
基于差分进化算法的正态分布均值变点检测
2023-02-01 07:44朱伟业成金良琼
科技创新与应用 2023年2期
朱伟业成,金良琼,沈 婷
(贵州民族大学 数据科学与信息工程学院,贵阳 550025)
变点检测问题自20世纪50年代被提出以来,一直是统计领域当中的一个热点问题。变点指的是从某个时刻开始,样本的分布或者数字特征发生了变化。变点检测就是要检测数据中是否存在变点及对变点的个数和位置进行估计。随着社会的发展,变点检测理论已广泛运用在经济、医学、气象和图像处理等领域。
在变点检测问题中,均值变点是一类重要的变点类型,数据的均值发生变化往往引起人们的重视。针对正态分布序列的均值变点问题,中外许多学者都对此进行过研究。Hawkins[1]应用极大似然法研究正态序列均值变点问题。Sen等[2]利用贝叶斯方法给出了均值变点的精确和渐进的分布函数。Kim等[3]采用一种退火随机逼近蒙特卡洛法(ASAMC)对韩国传染病数据进行均值变点研究。赵江南等[4]基于ASAMC方法对正态分布序列均值变点问题进行研究并将结果应用于乌鲁木齐市的温度变点检测问题。胡丹青等[5]在贝叶斯后验分布的基础上应用遗传算法,研究了线性回归模型中的多结构变点问题。王晓原等[6]运用加速遗传算法结合均值变点模型对交通流变点问题进行分析研究。郭卫娟[7]采用二分法对方差已知且相等的正态分布均值多变点问题进行研究,给出了变点位置的后验分布。缪柏其等[8]基于信息论准则,研究了异方差情况下的多元正态分布均值变点问题。何朝兵等[9]采用马尔科夫蒙特卡洛方法研究了左截断右删失情况下的对数正态分布序列的变点检测问题。杨丰凯等[10]采用一种非迭代抽样方法(IBF)与迭代Gibbs抽样算法做对比,研究了在无信息先验条件下的正态分布均值单变点问题。对于方差已知且相等的正态分布序列均值变点模型,贝叶斯法是一种常用的研究方法,但贝叶斯法存在的不足之处就是后验分布的计算量较大。基于此,本文将差分进化算法与贝叶斯法结合,对正态分布序列均值变点问题进行研究,模拟结果表明该方法能快速有效地计算后验分布的最大值,并且检测出均值变点的位置。
1 正态分布均值多变点模型

式中:μ1≠μ2,μ2≠μ3…μk≠μk+1,σ2为已知常数,则称该模型为正态分布序列均值变点模型,k为变点个数,r1,r2,r3...rk为变点位置。当k=1时,该模型为单变点模型,k>1时,为多变点模型。本文考虑的问题是在k已知的情况下,如何估计变点位置,即r1,r2,r3...rk的值。
针对变点问题的研究方法主要有(加权)最小二乘法、极大似然法、非参数方法和贝叶斯法等。贝叶斯法利用贝叶斯理论,对包括变点位置在内的未知参数选取合适的先验分布,利用似然函数推导变点位置的后验分布,结合样本数据计算分布的最大值,对变点的位置进行估计。运用贝叶斯法,如何选取参数的先验分布是关键,本文选择的是无信息先验分布。
2 贝叶斯估计
2.1 变点位置的无信息先验分布
正态分布序列均值变点模型中的未知参数为变点位置r1,r2,r3…rk和分布的均值μ1,μ2…μk+1。无信息先验分布可以理解为对参数的任何可能值既无偏爱,又同等无知[11]。在1,2…n-1上每个变点序列出现的概率都是相等的,因此本文选取r1,r2,r3…rk的联合先验分布为
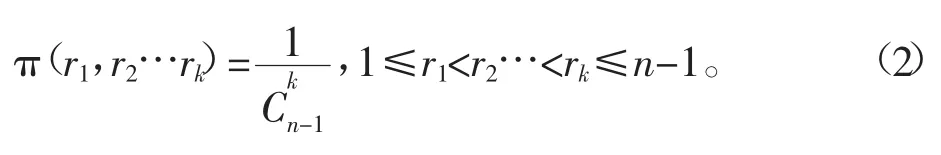
2.2 正态均值的无信息先验分布[11]
正态分布中的均值μ为位置参数,总体X的密度函数具有形式p(x-μ)。为求均值μ的无信息先验分布,对X做平移变换,得到Y=X+c,对参数μ也做同样的变换,得到η=μ+c。设分布Y有密度函数p(y-η),此时,μ和η应有相同的先验分布。即

π(·)和π*(·)分别为μ和η的无信息先验分布。此外,由变换η=μ+c可得到η的无信息先验分布为

比较式(3)和式(4)可得π(η)=π(η-c),由于η与c的任意性,可得均值μ的无信息先验分布为

这是正态均值μ的一个广义先验分布。
2.3 变点位置的后验分布
设参数θ=(r1,r2,…rk,μ1,μ2…μk+1),假设变点位置与均值参数互相独立,即

利用贝叶斯公式

可得θ的后验分布为
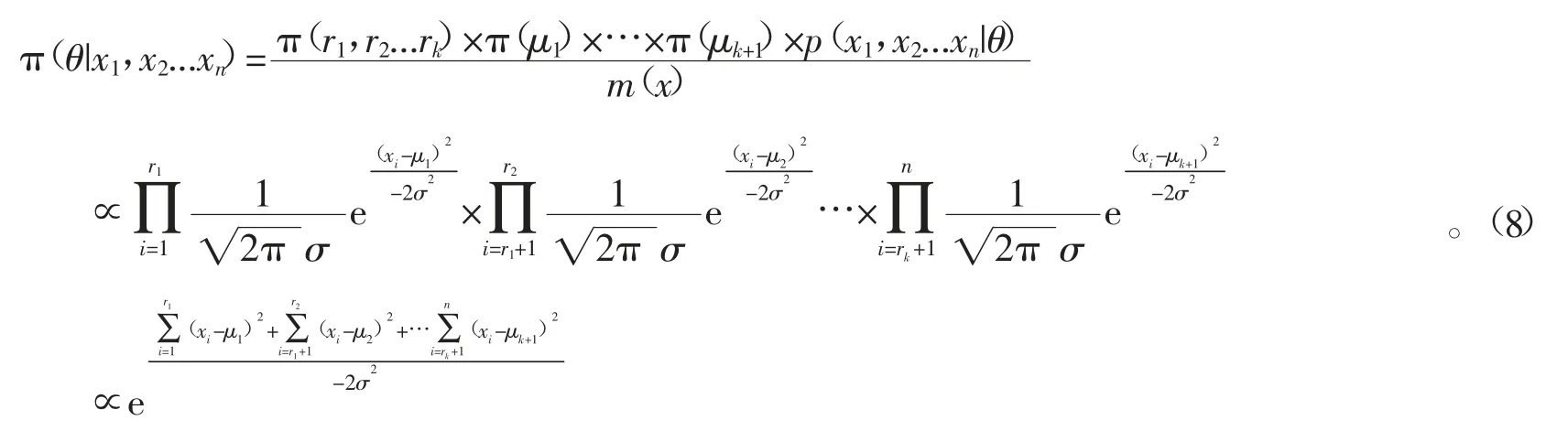
对式(8)中的μ1,μ2…μk+1积分,可得r1,r2,…rk的后 验分布为

为计算方便取对数,得
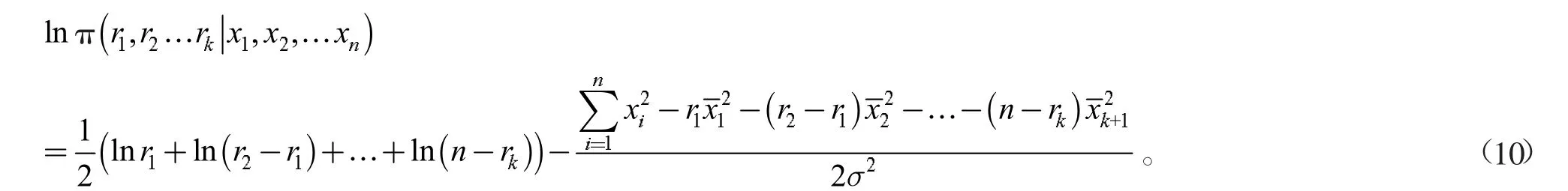
在多变点问题中,变点个数越多,变点位置的参数空间越复杂,计算后验分布最大值的计算量也变得越大。为快速找到该后验分布的最大值,本文引用差分进化算法进行分析。接下来介绍差分进化算法的原理和具体步骤。
3 差分进化算法介绍
差分进化算法(DE)是一种高效的全局优化算法。该算法模拟生物进化的过程,首先随机生成初代种群,然后通过变异、交叉操作生成子代种群,根据“优胜劣汰”原则,淘汰适应度低的种群,保留适应度高的种群。经过不断迭代进化,最终收敛到最优结果。差分进化算法具备结构简单、收敛快和自适应能力强等优点,被广泛运用在各个领域。具体算法流程如下[12-13]。
3.1 初始化种群
首先确定各个参数,包括迭代次数G、种群大小NP、种群维数D、变异算子F、交叉算子CR,以及搜索空间的上下限xmax和xmin。然后随机生成NP个长度为D的解向量xi,j,i=1,2…NP,j=1,2…D,xmin≤xi,j≤xmax。种群大小NP一般选取[50,200]。
3.2 变异操作
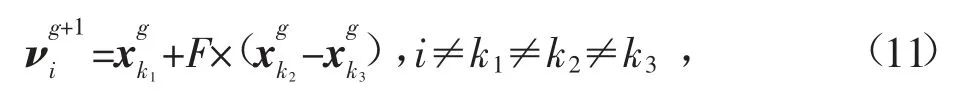
式中:i,k1,k2,k3为两两互不相等的随机整数表示第k个种群的第g代。在变异操作中,变异算子F取值范围为[0,2],F过小可能陷入局部最优,F过大则不容易收敛,一般取[0.4,1]居多。另外,如果变异以后的值νi,j超出了边界,可以随机在范围内再选择1个数,或者直接取边界值。
3.3 交叉操作

式中:rand(0,1)是1个0到1的随机数,变异算子CR用来控制子代向量值是变异向量值还是原向量值,jrand是1个0到D的随机整数,其保证了子代向量至少有1个元素与原向量不同。
3.4 选择操作
选择操作的原理是计算子代向量和原向量各自的适应度,如果子代向量的适应度更高,则将子代向量保留,替代原向量进入下一代循环,否则保留原向量。具体表达式如下

式中:f(·)为向量对应的适应度函数。
3.5 退出循环
当最后的解向量满足所需要的精度,或循环次数达到预设值G后,退出循环,否则重复步骤3.2到步骤3.4。
4 数值模拟
在变点个数已知的情况下,对正态分布序列均值变点的位置进行检测。考虑变点个数为2的情况,模型如下

根据上述模型,分别生成样本量为300、400、500、600的数据作为检测的样本。对应的变点位置分别为100和200、150和300、200和350、200和400。采用2种差分进化算法进行估计:差分进化算法和自适应差分进化算法。两者的不同之处在于自适应差分进化算法将变异算子F设为1个随迭代次数变化的值,在迭代初期,F较大,能保证种群多样性;迭代后期,F较小,能提高搜索效率。算法的参数选择:种群数NP=50,最大迭代次数Gm=20,变异算子F0=0.5,交叉算子CR=0.4,自适应变异算子由式(15)产生

式中:G表示当前迭代的次数。使用Matlab软件进行数值模拟1 000次,结果见表1、表2。

表1 不同样本量下差分进化算法的r1、r2识别结果

表2 不同样本量下自适应差分进化算法的r1、r2识别结果
从表1和表2可以看出,在样本量分别为300、400、500、600的情况下,迭代20次,得到的变点位置r1、r2的估计值与真实值的相对误差均小于0.05%,标准差均小于1.3。说明2种方法均能够较好地识别出变点位置r1、r2。对比2种方法估计结果的相对误差与标准差,除了在样本量为400的情况下,差分进化算法对于r1的估计相对误差为0.007%,大于自适应差分进化算法对应的相对误差0.005%以外,其余情况差分进化算法的估计结果的相对误差与标准差都小于自适应差分进化算法,整体估计效果更好。
在样本量为300、400、500、600的情况下,统计2种方法正确识别变点位置r1、r2及正负1个或2个单位偏差的次数,对比评估2种方法的识别率,结果见表3、表4。

表3 不同样本量下基本差分进化算法的r1、r2识别率

表4 不同样本量下自适应差分进化算法的r1、r2识别率
由表3和表4可以看出,除了在样本量n=300的情况下,差分进化算法对第二个变点正负1个单位偏差的识别率为96.7%,低于自适应差分进化算法的97%。其余情况下,差分进化算法的识别率均大于等于自适应差分进化算法,进一步说明前者的识别效果更好。从表中还看出r2的识别率大于r1的识别率,这是因为r2前后的均值跳跃度要大于r2前后的均值跳跃度,2组数据的差异更明显,因此更容易识别出来,符合常理。
为更加直观地观察估计效果,以样本量为600的实验结果为例,绘制r1、r2的散点图如图1—图4所示。

图1 差分进化中r1的散点图

图2 自适应差分进化中r1的散点图
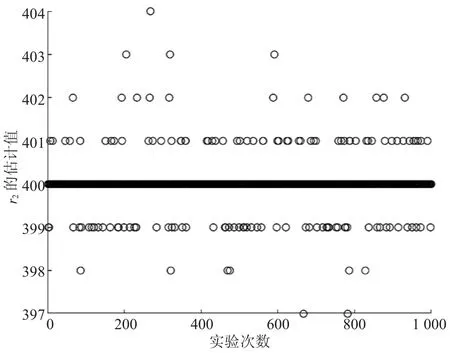
图3 差分进化中r2的散点图
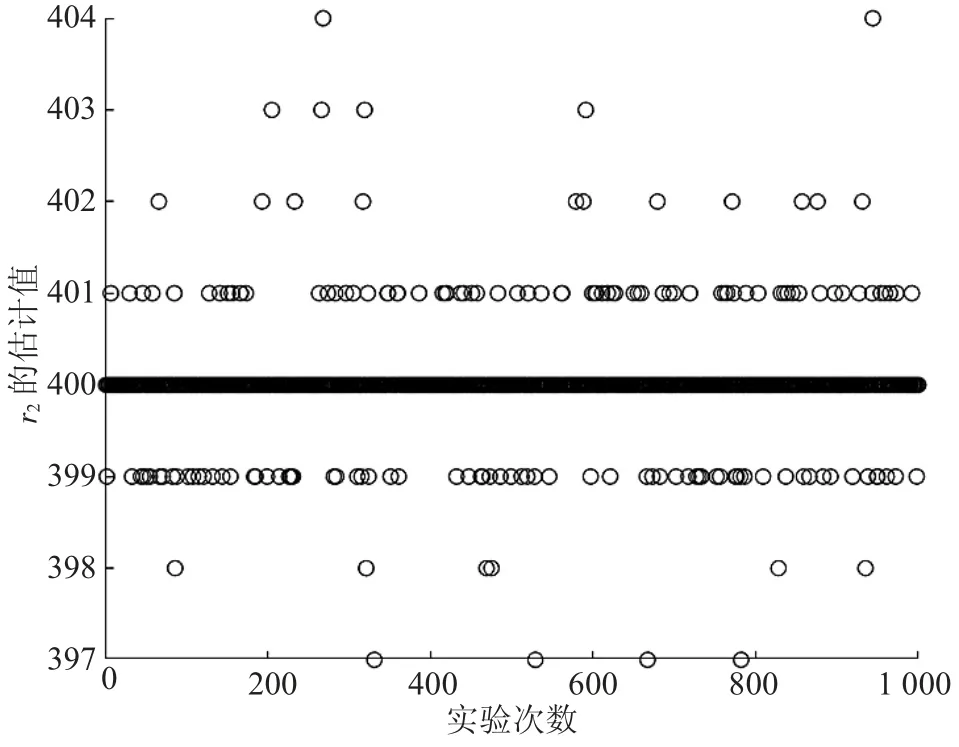
图4 自适应差分进化中r2的散点图
由图1—图4可以明显看出,2种方法对r1、r2的识别结果集中在各自对应的真值附近。其中,对r2的识别结果比r1更为集中,效果更好。
为了进一步对比2种方法的优劣,绘制迭代图如图5、图6所示。

图5 差分进化算法迭代图
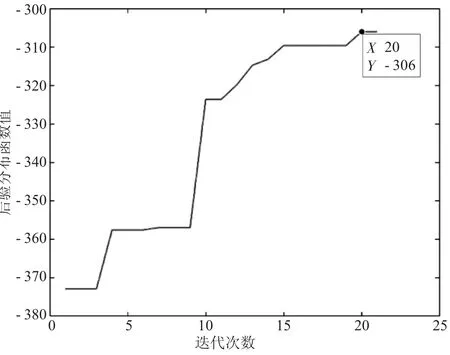
图6 自适应差分进化算法迭代图
从图5和图6可以看出,差分进化算法在迭代到第16代的时候就已经搜索到了最优解,但自适应差分进化算法到第20代的时候才搜索到最优解,这说明差分进化算法能够更快地收敛到函数的最大值。为探究迭代次数对2种方法估计效果的影响。下面将最大迭代次数Gm增加到100次,以样本量为600的变点模型为例,进行数值模拟,结果见表5、图7、图8。

表5 最大迭代次数Gm=100下的2种算法的识别结果
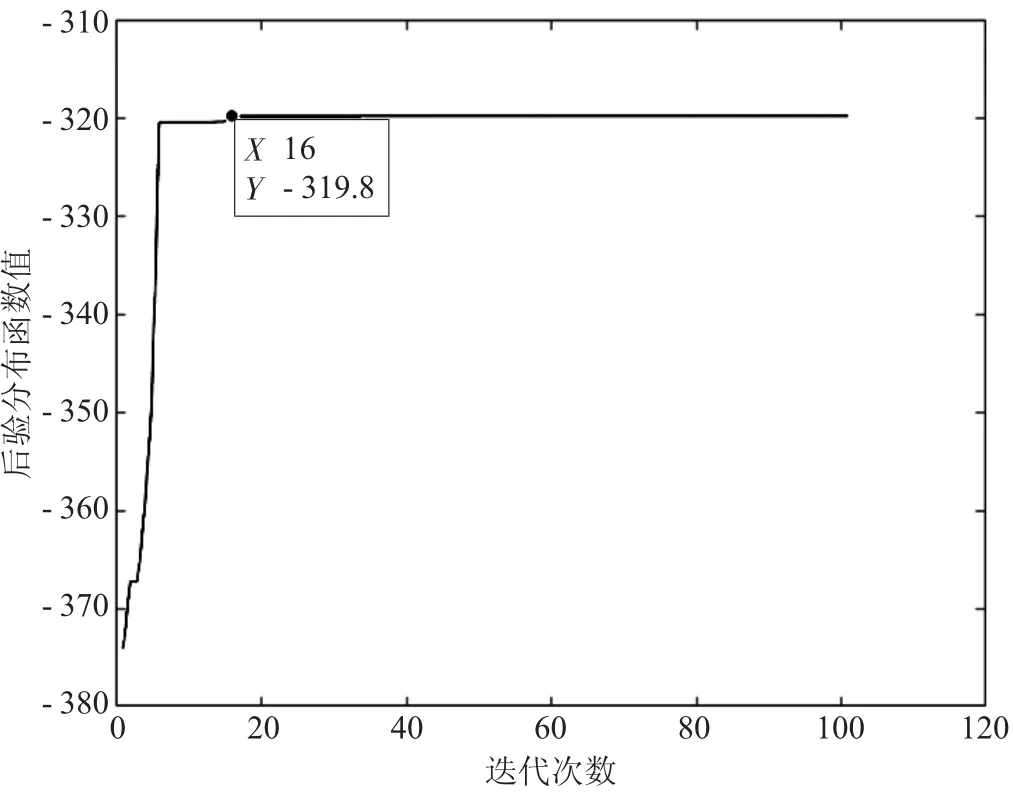
图7 Gm=100时差分进化算法的收敛图

图8 Gm=100时自适应差分进化算法的收敛图
由表5、图7、图8可知,在迭代次数足够大的情况下,2种算法对变点位置的检测效果相同。
由此可知:在迭代次数较小时,差分进化算法的检测效果要优于自适应差分进化算法。当迭代次数达到一定的程度时,2个方法的检测效果一致。
为了观察变点检测前后序列的均值特征,绘制变点检测前后的均值特征图如图9、图10所示。
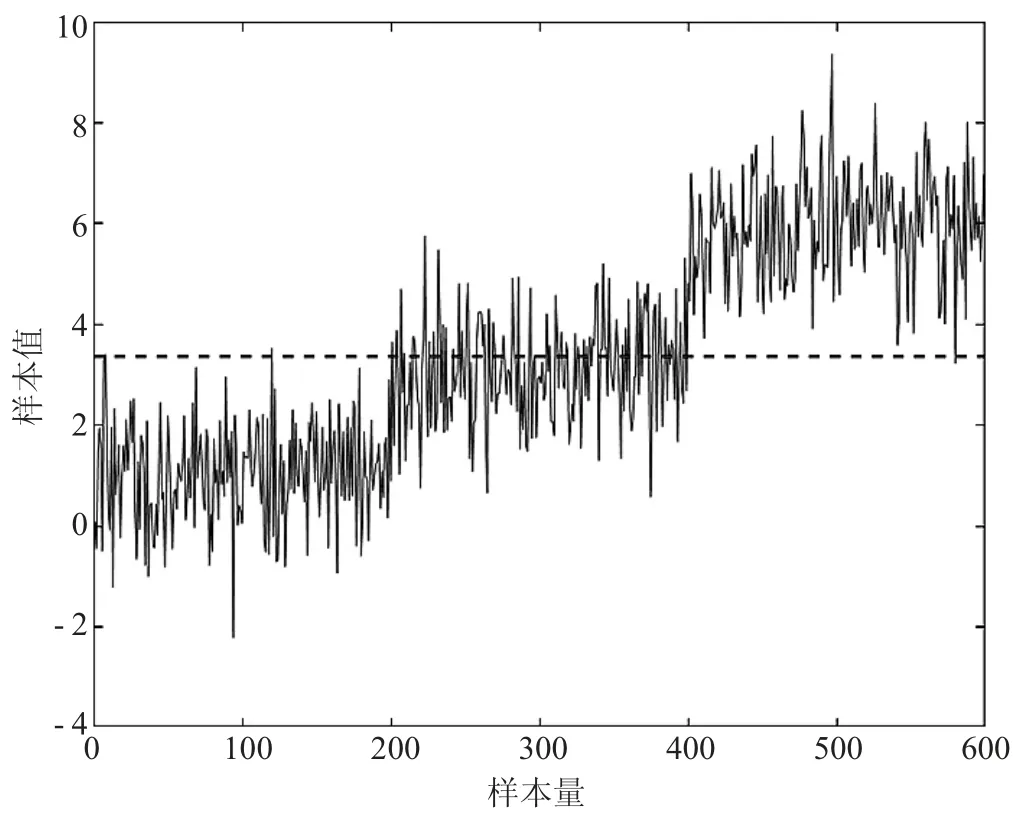
图9 变点检测前的均值特征

图10 变点检测后的均值特征
图9的虚线表示无变点模型的数据均值特征,图10的虚线表示在变点模型下的数据均值特征。可以看出变点模型将数据分成3段,每段分别刻画数据的均值。更符合数据的真实情况。这说明了本文引用的差分进化算法能够检测出变点的位置从而更好地解释正态分布均值的特征。
5 结束语
本文在贝叶斯理论的基础上,对已知变点个数条件下的正态分布序列均值变点模型进行研究。首先选择无信息先验作为变点位置和正态均值的先验分布,利用贝叶斯公式得到变点位置的后验分布。为快速计算后验分布的最大值,引入2种差分进化算法结合后验分布进行优化并进行数值模拟。模拟结果表明:2种算法均能够有效识别出变点的位置。其中,差分进化算法的效果要优于自适应差分进化算法,因此在选择方法时,应选择差分进化算法估计变点。综上,使用差分进化算法结合贝叶斯法能够更有效地检测变点个数已知下的正态分布序列均值变点模型中的变点位置。
猜你喜欢
内蒙古统计(2021年4期)2021-12-06
数学物理学报(2021年4期)2021-08-30
湖北第二师范学院学报(2020年8期)2020-10-13
河南科学(2020年4期)2020-06-03
安徽师范大学学报(自然科学版)(2020年1期)2020-03-28
中国卫生统计(2019年3期)2019-07-10
统计与决策(2019年6期)2019-04-22
雷达学报(2017年6期)2017-03-26
郑州大学学报(医学版)(2015年2期)2015-02-27
统计与决策(2013年16期)2013-10-20
