
基于遗传算法的银行智能排班系统设计
2023-08-21 11:02夏天舒李宇豪宣明辉林新雨
现代信息科技 2023年12期
关键词:遗传算法
夏天舒 李宇豪 宣明辉 林新雨

摘 要:银行的客服中心、作业中心、业务中心及网点都需要进行人员的排班管理,然而在目前银行的排班管理环节,排班编制的工作主要通过人工以手动方式进行,最终生成值班表,效率较低。针对此问题,文章通过遗传算法模拟了银行排班的流程,以银行员工的真实数据作为仿真实验的数据,经过试验发现,针对排班制定的优化算法与思想是具有推广意义的。
关键词:排班编制;智能排班;遗传算法
中图分类号:TP18;TP311.5 文献标识码:A 文章编号:2096-4706(2023)12-0128-06
Design of Intelligent Bank Scheduling System Based on Genetic Algorithm
XIA Tianshu, LI Yuhao, XUAN Minghui, LIN Xinyu
(Sunyard Technology Co., Ltd., Hangzhou 310053, China)
Abstract: The customer service center, operation center, business center, and branch of a bank all require personnel scheduling management. However, in the current scheduling management link of a bank, the work of scheduling is mainly done manually, ultimately generating a duty table, which is inefficient. In response to this issue, this paper simulates the process of bank scheduling using genetic algorithms, using real data of bank employees as the data for the simulation experiment. After the experiment, it is found that the optimization algorithms and ideas developed for scheduling have promotional significance.
Keywords: scheduling; intelligent scheduling; genetic algorithm
0 引 言
銀行在金融市场中占据重要位置,对经济发展有着重要的意义。中国改革开放以来,银行业务的发展越来越繁荣,银行业务量提升,一方面提高了银行的经济效益,另一方面,银行的工作压力也不断增加。不同的银行机构都将技术改革和管理等作为研究的重点,目的是提升其管理水平,为群众提供更好的服务。大部分银行在开展其业务的过程中,都会存在由于业务高峰量大而缺乏人员的情况,使得客户等待时间过长;相反的,在银行业务量不大时,人员闲置情况明显。上述情况,对银行而言,从人力和物力方面都是一种极大的浪费,资源的配置有待提升。
虽然我国的大部分银行都将技术与管理方法的改革作为目前的重点,然而,实际工作环节中,问题依然十分明显。对于管理弹性排班工作而言,人工依然是主要的工作方法,通过手动的形式,生成值班表。这是一种缺乏效率的方式,与此同时,银行的业务会不断发生变化,修改排班的情况经常发生。并且,排班工作会随着新周期的开始而重新编制,由于该工作周期短,对人工的消耗十分巨大。所以,本系统将排班管理工作进行弹性设计,这一系统的目的主要是针对排班工作中出现缺乏灵活性和效率的问题,
1 银行排班系统建设的意义
对于银行业务的处理而言,业务量大、缺乏资源等是目前银行部门面临的主要问题,这对于银行的经营发展产生了巨大的影响。
从当前大部分银行在对弹性排班进行管理的角度出发,本系统针对智能排班和资源管理进行设计,目的是对于当先在排班管理的过程存在的缺乏效率问题予以解决,从理论与现实的角度来讲,都有着重要的意义:
1)在排班工作方面,银行的效率十分低,而设计本系统对于这一问题的解决具有重要作用,能够促进银行业务的发展,使得银行的资源配置更加合理,保障客户服务水平,对于中国经济的发展与稳定有着重要作用。
2)本系统能够对工作效率的提升,工人压力的降低有着重要的作用,能够在人工方面缩减银行成本,提高银行的经济效益,对于银行业务水平的提升意义重大。
3)从理论的角度来讲,银行排班算法可以关联到退火算法、蚁群算法、遗传算法等,从该领域中,本设计具有一定的参考价值。
2 针对网点柜员排班需求的系统解决方案
排班管理系统的服务对象包含总行与分行,主要服务内容有管理排班规则、周期排班、柜员缺口查询、班表发布查询等组成。除此之外,其展示的界面十分友好,设置的排班网点灵活多变,排班的要素与管理健全。
2.1 网点柜员排班系统架构
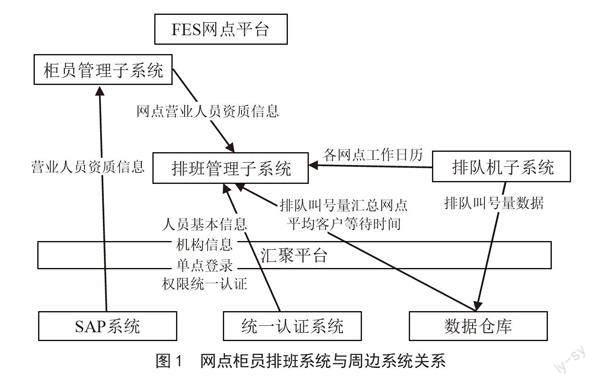
通过前面提供的需求,排班系统的排班要求来源于周边不同的系统,以排班规则为基础,对排班进行合理的计算。我们分析目前银行周边的系统情况,将系统之间的关系进行整理,如图1所示。
在排班系统中,网点柜员主要以柜员信息和机构信息为操作客体,在经过一致认证的平台中,实体网点的柜员信息和机构是其基础。
在排班系统中,银行网点系统(Front End System, FES)是客户端的最终集成点。在银行的网点系统中,将登录的模块功能用作其登录画面,其控制权限的功能被用于系统的权限管理。其后台中的独立系统则是排班系统的服务端,由专门的服务器用于部署。
在排班管理系统中,银行网点在跑批下,其网点柜员的资质证书、人员资质证书等都可以被管理系统获取,对跑批的设计时间为每天跑批。
在银行的网点系统中,该网点的工作日与休息日都被其排队机子系统所收录,而在排班管理系统中,其排班要素也需要依托这些信息为基础。所以,上述信息也会在系统跑批下而被获取。
2.2 网点柜员排班系统主要功能
在网点的管理系统中,其功能主要包含四个方面,即设置网点排班、发布网点排班、统计查询班表、系统日志,详情如表1所示。与此同时,人员信息、叫号量等信息也收录在系统中,其获取的渠道都来自交易接口,或者通过参考数据获取。
2.3 应用架构设计图
在上述系统结构以及相关需求的基础上,网点的柜员排班管理系统所包含的主要功能包括以下几个方面:
1)排班设置:在设置规则方面,其级别可以划分为三级,即总行、分行(区域支行)网点支行三个级别。在总行中,其用户类型设置为全行统一;分行则对柜员池和排班规定进行设定;网点则主要对柜口、排班人员、休息制度等规则进行设置。
2)排班和发布:网点进行排班的过程中,意向休息日先通过柜员进行登记,作为排班的优先条件,之后排班向导开始分别排班,排班内容由设置工作柜口、在系统已有规则的基础上完成排班、人工调整核验、申请柜员池、发布排班信息等项目组成,发布排班信息后可以重复修改发布。
3)班表查询:对网点班表具有查询权限的人员包括总行、分行、网点人员,查询的维度包括员工与类型,与此同时,分行对于人员的调派、排班存在的缺口等,都可以进行查询。
2.4 重点业务功能设计——网点排班向导
在设计业务功能的过程中设计了“向导”模式,网点排班系统中,管理员可以通过向导设置的五个步骤进行操作:设置网点工作柜口;对营业人员进行分配和预排班;校验排班规则;申请柜员池;发布排班表。
3 排班过程
3.1 排班模块分析
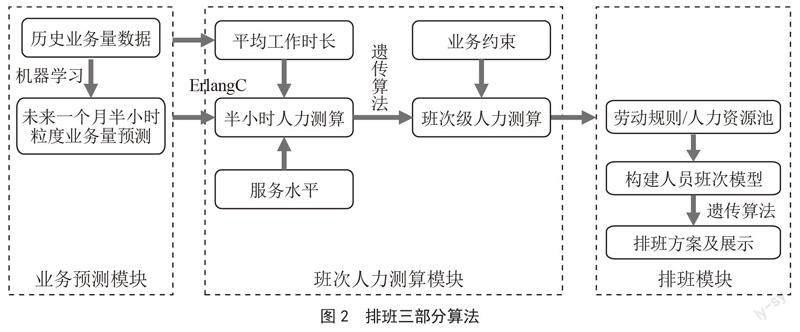
排班算法通常分为三个部分:业务量预测算法、人力测算算法和运筹排班算法。如图2所示。下面分别描述。
3.2 業务量预测
业务量预测主要是做元数据的统计、预测及预测模型训练。预测相关算法利用机器学习算法预测未来一段时间内的业务量数据,通过历史数据构建系列时序特征然后训练模型,然后进行预测,并根据预测的业务量来估算每天需要的人力安排,减少人力成本,能为规划业务的发展提供重要支撑。
3.3 模型构建
根据数据量,数据规律,确定最终算法,用于回归预测的主要是基于树模型预测,如GBDT、XGBoost等机器学习算法。
3.3.1 GBDT
GBDT(Gradient Boosting Decision Tree)算法如表2所示。
实现过程为:
1)初始化f0 (x) = 0
2)对m = 1, 2, …, M
计算残差:
rmi = yi = fm - 1(xi_).i = 1, 2, …, N
拟合残差rmi学习一个回归树,得到T(r:Φm)
更新fm(x) = fm - 1(r) + T(r:Φm)
3)得到回归问题提升树
3.3.2 回归树
回归树算法(最小二乘回归树生成算法)的实现原理如图3所示。
输入:训练数据集D;
输出:回归树f (x)。
在训练数据集所在的输入空间中,递归地将每个区域划分为两个子区域并决定每个子区域上的输出值,构建二叉决策树。
1)选择最优切分变量j与切分点s,求解Minj, x [mincΣxεR1 ( j, s) ( yi - Ci)2 + minc2ΣxεR2( j, s)( yi - C2)2]
遍历变量j,对固定的切分变量j扫描切分点s,选择使上述表达式达到最小值的对( j, s)。
2)用选定的对( j, s)划分区域并决定相应的输出值:
R1( j, s) = { x| x∽≤s},R2( j, s) = { x | x∽>s}
3)继续对两个子区域调用步骤(1)(2),直至满足停止条件。
4)将输入空间划分为M个区域R1, R2,…, RM,生成决策树。
算法优势:GBDT决策树的提升建立在中文梯度的基础上,是最适用于真实分布拟合的算法,GBDT是经过了好几轮的迭代更新,在这一更新过程中,产生若干弱分类器,每个分类器都为下一轮分类器的训练提供残差基础。对弱分类器而言,通常没有复杂的要求,并且高偏差与地方差并存,在训练过程中,偏差不断降低,分类器的精度也断得到提升。相较于弱学习能力的机器学习模型和参数复杂、内在原理黑箱的神经网络而言,利用最少的参数、最低的性能就可达到优秀的模型表现,且对于模型预测结果清晰且易解释。
3.3.3 业务量预测
业务量预测是根据历史数据对未来一段时间内的业务发生情况进行预测,通常需要把历史数据分成训练集和验证集,根据预测误差来收敛算法。如图4所示,预测误差必须收敛到可接受范围内,才可实现对未来业务量的精确预测。
3.3.4 人效转换
对于投入同样多的人力的情况下,不同的业务量所产生的服务水平是不同的。如图5所示,针对不同的业务量规模,需要配置对应的人力,才能达到相同的服务水平。
3.3.5 排班规则
在人工排班的情况下,排班规则往往五花八门很不规范,但一旦需要用运筹算法来实现,各类规则就必须能用表达式的方式来描述。如表3所示,各种规则需要分类,并排定优先级。
3.3.6 运筹排班算法示例
遗传算法:根据达尔文的生物进化论,模拟遗传学机理与自然选择的生活进化过程,在对自然进化过程进行模拟的过程中,寻找一种最优方案。实现过程如图6所示。
以50人,一个月(30天),10个班种的排班需求为例:
变异:染色体原料经过筛选之后,对染色体中的基因片段进行随机选取,然后进行变异操作。如图8所示。
当排班规则较多时,规则间可能发生冲突,此时需对规则设定优先级,以优先满足优先级较高的规则。通过规则满足率排查工具,在输出排班班表的同时,快速排查未被满足的规则,并定位到具体的人/天/班种,以方便后续手工调整。
3.3.7 排班结果输出
最终,在获得若干满足排班规则要求的排班方案中优选一种作为最终排班方案输出。如图9所示。
综上所述,智能排班能够通过算法帮助银行实现人员能效提升,优化劳动组合等目标。同时,利用智能排班搜集的数据、产生的数据及登记的数据,还可以对涉及的人员进行深度分析,包括工作能力、岗位匹配度、工作饱和度、人员配备合理度等。以呼叫中心为例:根据员工处理业务的效率,包括处理业务的平均时间、最大处理时间、最小处理时间、员工30 s应答率、回复率、无效话务量、处理业务量、在线时长、好评度等信息生成员工能力画像。根据画像,将员工能力分为高中初三个级别。
4 优化管理的保障措施
4.1 建立业务量预测事后验证机制
预测模型的建立并不能解决所有的问题,在业务量测定完成之后,要长期进行校准,将预测与实际数量之间进行对比,及时对预测中的各项不足进行完善,对客户来访的实际情况和预测值进行拟合度的测算,对准确率进行检测并进行合理的完善。通过预测模型的时候验证机制,使预测从发布到执行、到验证、再到优化形成完善的系统。与此同时,本系统还能够对实际数量与预测量进行检测和对比,从各个时段去发现之间的偏差,在以往经验的基础上,完善后期的预测,使得预测更具准确性。
4.2 排班优化环节和流程
排班系统在实际使用的过程中,需要持续对各个环节进行优化,以保证算法误差始终保持在可接受范围内。优化排班的环节:
1)针对短期业务量,在预测模板中输入排班计划。
2)针对不同时段内的误差与目标值作对比,净差为0是理想的最佳模式。
3)将排班以需求为前提做出合理的调整。
4)将线下培训与计划等做出合理调整,将不同时间段内的排班进行优化,具体如图10所示。
4.3 重新定位排班管理工作职责
首先是重视数据,及时做出总结。排班师的主要优势就是在数据方面的敏感性较高。对测算人力与业务量而言,数据积累是非常重要的前提,对于工作中出现的与运营有关的规律,排班岗需要及时总结。首先必须能够整体掌握年业务量,能够从总体上规划整年的人力水平。其次是以月和日为单位,对不同时段的业务量发展方向做出总结。在预测业务量方面也力求精准,以业务为前提,及时进行调整,使得预测更加准确。
其次是重视细节,对排班及时做出完善。业务量的变化是随时发生的,每个季度的变化都比较大,人员也与其离职率之间存在较大的关系,银行也会据此更新其考核指标,管理人员的工作重点也会相应地调整。排班管理工作要紧密联系中心指定的各项考核指标,针对不同省份的变化、营销业务的具体情况、外包人员的规模、目标设定的范围等,对排班的政策及时地做出调整,使排班表更加的优化。
5 结 论
本文选择银行员工的排班案例进行详细的分析,其本质是对条件得以满足情况下的优化排列组合。本文中的遗传算法对于传统遗传算法中存在的收敛过早问题做出了合理解决,实现了多样化种群,使最优解不再局限于某一部位,实现了全种群的最优化。本文測试采用的数据均来自银行员工,对模型与算法进行了验证,并且在问题解决方面也较为满意。为银行在排班方面的问题解决提供了可行性方案。
参考文献:
[1] 熊静.基于改进遗传算法的机场AOC人员智能排班研究 [D].广汉:中国民用航空飞行学院,2022.
[2] 王梦真,陈欢良.基于改进遗传算法解决多目标智能排班问题研究 [J].电脑知识与技术,2022,18(2):79-81.
[3] 王莹,张青,韦瑶,等.一体化智能排班软件系统的开发与应用 [J].协和医学杂志,2021,12(6):1030-1033.
[4] 陈庆丽,袁慧,梁付,等.护理中的智能排班——基于责任制护理的护士分组与自主月排班智能软件的开发与应用 [J].中国质量,2021(4):100-104.
[5] 周秀芬,胡琼.智能排班软件在水泥厂中的应用 [J].水泥工程,2020(S1):46-47.
[6]宋兵.管制员智能排班系统设计 [J].信息与电脑:理论版,2018(15):77-79.
作者简介:夏天舒(1970—),男,汉族,浙江杭州人,高级工程师,副总经理,本科,研究方向:银行运营监测系统、智能排班系统、智能运营管理系统、风险监测系统、运营数据分析平台、实时风险监测预警系统等。
猜你喜欢
测控技术(2018年2期)2018-12-09
石油地球物理勘探(2017年2期)2017-11-23
池州学院学报(2017年3期)2017-10-16
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
水利规划与设计(2016年9期)2017-01-15
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
现代计算机(2016年34期)2016-02-28
舰船科学技术(2016年1期)2016-02-27
智能系统学报(2015年4期)2015-12-27
