
基于学习者知识和性格的个性化课程推荐
2022-11-25 13:49班启敏吴雯胡文心林晖郑巍贺樑
华东师范大学学报(自然科学版) 2022年6期
班启敏,吴雯,胡文心,林晖,郑巍,贺樑
(1.华东师范大学 计算机科学与技术学院,上海 200062;2.华东师范大学 数据科学与工程学院,上海 200062;3.上海流利说信息技术有限公司,上海 200090;4.华东师范大学 信息化治理办公室,上海 200062)
0 引言
自适应学习是使用计算机算法来协调自适应学习平台与学习者的互动,并提供定制的学习资源和学习活动来解决每位学习者独特需求的教育方法[1].相较于线下的为所有学习者提供相同的学习资源的课堂模式,自适应学习更加关注学习者个体之间的差异,以帮助学习者高效掌握所学的知识[2].自适应学习面临的主要挑战之一是,如何为学习者提供定制的学习资源,即如何在海量的学习资源中,基于学习者的需求、能力和偏好为学习者生成个性化的推荐.
现有的学习资源的推荐主要依赖通过知识追踪技术获取的知识级别[3-5],其表示学习者对学习资源的掌握程度,如Huo等[3]使用上下文扩充深度知识追踪以获取学习者的知识级别,然后推荐给学习者未掌握的学习资源.虽然这些方法已经获得了很大的成功,但仍然存在着一些不足: ①在获取学习者知识级别时,尽管“遗忘”在学习过程中是一个常见的现象[6],但这些方法并未对遗忘现象很好地建模.即使是知识追踪中目前被广泛使用的深度知识追踪模型也很难模拟学习者出现的遗忘现象,因为该模型是用长短期记忆网络(Long Short-Term Memory,LSTM)[7]进行知识级别的预测,LSTM 对于每个状态进行相同的操作但遗忘现象是时间敏感且不均匀变化的.② 在进行学习资源推荐时,目前大多数的研究是将知识追踪和推荐分开来考虑,忽视了两者之间的深层连接,即知识追踪训练得到的知识级别和学习资源的表示可以帮助推荐.③仅仅依赖于知识级别生成学习资源的推荐是不充分的.因为该推荐方法只能提供满足学习者知识水平的学习资源,并未考虑学习者对学习资源类型、学习策略等的个人偏好,如对于同样的知识点,部分学习者偏向于通过视频来学习,而另一部分学习者则偏向于通过文本来学习.
为解决上述问题,本文提出了一个基于知识和性格的多任务学习框架去促进课程推荐.该框架将增强的知识追踪任务和推荐任务分别作为辅助任务和主任务,并通过这两个任务之间的信息共享机制,增强知识追踪任务,从而更好地帮助课程推荐任务[8].具体来说,在增强的知识追踪任务中,本文设计了一个个性化的遗忘控制器,通过引入3 个时间相关特征,增强的知识追踪模型可以解决学习者复杂的遗忘问题,从而捕捉更加准确的动态知识级别.在课程推荐任务中,对于学习者画像,本文不仅关注学习者的知识水平,同时考虑学习者的偏好.在最近几年,学习者的行为常常被用于建模学习者的意图以表示其偏好信息.此外,作为静态可测量并影响人们偏好的内在成分[9],教育心理学家认为性格对于理解学习者的行为表现是重要的[10-14],性格也逐渐地被认为是个性化学习中的一个影响学习者偏好的有价值的因素.因此,本文使用学习者的序列行为和学习者的性格建模学习者的偏好信息,将学习者的知识级别、学习者的序列行为、学习者的性格自适应地融合生成学习者的表示;对于课程,通过基于规则的方法选择候选的课程集合以保证推荐的逻辑性;在进行推荐时,结合学习者的画像和课程的表示,从候选课程集中选择既符合学习者知识水平又满足学习者学习偏好的课程生成推荐列表.本文主要贡献如下.
(1) 提出了一个端到端的知识和性格相结合的多任务学习框架以促进课程推荐,其中增强的知识追踪任务作为辅助任务去协助主要的课程推荐任务.
(2) 在增强的知识追踪任务中,设计了一个由3 个时间相关特征组成的个性化遗忘控制器,以解决学习过程中出现的遗忘现象.
(3) 在课程推荐任务中,自适应地融合学习者的知识级别、序列行为和学习者的性格以建模学习者的画像;利用基于规则的方法选择候选的课程并基于此生成合适的推荐.
(4) 在真实的教育相关数据集上进行了实验.结果表明,本文模型在点击率(Hit Ratio,HR)、归一化折损累计增益(Normalized Discounted Cumulative Gain,NDCG)、精确度(Precision,P)这3 个指标上均超过了基线模型.
1 相关工作
本文研究工作与课程推荐、推荐中的多任务学习、性格在自适应学习中的应用这3 个主流研究领域相关.
1.1 课程推荐
自适应学习系统中的推荐可以分为两大类: 第一类,基于学习者的序列行为[15-16];第二类,基于学习者的知识级别[3-5].第一类推荐通过学习者的行为捕捉学习者的偏好并生成相应的推荐,例如,Gong等[15]使用元路径(Meta-path)去指引学习者偏好的传播,并利用扩充的矩阵分解生成推荐列表;Pandey等[16]通过学习者的学习序列表示学习者的兴趣演变,并使用最近邻方法生成推荐结果.
尽管生成的推荐列表满足了学习者的偏好类型,但推荐的学习资源的难度很难保证适合学习者当前的知识水平.第二类推荐通过知识追踪技术[17]捕捉学习者的知识级别,并使用这个知识级别去预测学习者在下一个交互项上的表现,然后根据预测结果生成推荐列表.深度知识追踪(Deep Knowledge Tracing,DKT)[18]模型利用深度学习中的循环神经网络(Recurrent Neural Network,RNN)或LSTM 预测学习者的知识级别.Huo等[3]使用DKT 预测学习者的知识级别并推荐给学习者没有掌握 (较低知识级别) 的学习项;Liu等[4]将推荐视为马尔可夫决策过程,将知识级别作为状态并通过最大化全局收益的方式生成推荐结果;Wu等[5]将知识级别视作难度信息去过滤学习资源.尽管以上这些方法可以生成符合学习者知识水平的学习资源,但是这些方法都忽视了学习者个体之间对学习资源类型、学习策略的偏好差异.此外,尽管在学习过程中遗忘现象很常见[6],但上述方法在知识追踪中并没有很好地建模学习者的遗忘现象.事实上,一些知识追踪相关的研究已经尝试去解决遗忘问题[19-21],例如,Nagatani等[19]结合先前学习序列中交互间的时间间隔和练习次数扩充DKT;Ghosh等[20]、Pandey等[21]使用序列位置信息指代时间结合指数函数去建模遗忘现象.然而这些研究并未全面地考虑学习资源之间的先验、依赖相关性以及学习过程中出现的复习机制,即学习资源被反复地学习.
1.2 推荐中的多任务学习
上述基于学习者知识级别的方法在进行推荐时将其和知识追踪任务割裂了.然而,推荐任务紧密地依赖于知识追踪任务,知识追踪任务训练生成的信息有助于推荐任务.因此本文尝试将知识追踪任务作为辅助任务,推荐任务作为主任务,通过多任务学习优化这两个任务.
多任务学习致力于联合地学习多个相关的任务,以便一个任务中包含的知识可以被其他任务利用,以提升所有任务的通用性能.在多任务学习中,一个任务的学习结果可以作为提示去指引其他任务得到更好的性能[8].多任务学习的优越性被广泛地应用于推荐系统,例如,Hadash等[22]通过多任务学习框架同时学习排序任务和评分任务的参数;Chen等[23]利用层级互注意力选择器同时提升推荐任务和解释任务的性能;Meng等[24]和Wang等[25]利用知识图谱嵌入任务去协助推荐任务.
1.3 性格在自适应学习中的应用
现有的研究主要使用学习者的知识级别或学习者的行为生成个性化的学习资源推荐.然而,性格作为影响人们态度、行为和兴趣的内在因素[9]同样有着重要的作用.一个被广泛使用的性格模型是大五性格模型[26],其将性格定义为5 个维度: 经验开放性(Openness to Experience,简称O)、尽责性(Conscientiousness,简称C)、外倾性(Extraversion,简称E)、宜人性(Agreeableness,简称A)、神经质性(Neuroticism,简称N).大五性格模型: 经验开放性(O)常被用于判断一个人是易接受新事物/常有新想法还是遵循常规的/不爱创新的;责任心性(C)会使一个人成为可信赖的/自律的,或者条理性差的/粗心的;外倾性(E)更容易判断一个人是外向的/精力充沛的还是内向的/安静的;宜人性(A)反映了个体间在合作和社交之间的差异,有较高宜人性的人更易招人喜欢且为人和善,而较低宜人性的人易于批评人且爱争吵;对于神经质性(N),有着较高神经质值的人更容易忧虑和心烦,反之有着较低神经质值的人会更加淡定,且情绪会相对冷静.
性格不仅用于帮助生成电影[27]、音乐[28]的推荐,而且在个性化学习中也被视作一个有价值的因素.Furnham等[10]的研究表明,不同性格的个体之间存在着不同的认知风格和决策差异,不同类型的教育适合不同性格的学习者.性格影响学习者对于学习资源类型的偏好已经被证明,如Moller等[11]的研究表明,内向的学习者 (低外倾值) 偏向于视觉的学习方式,则这些学习者应该使用视频学习资源.此外,性格影响着学习者对于学习策略的偏好,例如,Chamorro-Premuzic等[12]的研究表明相较于情绪稳定(低神经质值) 的学习者来说,越内向 (低外倾值) 的学习者越倾向于独立学习;Wu等[13]发现在基于网站的学习系统中性格和学习者的交流行为存在着显著的相关性;Abyaa等[14]总结了性格在自适应学习中用户建模的应用.尽管性格已经被证明对于学习有影响,但很少有研究将其应用到自适应学习中的课程推荐.
为了生成同时满足学习者知识水平和偏好的课程推荐列表,本文结合知识追踪任务和课程推荐任务,使用多任务框架联合优化知识追踪任务和推荐任务.在推荐任务中,序列推荐已经在建模用户的动态偏好方面取得了较大的成功,例如,Yu等[29]使用基于时间的控制器和基于内容的控制器建模用户的长期和短期的兴趣;Zhou等[30]使用兴趣抽取层,从用户的历史行为序列中捕捉时序兴趣.因此,本文将课程推荐任务建模为序列推荐任务.此外,针对目前已有方法的不足,本文还研究了在知识追踪中利用时间上下文建模遗忘行为的效果,以及学习者的性格在课程推荐中的作用.
2 知识和性格结合的多任务学习模型
本文提出的知识和性格结合的多任务学习框架(Knowledge and Personality Incorporated Multi-Task Learning Framework,KPM)如图1 所示.KPM 将增强的知识追踪任务作为辅助任务(任务1),以协助主要的课程推荐任务(任务2).具体地,KPM 包含3 个部分: ①嵌入层,模型中使用的一些特征将会在该层被嵌入为低维稠密向量;② 增强的知识追踪任务,学习者动态的知识级别将会在该部分被捕捉;③课程推荐任务,候选课程的推荐分数将会在该部分得出,并以此生成推荐列表.下面详细介绍这3 个部分.
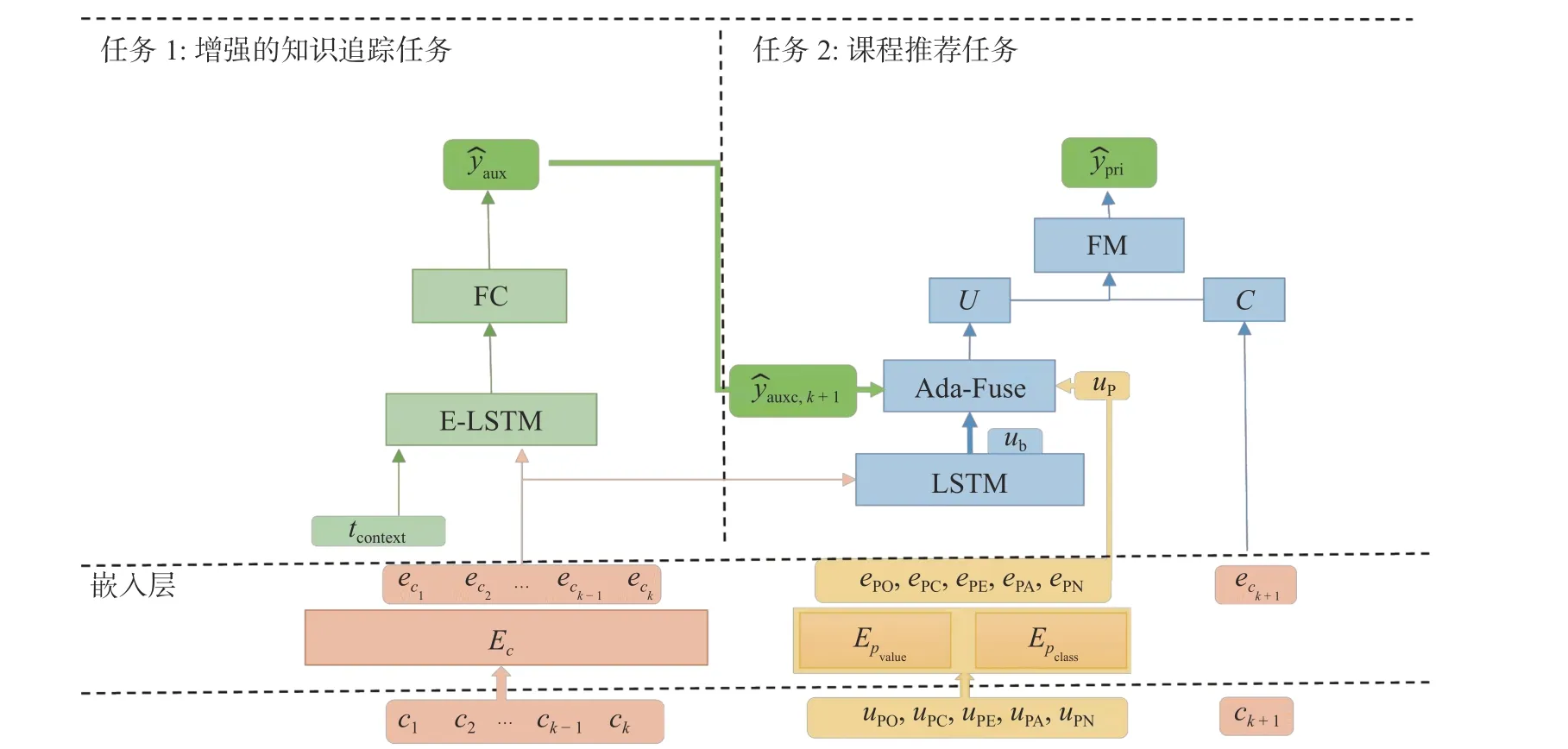
图1 知识和性格结合的多任务学习框架Fig.1 Knowledge and personality incorporated multi-task learning framework
2.1 嵌入层
KPM 使用4 类特征建模: ①学习者(user,u)的性格,使用uPO,uPC,uPE,uPA,uPN建模,以表示学习者大五性格中经验开放性(O)、尽责性(C)、外倾性(E)、宜人性(A)、神经质性(N)每个维度的性格值①每个维度的性格值 (1–7 分之间) 由两个相关问题进行平均得出.;② 学习者的行为,由出现在学习序列中的课程编号 (ID) 组成;③课程描述,即课程的IDc;④ 交互的上下文tcontext,由学习序列中每一个交互的时 间t组成.ePO,ePC,ePE,ePA,ePN分别是特征uPO,uPC,uPE,uPA,uPN的嵌入向量,其源于参数矩阵②13 代表所有可能的取值 (1,1.5,···,6.5,7),5 表示性格的维度类别 (O,C,E,A,N).嵌入向量 eP* 由性格值嵌入向量和性格维度类别嵌入向量拼接组成.,其中dP表示学习者性格的嵌入大小;ec是特征c(course,课程)的嵌入向量,其源于参数矩阵Ec∈Rn×d,其中,d表示课程的嵌入大小,n表示课程的总数量.
2.2 增强的知识追踪任务
原始的深度知识追踪由LSTM 建模.在本文提出的增强的知识追踪任务中,设计了一个个性化的遗忘控制器,它通过同时考虑学习者的行为序列和每一个交互的时间上下文信息去增强深度知识追踪模型.受Yu等[29]研究的启发,本文提出了3 个时间相关特征,具体如下.
2.2.1 时间间隔特征δt


式(1)中:wδ和bδ是可训练的参数;ti+1和ti分别表示学习者行为序列中任意第 (i+1)和第i个交互发生的时间.时间间隔特征δt编码了两个连续交互之间的时间距离.
2.2.2 时间跨度特征st
时间跨度特征被提出是因为课程之间存在预备和依赖关系且它们之间会相互影响.对于上述学习者a的学习记录Ba,交互对应的课程可能是交互对应课程的预备课程.在这种情况下交互i1a和交互之间的时间跨度会影响交互对应课程的准确率预测.st的计算公式为
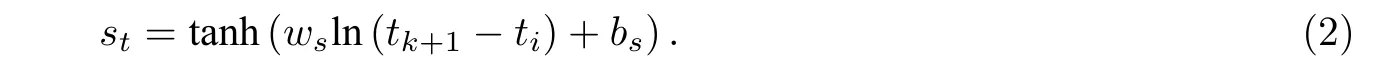
式(2)中:ws和bs是可训练的参数;tk+1表示要预测的 第 (k+1) 个交互发生的 时间.时间跨度特征st编码每一个课程和预测的目标课程ck+1之间的时序距离.
2.2.3 时间延迟特征ϵt
时间延迟特征被提出是因为学习过程中存在复习机制.在这种情况下,在预测交互项课程准确率时,先前学习过的相同课程具有较大的影响.对于学习记录Ba,如果交互和交互对应相同的课程则的结果会对交互课程的预测有很大的贡献.ϵt的计算公式为

式(3)中:wϵ和bϵ是可训练的参数;是预测的目标课程在先前的学习序列中对应的交互发生的时间.时间延迟特征 ϵt编码预测的目标课程ck+1和先前的相同课程间的时序距离.
进一步地,类似于Beutel等[31]的研究,本文将时间相关特征(δt和st)通过全连接层转换为稠密向量,并计算其对应的时间门(Tδ和Ts).为了更好地模拟学习者学习过程中的遗忘现象,本文利用以上3 个时间相关特征去增强LSTM (图1 中的E-LSTM)中的遗忘门和对应的核状态.相应的计算公式为

式(4)—(7)中:w*和b*是可训练的参数;fi,ii,ccell,i分别是E-LSTM 对应的遗忘门、输入门和核状态.在增强的知识追踪任务中,本文利用在每一个交互的课程ID 嵌入向量作为输入xi,并将该交互对应的准确率视为监督信息去优化嵌入向量和对应的权重.
在第i个交互中,学习者的知识状态隐向量hi通过

进行更新.式(8)中,oi是E-LSTM 对应的输出门.最终,通过包含Sigmoid 激活函数的全连接(Fully Connected,FC)层,学习者对于所有课程的知识级别通过

进行预测.式(9)中,wa和ba是可训练的参数.
由于数据集中课程的准确率是0~1 的连续值而不是离散的0和1,因此,本文将增强的知识追踪任务视为回归问题而不是分类问题.在这种情况下,模型可以更加准确地获取学习者对于知识的掌握程度.在回归问题中本文使用均方误差损失函数
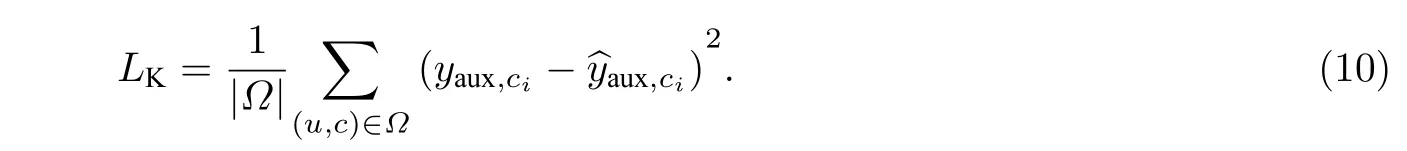
式(10)中:Ω是训练集的大小;(u,c) 表示训练集中的学习者 (user)和课程 (course);分别是训练集中第i个交互中课程ci对应的真实准确率和预测准确率.
2.3 课程推荐任务
本文基于学习者的画像U和课程的表示C生成推荐分数.
2.3.1 学习者的画像U
对于学习者的画像U的生产,本文用到了3 个学习者相关的特征: ①学习者对于目标课程的知识级别它通过增强的知识追踪获取;② 学习者的序列行为ub,它被考虑是因为它可表示学习者的学习意图;③学习者的性格uP,它被考虑是因为它可反映学习者对于学习资源类型、学习策略的偏好.考虑不同的维度有不同的优先权,本文采用门控机制去适应原始的特征.相应的计算公式为

式(11)—(12)中:w*和b*是可训练的参数;ec是课程嵌入向量;进一步,由于LSTM 方便序列建模且具备长时记忆能力,本文用LSTM 建模时序交互行为,即对于学 习者的性格,eP*由性格值嵌入向量和性格维度类别嵌入向量拼接组成,将每个维度的性格通过门控机制控制信息流动后,得到学习者对应性格维度的嵌入表示uP*;利用残差连接,并使用层正则化去获取学习者最终的性格表示,即
综上,基于特定的上下文自适应地融合3 个特征 (图1 中的Ada-Fuse),生成学习者的画像
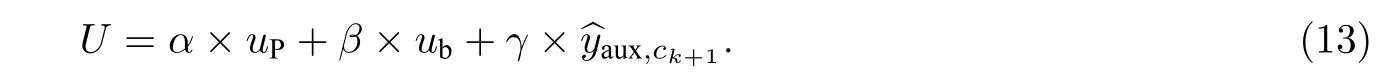
式(13)中:α,β,γ代表相关特征的自适应权重,其值通过Softmax 函数获得,即α+β+γ=1,且α,β,γ∈[0,1].
2.3.2 课程的表示C
对于课程的表示C,本文设计了一个基于规则的课程导航算法.该算法依赖专家知识去选择用于推荐的候选课程.使用候选课程不仅保证了知识结构的逻辑性而且降低了搜索空间.具体地,对于本文使用的数据集,如图2 所示,学习者完成一系列课程之后存在一个测验用于评估学习的结果.当构建候选的课程集时,本文从两类课程中进行选择: 第一类,学习者已经学过的课程;第二类,和学习序列中最后一个课程有着相同测验的课程.对于学习序列中最后一个交互k,第一类课程即图2 中蓝色大括号包含的课程,第二类课程即图2 绿色大括号包含的课程.

图2 候选课程示例Fig.2 Illustration of candidate courses
2.3.3 推荐分数
本文使用因子分解机(Factorization Machine,FM)[32]计算预测的推荐分数,即
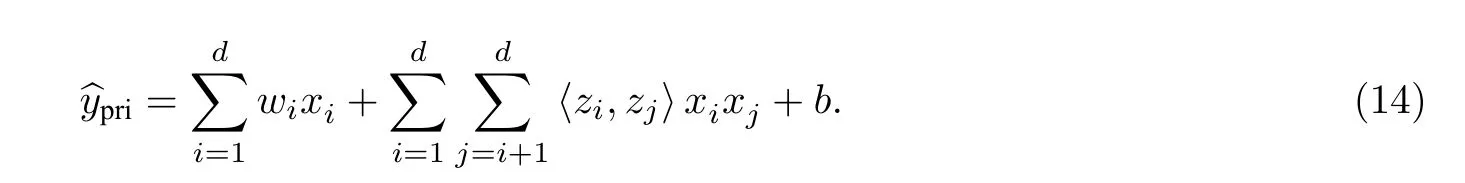
式(14)中:x=[U,C],[·,·] 表示拼接操作;w是线性回归的权重;是xi和xj之间的权重;〈·,·〉表示内积;b代表偏置项.
本文利用成对的贝叶斯个性化排序损失(Bayesian Personalized Ranking,BPR)去优化模型参数.假定观察的交互项相较于未观察到的交互项应该分配更高的预测分数,其形式为
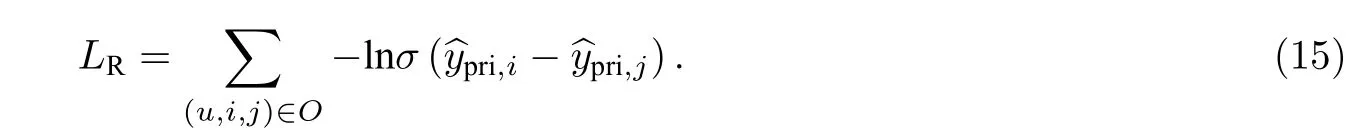
式(15)中:O={(u,i,j)|(u,i)∈R+,(u,j)∈R-}代表成对的训练数据,R+和R-分别代表观察到的和未观察到的交互项.
2.4 多任务学习目标函数
不同类型的损失函数通过参数λk线性地结合,并以端到端的形式去联合学习的2 个任务,即

3 实验
本文提出的推荐模型紧密地依赖于增强的知识追踪.为此,本文进行了2 个阶段的实验.
(1)阶段1: 评估增强的知识追踪模型的有效性.
(2)阶段2: 评估利用增强的知识追踪任务作为辅助任务、课程推荐作为主任务的KPM 模型的有效性.
3.1 实验数据集设置
实验所用数据集: 在阶段1 实验中,本文使用北大在线评测数据集(Peking University Online Judge,POJ)和流利说数据集 (Liu Li Shou,LLS)进行模型的评估;由于北大在线评测数据集目前无练习题之间的知识结构信息和学习者的性格信息,因此,在阶段2 实验中,本文仅使用流利说数据集进行模型的评估.
3.1.1 北大在线评测数据集(POJ)③https://drive.google.com/drive/folders/1LRljqWfODwTYRMPw6wEJ_mMt1KZ4xBDk
北大在线评测数据集是Pandey等[21]从北京大学在线评测平台爬取的,供研究者的编程练习.本文首先根据Pandey等[21]使用的预处理方式处理数据,即移除尝试提交次数少于2 次的学习者和被交互次数少于2 次的练习题;之后,通过统计,得到该数据集中存在提交次数超过50 000 次的10 位异常学习者.为符合实际情况,本文进一步将提交练习次数超过8 000 次的共11 位学习者进行了移除.最终本文使用该数据集包含了时间跨度在2019-07-27和2020-04-11 之间的13 289 位学习者、2 030 个练习题、424 004 个交互记录.因数据集中学习者的练习结果为离散的0,1 值,因此,在知识追踪任务中被视为分类问题并使用交叉熵损失函数进行训练.
3.1.2 流利说数据集 (LLS)
流利说数据集收集于人工智能驱动的教育科技公司—流利说④http://www.liulishuo.com.本文使用该数据集的时间范围在2019-12-31 到2020-02-29 之间,数据集包含了课程之间的知识结构信息、学习者的行为信息和性格信息.其中,课程之间的知识结构信息为模型部分所述的测试和多个课程之间的包含关系,学习者的行为信息从流利说App 中获取,学习者的大五性格信息是流利说平台通过邀请学习者填写TIPI (Ten Item Personality Inventory)问卷[26]的方式显式地获取的.过滤掉无效回答问卷⑤为了清洗数据,本文首先根据学习者的行为和对应的时间上下文排除了平均学习时间小于30 min 且总学习天数不超过1 周的学习者;然后根据学习者的TIPI 问卷答案过滤出在2 个相对的问题上有矛盾项的学习者 (例如同时在“我认为自己是外向的、热情的”和“我认为自己是保守的、安静的”这2 个问题上同时打1 分或同时打7 分将会被过滤掉).,最终保留了2 063 位学习者、1 198 门课程和对应的312 379 个交互,每个交互包含对应的课程ID、课程完成时间及课程的完成准确率.对于性格信息,每个维度的统计: 经验开放性 (O),均值=4.87,方差=1.01 ;尽责性(C),均 值=4.75,方 差=1.18 ;外倾 性(E),均 值=4.14,方差=1.41 ;宜人 性(A),均值=5.20,方差=0.88 ;神经质性 (N),均值=3.59,方差=1.22 .对于每位学习者的交互记录,本文将最后2 个交互分别作为验证和测试,其余的交互作为训练.在训练过程中,每个观察到的交互将被作为1 个正例与1 个未观察到的负例进行匹配,并像Zhou等[30]那样在每一步进行监督.在测试集,根据数据集的规模,同He等[33]那样,为每个观察到的交互匹配25 个随机采样得到的负例,并最终输出对这26 个实例 (1 个正例和25 个负例) 的预测分数.
3.2 阶段1 实验设置
3.2.1 评价指标
为了测量增强的知识追踪任务的效果,本文在POJ 数据集上的分类问题使用的指标是准确率(Accuracy,AAcc)[21],以及ROC 曲线下方的面积大小 (Area Under Curve,AUC)[18],这里用SAUC表示;在LLS 数据集上的回归问题使用的指标是均方误差 (Mean-Square Error,MSE)[34],这里用EMSE表示.相应公式为
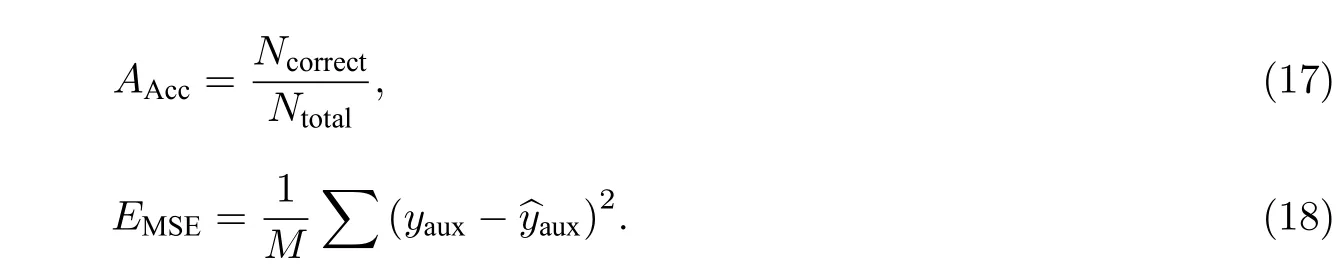
式(17)—(18)中:AAcc代表模型预测正确的样本数量Ncorrect在预测总样本数量Ntotal中的占比,即准确率;M是测试集中学习者的数量;yaux和分别代表课程真实的准确率和预测的准确率.
3.2.2 对比方法
在这一阶段,将提出的增强的知识追踪模型 (E_DKT) 与经典的深度知识追踪模型 (DKT) 进行对比,以验证本文引入的个性化遗忘控制器 (使用时间上下文模拟学习者的遗忘现象) 的有效性.具体操作如下.
(1) 深度知识追踪模型 (DKT): 使用LSTM 进行知识级别的预测.
(2) 增强的知识追踪模型 (E_DKT): 使用3 个时间相关特征增强E-LSTM 进行知识级别的预测,即本文提出的增强的知识追踪任务对应的模型.
3.2.3 实验结果
表1 报告了DKT和E_DKT 的对比结果.从表1 可以看出,通过融入时间上下文,E_DKT 可以得到更加准确的知识级别预测结果.这表明时间上下文信息确实可以更好地模拟学习者在学习过程中出现的遗忘现象.具体地,在POJ 数据集上,E_DKT 相较于DKT 分类得更加准确,在AAcc上提升了 (Gain⑥) 0.3%,在SAUC上提升了2.4%;在LLS 数据集上,E_DKT 相较于DKT 有着更小的预测误差,在EMSE上提升了1.1%.该结果验证了增强的知识追踪模型的有效性,为其进一步在推荐模型中被使用提供了依据.
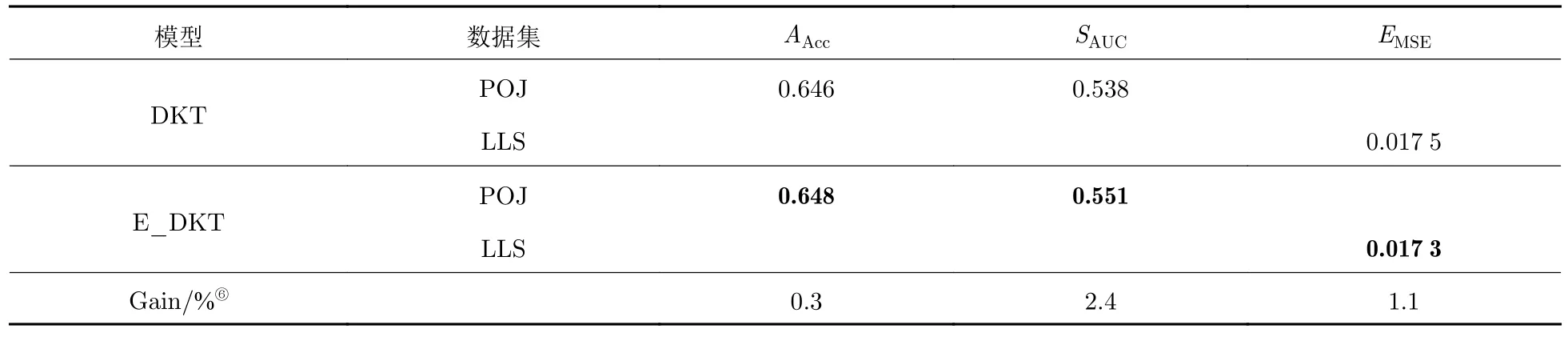
表1 知识追踪结果Tab.1 Results from knowledge tracing
在融入时间上下文后,E_DKT 在POJ 数据集上相较于DKT在AAcc指标上提升较小.通过对学习者案例的分析,如图3 所示,多数学生在在线编程平台上习惯于在某个时间段内进行多次的练习.在这种情况下,2 个连续交互之间的时间间隔就会很短,导致本文提出的E_DKT 中融入时间间隔特征 (δt) 的效果有所削弱.但因为知识点之间的依赖和先验关系,以及学习过程中复习机制的存在,时间跨度特征 (st)和时间延迟特征 (ϵt) 仍然是很有效的.因此,如表1 所示,在POJ 数据集上E_DKT 相较于DKT在AAcc指标上仍有0.3%的提升,在SAUC指标上有2.4%的提升.此外,在符合现实中的多数自适应学习场景的LLS 数据集上,本文并未发现这种几乎是连续学习的短时间间隔的情况;并且如表1 所示,通过这3 个时间特征的联合作用,E_DKT 相较于DKT 在LLS 数据集上EMSE指标得到了1.1%的提升,其结果表明了融入3 个时间特征的有效性.

图3 学习者学习序列案例分析Fig.3 Case study on the learning sequence
3.3 阶段2 实验设置
3.3.1 评价指标
为了测量推荐的课程是否满足学习者的偏好,本文使用推荐中广泛使用的度量标准: 归一化折损累计增益(NDCG,用GNDCG表示)[35]和点击率(HR,用RHR表示)[15]进行评估.NDCG 评价排序的准确性;HR 测量真实实例被成功推荐的百分比;此外,精确度(Precision,P)[3]被用于测量推荐的课程是否合适于学习者的知识水平.受候选课程集的限制,被推荐的课程不会超出学习者的认知范围.因此,本文在评判推荐的课程是否符合学习者知识水平时,重点关注的是该推荐是否有查漏补缺的作用,即本文将命中学习者先前学习过但未掌握的课程定义为成功的推荐.评价指标相应的计算公式为


式(19)—(21)中: 右下标中的N为生成的推荐列表中的前N项;Z为推荐列表中前N项的最大折损累积增益(GDCG,N)的归一化常数;Tu是测试集中学习者u的交互课程;代表推荐列表Ru中的中的第i个课程;I(x)是指示函数,如果x>0 则值为1,否则为0;在精确度(PN)中,本文用r=0,1 分别表示推荐出的(recommendation)在先前学习序列中作答准确率较低的课程和已经掌握的课程,并将作答准确率较低的课程(r=0 )作为真阳(True Positive,TP)样本NTP,而那些已经掌握的(r=1)作为假阳(False Positive,FP)样本NFP.
3.3.2 对比方法
本文设计实验以回答以下问题.
问题1: 提出的KPM是否比基线方法执行得更好?
问题2: 增强的知识追踪辅助任务是否会协助课程推荐主任务?
问题3: KPM 中的组件(如遗忘控制器和学习者的性格)是否影响最终的推荐性能?
具体地,本文将KPM和经典的基线模型进行对比以回答问题1;将多任务学习的KPM和仅考虑课程推荐任务的KPM_K 进行对比以回答问题2;将KPM和KPM_T、KPM_P 进行对比以回答问题3.涉及的模型具体如下.
1) 基线模型
(1) BPRMF[31]: 通过BPR 损失优化的矩阵分解(Matrix Decomposition,MF)模型,其仅利用了学习者-课程的ID.
(2) FM[31]: 通过分解因子机(Factorization Machine,FM),利用学习者–课程的ID 生成推荐.
(3) LSTM[7]: 通过长短期记忆网络进行序列预测从而生成推荐结果,其仅使用了学习者的行为序列.
(4) DIEN(Deep Interest Evolution Network)[32]: 使用两层的GRU 建模学习者的行为序列并生成推荐结果,在第二层中使用基于注意力更新门的GRU,其仅使用了学习者的行为序列.
2) 本文KPM 模型的变种
(1) KPM_K: 仅考虑课程推荐任务,其增强的知识追踪任务损失 (式(4)中的LK被移除).
(2) KPM_T: 移除在增强的知识追踪任务中引入的个性化遗忘控制器 (知识追踪由原始的深度知识追踪组成).
(3) KPM_P: 移除课程推荐任务中的学习者性格信息.
本文使用Tensorflow 实施所有模型.对于基线模型,本文使用其论文中报告的方法进行超参数的初始化,并进行微调以保证它们达到最优的性能.对于本文提出的KPM,最优的学习率、λk、丢弃率分别为0.001、0.100和0.800;嵌入大小固定为18;学习者行为序列中的最大长度设为135.
3.3.3 实验结果
对于所有方法,本文取推荐列表的前5 项(N=5 )和前10 (N=10)项进行汇报.
1) 整体性能比较 (问题1)
表2 所示报告了不同方法的整体性能.由表2 的实验结果可以得到以下的结论.
(1) 本文提出的KPM 模型在所有的评估指标上均取得了最好的结果.这表明KPM 模型推荐的结果不仅满足学习者的偏好,而且适合学习者的知识水平.具体地,KPM 模型相较于最好的基线模型DIEN在RHR,5上提升了 (Gain⑥) 3.9%,这说明KPM 模型能准确地推荐学习者下一个真正选择的课程;KPM 模型相较于DIEN 模型,在排序指标GNDCG,5上达到了5.8%的提升,其结果值得关注,因为学习者在真实生活学习场景中经常选择排在前面的推荐课程;KPM 模型相较于DIEN在P5上得到了5.9%的提升,表明结合知识级别的KPM 模型更能推荐出符合学习者知识水平的课程,帮助学习者进行查漏补缺.
(2) 在比较的方法中,基于深度学习的方法(DIEN和LSTM)相较于传统的协同过滤方法(BPRMF和FM)整体上表现得较好.一方面,深度学习对于学习者和课程的表示是更加有效的;另一方面,它们使用了可以反映学习者最近学习意图的序列行为信息.
由此,问题1 得以较好回答,即提出的KPM 比基线模型执行得更好.
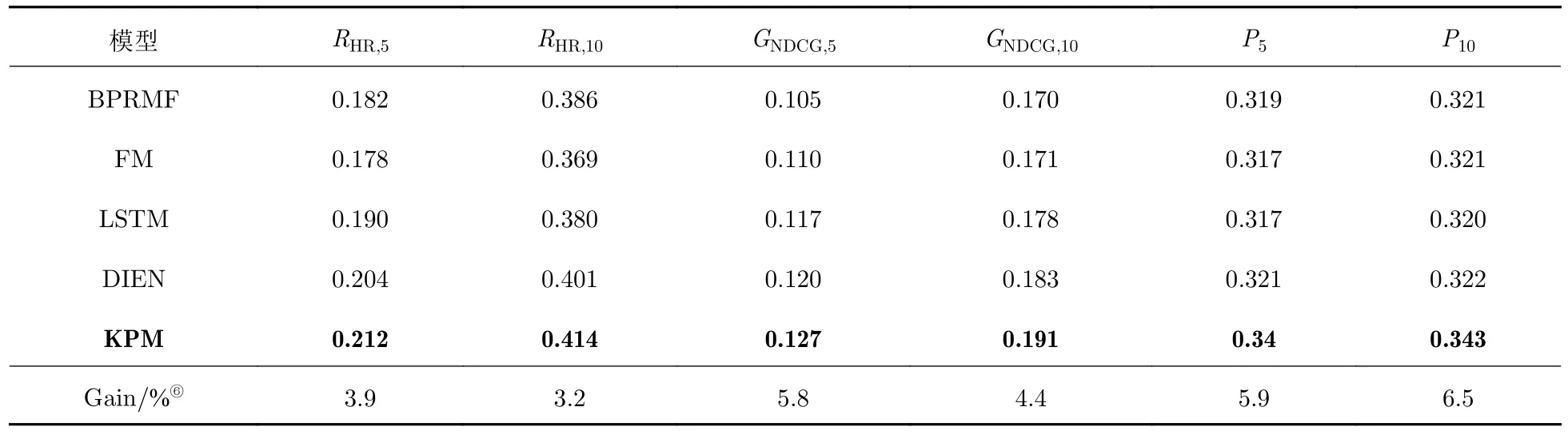
表2 整体性能结果Tab.2 Overall performance results
2) 多任务学习的效果 (问题2)
表3 所示是消融实验的结果.从表3 可以得到以下结论.

表3 消融实验结果Tab.3 Results of ablation studies
多任务学习模型KPM 相较于单任务模型KPM_K 在所有的评估指标上均得到了更好的效果,在RHR,5、GNDCG,5和P5上分别提升了 (Gain⑥) 11.6%、12.4%和11.5%,表明通过多任务学习的方法,在增强的知识追踪任务和课程推荐任务之间,共享知识级别信息是有效的;在增强的知识追踪辅助任务的帮助下,推荐的结果更加准确地匹配学习者的知识水平.
由此,问题2 得以较好回答,即增强的知识追踪辅助任务可以协助课程推荐主任务.
3) 各个组件的效果 (问题3)
由表3 的消融实验结果得到以下结论.
(1) 在所有的评价指标上,KPM 均优于其变种模型.具体地,①KPM 相较于KPM_T,其在RHR,5、GNDCG,5和P5上分别提升了 (Gain⑥) 9.8%、16.5%和10%,表明增强的知识追踪任务在多任务框架下仍然可以准确地捕获学习者的知识级别,可以帮助推荐匹配的课程;② KPM 相较于KPM_P 表现得更好,其在RHR,5、GNDCG,5和P5上分别提升了 (Gain⑥) 30.9%、35.1%和6.6%.结合学习者的性格信息后,HR 指标和NDCG 指标均有较大的提升,表明利用性格信息可以更好地迎合学习者的偏好,从而生成更加个性化的课程推荐.
(2) KPM_P 在HR 指标和NDCG 指标上次于KPM_T (RHR,5,KPM_P 的是0.162,KPM_T 的是0.193;GNDCG,5,KPM_P 的是0.094,KPM_T 的是0.109),在Precision 指标上优于KPM_T(P5,KPM_P 的是0.319,KPM_T 的是0.309).这证明了性格对于捕捉学习者的偏好更加重要,而准确的动态知识级别对于生成合适的知识水平课程贡献得更多.
(3) 为验证性格的作用,本文进一步进行了案例分析.图4 中间部分展示的是某学习者a的学习序列,其中绿色标记是该学习者a的真实学习序列中下一个学习的课程—342 听力课(“342”表示课程的ID,“听力课”表示课程所属的类型).将图4 中KPM 生成的“推荐列表1”和KPM_P 生成的“推荐列表2”进行比对,可以得到,融入性格信息后,模型可以较好地建模学习者的偏好信息,从而生成排序性更好的推荐结果.此外,通过图4 中“学习者a的性格”可知,学习者a属于高经验开放性(O),此类型的学习者相对更易接受新事物.模型KPM 因此生成了更加多样的推荐列表⑦借鉴Wu等[36]的工作,采用信息熵测量推荐结果的多样性,即,其中,是推荐的总数,Nr,s 代表推荐中属于类别 s 的个数,其中 s ∈S,S 代表推荐列表中类型的集合.信息熵越大则表明推荐列表中推荐的内容越多样.图4 中KPM和KPM_P 的信息熵结果分别为2.45和2.25..
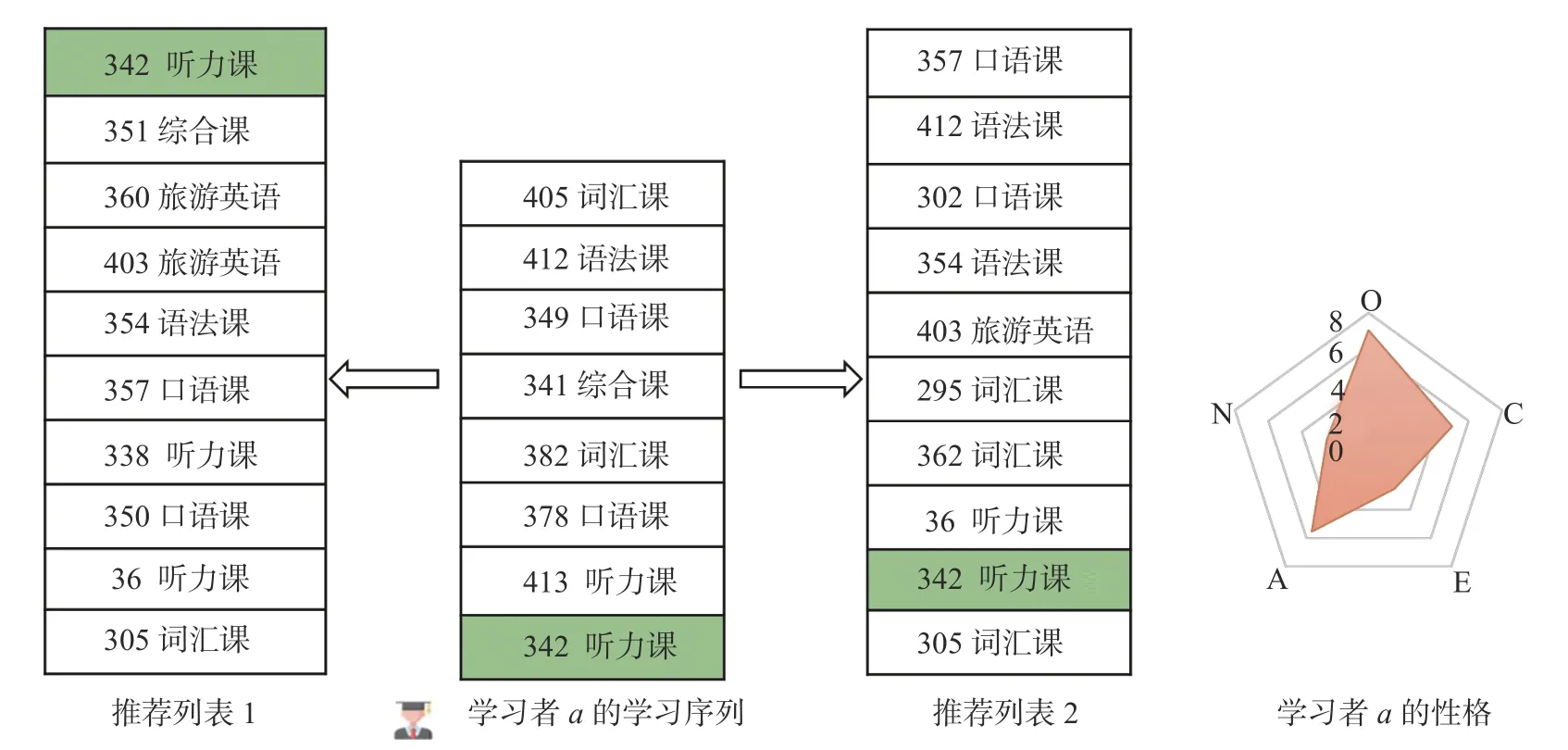
图4 性格的作用案例分析Fig.4 Case study on the effect of a learner’s personality
由此,问题3 得到了较好的回答,即KPM 中的组件如遗忘控制器,可以帮助KPM 通过更加准确的知识级别生成匹配学习者知识水平的推荐结果;融入学习者的性格可以帮助KPM 生成符合学习者偏好的个性化推荐结果.
4 总结与展望
针对自适应学习场景中面临的如何为学习者推荐个性化的学习资源挑战,提出了一个知识和性格结合的多任务学习框架KPM.在真实的教育相关的数据集上的实验结果表明KPM 在生成个性化课程推荐方面优于基线模型,即KPM 生成的推荐结果更好地满足学习者的偏好而且更适合学习者的知识水平.此外,消融实验结果表明了使用增强的知识追踪任务作为辅助任务,在增强的知识追踪任务中使用时间相关的上下文解决学习者的遗忘现象和在课程推荐任务中融入学习者性格信息的有效性.尽管本文在建模时引入了时间上下文信息和学生的性格信息,但这并不妨碍该模型的可扩展性,具体地,在时间上下文方面,可以在相关自适应学习平台上获取.在性格方面,尽管本文使用显式问卷形式收集学生的性格,但最近已有隐式获取性格方面的研究证明了通过多源异构数据如视频、图片、文本信息可以对性格进行准确的预测[13,37].在未来的研究中,可以针对以下方面进行探索.
(1) 本文在选择课程候选集合时依赖专家知识,因此在未来工作中将探索以知识图谱替代专家知识.
(2) 增加学习者学习效果等可量化的评估指标.
(3) 探索概念级别的细粒度推荐用以生成更加准确和可解释的推荐结果.
猜你喜欢
应用心理学(2022年5期)2022-11-05
北京大学学报(自然科学版)(2022年1期)2022-02-21
小哥白尼(野生动物)(2021年2期)2021-07-16
现代信息科技(2021年21期)2021-05-07
当代水产(2019年11期)2019-12-23
中国生物医学工程学报(2019年6期)2019-07-16
晚晴(2018年3期)2018-12-06
家庭影院技术(2018年5期)2018-06-29
家庭影院技术(2018年3期)2018-05-09
海外英语(2013年1期)2013-08-27
