
基于深度学习的岩石薄片矿物自动识别方法
2022-11-26 11:51徐圣嘉苏程朱孔阳章孝灿
浙江大学学报(理学版) 2022年6期
徐圣嘉,苏程*,朱孔阳,章孝灿
(1.浙江大学 地理与空间信息研究所,浙江 杭州 310027;2.浙江大学 地质研究所,浙江 杭州 310027)
0 引言
矿物识别是岩石分类定名的重要依据,也是了解岩石成因机理、物质运移、演化历史的基础,在采矿学、岩石学、火山学等地质学科领域中发挥了极为重要的作用[1-5]。通常,先将岩石磨制成薄片,再由专业人员在单偏光和正交偏光下从不同的角度观察待识别矿物的颜色、纹理、消光角、形状等特征[6-8],获取矿物信息,效率较低且受制于专家经验。除光学显微镜法,X 射线衍射(XRD)、扫描电镜-能量色散X 射线光谱仪(SEM-EDX)、QEMSCAN、MLA、电子探针、拉曼光谱等分析方法也能对岩石样品的矿物成分进行较准确的定量分析[9-16],但价格昂贵,人工成本和时间成本高,仅适用于样品数较少的情况[17-19]。近年来,随着深度学习在数字图像处理领域的发展,利用计算机对岩石薄片图像上的矿物进行快速自动识别成为可能[20]。矿物自动识别可有效提高岩石学基础研究工作的效率,避免受鉴定专家主观因素的影响,对“大数据+人工智能”范式在岩石学领域的应用起支撑与推动作用。
目前,已有很多针对岩石薄片图像的矿物自动识别研究。最常见的方法是先依靠人工干预提取矿物特征,再通过图像算法进行特征学习,建立矿物识别模型,从而实现对矿物的自动识别。总体而言,识别方法经历了由依靠单一颜色特征进行识别到依靠颜色、纹理、亮度等多种特征协同识别的转变。例如,MARSCHALLINGE[21]根据矿物图像的三原色(RGB)特征,采用最大似然分类法识别了4 种矿物。THOMPSON等[22]基于色调-饱和度-强度(huesaturation-instensity,HSI)颜色空间,采用人工神经网络(ANN)法对10 种矿物进行了识别。BAYKAN等[23]通过对比矿物在RGB、色调-饱和度-高度(HSV)和CIELab 3 种颜色空间下的识别效果,提出了一种基于RGB 和HSV 颜色分量的ANN 方法,并对矿物进行了分类[24]。然而,对某些矿物而言,仅凭颜色特征较难区分[18,25],因此,后续研究又进一步加入了矿物的纹理特征以提高识别精度[26]。例如IZADI等[27]基于颜色、纹理特征,提出了一种2个ANN 级联的矿物识别方法,取得了可靠结果。PEREIRA等[28]基于颜色、纹理特征,通过最近邻算法和决策树算法实现了矿物识别。之后,为提高识别精度,又加入了更多的图像特征。例如MAITRE等[29]依据颜色、纹理以及亮度特征,对比了3 种机器学习算法对砂粒样本中矿物颗粒的识别效果。RUBO等[30]从离散卷积滤波器中提取了75 种卷积特征,结合5 种非卷积特征,采用ANN 和随机森林方法对碳酸盐薄片进行了矿物及孔洞的识别。
近年来,以卷积神经网络(convolutional neural networks,CNN)为代表的深度学习方法得到了迅速发展,在数字图像处理领域显示了巨大优势[31]。CNN 方法无需人工干预,能从图像中自动捕获大量特征,并通过多层卷积运算在极大的感受野中累积丰富的上下文信息,非常适合图像特征的学习与表达[32]。目前,深度学习方法已成功应用于数字岩相学相关研究,如岩石分类和矿物识别,且取得了较传统图像算法更准确的结果[33-34]。SU等[35]提出了一种根据岩石薄片图像对岩性进行分类的级联卷积神经网络(Con-CNN),取得了良好效果,总体精度达89.97%。此外,也有不少对CNN 在矿物识别应用方面的探索,涵盖了不同尺度的矿物图像识别,即以手标本图像为代表的宏观尺度的矿物识别[17,33,36-37]和以岩石薄片显微图像为代表的微观尺度的矿物识别[34,38-43]。宏观尺度的矿物识别通常用于解决多种矿物图像间的分类问题。例如,彭伟航等[36]基于Inception V3 模型,引入中心损失函数作为限制模型的收敛条件,实现了对16 类常见手标本矿物图像的识别。OKADA等[37]则用高光谱相机拍摄了矿物图像,设计了一个CNN 以区分黄铜矿、方铅矿和赤铁矿,并对3 种不同粒度的赤铁矿进行了分类。微观尺度的矿物识别既有针对某种矿物的精细化提取,又有针对多种矿物的识别。例如,CHEN等[38]采用带有修正权重函数的U-Net 架构,解决了将页岩薄片背散射图像中的黏土复合体从矿物基质中分离的问题,因为两者的灰度级相似,无法用传统的图像阈值算法分离。郭艳军等[40]用ResNet-18 研究了5 种常见矿物对岩石薄片单偏光图像的识别。KOESHIDAYATULLAH等[41]研究了基于深度卷积神经网络(deep convolutional neural networks,DCNN)耦合的图像分类和目标识别任务,能同时定位和识别多个碳酸盐岩薄片图像中的6~9 种矿物颗粒、基质及胶结物。
已有研究表明,CNN 方法在岩石薄片图像矿物自动识别中显示了巨大的潜力和优势,但仍面临诸多挑战。其一,自然界中矿物的呈现形态复杂多样,图像的形状、大小、颜色、纹理等特征变化较多;其二,矿物在不同光性下的特征并未被充分、综合利用。基于此,本文提出一种用于矿物自动识别的岩石薄片图像深度学习方法。通过构建基于CNN的语义分割网络,自动提取矿物的多尺度复杂特征和语义信息,分别将矿物的单偏光图像和正交偏光图像用于矿物识别建模。通过融合不同光性图像,获取更准确的识别结果。对南京大学岩石教学薄片显微图像数据集的测试结果表明,本文方法的总体精度为86.7%,Kappa 系数为0.818。对比实验结果表明,本文方法的矿物识别精度及效率更高。
1 数据集
岩石薄片图像来自南京大学岩石教学样品显微图像数据集[44],包含28 种沉积岩、40 种火成岩、40 种变质岩的单偏光图像及正交偏光图像,每幅图像的尺寸为1 280 像素×1 024 像素。岩石样品主要来自我国境内,于1970—2019 年间采集,后被制作成薄片,岩石薄片偏光显微照片分别于2014 年和2019 年拍摄。
由于火成岩数据基本涵盖了常见的造岩矿物,这不仅是岩石分类命名的重要依据,也是理解岩石的化学成分、成因和成矿作用的基础。因此,将火成岩薄片在0°拍摄的透射单偏光图像及透射正交偏光图像分别作为训练样本和测试样本,岩石薄片包括石英闪长岩、花岗闪长岩、花岗岩、石英二长岩及黑云母花岗岩等。
通过人工镜下鉴定对数据集中的部分图像进行矿物标注,将其作为深度学习网络的训练样本。共标注石英、斜长石、碱性长石、角闪石、黑云母、绿泥石、不透明矿物、孔洞和其他等9 类矿物。为方便使用深度学习网络,将标注完成的矿物标签图像及其对应的单偏光和正交偏光图像统一裁剪为512 像素×512 像素的子图,最终构建了330 组(单偏光+正交偏光+标签图)数据。
2 矿物识别方法
由于矿物图像特征复杂多变,为在识别过程中充分地提取特征,提出一种岩石薄片图像矿物自动识别方法。如图1 所示,该方法的结构主要分为两部分:(1)构建深度卷积神经网络,通过多层深度卷积运算自动挖掘和提取图像的低层与高层特征,在保持图像原拓扑位置关系不变的前提下学习矿物的大量特征,最终以图像语义分割方式获取岩石薄片图像的像素级矿物识别结果;(2)基于矿物的单偏光特征和正交偏光特征是区分矿物种类的重要依据,人工鉴定需结合不同光性特征进行判断,因此,分别针对单偏光图像和正交偏光图像训练语义分割网络,在此基础上使用软投票法进行图像融合,综合利用不同光性图像特征,获取更准确的识别结果。

图1 基于深度学习的矿物自动识别方法结构Fig.1 The structure of automatic mineral identification method based on the deep learning
2.1 基于CNN的矿物颗粒语义分割
矿物颗粒语义分割网络整体遵循DeepLabV3+[45]网络结构,如图2 所示。该网络结构为编码器-解码器结构,首先在编码器中提取图像的多尺度语义特征,然后在解码器中重构多尺度语义特征的空间信息,使得网络输出的预测图像的空间分辨率与原始输入图像的相同。

图2 语义分割网络结构Fig.2 Structure of the semantic segmentation network
网络输入数据是单偏光图像或正交偏光图像(一种偏光图像训练一个网络模型),在编码器中由主干网络进行初步特征提取。主干网络选取ResNet-101[46]的前5个卷积模块,除第1个模块是7×7的卷积层外,其余4个模块均由不同个数的残差瓶颈结构堆叠而成,如表1 所示。对残差的学习能避免网络在层数深度堆叠的情况下出现梯度消失和梯度爆炸的现象,有利于网络更充分地提取图像中的局部细节特征。

表1 主干网络结构Table 1 Structure of the backbone
然而,仅通过局部细节特征识别矿物是不够的。通常,自然图像上的矿物特征具有较强的随机性,需通过更深层次的语义抽象进一步描述其特征。为此,在主干网络后,加入空洞空间金字塔池化(ASPP)[47]模块,以提取更多具有统计性的深层次语义信息。ASPP 用空洞卷积替代传统卷积,卷积核可在不增加参数与模型复杂度的条件下指数级地扩大感受野,从而避免牺牲太多图像中的空间分辨率,这意味着空洞卷积可在任意分辨率的图像上高效地提取密集特征。在此基础上,ASPP 采用4个并行的不同膨胀率的空洞卷积,分别为1个1×1的卷积和3个3×3的卷积(膨胀率分别为6,12,18),再对其做全局平均池化和卷积融合,从而获得大范围、多尺度的语义信息。
通常,通过ASPP 提取的特征信息较抽象,且通道数非常大,缺乏包含图像边缘特征的局部细节信息,因此在输入网络解码器时,需先经过1个1×1的卷积层以降低通道数,然后融合由主干网络提取得到的图像低层特征,补充欠缺的局部细节信息。对于融合后的特征图,使用3×3的卷积降低特征通道维数,通过双线性插值上采样将其恢复至与输入图像大小相同的矿物语义分割结果。该结果实际上是一组多通道的矿物类别归属概率图,通道数等于可识别的矿物类别数,每个通道上图像的像素表示该像素从属于某矿物类别的概率。
2.2 单偏光与正交偏光语义分割结果融合
为有效融合不同光性特征,得到更准确的矿物识别结果,使用软投票法处理由单偏光图像与正交偏光图像得到的像素级矿物识别结果。软投票法允许从汇总的多个加权分类器的预测概率中取概率最高的类别作为模型最终的预测结果。对于经过软投票法融合的矿物预测图像的每个像素j,其所属的矿物类别Cj为

其中,WPPL,WXPL=1−WPPL分别表示由单偏光图像和正交偏光图像训练得到的矿物识别模型的权重,其最佳取值可由实验获得;PPPL,PXPL分别表示由单偏光模型和正交偏光模型预测得到的该位置的像素从属于每个矿物类别的概率。将2 组加权后的概率分别相加,取概率最高的矿物类别作为融合后的类别。
3 对比实验与讨论
设计2 组对比实验:(1)对比深度学习与传统图像分类法最大似然法的识别精度差异,以验证深度学习方法在解决复杂问题方面的优势。(2)对比单个偏光的深度学习模型与融合软投票法模型的识别精度差异,以验证模型融合的提升作用。
采用PyTorch[48]深度学习框架,将数据集按7∶1∶2 划分为训练集、验证集、测试集,采用平移、旋转、缩放等组合方式对训练集进行5 倍的数据扩增,使网络能充分学习各类矿物的特征,避免产生过拟合现象。最终得到2个网络,即单偏光图像的语义分割网络和正交偏光图像的语义分割网络。在训练过程中,2个网络均使用相同的超参数,即基础学习率为0.000 01,梯度优化算法为Adam,权重衰减项为0.000 1,训练次数为100个epoch,每迭代5个epoch 对训练结果进行一次验证。最大似然法使用ENVI 图像处理软件,其训练样本和测试图像与本文方法相同。
采用像素级验证方法,在随机挑选的测试集切片图像中随机选取4 万个像素点(约为每幅图总像素的15%),将其作为验证样本,用于计算混淆矩阵与分类指标。
3.1 深度学习与最大似然法对比
用混淆矩阵、总体精度(overall accuracy,OA)、Kappa 系数等指标衡量两种方法对单偏光图像和正交偏光图像的矿物识别精度。这些指标是图像分类与目标识别领域的主要验证指标,用以指示分类器的表现。其中,混淆矩阵可详细地反映分类模型的性能,其中,列表示预测类别,行表示真实类别。通过混淆矩阵,能清楚地看到各矿物像元被正确分类的个数以及被误分的类别和个数。矩阵对角线上的数值越高,说明模型给出的正确像元数越多。在混淆矩阵的基础上,进一步计算得到模型的OA 和Kappa 系数。OA 反映的是被正确分类的像元数之和占总像元数的比例,仅统计混淆矩阵对角线方向上被正确分类的像元数。Kappa 系数同时考虑对角线方向被正确分类的像元以及对角线之外的各种误分、漏分像元,更具综合评价意义。通常,Kappa 系数大于0.8 表明模型具有很好的性能。
基于深度学习得到的单偏光网络模型与正交偏光网络模型的混淆矩阵如图3 所示。基于最大似然法得到的单偏光分类模型与正交偏光分类模型的混淆矩阵如图4 所示。为便于标准化衡量,将混淆矩阵中的像元数比例转化为0~1。
根据4个混淆矩阵,分别计算得到其OA 和Kappa 系数,如表2 所示。由表2知,对于单偏光模型,深度学习方法的OA 较最大似然法的提高了22.1%,Kappa 系数提高了26.3%;对于正交偏光模型,深度学习方法的OA 较最大似然法的提高了29.3%,Kappa 系数提高了36.3%。结合图3 和图4,可知深度学习方法不管是对混淆矩阵中多种矿物的识别精度,还是对模型整体的识别精度均优于最大似然法。说明深度学习方法在矿物识别上具有更强的应对能力,可以取得更好的识别结果。

图3 基于深度学习得到的单、正交偏光网络模型混淆矩阵Fig.3 Confusion matrix of the plane and cross polarized light model generated by deep learning method

图4 基于最大似然法得到的单、正交偏光分类模型混淆矩阵Fig.4 Confusion matrix of the plane and cross polarized light model generated by maximum likelihood
3.2 单偏光与正交偏光融合对比
为获得不同光性图像的矿物识别融合模型,首先需对融合模型中单偏光模型和正交偏光模型的权重进行实验,以获取最佳占比。为此,取0.1 为步长,统计单偏光模型权重在0.1~0.9 变化时,融合模型的识别精度变化趋势,如图5 所示。由图5知,随着单偏光模型权重的增加,融合模型的精度呈先升高后下降的趋势。当单偏光模型权重为0.4,正交偏光模型权重为0.6时,融合模型的精度最高。该结果较合理且具可解释性,结合表2,基于深度学习得到的正交偏光模型的OA 和Kappa 系数均高于单偏光模型的OA 和Kappa 系数,故正交偏光模型权重占比相对较大。
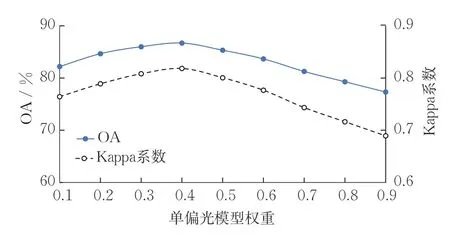
图5 OA,Kappa 系数与单偏光模型权重间的关系Fig.5 OA and Kappa coefficient of the plane polarized light model with different weights

表2 本文深度学习方法与最大似然法的精度对比Table 2 Comparison of the accuracy between deep learning method and maximum likelihood
取单偏光模型权重为0.4,正交偏光模型权重为0.6,计算得到融合模型的混淆矩阵如图6 所示。然后计算得到融合模型的OA 和Kappa 系数,如表3 所示。可知,融合模型的OA 较单偏光模型的提高了11.3%,较正交偏光模型的提高了6.1%;融合模型的Kappa 系数较单偏光模型的提高了15.6%,较正交偏光模型的提高了7.8%,表明融合模型能进一步提高识别精度。

图6 融合模型的混淆矩阵Fig.6 Confusion matrix of the fused model

表3 不同模型的精度对比Table 3 Comparison of the accuracy among different models
为更直观地体现融合模型的矿物识别效果,以火16花岗闪长岩图像的矿物识别为例,对结果进行可视化展示,如图7 所示。由图7(c)和(d)可知,融合模型的矿物识别结果与人工标注结果具有较好的一致性。预测得到的矿物类别和矿物图斑形状与人工标注结果基本吻合,例如红框A 中的石英、斜长石、碱性长石、角闪石、不透明矿物、孔洞等均得到较准确的识别,说明本文模型能对这些矿物进行良好的区分。值得注意的是,部分识别结果与实际不符,例如红框B中,部分角闪石被错分为黑云母。这可能是因为角闪石与黑云母在薄片图像上较相似,二者在单偏光下均偏黄绿色,在正交偏光下的干涉色重合较多,且角闪石图像上的局部纹理、形状等特征不明显,与黑云母产生了一定的混淆,导致模型做出错误判断。

图7 火16 花岗闪长岩单、正交偏光图像及矿物识别结果Fig.7 Display of Huo16 the granodiorite mineral identification result
4 结论
提出了一种基于深度学习的岩石薄片矿物自动识别方法,通过构建语义分割网络自动学习与提取岩石薄片图像矿物特征,获得像素级矿物识别结果。在此基础上,通过软投票法融合单偏光图像与正交偏光图像的识别结果,进一步提高了矿物识别精度。利用南京大学岩石教学样品显微图像数据集,实现了对石英、斜长石、碱性长石、角闪石、黑云母、绿泥石、不透明矿物、孔洞和其他等9 类矿物的自动识别。测试结果表明,总体精度为86.7%,Kappa 系数为0.818,优于传统图像分类法最大似然法的识别结果。由于深度学习方法主要依靠对大量数据的训练与优化,可以预见,随着被标注矿物种类的增加以及图像数据的扩充,其矿物识别能力及准确性将不断提升。
猜你喜欢
液晶与显示(2022年10期)2022-09-28
科普童话·学霸日记(2021年4期)2021-09-05
世界科学技术-中医药现代化(2020年2期)2020-07-25
矿产综合利用(2020年1期)2020-07-24
消费导刊(2018年8期)2018-05-25
中成药(2018年2期)2018-05-09
发明与创新·中学生(2018年1期)2018-02-02
学生天地(2017年30期)2018-01-05
学生天地·小学低年级版(2017年10期)2017-12-11
文物保护与考古科学(2016年4期)2016-05-17
