
基于LDA-TF-IDF和Word2vec文档表示
2023-08-02 04:05彭俊利王少泫陆正球李兴远
浙江纺织服装职业技术学院学报 2023年2期
彭俊利 王少泫 陆正球 李兴远

摘 要:针对自然语言处理中传统文档表示方法上下文语义信息不全,干扰词多等问题,提出了一种基于LDA-TF-IDF和Word2vec的文档表示方法。首先对数据集进行分词、去停用词等预处理;其次,利用LDA主题模型和TF-IDF抽取文档中具有表征性的特征词,并计算对应权重;最后,应用数据集训练Word2vec模型获取词向量,并将抽取的特征词权重融入Word2vec词向量构建文档语义向量。通过分类任务对该方法进行验证,实验结果表明,与已有方法相比该方法在垃圾短信数据集上表现效果更佳,驗证了方法的有效性。
关键词:LDA主题模型; TF-IDF; word2vec; 文档表示
中图分类号:TP391.1 文献标识码:A 文章编号:1674-2346(2023)02-0091-06
在大数据、人工智能时代,各类文本信息呈现指数级增长,互联网每时每刻都在产生数以亿计的文本数据,文本向量化表示可以帮助用户在巨量数据中快速获取所需的信息。目前,文档表示方法一般分为两种:一种是基于词袋模型(Bag-of-Word,BoW)[1]的构建方法,将所有文档看成词语的集合,计算文档中词语的词频信息构建文档向量;另一种方法是基于词嵌入(Word Embedding)的构建方法,通过深度学习模型建立词语与上下文的联系,并将所有词语都映射到某一维度的连续向量空间中,使词向量中包含更加丰富的语义信息,然后对词向量进行处理,得到文档向量。
上面两种文档表示方法存在着一定的问题。词袋模型不考虑文档中词语的顺序、语义等信息,将文档表示为一个同数据集所有词语总数相同维度的向量,向量每一维度上的值就是该位置词语的词频信息[2]。当利用词袋模型获取较大数据集的文档向量时,会得到高维向量,从而增加计算难度。而且这类高维向量具有稀疏性,即文档中词语表现在向量中的形式只有在极少数维度上存在有效权重[3]。此外,词袋模型的权重计算仅利用了词的频率,并未考虑词语在文中的语境,导致权重中缺乏语义信息,无法识别诸如“西红柿”“番茄”这类多义词。2013年,Mikolox等[4]提出的Word2vec模型使自然语言处理任务正式迈入了词嵌入模型时代,Word2vec利用词语与上下文的关联性,利用深度学习算法将词语转化为低维实数向量,有效解决了词频统计法存在的维度灾难问题。但词和向量是一一对应关系,多词一义或一词多义的问题并没有得到有效解决。随着对词嵌入模型的深入研究,CoVe、XLNet等基于深度学习的词嵌入模型相继出现,也被称为预训练模型。这些预训练模型在各类自然语言处理任务中都取得了很好的效果,赢得了学者们的青睐。但这类模型对算力、内存的要求极高,在很多任务中无法普及,所以Word2vec依然在各种自然语言处理任务中被广泛使用[5]。
文档中的词语少则几十多则上千,然而能表达文档主题的关键词却不多。去除干扰词,利用具有代表性的词语构建文档的语义向量是研究热点之一[5]。当前研究成果多是将词频―逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)[6]和词嵌入模型结合构建低维语义向量。汪静等[7]将词性、TF-IDF和Word2vec三者结合构建文本语义向量,最后在分类任务中验证了方法的可行性;石琳等[8]对TF-IDF进行了优化,并加权到Word2vec模型训练得到的词向量来表示文档,在物流评价的分类预测中得到了较好的结果。但这些方法将词语的TF-IDF权重与词向量结合时并未考虑词语在不同类别间的重要程度。针对这一问题,本文提出了一种融合隐含迪利克雷分布(Latent Dirichlet Allocation,LDA)、TF-IDF与Word2vec的文档表示方法,先利用LDA主题模型计算文档、主题、词语的3层关系与权重信息,筛选出能表达文档含义的词语集合,再将该集合内所有词语的LDA权重、TF-IDF值与词向量进行融合,构建文档向量。最后,在垃圾短信数据集上进行测试,验证了该方法的有效性。
1 相关模型介绍
1.1 TF-IDF模型
TF-IDF模型是基于概率统计的算法,根据某词语在某文档中出现的频次和整个数据集中出现的频次衡量一个词语的权重。在数据集中,若某词语仅在少数文档中出现,且该词在文档中被频繁使用,则该词语就能很好代表文档的主题。TF指词语在某篇文档中出现的次数,即词频,如公式(1)所示。
但TF-IDF值只是通过词语出现的频率来代表重要程度,并未包含词语的语义信息。无法区分多词一义和一词多义的情况,如若“土豆”和“马铃薯”的频次信息不同,就会导致TF-IDF权重不同。
1.2 LDA主题模型
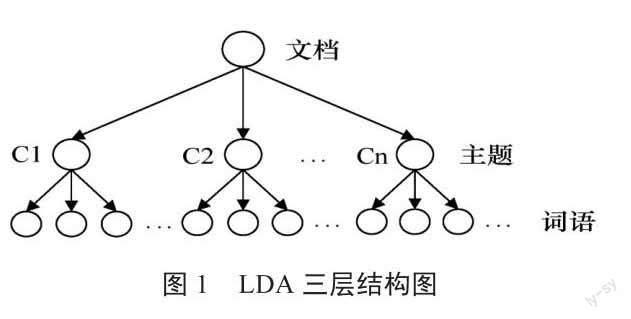
LDA主题模型是由Blei等[9]提出的一种生成文本、主题、词3层结构的贝叶斯概率模型。LDA建立在这样一种假设下:每篇文档都能提炼出若干主题,而文档中又有若干词汇能够代表每个主题[10]。层次结构图如图1所示。
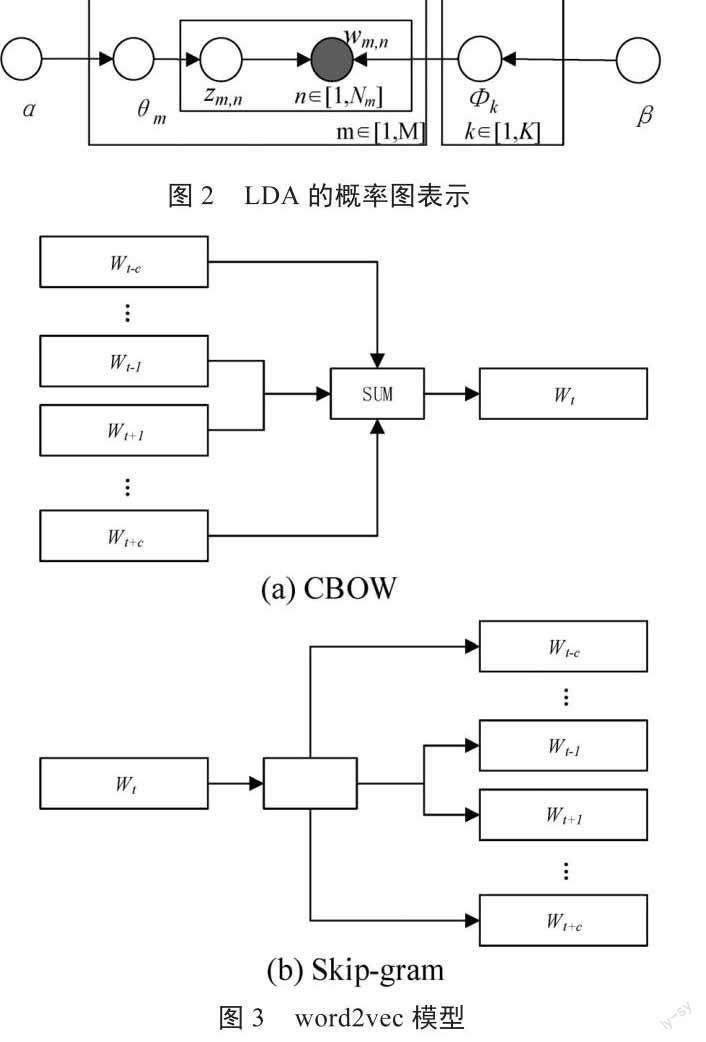
如图2所示,LDA主题模型由参数( , )确定, 为分布的超参数,是一个K维向量, 描述了各主题自身的概率分布情况[10]。
其中, 和 在使用算法时凭借经验进行设置, m表示文档与主题之间的概率关系,表示主题与词汇之间的概率关系,M表示文档数,K表示主题数,N表示每篇文档中各主题对应的词语数目,Z表示词在各主题中的分布情况[12]。通过吉布斯采样估计 和。
1.3 Word2vec模型
Word2vec是一种用于获取词向量的词嵌入模型。它将所有的词向量化,词向量中包含了词语与上下文之间的语义信息,可以较好地衡量词与词之间的关系。
Word2vec包含两类预测模型:CBOW和Skip-gram。CBOW模型根据中心词前后各c个词语来预测中心词,每个词语都会作为中心词对词向量进行调整,如图3(a)所示;Skip-gram模型相反,根据中心词预测前后各c个词语,如图3(b)所示。
CBOW模型的输入层是词wt的前后各c个one-hot词向量,这2c个词向量在投影层进行累加运算,再应用随机梯度上升法对投影层进行预测,将结果传到输出层。输出层是一棵哈夫曼树,在训练中用词语作为叶子结点,将词语的频次信息作为各结点的权重[2]215。Skip-gram模型原理相似。当训练完成后,使用词向量V进行简单的计算可发现类似关系:V(女王) = V(国王)-V(男人)+V(女人)[13],可见词向量包含了词语一定程度的语义信息。
2 融合LDA-TF-IDF和Word2vec的文档表示方法
考虑到词语权重信息的重要性以及干扰词对文档向量语义信息的影响,本文首先通过LDA获取各主题下词语的概率权重,选取具有强表征性的词语,并将LDA概率权重、TF-IDF值与Word2vec词向量进行融合,提出了一种文档向量表示法。
2.1 LDA-TF-IDF算法
由于传统的TF-IDF模型单纯以词语出现频率来衡量一个词语的重要性,并未包含词语的语义信息,并且IDF缺乏考虑词語在不同类别间的分布情况,当某类中含有该词语的文档数目越多,而在其他类中含有该词语的文档数目越少时,说明该词语具有更好的表征性,能较好地与其他类别进行区分。
为解决这一问题,本文提出了一种新权重计算方法,先将LDA中各主题下词语的概率权重与词语的IDF值相加,最后将得到的值与TF值相乘,这样得到的词语权重融合了LDA中的主题权重,在一定程度上弥补了IDF未考虑词语在不同类别间分布情况的缺点,增加了具有表征性的词语与干扰词之间的区分度。如公式(4)所示。
2.2 LDA-TF-IDF与Word2vec的融合
设数据集D中共M个文档,先对数据集中的文本数据分词,将分词后的数据输入Word2vec模型,预测每个词语对应的维实数向量。同时应用LDA-TF-IDF算法筛选具有表征性的词语构建单词集合T,并计算每个词语的LDA-TF-IDF权重值。
对于文档,先提取集合T与共同存在的词语,然后利用这些词语的词向量与权重信息将文档的文档向量表示为如公式(5)所示。
其中,表示词语的词向量,LDA-TF-IDF表示词语的权重信息。通过LDA-TF-IDF与Word2vec的融合构建包含词语在主题中的权重信息以及上下文语义信息的词向量,使其具有更强的表征性。模型工作步骤如图4所示。
3 实验
3.1 性能评价指标
分类任务常用准确率(Precision)、召回率(Recall)、值评价效果的好坏。其中,准确率P是指分类时被分入某类所有样本中分类正确的样本概率,如公式(6)所示。
3.2 实验结果与分析
为验证本方法的有效性,本文整理了1万条垃圾短信数据集作为实验数据,数据集分为垃圾短信(C1)和非垃圾短信(C2)。实验中与基于TF-IDF、Word2Vec和TF-IDF融合Word2Vec的垃圾短信识别方法进行了对比。经过多次实验,在运用本文设计的LDA-TF-IDF模型提取特征词时,将LDA的主题数目K设置为30,LDA超参数 =50/K, =0.01,这是常用设置。接着计算主题-词汇概率分布,提取每个主题的主题词,部分主题特征如表1所示。
所有实验采用五折交叉验证。测试结果如表2~表5所示。
由表2至表4实验结果可以看出,TF-IDF与Word2vec模型融合后的分类效果最佳,能够有效丰富词向量的语义信息。
由表4至表5实验结果可见,本文所提方法在垃圾短信识别中平均准确率P、召回率R、F1值比TF-IDF加权Word2vec分别提升了1.33%、1.42%、1.33%。用4种模型各类别评价指标的平均值制作对比图如图5所示。由图可知,本文所提方法在3项评价指标上均取得了最佳效果,验证了方法在文档表示方面的有效性。
3 结束语
针对现存文档向量表示方法的不足之处,本文提出了一种融合LDA与TF-IDF的词语权重计算方法,有效提取了词语在各类别间的重要程度和语义信息,将计算出的权值与Word2vec词向量进行进一步融合。最终在垃圾短信中文文本分类语料库上进行了验证,实验表明,所提方法比基于TF-IDF模型、Word2vec模型、TF-IDF融合Word2vec模型的文档向量表示方法效果更佳,证明了方法的有效性。但本文所提方法也有缺点,针对超短文本数据,算法可能无法有效学习到词语的权重与语义信息,后续将针对超短文本向量表示进行研究,提高算法对语义特征提取的准确率。
参考文献
[1]Manning C D, Schutze H. Foundations of Statistical Natural Language Processing[M].Cambridge: MIT press, 1999:229-252.
[2]唐明,朱磊,邹显春.基于Word2Vec的一种文档向量表示[J].计算机科学,2016,43(06):214-217,269.
[3]陳行健,胡雪娇,薛卫.基于关系拓展的改进词袋模型研究[J].小型微型计算机系统,2019,40(05):1040-1044.
[4]Mikolov T,Chen K,Corrado G,et al.Efficient estimation of word representations in vector space[C]//International Conference on Learning Representations.2013:1-12.
[5]彭俊利,谷雨,张震,等.融合单词贡献度与Word2Vec词向量的文档表示[J].计算机工程,2021,47(04):62-67.
[6]T S Z,H M L.Mining microblog user interests based on TextRank with TF-IDF factor[J].The Journal of China Universities of Posts and Telecommunications,2016,23(05):40-46.
[7]汪静,罗浪,王德强.基于Word2Vec的中文短文本分类问题研究[J].计算机系统应用,2018, 27(05):209-215.
[8]石琳,徐瑞龙.基于Word2vec和改进TF-IDF算法的深度学习模型研究[J].计算机与数字工程,2021,49(05):966-970.
[9]Blei D M,Ng A Y,Jordan M I. Latent Dirichlet allocation [J].Journal of Machine Learning Research,2003,3(03):993-1022.
[10]王振振,何明,杜永萍.基于LDA主题模型的文本相似度计算[J].计算机科学,2013,40(12):229-232.
[11]Dong X L,Wei L F,Zhu H J,et al.EP2DF:an efficient privacy-preserving date-forwarding scheme for service-oriented vehicular Ad Hoc networks [J].IEEE Transactions on Vehicular Technology,2011,60(02):580-591.
[12]张志飞,苗夺谦,高灿.基于LDA主题模型的短文本分类方法[J].计算机应用,2013,33(06):1587-1590.
[13]Mikolov T,Yih W,Zweig G.Linguistic Regularities in Continuous Space Word Representations[C]//Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics.Atlsnta:NAACL Press,2013: 746-751.
Abstract: Aiming at the problems of incomplete contextual semantic information and many interfering words in traditional document representation methods in natural language processing,a document representation method based on LDA-TF-IDF and Word2vec is proposed.Firstly,the data set is preprocessed by word segmentation and stopping words.Secondly,the LDA topic model and TF-IDF are used to extract the characteristic words in the document,and the corresponding weight is calculated.Finally, the data set is used to train the Word2vec model to obtain word vectors,and the extracted feature word weights are integrated into Word2vec word vectors to construct document semantic vectors.The proposed method is verified by a classification task.The experimental results show that the proposed method performs better on the spam SMS data set than the existing methods,which verifies the effectiveness of the proposed method.
Key words: LDA topic model;TF-IDF;word2vec;document representation
