
基于高维时序特征补充的直播行业用户流失预测模型
2022-12-09 09:12郑桂钖
科技与创新 2022年23期
郑桂钖,徐 宽
(1.华南理工大学工商管理学院,广东 广州 510000;2.中国科学技术大学大数据学院,安徽 合肥 230000)
1 研究背景
随着科技经济不断进步,市场全球化的进程继续深入,消费者的选择也越来越多,面对愈发激烈的市场竞争,各行各业愈发重视用户这一可谓“根基”的资源,且相较于保留老用户,新用户的获取成本通常要成倍地高于前者[1]。因而用户流失预警对企业而言重要性不言而喻。提高用户流失的预测精度,有助于构建用户流失预警体系,让实现对不同用户的挽留、转化、精准营销成为可能,从而提高企业的收益。
国内外学者在用户流失(Customer Churn)问题上主要集中在电信、金融行业。随着移动互联网的兴起,近些年来也有学者关注在线电商、游戏、社交等行业。早期用户流失研究致力于通过实证研究寻找影响用户流失的因素上,目前主要的研究工作都是围绕用户行为数据进行建模、分析,以总结用户流失行为的规律,或者对用户流失行为进行预测,即用户流失预测。在这个问题上,各领域各行业的研究大概可以分为2个方向:①将预测用户的流失时间,基于用户生命周期对用户剩余的生存期进行一个预测,这种方向大多结合生存分析进行研究[2];②将用户流失视为一个流失(Churn)与非流失(Non-Churn)这样一种二分类的问题,这也是绝大多数研究的方向。
目前的用户流失预测模型中,除了行业的选择外,主要差异集中在流失的定义、特征的选择及具体模型的选择。
在电信、金融、保险等偏合约性质的行业用户的定义较为简洁,在这些行业中用户离开一个服务提供商到另一个服务提供商的行为即被称为用户流失[3];但在电商、游戏、社交等互联网相关的非合约性质的行业中用户的流失没有一个明确的公认标准,最常见的是以最长连续无有效活跃天数(假设为T,下称阈值)作为判断标准,当用户连续不登陆天数大于T时则认为用户流失[4],通常而言阈值T与产品的用户黏性呈负相关关系,同时这种朴素的方法也受企业管理层对于用户流失敏感性的影响。
特征选择普遍是基于相关领域知识的,如前面提到有部分学者着重研究影响用户流失的因素,通常选择可描述流失相关因素及用户行为指标来构建特征;此外,也有一些学者结合其他社科领域的知识,如考虑同个社交网络中用户间的相互影响来对特征进行补充[5]。时间序列中往往包含了许多动态信息,但过去的研究往往只是对时间序列进行等距测量或聚类,并简单地视为离散特征输入[6],而鲜有考虑到深入挖掘时间序列的信息。
针对于将用户流失预测作为二分类问题的研究在建模算法上选择多种多样,从算法原理上大致可以分为以决策树、贝叶斯、逻辑回归为代表的基于传统统计学算法,以支持向量机、隐马尔可夫为代表的基于统计学习理论算法,基于启发式学习的预测算法,基于神经网络的深度学习算法及目前最热门的基于集成学习的算法。不同的方法各有特点,在不同的研究中表现也有所不同,但通常来说神经网络和集成学习算法表现会更优[7]。
综上所述,目前用户流失预测研究大部分集中在电信、金融、保险等合约关系明确的领域,而对互联网行业的研究相对较少,尤其是直播行业,若能较好地针对体量巨大的互联网行业用户进行准确的流失预测,将带来十分可观的经济效益。针对以往研究中粗糙的流失定义及缺乏对时间序列信息的挖掘问题,本文将从数据表现出发对用户流失进行更细粒度的指标量化和定义,同时对时间序列这一重要信息进行深入挖掘,对互联网直播行业用户进行流失预测,最后探究不同算法模型下与基于领域知识的模型在流失预测效果的差异。
2 理论与方法
2.1 时间序列特征
通过对时间序列进行特征提取,再将提取后的特征用以模型训练是解决机器学习中时序相关问题的常见做法。如何从时间序列中提取有效特征也是一个热门的研究领域,早期学者们通常会提取与序列分布相关的基本特征,如最大值、最小值、偏度、峰度等[8]。除此之外,在不同应用领域下也提出了针对性的带领域知识的特征抽取算法,如基于小波特征来监测齿轮震动以诊断机器故障[9],通过提取拟合指数函数的参数来估计轴承的剩余寿命[10]等。在后期,FULCHER等[11]提出了(Highly Comparative Time-series Analysis,HCTSA)框架并开发了HCTSA工具箱,其原理是利用庞大的科学工作语料库,集成天体物理学、金融、数学、工业应用等各个领域的特征生成算法,构建出时间序列的数千个特征,包括数据值的分布信息(如高斯性,离群值的性质)、自相关结构(如功率谱度量)、平稳性(性质如何随时间变化,如一阶差分)、熵和时间可预测性的信息理论度量、线性和非线性模型对数据的拟合状况等,并使用线性分类器进行特征选择,以求全面地量化和理解时间序列蕴含的有效信息。文献[12]也证明了在许多标准数据集上,基于HCTSA时间序列特征建模的方法在分类任务上表现优于传统的基于时间序列相似度方法。
受FULCHER和JONES等的启发,2016年CHRIST等[13]在HCTSA的基础上,提出了基于可扩展假设检验的时间序列特征提取(Feature Extraction on basisof Scalable Hypothesis tests,FRESH)算法框架。FRESH将特征抽取算法精简至63种,在不同参数下计算后共计得到794个特征;另外,FRESH使用基于假设检验的方法进行特征选择。2018年CHRIST等[14]也基于Python完成了对应软件包TSFRESH的实现,在特征提取与过滤算法上实现高度并行,同时也兼容了常见的机器学习框架,如scikit-learn,numpy等,便于直接应用到实际生产研究中。同时,在UCR标准时间序列分类数据集上的评估结果表明,FRESH方法在预测精度和计算开销上相较于经典的基于时间序列相似度方法及特征筛选算法均有一定优势[13]。
2.2 算法原理
本文涉及的机器学习算法的原理如表1所示。
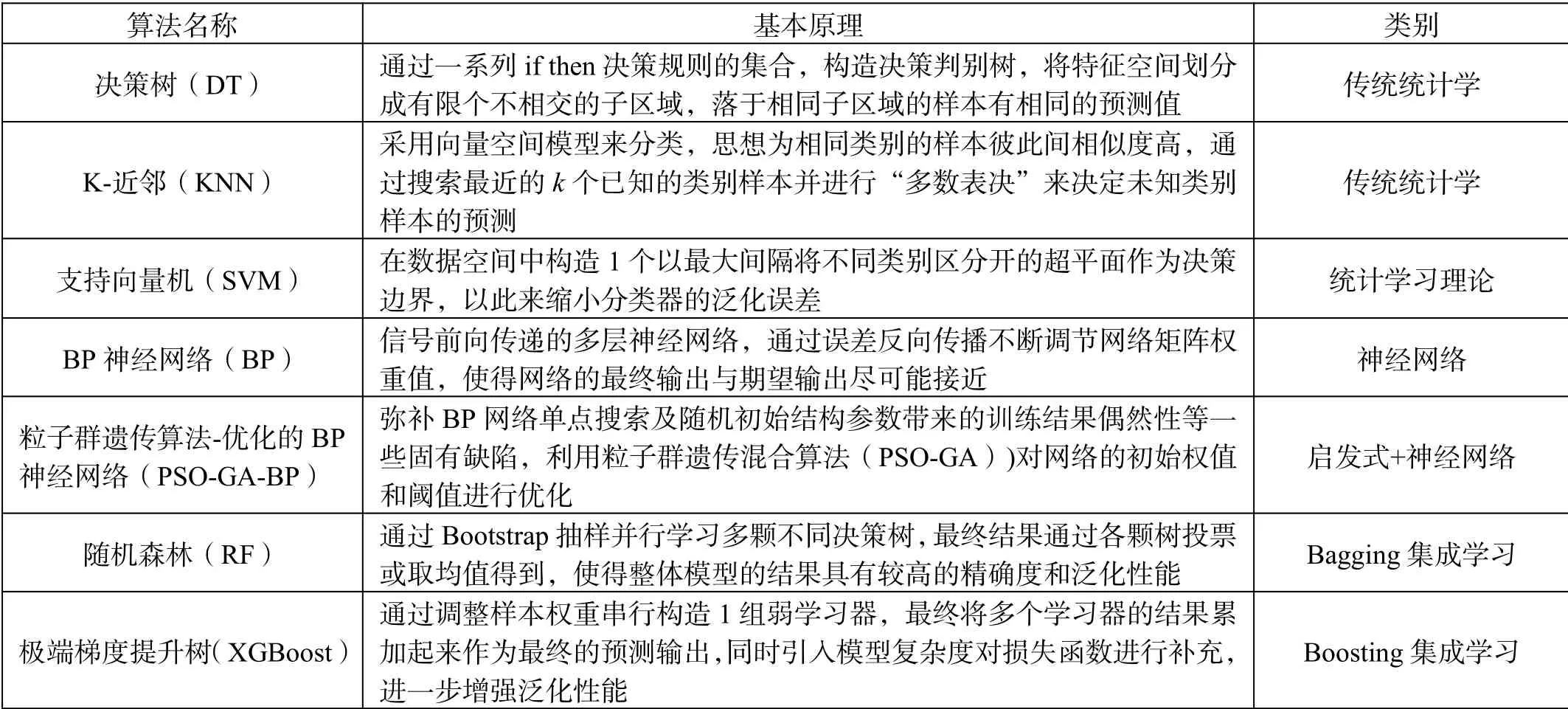
表1 算法概要
3 实例分析
3.1 数据来源
本文使用的数据来自国内某移动互联网研发公司的一款海外直播APP,以2020-10-01的某大区直播活跃用户于2020-09-18—2020-10-01共14 d内的各类行为及个人基本信息数据为基础,对这部分用户进行流失预测。其中,活跃用户定义位用户当天在直播房间内总时长不低于3 min,太少的时长有可能是因为用户仅仅为了签到或误操作,并不包含有效行为信息。出于信息完整性及实际考虑,数据中剔除了注册日期少于14 d的用户,一方面这部分用户在过去周期内的数据不完整;另一方面注册少于14 d的用户大体上算是新用户,他们的行为规律相比于已经长注册时间用户而言不够稳定,同时存在大量的用户注册后短时间内便流失,这些用户往往非APP的目标用户,他们的流失也并非企业关心的。
最终数据集中共包括219 910个用户,其中有45 099名用户被标记为流失用户,占比20.51%。
3.2 问题描述
用户流失预测的本质就是利用用户过去一段时间的行为特征等信息,从而来预测用户在未来一段时间是否会流失。因此从大层面上看,首先需要对用户流失做出合适的定义,接着选择相应的特征信息用以最后的建模预测。
而从时间维度上看,整个流失预警过程可以分为以下3个窗口:首先是行为观察窗口,在该窗口内对用户的特征进行收集,并在窗口末尾用以模型训练;从而来预测用户在未来的一段时间内是否流失,也即进入了流失预测窗口;最后是流失判别窗口,该窗口可以观察在预测窗口中定义为流失的用户是否真正流失,从而来辅助流失定义。用户流失预警过程如图1所示。
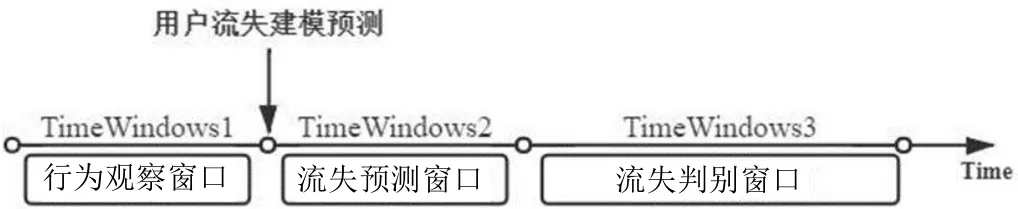
图1 用户流失预警过程
3.3 特征构建
在模型特征信息选择上分别构建2组特征,一组主要由用户的行为特征及个人特征属性组成,也是绝大多数研究所使用的,称为常规特征;另一组为对用户TW1的时长时间序列进行提取后的特征,称为高维时间序列特征。
3.3.1 常规特征
常规特征主要由以下4部分信息组成:①用户活跃相关信息,包括活跃/上麦的天数及总时长、平均时长,进房次数等;②用户营收相关信息,包括送礼/收礼人数、次数、金额,最大充值金额,背包礼物余额等;③用户社交相关信息,包括发送IM消息数量、关注主播数、好友数、被关注数等;④用户个人画像信息,包括国家、年龄、性别、注册至今天数、是否有过充值/消费行为等。
从直观上来说,用户在TW1内的行为是对其行为特征最好的刻画,但考虑到不同用户对于APP的黏性及所处生命周期阶段不同,因此将用户的历史行为信息也纳入特征中,最终常规特征共包含41维特征。
3.3.2 高维时序特征
通过TSFRESH框架提取了用户在TW1内的每日活跃时长序列的794个特征,主要包括以下几个部分:①时间序列值分布的基本统计信息,包括分布、散度、高斯性值、离群值属性等;②线性相关性,包括自相关性、功率谱特征等;③平稳性,包括StatAv、滑动窗口测量、预测误差等;④信息论与复杂性度量,包括自互信息、近似熵、Lempel-Ziv复杂度等;⑤线性和非线性模型拟合,包括自回归移动平均(ARMA)、高斯过程和广义自回归条件异方差(GARCH)模型的拟合优度、估计和参数值等。
3.4 数据预处理及特征工程
数据质量及特征工程的好坏会显著影响建模结果的准确和有效性,也是研究的可靠性保障,其主要包含以下工作。
3.4.1 异常值、缺失值处理
将超过正常使用所能达到的数据定义为异常数据,如异常心跳上报的时长数据及触发相应风控策略的营收数据等。经过统计,存在异常数据的用户占比低于0.01%,故将这部分用户直接剔除。而在缺失值上,最高缺失特征缺失值占比为0.29%,分别使用众数、均值对离散及连续变量进行缺失值填充。
3.4.2 特征筛选
特征筛选目标是尽可能在不引起重要信息丢失的前提下去除掉冗余甚至无关特征,保留与预测目标相关的特征。使用费舍尔精确检验(Fisher'sexact test)[15]及曼-惠特尼U验(Mann-Whitney U test)对二分类特征及数值特征进行假设检验筛选;针对高维时序特征,使用Benjamini-Yekutieli方法[16]控制多次假设检验的错误发现率FDR(False Discovery Rate)。显著性水平α均取0.05。经过筛选后,常规特征保留39维,高维时序特征保留326维。
3.4.3 数据标准化
实验中所使用的KNN是基于欧氏距离的算法,在计算过程中必须消除特征量纲的影响;同时,对于使用梯度下降来优化的算法,如SVM、BP、LSTM,归一化有助于加快收敛,因而在这些模型训练前,将对连续特征进行z-score标准化处理,同时在离散特征上采用独热编码。
3.5 实验设计
上文中提到,过去研究中具体用于流失预测建模的算法繁多,从大方向上主要可以分为传统统计学、统计学习理论、启发式、神经网络及集成学习5类。面对各式各样的算法选择,实验的第一部分将基于常规特征,选择各类算法中的主要代表模型来进行建模,探究不同模型的表现,同时也将得到的最优模型作为后续实验模型参照的baseline基准模型;同时,针对过去研究中对时序特征缺乏考虑的问题,实验的第二部分先使用高维时序特征进行建模,再将常规特征与高维时序特征进行融合建模,观察高维时序特征是否有助于提升模型表现。特征建模简要流程如图2所示。
模型构建的具体过程如图3所示,首先用特征工程的方法对初始数据集进行预处理,然后将清洗好的数据集按7∶3的比例随机拆分为训练集与测试集。训练集用以模型训练,以准确率为目标使用对半网格搜索(Halving Grid Search)[17]或贝叶斯优化(Bayesian Optimization)[18]选择最优参数,并进行5折交叉验证。确定最优参数后使用完整训练集进行模型训练,而后在测试集上进行预测得到预测结果,并使用准确率(Accuracy)、召回率(Recall)、F1值(F1-score)及AUC值全面地评估模型效果。

图2 特征建模简要流程

图3 流失预测模型构建过程
3.6 实验结果
3.6.1 基于常规特征建模
从算法使用频率、趋势及数据特性出发,在这部分实验中,以决策树DT、最近邻算法KNN作为传统统计学算法的代表,以支持向量机SVM作为统计学习理论算法代表,以粒子群遗传混合算法优化的BP神经网络作为启发式算法与神经网络的代表,并选择随机森林RF和XGBoost作为Bagging和Boosting等集成算法的代表。实验预测结果如表2所示。
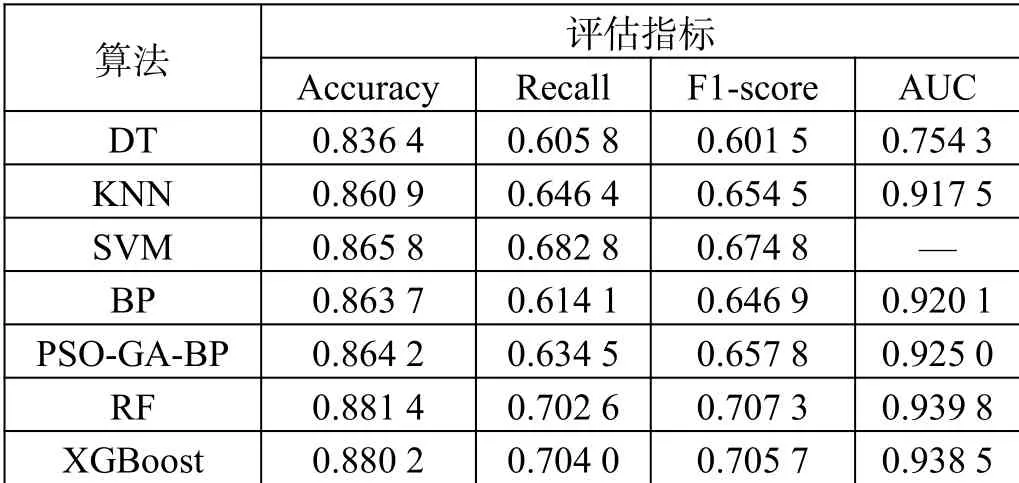
表2 基于常规特征建模的模型预测结果
从表2中可以看到,集成学习算法总体表现最优,基于Bagging集成学习的随机森林算法在准确率、F1值及AUC值取得最高得分,而基于Boosting集成学习的XGBoost在召回率上有最佳得分。此外,基于统计学习方法的SVM表现最优,经过PSO-GA改进后的神经网络次之,改进后的神经网络也相较改进前在正例样本表现上更优,有更高的覆盖率和F1值,而基于传统统计学习的决策树及K近邻算法表现较差。因此,选择基于常规特征进行建模的随机森林模型作为后续实验参照的基准模型。同时由于集成学习算法的出色表现,后续建模也更倾向使用集成学习算法。
3.6.2 基于时序及融合特征建模
这部分实验首先使用HCTSA方法提取出的时序特征进行建模,模型算法选择使用在前面表现较好的随机森林及XGBoost;然后将时序特征与常规特征进行融合,使用融合后的特征进一步对模型进行训练,观察模型在3组特征下的表现情况,如表3、表4所示。
为了让实验结果更加直观可视化,将实验结果以图4的方式呈现出来。从图4中可以看出,无论是随机森林还是XGBoost,基于常规特征建模的模型表现比基于高维时序特征建模的表现更好,这也意味着比起只考虑时间相关特征的高维时序特征,包含了如营收、社交及用户画像等多样化且更全面的常规特征在预测中有着不可忽视的作用;另一方面,基于融合特征建模的模型在各个指标的表现均优于在常规特征基础上建模的模型,尤其在召回率及F1值上有显著提高。相较于常规特征建模,2个模型在召回率上分别提升了5.98%及6.83%,在F1值上分别提升了2.39%及3.42%,这说明模型不仅整体预测精确度更佳,同时也提升了对于正例样本的捕捉能力,即对流失用户的判别能力,这也恰恰是流失预警模型最为需要和关注的。这也体现出高维时序特征的优势,其全面的信息弥补了常规特征中对时序缺乏深入挖掘的不足;同时,常规特征中考虑特征更加多样全面也补充了特征来源,将2种特征融合互为补充后模型得以进一步优化提升。
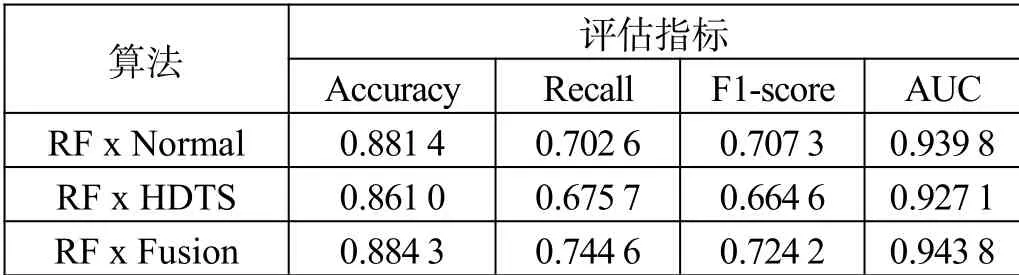
表3 基于时序及融合特征的随机森林结果

表4 基于时序及融合特征的XGBoost结果
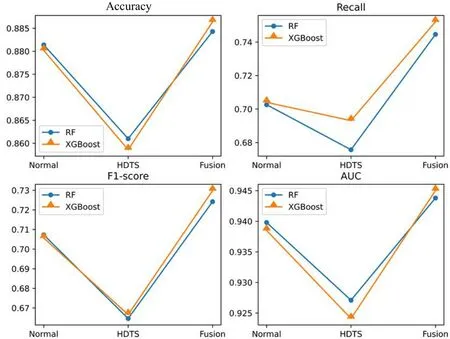
图4 模型的准确率、召回率、F1值和AUC对比图
4 总结
本文使用某直播APP真实的业务数据对用户进行流失预测。首先基于过去研究中常涉及的常规特征,选择常见的算法进行预测对比,包括基于传统统计学的KNN、统计学习方法SVM、启发式优化神经网络PSO-GA-BP、集成学习算法RF、XGBoost等,得出集成学习算法总体表现最优的结论。然后从用户过去的活跃时长序列中提取高维时序特征,与常规特征进行融合,用于集成学习算法训练。数据结果表明,基于融合特征方法能够使模型得到进一步的优化提升。
本文在时序特征的提取上只考虑了用户时长这一时间序列,未来可进一步考虑对更多序列进行特征提取以获取更多信息,如用户操作序列等。同时,预测流失用户的最终目的是提前判别用户状态,进而采取一定手段留住用户,探索如何更有针对性地将预测结果与客户挽留措施相结合也是非常有价值的方向,尤其在用户价值评定及具体挽留成本方面,目前研究仍较匮乏,对用户进行全面合理的价值评定及采用适当的成本进行高效促活,将有助于提升企业的切实收益。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
计算技术与自动化(2022年1期)2022-04-15
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
成都信息工程大学学报(2021年5期)2021-12-30
宁夏师范学院学报(2021年1期)2021-03-18
意林·作文素材(2021年23期)2021-01-22
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
计算机技术与发展(2020年2期)2020-04-15
初中生世界·九年级(2020年2期)2020-04-10
