
基于双流结构的跨模态行人重识别关系网络
2023-07-03 14:12郭玉彬李西明
计算机应用 2023年6期
郭玉彬,文 向,刘 攀,李西明*
(1.华南农业大学 数学与信息学院,广州 510642;2.广州市智慧农业重点实验室(华南农业大学),广州 510642)
0 引言
在行人重识别领域,Zajdel 等[1]首先在多摄像头跟踪的工作中提出了行人重识别的概念,即从图像和视频序列中识别检索特定行人。Gheissari 等[2]将行人重识别从多摄像头跟踪任务中分离出来,将它作为计算机视觉领域一个独立的任务来研究。Wu 等[3]明确了可见光-红外跨模态行人重识别的概念,即根据给定行人的可见光(红外)图像,在红外(可见光)摄像头采集的行人图像库中检索同一个行人身份的所有图像。目前在可见光范围内行人重识别问题的研究成果较多,可见光-红外范围的成果则较少,原因在于跨模态行人重识别任务不仅要面对单模态行人重识别任务中的所有挑战,还要面对不同模态图像特征差异大和高层语义特征相关的挑战。
Wu 等[3]对单流、双流、非对称全连接层网络结构在跨模态行人重识别问题研究中的表现进行了评价。Ye 等[4]使用双流网络结构提取可见光与红外行人图像之间的公共特征,网络结构主要由特征提取和特征嵌入两个模块组成。特征提取模块从两个不同模态(红外模态和可见光)学习对应模态的特定信息;特征嵌入模块学习不同模态的共同特征,再将两个模态的特定特征映射到共同特征空间中,然后进行可见光与红外模态间的行人图像识别,识别效果较好。在损失函数的设计方面,三元组损失(Triplet loss)函数[5]最初在解决人脸识别问题时被提出,之后成为一种广泛应用的度量学习类损失函数。跨模态图像推理网络(Cross-modality Graph Reasoning Network,CGRNet)[6]、集合与实例结合的对齐重识别网络(Joint Set-level and Instance-level Alignment re-identification network,JSIA)[7]中都使用了以缩小不同模态图像间差异为目标的损失函数。另外,在可见光图像的特征提取方面,增强判别性特征学习方法(Enhancing the Discriminative Feature Learning method,EDFL)[8]、带加权三元组的注意力广义平均池化模型(Attention Generalized mean pooling with Weighted triplet loss,AGW)[9]都使用图像局部特征之间的关系强化图像高层语义特征。
受以上研究启发,本文提出了一种基于双流结构的跨模态行人重识别关系网络(Infrared and Visible Relation Network Based on Dual-stream Structure,IVRNBDS)。该网络综合利用可见光和红外模态行人图像的不同特征、两种特征的共享特征和行人身体不同部分的关系信息进行行人重识别,并使用异质中心三元组损失(Hetero-Center Triplet Loss,HC_Tri Loss)函数[10]将不同模态的图像特征映射到同一特征空间中。为验证模型的有效性,在SYSU-MM01(SunYat-Sen University MultiModal re-identification)数据集[3]和RegDB(Dongguk Body-based person Recognition)数据集[11]两个公开的跨模态行人重识别数据集上进行实验,实验结果表明IVRNBDS 具有较好的识别效果。
1 相关工作
目前已有的基于深度学习的跨模态行人重识别方法主要分为以下三类。
1)行人统一特征提取方式。该类方法是常用的减弱模态之间的差异的方法,主要思路是提取与模态差异无关的特征,比如:Ye 等[4]提出的双流卷积神经网络特征学习网络(TwO-stream convolutional Neural network fEature learning network,TONE),利用双流网络结构提取可见光与红外行人图像之间的公共特征;Liu 等[8]利用提出增强判别性特征学习的网络,具体地,利用卷积神经网络(Convolutional Neural Network,CNN)的不同层含有不同语义信息的特点,以跳步连接的方式融合中间层的特征;Xiang 等[12]将MGN(Multiple Granularity Network)结构[13]引入特征提取模块,结合图像的局部和全局信息提高特征嵌入的表达能力;Lu 等[14]提出了跨模态共享及特异特征转移算法,该算法采用了双流特征提取器提取特征,通过图卷积融合特异特征与共享特征;Zhao等[15]则是将不同模态的行人图像输入同一个网络中,结合行人ID(IDentification)损失提取特征;Zhang 等[16]提出了一个基于双流网络的跨模态行人重识别算法,将两种模态特定特征嵌入三维张量空间中,生成两种模态下的特定内核,然后通过对比计算两个内核的差异性提取对比特征。
2)基于度量学习的跨模态行人重识别方式。该类方法注重损失函数的设计。损失函数设计的目标是使同一行人的所有模态的图像之间的距离尽可能小,使不同行人的所有模态的图像之间的距离尽可能大,如:Ye 等[17]提出了双向双约束高 阶(Bi-directional Dual-constrained Top-Ranking,BDTR)损失,Zhu 等[18]提出了异质中心损失,Liu 等[10]提出了HC_Tri Loss 等;另外,Hao 等[19]提出了Sphere Softmax 并对模态内差异和模态间差异进行约束,Liu 等[8]利用双模态三元组损失减小模态间和模态内差异。
3)基于模态转换的方式。该类方法利用生成对抗网络将一种模态的行人图像转换成另一模态的行人图像,以便更好地提取共享特征。Wang 等[20]设计了双层差异缩减网络,利用两组生成对抗网络对可见光与红外行人图像进行图像的双向转换,通过特征嵌入减小无法充分转换的外观差异,以缩小特征提取结果的模态差异。Wang 等[21]提出了对齐的生成对抗网络,也使用了两组生成对抗网络进行可见光与红外模态行人图像的双向转换。此研究与文献[20]中的不同在于此研究将红外图像转换成可见光图像的生成对抗网络用于辅助跨模态行人重识别模型训练,然后和可见光的RGB三维度图像拼接,生成四维度图像,再进行总体训练提取网络特征。Zhang 等[22]提出了基于不同模态的师生模型,包含可见光图像生成红外图像的生成对抗网络、主干网络和预训练师生模型这3 个模块,提升了生成图像的质量。Fan 等[23]提出了跨模态双子空间配对方法实现模态互转。Choi 等[24]为解决同一模态内和不同模态间图像特征差异的问题,提出了一种分层跨模态解纠缠方法。此方法可以从两种模态图像中分离模态内特征和跨模态特征,提高了生成图像的质量。
这些方法都在一定程度上提升了可见光与红外跨模态行人重识别模型在公开数据集上的识别精度,但目前的识别效果与单模态下的识别效果还有较大的差距;同时大多数方法都侧重全局特征的提取和使用,没有考虑更具有辨识度的局部特征、图像的每个局部特征与整体特征的关系等细节。
2 IVRNBDS
IVRNBDS 的结构如图1 所示,由双流模块、关系模块和损失函数模块这部分组成。双流模块以残差网络(Residual Network,ResNet)50为骨干网络,首先将输入的可见光图像和红外图像在Stage1 中的卷积块分别进行模态特征提取,然后在Stage2 合并提取特征,并与Stage3、Stage4、Stage5 网络层一起作为特征嵌入器进行参数共享得到共享特征。后续的关系模块先将经过双流网络提取的共享特征水平切分为6 个片段以进行局部特征的学习。接着,将局部特征分别输入局部关系模块(One-vs-Rest Relational Module,ORRM)和全局关系模块(Global Contrastive Relation Module,GCRM)。ORRM 提取行人图像每个单一片段与其他片段之间的关系特征,GCRM提取行人全局关系特征。为了使整个网络模型提取到更多有效的行人特征,IVRNBDS 采用ID 分类损失和HC_Tri Loss 组合监督训练,以便更好地优化可见光和红外两个模态中不同行人图像之间的三元组关系。
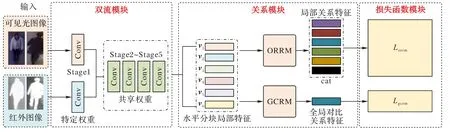
图1 IVRNBDS的结构Fig.1 Structure of IVRNBDS
2.1 ORRM
ORRM 的输入是共享特征水平切分所得到的6 个片段,v1~v6。图2 给出片段v1与其他片段之间关系的计算过程。首先,对片段v1进行GeM(Generalized Mean)池化操作之后得到f(v1),将剩余片段v2~v6求平均(图2 中的A 操作),结果记作vr,再进行GeM 池化操作得到f(vr)。接着,将特征f(v1)和f(vr)分别进行卷积操作(图2 中的Conv 操作,具体包括一个1×1 卷 积、一 个Batch Normalization 和一个ReLU(Rectified Linear Unit)操作),得到特征fˉ(v1)和fˉ(vr)。然后,对fˉ(v1)和fˉ(vr)进行连接(图2 中的C 操作)、卷积操作(图2 中的Conv操作,具体包括一个1×1 卷积、一个Batch Normalization 和一个ReLU 操作)。最后,将所得结果与fˉ(v1)相加(图2 中的+操作)得到含有所有局部特征的局部关系特征f^(v1)。
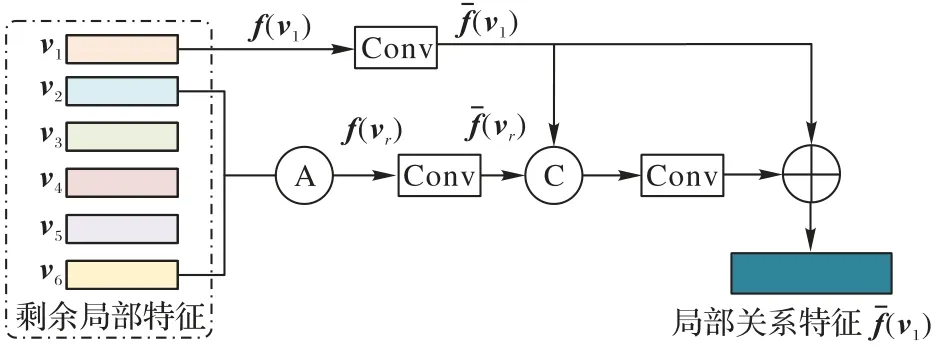
图2 片段v1与其他片段之间关系的计算过程Fig.2 Relation computing process of segment v1 and others
ORRM 对输入v1~v6分别进行上述操作,得到6 个关系特征,分别记作f^(vi)(i=1,2,…,6)。ORRM 的结构即包括图2结构的6个复本,每个复本对应求解一个片段vi(i=1,2,…,6)和其他片段vj(j=1,2,…,6 ∧j≠i) 之间的 关系特 征。ORRM 的设计思路很好地表达了行人的一个片段和其他片段之间的关系,有利于提取更具辨识度的行人特征信息。
2.2 GCRM
为了更好地表示整个行人图像信息,可见光单模态行人重识别方法通常采用全局平均池化(Global Average Pooling,GAP)方法[25]或全局最大池化(Global Max Pooling,GMP)方法[26],或者是这两种方法的结合。GAP 方法的特点主要是进行整个行人图像的平均全局信息表示,但是很容易掺杂图像的背景信息使得提取的行人特征不干净;GMP 方法的作用是过滤背景信息,而将局部有用的行人信息聚合到一起,但这样缺少整个行人图像的全局信息。Fu 等[27]将两种方法结合,弥补了两种方法单独使用的缺陷,实验结果表明两种方法结合的效果优于单独使用GMP 或GAP。受此启发,本文设计了GCRM,用于从行人身体片段信息中提取代表行人图像的全局信息特征,GCRM的结构如图3所示。

图3 GCRM的结构Fig.3 Structure of GCRM
2.3 损失函数
本节损失函数用ID 身份损失(Lid)对提取的行人图像局部特征进行计算,引进HC_Tri Loss 函数[10]计算全局特征,保留ID 身份损失对局部特征计算。HC_Tri Loss 函数与普通的三元组损失函数相比,更适用于跨模态行人重识别,因为它是将锚点中心与其他样本中心比较,而普通的三元组损失是将锚点与其他样本比较,这样可以降低普通的三元组损失函数原有的强约束能力,让不同模态的图像更好地映射到同一特征空间中。
HC_Tri Loss 的示意图见图4。图4 中的圆代表行人图像样本中心,不同的颜色代表不同标识的行人。异质中心三元组损失的目标是从不同的模态拉近那些具有相同身份标签的中心,推远那些具有不同身份标签的中心。无论哪个模态的样本,都是比较中心到中心的相似性,而不是样本到样本的相似性或样本到中心的相似性。

图4 HC_Tri Loss的示意图Fig.4 Schematic diagram of HC_Tri Loss
具体地,首先异质中心三元组采取了在线随机采样策略,通过在网络训练的一次迭代过程中随机选择P位行人,接着在选中的P位行人中随机选择K张可见光图像和K张红外图像组合成一个mini-batch,即一个mini-batch 共包含2 ×P×K张图像。这种采样策略充分发挥了小样本采样的优势,可以保证每一个行人的样本数相同,巧妙地避免了样本中行人图像数不一致所带来的干扰,并且随机采样使得在mini-batch 这种小范围里的局部约束能够和在整个数据集中的全局约束取得同等的效果。如上所示,在mini-batch 中获取来自每个模态的每个行人标识的特征中心。如异质中心三元组表达式如下:表最难区分的负样本。总而言之,异质中心三元组损失函数的目标就是专注于一个跨模态的正样本对和在模态内与模态间最难区分的负样本对。
本文将异质中心三元组损失函数用于可见光-红外跨模态行人重识别模型中,综合优势主要有以下3 点.
1)减弱了传统三元组损失函数的强约束力,降低了模型计算成本;
2)通过缩小不同模态图像正样本(中心)对之间的距离能够有效地保证类内的紧凑性;
3)最难负样本(中心)的设计能够有效地保证在可见光模态和红外模态下不同行人特征的可区分性。
ORRM 模块整体损失函数为:
GCRM 整体损失函数为:
最终总体损失表示为:
3 实验与结果分析
3.1 实验设置
本文实验使用64 位Ubuntu20.04 操作系统,采用深度学习框架PyTorch 1.10.0 实现,训练服务器采用显卡内存为32 GB 的NVIDIA 3090,CUDA 版本为11.3。与先前存在的跨模态行人重识别模型相同,采用在ImageNet 上进行预训练后的权重参数进行初始化。在训练阶段,将输入图像的尺寸调整为高288,宽144,Batch Size 大小设为64,每次随机选取4个不同的行人图像作为模型输入,每个行人包含有8 张可见光图像和8 张红外图像。优化器算法选取随机梯度下降(Stochastic Gradient Descent,SGD)作为网络模型的优化器,总共训练60 个epochs,学习率初始化值为0.1,第20 个epochs到第30个epochs之间学习率衰减为0.01,第50个epochs后学习率衰减为0.001,用于实验的两个跨模态数据集共享相同的实验设置。
本文的实验数据集是SYSU-MM01 数据集[3]和RegDB 数据集[11],这是目前较常用的两个公开的跨模态行人重识别数据集。SYSU-MM01 数据集由6 个摄像头采集的图像组成,包含4 个可见光摄像头和2 个红外摄像头。总共包含491 个行人ID,其中296 个行人ID 用于训练集,99 个行人ID 用于验证集,96 个行人ID 用于测试集。在这些行人图像中,可见光行人图像数有15 792,RGB 图像数有287 628,用作训练集的可见光行人图像数为19 659,红外行人图像数为12 792。RegDB数据集是同时使用可见光摄像头和红外摄像头拍摄。共包含行人图像数412(男人158,女人254),每人包含可见光图像数10,红外图像数10,其中拍摄到行人正面的有156,背面的有256。全部图像含有可见光行人图像数4 120,红外行人图像数4 120。该数据行人图像的特点是图像比较小,清晰度较差,每个行人身份的可见光图像和红外图像的姿态一一对应,在姿态上的变化很小,这些数据集本身的特点降低了跨模态行人重识别任务的难度。
3.2 相关方法对比
本文与近两年表现较好的可见光-红外跨模态行人重识别方法进行比较,对比方法主要有:基于度量学习的行人重识别方法TONE[4]、BDTR[17];基于生成对抗网络的方法XIV(X-Infrared-Visible)[28]、JSIA[7]、对齐的生成对抗网络(Alignment Generative Adversarial Network,AlignGAN)[21];基于局部特征学习的方法AGW[9]、动态双注意聚集网络(Dynamic Dual-attentive AGgregation network,DDAG)[29]、局部全局多通道学习方法(Global-Local MultiChannel learning method,GLMC)[30]以及基于共享参数学习的方法跨模态共享-特殊特征转换(cross-modality Shared-Specific Feature Transfer,cm-SSFT)方 法[13]、基于跨模态相似性保持(Cross-Modality Similarity Preservation,CMSP)的行人重识别算法[31]、颜色无关的特征一致性学习(Color-Irrelevant Consistency Learning,CICL)方法[32]、神经特征查询(Neural Feature Search,NFS)方法[33]。
本文实验评价指标使用相似度排名第1(similarity Rank 1,Rank-1)和平均精度均值(mean Average precision,mAP)。Rank-1 指标指先求解每张查询图像与测试集(Gallery set)中每张图像的相似度(similarity),对每张查询图像,依据相似度排序对所有测试集图像进行排序,再计算相似度最高的图像与查询图像属同一ID 的概率平均值。Rank-1 指标越高,实验效果越好。对查询集中每张查询图像、测试集中所有与之匹配的行人图像先计算平均精度(Average Precision,AP),再求所有匹配的行人图像的mAP。mAP 越高,实验效果越好。
表1 列出了本文网络与上述方法在SYSU-MM01 数据集上的对比结果。在全局搜索模式下,IVRNBDS 比上述方法效果更好。IVRNBDS 在性能评价指标Rank-1 和mAP 上对应的取值分别为70.13%和65.33%,比GLMC 方法在Rank-1 指标上提升了5.76 个百分点,在mAP 指标上提升了1.90 个百分点。在室内搜索模式下,IVRNBDS 也表现出了较大的优势。比NFS、CICL、GLMC 方法在Rank-1 指标上分别提升了7.57、3.76、3.01 个百分点,比NFS、cm-SSFT 方法在mAP 指标上分别提升了3.36 和0.55 个百分点。

表1 IVRNBDS与其他方法在SYSU-MM01数据集上的性能对比 单位:%Tab.1 Performance comparison of IVRNBDS and other methods on SYSU-MM01 dataset unit:%
表2 为IVRNBDS 和其他对比方法在RegDB 数据集上的实验结果对比。在可见光-红外模式(Visible-Infrared)下,IVRNBDS 分别取得了92.34%的Rank-1 和92.58%的mAP,与GLMC 相比,在Rank-1 上提升了0.5 个百分点,在mAP 上提升了11.16 个百分点。同样有效的是在红外-可见光模式(Infrared-Visible)下,IVRNBDS 分别取得了91.35%的Rank-1和91.78%的mAP。相较于GLMC,在Rank-1 上提升了0.23个百分点,在mAP 上提升了10.72 个百分点。

表2 IVRNBDS与其他方法在RegDB数据集上的性能对比 单位:%Tab.2 Performance comparison of IVRNBDS and other methods on RegDB dataset unit:%
3.3 消融实验
为了进一步分析IVRNBDS 框架中ORRM、GCRM 和异质中心三元组损失函数设计的有效性及贡献,本文设计了一系列消融实验。使用AGW 网络,应用标准的交叉熵分类损失与带权重的正则三元组损失函数进行优化,在表3 中用“B”来表示。采取分别添加ORRM、GCRM、异质中心三元组损失函数的方式,对比它们对红外-可见光跨模态行人重识别任务的影响。整个实验在SYSU-MM01 数据集上进行。

表3 SYSU-MM01数据集上的消融实验结果 单位:%Tab.3 Results of ablation experiments on SYSU-MM01 dataset unit:%
ORRM的影响 如表3所示,和Baseline网络(表3中表示为B)相比,包含了ORRM 得到的模型取得了更好的效果。在全局搜索模式下性能评价指标Rank-1 由47.50%提升至62.68%,mAP 则从47.65%提升至57.51%;在室内搜索模式下模型性能也得到了相应的提升,Rank-1提升了8.24个百分点,mAP则提升了4.20个百分点。在RegDB 数据集上的实验结果见表4,在可见光-红外模式下,与Baseline 相比,在Rank-1 和mAP 指标上分别提升了18.88 和23.57 个百分点;在红外-可见光模式下,因为在原论文中没有结果,所以在此不再讨论。实验结果验证了ORRM关系模块的有效性。

表4 RegDB数据集上的消融实验结果 单位:%Tab.4 Results of ablation experiments on RegDB dataset unit:%
GCRM 的影响 如表3 所示,与Baseline 网络相比,当使用了GCRM 后,模型性能得到了显著的提高,在全局搜索模式下,加入GCRM 之后,Rank-1提升了14.5个百分点,mAP 提升了11.79 个百分点,在室内搜索模式也取得了极大的性能提升,Rank-1 提升了13.2 个百分点,mAP 提升了7.17 个百分点。性能评价指标Rank-1 精确率由47.50% 提升到了62.00%,而mAP 则从47.65%提升到了59.44%。在RegDB数据集上的实验结果见表4,在可见光-红外模式下,与Baseline 相比,在Rank-1 和mAP 指标上分别提升了16.89 和21.79个百分点,验证了GCRM的有效性。
异质中心三元组损失函数的影响 同样地,与Baseline网络相比,用异质中心三元组损失函数替换Baseline中的批次难样本挖掘损失后得到的模型性能也得到了提升,取得了更好的效果,性能评价指标Rank-1 在全局搜索和室内搜索两种模式下分别提升了14.02 和11.24 个百分点,而mAP 分别提升了10.87 和6.33 个百分点。在RegDB 数据集上的实验结果见表4,在可见光-红外模式下,与Baseline 相比,在Rank-1 和mAP指标上分别提升了9.17和1.98个百分点,验证了异质中心三元组损失函数对跨模态行人重识别任务的有效性。
选择三元组损失函数和批量难样本三元组损失函数[34]与本文使用的异质中心三元组损失函数进行对比。表5 中“A”表示除去损失函数的网络结构。表5 给出在SYSU-MM01 数据集上、在实验设备和实验环境都相同情况下,60 个epochs 的训练时间。可见异质中心三元组损失的训练时间要少于其他的三元组损失函数。

表5 不同损失函数在SYSU-MM01数据集上的训练时间 单位:minTab.5 Training time of different loss functions on SYSU-MM01 dataset unit:min
此外,还比较了IVRNBDS 与同样使用双流网络结构的AGW 和DDAG 的计算量和推理时间,如表6 所示。相较于AWG,IVRNBDS 和DDAG 的计算量,即每秒浮点运算次数(FLoating-point Operations Per second,FLOPs)会稍微更大一些,原因是网络关注局部特征与整体特征的关系,所以包含了耗时较多的分块操作。而IVRNBDS 和DDAG 模型,都包含分块操作,计算量相差不大。但IVRNBDS 在单幅图像进行推理时所消耗的时间会比DDAG 更多,这是因为IVRNBDS需要作大量分块后的局部特征-全局特征关系的计算,这一操作比较复杂,需要等到所有分块的关系特征计算完毕才能进行下一步的计算,网络在等待同步的时候需要花费时间。但是IVRNBDS 的实验结果均优于其他对比模型的评价指标,这是值得的。

表6 不同方法在SYSU-MM01数据集上的计算开销Tab.6 Computational cost of different methods on SYSU-MM01 dataset
最后,实验表明使用了本文中的所有模块的IVRNBDS取得了最佳的性能。在SYSU-MM01 和RegDB 数据集上得出的实验结果说明了IVRNBDS 的有效性。从以上实验结果可以看到,IVRNBDS 在RegDB 数据集上的提升幅度比在SYSU-MM01 数据集上更大,这是因为RegDB 数据集的图像小、清晰度较低,并且每个身份的可见光图像和红外图像的姿态变化幅度很小,基本上一一对应。得益于ORRM 挖掘了单个模态图像的局部特征与其他部分特征之间的关系,以及GCRM 挖掘的行人图像核心特征和平均特征之间的对比关系,异质中心三元组损失函数的使用,也让不同模态图像之间的全局特征更具表达力并且减弱了背景噪声信息的干扰,使得IVRNBDS 在SYSU-MM01 和RegDB 数据集都取得了效果的提升,并且在RegDB 数据集上的提升效果尤为明显。
3.4 可视化分析
图5 展示了IVRNBDS 在跨模态数据集SYSU-MM01 上进行实验的3 组可视化结果。每一行代表一组,每组包括9 列。其中的Query 列代表待检索行人图像,接着的8 列图像表示IVRNBDS 从行人图像库gallery 中检索出来的与待检索行人Query 相似度最高的行人图像,排序越靠近Query 列的图像,相似度越高。
另外,在对IVRNBDS 进行测试时,对行人重识别的检索结果进行了可视化检验,检索结果正确用方框展示,检索结果错误用虚线框展示。图5 中虚线框和方框的情况大体上反映了IVRNBDS 在SYSU-MM01 公开数据集上全局搜索模式下的结果,可以看出与待查询图像具有相同尺度大小的图像匹配更准确;与待查询图像角度不同的图像匹配效果基本准确;对有多个人物重叠图像匹配效果不是很理想。总体来说,通过可视化的方式展示了IVRNBDS 的有效性。
4 结语
本文针对可见光-红外跨模态行人重识别精度低的问题提出了IVRNBDS,IVRNBDS 主要包含双流模块、关系模块和损失函数模块。关系模块中,ORRM 进行行人图像局部关系特征的挖掘,GCRM 进行行人图像的核心特征与平均特征之间的对比关系特征的提取;异质中心三元组损失函数将锚点中心与其他样本中心作比较,更适用于跨模态行人重识别。实验结果表明,IVRNBDS 在可见光-红外跨模态行人重识别公开数据集SYSU-MM01 和RegDB 上都取得了不错的识别效果,在识别精度上取得了有效的提升。
比较不同模态图像特征,进而提取共同特征,使用同一网络框架或算法同时处理单模态和跨模态行人重识别任务、并提高识别精确率是下一步要研究的问题。
猜你喜欢
山西大学学报(自然科学版)(2021年1期)2021-04-21
意林(2021年5期)2021-04-18
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
五邑大学学报(自然科学版)(2019年3期)2019-09-06
扬子江(2019年1期)2019-03-08
数学物理学报(2017年5期)2017-11-23
小天使·一年级语数英综合(2017年6期)2017-06-07
计算机工程与设计(2015年1期)2015-12-20
现代防御技术(2014年6期)2014-02-28
