
炼化装置中检测仪表与执行机构的异常诊断
2023-02-13 09:27吴岩松王少贤王若暄
化工自动化及仪表 2023年1期
王 珠 吴岩松 王少贤 王若暄
(中国石油大学(北京)信息科学与工程学院自动化系)
异常一般指的是系统由于出现一个或者多个参数、特性低于正常指标,出现了系统存在安全隐患的情况[1]。 工业上的异常检测分为单个参数的异常检测与报警和控制回路中关联变量的异常检测。 关联变量(即操作变量和被控变量)的异常检测能够有效地反映出工艺过程中工况的迁移,以及执行机构和检测仪表所发生的异常情况。
目前,炼化装置中异常工况的检测方法根据原理可分为3类:基于知识的方法、基于模型的方法和基于数据驱动的方法[2~4]。 其中,使用基于知识的方法和基于模型的方法实现故障检测需要对机理进行充分的分析并掌握丰富的现场经验,导致这两种方法在日趋复杂的化工生产过程中难以获得良好的效果。 随着信息时代的发展,智能仪表、传感网络等实现了对关键点位的全方位检测,同时,也储存了海量的体现装置运行状态的过程数据[5,6]。 如今,基于数据驱动的方法无需复杂机理知识,从历史数据中挖掘有效信息的优势被显现出来,成为应用在故障检测中的重要技术手段[7]。
基于数据驱动的常用诊断方法主要包括:基于统计原理的方法、 时域和频域特征分析方法、包含人工智能的机器学习算法。 基于统计原理方法主要针对单个参数,以相关过程变量的历史数据为基础,借助多元投影等手段将历史数据划分为不同子空间, 进而构造异常判断的控制限[7,8]。LI W H等提出将递归主元分析(Principal Component Analysis,PCA)应用于过程监控中[9]。CAI L和TIAN X提出一种基于鲁棒独立成分分析(Independent Component Analysis,ICA) 的故障检测方法, 一定程度上解决了传统ICA方法对异常值敏感的问题[7,10]。 ZHAO S J等提出针对多阶段的间歇过程的基于偏最小二乘(Partial Least Squares,PLS)模型[11]。 FAZAI R等提出将广义似然比检验与PLS方法相结合, 建立故障检测模型并应用在化工过程检测中[12]。 与PCA、PLS等传统多元统计方法相比,支持向量机描述(Support Vector Data Description,SVDD)训练数据不存在高斯限制,可扩展到非线性情况, 逐渐应用于异常检测[7,13,14]。张汉元和田学民提出一种改进的SVDD算法,将其应用于非线性过程的故障检测[15]。
机器学习算法的核心是分类器,基于打好标签的正常与异常数据进行分类,实现对异常的诊断。 YéLAMOS I 等提出一种基于支持向量机(Support Vector Machine,SVM) 的化工过程故障诊断方法[16]。 程换新和王建庆引入惩罚正则项优化深度置信网络 (Deep Belief Network,DBN)[17],提高了故障诊断准确率。 李钢和周东华提出基于SPM的多变量连续过程在线故障预测方法[18],可应用于线性时不变系统。 张浩等提出基于关联变量时滞分析卷积神经网络的生产过程时间序列预测方法[19],可应用于大时滞系统的长步长时间序列预测。HAN Y等对长短期记忆(Long Short-Term Memory,LSTM) 网络的隐含层节点个数进行优化,建立了一种基于LSTM的化工过程故障检测模型[20]。 窦珊等对LSTM进行时间序列重建,实现对生产转置的异常检测报警[21]。
上述多元统计方法与机器学习方法都属于“监督”学习,需通过大量历史数据训练产生数据的标签,过程比较耗时。 “无监督”学习在数据分析、 模式识别及机器学习等领域是一项重要的技术[22]。 其中,k-means聚类算法具有简单、高效的优点。 刘丽云等将其应用于TE过程的故障诊断[23]。
针对闭环反馈控制回路关联变量的异常检测,可以在两个关联变量之间建立有效的数学模型。 采用相关分析法辨识对象的脉冲响应函数[7,24]。
通常基于数据驱动的故障/异常检测,只针对单一变量或具有关联变量的检测仪表与执行机构。 对于实际复杂工业控制回路,无法判断其故障/异常是由噪声干扰、工况迁移还是检测仪表与执行机构发生异常造成的。 笔者在单变量历史趋势的基础上进一步对控制回路的工况迁移、检测仪表或执行机构进行异常检测,提出一种通过相关分析提取动态特性, 建立有限脉冲响应模型,通过有限脉冲响应模型取值参数准确表示控制回路的运行状态,k-means聚类算法对整体动态特性进行聚类分析,SVDD根据聚类密度建立一个或多个超球体的方法来实现对单变量和多变量过程的综合异常诊断。 利用实际炼化厂数据进行测试,结果表明该方法具有一定的可靠性。
1 辨识模型和辨识方法
1.1 控制回路中动态数据的选取
笔者选取实际运行过程中某一控制回路输入输出数据进行辨识。 在相关分析辨识方法中,传统的开环多次阶跃的输入信号并不满足系统辨识对输入信号丰富且持久的激励要求[25],由于部分输入信号的前向时刻与当前时刻的值相等,导致自相关矩阵中很多列向量差别不大,这样的矩阵为病态矩阵,条件数很大[26],若输入的自相关矩阵奇异,则无法对矩阵进行求逆运算。
因此,笔者选取运行过程中具有动态特性的数据进行相关分析辨识,保证输入的自相关矩阵非奇异。
1.2 相关分析法辨识脉冲响应模型
笔者采用多变量相关分析辨识方法,利用输入自相关函数和输入输出互相关函数辨识出单通道的有限脉冲响应模型。
线性定常离散传递函数模型如下:

其中,y1×q和u1×p分别为多变量系统在闭环自动控制下的p维输出和q维输入,e1×q为输出噪声,离散传递函数G(z)的展开式为:

则取过渡时间为N=k,当i>N时,令gi=0,可得系统的有限脉冲响应模型如式:
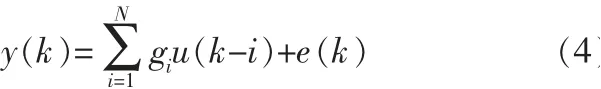
取多变量输入输出互相关函数Ryu和输入自相关函数Ruu为:
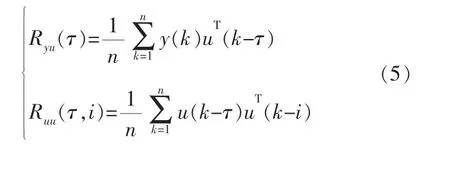

2 异常检测方法
2.1 k-means
2.1.1 k-means算法原理
k-means属于无监督学习算法, 其基本思想是:通过迭代寻找将数据分为若干个簇的一种划分方案,使得簇内的点尽量紧密,簇与簇之间的距离尽量大。
k-means算法以距离作为数据间相似性度量的标准,一般采用欧氏距离来计算数据对象间的距离,其公式为:
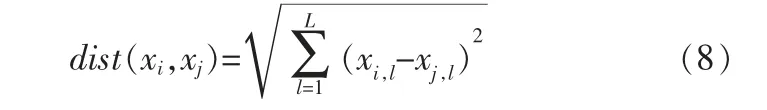
其中,L表示数据对象的个数。
k-means聚类算法执行过程中, 每次迭代,对应簇的质心都要进行更新。 定义第k个类的质心为Centerk,类簇的质心更新方式为:
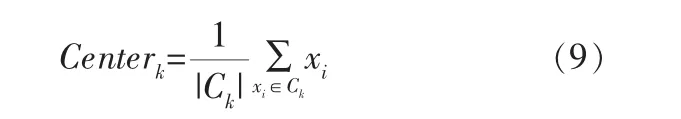
其中,Ck表示第k个类簇,|Ck|表示第k个类簇中数据对象的个数。
定义损失函数为各个样本距离所属簇中心点的误差平方和:
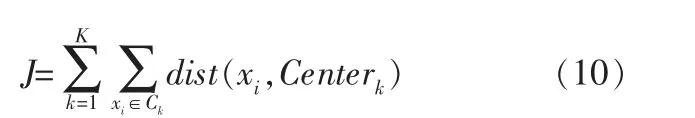
其中,K表示类簇的个数。 若前后两次迭代J的差值小于某一阈值,则终止迭代,得到聚类最终结果,即:
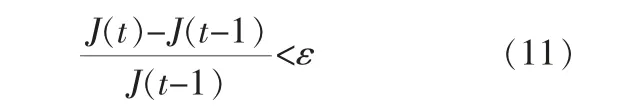
其中,t为迭代次数,ε为设定阈值。
2.1.2 k-means最优K值选取
当数据维度较少且每类数据较为分散时,可以人为对K值进行设定。 但炼化装置中数据量庞大,维度较高,通过人工设定K值并不现实,若人工设定不合适的聚类数,会导致最终聚类后的某一簇包含异常样本与正常样本数量相当,聚类效果较差。 选取最优K值的具体步骤如下:
a.确定K的取值集合和最大迭代次数tmax。
b. 对每一个K的取值,都进行迭代,更新类簇的质心位置,终止迭代的损失函数记为Jmink。
c. 将所有K值下的损失函数在同一坐标系下进行比较。
d. 观察图像, 损失函数值出现明显拐点时,所对应的K值即最优聚类数。
2.1.3 k-means算法具体实施步骤
k-means算法具体实施步骤如下:
a.通过上述方法确定最优聚类数K。b.选择K个对象作为初始聚类中心。
c.计算每个聚类对象到聚类中心的距离。
d.更新聚类中心。 直至聚类中心不发生改变或达到最大迭代次数,算法终止。
e.将每类中所包含的数据保存并打好标签。
2.2 SVDD
SVDD基本思想是构造超边界形成一个超球体,使其尽可能多地包含训练样本中的正样本,实现正样本与负样本最大程度的分离[27,28]。 SVDD核心问题是寻求最优边界以达到最优检测效果[7,29]。
假设有一组正常训练数据x∈Rn×d, 其中n是样本个数,d是特征维度。 首先通过非线性变换函数Φ:x→F将函数从原始空间映射到特征空间,在特征空间寻找一个体积最小的超球体。 具体公式如下[30,31]:

其中,R是超球体半径;a是超球体圆心;ξi≥0为松弛变量;C为常数, 其作用在于控制半径a的最小化和松弛变量的权衡。
结合拉格朗日乘子法,式(12)可以转化为式(13)的对偶问题:
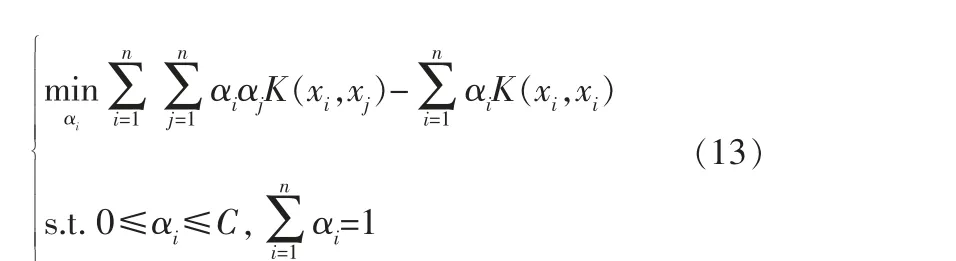
其中,αi是xi对应的拉格朗日系数。
当超球体边界无法保证准确分类时,可采用核函数的方法对SVDD进行优化, 将训练数据映射至更高维的空间进行超球体的计算。 常用的核函数包括线性核函数、多项式核函数、Gaussian核函数和Sigmoid核函数,核函数的确定需根据具体的需求[7,32]。 笔者根据需求选取如下Gaussian核函数:

在所有正常训练样本中,把拉格朗日系数满足0<αi<C的样本称为支持向量,训练数据集中属于支持向量的集合为SV,可由下式计算超球体球心和半径[31]:

若o≤kR(k≥1),说明测试样本在超球体球面上或者内部,属于正常样本;反之,属于异常样本。
在实际训练过程中,应在正类样本训练集中加入少量负类样本来防止过拟合现象。 假设训练样本中正样本和负样本标签分别为:

测试样本xt到超球体球心的距离为:
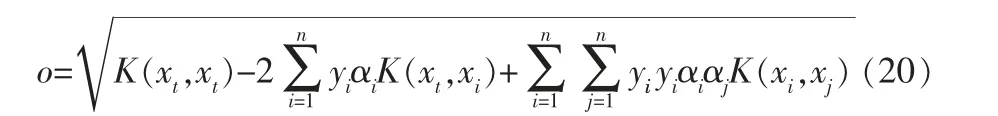
3 异常诊断总体流程
异常诊断主要分为两个阶段:训练阶段和在线测试阶段,具体流程如图1所示。

图1 异常检测总体流程
训练阶段的主要步骤为:在控制回路中存在大量操纵变量与被控变量历史数据的情况下,经相关分析法辨识得出有限脉冲响应模型参数,总体构成一个数据矩阵, 并在最优聚类数下进行kmeans聚类。 此时,分以下3种情况训练SVDD超球体: 将含有大量数据样本的类作为正常工况,并训练正常工况SVDD超球体; 将含有一部分数据样本的类作为异常工况一、异常工况二等多种异常工况,并训练每类异常工况的SVDD超球体;将只含有少量数据样本的类,或类中数据量占总数据量百分比不超过设定值的类舍弃,作为明显故障的数据样本。
在线测试阶段主要步骤:将在线辨识得到的有限脉冲响应模型参数与已训练的多个超球体所设阈值进行比较,若其在正常工况超球体阈值范围之内,则为正常工况;若其在训练的多个异常工况超球体所设阈值范围之内,则说明发生异常工况, 并诊断出具体产生哪一类异常工况;若其在所有已训练好的超球体阈值范围之外,则说明此时检测仪表或执行机构发生显著异常现象,并有发展为故障的趋势。
4 实际数据实验研究与验证
本课题的数据为国内某炼化厂分馏总貌一段温度控制回路中检测仪表与执行机构的实际过程数据,将其在Matlab平台上进行仿真测试。首先, 获取炼化厂中一段单输入-单输出控制回路的过程动态历史数据,每60 s采样一次,根据历史趋势选择数据段,使得动态矩阵非奇异。 然后,建立训练样本数据集,将历史数据按照时间序列进行划分, 取每500 min的采样数据作为一组数据,通过相关分析法辨识其有限脉冲响应模型。 通过现有的有限的实际过程控制回路的历史数据,共辨识出9组有限脉冲响应模型参数。 有限脉冲响应模型阶次为10。 最后,总体构成了一个9×10的矩阵。
将9组有限脉冲响应模型参数进行聚类分析。 首先,确定最优聚类数目为2,即将此数据集聚为两类。 经聚类后,其中一类含有7组数据,另一类含有2组数据。 由于在实际化工运行过程中,正常数据要多于异常数据。 所以,选取密度大的一类作为正常样本数据集训练SVDD超球体。
训练SVDD超球体,核函数采用Gaussian核函数,C值和ξ值分别为0.3和0.03。
获取此控制回路近一段时间内的过程动态数据,共辨识出5组有限脉冲响应模型,有限脉冲响应模型参数构成一个5×10的矩阵,将其作为测试样本集。 利用经过训练的SVDD模型进行异常检测,最终的测试结果如图2所示。
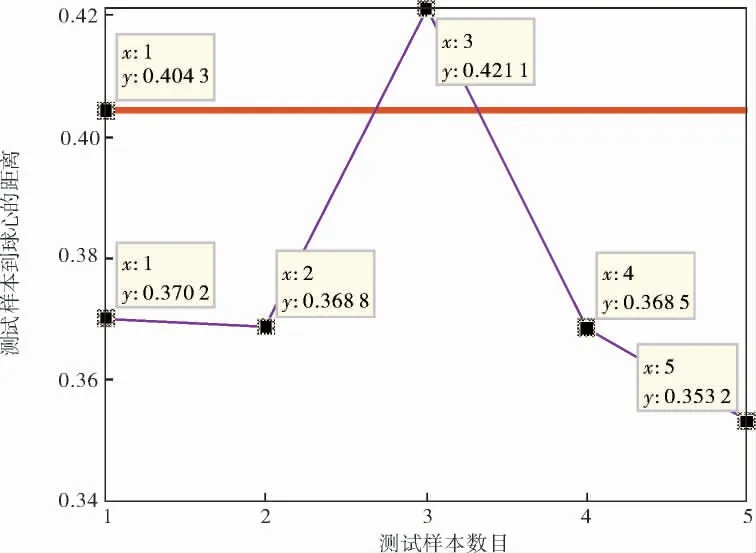
图2 单输入-单输出异常检测结果
对检测结果进行分析:测试样本数目为5,经训练后SVDD超球体阈值为0.404 3。 样本1、2、4、5距超球体球心的距离都小于阈值, 即正常样本。样本3距离超球体球心的距离为0.421 1, 大于阈值,即异常样本。 然后,在此控制回路没有受到噪声干扰以及工况发生迁移的情况下,判断控制回路中检测仪表或执行机构出现异常。 最后,对异常划分等级,根据实际现场工业过程对控制回路的要求而定。
5 结束语
在当今工业背景下,不再只期望工业过程平稳运行,而对控制效果、产品质量提出了更高的要求。 所以,对控制回路的异常诊断更具有实际意义。 笔者提出使用相关分析法进行模型参数辨识、k-means与SVDD算法进行异常检测的方法,可实现对执行机构与检测仪表的异常检测。 将笔者所提方法用于实际的工业过程中,测试结果验证了所提方法的有效性。
猜你喜欢
上海大中型电机(2021年1期)2021-06-09
数学大王·低年级(2021年4期)2021-04-27
消费电子(2020年5期)2020-12-28
铁道通信信号(2019年6期)2019-10-08
池州学院学报(2017年5期)2018-01-23
雷达学报(2017年6期)2017-03-26
华北理工大学学报(社会科学版)(2015年3期)2016-01-11
电大理工(2015年3期)2015-12-03
电子设计工程(2015年6期)2015-02-27
