
一种基于电力行业的智能视频监控系统
2022-11-03 12:39李鹏鸣王志斐
仪器仪表用户 2022年11期
李鹏鸣,王志斐
(国网漯河供电公司,河南 漯河 462000)
0 引言
目前,国内的电力行业监控大都依赖于人工观看,效率低下且常常会出现不能及时地发现隐患而导致事故的现象出现。因此,如何高效地、及时地将有用的监控信息传递给安全检查人员是目前智能监控系统中亟待解决的问题。随着智能发电以及人工智能的兴起,智能视频监控系统已经成为电力行业主要建设的方向。智能监控系统可以较好地弥补目前电力行业大量存在的数字监控系统的不足,通过计算机AI算法自动判别监控区域内违章的行为并发出报警,并将报警传递给安全员,及时地采取措施来避免事故的发生[1-4]。在电力行业中,由于危险系数较高,存在大量限制行人进出的区域,这样就极大增加了安全巡视人员的工作量,同时也容易出现监管的缺失,而智能监控系统能够自动对出现在视频中的行人及其他运动目标进行检测跟踪,同时对行人是否按照要求采取安全防护措施进行判别,尽量避免人身伤亡以及设备损坏的情况出现[5-7]。
智能视频监控系统主要是对感兴趣区域的图像进行检测及定位,因此定位与跟踪技术是智能监控的主要技术[8]。文献[9]采用帧间差分法与背景减除法实现关键区域行人的提取,实现运动目标的检测。文献[10]采用高斯背景建模的方法对出现在监控区域内的物体进行提取,对提取出来的目标进一步采用HOG+SVM的方法实现行人的判别。文献[11]则采用改进Vibe算法实现了运动目标的提取,采用Adaboost算法进行行人检测,通过卡尔曼和匈牙利算法对检测到的目标进行跟踪。文献[12]采用了一种通过融合自注意力机制来改进Faster R-CNN的目标检测算法,实现了安全帽检测。文献[13]采用面部特征与神经网络相结合的算法,通过多任务级联卷积神经网络提取脸部特征与VGG深度卷积神经网络相结合进行安全帽检测。文献[14]提出了一种基于SSD改进的安全帽检测新方法,实现了现场行人安全帽的快速检测。目前,以YOLO为架构的神经网络模型成为目前施工现场安全帽检测的主要研究方向。
本文以电力行业的实际应用为基础,根据电力行业的实际需求设计了一套应用于电力行业的视频监控系统。该系统以计算机AI为基础,实现了对危险区域的行人监测以及人员是否佩戴安全帽的监测,保障人员和设备的安全,并将违章行为传递给安全监管人员,从而提高监视效率,达到智能监控的目的。
1 基于Vibe算法的运动目标监测
1.1 运动检测
传统的目标监测方法有平均背景建模法、高斯背景建模法,以及三帧差分法。平均背景建模法主要是通过对监控摄像头部署初期,读取摄像头场景下一段时间的数据进行建模。建模完成后,通过对比当前时刻的视频帧与背景帧,找出运动目标。该方法优点是监测速度快,但是对电力行业场景、监控区域的背景会经常变化,因此平均背景建模法不能适用于电力行业的视频监控中。三帧差分法是基于平均背景建模法的改进形式,通过连续的三帧图像实现对运动目标的监测,优点同样是监测速度快,且不受背景变化的影响,但是检测精度不高,容易出现漏检和误检的情况。高斯背景建模法是一种基于统计学的建模法,使用统计学原理对目标图像的前景以及背景进行区分,能够实现对一些负杂场景的背景进行建模,但是其算法较为复杂且极其依赖于第一帧的图像质量。因此,不适用电力行业这种对检测速度要求较高的场景。Vibe建模方法是一种比较新颖的算法,其优点为算法简单,计算速度快,且易于移植。
Vibe背景建模模型是通过对监控图像中某个像素点的像素值(x,y)四周相邻位置的像素点进行计算,算法将当前时刻及以前该像素点像素值作为标准值,当有新的一帧图像时,及t=n时,改像素点的背景模型值为:
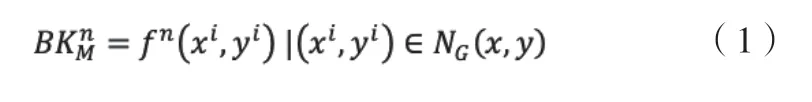
其中,NG(x,y)表示像素点相邻的像素值,f n(xi,yi)表示监控视频帧当前时刻图像的像素值,NG(x,y)中的像素点(xi,yi)被选中的可能次数为L=1,2,3,…N。Vibe算法是根据监控视频第一帧的图像建立样本集,当后续视频帧图像读取后,根据采样集对视频监控场景的背景模型进行迭代。在t时刻,监控图像中某一像素点(x,y)的像素值f k(x,y)根据预先设定好的阈值T来判断该像素点为监控图像中的前景还是背景。
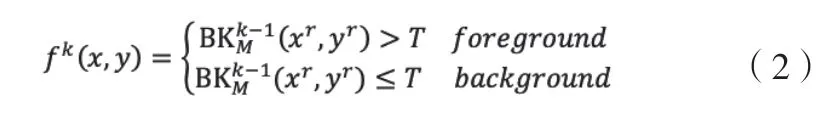
上标r为随机选择的像素,T为设定的阈值,当像素值f k(x,y)大于预设值T时,则判断当前监控图像中该点的像素为前景,否则为背景。同时,Vibe算法也存在更新机制,图像中的所有像素点都根据固定的概率去更新自身的样本值,在更新本像素点像素值的同时以同样的方式去对相邻像素点的值以随机更新的原则更新。这种更新机制可以保证Vibe算法在场景中出现新的背景时快速地更新,提高检测精度。但是Vibe算法同样受监控摄像头所采集的第一帧图像的影响较大,因此本文采用Vibe算法和平均背景建模法相融合的算法,首先采集监控摄像中一段时间的监控图像,通过平均背景建模法作为Vibe算法的初始帧,能够排除初始帧对Vibe算法的影响。
1.2 运动目标跟踪
当检测出来运动目标后,为使检测视频帧显示更加平滑,需要对检测出来的运动目标进行跟踪。在电力行业场景中,由于人流量较大对视频中运动目标跟踪的精度要求不高,但是当视频中的运动目标误入危险区域后,需要快速地将检测结果返送给安全管理人员。因此,智能监控系统需要有较快的响应速度。综合电力行业的实际需求,本文所搭建的智能监控系统采用以卡尔曼滤波和匈牙利最优匹配融合的算法来实现对监控中检测的运动目标进行跟踪。卡尔曼滤波可以对监控中出现的运动目标的当前时刻的位置来实现对运动目标后续可能出现的位置进行预测,因为预测位置可能与下一帧运动目标出现的位置出现偏差。因此,采用匈牙利最优匹配算法去判断预测位置与实际位置的匹配程度,当运动目标的实际位置与预测位置匹配时,再对卡尔曼滤波器进行更新。采用该种跟踪算法虽然跟踪准确性稍低,但是整体计算量小,跟踪速度快,且算法相对简单,便于后期的维护,能够满足当前电力行业对危险区域运动目标检测的需求。
2 安全帽检测
2.1 YOLO网络结构
YOLO是一种新型的网络架构模型,相比较于传统的网络架构模型,其检测速度快,检测精度高,尤其适用于复杂的检测环境。在电力行业场景中需要快速地对违章行为进行检测并上报到安全管理员及时地制止违章行为。因此,本文选择YOLO神经网络架构来实现电力行业施工区域的安全帽检测。图2为YOLO模型的架构,从网络架构中可以看出,模型使用了一系列的卷积层、最大池化下载样层以及全连接层。YOLO网络架构视频检测的核心是将输入的图像分为N×N的区域,对于每个区域给出两个先验框,对于置信度高的格子(即位于物体中心的区域)通过回归任务将两个先验框调整至合适的大小,然后选择IOU指标较大的框作为预测结果。对于安全帽的检测,首先程序读取当前时刻的视频帧,将视频帧分为7×7的网格,每个网格都会生成两个预测框,因此会产生7×7×2共98个预测框,每个预测框都会对应30个向量,网络的输出就是7×7×2×30维的向量。该结构有利于实现不同目标大小的安全帽佩戴检测,最后将特征分别输入预测网络中实现安全帽预测及位置预测。
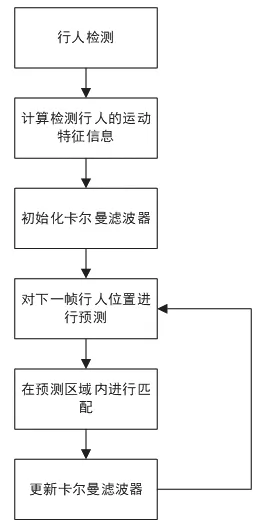
图1 行人跟踪流程图Fig.1 Pedestrian tracking flowchart

图2 YOLO网络层Fig.2 YOLO Network layer
2.2 损失函数
YOLO的损失函数主要有3部分构成,第一部分为坐标损失,把智能监控系统中的视频帧图划分成若干个单元格,YOLO神经网络以单元格为单位对视频帧中的物体进行预测和分类,YOLO神经网络把视频帧中的各个物体进行预测和分类,同时YOLO神经网络会把每个预测物体的边框x,y,w,h标注出来,以便后续处理。第二步置信度损失,YOLO神经网络的置信度损失由两种类型构成:一部分是包含物体时置信度的损失,一个是不包含物体时置信度的损失。因为视频帧中所划分的单元格必须预测预测框和真实框的大小与坐标,所以所有单元格都会产生一个预测置信度分数。置信度损失函数主要有两个评价指标,第一是预测框内是否存在检测目标,第二为预测框的准确度,置信度的公式为:

其中,confidence为置信度,Pobj表示单元格内检测目标存在的情况。当检测目标存在为1,否则为0。第三部分为类别损失,YOLO神经网络会根据所读取的视频帧所预测的物体的数目,确定视频帧中每个单元格所预测的类别与真实类别的偏差构成YOLO神经网络的损失函数。预测过程中与真实值所产生的偏差就组成了YOLO神经网络的损失函数,损失函数由3部分组成:坐标预测损失、置信度预测损失、分类预测损失,因此损失函数的计算公式为:
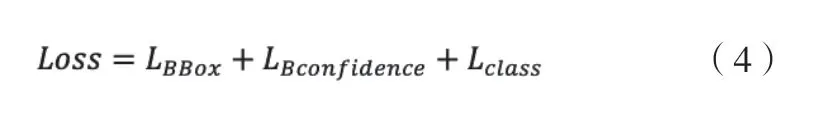
2.3 数据收集与训练
本文基于YOLO网络架构模型对电力行业施工区域内工人是否佩戴安全帽进行检测。本文随机选取在施工区域内佩戴安全帽施工人员的8000张左右的视频帧用作神经网络模型的训练。在训练过程中设置合适的损失函数,以避免在图形训练的过程中过拟合的情况出现。在进行YOLO模型训练的时候,首先需要对用于训练的视频帧进行标注。本文选取专用的标注软件对所有视频集中的安全帽进行标注,将标注好的视频集以统一的格式输入到YOLO神经网络模型中。训练好的模型为一个权重文件,该权重文件可部署到后台,用于后续出现在视频帧中行人是否佩戴安全帽的检测。在电力行业的实际应用中,一般采用双线程的形式来实现安全帽的监测,一个线程用于从厂级监控摄像头中读取视频帧,另一个线程用于安全帽的监测,采用该种架构可以保证采集的精度和速度,进而达到实时的监测效果。模型训练及检测流程如图3。
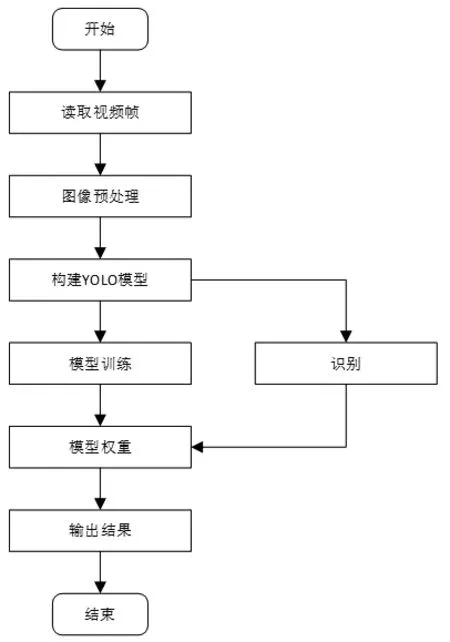
图3 佩戴安全帽行为检测流程Fig.3 Behavior detection process of wearing a helmet
3 智能监控系统设计
智能视频监控系统由监控部分和后台处理算法两部分构成,监控部分主要是对监控视频的数据进行读取并对视频数据进行存储,后台部分主要为智能监控系统所部署的算法,主要分为行人检测以及安全帽检测两部分。系统工程运行在Windows系统上,采用双线程的形式,通过相应摄像头驱动设备提供的接口读取并保存视频帧,同时采用双线程并行运行的方式,每隔一段时间获取一张待检测的样本帧,将样本帧送至后台进行处理,并将处理结果存至特定的缓存目标目录,用于记录日志。其系统结构如图4。
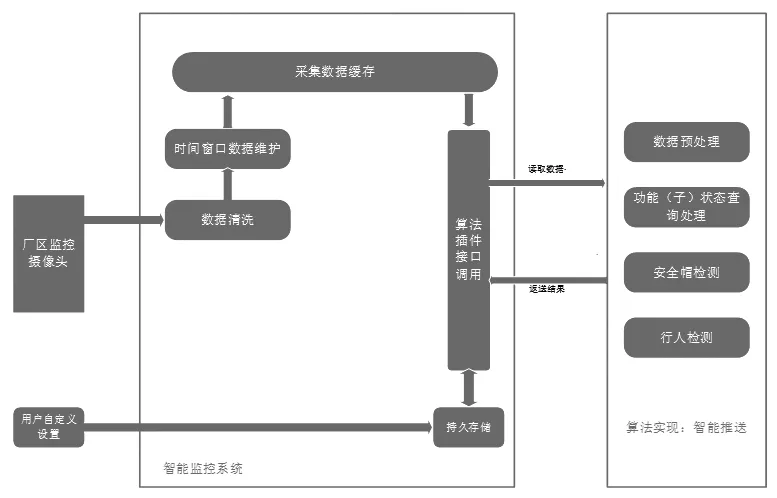
图4 智能监控系统架构Fig.4 Intelligent monitoring system architecture
视频选取某站配电室中的监控视频,监控实验内容为检测监控视频中出现的运动目标。首先,对视频中监控中出现的运动物体进行检测,将运动区域标记为感兴趣区域,对感兴趣的区域进行检测判断是否为行人,如果监测目标为行人,则对监测到的目标进行跟踪,监测效果如图5、图6。

图5 单行人检测跟踪效果图Fig.5 Single pedestrian detection and tracking renderings

图6 多行人检测跟踪效果图Fig.6 Multi-pedestrian detection and tracking renderings
从图5可以看出,当监控范围内出现单个运动目标以后,智能监控系统会自动对监控区域内的运动目标进行跟踪,跟踪效果良好。图6为较远距离的视频监控图像,从图中可以看出,当运动目标较小时,本文所设计的算法依然能够保持对出现在监控区域的所有行人进行检测和跟踪,证明了本文所设计算法的有效性。
对于电力行业中是否佩戴安全帽的行为的检测,本文选取某地施工现场一段监控视频来进行验证。检验内容为对出现在施工现场监控区域内所有的现场人员是否佩戴安全帽的行为进行检测,检测效果如图7。

图7 行人安全帽检测效果图Fig.7 The effect of pedestrian safety helmet detection
从图7中可以看出,无论出现在监控区域内的行人距离监控摄像头的距离如何,本文所采用的模型均保持较好的检测效果。从表1中可以看出,本模型在复杂的施工区域内检测率较高,能够对出现的视频监控区域内行人是否佩戴安全帽进行检测,且对距离摄像头较近区域内安全帽检测准确率较高。当监测区域边缘出现行人时,由于距离摄像头太远,会出现一定的漏检的情况出现。
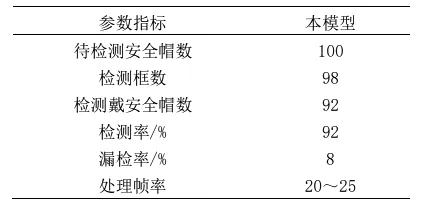
表1 模型性能效果Table 1 Model performance effects
4 结束语
电力行业的智慧化建设离不开智能监控体系的建设。本文通过搭建智能监控体系,通过采用基于Vibe的背景建模法实现了关键区域内运动目标的检测,检测速度快,检测效果良好。通过采用YOLO为架构的神经网络模型,实现了监控区域内行人是否佩戴安全帽的检测,在保证快速性及准确性的同时,实现了电力行业工作范围区运动目标检测以及行人是否佩戴安全帽检测。通过部署在电力行业中的实时监控摄像验证,证明了检测方法的有效性,智能监控有力地保障了电力行业中的行人及设备的安全。未来将在本模型的基础上,对两种算法进行进一步融合,进一步优化系统架构,进一步提高智能监控系统在电力行业施工现场检测的准确率。
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
初中生世界·九年级(2020年2期)2020-04-10
活力(2019年19期)2020-01-06
课外生活·趣知识(2019年4期)2019-09-10
电子制作(2018年17期)2018-09-28
科技与创新(2017年18期)2017-11-30
今古传奇·故事版(2017年5期)2017-04-08
现代企业文化·理论版(2016年14期)2016-10-21
安全与健康(2008年11期)2008-12-27
