
基于自然语言处理的医疗问答系统研究与实现
2023-08-21 04:19谢崇波
现代信息科技 2023年12期


摘 要:针对民生的医疗健康大数据,运用知识图谱构建医疗知识图谱,通过F1值比较,在知识图谱构建的知识抽取阶段采用Bert模型自然语言处理算法,而关系抽取阶段采用基于注意机制的卷积神经网络(Att-RCNN),通过上述两种算法将建立好的知识图谱存储于图存储引擎Neo4j中;其次,为了系统能够识别用户的意图,通过F1值比较,最终采用BERT-TextCNN算法模型处理用户意图识别和槽位匹配;最后,利用Django框架搭建后端,前端采用微信接口实现用户与该系统的交互。
关键词:知识图谱;自然语言处理;智能问答系统;深度学习
中图分类号:TP312 文献标识码:A 文章编号:2096-4706(2023)12-0001-06
Research and Implementation of Medical Question Answering System Based on
Natural Language Processing
XIE Chongbo
(Sichuan Vocational College of Information Technology, Guangyuan 628040, China)
Abstract: Aiming at the big data of medical and health care of the people's livelihood, the knowledge graph is used to construct the medical knowledge graph, and through the F1 value comparison, the Bert model natural language processing algorithm is used in the knowledge extraction stage of the knowledge graph construction, and the convolutional neural network (Att-RCNN) based on the attention mechanism is used in the relation extraction stage. Through the above two algorithms, the established knowledge graph is stored in the graph storage engine Neo4j. Secondly, in order for the system to recognize the user's intention, through the F1 value comparison, the BERT-TextCNN algorithm model is finally used to process the user's intention recognition and slot matching. Finally, the Django framework is used to build the back-end, and the front-end uses the WeChat interface to realize the user's interaction with the system.
Keywords: knowledge graph; natural language processing; intelligent question answering system; Deep Learning
0 引 言
人工智能技术的发展带来各种科学技术革新,引领着各种智能交互方式的发展,“人工智能+”(即AI+)的概念也渐入人心。作为民生问题之一的医疗健康,在人工智能技术推动下衍生出“AI+医疗”[1]的新模式及新交互方式——自动问询系统。
目前,自动问询系统的构建存在以下几个问题:1)互联网医疗诊断问询大数据语料信息具有海量、异构、动态的特性且主观性强,导致信息缺乏系统性、针对性,难以根据具体患者和客户给出系统性、针对性的问询。再者,市面上缺乏开源且高质量的医疗语料数据。2)用户问询的语义抽取及解析需要自然语言算法建模来进行有监督学习,而医学成本高,大量的手工标注数据,时间、精力和人力成本巨大[2]。3)海量且领域性强的医疗语料数据通过知识抽取算法进行进一步推理,还存在一定的提升空间[3]。4)早期根据检索和问答模版匹配来实现的问询系统,难以满足复杂场景需求。因此,需要运用语义解析技术实现用户意图识别。
针对上述问题,在结构化、半结构化和非结构化医疗语料大数据基础上,本课题选用知识图谱技术[4]构建医疗知识图谱。知识图谱相比传统数据库,知识图谱一是能够灵活地将多种来源的语义数据有效地组织成一张具有极强表达能力的语义网络,解决了医疗语料数据的异构和不规则性,为后续知识推理[5]和意图识别的工作奠定基础;二是在知识图谱知识抽取和知识推理阶段,采用基于深度学习的抽取、推理方法,可在已有知识图谱或者无标注语料基础上进行对齐和自动化标注,逐渐达到扩充知识图谱目的,有效地解决了医疗语料数据量大而带来的各种成本问题。
在医疗知识图谱构建完成的基础上,为达到问询功能,亟待解决用户意图识别。本课题采用当下流行的自然语言处理算法基于Transformer双向编码表示的(Bidirectional Encoder Representations from Transformers, BERT)模型[6]实现知識抽取、语义解析和意图识别任务。BERT算法模型相较于传统自然语言处理算法不仅可以学习句子左右两边的上下文信息,而且获取上下文的句子的距离也更远,可更好地满足处理复杂的语义解析场景。
因此,本课题通过数据爬虫技术[7]获取百度百科、丁香网、寻医问药网等网站的医疗语料数据,在此基础上构建医疗知识图谱,奠定问询系统的数据基础;其次,利用自然语言处理技术进行用户语义解析和意图识别;再者,问询系统的交互离不开后端的支持,本课题采用Django/Flask框架[8]开发问询系统的后台;最后,前端将使用微信进行交互。至此,医疗问询系统架构图构建完成,如图1所示。
1 知识图谱技术
1.1 知识图谱定义
知识图谱概念于2013年由谷歌提出,其本质是揭示万物之间关系的语义网络。知识图谱旨在从多种类型复杂、碎片化的数据中抽取概念、实体和关系,再通过知识融合建立以上三者的可计算体系模型。按照知识的覆盖范围和领域的不同,知识图谱整体可以划分为通用性知识图谱和领域性知识图谱。
知识图谱通用形式为知识图谱=(实体,关系,实体),即G=(Entityhead, Relation, Entitytail),为了便于区分,前者为头实体,即Entityhead;后者为尾实体,即Entityhead;而夹在两者之间为实体之间的关系,即Relation。其中,Entity = [Entity1, Entity2, …, Entityn]表示实体的集合,其包含了n种实体的概念Relation = [Relation1, Relation2, …, Relationn]表述实体之间的关系集合,其包含了n种不同的关系。
1.2 知识图谱构建技术路线
医疗知识图谱构建流程,如图2所示,大致分为5个部分:1)数据源获取。2)知识抽取,即在各个数据源中自动或半自动的抽取实体间关系,主要包含实体抽取、关系抽取、属性抽取等任务。3)知识融合,即建立异构本体或异构实例之间的联系,使从不同知识源中抽取的知識整合在同一框架下,且异构的知识图谱间能够互操作,主要包含框架匹配(对概念、属性、关系等进行匹配和融合,如对不同来源的病的别名、症状等属性进行融合等)和实体对齐[9](判断两个知识库中的两个或几个实体是否表示同一对象,通过对齐合并相同的实体完成知识融合[10])。4)知识推理,又叫知识计算,即从建立好的知识图谱中推理出实体或者实体间的关系,如本课题根据用户问题推断出意图等。5)知识应用,即将建立好的图谱应用到相应的垂直领域中。
综上所述,本课题关于利用自然语言技术实现医疗知识图谱的构建,在自然语言处理模块主要涉及的有意图识别(意图归纳、意图分类模型)和槽位填充(语义槽设计、命名实体识别和实体链指)。构建完成的知识图谱存储在Neo4j中,然后运用Python语言实现前后端的交互问询。
2 知识图谱构建
2.1 实体抽取
知识抽取包含实体抽取(命名实体识别)和关系抽取。实体抽取的方法分为3类:基于传统规则和模板、基于统计机器学习和基于深度学习的知识抽取。
目前,基于深度学习的知识抽取因其实现了实体抽取的自动化和解决了特征提取误差传播的问题,该方法在实际应用中取得效果显著。基于此,本文也将几种基于深度学习的方法应用于本项目自建的数据库,通过F1值和Acc选取合适的实体抽取方法,F1值和Acc如式(2)和式(3)所示。具体的方法评测值,如表1所示。
其中,Acc表示精确率,Recall表示召回率(R),n表示识别正确的实体数,m表示识别出的虚假实体数,l表示丢失的实体数。
根据表1可知,在自建数据库上基Trans-former的BERT模型表现较好,F1值为93.2。因此,本课题选用BERT模型作为实体抽取方法。
2.2 关系抽取
关系抽取方法大致分为三类:基于传统规则和模板、基于统计机器学习和基于深度学习的关系抽取,基于深度学习的关系抽取是近年来研究的热点。该方法分为流水线方法[15]和实体关系联合抽取方法[15]。本项目选取的方法为流水线方法。如表2所示,近几年流水线方法的关系抽取效果,通过F1的值来衡量。
如表2所示,在公共数据集SemEval-2010数据集上基于注意机制的卷积神经网络(Att-RCNN)[16]取得更好的效果。同时,在自建数据库上该方法也获得了较为理想的F1值。因此,在本项目中采用的关系抽取模型为Att-RCNN,即基于注意力机制的卷积神经模型。
综上所述,知识图谱最重要的实体抽取和关系两个过程算法模型已选取完成,基于BERT模型和Att-RCNN模型建立了一个医药知识图谱,存储在neo4j中,如图3所示的部分医疗知识图谱。
在实体抽取和关系抽取中,将要抽取的语料库分为训练集、开发集和测试集,并得到最终的F1值,实体类型概览表,如表3所示。
如表3所示,本课题整理了约5.3万条和7个类型的实体类型,基于此5.3万条实体类型从中抽取实体关系,如表4所示。
如表4所示,本课题最终确定了10个类型,约27万多条实体关系。根据实体类型和实体关系给出了属性类型,如表5所示。
3 意图识别和槽位填充
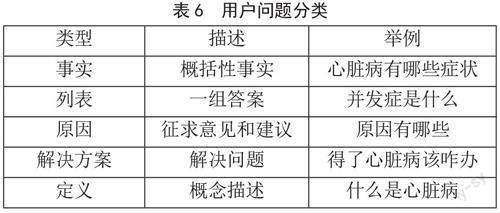
基于上述已将医疗知识图谱建立完成,由于知识问答系统需要通过用户的问题从知识库中获取答案,最终以自然语言形式返回给用户。所以,整个过程需要解决两个问题:1)用户的意图识别。2)意图识别后与知识图谱中的知识建立映射。本课题将问题进行了一个分类,即可将用户意图的问题进行分流,如表6所示。
为了解决上述两个问题,需要用的技术是语义解析和槽位填充。这两种方法都是基于深度学习的方法,在实际应用中由于关联性太强,所以一般采用来联合训练方法。本课题中采用BERT预训练模型和深度卷积神经网络TextCNN来进行语义解析和槽位填充的任务。
基于BERT预训练-TextCNN模型[17]分为两个步骤:
1)在预训练BERT模型基础上,利用多层双向的Tran-sformer编码器进行训练所有标记化文本,输出文本语义特征向量;2)将第1步中文本语义特征向量输入到TextCNN模型中进行监督式训练,最大程度提取文本序列中不同抽象层次的语义信息,最终得到文本高层特征向量。整个过程如图4所示。
BERT-Text模型如图4所示,其中X = {x1, x2, …, xn}为医疗问句,T1, T2, …, Tn为Transformer输出的文本特征向量,y1, y2, …, yn为文本高层特征向量。
将上述模型应用到本课题的意图识别和槽位填充上,并且与Word2Vec-TextCNN[18]模型做对比,结果如表7所示。
从表7可以得出,BERT-TextCNN模型适合本课题的意图识别和槽位填充。
4 医疗助手的设计与实现
本项目由图谱构建、数据存储和智能助手三个模块组成,图谱构建模塊利用多种数据源抽取医学知识并以此构建知识图谱;数据存储模块利用图存储引擎Neo4j来存储知识图谱信息;智能助手负责用户的交互,通过意图识别和槽位填充实现问答功能。整个系统构建流程,如5所示。
上述已经将图谱构建模块、数据存储模块构建完成,接下来,将继续介绍智能助手的设计与实现。智能助手的设计与实现,如图6所示。
根据图6的构建图,利用微信搭建出医疗问询系统。为了测试系统准确性,本课题测试1 000条数据,其中有903条达到用户需求,测试结果达到较高准确性,如图7所示。
与此同时,本课题也测试了微信接口,结果如图8所示。由图可以看出,系统较好地响应了用户的问题。
5 结 论
本项目利用知识图谱技术和自然语言技术实现医疗智能问询系统,知识图谱技术解决数据结构问题,自然语言技术解决知识图谱的知识抽取、关系抽取、意图识别和槽位填充的问题,虽取得了较好的精确性,但本项目在关系抽取、多轮对话和知识图谱的泛化性上还有待提高。
参考文献:
[1] 程国华.“AI+医疗”时代,我国医疗服务砥砺前行 [J].张江科技评论,2020(4):52-53.
[2] 金朋.意图识别与槽位填充关键技术研究 [D].哈尔滨:哈尔滨工业大学,2021.
[3] 张吉祥,张祥森,武长旭,等.知识图谱构建技术综述 [J].计算机工程,2022,48(3):23-37.
[4] 杭婷婷,冯钧,陆佳民.知识图谱构建技术:分类、调查和未来方向 [J].计算机科学,2021,48(2):175-189.
[5] 封皓君,段立,张碧莹.面向知识图谱的知识推理综述 [J].计算机系统应用,2021,30(10):21-30.
[6] YU G H,ZHANG Z X,LIU H,et al. Masked Sentence Model Based on BERT for Move Recognition in Medical Scientific Abstracts [J].Journal of Data and Information Science,2019,4(4):42-55.
[7] 罗安然,林杉杉.基于Python的网页数据爬虫设计与数据整理 [J].电子测试,2020(19):94-95+31.
[8] 徐秀芳,夏旻,徐森,等.基于Django的校园疫情防控系统设计与实现 [J].软件导刊,2021,20(2):24-30.
[9] 杨秀璋,彭国军,李子川,等.基于Bert和BiLSTM-CRF的APT攻击实体识别及对齐研究[J].通信学报,2022,43(6):58-70.
[10] 马忠贵,倪润宇,余开航.知识图谱的最新进展、关键技术和挑战 [J].工程科学学报,2020,42(10):1254-1266.
[11] YAN H,DENG B C,LI X N,et al. TENER:Adapting Transformer Encoder for Named Entity Recognition [J/OL].arXiv:1911.04474 [cs.CL].[2022-11-05].https://arxiv.org/abs/1911.04474v3.
[12] DEVLIN J,CHANG M W,LEE K,et al. BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding [EB/OL].[2022-11-05].https://arxiv.org/pdf/1810.04805.pdf.
[13] 曾青霞,熊旺平,杜建强,等.结合自注意力的BiLSTM-CRF的电子病历命名实体识别 [J].计算机应用与软件,2021,38(3):159-162+242.
[14] LUO X,XIA X Y,AN Y,et al. Chinese CNER Combined with Multi-head Self-attention and Bi LSTM-CRF [J].Journal of Human University:Natural Sciences,2021,48(4):45-55.
[15] 姜天文.条件性知识图谱构建及其应用研究 [D].哈尔滨:哈尔滨工业大学,2021.
[16] GUO X Y,ZHANG H,YANG H J,et al. A Single Attention-Based Combination of CNN and RNN for Relation Classification [J].IEEE Access,2019,7:12467-12475.
[17] 郑承宇,王新,王婷,等.基于ALBERT-TextCNN模型的多标签医疗文本分类方法 [J].山东大学学报:理学版,2022,57(4):21-29.
[18] KIM Y. Convolutional Neural Networks for Sentence Classification [J/OL].arXiv:1408.5882 [cs.CL].[2022-11-10].https://arxiv.org/abs/1408.5882v2
作者简介:谢崇波(1992—),男,汉族,陕西汉中人,助教,硕士,研究方向:深度学习、自然语言处理。
收稿日期:2022-10-12
基金项目:四川信息职业技术学院校级课题(2022C18)
猜你喜欢
计算机应用(2016年12期)2017-01-13
新教育时代·教师版(2016年23期)2016-12-06
智富时代(2016年12期)2016-12-01
智富时代(2016年12期)2016-12-01
法制与社会(2016年32期)2016-12-01
中国远程教育(2016年9期)2016-11-19
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
中国教育信息化·基础教育(2016年9期)2016-10-18
电脑知识与技术(2016年10期)2016-06-16
