
基于XGBoost 的网络舆情文章预警模型建立
2023-06-21 01:58方茜
智能计算机与应用 2023年6期
方 茜
(贵州师范学院数学与大数据学院, 贵阳 550018)
0 引 言
随着互联网的快速发展,越来越多的网络应用成为广大民众畅所欲言的平台。 绝大部分的网民主要从手机新闻app、微博、论坛、微信公众号等平台获得资讯,而这些平台在提供资讯的同时也提供用户对文章进行评论、转发、点赞等互动功能。 网络的开放性及自由性使得人们通过网络表达对文章报道事件的看法及心声,而这些看法及心声反映着民众的态度,同时也反映着社会舆情。 然而当负面的舆情占比较大时,舆情危机产生,从而对社会造成重大影响,扰乱社会秩序,导致相关部门的管理失衡。
网络舆情预警是在预警对象传播的整个生命周期采取不间断的监测工作。 通过实时采集预警对象的数据并对其分析,当达到监测阈值时,应使用预警模型及时反应预警对象的预警等级。 预警使得一些可能产生舆情危机或已成为危机的信息能够被及时发现,由相关部门做出相应的引导决策,及时控制不良信息及不好舆论泛滥成灾。
1 相关工作
目前,国内的研究中提出了多种类型的舆情指标体系。 其中,曾润喜等人[1]通过文献调研,将网络舆情监测与预警指标体系分为4 类:
(1)基于社会预警启示的指标,从警源、警兆和警情3 个一级指标来构建指标体系,该方法的主观性较强;
(2)基于主题分类的指标体系[2],从舆情事件产生背景及指向性设计指标体系,然而该方法缺少指标量化研究;
(3)基于舆情不同发生主体的指标体系,从特定领域的角度设计指标体系(如高校)[3]等;
(4)基于网络舆情内在机理的指标体系[4],使用舆情发展周期中出现的因素建立指标体系。 国内已有舆情预警研究中,有的将网民的情感极性[5]作为其中一个预警指标,也有直接通过分析文本的情感极性[6]对舆情进行预警。
研究中发现,基于指标体系的预警研究大部分还处于理论研究阶段,实际应用价值不高,并存在以下问题:
(1)指标体系建立依赖专家经验知识,主观因素较强,缺乏数据驱动的客观实证性研究。
(2)一些定性指标的量化依赖专家打分,导致舆情预警综合研判滞后,难以实现对预警对象的及时预警。
(3)已有的基于指标体系的预警研究还处于理论期,实用性较差。 因此,本文提出一套基于文章预警的特征,通过相关性分析和特征筛选的方法,对预定义文章的预警特征进行筛选,并使用XGBoost 方法建立文章预警模型。
2 网络舆情文章预警指标体系的建立
2.1 预选指标特征
本文以新闻文章为预警对象,通过分析造成文章预警因素,并结合以往舆情预警研究的指标体系综合分析,从文章特征、受众特征两方面考虑,列出对文章预警具有影响的特征作为预选指标。
2.1.1 文章特征
文章特征从文章内容出发,通常描述某一事件内容,不同类型事件其影响程度不同。 文章特征主要有以下几点:
(1)文章主题重要性(topic_importance)
文章主题重要性用于衡量这篇文章报道事件内容的重要程度。 不同的主题所造成的影响程度不同,通过提取文章的关键主题词,关键主题词出现频率越高,对文章的主题表现就越重要。 因此,统计该关键主题词频占文章中总词的频率作为文章重要性判断。
(2)文章情绪(mood_emotion)
文章情绪表示文本内容特征信息所表达出的情绪,文章本身的情绪对阅读文章的网民情绪具有一定的影响。 文章情绪可以使用Lei J[7]提出的方法,计算出文章的情绪标签,并取概率值最大的情绪作为文章的情绪,该值为离散值。
2.1.2 受众特征
受众特征表示除文章本身信息外的其它信息,其来源于网民在阅读完文章后对文章的一系列行为动作产生的数据。 主要包括以下特征:
(1)参与人数P(participants_num)
参与人数用于表示阅读该文章的网民中参与评论总人数C及对评论点赞的人数Z之和,也即是评论区参与总人数:P=C+Z。 文章的参与人数反映网民对这件事的关注程度,可以通过爬虫直接从新闻页面获取得到。
(2)评论总数C(comments_num)
评论总数表示对这篇文章进行评论的总人数,可以通过爬虫直接从新闻页面获取。 评论越多,表示网民对这件事的反响越强烈,同时也会使该文章成为热点文章,从而受到更多人的关注。
(3)评论情感倾向CE(comment_emotion)
文章评论反映网民对文章报道事件的态度倾向,情感倾向的正负极表示网民对这件事是支持还是反对。 通过现有的情感分析技术判断评论情感得分,用F_score表示每条评论情感分值,文章所有评论的情感倾向值:使用均值来表示。 当负面评论较多时,CE <0,表示为-1,CE≥0 时,表示为1。
(4)评论变化拐度
评论变化率是指单位时间内评论数的变化,评论变化率Cfre=(C t2- Ct1)/Δt,Δt=t2- t1。 其中,Ct1表示单位时间t1 的评论数,Ct2表示在单位时间t2 的评论数。 通过一段时间内评论数的变化,能够了解到在这段时间内网民对这篇文章的关注趋势变化。 若评论数在某一时段内持续上升时,应引起相关部门关注,预防舆情危机产生。 评论变化拐度用于描述评论数在前一时间段转变到后一时间段趋势变化的情况,分别用前一时间段评论数变化率和后一时间段评论数变化率进行比较得出。 通过分析,拐度的7 种情况见表1。

表1 评论变化拐度情况列表Tab. 1 Comments on the change of the inflection situation list
从G1 ~G7 穷举所有可能的拐度情况,G1 ~G3表示相对于前一段时间,下一时间段往评论变大的方向拐;当两时间段内容评论变化率相等时,G4 表示持平状态,下一时间段评论往持平方向; G5 ~G6表示相对于前一段时间,下一时间段评论往变小方向拐。 通过分别统计一定时间段内出现评论变大、变小、持平的占比,来表示评论变化拐度情况。 在表1 列举的11 种评论拐度图形中,任意一种图形出现一次则计数为1,所有评论拐度图形出现的次数之和为拐度总次数,用Gtotal表示。
变大的占比(g_up)为
持平的占比(g_bal)为
变小的占比(g_down)为
(5)文章每种情绪投票占比
网民阅读完文章后,可以通过投票方式表达对此文章的情绪态度。 总投票数和每类情绪的投票数可以通过爬虫代码从网页直接获取。 使用每种情绪的投票占比来表示网民对这篇文章的实际情绪,其由每类情绪的投票数除以总投票数得到。 情绪共有6 种:分别为愤怒(angry)、震惊(shocked)、搞笑(funny)、新奇(novel)、感动(moved)、难过(sad)各投票数。
综上,本文预选取的所有预警指标特征见表2。

表2 文章预选指标特征列表Tab. 2 Feature list of article pre-selected indicators
用于文章预警的特征包含连续特征和离散特征,表2 中离散特征名称中标注∗,其余为连续特征。 由于这些特征的量纲不同,其度量范围和数量差别较大。 因此,为便于综合评价,减少数量级差异,本文使用min-max 方法对特征进行归一化处理,使其值在[0,1]之间。
2.2 指标特征分析
通过分析文章的相关信息,预选15 个特征用于文章预警研究,本节使用皮尔逊相关性判断特征与预警相关性,通过相关性分析可以得到本文预选的预警特征指标是否与预警相关。
由表3 可知,本文预选的特征指标除主题重要性f1、读者愤怒情绪投票f10、难过情绪投票f15 相关性最低且不显著以外,其它特征都表现较强的显著性。 主题重要性f1 相关性最低且不显著,其原因可能是因为该方法的量化是通过主题词在全文中出现的概率来反应主题重要性,不同文章通过该方法计算得到的概率值相差不大,导致每篇文章的主题重要性区分度不高。 由于该特征与预警相关性小于0.1,可筛除该指标。 因此,通过上述特征分析,本文预选的特征基本与预警显著相关。

表3 文章预选特征指标与预警的相关性Tab. 3 The correlation between pre-selected feature indicators and early warning
3 基于XGBoost 的预警模型建立
本文目标旨在舆情监测过程中收集到一篇文章相关数据后,能够对其判断是否要对文章舆情预警,以及确定预警级别。 参考《国家突发公共事件总体应急预案》[8],其按突发公共事件产生的危害程度、可控性和影响程度、发展态势、紧急程度等因素,本文将文章预警等级分为5 个等级,分别为特别严重(1 级)、严重(2 级)、较重(3 级)、一般(4 级)、不预警(0 级)。 同时舆情监测预警系统中需要对监测的预警对象的预警级别及时准确反馈,以达到预警目的。 因此,在模型的选择上需要使用一个速度快、准确率高的模型。
由chen 等人[9]提出的 XGBoost ( Extreme Gradient Boosting),因其速度快、准确率高等优点而受到广泛应用。 XGBoost 方法是GBDT(Gradient Boosting Decision Tree)梯度提升树的改进版本,其与GBDT 不同在于基学习器除决策树外还支持线性学习器,并加入正则项使得偏差与方差均衡。 传统的GBDT 在优化过程中只用到一阶泰勒展开,而XGBoost 用到泰勒一阶展开和二阶展开。
梯度提升树是由Boosting 方法结合Gradient 梯度得到的。 Boosting 是集成学习中的一种,其核心思想是通过迭代过程中前一轮的误差率动态更新训练集权重,每一轮都是一个弱学习器,由多个弱学习器集成强学习器实现回归和分类。 而GBDT 方法的每一轮迭代目标是找一棵决策树模型的弱学习器使得本轮的损失函数最小。 GBDT 模型是由k个基学习器组成加法运算,可表示为
其中,F表示所有基学习器组成的函数空间。对于n个样本,其损失函数为
损失函数表示模型的偏差,最小化损失函数就是最小化模型的偏差。 为了使模型的偏差和方差达到较好的平衡,加入正则项来抑制模型的复杂度,因此模型的目标函数表示为
式中Ω表示基学习器的复杂度,即模型的结构风险。
由于本文以决策树模型作为基学习器,因此可以使用树的深度、叶节点的个数等反应模型的复杂度。 GBDT 前向分布算法的思想是从前往后建立基学习器,以此来逐渐优化,逼近目标函数Obj的过程。 该过程以一个常数项开始,每次添加一个新的函数,其过程如下:
上述过程中(0)~(t) 表示从第0 轮到第t轮,每一轮添加一个基学习器,主要在于GBDT 的目标函数,即每个基学习器的加入都是以优化目标函数为目的。 公式(7) 表示第t轮的预测值计算,ft(xi) 为要加入的基学习器,则此时的目标函数为
使用泰勒公式展开公式(8)中的目标函数。 令gi为目标函数中的一阶偏导,令hi为二阶偏导,是t前一轮的训练结果,yi是其对应的真实值,可作为常数处理,则由公式(8)转化为
当对目标函数公式(8)只求一阶偏导时,模型为GBDT,求一阶、二阶偏导时,模型为XGBoost,即公式(9)为XGBoost 的目标函数,损失函数不同对应着不同的gi和hi。 在XGBoost 中复杂度Ω(ft) 的公式为
其中,λ为学习率;T表示叶子节点个数;wj为叶子节点的权重。Ω(ft) 作为结构风险,将叶子节点的个数加入惩罚项,以限制模型的复杂度,并使用L2 正则避免过拟合。
模型构建如图1 所示,模型的输入为上节中通过特征分析后得到的文章预警特征指标,输出为文章预警级别。 通过文章数据集提取文章数据,并量化各项文章预警特征,输入到XGBoost 模型中,训练得到基于XGBoost 的网络舆情文章预警模型。 该模型的内部是由多棵CART 树构成,一篇文章的预警等级由其所在的多棵树中的叶子节点权重共同确定,除第一棵树以外,每一棵树都是训练上一棵树的损失值,使得整个样本的损失尽可能减少,得到最优的分类结果。

图1 基于XGBoost 的文章预警建模过程Fig. 1 The modeling process of article early warning based on XGBoost
4 实验
4.1 实验数据
实验数据是使用爬虫代码,爬取新浪社会新闻网站情绪排行榜上的新闻数据而得,其中包括新闻标题、新闻内容、每篇文章对应的情绪投票结果及每篇新闻的评论数据。 这些情绪分别为感动、震惊、搞笑、难过、新奇、愤怒6 类情绪。 选择6 名网络舆情研究的学者,分别对收集到的3 310 篇文章标记预警等级,通过Fleiss Kappa 一致性检验后,得到Kappa=0.758(Kappa 系数划分为大于0.75 为优秀,0.40~0.75 为正常至良好,低于0.40 为差),因此使用标记预警等级后的数据集作为实验的真实值。 每类预警级别(从1 级到4 级预警严重程度逐级递减,0 级表示不预警)的样本数见表4。

表4 每类预警级别样本数Tab. 4 Number of samples for each warning level
4.2 实验结果与分析
实验一预警特征筛选结果及分析
通过XGBoost 模型训练得到的指标特征重要性得分如图2 所示。 横轴表示特征重要性得分值(F_score),纵轴对应表2 中的每个特征指标。

图2 指标特征重要性Fig. 2 The importance of features
可以看出,文章的参与人数(participants_num)具有最高的重要性得分,说明一篇文章的参与人数越多,越有可能需要预警。 其次是网民对文章报道事件的震惊情绪(shocked),说明当看完文章的网民产生震惊情绪时越有可能需要预警。 特征重要性得分排名前三的特征是衡量预警等级的最重要特征。而文章情绪特征重要性得分较低,说明其对预警等级的重要性较小。 其中,文章情绪为难过(mood_sad)时最低,说明文章情绪表现为难过时,对预警等级的分类影响较弱。
实验二基于XGBoost 的文章预警模型效果及分析
表5 展示了采用3 种方法建立网络舆情文章预警模型的性能指标对比结果。 其中SVM 方法对预警等级的划分效果最差,而基于决策树的预警模型比基于SVM 的预警模型效果要好。 性能最好的是基于XGBoost 建立的预警模型,其能够达到77%的平均准确率,且其F1-measure 的值能够达到56.2%。说明本文提出使用XGBoost 建立的预警模型能够很好的实现对网络舆情文章进行预警等级的分类。
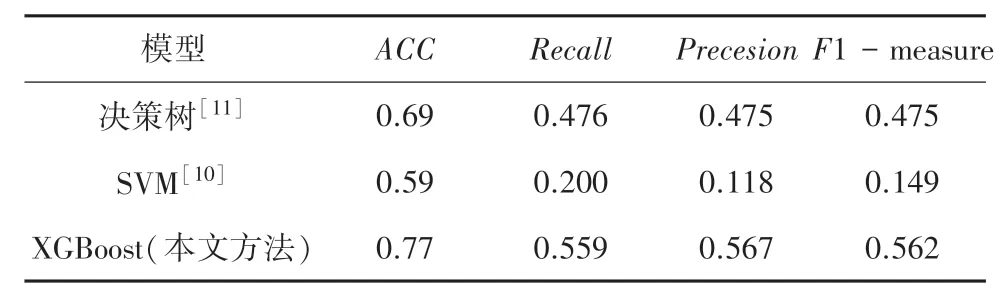
表5 三种模型性能对比Tab. 5 Performance comparison of three models
为了查看每个预警等级被分类准确的性能效果,本文选择准确率较高的基于决策树和基于XGBoost 建立的预警模型的ROC曲线进行对比展示,如图3、图4 所示。 图中不同颜色代表不同的预警等级(0 级~4 级)的ROC曲线,深蓝色的表示整体平均的ROC曲线。 area 对应每个预警等级ROC曲线下的面积,即AUC值,该值越高,表示预警模型越能判别出该预警等级。

图3 基于决策树的预警模型ROC 曲线Fig. 3 ROC curve of early warning model based on decision tree
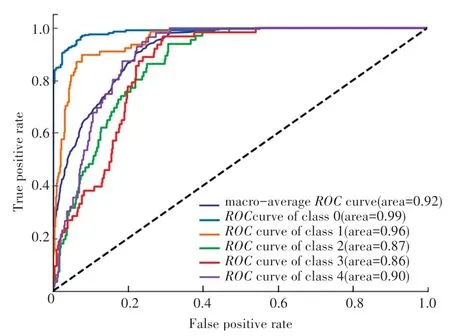
图4 基于XGBoost 的预警模型ROC 曲线Fig. 4 ROC curve of early warning model based on XGBoost
从图3 和图4 中可知,基于XGBoost 的预警模型在每个预警等级的判定命中率上均高于基于决策树的预警模型。 其中,宏平均AUC相差8%,除等级0(无警)的AUC相差3%以外,其他预警等级的AUC相差6%~10%之间,说明基于XGBoost 的模型更有助于预警等级的判定。
综上,本文提出以数据驱动的方式客观验证提出的特征指标的有效性,使用XGBoost 建立网络舆情文章预警模型对文章预警等级分类在宏平均评估指标ACC、F1、及AUC均取得了较好的效果,显著优于使用SVM 建立预警模型以及非集成的决策树模型,且对文章预警等级为非常严重的判断明显优于其他等级,有效防止高严重级别的等级被误判为低严重级别。
5 结束语
针对现有研究中舆情预警多集中在以主观经验设计的指标体系为核心的静态预警模型研究,指标体系的建立主观性太强,依赖于专家经验,缺乏基于数据驱动的实证研究。 本文通过分析引起文章舆情危机的因素,为新闻文章的预警等级的综合判定设计一套全面可量化的预警特征集,以真实数据验证所提指标体系对舆情文章预警的重要性,建立了全面可量化的文章舆情预警指标,使得预警指标体系更具客观性。 不仅解决了现有指标体系预警方法的主观性,并提出使用集成方法XGBoost 建立文章预警模型,实现对文章预警级别的判定。 通过对比实验的结果表明,本文提出的方法明显优于现有的基于决策树的预警模型和基于SVM 的预警模型,能够有效实现对新闻文章预警等级的判断。
猜你喜欢
今日农业(2019年12期)2019-08-13
现代园艺(2017年22期)2018-01-19
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
领导决策信息(2017年11期)2017-05-17
中国民政(2016年16期)2016-09-19
中国民政(2016年10期)2016-06-05
中国民政(2016年24期)2016-02-11
火控雷达技术(2016年3期)2016-02-06
小说月刊(2014年11期)2014-04-18
传媒国际评论(2014年1期)2014-02-27
