
基于社交关系和时序信息的团购推荐方法
2023-07-03 14:11孙男男朴春慧马新娜
计算机应用 2023年6期
孙男男,朴春慧,马新娜
(1.石家庄铁道大学 信息科学与技术学院,石家庄 050043;2.北京全路通信信号研究设计院集团有限公司,北京 100070;3.河北省电磁环境效应与信息处理重点实验室(石家庄铁道大学),石家庄 050043)
0 引言
近年来,随着团购模式的发展与移动终端数量的激增,传统的商品推荐机制在团购推荐问题上逐渐显出弊端。团购一般指消费者通过聚集消费需求实现降价目标的一种动态制定商品价格的电子商务模式[1]。团购平台的用户可以分为单个用户和群组用户。
从用户的角度,目前的团购推荐方法中,综合研究单个用户和群组用户的方法较少。其中,向单个用户推荐的研究有很多,群组推荐也是推荐系统领域关注的一个热点。从团购平台的角度,存在很多单个用户独自成团的现象,而且很多群组也存在临时性的特点。所以综合考虑对两种用户进行个性化推荐,具有研究意义和实用价值。从商家的角度,最终的目的是平台的用户多参与到团购活动中,进而提高商家的销售额,所以分别设计两种具有针对性的个性化推荐算法具有很好的应用场景。
在对单个用户进行推荐时,虽然目前基于循环神经网络(Recurrent Neural Network,RNN)中门控循环单元(Gated Recurrent Unit,GRU)的推荐算法[2-3]可以建模更为复杂的序列关系,但没有考虑用户行为之间的时间间隔信息,对推荐结果的多样性有很大的影响;之前的研究多是按照交互次数排序的方法计算商品对用户的重要性,仅考虑交互次数,不同商品可能对于同一用户的重要性相同;用户-商品交互数据中存在噪声,导致推荐精度降低。
尽管目前团购推荐是推荐系统领域关注的一个热点,具有研究意义和实用价值,但是对群组进行推荐时仍面临如下挑战:1)目前群组偏好融合策略大多是预定义、启发式的方式,不足以体现复杂、动态的群组决策过程;2)忽略了群组与项目交互的时间信息,人们通常认为群组用户更倾向于花更多的时间在其感兴趣的项目上,并且这些感兴趣的项目普遍与当前的目标项密切相关;3)用户易受到朋友的影响,在面对不同的项目时通常会对不同的朋友产生依赖。
因此,针对上述问题,在对单个用户进行推荐时,本文同时考虑了个性化时间间隔和自注意力网络,提出了融合时序感知GRU 和自注意力的团购推荐模型(group buying Recommendation model integrating Time-series aware GRU and Self-Attention,RTSA)。在对群组用户进行推荐时,本文利用门控循环单元、社交网络和分层自注意力网络,提出了融合社交网络和分层自注意力的团购推荐模型(Group buying Recommendation model integrating Social network and hierarchical Self-Attention,SSAGR)。
1 相关研究
1.1 序列推荐
传统的序列推荐模型包括序列模式挖掘[4]和马尔可夫链(Markov Chain,MC)模型[5-6]。基于序列模式挖掘的方法虽然简单直观,但通常会产生大量冗余模式;其次,序列模式挖掘利用用户的历史交互数据中出现较为频繁的特征,进行学习并推荐,导致推荐的商品相似性较高,容易使用户感到疲倦。基于MC 的模型假设用户下一次的交互行为只受最近几次交互的影响,一般只能捕获短期依赖。如个性化马尔可夫链分解(Factorizing Personalized Markov Chains,FPMC)[6]将一阶MC 与矩阵分解方法相结合,对用户的兴趣偏好和动态转换进行了建模,只考虑了当前项与前一项之间的关系,不能在复杂的场景下利用其他辅助信息挖掘更多的隐式关系。
1.2 群组推荐
随着团购模式的发展,群组推荐任务逐渐成为研究热点。这些群组用户或具有相似的兴趣偏好,或具有相同的需求,同质性较高。如果只是将群组用户的偏好进行简单的融合来产生最终的推荐结果,会导致部分群组用户的兴趣偏好被忽略。因此团购推荐系统既需要考虑群组的一般偏好,还需要综合、动态地考虑群组中用户的个人偏好,即团购推荐任务的核心问题是融合策略的选择。
常用的融合策略包括平均策略[7]、最少痛苦策略[8]、最大满意度策略[9]、专家知识策略[10]等。与这些基于内存的方法不同,基于模型的方法建模用户间的交互信息,具有更好的推荐效果 。如 AGR(Attention-based Group Recommendation)[11]通过考虑群组内成员间的影响学习用户的权重,但是它只利用了项目的ID 信息。AGREE(Attentive Group REcommEndation)[12]采用了注意力网络得到群组的嵌入表示,但此模型仅从用户的角度考虑群组的表示方法。
1.3 深度学习推荐
随着深度学习的快速发展,基于RNN 的方法[13-14]在推荐领域获得了成功。如Hidasi 等[13]首次提出了GRU4Rec(GRU-based RNN approach for session-based Recommendations)模型,利用了RNN 学习用户点击序列之间的顺序关系。Chen 等[14]针对基于RNN 的模型中项目之间关联性不强的问题,提出了基于用户记忆网络的序列推荐模型。虽然这些基于RNN 的序列推荐模型可以建模更为复杂的序列关系,但仍存在两方面的问题[15-16]:一是没有考虑用户行为之间的时间间隔信息,它对实现推荐结果的多样性有很大的影响;二是用户的历史交互序列中,存在一些无意义的行为,这些不相关的数据会产生噪声,影响推荐结果的准确性。
近几年来,自注意力机制已被应用于各种任务中,并取得了巨大的成效。本质上,这种机制的输出部分依赖于输入中特定的内容,通过计算各部分输入信息的权重使设计的模型更具备解释性。目前自注意力机制已被广泛应用于推荐系统[15,17-20],用于强调用户的交互序列中真正相关和重要的商品信息,从而处理序列中的噪声问题。Sun 等[15]提出了双向基于Transformer 的推荐模型,从用户-商品交互序列左右两个方向提取用户的交互信息,对目标用户进行下一个商品的推荐。Kang 等[17]提出了自注意力序列推荐模型,既能够捕捉较长的用户-商品历史交互序列信息,也能够针对相对较少的用户交互行为序列进行预测。Li 等[18]提出了一个明确的对交互时间进行建模的序列推荐模型,探索了时间因素对下一个商品预测的影响。Zhang 等[20]分别对属性间的特征关系建模,更深层次地挖掘用户潜在偏好,提出了特征级自注意力网络序列推荐模型。但是自注意力机制只是模型中的一个模块,本身不包括循环层或者卷积层,并不知道序列中商品的位置等信息;同时,在现有的基于自注意力机制的模型中,大部分都未添加辅助信息进行建模。
2 RTSA设计
RTSA 的结构如图1 所示。此模型主要包括3 个部分:1)利用时序感知GRU(Time-series aware GRU,TGRU)层学习用户偏好复杂的动态时序特征;2)通过融合个性化时间间隔的自注意力层TSA(Time-aware Self-Attention)捕捉时间间隔、商品位置与商品嵌入信息之间的关系模式;3)将自注意力层的输出表示输入全连接层,与所有商品的嵌入表示点积,预测下一个商品的输出。
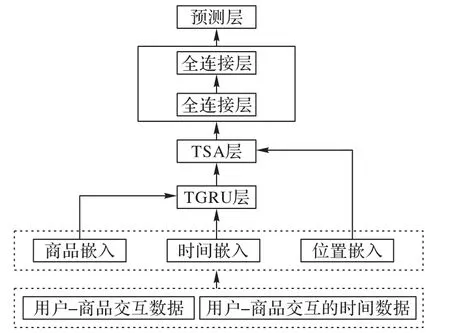
图1 RTSA的结构Fig.1 Structure of RTSA
2.1 公式化描述
2.2 时序感知GRU
在进行商品推荐时,融合时间上下文信息可以在一定程度上提高商品推荐的准确性和多样性。因此本文在GRU 模型的基础上加入时间门,提出了时序感知GRU 模型。在此模型中,时间门主要是控制当前交互商品的时间信息对下一个商品推荐的影响。通过输入用户-商品交互序列中商品的嵌入表示矩阵EI和个性化时间间隔矩阵Ru,使交互时间的远近被考虑在内。TGRU 如图2 所示。

图2 TGRU模型Fig.2 TGRU model
由图2 可知,TGRU 模型是在基础GRU 模型上添加了时间因素。故在基础GRU 模型(式(1)~(4))的基础上,添加了式(5),并对式(3)进行了修改如式(6):
其中:⊙是点积运算;σ是sigmoid 激活函数;更新门zt、重置门rt和时间门Tt控制每个隐层的信息更新;W**表示权重系数矩阵;b*是偏差参数;Δtt表示任意两个商品之间的个性化时间间隔;xt和ht-1分别表示当前时间t的输入向量和上一时间t-1 的输入向量;h~t中的rt⊙ht-1表示通过重置门rt控制上一时间的输入需保留的信息量;ht的前半部分通过更新门zt控制当前时间输入的信息量,后半部分通过1 -zt控制上一时间输入的信息量。
2.3 融合个性化时间间隔的自注意力网络
用户-商品交互序列中,不同的商品对下一次推荐的重要性不同;用户-商品交互数据中混杂着一些噪声,导致推荐精度降低[21],因此本文引入了自注意力机制,从众多信息中找到对下一次推荐贡献最大的关键信息,提出了融合个性化时间间隔信息、商品位置信息和商品序列信息的自注意力模型TSA。该模型结构如图3 所示。

图3 TSA模型Fig.3 TSA model
其中:n表示交互序列的长度;V表示值向量,是自注意力网络中的表述;WV是值的输入预测;v是V值向量的其中一个元素;WV∈Rd×d是可学习的权重参数,d表示用户的嵌入向量维度。权重系数αij使用softmax 函数计算,如式(9)所示:
其中βij通过一个考虑输入、关系和位置的函数计算。
其中:WQ∈Rd×d和WK∈Rd×d都是可学习的参数;用于维度过高时,避免内积值过大。上标Q、和K 分别表示查询和键。
2.4 全连接层和预测层
为了增强模型的性能,本文在自注意力层后应用了层归一化、正则化和以高斯误差函数(Gaussian Error Linear Unit,GELU)为激活函数的全连接层,最终得到融合商品信息、位置信息和个性化时间间隔信息的联合输出表示z=(z1,z2,…,zn),如式(11)~(13)所示。
其中:W*表示权重系数矩阵,b*是偏差参数。
在经过全连接层之后,将此联合表示zt输入预测层。利用其与所有商品的嵌入表示矩阵EI∈R||I×d进行点积,得到目标用户u对每个候选商品的偏好得分
3 SSAGR设计
SSAGR 的结构如图4 所示。此模型主要包括3 个部分:1)采用RNN 学习用户随时间变化的复杂潜在兴趣;2)利用用户社交网络和分层自注意力网络,设计群组偏好融合策略;3)通过神经协同过滤(Neural Collaborative Filtering,NCF)学习群组-项目交互函数,完成团购推荐。
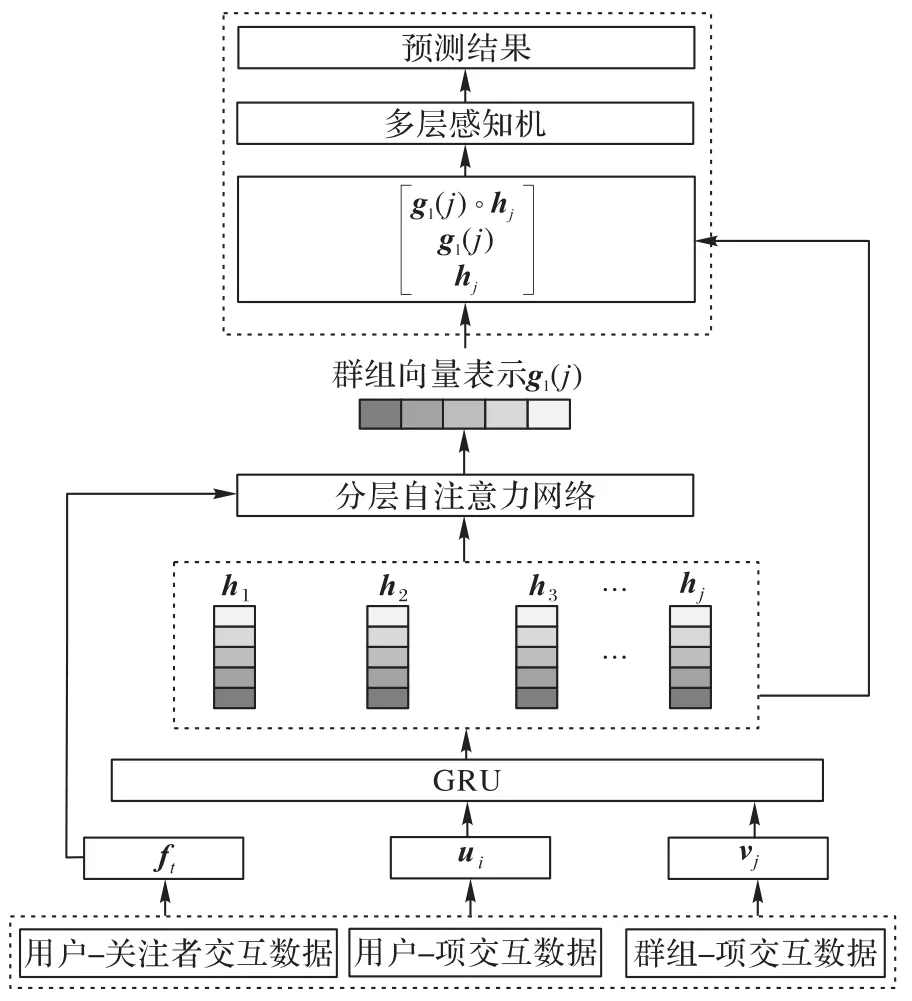
图4 SSAGR的模型结构Fig.4 Model structure of SSAGR
3.1 公式化描述
3.2 分层自注意力网络
分层自注意力网络的结构如图5 所示,展示了对用户、社交关注者嵌入聚合策略的设计,通过向量ui、hj和ft,得到最终的群组嵌入表示gl。首先,通过用户级自注意力网络,将用户的社交关注者信息纳入到用户表示中;然后,采用群组级自注意力网络,融合成员用户的向量表示,获得每个群组的嵌入表示向量。
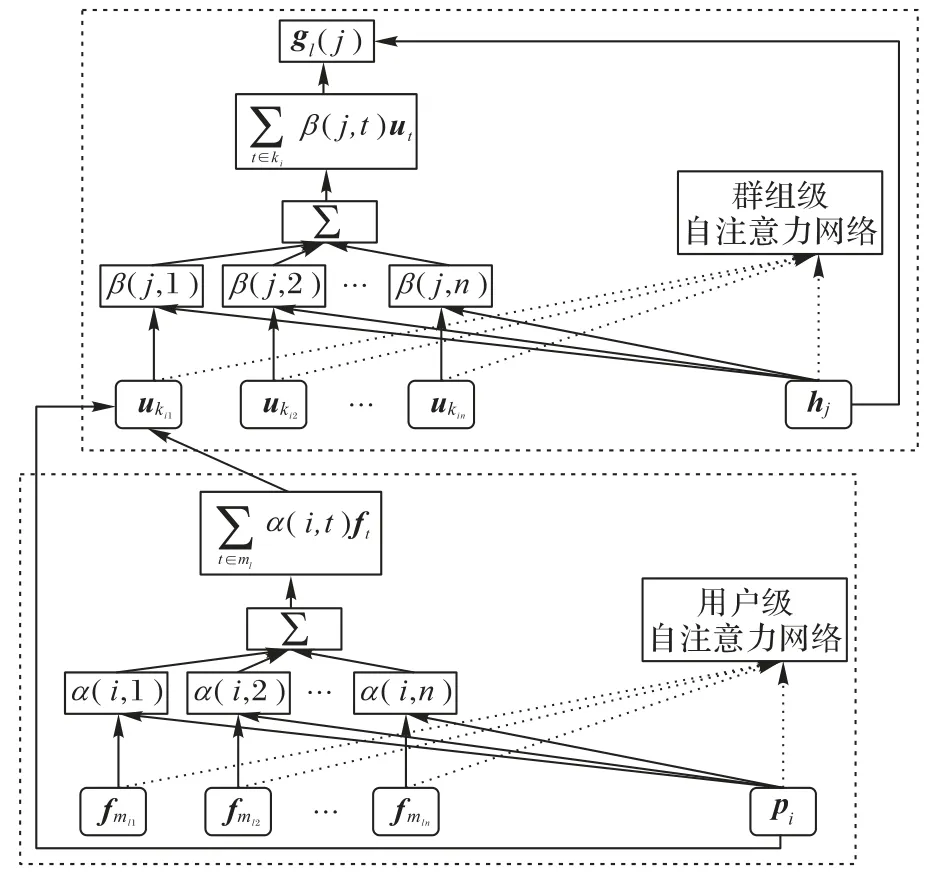
图5 分层自注意力网络的结构Fig.5 Structure of hierarchical self-attention network
3.2.1 用户级自注意力网络
在社交网络中,用户的兴趣不仅和自身偏好相关,还受到朋友的影响;并且朋友的影响也不是一成不变的,在与不同的团购项目交互时,朋友的影响是动态变化的。将用户的社交网络数据输入用户级自注意力网络中,结合用户的一般偏好,得到用户的向量表示。
具体地,根据图5 中用户级自注意力网络的结构,本文将用户嵌入表示分为其关注者嵌入融合表示和用户自身偏好嵌入表示pi两部分。
其中:α(i,t)是一个 可学习的参数,以ft和pi为输入,如式(16)所示。
其中:WT表示预测层的权值矩阵,Wf和Wp表示将关注者的嵌入向量ft和用户的一般偏好嵌入pi转换到隐含层的权值矩阵,b表示偏差向量,GELU 作为隐层的激活函数,softmax 函数进行归一化。
3.2.2 群组级自注意力网络
群组级的自注意机制,基于用户级的自注意力网络学习融合策略。此群组级自注意力网络的目标即通过成员用户的嵌入表示ui,得到整个群组的表示gl。
具体地,与用户级自注意力网络类似,群组嵌入分为用户嵌入融合和群组一般偏好嵌入qt两部分,如式(18)所示:
摘 要:近年来,随着“互联网+”时代的来临,新媒体在高等教育中得到广泛应用,不仅有效提高了课堂教学质量,强化了大学生的学习效果,还进一步推动了高等院校的教育革新,对实现我国现代教育目标具有重要影响。思想政治是大学教育体系中的重要组成部分,新媒体的兴起与发展既为大学生思想政治教育工作带来前所未有的发展机遇,同时也提出了严峻的挑战。现阶段,如何有效运用新媒体提高大学生思想政治科目的教学效果,增强学生的核心素养,已经成为当今社会广泛关注的首要课题,并受到人们的普遍重视。就新媒体环境下大学生思想政治教育展开探讨,希望对日后的相关研究有所帮助。
其中:β(j,t)是一个可学习的参数,以ut和hj为输入,如式(19)所示。
其中:W表示预测层的权值矩阵,Wu和Wh表示将用户偏好嵌入ut和项目属性嵌入hj转换到隐含层的权值矩阵,b表示偏差向量,GELU作为隐层的激活函数,softmax函数进行归一化。
3.3 多层神经网络框架
神经协同过滤(NCF)是一个项目推荐的多层神经网络框架[22]。它以分层自注意力网络输出的群组表示gl(j)和项目表示hj作为输入,从数据中学习群组-项目交互。针对给定的群组-项目交互对(gl,hj),得到每个实体部分的嵌入向量,然后将它输入多层感知机(Multi-Layer Perceptron,MLP),得到最终的群组预测得分。
其中:eh表示全连接层的第h层的输出神经元。
4 仿真实验与结果分析
4.1 RTSA实验分析
4.1.1 实验设计
1)实验数据。
采用MovieLens-1M 和Amazon Beauty 数据集[18]评估本文模型。参照文献[23]中的步骤进行预处理。将评级视作用户的隐形反馈,即用户与项目进行了交互。对于所有用户,用其交互序列中的时间戳减去某个用户的时间序列中最小的时间戳,并升序排序。此外,过滤了交互少于5 次的用户和商品。数据集的统计特征如表1 所示。

表1 MovieLens-1M和Amazon Beauty数据集的统计特征Tab.1 Statistical characteristics of MovieLens-1M and Amazon Beauty datasets
在对两个数据集预处理后,采用了leave-one-out 方法[22]将其分别划分为训练集、验证集和测试集。即使用与用户进行最后一次交互的项目进行测试,倒数第二个交互项目用于验证,其余的项目作为训练集。
本文采用准确率(Precision,Pre)、召回率(Recall)、命中率(Hit Rate,HR)和归一化折损累计增益(Normalized Discounted Cumulative Gain,NDCG)[24]作为评价指标。受推荐列表长度的限制,一般取前10 个商品作为推荐结果展示[25],评价指 标分别 为Pre@10、Recall@10、HR@10 和NDCG@10。
其中:L(u)是用户u的推荐列表,C(u)是用户u在测试集中真正感兴趣的商品;| |GT是所有用户测试集合的商品总数,Number_of_Hits@k表示的是每个用户top-k列表中属于测试集合的个数总和;Zk是归一化参数,ri表示排序为i的推荐结果的相关性,k表示推荐列表的大小。
3)对比模型。
为了验证RTSA 的有效性,将其与以下4 种模型对比:1)个性化马尔可夫链分解(FPMC)模型[6];2)基于会话的RNN 推荐(GRU4Rec)模型[13];3)基于时间间隔感知自注意力的序列化推荐(Time interval aware Self-Attention for Sequential Recommendation,TiSASRec)模型[18];4)卷积序列嵌入推 荐模型(Convolutional sequence embedding recommendation model,Caser)[26]。
4)参数设置。
本文基 于 PyTorch 1.6.0 框架实 现 RTSA。在MovieLens-1M 和Amazon Beauty 数据集中,设置参数值如下:batch size 为128,正则化比例为0.2,学习率η为0.001,使用Adam 优化器。其中,在MovieLen-1M 数据集中,最大交互序列长度为50,最大时间间隔为2 048;在Amazon Beauty 数据集中,最大交互序列长度为25,最大时间间隔为512。
4.1.2 序列推荐模型性能对比
在MovieLens-1M 和Amazon Beauty 数据集上,对比RTSA与4 种代表性的序列推荐模型,结果如表2 所示。

表2 2个数据集上5种推荐模型的对比结果Tab.2 Comparison results of five recommendation models on two datasets
1)在MovieLens-1M 数据集中,基于神经网络的推荐模型(GRU4Rec、Caser)比基于马尔可夫链的模型(FPMC)在Pre@10、Recall@10、HR@10 和NDCG@10 指标上均表现较好;在Amazon Beauty 数据集上,相较于GRU4Rec 和Caser,FPMC 在Recall@10 和NDCG@10 指标上性能更好。由此可见,各模型在不同稀疏度的数据集上有不同的推荐效果。
2)在两个数据集中,基于时间间隔自注意力的推荐模型(TiSASRec)在4 个评价指标上比基于神经网络的推荐模型(GRU4Rec、Caser)性能更好,表明基于自注意力机制的推荐模型能够自适应地为不同的商品分配不同的权重,比基于神经网络的推荐模型能更好地捕捉商品之间的依赖关系。同时,在一定程度上说明了时间间隔信息作为辅助信息对于提高模型推荐性能的积极作用。
在两个数据集中,RTSA 在4 个指标上均优于其他对比模型。在MovieLens-1M 数据集中,相较于对比模型中最优的基线模型TiSASRec,RTSA 在Pre@10、Recall@10、HR@10 和NDCG@10 指标上 分别提高了2.91%、2.61%、5.52% 和5.78%。在Amazon Beauty 数据集中,相较于最优的基线模型,RTSA 在Pre@10、Recall@10、HR@10 和NDCG@10 指标上分别提高了10.34%、5.97%、11.73%和7.69%。
4.1.3 潜在维度d对模型的影响
在RTSA 中,潜在特征维度d是一个重要的参数。当d越大,向量表示越复杂,向量有更好的特征表达能力。图6展示了MovieLens-1M 数据集中各个模型在{10,20,30,40,50}不同维度下的HR@10 和NDCG@10 值。

图6 MovieLens-1M数据集上HR@10和NDCG@10随着维度d的变化Fig.6 HR@10 and NDCG@10 changing with different dimension d on MovieLens-1M dataset
从图6 可以看出,RTSA 在两个评价指标上都超过了其他的基线模型;随着特征维度的增加,RTSA 的HR@10 和NDCG@10 值也逐渐增加。
4.1.4 最大交互序列长度n对模型的影响
图7 是在保持其他参数最优情况的前提下,在MovieLens-1M 数据集中,RTSA 在{10,20,30,40,50}不同交互序列长度下的NDCG@10 值。结果显示了RTSA 当考虑较长的序列时,NDCG@10 值逐渐有所提高。由此可知当用户的交互序列是长序列时,模型能够更好地捕捉商品和时间间隔之间的关系模式,从而提升模型的推荐性能。

图7 在Movielens-1M数据集上n对RTSA模型的影响Fig.7 Influence of n on RTSA model on MovieLens-1M dataset
4.1.5 个性化时间间隔思想的有效性
为了证明本文个性化时间间隔思想的有效性,本文进行了有无融合个性化时间间隔的对比实验。当考虑个性化时间间隔因素时,即RTSA;当不考虑个性化时间间隔时,即不输入个性化时间间隔矩阵。实验结果如表3所示。
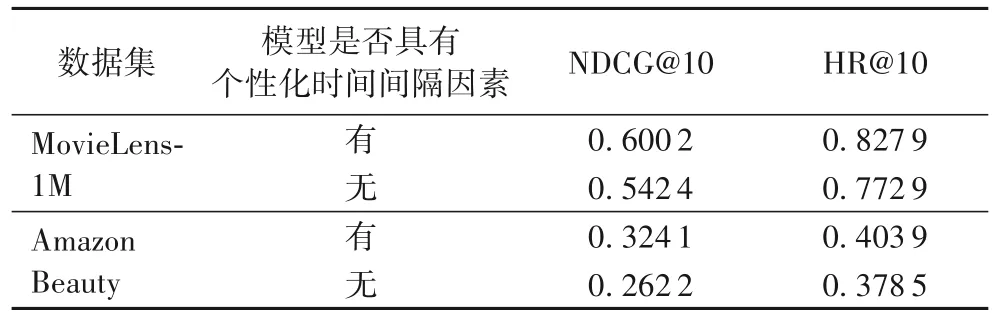
表3 时间间隔因素对模型的影响Tab.3 Influence of time interval factor on different models
由表3 可以看出,在两个数据集上,具有个性化时间间隔因素的模型比不考虑个性化时间间隔思想的模型具有更好的推荐效果。这可能是因为融合个性化时间间隔的模型能准确、全面地刻画用户偏好的变化趋势。把时间间隔信息作为辅助信息输入模型中,能够挖掘商品和时间间隔信息之间的隐式关联,进一步从时间间隔的角度预测用户在未来的兴趣偏好。
4.1.6 TGRU对模型的影响
为了验证TGRU 层在RTSA 中的有效性,进行了有无TGRU 层的消融实验。当有TGRU 层时,即RTSA;当无TGRU层时,即个性化时间间隔嵌入表示直接输入TSA 层。在MovieLens-1M 数据集上以HR@10 和NDCG@10 为例,实验结果如图8 所示。
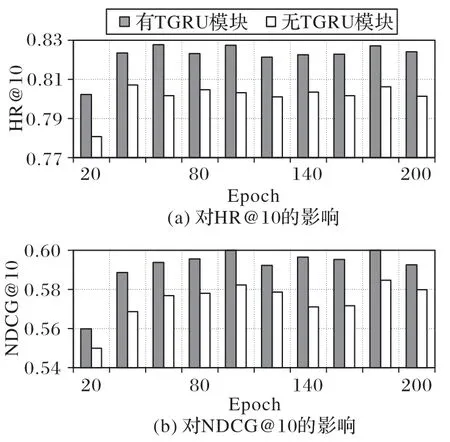
图8 TGRU层对模型的影响Fig.8 Influence of TGRU layer on different models
4.2 SSAGR实验分析
4.2.1 实验设计
1)实验数据。
本文采用MaFengWo 和Douban Book 数据集来评估提出的模型SSAGR。MaFengWo 是一个从旅游网站抓取的数据集,用户记录自己的旅行地点,创建或者加入群组。此数据集保留了至少包含2 个成员、去过3 个地点的群组信息,同时收集了每个群组的所有旅行地点以及每位群组成员的旅行地点。Douban Book,用户一起阅读书籍,项目对应于书籍。在预处理过程中,过滤了交互少于10 个的用户和书籍。数据集的详细信息如表4 所示。

表4 MaFengWo和Douban Book数据集的统计特征Tab.4 Statistical characteristics of MaFengWo and Douban Book datasets
以MaFengWo为例,它包括5 275个用户、995个群组、1 513 个项目、39 761 个用户-项目交互和3 595 个群组-项目交互。平均每个群组有7.19 个用户,每个用户去过7.54 个地点,每个群组去过3.61 个地点。用户-项目交互矩阵的稀疏度是99.50%,群组-项目交互矩阵的稀疏度为99.76%。另外,此数据集还包括社交关注信息,收集其中5 275 个用户的关注数据。最终此数据集还包括13 076 个关注人、53 235个用户-关注者交互。平均每个用户有10.09 个关注者,每个关注者被4.06 个用户关注。
2)评价指标。
本文最终的目标是将推荐列表采用top-k方式推荐,因此为了评价推荐模型的有效性,采用了leave-one-out 方法[22]。为了直观体现SSAGR 的改进效果,本文参照文献[24]采用了两个广泛使用的top-k评价指标,命中率(HR)和归一化折现累积增益(NDCG)。受推荐列表长度的限制,一般取前5 或10 个商品作为推荐结果展示[25],故本文评价指标分别为HR@5、NDCG@5、HR@10 和NDCG@10。
3)对比模型。
为了证明本文提出模型SSAGR 的有效性,将它与以下基线模型进行了对比实验。
AGREE[12]采用了注意力网络得到群组嵌入表示,通过NCF 框架建模群组-项目间的交互。与其他的群组推荐模型GroupIM(Group Information Maximization)[27]、DRGR(Deep Reinforcement learning based Group Recommender system)[28]等相比,AGREE 有着更优的性能。SIGR(Social Influence-based Group Recommender)[29]根据用户-项目图和群组-项目图的嵌入模型,利用注意力机制学习不同组中用户的影响。
为了验证本文融合策略的有效性,对比了几种预定义融合策略。NCF[22]将群组当作用户进行推荐。NCF+avg[7]采用平均融合策略,群组偏好分数为个体偏好得分的均值。NCF+lm[8]采用最小痛苦策略,群组偏好分数为成员的最低分数。NCF+ms[9]采用最大满意度策略,群组偏好分数为成员的最高分数。NCF+exp[10]采用专家策略,本文考虑的专家知识为用户在训练集中交互的项目数量[29]。
SSAGR-G 为SSAGR 的变体,它仅考虑群组级自注意力网络,不考虑社交网络的影响,即不输入用户-社交关注者交互数据。SSAGR-F 为SSAGR 的另一个变体,它仅考虑用户级自注意力网络,对于群组用户的融合表示过程采用统一的权重。
4)参数设置。
为了优化SSAGR 的参数,本文对两个数据集进行了网格搜索[30],参数的搜索范围为:在[128,256,512,1 024]和[0.001,0.005,0.01,0.05,0.1]中分别选择批量大小和学习率。同时本文参照文献[22]将负采样比设置为4;对于嵌入层,采用了Glorot 初始化策略;对于隐藏层,所有参数均使用均值为0、标准差为0.1 的高斯分布进行初始化;在分层自注意力网络和NCF 中,将第一个隐藏层的尺寸与嵌入层的尺寸设置为32。
4.2.2 群组推荐模型性能对比
在MaFengWo 和Douban Book 数据集上,本文将SSAGR与其他基线模型进行了对比,结果如表5 所示。

表5 各推荐模型在两个数据集上的性能对比Tab.5 Performance comparison of recommendation models on two datasets
从表5 中可见:1)在MaFengWo 和Douban Book 数据集上,SSAGR 相较于其他群组推荐模型,在两个评价指标上具有更好的推荐效果,验证了本文模型的有效性。在MaFengWo 数据集中,相较于最优的基线模型AGREE,SSAGR 在HR@5、NDCG@5、HR@10、NDCG@10 指标上分别提高了3.53%、2.63%、1.81%、2.17%。在Douban Book 数据集中,相较于最优的基线模型AGREE,SSAGR 在在HR@5、NDCG@5、HR@10、NDCG@10 指标上分别 提高了2.92%、2.52%、1.49%、2.04%。2)NCF+avg、NCF+lm、NCF+mp 和NCF+exp 这4 种模型中,没有明显更优的模型,说明了预定义的静态融合策略不能准确地对群组决策过程建模,也侧面说明了自注意力网络动态学习用户权重的必要性。3)上述各种推荐模型在两个评价指标上,当推荐个数为10 时均取得更好的推荐结果。
4.2.3 迭代次数c对模型的影响
在SSAGR 中,迭代次数c是一个重要的参数。以MaFengWo 数据集为例,图9 展示了SSAGR 和AGREE 在两个推荐指标上,随c变化的性能对比结果。

图9 MaFengWo数据集上迭代次数c对HR@10和NDCG@10的影响Fig.9 Influence of the number of iterations c on HR@10 and NDCG@10 on MaFengWo dataset
从图9 中可见:1)相较于AGREE,SSAGR 方法在HR@10和NDCG@10 两个评价指标上具有更好的效果,表明利用分层自注意力网络融入用户的社交网络数据,在一定程度上提高了推荐模型的有效性;2)与AGREE 的收敛速度相似,SSAGR 基本在迭代次数为20 时趋于稳定。与AGREE 相比,本文还使用另一个自注意力网络加权社交关注者的嵌入向量。在不影响收敛速度的情况下提高了模型的泛化性,为SSAGR的有效性提供了依据。
4.2.4 推荐序列长度k对模型的影响
在团购推荐模型中,推荐列表长度k也是一个重要的参数。以MaFengWo 数据集为例,图10 展示了SSAGR 和AGREE 在两个推荐指标上,随k变化的性能对比结果。

图10 推荐列表长度k对HR@k和NDCG@k的影响Fig.10 Influence of recommendation list length k on HR@k and NDCG@k
从图10 中可以看出,对于SSAGR 和AGREE 的top-k性能问题,当推荐个数k为10 时均取得更好的推荐结果,随着k值增加,HR 和NDCG 两个评价指标越来越高。因此,推荐列表长度的增加可在一定程度上提高推荐准确性。
4.2.5 模型组件的影响
为了验证SSAGR 在用户级和群组级考虑的全面性,本文提出了SSAGR-G 和SSAGR-F 两种变体模型,在MaFengWo数据集上进行了对比实验,结果如图11 所示。

图11 MaFengWo数据集上3种模型的性能对比Fig.11 Performance comparison of three models on MaFengWo dataset
从图11 中可见:1)相较于其他两种考虑较为单一的算法,SSAGR 利用了两个自注意力网络,同时考虑了群组与用户、用户与关注者之间的关系,具有更优的推荐效果。这说明社交关注者嵌入聚合和用户嵌入聚合都有利于群组决策,组合起来可以获得更好的性能。2)SSAGR-G 的性能优于SSAGR-F,说明在SSAGR 框架下,用户偏好嵌入学习的重要性大于社交关注者的嵌入融合学习。
4.2.6 分层自注意力网络的作用
SSAGR 除了具有更好的推荐性能外,还能解释群组成员的注意权重。为了深入了解分层自注意力网络的注意力权重学习过程,本文在一个两部分的方案中,对随机选择的测试群组和测试用户进行了案例分析。
为了验证群组级自注意力网络的作用,分析群组对正实例和负实例的预测得分,首先在数据集MaFengWo 中随机选择了1 个测试群组(G49),其中包括3 个成员用户(U837、U838 和U839),该群组一起参观了3 个正实例地点(I54、I284和I462),设目标值为1(正实例为1,负实例为0)。除了3 个正实例地点外,本文还随机选取了3 个负实例(I52、I346 和I591),其目标值设为0。表6 展示了SSAGR 和SSAGR-F 中群组用户的注意力权重和抽样群组对实例地点的预测得分R。

表6 抽样群组对群组级自注意力的影响Tab.6 Influence of sampled groups on group-level self-attention
由表6 可见:1)对于不同的地点,群组成员的注意权重有明显的差异。2)对于正实例,SSAGR 的预测得分远大于SSAGR-F,更接近目标值1;对于负实例,SSAGR 的预测得分小于SSAGR-F,更接近目标值0。由于SSAGR-F 为群组中的所有成员用户分配了相同的权重,因此模型的能力相对有限。这说明了将群组级自注意力网络融入SSAGR 的有效性和考虑用户关系的全面性。
为了深入了解用户级的注意权重学习,本文对一个随机选择的测试用户(U127)进行了案例分析,获得了此用户的社交关注者(F43、F328 和F739),并随机选择了3 个正实例(I31、I297 和I521)和3 个负实例(I81、I189 和I542)。表7 展示了SSAGR 和SSAGR-G 中各社交关注者的注意力权重和抽样用户对实例地点的预测得分R。

表7 抽样用户对用户级自注意力的影响Tab.7 Influence of sampled users on user-level self-attention
由表7 可见:1)对于不同的地点,各社交关注者的注意力权重具有明显的差异。例如,对于地点I297、I521 和I189,关注者F739 的注意力权重相较于其他用户较高,这可能是因为人们的旅游场馆和观察到的场馆相似。2)相较于模型SSAGR-G,SSAGR 的预测得分更接近目标值(正实例为1,负实例为0)。这说明了将用户级自注意力网络融入本文框架的有效性。
4.3 RTSA与SSAGR对比实验分析
4.3.1 实验设计
1)实验数据。
为了对比本文所提模型RTSA 和SSAGR 的性能,本文在Douban Book 数据集上进行对比实验与分析。在预处理过程中,过滤掉交互少于10 个的用户和书籍。
2)评价指标。
在评价指标的选择上,本文采用HR 和NDCG。同时受推荐列表长度的限制,一般取前10 个商品作为推荐结果展示[25],故本节实验的评价指标为HR@10 和NDCG@10。
3)对比模型。
在对比模型的选择上,由于本文在SSAGR 的NCF 框架中集成了用户-项目交互数据来提高群组推荐的性能,学习了同一嵌入空间中用户-项目交互与群组-项目交互,所以在同一框架NCF 中能够同时处理群组推荐和项目推荐[15]。本节对比了RTSA 与SSAGR 对单个用户进行项目推荐的性能,并分析了SSAGR 在群组推荐SSAGR(Group)和用户推荐SSAGR(User)两个方面的性能差异。
4.3.2 实验结果分析
在Douban Book 数据集上,本文将RTSA 与SSAGR 推荐模型进行了对比,结果如表8 所示。

表8 在Douban Book数据集上模型性能对比Tab.8 Models performance comparison on Douban Book dataset
从表8 中可见:1)在对单个用户进行项目推荐时,RTSA的性能优于SSAGR。这在一定程度上说明,在使用RNN 和自注意力网络对目标用户进行项目推荐时,个性化时间间隔因素的重要性大于用户社交关系因素。2)在使用SSAGR 对User 和Group 进行推荐时,SSAGR(User)的性能优于SSAGR(Group)。这在一定程度上说明,群体推荐需考虑群组内每个用户的兴趣偏好生成群体推荐模型,推荐结果可能是在牺牲部分用户特有偏好的基础上完成的;而个体推荐是基于用户自身的交互数据构建的偏好模型,与用户的需求一致,故准确率更高。由此说明,群体推荐的研究以个体推荐的研究为基础,但远复杂于个体推荐。
4.3.3 单个抽样用户对推荐结果的影响
为了深入了解提出的两个推荐模型,本文对随机选择的测试用户进行了实例分析。首先在Douban Book 数据集上随机选择了1 个测试用户(U851),并随机选择了包含此用户的3 个群组(G105、G175 和G209)。表9 以实例的形式展示了RTSA 与SSAGR 的top-5 推荐结果。

表9 Douban Book数据集上抽样用户与群组的top-5结果Tab.9 Top-5 results for sampled users and groups on Douban Book dataset
由表9 可见:1)RTSA 与SSAGR 对单个用户U851 进行推荐的top-5 推荐结果不同。因为RTSA 在进行单个推荐时,性能优于SSAGR。故RTSA 的top-5 推荐结果结合了用户U851的兴趣偏好(悬疑、影视),推荐的书籍类型是悬疑、影视。而由表8 可以看出SSAGR 模型进行单个用户推荐时较差,故推荐的top-5 在悬疑、影视外还包括言情类型(怦然心动)。2)在SSAGR 模型中,随机选取了包含用户U851 的3 个群组(G105、G175 和G209)。在3 个群组的top-5 推荐结果中,与对单个用户U851 进行推荐的结果并不完全相同。因为SSAGR 构建了分层自注意力网络,群组嵌入分为用户偏好嵌入融合和群组一般偏好嵌入两部分,用户嵌入表示分为关注者嵌入融合表示和用户自身偏好嵌入表示两部分。故在进行群组推荐时,SSAGR 的结果并非只是考虑用户U851 的兴趣偏好(悬疑、影视),还需结合群组内其他成员的偏好(如群组G209 的兴趣偏好还包括科幻),动态聚合后进行最终的群组推荐。3)在3 个群组中,由于G105、G175 和G209 成员个数分别为4、7、14,故在进行群组推荐时,成员用户较少的群组中,用户U851 在构建群组兴趣模型时起到的作用更大,与对单个用户推荐结果的相似度更高。
4.3.4 不同抽样用户对推荐结果的影响
为了分析用户参与群组的个数对推荐效果的影响,本文利用SSAGR 在Douban Book 数据集中进行了实验分析。以均值重复率作为指标展示了用户参与群组个数对推荐结果的影响。其中,均值重复率定义为此用户所在多个群组的top-5 推荐结果与此单个用户top-5 推荐结果中重复率的均值,如式(26)所示:
其中:R表示均值重复率;n表示测试用户参与群组个数;k表示推荐列表长度;mi表示用户所在群组top-k推荐列表中与个体推荐结果中重复的个数。
当用户分别参与5、10 和20 个群组时,其均值重复率的值依次为0.381 2、0.204 3 及0.231 9。由此可见:1)随着用户参与群组的个数越来越多,重复率基本呈现下降的趋势。这主要是因为用户在不同的群组内,他的兴趣偏好多样化,故在进行目标群组推荐时,在群组偏好模型构建过程中产生的影响力降低,从而影响最终的推荐结果,导致重复率下降。2)当用户参与群组个数为20 时,重复率稍高于用户参与群组个数为10 时的情况。这可能是由于推荐中歧义情况所在,虽然此用户参与的群组个数较多,但他与项目的交互数据也很多,故他在群组中的影响力相较于交互数据少的用户更高。所以推荐平台若对此类用户的兴趣模型进行深层次的分析,能够进一步挖掘此类用户的商业价值,对推荐平台分析用户的兴趣偏好在维持现有用户群体的基础上吸引新的用户,具有一定的意义。
5 结语
本文在团购场景下,研究了基于社交关系和时序信息的团购推荐方法。
对于团购中的单个用户,提出了融合TGRU 和自注意力的团购推荐模型RTSA。首先通过计算用户购买的任意两个商品之间的个性化时间间隔,构建了TGRU 模块;进一步地,考虑到用户-商品交互序列中不相关数据会产生噪声,采用自注意力网络,研究了商品位置及个性化时间间隔的影响。
对于团购中的群组用户,提出了融合社交网络和分层自注意力的团购推荐模型SSAGR。首先,采用RNN,获取了团购中用户随时间变化的潜在兴趣;然后,利用用户级自注意力网络,将用户的社交网络信息整合到用户表示中;进一步地,通过群组级自注意力网络,动态调整群组中用户的权重,得到了群组表示向量;最后,通过NCF 框架挖掘群组-项目交互,完成了团购群组推荐。
实验结果表明,RTSA 和SSAGR 在各评价指标上均有明显提高,验证了两个模型的有效性;在对单个用户进行项目推荐时,RTSA 性能优于SSAGR,且SSAGR 对单个用户进行推荐时性能优于对群组进行推荐,说明了群体推荐的研究是以个体推荐的研究为基础,但比个体推荐更复杂。
在之后的研究中,可以将社交关系分解为多个方面,如同事、家庭等,然后将每个方面的社交影响编码为分离的用户嵌入,以提高团购推荐的准确度。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
数学小灵通(1-2年级)(2020年11期)2020-12-28
小学生学习指导(低年级)(2019年3期)2019-04-22
电子测试(2018年14期)2018-09-26
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
山西大同大学学报(自然科学版)(2016年6期)2016-01-30
读写算·小学低年级(2014年4期)2014-07-24
计算机工程与设计(2011年7期)2011-09-07
小雪花·成长指南(2009年10期)2009-12-04
