
多尺度对称压缩伪影去除神经网络
2023-07-21 08:19卜东寒李志宏王安红赵利军
太原科技大学学报 2023年4期
卜东寒,李志宏,王安红,赵利军
(太原科技大学 电子信息工程学院,太原 030024)
图像的数据量迅速增加,图像压缩与恢复技术面临巨大的挑战。有损压缩如JPEG[1]会引入复杂的压缩伪影,尤其是块伪影,振铃效应和模糊。不仅影响视觉效果,还给目标检测等领域带来极大的负面影响。因此,去除压缩伪影在图像处理领域尤为重要。针对压缩伪影去除,相关研究人员提出了很多算法。Foi等人[2]提出基于形状自适应离散余弦变换的图像滤波算法,但会导致输出图像丢失高频信息。Yoo等人[3]提出了基于DCT的后处理算法去除块效应,但仍存在较明显伪影。近年来基于深度学习的算法在各种计算机视觉领域[4-8]取得了十分优秀的效果。在去除JPEG压缩伪影方面,DONG等人[9]最早提出了一种基于卷积神经网络(CNN)的框架,但恢复图像仍有一些明显的块效应。Zhang等人[10]提出了一种双域多尺度CNN放大接收域,利用像素域和DCT域的冗余去除JPEG压缩伪影。
本文提出了一个多尺度对称压缩伪影去除神经网络,在原始图像尺寸和小图像尺寸采用对称的网络结构进行特征提取和整合。为了更多恢复出图像的纹理信息,并且增加在高层次视觉处理如目标检测中的表现效果,本网络同时在感知空间控制模型训练。实验结果表明,本文所提算法可以在压缩伪影去除处理中取得更好的性能。
1 所提算法
1.1 网络整体结构
为了去除压缩伪影,本文设计构建了一个基于卷积神经网络的结构框架,如图1所示。低分辨率会弱化失真,缩小图像可以减小压缩伪影带来的影响,所以采用多尺度的多支路结构,使得降低分辨率的支路提取到的特征对不改变分辨率支路提取的特征进行信息增强。同时,在图像原始尺寸和小尺寸的特征提取过程中,输入均为带有压缩伪影的图像,输出均是用于恢复重建图像的特征,考虑到两条支路输入与输出的一致性,两条支路采用相同的网络结构,整个压缩伪影去除网络呈现出对称的特点。

图1 多尺度对称压缩伪影去除神经网络Fig.1 Multi-scale symmetrical neural network for compression artifacts reduction
图1中矩形框代表卷积操作,卷积核尺寸均为3×3,卷积步长为1.在未改变图像尺寸的支路中,首先使用一层卷积操作输出大通道特征图,再送入多个残差块中进一步增强和处理特征。在改变分辨率的支路中,采用步长为2的卷积实现缩小图像,同时充分提取图像特征并输出大通道特征图。接下来输入多个残差块增强并处理特征,将得到的特征图使用Subpixel上采样变回原图尺寸。将两条支路的输出在通道维度上进行拼接,再经过一个卷积映射回原始图像的通道数。为了加快网络收敛,迅速获得图像内容和结构信息,本网络整体进行残差学习。
1.2 损失函数
本文使用一种复合损失函数进行网络训练,如公式(1)所示,主要由三部分构成:MSE损失、VGG损失和SSIM损失。其中,MSE损失函数可以保证重建图像与原始图像之间逐像素的相似性,但是单独使用可能会导致输出图像过度平滑。为了更好地保留图像的边缘和细节等高频信息,本文结合了SSIM损失提高对图像结构相似性的判断,同时可以加快收敛,快速获得结构信息。但是使用单一的SSIM损失函数可能会带来亮度的改变或者颜色的偏差,与MSE函数复合使用可以规避这一缺陷。在此基础上,加入VGG损失确保要对比的两幅图像在感知空间有一致性,进一步提高模型性能。

(1)
(2)
为了避免MSE损失带来的过度平滑,缺少高频信息,添加感知损失,将重建后图像与原始图像都映射到感知空间对比两图像的感知内容的差异,如公式(3)所示。本文采用了PyTorch模型库中添加的预训练好的VGG网络模型,提取用于特征提取的最后一层卷积经过ReLU激活层的输出φV(·)作为感知对比,减小感知间的差异性。
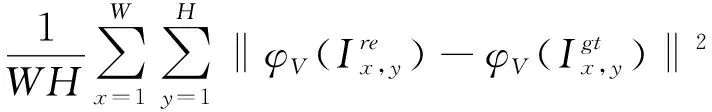
(3)

(4)
2 训练和测试
2.1 数据集
本网络使用了MSCOCO数据集作为训练集,另外,从MSCOCO中随机选取了100张不同于训练集的图像作为一个测试集,在下文中称为MSCOCO_test100.测试集另外还包括LIVE1数据集、Classic5数据集、BSD500数据集中的测试集等,具体可参见表1.使用标准JPEG压缩方案,将压缩参数Q设置为10、20、30、40,得到压缩数据集。在压缩伪影去除的实验中,使用了图像Y通道(YCbCr空间的Y通道)和RGB彩色图像两种方案作为数据集。

表1 本文所提算法与ARCNN的PSNR与SSIM对比结果Tab.1 The PSNR and SSIM comparison results between ARCNN and the proposed algorithm
2.2 参数设置和网络训练
在训练过程中,每个Epoch随机从MSCOCO数据集中抽取10 000张图像作为训练集,并将其随机裁剪成200×200的图像进行批次训练,减少训练时间。使用Adam优化器进行模型训练,采用等间隔调整的方式进行学习率衰减,初始学习率设置为0.000 5,每30个Epoch学习率的值变为原来的一半,总共训练150个Epoch.损失函数的三个参数值,α、β、γ均设置为1.本网络使用PyTorch实现,训练在NVIDIA TITAN RTX 与 TITAN XP GPU上进行,测试在NVIDIA TITAN RTX GPU上进行。
3 实验结果
3.1 对比实验结果
使用ARCNN和DMCNN给出的官方测试代码和预训练模型进行该算法的测试,与本文提出的模型效果进行比较。ARCNN与DMCNN分别将数据集处理成不同的尺寸,ARCNN不改变原本的数据集,而DMCNN对数据集进行了裁剪,为了比较公平,分别用它们的方法处理数据集进行结果对比。
3.1.1 客观比较
峰值信噪比PSNR是图像处理领域使用极其广泛的评价指标,但是它没有考虑到人眼的视觉特性,而结构相似性SSIM分别从亮度、对比度和结构三方面度量图像相似性。近些年来关于图像处理方面的研究更加注重于SSIM的对比,所以本文主要侧重于SSIM指标进行恢复图像质量评价。
Skimage是基于Python开发的图像处理包,在图像处理领域尤其是基于深度学习的图像处理方面具有广泛的应用。为保证比较公平,本文中对所有比较方法全部用给出的预训练模型进行测试,将得到的结果统一使用Skimage图像处理包计算。
本文所提模型与ARCNN的结果对比如表1所示,最优参数用加粗字体表示,每个压缩质量参数Q中最后一行对应的是每个算法在所有测试集上的平均值。在大部分测试集上,本文所提算法的PSNR高于ARCNN.在所有测试集上,本文所提算法的SSIM均优于ARCNN.
本文所提模型与DMCNN的结果对比如表2所示,最优参数用加粗字体表示,每个压缩质量参数Q中最后一行对应的是每个算法在所有测试集上的平均值。在大部分测试集上,本文所提算法的SSIM优于DMCNN.而PSNR次于DMCNN,这是由于DMCNN的损失函数全部由MSE组成。
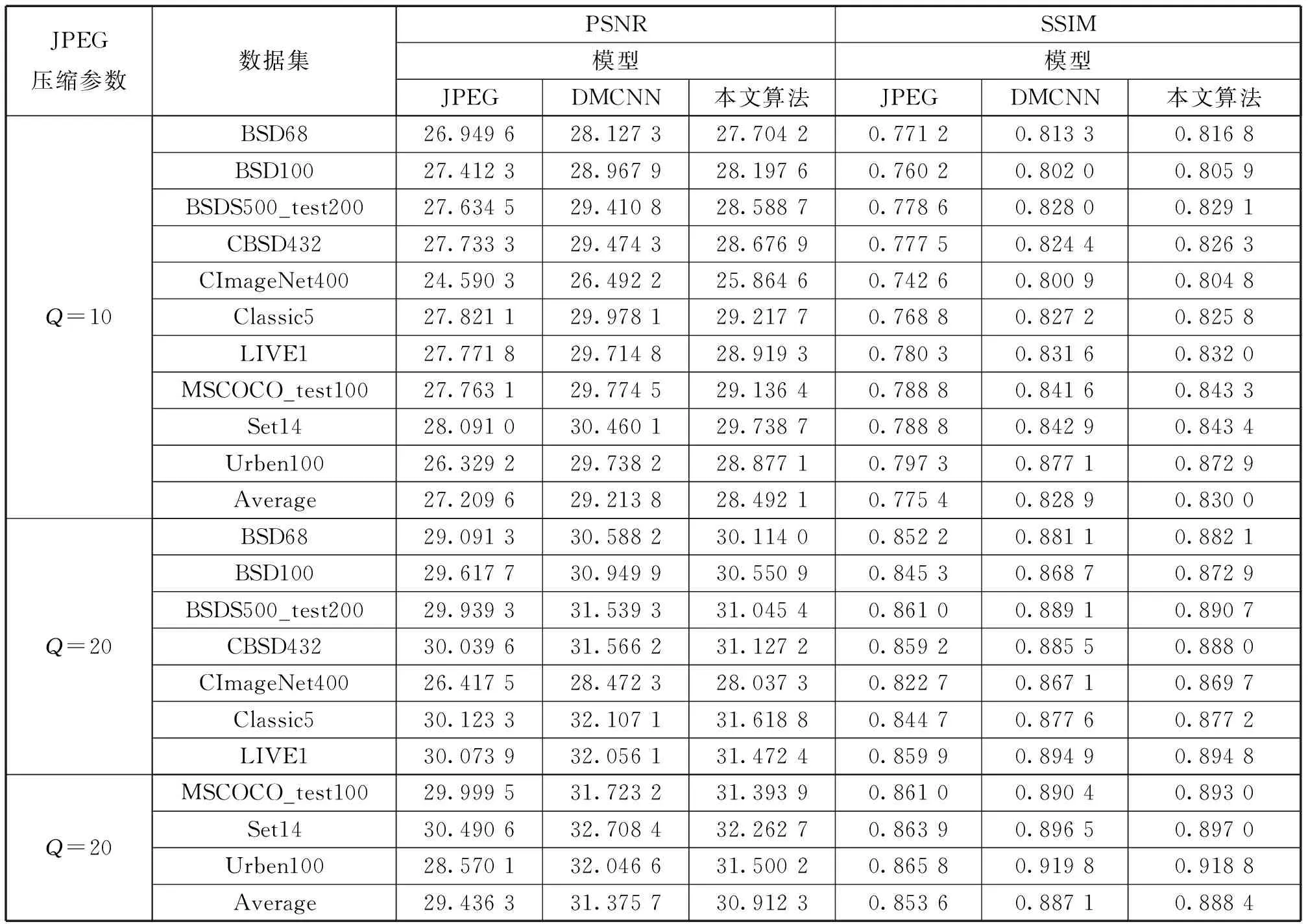
表2 本文所提算法与DMCNN的PSNR与SSIM对比结果Tab.2 The PSNR and SSIM comparison results between DMCNN and the proposed algorithm
表3列举了各个模型的参数量的对比。其中,ARCNN的模型最小,但是在数字度量指标的成绩很低,视觉质量有所欠缺。相对更好的是DMCNN和本文所提算法,但是本文算法模型的参数量仅仅为DMCNN的四分之一,却可以取得更高的SSIM和视觉质量,获得更好的恢复效果。

表3 各个模型的参数量对比Tab.3 Comparison of parameters of each model
3.1.2 主观比较
图2和图3中展示了测试集中主观视觉对比的部分结果。图中第一列是原始图像,第二列是经过JPEG压缩的图像,第三列分别是经过ARCNN和DMCNN恢复出的图像,最后一列是本文所提算法的恢复结果,展示的均为局部放大图,可以看到更清晰的细节内容。

图2 本文算法与ARCNN的视觉对比Fig.2 Visual comparison between ARCNN and the proposed algorithm

图3 本文算法与DMCNN的视觉对比Fig.3 Visual comparison between DMCNN and the algorithm proposed
从图2中的第一幅图像的局部放大图可以看出,本文所提算法重建出的图像中的树木枝叶更加分明。相比来说,ARCNN重建出的图像比较模糊,且受块伪影影响较大,本文算法可以重建出更加清晰更加丰富的纹理。在第二幅图像的天空部分,ARCNN的恢复重建结果还有明显的带状效应,而本文算法的恢复结果没有明显的过渡边缘,比ARCNN的结果更加接近原始图像。
本文算法去除图像压缩伪影的结果比DMCNN有更丰富的纹理,如图3所示。第一幅图像中老虎身上的条纹对比度更大,第二幅图像中恢复出的水花更加明显。
3.2 目标检测实验验证
表4是经过不同处理的数据集在YOLOv5各个模型上的mAP对比。此处使用了四个不同大小的模型,从小到大依次是Yolov5s、Yolov5m、Yolov5l、Yolov5x.不同的处理分别表示为原始数据集、经过JPEG压缩的数据集和经过本文算法恢复出的数据集。mAP均在JPEG压缩之后下降明显,但是在经过本文的恢复算法之后,所有模型的mAP值都会有较大回升。

表4 不同处理的数据集在YOLOv5上的mAP对比Tab.4 mAP of different processed data on YOLOv5
图4中第一列是目标检测的标签示意图,第二列是原始数据集的目标检测结果,第三列是将原始数据集经过压缩之后的检测结果,最后一列是使用本文算法对压缩图像恢复之后的目标检测输出。此处使用的目标检测算法是Yolov5x预训练模型。

图4 经过不同处理的数据集在YOLOv5模型上的检测结果Fig.4 Object detection results of different processed data on YOLOv5
如图4所示,图像经过JPEG压缩之后,产生了明显的漏检,比如第一幅图像中的狗和第三幅图像中的人。第二幅图像中的长颈鹿一只漏检,另外一只虽然可以检出,但是概率得分从0.9下降到0.5,经过本文算法恢复之后的检测结果不仅可以提高检出率,还可以提高检测概率分数。第三幅图像中有一些小型目标因压缩导致了漏检,本文算法恢复后也可以重新检测出来。
4 结论
为了去除压缩伪影,本文提出了一个多尺度对称神经网络,在原始图像尺寸和小图像尺寸采用对称的网络结构进行特征提取和整合。为了加速网络训练,快速获取图像的结构信息,本网络采用残差结构,同时在感知空间控制模型训练。实验结果表明,本文所提算法可以在图像压缩伪影去除处理中取得更好的性能,并且可以在一定程度上对抗压缩伪影给目标检测领域带来的负面影响。
猜你喜欢
西安石油大学学报(自然科学版)(2022年5期)2022-10-08
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
中国医疗器械信息(2019年3期)2019-03-09
中国医学影像学杂志(2018年9期)2018-10-17
北京航空航天大学学报(2018年1期)2018-04-20
电信科学(2016年9期)2016-06-15
电测与仪表(2016年13期)2016-04-11
中国卫生标准管理(2015年4期)2016-01-14
中国医学装备(2015年10期)2015-12-29
