
面向用户生成内容的多粒度知识组织研究
2022-11-23 12:03王忠义郑鑫王珂莹
情报学报 2022年10期
王忠义,郑鑫,王珂莹
(华中师范大学信息管理学院,武汉 430079)
1 引言
在大数据时代,网络信息资源已经成为了大数据的重要来源之一。作为网络信息资源中的重要组成部分,用户生成内容(user generated content,UGC)也相应地成为一种重要的大数据资源。UGC是指网络用户通过各种社交媒体平台所发布的信息,包含了大量人们在工作、生活中总结出的经验、诀窍等知识内容,成为人们获取知识的重要来源之一。与传统信息资源不同,UGC以碎片化的形式广泛地存在于各个社交媒体平台。尽管这种碎片化的知识可以帮助人们精准且快捷地获取知识,但就人类的认知规律而言,不利于人们对知识的理解和有效使用以及构建相应的知识体系。从总体上看,人们的知识获取行为符合从局部到整体、从低层概念到高层概念逐步构建知识体系的认知规律。处在不同认知阶段的用户具有不同粒度的知识需求,处在高级认知阶段的领域专家用户往往需要细粒度的知识来优化已有的知识结构,而处在低级认知阶段的普通用户则更需要构建较粗粒度的知识体系。因此,对碎片化的UGC知识进行从点到面、从局部到整体的多粒度组织十分必要。
2 相关研究
2.1 大数据环境下的UGC研究
UGC这一概念在2005年由O'Reilly学者首次提出[1],随后在国内外受到了学者们的广泛关注。总体来说,可以将有关UGC的研究划分为基础理论研究、应用研究以及“碎片化”研究等几个方面。UGC基础理论研究包括内涵研究、生成动机研究、传播机制研究、质量研究、内容分析研究以及法律问题研究等;UGC应用研究主要涵盖了教育、地理、电商、民主政治、公共媒体、图书馆、博物馆等领域;UGC“碎片化”研究可以分为对UGC碎片化现象和内容的研究两个部分,新闻传播领域的学者主要针对“碎片化”现象进行研究[2],计算机科学、图书档案和信息科学等领域的学者主要针对“碎片化”内容进行相关研究,以知识图谱和知识地图的形式结构发现和揭示碎片化知识间的关联[3-5]。总体来说,针对UGC碎片化的研究还相对较少,研究的方向较为单一。
2.2 基于知识元的知识组织研究
知识组织(knowledge organization)的概念最早由美国分类法专家布利斯在1929年提出[6]。在知识组织的过程中,组织单元的选择至关重要。知识元是不可分割的最小知识单元。温有奎[7]和姜永常等[8]通过系统论证,认为知识元应该是进行知识组织的基本单位,姜永常等[8]还具体给出了基于知识元的知识组织流程,包括知识元抽取、知识分类与标引、知识元库和知识仓库构建四个部分[7];陈果等[9-10]提出知识元可以是细粒度的具备语义完整性的知识组织单位[9],并且界定了具有一定领域性特征资源中知识元的概念[10];李锐等[11]以学科已有的层次结构为基础建立知识模块,并将知识模块进一步划分为多个子模块,将子模块看作一个知识元来建立知识组织体系,该方法有一定的参考价值,但对知识元的描述不够准确且适用范围有限。还有部分学者提出了要对不同粒度的知识进行多粒度组织。徐绪堪等[12]将客体知识通过分类和聚类的方式分为不同粒度的知识,结合用户需求对多粒度的知识进行组织;冯儒佳等[13]对科技文献进行了多粒度知识组织建模,对科技文献资源和知识元分别进行了粗、中、细粒度的划分,并建立了不同粒度资源和知识元之间的映射,实现了基于科技文献的多粒度知识组织和集成。
2.3 面向UGC的知识组织研究
当前面向UGC的知识组织研究相对较少,根据组织对象的不同,主要可以划分为两个部分:面向UGC文献的知识组织和面向UGC内容的知识组织。
面向UGC文献的知识组织主要是借助相关的词表或构建相应的领域本体知识库对UGC文献进行知识组织。丁文姚等[14]结合FOAF(friend-of-afriend)词表对UGC用户信息进行组织。么媛媛等[15]基于本体理论构建UGC、用户和发布平台三个元概念及元关系构建了一套UGC元数据标准模板。胡华[16]提出了结合UGC信息源中半结构化的维基百科信息和UGC信息源中非结构化的文本资源信息的本体构建方法体系。陈果[9]在构建领域知识库的基础上,结合知识库中的语义关联以及UGC资源中的共现相似度生成知识元链接,对UGC文档中的知识元进行了标识并建立了和文档资源的链接。唐晓波等[17]基于词性规则和中心词进行概念和概念短语的抽取,应用互信息和左右信息熵的统计方法进行概念过滤,建立了基于UGC信息源的本体概念抽取模式。郑姝雅等[18]提出了一套自动构建UGC本体的方法,完成了领域UGC本体的自动构建。
面向UGC内容的知识组织主要从主题角度出发进行知识组织,需要借助各种主题模型来确定文档-主题以及主题-词之间的概率关系。赵华[19]基于主题模型构建了UGC主题层次体系,结合用户建模和社区发现建立三维度关联并对UGC进行信息组织。金碧漪[20]对来自大众普遍使用的社交媒体上的多种疾病数据进行采集分析,提炼健康主题,提取特征词汇及特征词间关系,最终构建了消费者健康知识图谱。陈晓威[21]以话题为基本知识单元,借助LDA(latent Dirichlet allocation)主题模型生成社会化问答平台“文档-主题”概率矩阵,并通过二元图投影构建知识网络模型。
综上,通过对相关研究进行梳理和分析后发现,目前图书情报学领域关于UGC的相关研究较少,特别是在UGC内容组织方面,还缺乏较为系统和成熟的研究。已有的UGC知识组织研究多侧重于从概念层次或利用主题模型来对UGC中的知识进行组织,前者对知识的描述形式过于单一,粒度过粗,后者在海量的碎片化UGC内容中存在很大的主题漂移风险;且已有的面向UGC的知识组织研究中较少考虑人的认知规律,难以提供个性化服务。为此,如何在已有组织方法的基础上探寻新的符合UGC特点和用户认知规律的知识组织方法成为UGC知识组织研究的一种发展趋势。
3 面向UGC的多粒度知识组织模型构建
在上述分析的基础上,本课题组提出了基于碎片化UGC的多粒度知识组织模型[22]。如图1所示,该模型自下而上分为三个模块:碎片化UGC知识元抽取、碎片化UGC多粒度关联、碎片化UGC多粒度索引。①碎片化UGC知识元抽取。先借助知识要素抽取算法,从碎片化UGC中抽取组成知识元的知识要素,接着借助改进的K-means方法对知识要素进行聚类,得到知识元的属性特征,最后根据知识元描述模型生成面向碎片化UGC的知识元。②碎片化UGC多粒度关联。先借助概念匹配方法发现知识元之间的等同关联,然后利用多阶关联分析方法发现知识元之间的非等同关联。③碎片化UGC多粒度索引。先基于RDF(resource description framework)描述框架建立面向UGC的细粒度的知识元索引,然后在此基础上生成粗粒度的“概念→知识元”索引和概念索引,通过多粒度索引可以为UGC用户提供多粒度的知识检索服务。接下来,本文将详细论述各部分的具体实现过程。

图1 碎片化UGC多粒度知识组织模型[22]
3.1 UGC知识元抽取
知识元的抽取是知识组织的基础,为从碎片化的UGC中抽取出能够完整表达知识内容的最小单元,本课题组结合UGC文本的特性,基于知识元抽取的相关理论提出了一种面向碎片化UGC的知识元抽取方法[23],具体的抽取流程如图2所示。
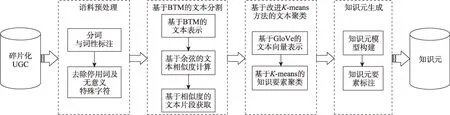
图2 碎片化UGC知识元抽取流程[23]
(1)语料预处理。此阶段主要任务是对语料库中的UGC文本进行分词和停用词处理。UGC文本用词随意,因此包含很多无意义的特殊字符,如表情的转换字符、错词等,需要去除。
(2)基 于BTM(balise transmission module)的文本分割。先根据Gibbs采样算法构建BTM模型;接着由BTM模型推导出UGC文本的主题分布[24],即文本的主题向量;最后由主题向量的余弦相似度计算文本之间的相似度。对于相似度达到阈值m且与线索词所在语句相邻的文本,将其合并为一个文本片段,即知识要素的具体内容;若未达到阈值m,则中止相关文本片段搜索,文本分割完成。
(3)基于改进K-means方法的文本聚类。为了克服传统TextRank方法存在的不足,本文选取中文维基百科数据作为GloVe(global vectors)词向量训练的语料生成GloVe词向量,基于GloVe词向量[25]对文本片段进行向量化表示。将文本片段的GloVe向量作为K-means输入值,通过计算余弦相似度完成聚类中心初始化,然后进行知识要素聚类并测试不同的K值以获取最佳聚类个数。
(4)知识元生成。知识元生成包括两个步骤:知识元模型构建和知识元要素标注。在知识元模型构建中,本文定义了一个四元组来对知识元进行描述,即<id,标识词,属性,知识要素>。知识元要素标注主要是基于知识元模型,对从碎片化UGC中识别的知识要素进行标注,进而完成知识元的构建。
3.2 碎片化UGC的多粒度关联构建
为实现碎片化UGC的多粒度关联构建,本文先借助概念匹配方法构建知识元间等同关系关联,然后借助多阶关联分析方法构建知识元间非等同关系关联,最终形成碎片化UGC的多粒度关联体系。
3.2.1 知识元等同关系关联
当两个知识元之间具有相同或相近的含义时,判定这两个知识元之间具有等同关系的关联。本文借助概念匹配的方式识别知识元之间的等同关系,通过对两个知识元中所包含概念进行相似度计算来判断。具体来说,本文借助已有的知识组织体系,将其中的等同和相近概念作为语料库,对知识元标识词进行概念匹配,若两个知识元标识词均匹配到同一概念,则判定这两个知识元之间存在等同关系。在完成等同关系关联后,对抽取后的UGC知识元描述模型加以扩展,即为KS=(id,标识词,属性,知识要素,概念关联集),概念关联集为上述操作后所形成的概念网络,具体可描述为概念关联集=[(c1,c2,s1),(c1,c3,s2),…],其中c1、c2、c3为概念,s1、s2为关联,(c1,c2,s1)意为c1和c2以s1关系相关联。然后进行知识元间等同关联的构建。具体来说,是对UGC中存在等同关系的知识元建立等同关联。相应地,知识元模型中的知识要素和属性共享,概念集中的标识词可互相替换。例如,设知识元A=(id1,标识词c,属性a,知识要素kn1,概念关联集=[(c,c1,s1),(c,c2,s2)]),知识元B=(id2,标识词c′,属 性b,知 识 要 素kn2,概 念 关 联 集=[(c′,c3,s3)]),如果标识词c和标识词c′概念匹配为等同关系,那么知识元A将具有知识要素kn2和属性b,并在其概念关联集中添加(c,c3,s3)。同理,对于知识元B而言,其也将具有知识要素kn1和属性a,并在其概念关联集中添加(c′,c1,s1)和(c′,c2,s2)。知识元A和知识元B的关联如图3所示。
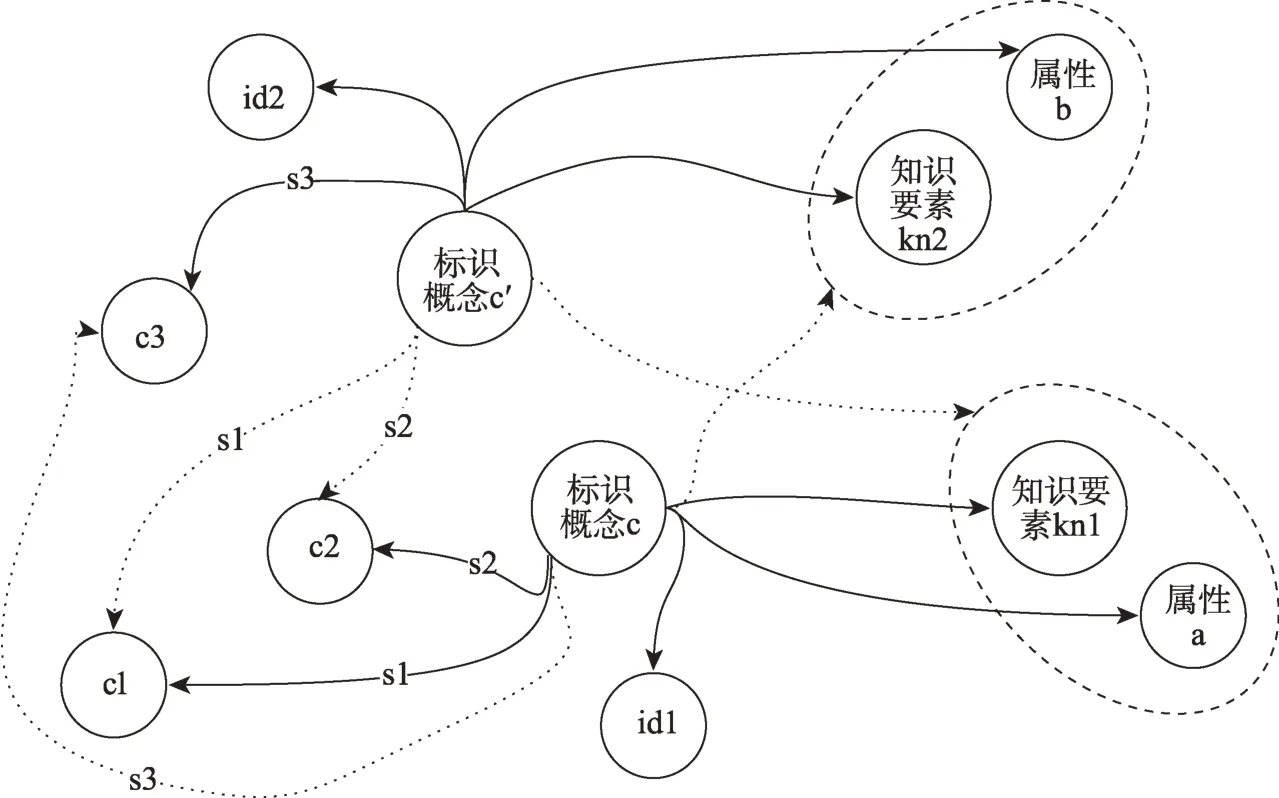
图3 UGC知识元等同关联示例
3.2.2 知识元非等同关系关联
当两个UGC知识元之间存在关联但不满足概念匹配的条件时,即判断这两个知识元之间存在非等同关系。本文中对非等同关系的判断借助于多阶关联分析的方式,该方法主要包括知识元标识词对提取、二阶知识发现、三阶知识发现和关联强度计算等。知识元标识词对提取的主要任务是依据非相关知识元的知识表示模型,从非相关知识元中抽取出标识词,构建主题词对。二阶和三阶知识发现的主要功能是挖掘出非相关知识元之间可能存在的各种潜在关联关系(图4)。二阶(实线部分)和三阶(虚线部分)知识发现流程为:①以非相关知识元a为起始知识单元,发现所有与知识元a相关联的中间知识元b;②将中间知识元b和目标非相关知识元c的标识词组成主题词对进行共现匹配,若匹配结果不为空,则记录知识元b和c之间的共现频次;若匹配结果为空,则说明知识元b和c之间不存在关联,返回,继续以中间知识元b为起始点,发现所有与知识元b存在共现关系的中间知识元d;③将中间知识元d和目标知识元c的标识词组成主题词对进行共现匹配,若匹配结果不为空,则记录知识元d和c之间的共现频次;若为空,则说明知识元d和c之间不存在关联,终止整个循环;④依据二阶和三阶关联发现的结果,构建起始知识元a和目标知识元c之间的链接,借助相关推理规则或公式分析出非相关知识元a和c之间的关联类型。
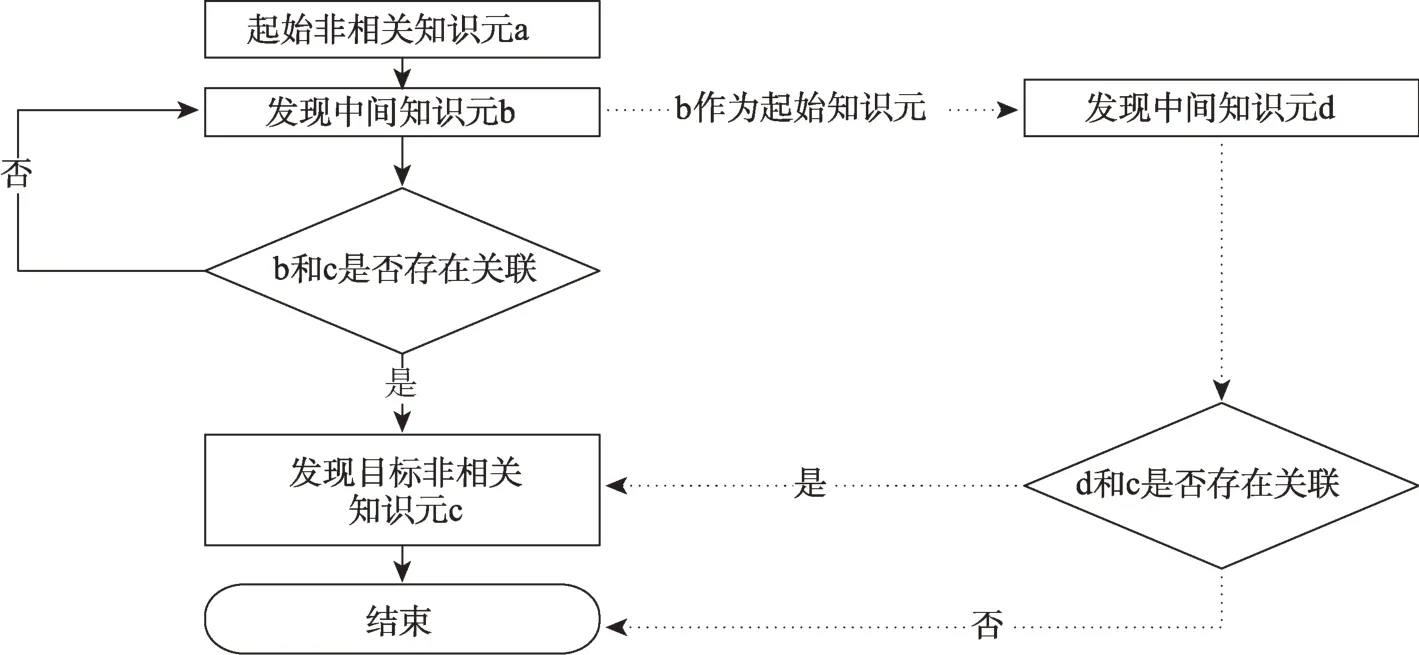
图4 多阶关联分析流程
关联强度计算的主要功能是基于非相关知识元之间的共现关系,计算两个非相关知识元之间的相关强度,即,
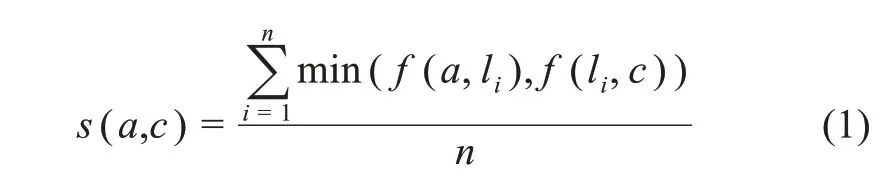
当两个非相关知识元的相关性程度低于阈值时,舍弃;当两个非相关知识元的相关性程度超过一定的阈值时,在它们之间建立关联关系,从而实现非等同关系的发现。其中,n为中间知识元的个数,n=1,表示二阶知识发现,n=2,表示三阶知识发现;li为中间知识元;f(x,y)表示知识元x和y的直接关联度,其计算方法为
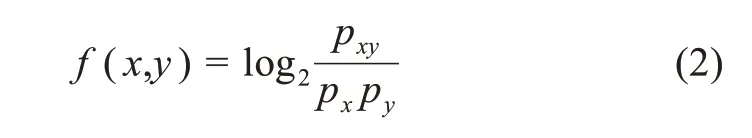
其中,pxy为标识词x和y在各种粒度大小的知识元中共现的概率;px、py分别表示标识词x和y出现的概率。pxy的计算方法为
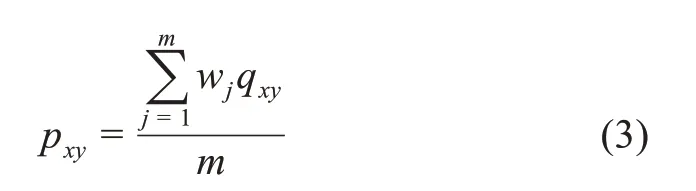
其中,m为知识元粒度划分的类别个数;qxy为标识词x和y在相同粒度大小的知识元中共现的概率。
3.3 碎片化UGC多粒度索引
为实现对碎片化UGC建立语义层面的多粒度索引,本文依据语义索引模式提出了面向碎片化UGC的多粒度索引方式,如图5所示。首先,以UGC知识元描述模型为基础构建细粒度的知识元索引,以多粒度关联为基础构建粗粒度的概念-知识元索引和概念索引,三者结合构成面向碎片化UGC的多粒度语义索引模式;其次,用户在输入检索词表达检索需求后,先对检索词进行基本处理,然后在知识元索引中搜寻相关知识元内容,再根据概念-知识元索引获取命中知识元的对应概念,接着根据概念索引完成知识元概念层的定位;最后,返回命中知识元和其知识元概念层级结构,呈现详细知识元语义信息,且在此基础上用户可点击知识元结构中的概念描述集和知识元关系关联图,将以在三种语义索引中搜寻的方式返回检索结果,实现不同粒度知识元间的相互跳转,从而在语义层面上深入扩展用户检索需求。
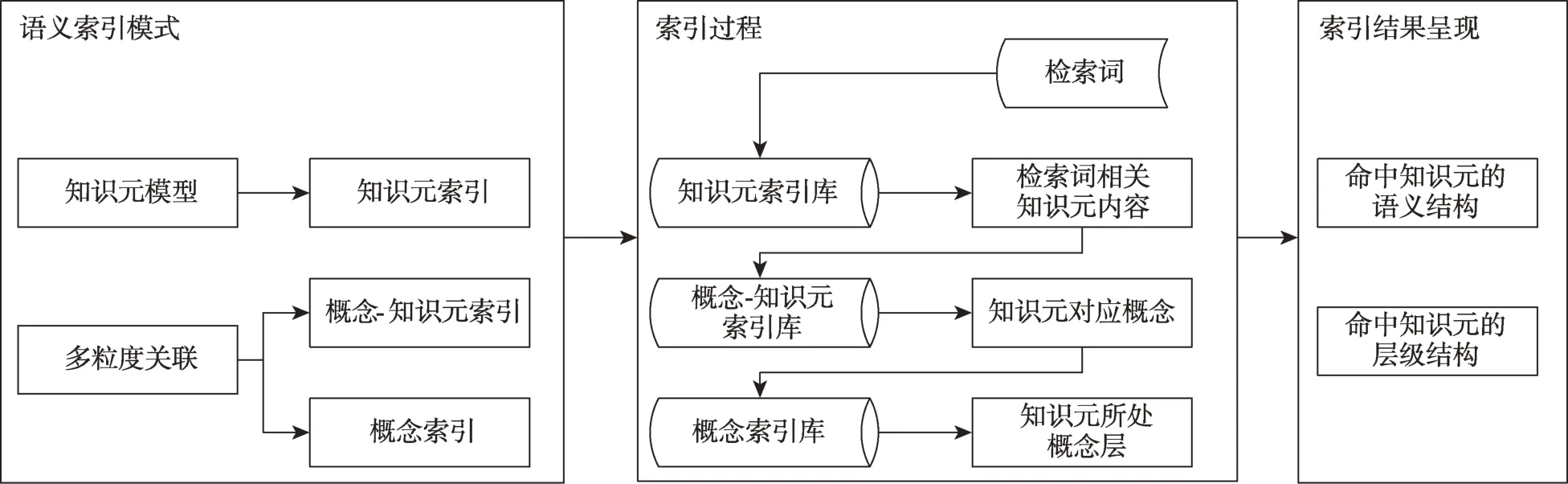
图5 碎片化UGC多粒度索引
3.3.1 细粒度的知识元索引
知识元是UGC的基本知识单元,是细粒度的知识构件,建立知识元索引将满足对细粒度UGC知识的检索需求。UGC知识元描述模型及其扩展概念关联集是构建知识元索引的基础,RDF描述框架则为具体的索引实现提供描述方式。本文选择以RDF为描述框架,依据UGC知识元描述模型对知识元建立索引,如图6所示。

图6 知识元索引
具体来说,UGC知识元模型表示为五元组,即(id,标识词,属性,知识要素,概念关联集),id、标识词、知识要素和属性都可以直接表示为(主体,谓词,客体)的三元组形式,其中属性描述的是知识要素的特征,因此,其三元组形式为(知识元,属性,知识要素)。概念关联集是知识要素中的概念及其关联的集合,因此,其三元组中的谓词为概念关联集类型,客体为概念关联集,概念关联集中又包含概念关联所转换的三元组,比如,若知识元G的概念关联集为[(c,c1,s1),(c,c2,s2)],则概念关联集所转换的三元组为(知识元,概念关联集,[(c,c1,s1),(c,c2,s2)])。综上,基于RDF描述框架对UGC知识元完成三元组描述。
UGC知识元转换为基于RDF的三元组描述方式后,就能够根据主体、谓词和客体建立知识元索引。一个UGC知识元可转换为多个三元组,三元组属性中含有知识元中的某个特征项,将所有主体作为一个虚拟文档索引单位建立倒排文档,将主体里的内容作为索引对象,谓词和客体以同样的方式建立索引。知识元索引除了对知识元模型参数建立索引之外,还需要对知识元的直接关联知识元建立索引,例如,若知识元K1与知识元K2之间存在关联s,则有三元组(K1,s,K2),建立索引时K1与K2为知识元唯一标识符。
3.3.2 粗粒度的概念索引
知识元索引能够对UGC知识元进行三元组检索,检索知识元的各项属性和特征,并且能够索引与知识元直接关联的其他知识元。但其从单个知识元出发,对知识元关联的特征标引只考虑了直接关联,对整体知识元关联结构的标引不充分。为了提升UGC多粒度关联标引的效率,本文提出了构建粗粒度的概念索引来解决这一问题。概念索引是UGC知识元在概念层的关联索引。概念索引具体分为概念-知识元索引和概念索引两部分,如图7所示。

图7 概念索引
概念-知识元索引所标引的是一个概念与多个知识元之间的关系,即多个具有相同概念含义的知识元与概念之间的关系。概念-知识元索引提供两个方面的检索服务,一是搜寻某一概念下的所有知识元,二是由某个知识元查询其所属概念,从而可以获取与知识元相关的其他知识元,既可能包含直接关联知识元,也可能包含间接关联知识元,也可以根据知识元所属概念层定位。概念-知识元索引同样采用三元组形式,主体为概念,谓词为包含,客体为概念所属知识元。概念索引建立是在概念-知识元索引的基础上所建立的概念层概念之间关联的索引,概念索引反映的是概念之间的层级关联,而层级关联来源于不同概念所包含的知识元间的关联。概念层可视为粗粒度的知识关联层,概念索引的三元组描述为(概念,层级关系,概念),层级关系为上下级关系。概念索引展现概念间粒度关系,可将概念分解为多个细粒度的概念,又可获取更粗粒度的概念。
综上,概念索引作为概念层结构索引,提供总架构;概念-知识元索引将多个知识元与概念建立索引;知识元索引提供与知识元相关的各项属性特征检索,为最细粒度的知识单元索引。这三者结合起来既可以提供细粒度的知识元检索,又可以根据粗粒度的概念检索,不同粒度概念之间也可相互跳转,而概念又可由细粒度知识元集来揭示,从而满足UGC的多粒度索引与检索的需求。
4 实证研究
4.1 数据来源及处理
本文的实验数据分别来自CSDN(Chinese soft‐ware developer network)和博客园两种专业博客。之所以选取这两种博客作为实验数据的来源,其原因主要在于它们具有较高的知识密度[26],这有利于克服碎片化UGC多源分布性导致的知识内容离散分布的问题,进而提高知识要素抽取和知识元生成的效率。具体而言,首先,借助网络爬虫从CSDN和博客园中爬取与“检索”这一主题相关的UGC文本片段;然后,借助NLPIR(natural language pro‐cessing and information retrieval)分 词 工 具,融 合“检索”相关的词条,对爬取的UGC文本片段进行分词,并去除分词结果中的停用词。
4.2 UGC多粒度关联实证
UGC多粒度关联实证包括三个部分:生成知识元概念关联集,获取知识元等同关系,获取知识元非等同关系。
4.2.1 概念关联集创建
本文选择分类-主题词表和维基百科数据作为已有知识组织体系数据,采用命名实体识别的技术方法,对UGC知识元知识要素进行概念识别,在识别出的概念之间进行关联查找。关联查找先是从已有知识组织体系中提取,若出现冲突则以分类-主题词表为准,在此基础上对于没有识别出关联的概念,再使用基于规则和句法结构的方法提取部分关系。表1为“搜索引擎”下的部分知识元概念关联集。
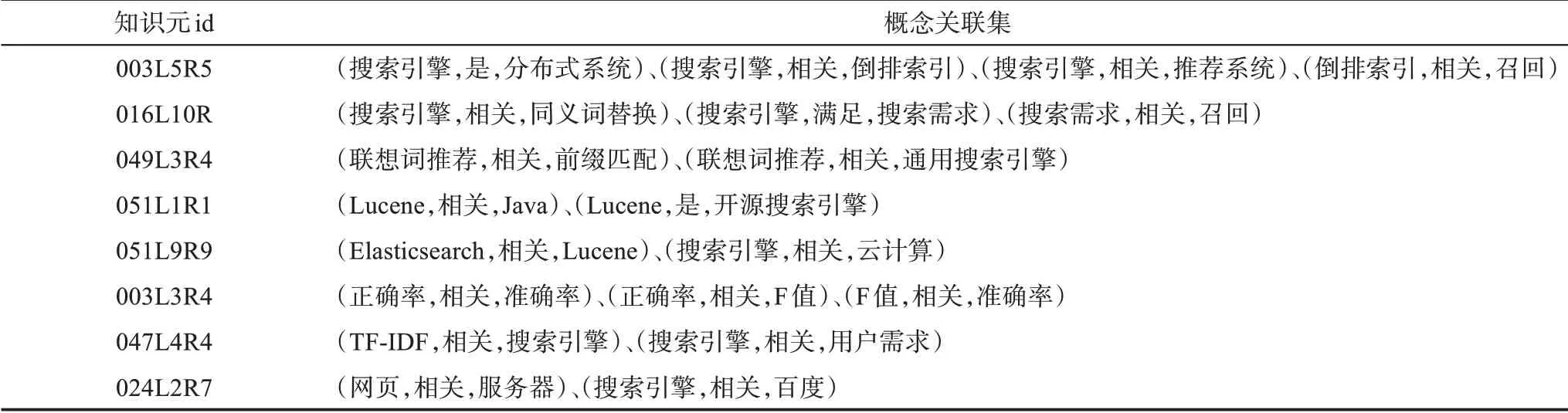
表1 “搜索引擎”标识词下的部分知识元概念关联集
4.2.2 知识元等同关联构建
等同关联实证分为两步。首先,在已有知识组织体系中查询两个知识元标识词之间是否为等同概念,若满足条件,则将两个知识元视为等同关联知识元;否则,计算两个知识元的知识要素的相似度,再根据相似度进行判断。具体而言,先以知识元抽取中所构建的BTM+GloVe的语义向量作为知识要素向量,计算向量余弦值,若其大于阈值,则视为知识要素相关性强;然后进入知识元概念关联集相似度的判断,比较概念关联集中关联边,每条边以完全匹配的方式判断,即节点及节点间的关系都需要完全相匹配才能判定两条边一致;具有等同概念关系的节点视为相同节点,若关联集相似度高于阈值,则判定知识元具备等同关系。本文共构建了56对等同关联,其中与“倒排索引”等同关联的知识元及关联判定依据如表2所示。

表2 与“倒排索引”等同关联的知识元及关联判定依据
若知识组织体系匹配为1,则表示在已有知识组织中有匹配到等同关系;若为0,则表示没有,需要进行下一步;Null表示不需要进行下一步便可判定有等同关联。为了便于直观查看,这里的知识元直接用概念标识词表示,实际是指概念标识词中的某个知识元,省略了知识元id。需要注意的是,若知识元具有等同关系,则其各自所属的概念标识词之间也具备等同关系;但若概念标识词具有等同关系,则其下属知识元之间不能认为有等同关系。
4.2.3 知识元非等同关联构建
关于非等同关联的判定,首先在已有知识组织体系中查询两个知识元标识词之间是否存在除等同关系以外的其他关联关系,如层级和相关关系。若有,则作为两个知识元间的关联关系;若无,则基于概念关联集,借助于多阶关联分析的方式来识别知识元之间的非等同关联关系。本实验共构建了274对非等同关联,其中部分非等同关联的知识元及关联如表3所示。
从表3可以看出,“检索”和“图像检索”之间存在层级关系,“音乐检索”和“哼唱检索”存在包含关系,“模糊检索”和“精确匹配”、“查准率”和“召回率”、“创建索引”和“分词器”、“布尔检索”和“布尔逻辑”之间存在相关关系。
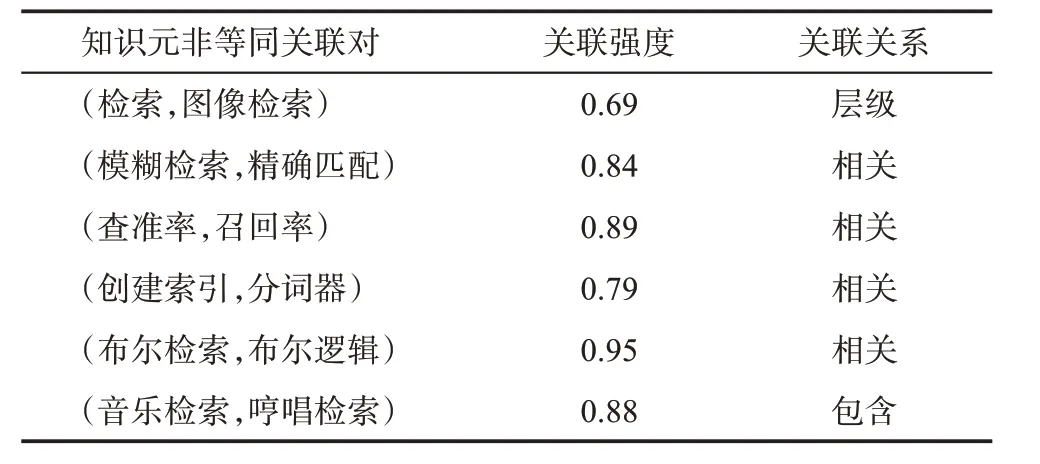
表3 非等同关联的知识元及关联关系(部分)
4.3 碎片化UGC多粒度索引及服务实证
4.3.1 UGC多粒度索引创建
对于上文所得到的UGC知识元和知识元关联,将其以知识元语义描述模型的方法存储到数据库中,本节选择关系型数据库MySQL存储数据,调用lucene架包实现索引创建。从数据库中读取出数据,根据上述内容创建知识元索引、概念-知识元索引和概念索引,生成倒排文档。其中,对知识元索引的主体和客体采用Field.Store.YES,Field.Index.TOKENIZED索引,既存储也分词;谓词采用Field.Store.YES,Field.Index.UN_TOKENIZED索引但不分词;对于概念-知识元索引和概念索引,三元组均采用索引但不分词方式创建索引。每个索引生成相应索引文件。
4.3.2 UGC多粒度知识组织检索服务
本文实证的最终模块是为用户提供检索服务。用户输入检索词,如图8所示,在生成的索引文件中进行检索,并返回结果。为直观展示检索结果,本文选择以可视化的方式显示检索结果界面,如图9所示,其主要包含四个部分内容,左上为与检索式相匹配的知识元整体模型显示,点击其中的概念标识词会返回同一标识词下的所有知识元,左下为知识元对应知识要素,右上为该知识元所在的概念上下层级结构,点击可进行不同粒度概念跳转,右下为与该知识元直接相关联的其他知识元,点击将跳转为该知识元可视化界面。

图8 输入“搜索引擎”关键词查询
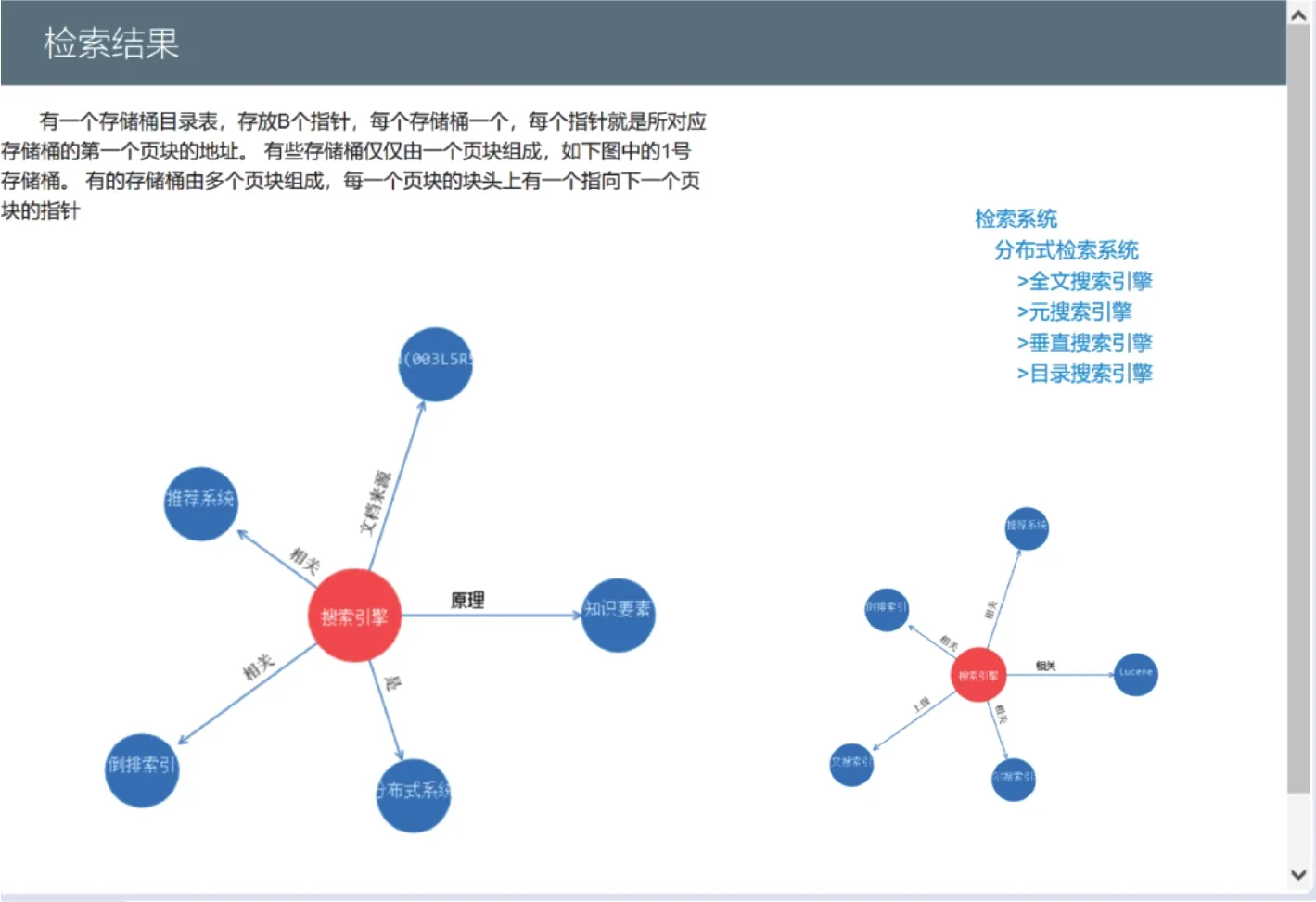
图9 查询返回可视化界面
5 总结与展望
本文以知识元作为知识组织的基本单位,首先,借助知识要素的抽取和聚类生成面向UGC内容的知识元;其次,通过概念匹配和多阶关联分析的方法构建UGC知识元间的多粒度关联关系;最后,以RDF三元组描述框架构建UGC知识元索引、概念-知识元索引和概念索引,实现对碎片化UGC的多粒度知识组织。在此基础上,以CSDN和博客园为UGC数据来源进行实证研究,研究结果证明了本文所提出的对碎片化UGC进行知识组织流程的有效性。虽然本文提出了一种面向UGC的多粒度知识组织的方法,但本文对面向UGC的多粒度知识服务的讨论不够深入,如何根据用户需求构建个性化知识服务尚需深入讨论。为此,未来将基于用户认知和行为特征进一步探究面向UGC的多粒度融合知识服务问题。
猜你喜欢
计算机与生活(2022年3期)2022-03-13
粉末冶金技术(2021年3期)2021-07-28
小型微型计算机系统(2020年10期)2020-10-21
科学与财富(2019年27期)2019-10-25
数码世界(2019年9期)2019-09-07
五邑大学学报(自然科学版)(2019年3期)2019-09-06
电子制作(2019年14期)2019-08-20
计算机技术与发展(2018年12期)2018-12-20
数码设计(2017年1期)2017-10-13
计算机系统应用(2017年5期)2017-06-07
