
基于优化支持向量机的玉米淀粉含量估计
2022-10-21 12:19冯惠妍
科学技术创新 2022年27期
冯惠妍
(黑龙江八一农垦大学,黑龙江 大庆 163319)
淀粉是目前重要的可再生工业原料,我国玉米淀粉约占总产量的80%[1],可以通过化学计量方法,将玉米用0.3%的亚硫酸浸渍后,进行破碎、过筛、沉淀等工序制成和获得含量。而结合近红外光谱技术不需要破坏样品,可获取样品的光谱信息,通过光谱分析可实现对样品的定性判断和定量分析。近红外光谱技术已被广泛应用在农产品检测中。文献[2]结合主成分分析,建立了不同种类淀粉的定性判别模型和基于PLS建立了淀粉混合物的预测模型;文献[3]研究了近红外光谱结合支持向量机检测甘薯粉丝掺假木薯淀粉和玉米淀粉的可行性。因此结合近红外光谱技术,分析近红外光谱数据,实现对玉米淀粉含量的有效估计具有重要实际应用意义。本研究基于玉米近红外光谱数据,以玉米淀粉含量指标为研究对象,拟首先使用多种数据预处理方法及其组合方法进行光谱的预处理,利用主成分分析算法PCA 进行光谱数据特征提取的基础上,再结合使用粒子群优化PSO 算法,实现对支持向量回归算法中的重要参数,惩罚因子C 和核函数参数gamma 的参数寻优,以此构建一个优化SVR 的玉米淀粉的回归预测模型,实现对玉米淀粉含量的有效预测估计。
1 数据准备
公开的玉米近红外光谱数据包括80 个玉米样品,波长范围为1 100-2 498 nm,间隔2 nm(700 个通道),数据列中包括指标淀粉含量值,其最大值66.4 720、最小值62.8 260、平均值64.6 956 以及标准差0.81 559。
光谱预处理在大多数情况下可以改善预测结果,但是有时使用源光谱也可产生很好的结果[4],因此本文首先考虑使用源光谱建立模型。文中选择使用的光谱 预 处 理 方 法 有 源 光 谱、SNV、SNV+SG、MSC、MSC+SNV、FD MSC+SNV+FD[5]。
高维的光谱数据增加了构建模型的难度和复杂度,通常需要从高维的数据中提取出数据特征,研究使用主成分分析PCA 提取出数据主成分[6],简化了数据规模为后续建模做准备。
数据进行特征提取后,使用SPXY(Sample set Partitioning based on joint X-Y distance)算法以4:1的比例划分训练集和预测集。
2 建模及模型评价
2.1 建模
支持向量机(Support Vector machine,SVM)是一种基于统计学理论的机器学习算法,由Cortes 和Vapnik 于1995 年提出,算法尝试寻找具有最大间隔的超平面来区分不同类别的样本,其中间隔定义为不同类别的样本到分类超平面的距离。目前该算法思想已广泛应用于分类和回归问题中,并且大多数情况下运行效果相对较优[7]。支持向量回归(Support Vector Regression,SVR)是使用SVM 来拟合曲线,做回归分析。考虑研究使用的光谱数据的非线性和RBF(Radial Basis Function)实现分类问题的实验效果成功[8],本研究选择RBF 作为SVR 的核函数,RBF 核函数有两个重要的参数:C 和gamma,不同参数所建模型的预测能力不同,可以选择网格搜索实现参数优化,但是耗时长,因此本文选择粒子群优化算法进行SVM的2 个重要参数寻优。
粒子群算法(Particle Swarm Optimization)是由美国社会心理学家J.Kennedy 和电气工程师R.Eberhart于1995 年共同提出[9]。算法的基本思想受到许多对鸟类的群体行为进行建模与仿真研究结果的启发。算法的主要步骤:
(1) 随机初始化D 维空间中的每个粒子的位置x 和速度v。

(2) 计算粒子适应度值F:选择模型预测的预测值与真实值之间的RMSE 作为适应度值F。
(3) 更新每个个体最优值和全局最优值。
(4) 更新粒子的速度和位置。
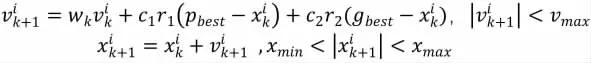
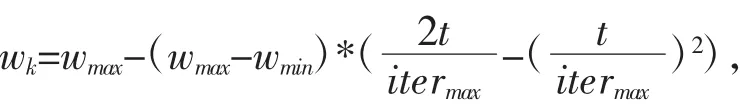

图1 基于PSO 算法优化SVR 的玉米淀粉预测模型
2.2 模型评价
为了评价所建立模型的预测性能,本文采用三种评估方法:均方根误差(Root mean square error,RMSE),RMSE 越小说明模型预测精度越高;决定系数(coefficient of determination,R2)值越接近1,模型稳定性越好;预测相对分析误差RPD[10],Chang 等提出的相对分析误差评判等级:RPD≥2 时,模型具有很好的预测效果,属A 类模型,可用于定量预测;1.4≤RPD<2时,模型有一定的预测效果,属B 类模型,可用于粗略的预测;RPD<1.4 时,模型的预测效果较差,属C 类模型,不能用于定量预测[11]。
3 实验结果
SVM 算法中参数C 和gamma 的设置范围[0.1,100],PSO 算法中惯性权重的最大值0.9,最小值0.4,迭代次数设置为100,粒子个数分别设置为20、30、40、50、60。考虑PSO 算法可陷入局部最优,文中采用重复执行20 次取最好结果为最终的预测结果。不同预处理方法时,模型的预测结果如下:
(1) 源光谱时,PCA 各维度时模型的预测RMSE 及各维度时PSO 算法设置不同粒子数时的预测RMSE 如图2 所示。从图2 中可以得出,当25 维度特征提取时,粒子个数设置为50 时预测集的RMSE最小,不同粒子数时的训练集和预测集的运行结果,如表1 所示,其中粒子个数50 时训练集的RMSE 为0.4732,R2为0.7075,预测集的RMSE 为0.3292,R2为0.6084,RPD 为1.6504>1.4,预测模型具有一定的预测效果。
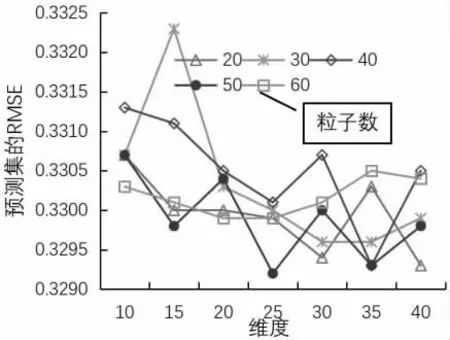
图2 源光谱时模型的预测RMSE

表1 降维25、不同粒子数时模型的运行结果
(2) SNV 预处理时,PCA 各维度时模型的预测RMSE 及各维度时PSO 算法设置不同粒子数时的预测RMSE 如图3 所示。从图3 中可以得出,当10 维度特征提取时,粒子个数设置为50 时预测集的RMSE最小,不同粒子数时的训练集和预测集的运行结果,如表2 所示,其中粒子个数50 时训练集的RMSE 为0.1657,R2为0.9628,预测集的RMSE 为0.2044,R2为0.8853,RPD 为3.05>2,预测模型具有很好的预测效果。
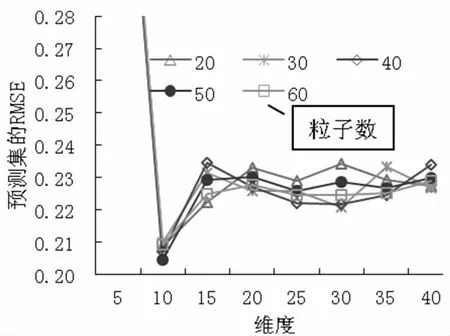
图3 SNV 预处理时模型的预测RMSE

表2 降维10、不同粒子数时模型的运行结果
(3) SNV+SG 预处理时,SG 选取平滑点数为7,多项式次数为3。PCA 各维度时模型的预测RMSE 及各维度时PSO 算法设置不同粒子数时的预测RMSE如图4 所示。从图4 中可以得出,当10 维度特征提取时,粒子个数设置为50 时预测集的RMSE 最小,不同粒子数时的训练集和预测集的运行结果,如表3 所示,其中粒子个数50 时训练集的RMSE 为0.1681,R2为0.9617,预测集的RMSE 为0.2047,R2为0.8850,RPD 为3.0466>2,预测模型具有很好的预测效果。
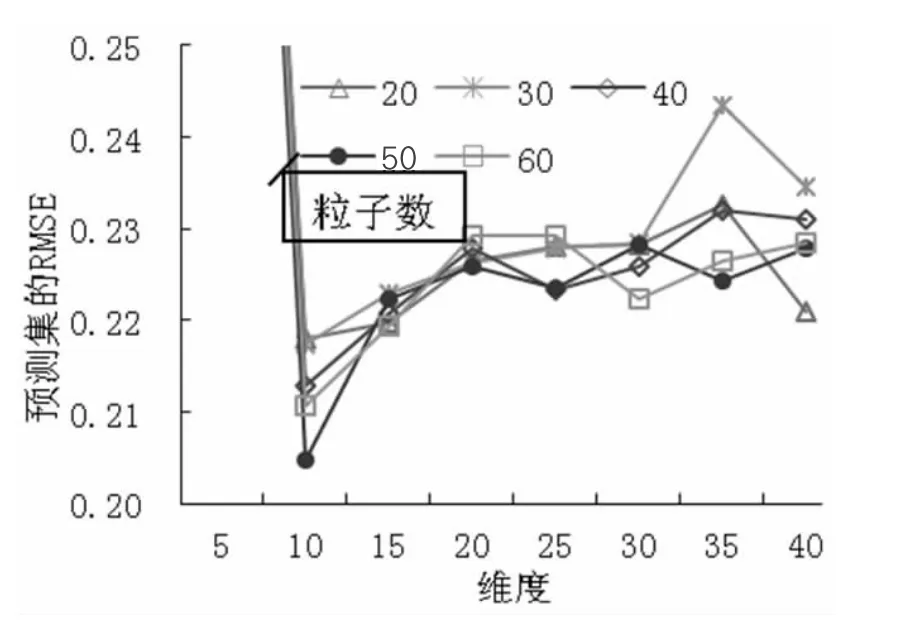
图4 SNV+SG 预处理时模型的预测RMSE

表3 降维10、不同粒子数时模型的运行结果
(4) MSC 预处理时,PCA 各维度时模型的预测RMSE 及各维度时PSO 算法设置不同粒子数时的预测RMSE 如图5 所示。从图5 中可以得出,当10 维度特征提取时,各粒子数设置时预测集的RMSE 几乎相等,不同粒子数时的训练集和预测集的运行结果,如表4 所示,其中粒子个数50 时训练集的RMSE 为0.1754,R2为0.9583,预测集的RMSE 为0.2037,R2为0.8861,RPD 为3.0611>2,预测模型具有很好的预测效果。
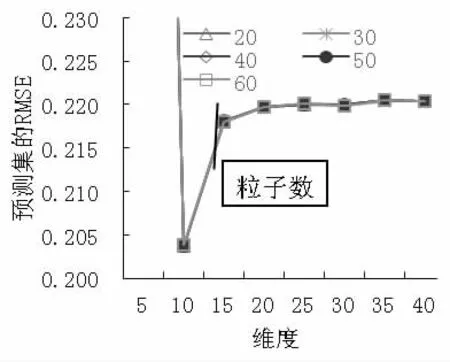
图5 MSC 预处理时模型的预测RMSE
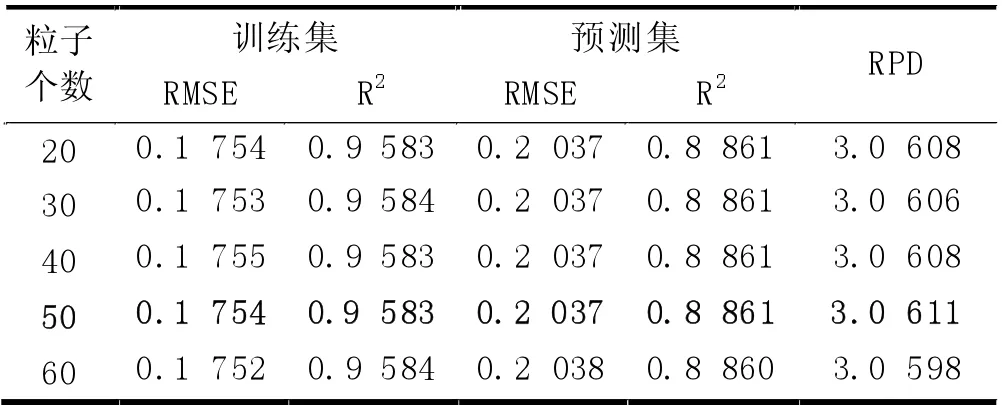
表4 降维10、不同粒子数时模型的运行结果
(5) MSC+SNV 预处理时,PCA 各维度时模型的预测RMSE 及各维度时PSO 算法设置不同粒子数时的预测RMSE 如图6 所示。从图6 中可以得出,当10维度特征提取时,各粒子数设置时预测集的RMSE 几乎相等,不同粒子数时的训练集和预测集的运行结果,如表5 所示,其中粒子个数60 时训练集的RMSE为0.1754,R2为0.9583,预测集的RMSE 为0.2036,R2为0.8863,RPD 为3.0631>2,预测模型具有很好的预测效果。
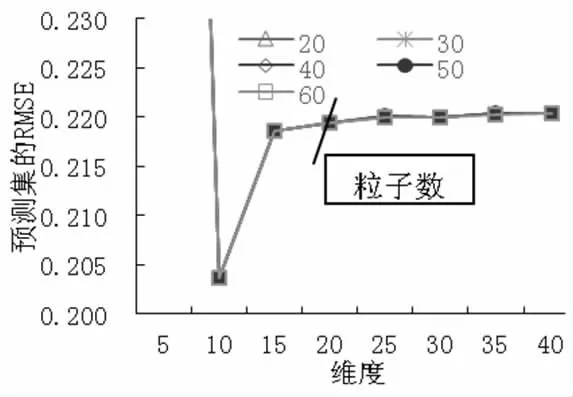
图6 MSC+SNV 预处理时模型的预测RMSE
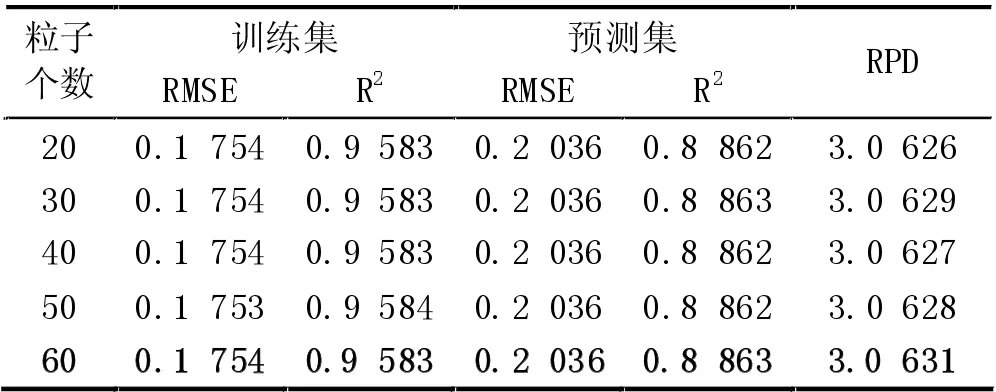
表5 降维10、不同粒子数时模型的运行结果
(6) FD 预处理时,PCA 各维度时模型的预测RMSE 及各维度时PSO 算法设置不同粒子数时的预测RMSE 如图7 所示。从图7 中可以得出,当10 维度特征提取时,各粒子数设置时预测集的RMSE 几乎相等,不同粒子数时的训练集和预测集的运行结果,如表6 所示,其中粒子数60 时训练集的RMSE 为0.6470,R2为0.4393,预测集的RMSE 为0.4014,R2为0.5095,RPD 为1.4747。预测模型具有一定的预测效果,但是预测精度和模型的稳定性相对不高。

图7 FD 预处理时模型的预测RMSE
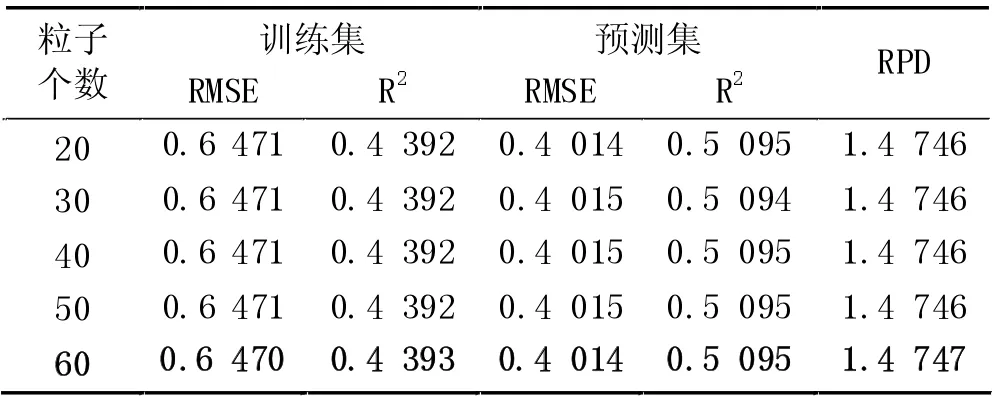
表6 降维10、不同粒子数时模型的运行结果
(7) MSC+SNV+FD 预处理时,PCA 各维度时模型的预测RMSE 及各维度时PSO 算法设置不同粒子数时的预测RMSE 如图8 所示。从图8 中可以得出,当45 维度特征提取时,有最小的预测RMSE,不同粒子数时的训练集和预测集的运行结果,如表7 所示,其中粒子数40 时训练集的RMSE 为0.2329,R2为0.9261,预测集的RMSE 为0.2718,R2为0.7625,RPD为2.1196。预测模型的预测效果良好,但是预测模型的预测精度和模型的稳定性相对不高。
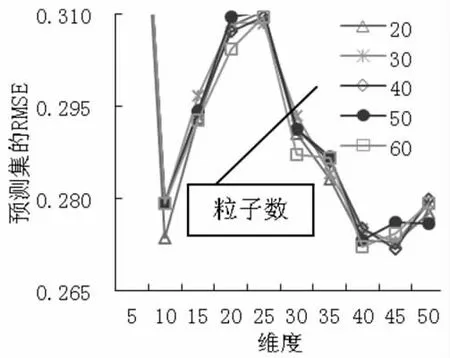
图8 MSC+SNV+FD 预处理时模型的预测RMSE
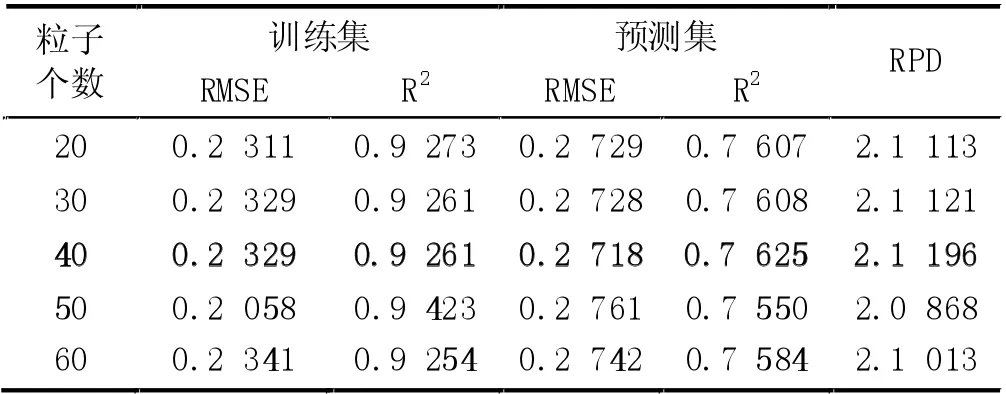
表7 降维45、不同粒子数时模型的运行结果
4 结论
本文基于玉米光谱数据,结合粒子群优化算法,优化支持向量回归模型中的参数C 和gamma,建立了一个用于玉米淀粉含量预测的预测模型。实验对比不同预处理和PSO 算法中设置不同粒子数时的预测效果,从实验结果得出结论如下。
(1) 预处理方法中,选择SNV,SNV+SG、MSC、MSC+SNV、MSC+SNV+FD 的预处理后建立的模型的预测效果均高于未进行预处理,即使用源数据时建立的预测模型的预测效果;而基于FD 的预处理方法建立的预测模型不理想,这也就说明针对本文的光谱数据,选用合适的预处理方法有助于提升模型的预测精度。
(2) 使用PSO 进行SVR 建模的参数优化时,不同的粒子个数设置影响模型的预测效果。进行MSC和MSC+SNV 预处理时的模型预测结果优于预处理是SNV、SNV+SG 和MSC+SNV+FD 时的预测结果。其中MSC+SNV 预处理时,PCA 主成分10 时,PSO 的粒子数为60 时,预测模型最优。
因此,针对玉米近红外光谱数据集,文中提出的PSO 优化SVR 的建模方法能够有效的预测玉米淀粉含量。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
农业技术与装备(2022年6期)2022-08-17
纺织标准与质量(2022年3期)2022-08-10
农业工程学报(2022年8期)2022-08-08
健康体检与管理(2022年4期)2022-05-13
化工进展(2022年3期)2022-04-12
黑龙江大学自然科学学报(2022年1期)2022-03-29
祝您健康·文摘版(2021年3期)2021-03-09
建材发展导向(2021年23期)2021-03-08
饮食与健康·下旬刊(2018年3期)2018-04-11
