
结合注意力机制GoogLeNet 的羊只个体识别
2023-06-21 01:58李章辉王天一李远征
智能计算机与应用 2023年6期
李章辉, 王天一, 李远征
(贵州大学大数据与信息工程学院, 贵阳 550025)
0 引 言
随着智能化养殖[1]的快速发展,智能化养殖场建设和畜牧养殖精准化逐渐成为高效管理的理念。高效的养殖场管理需要精准化到个体的身份信息,因此收集和识别个体信息变得尤为重要。 在智能化养殖过程中,为每只羊建立个体档案有利于对养殖场精准化饲养和实时监控每只羊的身体健康信息提供了前提条件。 传统的养殖场对动物的个体识别主要靠人工识别,但在大型养殖场,仅靠人工无法做到有效的个体识别。 由于智能化养殖具有效率高、识别准确以及人力成本低等优势,因此智能化养殖正在逐步取代传统化养殖。
智能化养殖减少了人工在大规模养殖中管理不当等问题,涉及到个体识别[2]、目标检测[3]等领域。在动物个体识别领域,韩丁等[4]提出了将空间变换网络引入VGGNet 网络,对羊面部表情数据集的实验。 宋一凡等[5]对比和总结了以牛只面部、躯干和口鼻3 个部位特征的非接触式机器视觉[6]识别方法的研究成果。 马娜等[7]设计了卷积层-池化层-卷积层-池化层2 层卷积神经网络[8]模型,对猪个体身份进行识别。 拉毛杰等[9]使用卷积神经网络改进了畜牧业动物图像的识别准确率。 在动物目标检测领域,魏斌等[10]基于深度学习模型的羊脸检测效果较为理想,而羊脸识别工作在正面羊脸上取得了较高的准确率。 张宏鸣等[11]提出通过添加长短距离语义增强模块进行多尺度融合,结合Mudeep 重识别模型实现了肉牛多目标跟踪。 张宏鸣等[12]提出了一种基于YOLOv3 模型和卷积神经网络的多目标肉牛进食行为识别方法,为养殖场中对动物行为非接触式检测提供了新的途径。 何东健[13]提出基于最大连通区域的目标循环搜索环境建模、目标检测算法,提高了识别犊牛动作的正确率(如:躺、站、走、跳等)。
本文在GoogLeNet 网络中引入注意力机制模块组成SE-GoogLeNet,将有用信号进行筛选放大,对dropout 参数进行调整。 在训练过程中,调整学习率大小以及对优化器参数进行优化,提高了对复杂背景下羊的识别准确率。 实验表明,改进后的SEGoogLeNet 相比改进前的模型,验证集精度提高了2.2%,并利用采集羊图像对训练好的模型进行了评价。
1 SE-GoogLeNet
1.1 GoogLeNet
在一些典型的深度学习网络中,大都存在着网络训练收敛慢、训练时间长、容易出现梯度消失和梯度爆炸等现象。 为避免上述问题发生,在GoogLeNet网络中提出了Inception 模块,网络深度有22 层,结构如图1 所示。 GoogLeNet 网络采取全局均值池化策略,代替全连接层以减少参数,并增加了两个辅助分类器帮助训练,将Inception(4a)和Inception(4d)模块的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中,不仅达到了模型融合的效果,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,有益于网络的训练。
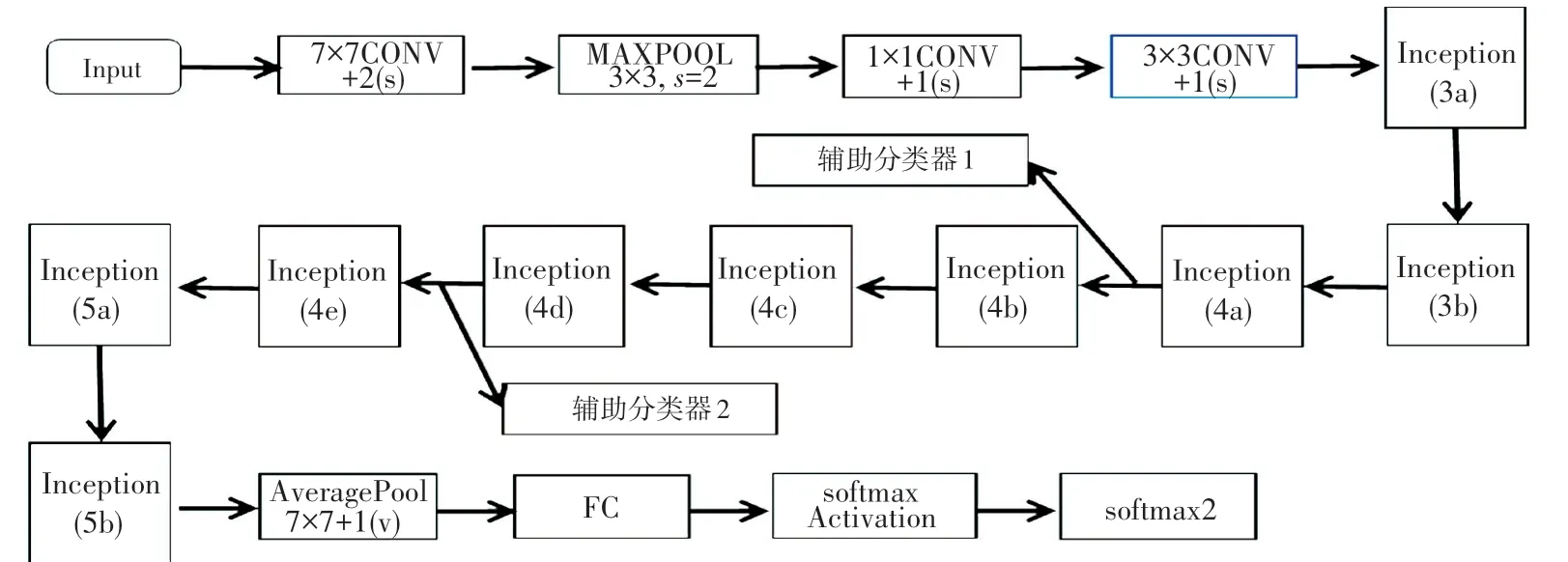
图1 GoogleNet 网络模型图Fig. 1 GoogleNet network model architecture
Inception 模块中存在滤波器,且滤波器的输出合并构成下一层的输入。 具体来说,Inception 模块利用1×1 卷积核降维,再利用3×3、5×5 卷积核进行卷积操作,将输入的特征矩阵分别与这4 个分支运算并得到4 个输出,输出在深度上拼接得到最终的输出(使用Padding 填充让4 个分支输出能在宽度和高度上保持一致)。 使用不同大小卷积核融合了不同尺度的特征信息,增加了网络的宽度以及网络对尺度的适应性,使得卷积网络在特征提取过程中得到了不同大小的感受野,使网络在训练过程中对不同大小个体有了更强的识别能力。 如图2 所示,Inception 模块结构增加了网络的宽度,可以达到更好的识别效果。 将网络由深变宽,避免了网络过深出现梯度消失和模型退化的问题。

图2 Inception 模块Fig. 2 Inception module
相比于传统的Inception 模块,GoogLeNet 网络提出的Inception 模块在分支2、3、4 中添加了1×1的卷积层,这3 个1×1 的卷积核是为了对通道方向上进行降维,减少参数量。 如图3 所示,以Inception(3a)模块中1×1 卷积后连接5×5 卷积分支为例计算参数量,使用1×1 卷积操作的模型参数仅为未使用1×1 卷积模型参数的12.9%。
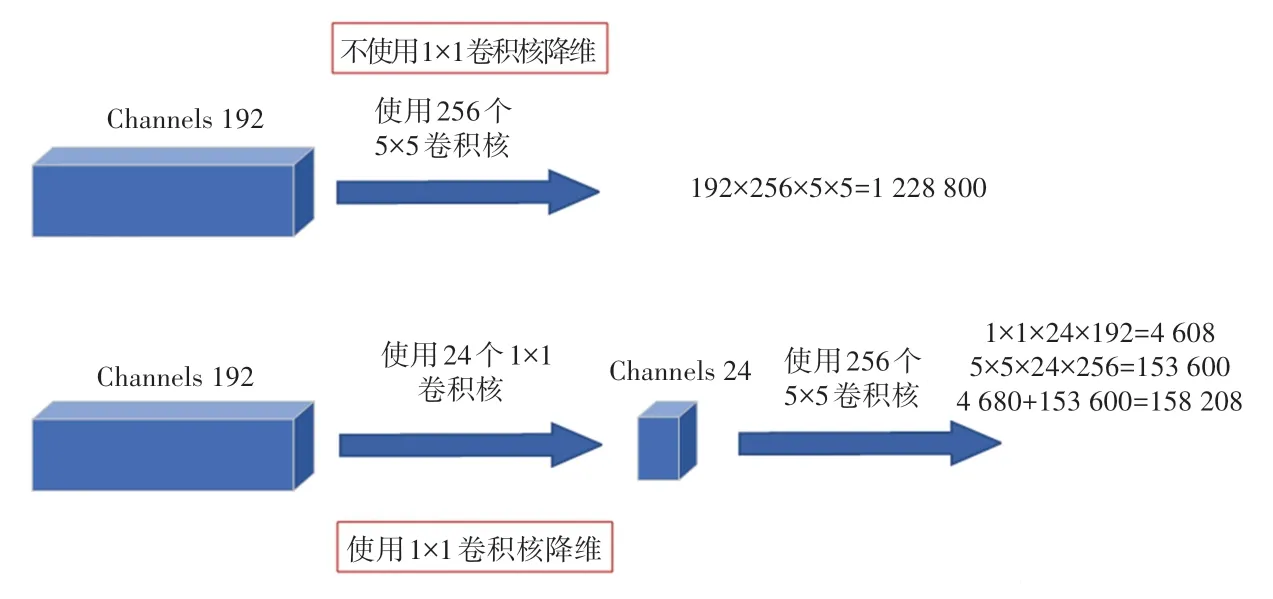
图3 Inception 模块参数量对比Fig. 3 Inception module parameter comparison
1.2 改进SE-GoogLeNet
虽然GoogLeNet 网络层数比较深,有较强的特征提取能力,但本文研究的是在养殖场环境下的羊个体识别,在识别过程中会遭受到不同程度噪声的干扰,这些噪声的干扰也会随着网络的训练进行传递,对识别个体精度造成不利的影响。
本文提出的改进GoogLeNet 网络结构如图4 所示。 该网络在主分类器末的平均池化层后引入了注意力机制模块,以改变每个通道的权重,将有用的特征进行放大,去除池化后学习到冗余特征信息。 为了防止过拟合现象的发生,将主网络中随机失活(dropout)层随机失活神经元由40%增大至70%。

图4 SE-GoogLeNet 网络结构图Fig. 4 SE-GoogLeNet network structure diagram
注意力机制结构如图5 所示,该机制是对输入进来的特征层进行压缩操作,每一层进行平均池化操作得到本层的参数。 池化操作是在水平和垂直两个维度进行,针对于C个通道得到C个平均池化后的输出,接着进行两次全连接层,对输出结果进行一个Sigmoid 激活函数处理,将输出的值固定在0 ~1之间,得到每一个通道的权值,将此权值乘以输入进来的每个特征层,得到最终输出。 压缩操作函数公式如式(1)所示:
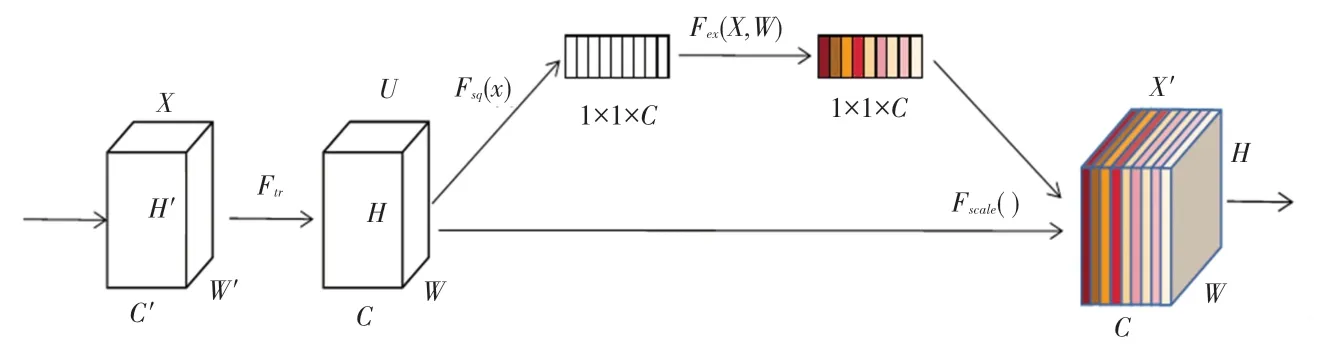
图5 注意力机制结构图Fig. 5 Structure diagram of attention mechanism
其中,Zc表示输出特征层;Fsq表示压缩操作函数;H、W表示特征图的宽和高;i、j表示特征图上的坐标位置。
由于本文采集到的数据集较少,易发生过拟合现象,因此对主分类器中的随机失活(dropout)层随机失活从40%增大至70%。 在网络训练过程中,从中随机丢弃一些隐藏单元,相当于在一个大的模型中随机抽取出一个小的模型。 由于随机失活的过程是动态的,每次训练过程中随机失活的神经元都有可能是不相同的。 也就是说只训练当前子模型使用过的参数,而对于未使用过的参数不进行更新。 这些抽取出来的子模型共享参数,最终相当于训练了很多的子模型。 在进行预测时,综合所有子模型的预测结果,很好的解决了过拟合的问题。 具体公式如式(2)所示:
其中,Bernoulli(p) 是指伯努利分布。 以一个概率为p的伯努利分布,随机生成与节点数相同的0、1 值,p就是每个神经元被保留下的概率。
在经过伯努利分布计算后得出概率p后,对输入的神经元重新计算进行随机失活。 式3 中,是第l层的输入;是第l层的输出;是第l层的权重矩阵;f是激活函数。
针对多分类问题,主分类器和副分类器的交叉熵损失函数表达式如式(4)所示:
其中,M表示类别的数量;yic表示符号函数(0或1),若样本i的真实类别等于c取1,否则取0;Pic表示观测样本,i属于类别c的预测概率。
SE-GoogLeNet 网络采用一个主分类器和两个辅助分类器进行输出,用定义好的损失函数分别求得3 个预测分类器的预测与真实标签之间的损失,将主分类器的损失值与两个副分类器损失值的0.3倍相加得到总损失值。 总损失值计算如式(5)所示:
其中,Loss表示总损失;Loss0 表示主分类器损失;Loss1、Loss2 表示副分类器损失。
2 实验结果与分析
2.1 实验数据
本文中数据均来自贵州省某羊养殖场的拍摄视频,分别对40 只羊进行了视频拍摄(分辨率为1 920×1 080)。 经过Adobe Premiere Pro 软件进行视频抽帧,对视频中羊的全身、头部等突出的个体特征进行图像筛选,并将不同成长期的羊只混合在一起,共计抽取600 张样本图像。 部分图像示例如图6 所示。

图6 羊部分图片数据集Fig. 6 Examples of sheep data set
由于在网络训练中需要大量的数据来达到更好的训练效果、提高网络检测的精度,但由于采集到的图片数量有限,将对抽取的600 张图片进行数据增强,增加数据数量,防止在网络训练中出现过拟合的现象。 本文采用的数据增强主要是对图片进行多个角度的旋转、对比度的调整、亮度的调整、随机平移等方式对源图片进行数据扩充,数据扩充为原始图片的7 倍数量,共计4 200 张羊的图像。
本文在训练过程中将数据按照8 ∶2 的比例划分为训练集和验证集。 考虑到每张照片尺寸大小的原因,使用transforms 工具包将所有的样本图像进行随机裁剪,设置大小为224×224 像素,并将其进行均值和方差都为0.5 的标准化处理,以便高效的对网络进行训练。 处理后训练集和验证集的数据量见表1。

表1 数据集统计Tab. 1 Statistics of dataset
2.2 实验环境
本次实验是在Python3.9、Pytorch1.11 的环境下进行,采用RTX2070 加速训练,GPU 显存为8 GB,CPU:AMD Ryzen 5 3600,CPU 基频为3.49 GHZ。
2.3 超参数设置
在深度学习网络训练中,超参数选择的好坏不仅和模型自身有关,还和软硬件的配置相关。 本实验在进行超参数调整之后,利用改进的SE -GoogLeNet 模型进行训练时,采用批量训练方式对训练集进行随机打乱,验证集保持不变,Batch_size的大小设置为16,训练周期为60。 采用Adam 优化器训练,eps值设为1e-5,初始学习率为0.000 08。
2.4 结果分析
为了了解不同优化算法[14]对SE-GoogLeNet 网络模型性能的影响,本文选择Adam、SGD、RMSprop 3 种算法在相同的实验环境下进行训练,结果见表2。 由表2 中数据可见,Adam 的训练时长最短,且精度最高,相比RMSprop 算法、SGD 算法高出了1.4%、29.9%。 因此,本文采用Adam 优化算法进行训练。

表2 不同优化算法下的模型精度Tab. 2 Model accuracy under different optimization algorithms
在采集的羊图像数据集上进行训练,保证了每个模型在相同实验环境下完成训练。 在训练过程中,每个训练周期后都会对模型的精确度进行验证并保存数据。 引入注意力机制后,模型的识别准确率得到了较大的提升,但是模型的大小增长非常小,进一步显示出模型性能的优越性。 改进后的网络与3 种经典分类网络在羊只数据集上的准确率和模型占用内存容量对比见表3。

表3 模型准确率和模型占用内存容量对比Tab. 3 Comparison of model accuracy and model memory capacity
本文将数据集在GoogLeNet、改进后SE -GoogLeNet 上的验证集准确率的曲线展示如图7 所示。

图7 改进前与改进后GoogLeNet 网络在羊图像上的验证集精确度与损失值曲线对比图Fig. 7 Comparison of validation set accuracy and loss value curves of GoogLeNet network on sheep images before and after improvement
由图7 可见不同模型之间的曲线趋势,SEGoogLeNet 代表本文改进后的模型曲线。 模型学习羊只身体特征,不断提高对个体的分类能力。 本文构建的基于注意力机制的SE-GoogLeNet 模型准确率更高,分类效果更好(如图7(a))。 其主要原因是:一方面在于Inception 模块将不同大小个体学习到的特征信息进行多尺度融合(Multiscale fusion),Inception 模块有不同尺寸大小的卷积核进行提取特征,并将这些特征在深度上进行融合,进一步提高了模型的特征提取能力;另一方面在于加入注意力机制将有用信息的权重增强,削弱了噪声的干扰,因而提高了模型最终的分类能力。
Loss损失函数在模型训练中是一个重要参数,可以通过其下降趋势反映训练效果的好坏。 在训练网络过程中,不断地将数据传入到网络中进行迭代,经过正向传播后得出一个预测值,将预测值与实际标签做出对比得到一个损失值,将得到的损失值进行反向传播来修正权重的误差,使得损失函数不断地减小,依次循环,训练精度将会不断的得到提高。由不同模型在训练时的损失函数对比(图7(b))可以看出,Loss值在第55 个周期时已经收敛,达到了模型精度最高且泛化性能最好点的值。
利用SE-GoogLeNet 网络模型训练得到的权重对随机选取的3 只羊图像进行预测,预测结果均达到了100%准确率,说明改进后的SE-GoogLeNet能较好的对羊只个体识别,羊只预测结果如图8 所示。

图8 羊只预测结果Fig. 8 Prediction result of sheep
3 结束语
本文针对目前大规模羊场养殖中存在的羊个体识别的效率低、人工依赖性较大等问题,提出了基于结合注意力机制的GoogLeNet 网络改进的SEGoogLeNet 模型,在网络中引入注意力机制模块用来减少噪声影响,提高了模型的精度;同时,在相同实验环境下研究了不同优化算法对模型性能的影响。 实验结果表明,改进后的SE-GoogLeNet 模型在对40 只羊的验证集准确率达到了94.5%,相对于原GoogLeNet 模型精确率上升了2.2%,改进后的SEGoogLeNet 模型相比于其它主流算法具有较高的准确率,在智能化养殖中将会有很好的前景。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
电子制作(2019年11期)2019-07-04
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
