
基于改进模糊聚类算法的数据信息分析与预测模型设计
2023-08-19 09:59高楚淮
电子设计工程 2023年16期
高楚淮
(河北北方学院附属第一医院,河北 张家口 075000)
随着药品生产供应市场的发展,建立安全完备的药品研制、生产及流通体系势在必行。当前我国的医药市场主体依然呈现出“多、散、小”的格局,且药品的基础资料多为非结构化数据,故仍存在信息统计与查询困难的问题。而如何运用大数据平台进行药品信息的分析,并实现准确的分类及预测,对药品流通的所有参与者而言均具有重要意义。对于监管者,其可建立行之有效的安全风险防范体系;而对于医疗机构,则能优化供应链管理水平,进而逐步实现运行模式的优化[1-4]。
聚类分析(Cluster Analysis)是数据挖掘领域的常用算法,近年来基于划分、层次与密度分析等思路,该算法得到了进一步的发展[5-11]。其中,模糊聚类(Fuzzy C-Means,FCM)算法是一种基于模糊数学理论的机器学习(Machine Learning,ML)算法。与其他聚类算法不同的是,其引入了隶属度函数,增添了样本类别的非定性描述,使得物体与客观世界建立了更为契合的映射关系。此外,该方法无需训练样本,是一种无监督的聚类方法,并可自动提取药品信息中的特征,进而实现样本的自主分类。文中在对常用的、基于目标函数的模糊聚类分析算法进行讨论的基础上,结合医药数据信息分析的应用场景对该算法加以改进。仿真结果表明,改进后的算法在对药品数据进行聚类预测时,关键性指标有了显著改善。
1 理论基础
1.1 传统模糊聚类算法
基于目标函数的模糊C 均值聚类(FCM)算法是模糊集理论中常用的数据分析方法[12-14],其结构简单且计算复杂度较低,并可对样本数据进行自动分类。FCM 算法的基本流程如图1 所示。
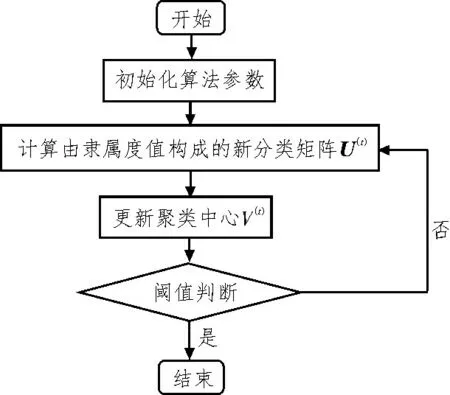
图1 传统FCM算法流程
1.2 改进模糊聚类算法
传统的FCM 算法虽应用广泛,但其在对药品数据资源进行分析时,对初始值较为敏感,导致收敛速度较慢,且在迭代过程中易陷入局部最优,影响了数据分析及预测的精度。因此,文中将继续对FCM 算法进行改进[15-16]。改进的算法流程如图2所示。
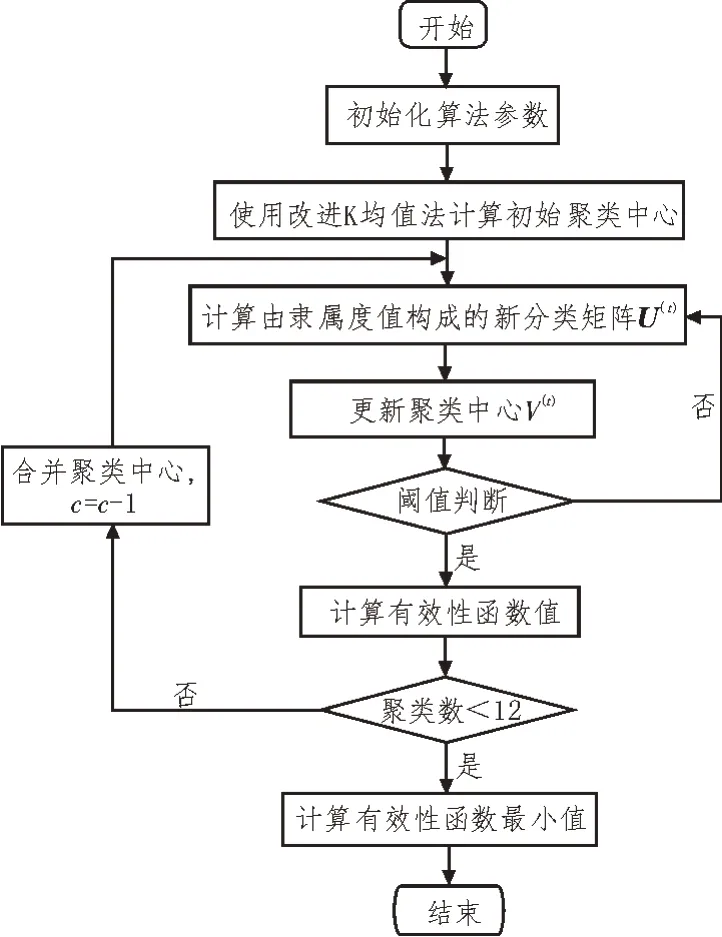
图2 改进的FCM算法流程
首先使用K 均值法(K-means)计算初始聚类中心,具体表达式为:
采用二维空间内所有对象到样本中心的平方差之和,作为K-means 的误差判别E,而p为输入样本在二维空间的映射,mi则为Ci的聚类中心。引入该方法后,能够有效提升FCM 的聚类中心初始化效果。
此外,为了度量FCM 算法的聚类效果,文中还引入了一种基于信息粒度的有效性函数。信息粒度可表征类间样本的耦合性,且其主要包含耦合度Cd(c)和分离度Sd(c)两个概念。其计算公式分别为:
基于式(2)-(3),可得到度量聚类效果的有效性函数为:
式(4)中,α为耦合度和离散度间的权重调节因子。
根据图2 的流程,改进后的FCM 会根据有效性函数GD 对分类效果进行判别,使得类内样本间的距离尽量缩小,而类别间的聚类中心间距则尽可能扩大。其中,类别间聚类中心的距离判别方法如下:
此外,为避免数据噪声对模糊矩阵隶属度的判别造成影响,文中还对目标函数进行了改进:
式(6)中,ηi为松弛因子,其降低了原损失函数对隶属度的约束。该参数的表式如下:
其中,K为常数。则改进后的FCM 算法参数更新方法如下:
2 方法实现
2.1 仿真实验设计
为了评估改进后的模糊聚类算法性能,文中筛选了某药品信息库中的部分药品作为数据集。具体的数据集参数为:样本总数有450个;药品类别有3种;每类样本个数为150 个;药品特征参数有8 个。
在评估改进后的聚类方法对于药品的聚类分析效率时,使用了均方根误差(SRMSE)作为评价指标。其定义方式如下:
其中,Dp(x,y)为聚类后样本在二维空间内的位置坐标,c(x,y)是数据集中实际聚类中心的位置坐标,N则为该类药品的样本总量。
在进行仿真分析时,文中结合样本规模对改进FCM 算法的参数进行了设置,如表1 所示。

表1 算法仿真过程中所用参数的设置
此次所使用的仿真软硬件环境为:CPU 为i7-10750H;硬盘规格为1 TB 7200 rpm;系统内存16 GB,操作系统为Windows10。显卡采用P620,显存4 GB,编程环境为Matlab 2019b。
2.2 算法仿真结果
为了评估算法的改进效果,将其与传统模糊聚类方法进行了比较。两种算法的迭代曲线如图3所示。
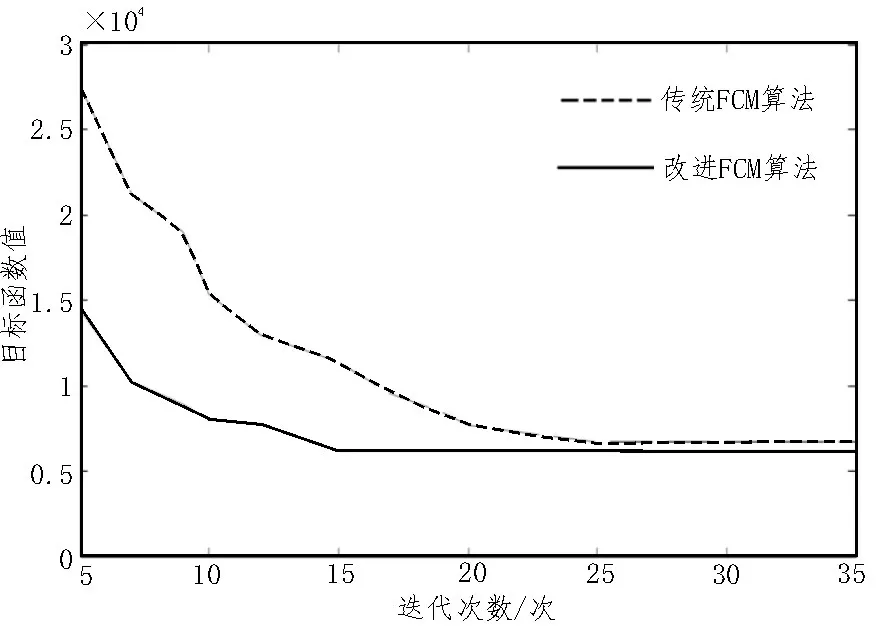
图3 算法迭代曲线
图3 显示了算法在迭代过程中,目标函数随迭代次数的变化情况。从图中可以看出,传统算法在进行25 次迭代之后,目标函数值才趋于平稳;而该算法的目标函数值仅迭代15 次便趋于稳定,且迭代效率提升了约40%。由此可知,与传统FCM 算法相比,改进算法的目标函数收敛速度较快。
根据实际的算法应用场景,在对药品数据进行聚类分析前,由于类别数量c并非确定值,故还需根据算法的有效性函数值来确定。表2 给出了在仿真过程中,将数据集划分为不同类别时的算法有效性函数值。可以看出,当c=3 时,算法能够得到最优的有效性函数值,约为0.421 3,而该类别数也与数据集的实际类别数相一致。
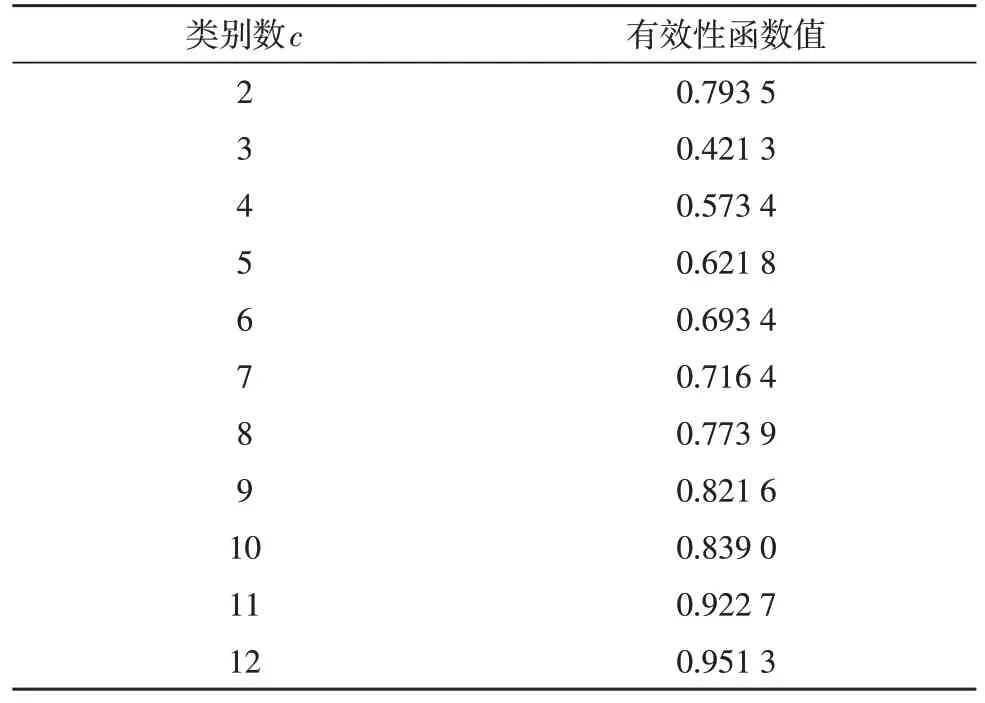
表2 不同类别数所对应的有效性函数值
对数据集进行聚类仿真实验,得到的结果如图4所示。
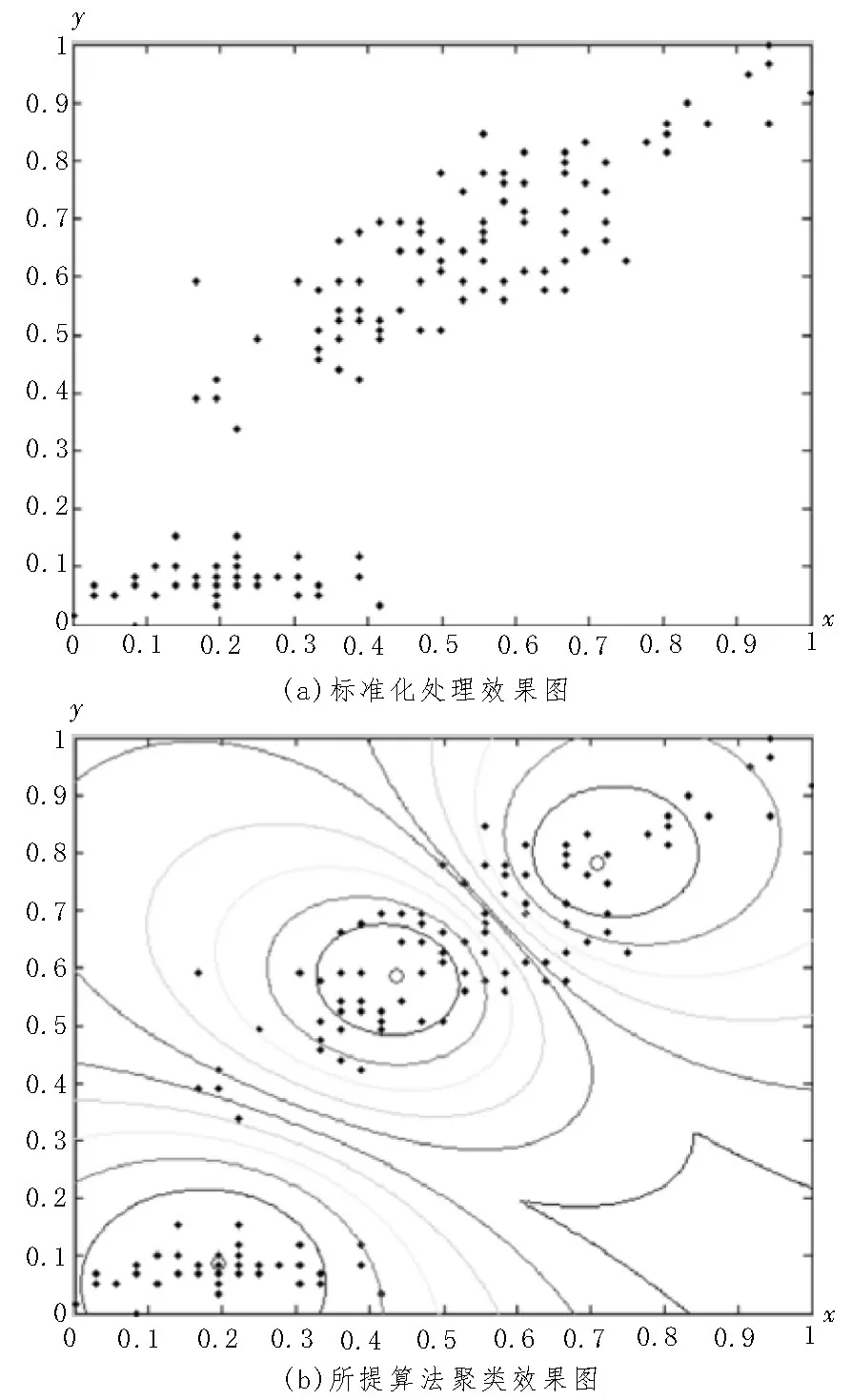
图4 算法的样本分类效果图
图4 中,将表1 的数据集进行标准化处理,并映射至二维空间,即可得到图4(a)所示的效果图;而对图4(a)中的数据使用文中算法进行聚类,获得的效果如图4(b)所示。在图4(b)中,空心圆圈为实际的聚类中心,圆弧线则为类别的边界。从图4(b)可以看出,圆弧线将所有的样本划分为3 类,且各个类簇之间并未存在交叠的现象。由此证明所提算法能对数据集中的所有数据进行明确分类。
对于聚类算法,首先要将一堆无序的数据划分为正确的类别。表3 给出了算法在50 次运行过程中,能将实验数据正确划分为3 类的统计结果。由表可知,该算法的正确率为94%,相较于传统算法,提升了8%;而平均运行时间降低至201 s,在传统算法的基础上缩短了27.17%。
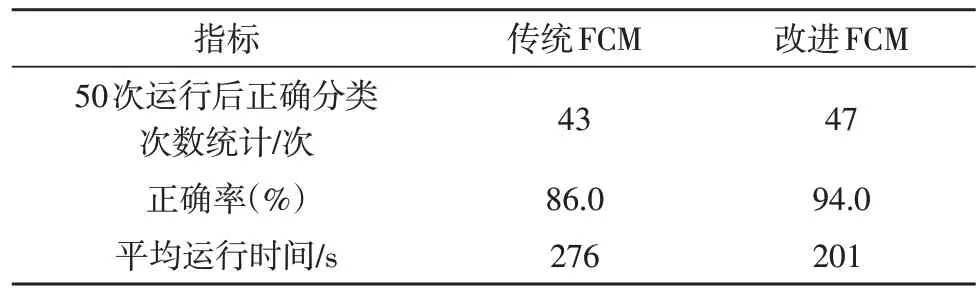
表3 算法聚类性能对比
表4 统计了在类别数c=3 时,所有样本的分类精度情况。对于450 个测试样本,该算法的误分类数量为23,分类错误率为5.11%,RMSE 值为0.032 1。且相较于传统FCM 算法,其错误率下降了5.56%,RMSE 值则降低了79.61%。

表4 算法分类精度性能对比
3 结束语
文中对药品的聚类分析与预测方法进行了研究,通过引入新的聚类中心初始化机制及有效性函数改进了传统的FCM 方法。仿真结果表明,该算法对于聚类中心与样本的分类精度均有显著改善。而随着我国医药领域数字化进程的推进,所提算法将会有更为广阔的应用前景。
猜你喜欢
中国合理用药探索(2022年1期)2022-11-26
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
中国卫生(2016年5期)2016-11-12
新校长(2016年8期)2016-01-10
中国卫生(2015年5期)2015-11-08
电子设计工程(2015年6期)2015-02-27
中国卫生(2014年7期)2014-11-10
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
