
基于激光诱导击穿光谱技术结合机器学习算法的3种干腌火腿产地识别
2022-11-22 07:03黄忠宇周卫东
中国食品学报 2022年10期
郭 茂,黄忠宇,汪 杰,周卫东*
(1 浙江省光信息检测与显示技术研究重点实验室 浙江金华 321001 2 浙江师范大学数学与计算机科学学院 浙江金华 321001)
干腌火腿是我国的传统肉制品,历史悠久,风味独特,种类繁多,受到广大消费者的喜爱,这其中以浙江金华火腿、云南宣威火腿、江苏如皋火腿最为著名。火腿品质的好、坏与产地有着紧密的联系,如余功雄[1]指出:传统的金华火腿之所以长盛不衰,最主要的因素是:以中国名猪种“金华两头乌”的后腿为原料,加上金华地区特殊的气候条件和民间千年世代相传的腌制工艺,使其具有独特的地域性,离开这个特定的地域,是腌制不出真正的金华火腿的。说明对干腌火腿进行产地识别具有重要意义。
迄今为止,国内外已有一些科研人员将多种技术手段应用于干腌火腿的分类鉴别上,如:宋雪[2]分别基于电子鼻(一种电化学传感器阵列)和电子舌(一种味觉传感器阵列)对金华火腿和宣威火腿进行产地识别与品级评定,取得较好的结果。吕晓雷等[3]采用气-质谱联用技术区分不同年份的金华火腿。高韶婷[4]通过红外三级鉴定法分析不同产地和等级间干腌火腿的红外谱图,为不同产地干腌火腿及肉制品的鉴别提供了一种新的方法。姚璐[5]利用电子鼻采集试验数据,分别结合PCA和LDA 的方法较好地区分特级、一级和二级的金华火腿,其中PCA 区分效果好,LDA 显示一级品和二级品之间有少部分重叠,之后,将高光谱成像系统获得的数据结合数据分析软件建立基于高光谱的金华火腿判别模型,训练集和验证集的总体识别率分别为96.19%和89.52%。Laureati 等[6]采用理化分析、电子鼻分析、仪器质构分析、图像分析、感官评定、统计分析等多种方法将帕尔马火腿、圣丹尼尔火腿和托斯卡纳火腿3 种火腿区分开来。Santos 等[7]设计一种氧化锡多传感器系统,在结合人工神经网络后可以鉴别用不同饲料饲养的猪制作的火腿以及不同成熟时间的猪制作的火腿。然而,这些技术方法需对样品进行预处理,难以实现在线实时检测,具有一定的局限性。
激光诱导击穿光谱(Laser-induced breakdown spectroscopy,LIBS)是一种元素分析技术,由一束高能激光激发样品表面使之产生等离子体,其会发射表征样品组分信息的元素特征谱线。LIBS 技术具有适用范围广(可用于固态、液态、气态),对物质损伤小,检测速度快,样品无需预处理或处理简单等优点。目前LIBS 技术广泛应用于钢铁制造及加工[8]、环境监测[9]、生物医疗[10]、深空探测[11]、食品安全[12-13]等领域,具有极大的发展前景。
目前,LIBS 技术在物质的分类鉴别上也得到很好的应用。冯中琦等[14]将LIBS 技术与化学计量学方法结合,可以快速、准确识别航空合金牌号。陈兴龙等[15]在用LIBS 技术取得试验数据后,以主成分作为自组织映射神经网络的输入变量,可对火山灰岩、砂岩、白云岩实现100%的准确分类。於筱岚等[16]利用LIBS 技术结合LDA 判别分析模型,鉴别了不同厂家生产的抹茶和不同杀青方式制成的绿茶粉。Bilge 等[17]利用LIBS 技术对牛肉、猪肉和鸡肉进行研究,在结合PCA 算法后,对3 种肉的识别率达83.37%。目前,将激光诱导击穿光谱技术应用于干腌火腿的分类鉴别还未见报道。
本文使用激光诱导击穿光谱技术对国内不同产地的3 种著名干腌火腿进行分类,探究激光诱导击穿光谱技术结合机器学习算法区分产地的可行性,为后续干腌火腿的快速区分和检测提供新技术。
1 材料与方法
1.1 样品制备
浙江金华火腿,金字火腿股份有限公司;江苏如皋火腿,南通今天食品有限公司;云南宣威火腿,宣威市浦记火腿食品有限公司。
通过人工切片的方式将火腿切成30 mm×30 mm×3 mm 的薄片,尽量选取瘦肉部分。获得如皋火腿样品4 片,金华火腿样品5 片,宣威火腿7片。
1.2 光路图与试验仪器
采用装置如图1所示,激光光源为Plite 200-Ⅱ型双脉冲激光器(北京中科思远光电科技有限公司),输出激光波长1 064 nm,激光能量50 mJ,脉冲频率1 Hz,脉冲宽度8 ns。激光脉冲经反射镜反射后,由1 块焦距为100 mm 的透镜聚焦在样品表面产生等离子体。等离子体发射的特征光由光纤探头收集并由光纤传递至光谱仪 (AvaSpec-2048-USB2 型光纤光谱仪)中,光谱仪采集范围为196~510 nm,积分时间2 ms,光谱分辨率0.09~0.10 nm。激光脉冲和光谱仪采集间的延时由数字信号发生器控制,经试验条件优化,采集延时设置为650 ns。待测火腿切片样品被放在二维移动平台上,可实现激光烧蚀位置的实时调节。
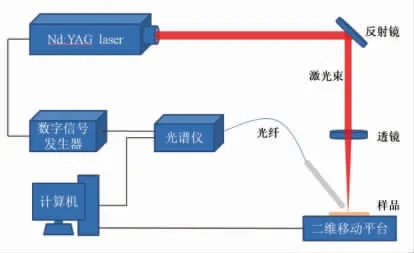
图1 LIBS 试验装置示意图Fig.1 The diagram of LIBS experimental device
1.3 试验步骤
在相同的试验条件下,先、后采集4 片如皋火腿、5 片金华火腿和7 片宣威火腿的光谱。每片火腿正反面各采集150 个点,最终获得如皋火腿光谱1 200 个,金华火腿光谱1 500 个,宣威火腿光谱2 100 个。其中,金华火腿和宣威火腿需采集更多数据的原因:相比于如皋火腿,这两种火腿更难获得有效的LIBS 光谱,因此增加了样本数量。
2 结果与讨论
2.1 数据预处理
为了减少试验数据的波动,尽量排除激光能量不均和样品表面不平整带来的影响,采用最大最小归一化方法(Min-max normalization)对光谱数据进行预处理。最大最小归一化是将原始数据线性映射到[0,1]区间,归一化公式如下:

式中,x——原光谱数据;xmax——原光谱数据中强度最大值;xmin——原光谱数据中强度最小值;x*——最大最小归一化后的光谱数据。
在采集光谱过程中发现3 种火腿在422.752 nm 处都有较强的信号。依据此处的信噪比,每种火腿筛选出信噪比最高的100 个光谱,作为之后机器学习的数据集。
每种火腿筛选出的100 个光谱经平均得到的光谱图见图2。可以发现,3 种火腿的LIBS 光谱比较相似。
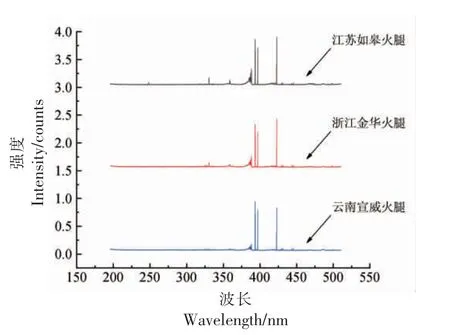
图2 3 种火腿样品的LIBS 光谱图Fig.2 LIBS spectra of three ham samples
2.2 训练集与测试集的选取
训练集与测试集的划分见表1。随机选取每种样品70%的光谱数据作为训练集,剩下的30%作为测试集。

表1 训练集与测试集的划分Table 1 The division of training set and test set
在此必须指出:训练集与测试集的选取是随机的,当选取不同的训练集和测试集时,最终得到的预测正确率也是不同的。在试验中,将算法独立重复多次,以平均正确率作为衡量标准。
2.3 KNN(K 近邻)
K 近邻(K-Nearest Neighbor,KNN)是机器学习中一种基本的分类方法,分类时,对于待预测样本,根据K 个最近的训练样本的类别,通过多数表决的方式进行预测。光谱数据中,每一个波长点对应一个特征。
正如2.2 节所述,训练集和测试集的选取是随机的,由于不同的组合搭配会得出不同的正确率,因此将KNN 算法独立试验了100 000 次,每次都随机选取每种火腿光谱数据的70%作为训练集,30%作为测试集。结果如图3所示。
图3中,横轴代表90个预测样本中预测正确的个数,纵轴代表100 000 次独立试验中某个预测正确个数出现的次数。可以看出,结果基本符合正态分布。对其进行高斯曲线拟合,结果显示均值为63.48,平均正确率为70.53%。其中最优异的一次预测正确77 个样本,最高正确率为85.56%。
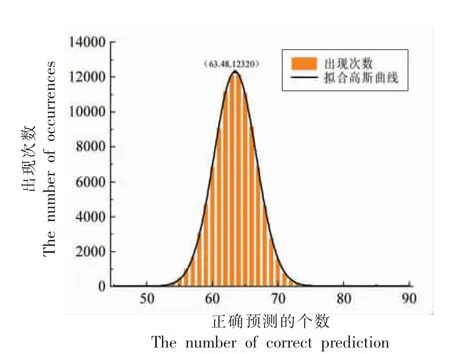
图3 KNN 算法循环100 000 次结果图Fig.3 The results figure of KNN loops 100 000 times
2.4 支持向量机
支持向量机(Support vector machine,SVM)最早在上世纪90年代由Cortes 等[18]提出,是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器。
将SVM 用于多分类问题有多种思路。本文采用一对一(One-versus-one),即每次只针对其中的某两类构建分类器模型。当有N 个类别时,需要构建的分类器模型数量为N(N-1)/2。最终由这些分类器投票,由票数决定最终的类别。该思路不适用于类别数量较多的情况,这是因为会导致需要构建的分类器数量急剧上升。本试验共有3 个类别,只需要构建3 个分类器。
核函数(Kernel function)是SVM 模型的一个重要参数。用与KNN 相同的方法将SVM 用于火腿测试样本的预测。不同核函数的SVM 模型平均预测正确率见表2。

表2 SVM 模型不同核函数的平均预测正确率Table 2 The accuracy rate of different kernel functions of the SVM model
本试验的SVM 模型采用线性核,其独立试验100 000 次结果见图4。
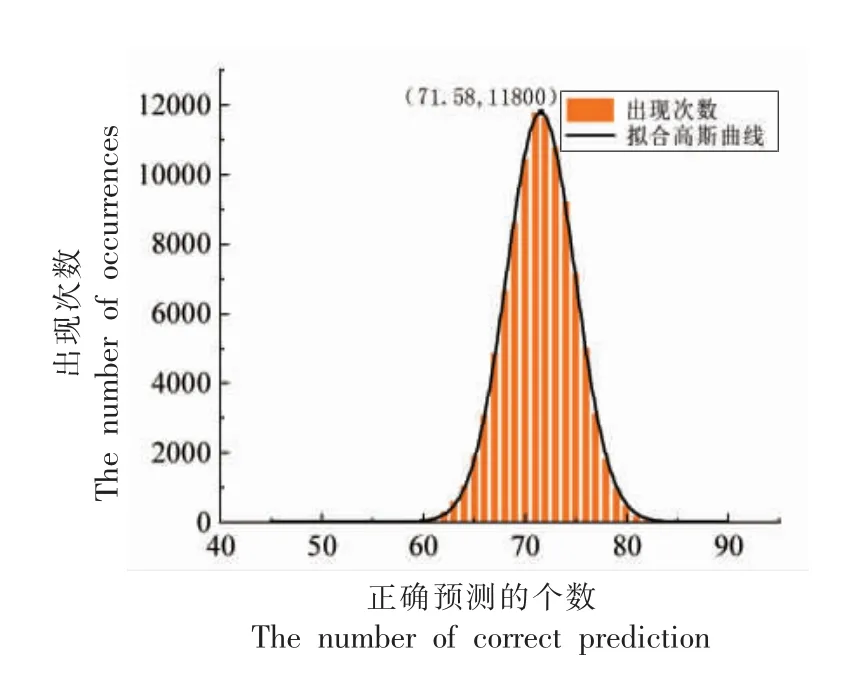
图4 SVM 算法循环100 000 次结果图Fig.4 The results figure of SVM loops 100 000 times
拟合出的高斯曲线均值为71.58,平均正确率为79.53%。其中,最优异的一次预测正确85 个样本,最高正确率为94.44%
2.5 PCA
主成分分析 (Principal component analysis,PCA)是一种常用的无监督学习方法,可以实现对数据的降维。光谱数据常有数千个光谱点,数据量大。利用PCA 处理数据可在有效保留光谱数据信息的同时,减少数据量,增加模型的建立分析速度。
用PCA 处理3 种火腿样品共计300 个光谱数据后,以前3 个主成分得分绘制三维空间散点图(图5)。
其中,第1 主成分(PC1)、第2 主成分(PC2)和第3 主成分(PC3)分别包含了70.32%,3.68%和1.27%的方差信息。
从图5可以看出,3 种火腿存在大量的重叠,难以直接区分。
选取不同个数的主成分,在该条件下分别结合KNN 和SVM,独立重复1 000 次试验,计算平均预测正确率,PCA+KNN 和PCA+SVM 结果如图6所示。
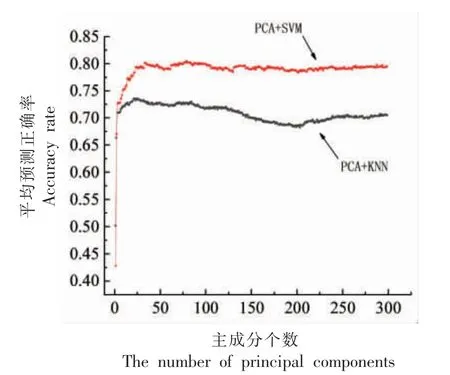
图6 不同主成分数量下的平均预测正确率Fig.6 The accuracy rate of different number of principal components
PCA+KNN 的平均预测正确率在主成分达到22 个时到达最大。PCA+SVM 的平均预测正确率则在主成分达到23 个后开始趋于稳定,在主成分达到79 个时达到最大。
综上,为保证分类正确率同时提升建模分析速度,对PCA+KNN 和PCA+SVM 分别选取主成分22 个和79 个。随后独立重复100 000 次试验,比较最终结果。前22 个主成分包含的方差信息为80.79%,前79 个主成分包含的方差信息为89.13%。
将KNN、SVM、PCA+KNN、PCA+SVM 4 种方法的结果汇总,见表3。
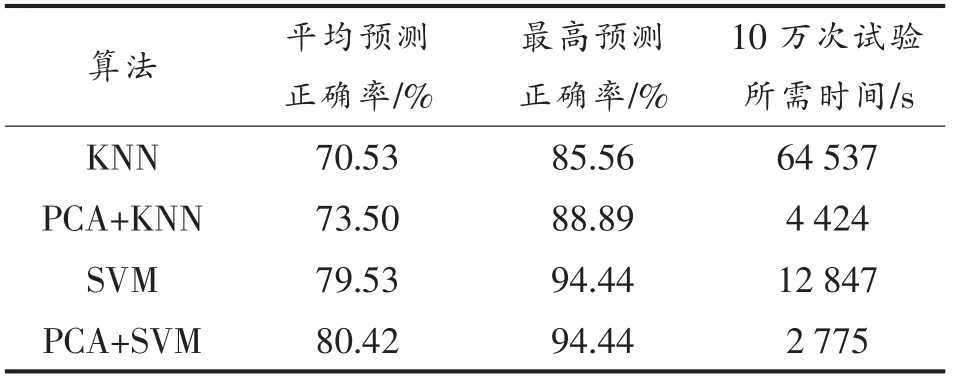
表3 4 种方法结果汇总表Table 3 Summary of the results of the four methods

KNN 在结合PCA 算法后,不论是平均正确率还是最高正确率,均有小幅提升;PCA+SVM 相比SVM 提升0.89%的平均正确率。这是因为PCA 算法降低了计算的复杂度,避免了过拟合现象。此外,PCA 实现了对数据的降维,从而大大加快了建模分析速度,这在物质的快速鉴别中具有重要意义。
2.6 全连接神经网络
全连接神经网络 (Deep neural networks,DNN)是最朴素的神经网络,也是当前广为运用的神经网络之一。相比于传统的神经网络模型,DNN更强调其隐藏层的深度。DNN 的基本原理如图7所示。
图7 DNN 原理示意图Fig.7 The Schematic diagram of DNN
根据采集到的光谱数据的实际情况,建立由输入层、隐藏层和输出层构成的全连接神经网络。处理初始数据并获取属性标签,取学习速率为0.0005,通过ReLU 和Softmax 激活函数完成多分类任务。该网络运行结果见图8。

图8 DNN 运行结果Fig.8 The result of DNN
通过该网络的预测结果可看出,在完成150次训练后,结果收敛到期望的误差,准确率达85.56%,取得较好的结果。
3 结论
利用激光诱导击穿光谱技术结合4 种机器学习算法区分3 种产地不同的火腿。KNN 的平均正确率为70.53%,SVM 为79.53%。对于干腌火腿的LIBS 光谱数据,SVM 算法比KNN 算法具有更高的分类正确率。用PCA 对3 种火腿的光谱数据进行预处理,分别取前22 个主成分和前79 个主成分作为KNN 和SVM 的输入变量,PCA+KNN 和PCA+SVM 的平均正确率分别为73.50%和80.42%,与直接使用KNN 和SVM 相比,分类正确率均有提升,并且建模分析速度大幅提升。利用全连接神经网络构建的分类器,在150 次训练后仍具有最高的分类正确率,为85.56%。本研究结果为干腌火腿的产地快速区分和检测提供了新技术手段。
猜你喜欢
大江南北(2022年11期)2022-11-08
宝藏(2021年1期)2021-03-10
中华养生保健(2020年7期)2020-11-16
保健医苑(2020年1期)2020-07-27
陶瓷科学与艺术(2018年1期)2018-07-13
学苑创造·A版(2017年9期)2017-09-25
家教世界·创新阅读(2016年11期)2016-12-27
天津护理(2016年3期)2016-12-01
英语学习(2016年2期)2016-09-10
故事会(2016年15期)2016-08-23
