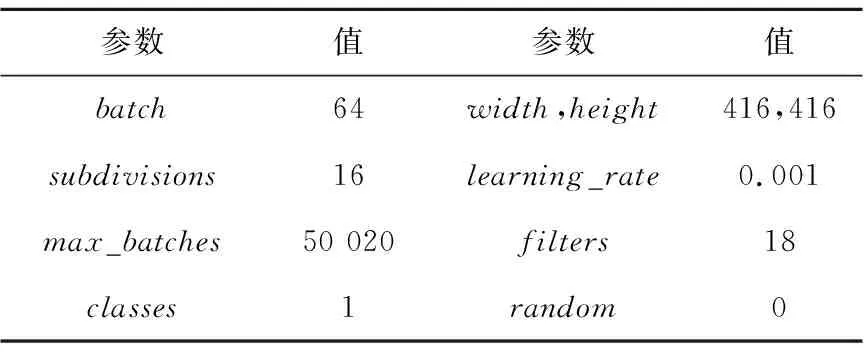
Table 1 Training parameters setting of YOLOv3 model表1 YOLOv3模型训练参数设置
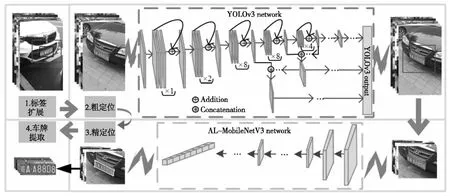
Figure 2 Process of license plate location and extraction图2 车牌定位与提取流程
为了确保粗定位阶段检测到的车牌区域能够涵盖车牌4个顶点,且4个顶点均处于区域内部,本文采用了一种车牌区域边界扩展策略,如图3所示。图3中的内框为车牌的外接矩形,外框为基于内框大小所确定的最终扩展后的包含车牌的感兴趣区域。所训练的YOLOv3模型在粗定位阶段即要实现感兴趣区域的准确定位。扩展策略对尺度不同的车牌目标采用不同的扩展方式,具体如式(1)和式(2)所示:
(1)
(2)
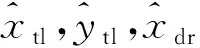

Figure 3 Relationship between target bounding box and circumscribed rectangular box图3 目标边界框与外接矩形框关系
3.2 基于改进的MobileNetV3的车牌精定位
3.1节中的粗定位模块能够给出图像中含有车牌的候选区域,为了能够对这些候选区域中的车牌顶点位置进行精确估计,本文通过对MobileNetV3-Small网络进行适当修改,使其能够回归出车牌4个顶点的相对坐标,实现精确定位。主要改进工作包括:(1)在网络输入部分增设一层3×3的卷积层,在几乎不增加计算量的基础上进一步提升了MobileNetV3-Small网络特征抽取能力。(2)为了能够回归出候选区域中车牌4个顶点相对于该区域的相对位置(均在0~1),本文将原网络输出层中的Softmax激活函数调整为Sigmoid函数,从而将用于分类的网络转换为回归网络来精确拟合4个顶点,且同时保证了4个回归值之间的独立性。为了后续表述方便,本文用AL-MobileNetV3(Accurate Location Mobile- NetV3)来代表改进后的网络模型,网络结构如图4所示。其中输入为固定的448×448×3,实验结果显示,这种分辨率的输入可以满足CCPD数据集[10](详见4.1节)中各种尺寸车牌候选区域的顶点估计。网络的输出为顺时针方向4个车牌顶点相对于输入图像区域左上角的坐标值,其中(x′0,y′0)为车牌左上角顶点相对于图像左上角顶点的水平与垂直方向的坐标;(x′3,y′3)为左下角顶点的相对坐标。

Figure 4 Diagram of AL-MobileNetV3 network图4 AL-MobileNetV3网络结构图
虽然AL-MobileNetV3相对于原模型增设了一层3×3的卷积层,增加了少许计算量,但由于MobileNetV3-Small本身是一个超轻量级网络,配合YOLOv3在GPU下运行完全能够保证实时性,因此增设的一层卷积层对速度几乎没有任何影响,且能够提升网络回归输出的精度。这种具有固定输出的回归网络可以在所有情况下保证车牌顶点的输出,即使是在车牌模糊的情况下,前提是前一阶段车牌候选区域准确有效。这种两阶段分离的方式,具有更好的灵活性,且利于模型改进。另外,由于输出包含4个顶点的坐标,若一个坐标出现异常,理论上还可以根据车牌形状先验知识,排除异常估计值并反推出可能的坐标点。
训练时,本文首先根据所用数据集中的车牌顶点标签重新换算出车牌4个顶点在定位阶段所构建的扩展车牌区域中的相对坐标,然后选择均方误差作为损失函数,如式(3)所示:
(3)
其中,(xi,yi)代表车牌顶点的真实相对坐标;(x′i,y′i)为所用回归网络的相应预测值。所用AL-MobileNetV3模型网络参数设置如表2所示。
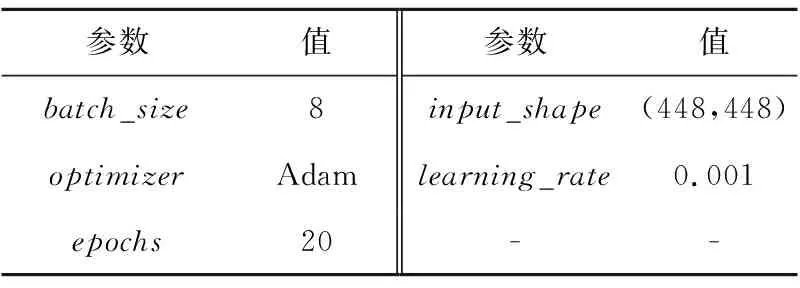
Table 2 Training parameters setting of AL-MobileNetV3 model表2 AL-MobileNetV3模型参数设置
4 实验
4.1 数据准备
为了有效评估本文所提算法性能,采用目前规模最大的开源车牌数据集CCPD[10]开展实验。现使用的CCPD数据集在2018年的版本上进行了一定扩充,包括9个子集,共30多万幅图像,各个子集的划分是根据所处拍摄环境而定的。每幅图像包含车牌外接矩形、顶点坐标和车牌号码等标签信息(NP子集除外,因为其不含车牌),分辨率为720(宽)×1160(高)×3(通道)。和旧版本相比,检测扩充后的CCPD数据集中的车牌更具挑战性。
本文在实验中对所用数据集进行了如下划分:首先将子集Base以随机的方式等分,其中一部分作为训练集(含验证集),另一部分和CCPD中其余子集(NP子集除外)一起作为测试集。在训练时,从训练集中随机取出20%作为验证集,其余80% 用于训练。车牌粗定位阶段和精定位阶段的数据标注信息均以车牌的4个顶点信息为基础进行设定。
在粗定位中,训练YOLOv3网络模型所用的标注框由2个阶段得到。首先,根据原始数据集中车牌顶点坐标信息得到车牌的外接矩形,然后以外接矩形为参考利用3.1节中所述式(1)和式(2),得到用于训练粗定位中YOLOv3网络模型的扩展矩形框。为了便于后续和未扩展框的情况作对比,这里同时还保留了车牌的外接矩形标注信息。图5给出了一些带有标注框的图例,图5a中白色外框为扩展框,内部的灰色小框为根据车牌顶点得到的外接矩形框。
在精定位阶段,根据上一阶段的粗定位结果从原图中截取出相应区域可构成所需训练集、验证集和测试集中的图像,然后换算出车牌4个顶点在所截取的含有车牌的图像框中的相对坐标作为标注信息,图5b为一些带有顶点标注的图例。所用的测试集是从粗定位测试集中那些能够被正确检测出车牌区域的图像中截取来的,这样做的目的是避免粗定位阶段产生的错误对车牌精定位阶段的模型训练造成干扰。

Figure 5 Label examples of datasets图5 数据集标签示例
4.2 实验及结果分析
实验所用软件环境为安装CUDA9.0的Ubuntu 16.04,所用深度学习框架为TensorFlow;硬件设备主要包括2.4 GHz的Intel Xeno ES-2460 CPU,NVIDIA GeForce GTX 1080 Ti GPU和DDR4 64 GB内存。
4.2.1 粗定位实验及结果分析
为了更加可靠地验证粗定位阶段所采用的边界扩展策略的有效性及粗定位的准确性,本文进行了2种对比实验,这里称其为实验A和实验B。在实验A中,先用带有车牌外接矩形标签的数据训练YOLOv3模型;然后再对YOLOv3的输出结果进行边界扩展,得到适用于精定位的图像区域。与实验A不同,在实验B中是用车牌边界区域扩展后的标签信息来指导训练,这样得到的YOLOv3模型就能够直接输出用于后续精定位的候选区域。2种实验所用目标锚框尺寸如表3所示,这是通过K-Means聚类算法对数据集中目标尺寸聚类得到的。实验A和实验B所用的标注框不同(详见3.1小节),造成所训练的YOLOv3学习到的知识在本质上也发生了变化。
由于粗定位的目的是能够鲁棒地找到包含车牌4个顶点的候选图像区域,以便于后续轻量级精定位网络专注于车牌4个顶点相对坐标的回归估计,因此这里没有使用基于检测框的交并比IoU来计算精确率,而选择依据车牌的4个顶点是否被包含在检测框内来统计。若4个顶点均在最终的检测框内则判为正确,否则判为错误。表4给出了2种实验在CCPD中各个子集上的召回率。

Table 3 Size setting of anchors in YOLOv3 model表3 YOLOv3模型锚框尺寸设置
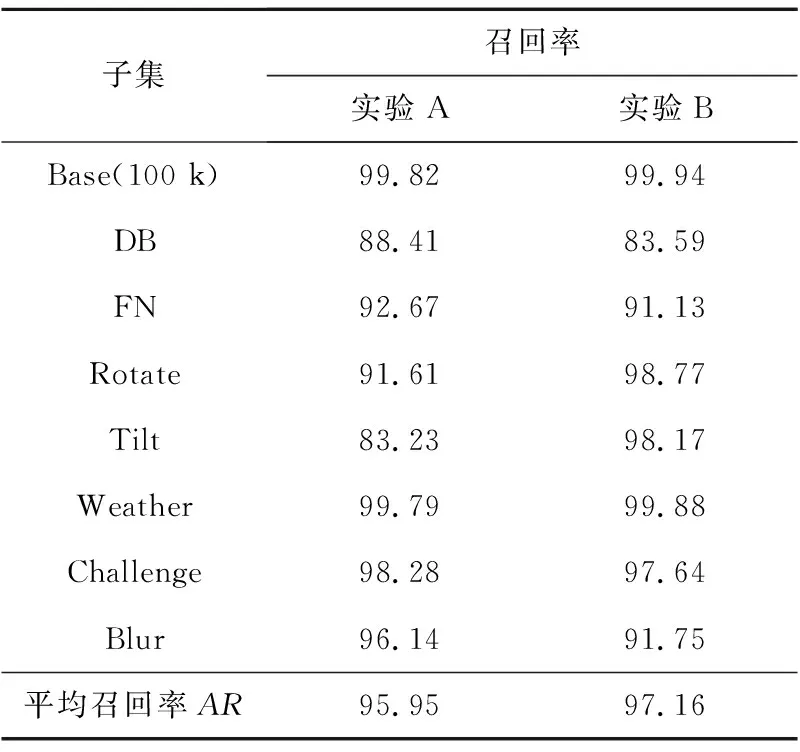
Table 4 Recall of rough location model on each subset
从表4中的数据可以看出,实验A与实验B的平均召回率都在95%以上,除个别子集如DB、Tilt外,在子集上也都能取得高于90%的召回率,这说明所用的2种方法在多种场景下都能较准确地发现车牌。实验B在子集Weather、Tilt、Rotate和Base(100k)上的召回率要优于实验A的;在子集Blur、Challenge、FN和DB上的召回率低于实验A的,但相差不大,均在5%以内,但反观Tilt子集和Rotate子集实验B的召回率要远高于实验A的,分别提升了15%和7%,这说明实验B更能应对车牌拍摄角度的变化。而在平均召回率上,实验B的也优于实验A。对于准确率,从表5中可以看出实验B在各个子集上都能取得优于实验A的准确率,且在Base、Rotate、Weather和Challenge子集上的准确率均高于99%。综合可知,本文实验B中所用粗定位方法在召回率和精确率上都更具优势,验证了其有效性。实验B能够取得更好的粗定位效果说明边界扩充后的车牌数据标签有可能指导YOLOv3模型在学习过程中更加关注车牌和非车牌区域之间的区分,能够在输出的车牌尺寸上以区域中的车牌为核心注意区域。而在DB子集上,实验A和实验B的召回率均小于90%,这主要是因为DB子集包含了一些车牌区域极度昏暗或高光反射的图像,原始标注框也存在一些错误。图6给出了本文所用车牌粗定位方法(实验B所用方法)在CCPD数据集中各场景下的一些正确检测示例,结合表4和表5可知,本文所提粗定位方法能够有效应对各种非约束场景带来的背景干扰、倾斜程度严重和光照条件差等不利因素,取得较好的粗定位检测结果。
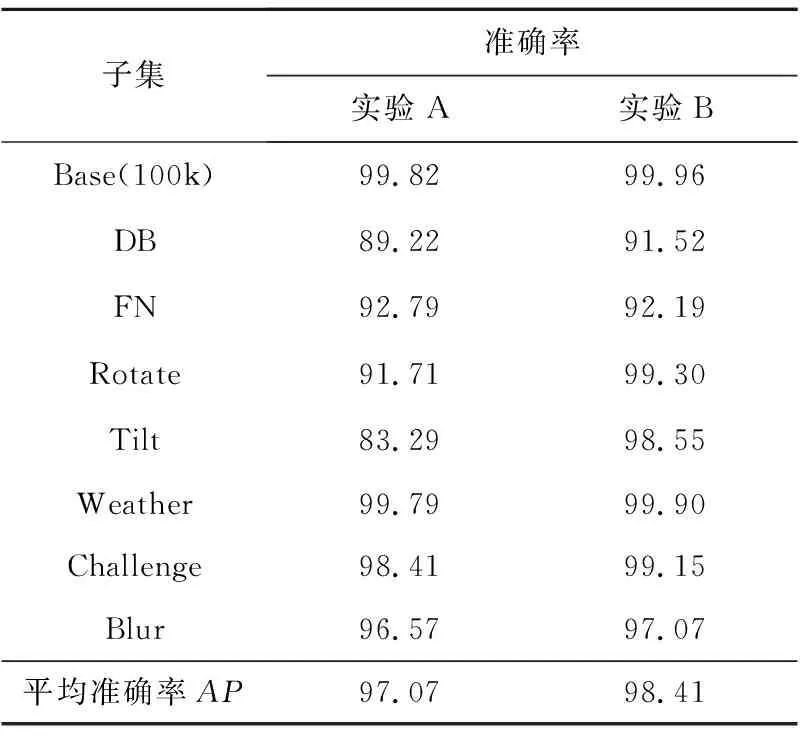
Table 5 Precision of rough location model on each subset

Figure 6 Correct example of rough location图6 粗定位方法正确示例

Figure 7 Incorrect example 1 of rough location:Large label error图7 粗定位方法错误示例1:标签误差大

Figure 8 Incorrect example 2 of rough location:The label is correct,the detection is incorrect图8 粗定位方法错误示例2:标签正确,检测有误

Figure 9 Incorrect example 3 of rough location:No target detected图9 粗定位错误示例3:未检测到目标
图7~图9给出了本文所用车牌粗定位方法在CCPD数据集上因多种原因粗定位失败的一些实例,图中的虚线框表示标注框,实线框表示模型检测输出的粗定位结果。根据情况的不同,失败的情形及其原因主要包括3类:(1)原始数据集中标注信息不准确造成定位错误(如图7所示)。这类问题又存在2种情况:一种情况是原始标注框错误,将非车牌区域标注为车牌,如图7a中虚线框所示;另一种情况是原始车牌标注框过大,如图7b所示。这类图像出现在测试集中时,检测模型即使输出正确结果,也不能匹配标注信息,在计算准确率和召回率时会被误认为预测错误。但是,模型的输出有可能是正确的,从图7a和图7b中的实线框可以看出,模型输出是正确的,但无法匹配标注信息,从而被误判。这类错误可以通过再次清洗原始数据集得到纠正。(2)检测模型自身存在不足,在有些情况下不能够输出正确结果。这类情况也可分为2种:一种是标注框正确,但实际上检测框只包含了一部分车牌区域,车牌信息不完整导致后续精定位失败,如图8a所示。这主要是由于光照条件过差,使得车牌不同区域亮度分布极度不均造成的。另一种是仅有少许车牌边界区域没有被检测框包含,如图8b所示,这种情况在精定位阶段往往能够给出正确结果,但在粗定位阶段被判为定位失败。这可以通过调整判断标准,增设检测车牌实际区域在检测区域的所占比例阈值解决。(3)图像中车牌区域的图像质量太差,存在严重遮挡、极端光照或严重模糊等问题,如图9所示。
4.2.2 精定位实验及结果分析
为了有效评估本文所改进的AL-MobielNetV3在车牌精定位应用中的性能,采用常用的交并比IoU指标(如图10所示)来计算精定位阶段输出的4个车牌顶点构成的车牌外接矩形与实际车牌外接矩形之间的重合度。
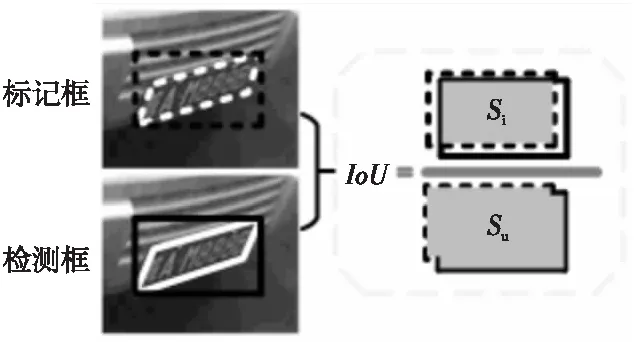
Figure 10 IoU calculation method图10 IoU计算方式
当IoU>0.7时,说明二者重合度较好,定位准确,否则判为定位失败。图10中虚线框均为实际车牌的标记框,其中虚线白框是实际标注的4个车牌顶点得到的外接矩形,通过这个外接矩形,可以得出虚线黑框表示的车牌外接矩形。实线框表示实际检测的结果,实线白框为精定位得到的4个顶点构成的车牌外接矩形,实线黑框为换算出的实际检测到的车牌外接矩形。这种计算主要是为了方便后续和其他基于矩形检测框的车牌目标定位算法作对比。表6给出了精定位模型在CCPD中各个子集上的准确率,可以看出,AL-MobileNetV3在所有子集对应的场景中都能够给出很好的精定位结果,平均准确率为99.62%。在速度方面,没有进一步进行代码优化的情况下,所用精定位模型推理速度约为35.4 fps,能够满足车牌实时检测的需要。
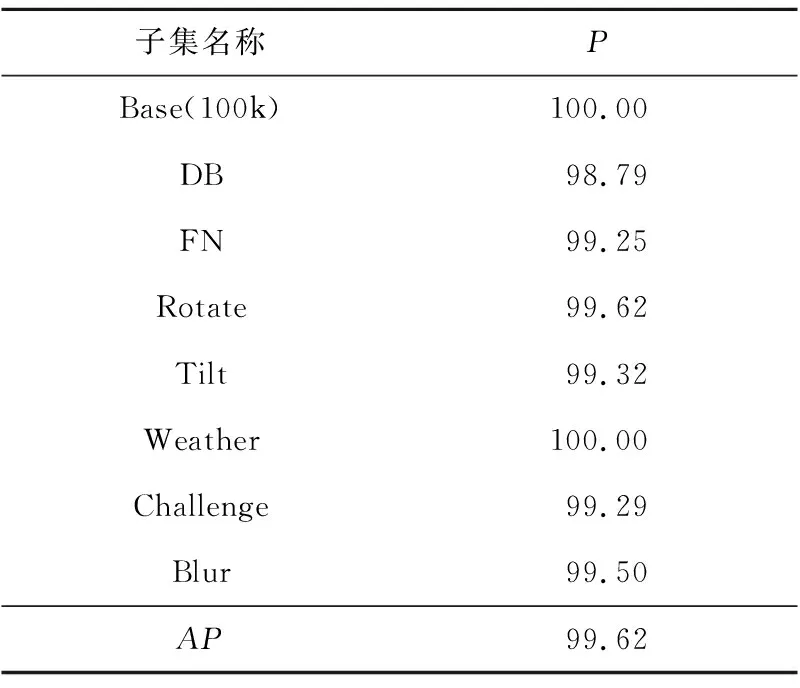
Table 6 Precision of precise location model on each subset
图11为本文所用车牌精定位模型在CCPD各子集对应场景下的一些正确检测示例,可以看出改进的AL-MobileNetV3模型能够较好地应对多种倾斜、光照不佳,甚至是背景干扰大的情况,进而估计出车牌4个顶点的相对坐标值。

Figure 11 Correct examples of precise location图11 精定位模型正确示例
但在有些特殊情况下,AL-MobileNetV3也会出现定位失败或不准的情况,如图12所示,其中白色框为实际检测框,白色虚线框为标记框。这些定位错误可分为3类:(1)原始标记框有误,精定位也示能估计出准确的检测框,如图12a所示。这种错误很可能是因为训练数据集中原始标记数据存在少量不正确的情况,致使AL-MobileNetV3模型在训练时学习到了错误知识。有趣的是,图12a中前2幅定位结果比原始标注框还更加拟合了实际的车牌区域,这也说明模型从其他正确标注的图像中学到了关键知识。(2)标注框正确,检测框有误,如图12b所示。这常发生在车牌图像倾斜角度过大或光照条件极端的情况下,这也说明本文精定位模型在少数极端场景下的性能还有待提升。(3)该类错误是一种伪错误,模型实际输出的检测框是正确的,但由于原始标记数据有误,致使被判定为检测失败。对于第(1)类和第(3)类错误,理论上都可以通过清洗原始数据集、校正不正确的标签信息来得到纠正。第(2)类错误也是一种样本不均衡现象的体现,因为CCPD中各个子集的图像数目不完全均衡且极端情形下的车牌图像数目偏少,致使模型无法学习到所有情况下的判别知识。

Figure 12 Incorrect example of precise location图12 精定位模型错误示例
4.2.3 车牌定位整体结果分析与对比
为了能够更加公平且客观地对本文所提车牌定位算法整体性能进行评测,本文和文献[10,24]中相关数据进行比较,同时施加以下约束:(1)选择与文献[10,24]相同的数据集选取方式。(2)比较时,在粗定位阶段选择实验A所采用的方案,虽然实验B所采用的方案性能更佳,但为了能够保证在粗定位阶段所用训练数据及标签信息和对比方法一致,本文首先选择实验A的方案进行比较。实验A中是先进行车牌直接检测,然后对检测到的车牌区域进行扩展后再输入精定位网络。(3)将车牌目标真实外接矩形框与根据精定位得到的4个顶点反算出的外接矩形之间的交并比IoU作为评判指标,当IoU大于设定阈值0.7时,可判定为定位正确,否则判定为定位错误。
对比表7中的数据可看出,4.2.1节所述的实验A的方案的准确率在Challenge、Weather和Base子集上相比于其他算法,具有明显优势,在FN子集上次优,而在DB、Rotate和Tilt子集上,特别是Tilt子集上表现较差。这主要是由于车牌出现过度倾斜后,当粗定位的矩形框不能准确框住车牌区域时,经过扩展后会使得车牌顶点处于扩展区域的边缘或者不在扩展区域内。而后续精定位模型在训练时的数据均是在粗定位正确的情况下获得的,所以即便进行了区域扩展,在一些特殊情况下精定位输出的结果甚至可能比粗定位还更偏离正确答案。即便是在这种情况下,本文方法在平均准确率AP上也是最优。另外,由于Blur子集中图像模糊,在CCPD原作者文章中没有进行评测[10],因此其他方法也没给出Blur子集上的检测数据,本文所采用的实验A的方案在Blur数据集上也取得了较好的效果。
表8是利用本文所提粗定位方案B结合精定位模型在新版CCPD数据集上的定位结果。相比于文献[10]中的旧版数据集,新版CCPD数据集更具挑战性。如前所述,定位时粗定位方案B,先通过车牌外接矩形得到新的标注数据,然后再进行粗定位,接着将粗定位得到的图像区域输入AL-MobileNetV3进行精定位,最后得出车牌4个顶点的坐标。评测时,再根据4个顶点坐标反算出车牌外接矩形,得到和标注框之间的IoU值,从而计算出准确率。为了全面评估出算法性能,本文还同时计算了召回率。对比召回率和准确率可知,即使是在更具挑战性的新版CCPD数据集上,本文所提出的粗定位方案B结合精定位的方法在所有子集上都能取得较好检测效果,平均准确率可达99.96%,平均召回率可达99.94%。
除精确率与召回率外,本文还同时计算了整个
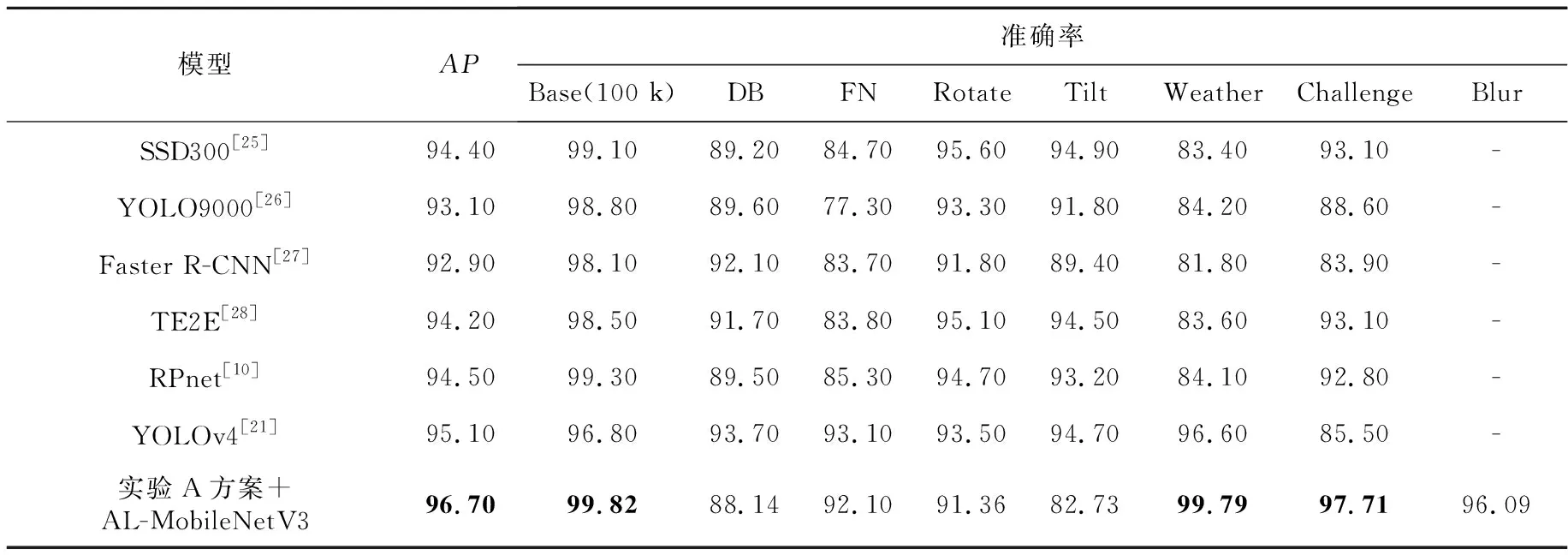
Table 7 Comparative analysis of location precision of each model
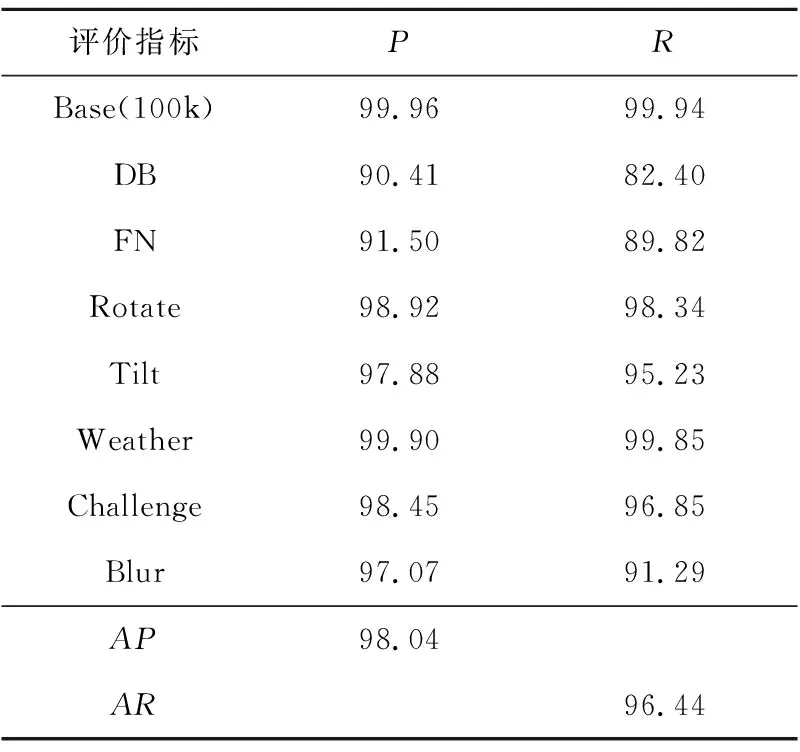
Table 8 Precision and recall of the rough location experiment B+AL-MobileNetV3 method on each subset
算法的计算性能,略去调用函数及装载数据的开销,粗定位环节在CCPD数据集上每幅图像的处理速度在0.03 s左右;精定位环节的处理速度为每幅图像0.028 s左右。精定位中轻量级模型和粗定位中YOLOv3模型的计算速度相近,是因为YOLOv3的实现是基于C版本的Darknet框架,而AL-MobileNetV3则是基于Python版本的PyTorch框架。若都统一在C版本的深度学习框架中,速度还有提升的空间。
4.2.4 几何校正及车牌区域提取
经过粗定位与精定位,可以得到车牌4个顶点坐标,通过透视几何变换可方便地将非矩形区域的车牌图像矫正为矩形,图13给出了一些示例。可以看出,经过校正的车牌区域更便于辨识,对提升后续车牌识别的准确率具有重要意义。

Figure 13 Correction and extraction of license plate图13 车牌校正与提取
5 结束语
为克服基于深层卷积神经网络的主流目标检测网络所采用的矩形检测框无法很好地拟合各种开放环境下车牌区域的问题,本文提出了一种将YOLOv3与轻量级MobileNetV3-Small网络级联实现由粗到精的车牌定位方案。 在粗定位阶段,利用简洁有效的车牌区域扩展办法,提升了YOLOv3模型检测结果的稳健性;在精定位阶段,通过适当修改MobileNetV3-Small网络使其适用于车牌顶点回归问题,在不影响实时性的情况下充分发挥2种网络的优势,解决了非约束场景下车牌的精确定位问题。
从实验结果可以看出,在粗定位阶段,车牌是否完整包含在定位区域中对后续精定位的结果具有重要影响,所以在个别极端情况下会出现粗定位结合精定位得出的4个顶点的外接矩形区域还不如直接用矩形框进行定位准确的情况。后续可以考虑在不影响精定位模型计算性能的情况下,增设额外的输出来对输入内容进行判读,以便于进一步确认输入图像是否满足精定位要求。另外,后续还可以通过迭代的方式筛选出标注错误的样本,对其进行纠正后再训练,以提升车牌定位准确度。
猜你喜欢
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
中等数学(2021年9期)2021-11-22
中等数学(2021年8期)2021-11-22
合肥工业大学学报(自然科学版)(2020年2期)2020-03-23
南京大学学报(数学半年刊)(2020年1期)2020-03-19
电子制作(2019年12期)2019-07-16
小猕猴智力画刊(2017年5期)2017-05-25
电子制作(2017年22期)2017-02-02
都市丽人(2015年4期)2015-03-20
中学生数理化·高一版(2009年6期)2009-08-31
