
基于知识表示学习的知识图谱补全研究进展
2023-09-25 08:54于梦波杜建强罗计根邱俊洋
计算机工程与应用 2023年18期
于梦波,杜建强,罗计根,聂 斌,刘 勇,邱俊洋
江西中医药大学计算机学院,南昌330004
随着人工智能时代的到来,知识图谱技术在知识表示与推理领域发挥着举足轻重的作用。知识图谱(knowledge graph,KG)可以理解为一种由节点和边组成的大型语义网络,也可看作一种基于图的数据结构。KG 通常以三元组(Eh,Rr,Et)的形式展现,其中Eh、Et分别表示头实体、尾实体,Rr表示两实体间的关系,每个三元组都代表现实世界中客观存在的事实,典型的知识图谱如Freebase[1]、YAGO[2]、Schema.org[3]等。知识图谱通过结构化的表示方式,可以清晰地表达出实体间的关系,具有易扩展、易理解、结构友好等优点,在学术界和工业界得到广泛应用。知识图谱早期主要用于搜索结果优化,随后知识图谱在系统推荐[4]、智能问答[5]、知识搜索[6]等领域发挥了重要作用。然而,现有知识图谱大都采用半自动化结合人工的方式构建,具有不完整性。Freebase 作为当今最大的通用知识图谱,其中71%的人物实体没有出生信息,75%的人物实体缺少国籍信息[7]。如图1所示,三元组(故宫,位于,北京)信息缺失,其增加了知识推理的难度,KG 中的知识不完全会对问答、推荐等任务产生极大影响,知识图谱的完善已成为极其重要的问题。
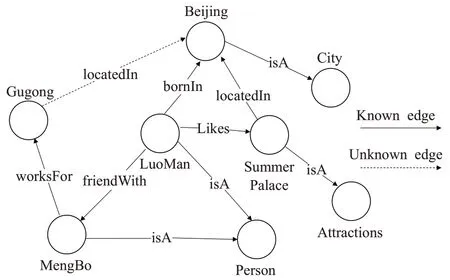
图1 两节点间存在缺失边的图谱示例Fig.1 Example of graph with missing edge between two nodes
为有效解决上述问题,不少研究者通过表示向量的形式在低维连续向量空间中学习实体和关系的嵌入特征,预测未知的三元组信息完成知识图谱补全(knowledge graph completion,KGC),该方法既能简化计算又能缓解数据稀疏的问题,有效提升KG的下游应用效果。
为此,本文将现有基于知识表示学习的KGC 方法进行整理和分类,总结现有的方法及相关研究成果,并对未来的发展方向做出合理的展望。本文的主要贡献如下:(1)对现有基于知识表示学习的KGC方法进行了较为全面的分类,根据KG 类型的不同,分为静态知识图谱补全(static knowledge graph completion,SKGC)、时序知识图谱补全(temporal knowledge graph completion,TKGC)以及多模态知识图谱补全(multimodal knowledge graph completion,MKGC)。(2)详细阐述三类KGC代表性模型的算法思想,并在拟解决的关键问题、设计思路、模型评价等方面进行对比总结。(3)列出三类KGC 代表性方法常用的数据集,以数据集WN18RR 和FB15K-237、ICEWS18 和ICEW14、FB15K-237-IMG 和WN18-IMG 为例,对相关KGC 模型在该三类不同数据集上的链接预测结果进行对比、分析和总结。(4)展望知识图谱补全未来的发展方向,为相关领域的研究人员提供参考。
1 知识图谱补全的任务定义
为了能够更好地理解KGC 任务,以符号表示的形式分别对静态、时序以及多模态知识图谱补全进行介绍。静态知识图谱被定义为SKG=(E,R,S),其中图谱中的实体集合E={e1,e2,…,eM}和关系集合R={r1,r2,…,rN},S={(ei,rk,ej)|ei ej∈E,rk∈R}⊆G={E×R×E} 代表图谱中的三元组集合,SKGC是指推理出不属于S但属于G的事实。由于融入时间信息,时序知识图谱被定义为TKG=(E,R,T,Q) ,其中图谱中的实体集合E={e1,e2,…,eM}和关系集合R={r1,r2,…,rN} ,时间戳(包含时间点和时间间隔)T={t1,t2,…,tL}(L为时间戳数量),Q={(ei,rk,ej,tl)|ei ej,rk∈E,R;tl∈T}⊆F={E×R×E×T}代表图谱中的四元组集合,TKGC是指推理出不属于Q但属于F的事实。从多模态知识图谱构建的角度看,多模态知识图谱被定义为MKG=(E,R,C,I,V),其中E、R、C、I、V分别代表实体、关系、文本描述、图像以及视频的集合,MKGC 是指从实体的文本描述、图像、视频等多模态信息中获取丰富的补充知识,以预测MKG中缺失的实体。通常真实世界中构建的知识图谱不完整,存在事实信息缺失的情况,知识图谱补全旨在通过预测出未知的事实信息,使得知识图谱更丰富、更完善,进而提升知识图谱的完整性。
链接预测(link prediction,LP)是一种预测KG中缺失事实的任务,旨在解决KG 的不完整问题[8]。具体来说,对SKGC 中给定的事实三元组(Eh,Rr,Et),存在以下三种情形,其一是(Eh,Rr,?)表示给定其中的头实体Eh和关系Rr来预测缺失的尾实体Et;其二是(?,Rr,Et)表示给定其中的尾实体Et和关系Rr来预测缺失头实体Eh;其三是(Eh,?,Et)表示给定其中的头实体Eh和尾实体Et来预测两实体间的关系Rr,然后再通过计算相应的评分函数来预测缺失事实成立的可能性。与SKGC 不同的是,由于引入时间信息,相应的三元组也扩展为四元组,TKGC 对于给定的事实四元组(Eh,Rr,Et,Tl),存在以下四种情形,其一是(Eh,Rr,?,Tl)表示给定其中的头实体Eh、关系Rr以及时间戳Tl来预测缺失的尾实体Et;其二是(?,Rr,Et,Tl)表示给定其中的尾实体Et、关系Rr以及时间戳Tl来预测缺失头实体Eh,其三是(Eh,?,Et,Tl)关系预测,其四是(Eh,Rr,Et,?)时间预测。MKGC 则是利用实体的文本描述、图像、视频等多模态信息来扩充实体和关系的语义信息,预测出MKG中缺失的实体。
2 静态知识图谱补全
静态知识图谱补全本质上是根据KG 中已存在的实体和关系去预测和补全缺失的三元组信息。按照拟解决问题的侧重点为分类依据,将其分为基于翻译模型的方法、语义匹配的方法、深度学习的方法三类。
2.1 基于翻译模型的方法
基于翻译模型的方法将KG 中的实体和关系转化到低维连续的向量空间中,并将关系视为该向量空间中的翻译操作,通过计算头、尾实体向量间的距离来衡量事实成立的合理性。Bordes等人[9]首先提出了TransE模型,认为不同实体类型间的一对一关系可以表示成嵌入向量空间中的计算。但TransE仅能有效处理简单的1-1关系,不能处理自反、一对多、多对一及多对多等复杂关系类型。为此,研究者在TransE的基础上提出了众多优化方法并进行有效扩展。
(1)TransE
TransE 将实体和关系向量嵌入到同一空间中,如图2(a)所示,关系向量r可视为头实体向量h到尾实体向量t间的翻译,表示为h+r≈t。TransE 的评分函数定义为:其含义为h+r与t的L1 或L2 距离。尽管TransE 的参数量小,计算复杂度低,但仅能处理简单的1-1关系。以多对一关系为例,若使用TransE 对事实三元组(hi,r,t)和(hj,r,t)进行表示学习,可能会预测出hi=hj的错误结论,很大程度上降低了模型区分不同实体的能力。
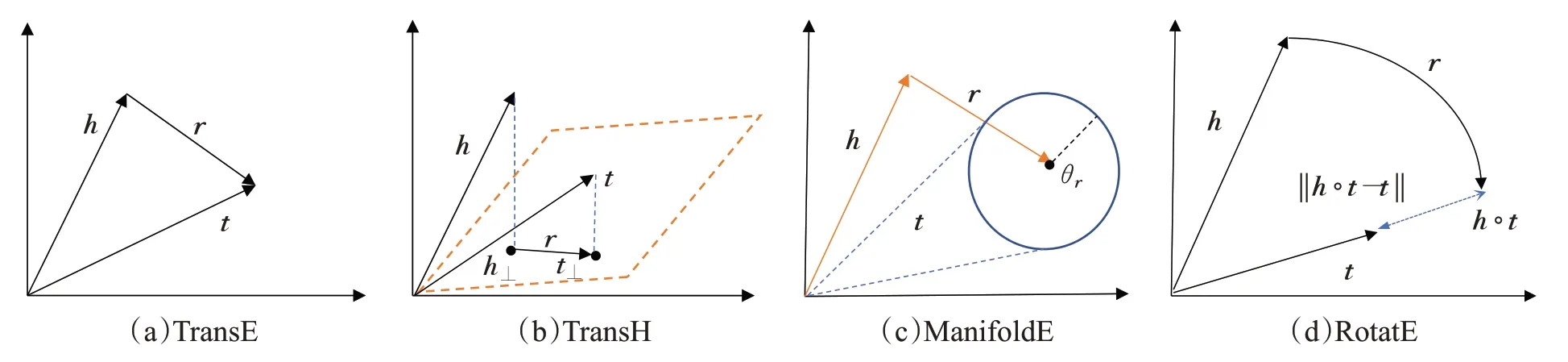
图2 TransE、TransH、ManifoldE、RotatE的模型思想Fig.2 Model ideas for TransE,TransH,ManifoldE,RotatE
(2)TransH
为解决复杂关系类型问题,TransH[10]提出将关系在超平面上建模并转换的方法,使得具有多个关系的实体以不同的向量表示。如图2(b)所示,TransH 将头实体向量h和尾实体向量t在超平面上完成投影,并使用关系向量r连接投影向量h⊥和t⊥完成转换。TransH 的评分函数定义为:
(3)TransR
Trans(E,H)将关系视为从头实体到尾实体间的转换并在同一空间中建模实体和关系间的联系,但实体上实体和关系关注的对象不同。于是,TransR[11]提出在单独的实体空间ℝd和关系空间ℝk中建模实体和关系的嵌入表示,头实体向量h和尾实体向量t通过矩阵Mr转换到关系空间,与具有r关系的实体距离变近,与不具有r关系的实体距离变远。TransR的评分函数定义为:
其中,h⊥=Mrh,t⊥=Mrt,Mr∈ℝk×d是投影矩阵。
(4)TransD
Trans(H,R)均根据关系来投影实体,它们未能考虑到实体的多样性。于是,TransD[12]提出一种细粒度方法用于解决实体和关系的多样性问题,其分别为实体和关系定义两个向量,一个用来表示实体和关系,另一个用来构建动态映射矩阵,通过使用实体和关系的动态映射矩阵Mrh,Mrt∈ℝk×d完成从实体空间到关系空间的转换。TransD的评分函数定义为:
其中,Mrh=rphTp +Ik×d,Mrt=rptTp +Ik×d,hp,tp,rp表示投影向量。
(5)TransM
TransM[13]通过对KG中的复杂关系类型分配较低的权重wr,使得关系t在复杂关系中离h+r更远,TransM有效缓解了TransE在建模复杂关系时的不足。TransM的评分函数定义为:
(6)ManifoldE
为缓解不适定代数系统和过于严格的几何形式,如图2(c)所示,ManifoldE[14]假设将事实三元组中的所有尾实体近似的位于高维球体中,即以θr为半径,h+r为中心的超球体,采用基于流形的原则替代h+r≈t。ManifoldE的评分函数定义为:
其中,Dr为关系特定的流行参数,M:E×L×E→R是流行函数,其中E是实体集,L是关系集,R是实数字段。
(7)STransH
为有效处理自反及复杂关系类型、受TransH 的启发,STransH[15]通过结合关系的超平面投影思想,将头、尾实体映射到给定关系的超平面予以区分,并引入单层神经网络的非线性操作来加强实体和关系间的联系。
STransH的评分函数定义为:
其中,Wr,1、Wr,2为关系r的两个矩阵,g(⋅)为tanh 激活函数。
(8)NTransGH
为解决Trans(E,H)在表达复杂关系的局限性,NTransGH[16]首先利用一组基向量来确定为关系建模的广义超平面,然后再设计一个两层神经网络用于捕获复杂关系类型。NTransGH的评分函数定义为:
其中,w1,w2是权重参数,m=Mrh⊥+r-Mrt⊥为经过投影平移后的三元组。
(9)RotatE
为提升建模和推断不同关系模式的能力,如图2(d)所示,RotatE[17]将每个关系建模为复数向量空间中从头实体到尾实体的旋转,对于每一个事实三元组,其期望t=h∘r,模长定义为,嵌入向量中的所有元素均满足ti=hiri。RotatE的评分函数定义为:其中,∘表示Hadamard 乘积,RotatE 能够同时建模和推断对称/反对称、反转和合成等不同关系模式,其还提出一种新的生成对抗性网络的负采样策略,在链接预测方面效果显著,可扩展到大型KG中。
除上述模型外,TransG[18]提出一种生成贝叶斯非参数无限混合嵌入用于解决KG 中的多关系语义问题;TransF[19]通过仅约束h+r与t的方向或t-r与h的方向相同来建模复杂多样的实体和关系;TransA[20]为每个关系引入一个非负加权矩阵,并采用自适应马氏距离实现更加灵活地处理复杂关系;TranSpare[21]提出share 和separate 两个版本分别用于解决KG 中存在的异质性和不平衡性问题;TransAt[22]提出关系注意力机制,同时学习基于翻译的嵌入、关系相关的实体类别和注意力;TransMS[23]通过使用非线性函数和线性偏置向量解决KG 中具有多向语义的复杂关系;TransP[24]通过将实体投影到为关系定义的头实体空间和尾实体空间,并在两位置空间中再投影到公共空间来建模实体和关系间的联系;QuatE[25]通过基于四元数空间的头尾实体之间的关系旋转来建模实体和关系;QuatR[26]通过结合关系旋转模型和深度胶囊神经网络模型用于推断和建模不同的关系模式;MuRP[27]提出在双曲空间的庞加莱球模型中对实体建模,通过Mbius 矩阵向量乘法和Mbius 加法学习特定的关系参数完成实体的嵌入表示;HAKE[28]通过将实体和关系映射到极坐标系中实现对语义层次结构的建模;DihEdral[29]使用二面体对称群来建模图谱中的实体和关系;MRotatE[30]从关系和实体旋转的角度利用三元组特征处理多重关系;陈恒等[31]使用球坐标系对实体和关系进行建模表示,用于解决KG中普遍存在的语义分层现象。
2.2 基于语义匹配的方法
基于语义匹配的方法充分利用张量分解、线性或非线性结构,通过匹配实体潜在的语义和嵌入表示中的关系,使用基于语义相似度的评分函数来衡量事实三元组成立的可能性。
(1)RESCAL
RESCAL[32]以张量分解为基础,是一种用于关系学习的张量因子分解方法,旨在解释二元关系数据的固有结构。其能够通过模型的潜在成分进行集体学习,并提供了一种计算因子分解的有效算法。具体来说,RESCAL将KG(假设该KG由n个实体和m个关系组成)中的三元组建模为一个大小为n×n×m的三维张量X,若三元组(h,r,t)在训练集中存在张量项Xijk=1 表示存在第k个关系(第i个实体,第j个实体)。否则,对于不存在或未知的关系,Xijk被设置为零。对于每个三元组的评分函数如下所示:
其中,Mr为关系r的建模矩阵。关系矩阵Mr的各个权重捕捉头实体向量h的第i个潜在因子hi和尾实体向量t的第j个潜在因子tj之间的相互作用量。虽然RESCAL在多关系数据集上表现很好,但是计算复杂度太高。并且随着关系类型的增加,其参数数量增长非常快,难以运用到大规模的知识图谱中。
(2)SimplE
为解决头、尾实体两嵌入向量之间的独立性问题,Kazemi 等人[33]在经典CP[34]分解的基础上进行改进,衍生出一个简单、可解释、具有完全表达能力的双线性模型SimplE,其具有独立学习每个实体拥有两个嵌入向量的能力,且能够通过权重绑定的方式将背景知识融入到嵌入表示中,编码先验知识。具体来说,该模型通过引入了关系的逆,利用关系的倒数来解决CP 中每个实体的两个向量的独立性,并且计算(h,r,t)和(t,r-1,h)的CP评分的平均值,SimplE的评分函数定义为:
其中,r′代表关系的逆的嵌入表示,符号∘代表Hadamard乘积。
(3)DistMult
针对RESCAL 参数量大,计算复杂性高的问题,DistMult[35]模型提出了一个用于多关系学习的通用网络框架。该模型减少对关系矩阵的约束,将关系矩阵Mr改为对角矩阵,表示更加简单。定义了如下评分函数:
其中,diag(r)∈ℝd×d表示与关系对应的双线性变换矩阵。该分数仅能获得h和t相同维度的交互,虽然减少了关系对应的参数数量,但仅能学习到对称关系。
(4)ComplEx
为解决非对称关系的问题,受DistMult 的启发,ComplEx[36]首次将复数向量空间引入到知识表示学习之中,采用DistMult 将关系矩阵改为对角矩阵的思想,并将矩阵元素的类型设置为复数。具体来说,其通过使用Hermitian 点积进行关系、头实体、尾实体三者的共轭式合成,使其能够学习到对称关系以及反对称关系。ComplEx的评分函数定义为:
(5)TuckER
TuckER[37]基于Tucker[38]分解将张量分解为一组矩阵和核心张量W乘积的形式来学习嵌入,其评分函数定义为:
其中,W∈ℝde×dr×de是一个共享的原型关系矩阵池,不同的嵌入关系以不同的方式组合在一起,×n表示张量积,de和dr分别代表实体和关系的向量维数。TuckER具有充分表达性,RESCAL、DistMult、ComplEx和SimplE模型均可以解释为TuckER的特例。
(6)HolE
为提升RESCAL 的效率,Nickel 等人[39]提出了全息嵌入模型HolE 来学习整个KG 的组成向量空间表示。具体来说,HolE 使用向量表示的循环相关性构建关系数据的组合表示,运用组合运算符将头实体向量和尾实体向量的循环相关作为实体对的嵌入表示,然后将组合向量与关系表示相匹配来评测事实的合理性。其评分函数定义为:
HolE 通过循环相关构建组合表示,可以捕获实体和关系间的丰富交互。参数数量减少,相较于RESCAL模型有更好的效果,易扩展在大型数据集上。
除上述模型外,TATEC[40]提出为多关系数据建模双向和三向交互,即不仅包含三个元素之间的交互,还包含仅有两个元素间的双向交互;LFM[41]提出一种基于双线性结构用于建模大型多关系KG的方法,其将实体建模为嵌入向量、关系编码为实体上的双线性算子;ANALOGY[42]在RESCAL 的基础上引入类比推理的思想,其通过显式建模多关系数据的类比结构,使用的评分函数与RESCAL 相同,有所区别的是ANALOGY 对关系矩阵增加了正规性和可交换性约束。
2.3 基于深度学习的方法
基于深度学习的方法侧重学习实体和关系的特征嵌入,利用多层神经网络强大的自适应学习能力来建模图谱中实体和关系间的语义关联,通过提取其隐藏特征来学习具有丰富表现力的嵌入表达。
(1)NAM
神经关联模型(neural association model,NAM)[43]通过使用深度神经网络架构来建模KG 中实体和关系间的联系。对于每个三元组,NAM 首先将对应的头实体向量h以及关系向量r在输入层完成拼接,得到z(0)=[h;t]∈ℝ2d,然后经过由L层非线性隐藏层组成的深度神经网络,最后将第L层的结果与尾实体向量t通过线性输出层获得该事实的得分。NAM的评分函数如下所示:
其中,M(l)代表第L层的权重矩阵,b(l)代表第L层的偏置,事实成立的概率通过倒数第一个隐藏层的输出与尾实体向量t的内积得出。
(2)ConvE
ConvE[44]提出一个神经链接预测模型,其通过卷积层和全连接层建模输入实体和关系间的交互。对于每个三元组,ConvE 首先使用2D 卷积将头实体向量h和关系向量r拼接成一个二维矩阵作为卷积神经网络的输入,然后依次经过卷积层和全连接层,将获得的特征映射张量向量化并投射到k维向量空间中,最后再使用点积操作将输出与尾部嵌入合并获得该事实的得分。ConvE的评分函数定义如下:
其中,Mh代表头实体向量h的二维矩阵,Mr代表关系向量r的二维矩阵,∗代表卷积操作,ω代表卷积核,w是映射矩阵,vec是将特征映射张量向量化的操作。ConvE 通过卷积操作学习多层非线性特征用于表达语义信息,并通过权值共享的方式来减少参数的数量。
(3)HypER
HypER[45]提出了一种超网络模型用于KG上的链接预测,通过实体嵌入上卷积特定于关系的过滤器,在实体和关系嵌入之间创建非线性交互,从而实现跨关系的多任务学习。具体来说,首先将实体嵌入e1与过滤器Fr进行卷积,过滤器Fr通过超网络H依据关系嵌入wr创建,其次将得到的特征映射Mr通过权重矩阵W映射到de维向量空间,并使用非线性函数f,然后通过内积与所有对象向量e2∈E结合,最后使用sigmoid 函数为每个三元组进行评分。HypER的评分函数定义为:
其中,非线性函数f为ReLU,Fr为过滤器,∗代表卷积操作,W为权重矩阵。
(4)CapsE
CapsE[46]首次提出使用胶囊网络建模关系三元组用于实现KGC 任务,首先将嵌入向量h、r和t都拼接成三列矩阵[h;r;t],其次将其输入具有多个过滤器的卷积层中生成不同的特征向量,之后再将其构建为相对应的胶囊,然后路由到另一个胶囊以产生连续的向量,最后通过计算向量输出的长度来获得该事实的得分。CapsE的评分函数如下所示:
除上述模型外,ConvR[47]在ConvE 的基础上提出利用自适应卷积来增强实体和关系的交互能力;InteactE[48]在特征提取部分使用循环卷积操作,并通过改变特征组合的方式来捕获实体和关系的交互;ReInceptionE[49]提出一种关系敏感且能充分利用局部和全局结构信息的嵌入模型来学习实体和关系的联系。
2.4 小结
第2 章主要介绍了静态知识图谱补全的3 大类方法,即基于翻译模型的方法、语义匹配的方法、深度学习的方法。表1 从类别、模型方法、实体关系嵌入、评分函数、优缺点五方面对SKGC 的代表性模型进行对比总结。

表1 静态知识图谱补全模型总结Table 1 Summary of static knowledge graph completion model
3 时序知识图谱补全
静态知识图谱补全中的实体和关系是固定不变的,即原有KG中已存在需要补全的关系。然而,知识图谱中的事实信息会随着时间发生变化,上述SKGC方法仅适用于知识图谱事实信息未发生改变的情况下,TKGC是在KG补全任务中添加新的实体。本章重点介绍KG随时间信息发生变化的知识表示学习补全方法,时序知识图谱补全是当下研究中的热点,该方法的核心是如何将融入时间戳的模型进行有效的链接预测。按照处理时间信息的方式不同,将其分为时间内嵌补全方法、时间外嵌补全方法和时间外推补全方法三类。
3.1 时间内嵌补全方法
时间内嵌入补全方法旨在将时间信息内嵌于实体和关系中,再建模实体和关系间的联系,进而完成给定时间点内的预测。借鉴TransH的思想,文献[50]提出了一种时间感知的知识表示方法HyTE,该方法将时间范围输入KG分割成多个子图,每个子图对应相关的时间戳,然后将每个子图的实体和关系投影到时间戳特定的超平面上,每个时间戳与对应的超平面相关联利用KG的时间范围事实来执行链接预测,并对未注释时间事实的时间范围进行预测。文献[51]提出将时间和关系组合成由关系类型和时间戳字符组成的时间序列作为LSTM的输入进而得到融合时间信息的关系向量,再通过结合TransE的评分函数进行预测,TA-DistMult采用了同样的思想,效果比TA-TransE好。为了在任何给定的时间提供实体特性,受到历时词嵌入的启发,文献[52]提出了一个新的嵌入模型DE,通过设计出新的实体映射函数将实体和时间戳作为输入,并在该时间为实体提供隐藏表示。该模型的特点是任何SKGC 方法都可以通过DE 潜在地扩展到时序领域中,DE 与SimplE 相结合展现出较好的性能,但该模型不能对涉及时间间隔的事实进行建模。文献[53]认为现有的时间感知嵌入方法只关注事实的真实性,即仅仅将时间信息与实体或关系相融合,忽略了时间的平滑性。为捕获精细粒度的时间关系提出了RTGE模型,该模型通过提出附加平滑因子,考虑相邻时间步长的超平面之间的时间平滑性,可以保留给定图的结构信息和演化模式。RTGE与HyTE的思想均为学习不同时间段的超平面,有所不同的是,HyTE 中相邻时间间隔的超平面彼此独立,而RTGE 引入了定时平滑的概念来联合优化和学习相邻时间间隔的超平面。RTGE 可以避免由于相邻时间间隔的超平面的独立学习而导致的嵌入空间之间缺少时序关联的问题。受到RotatE的启发,文献[54]提出了一种基于K维旋转的嵌入模型ChronoR,通过旋转和缩放操作在嵌入空间中变换对象和对象实体,将时间信息内嵌于实体的旋转过程中,以获得实体和关系的动态变化。
3.2 时间外嵌补全方法
时间外嵌补全方法通过学习四个维度向量的独立嵌入表示,在相关计算方法中引入时间向量完成给定时间点内的预测。文献[55]提出结合张量分解的方法来完成TKGC 的补全工作,将KG中的事实集合视为四阶张量,包括头部实体、关系、尾部实体和时间维度。通过添加时间维度信息来表示特定时间戳上三元组的有效性,该方法可以进一步推广到其他基于张量分解的静态KG 表示学习。在其论文中,T-SimplE 取得了较好的结果。文献[56]提出了一种新的时序知识感知嵌入方法TeLM,其通过多向量嵌入的方式来表示知识图谱,并使用线性正则化器来学习时间嵌入,进而执行时序知识图谱的四阶张量因子分解。值得注意的是,与实值和复值嵌入相比,多向量嵌入提供了更好的泛化能力和更丰富的表达能力,具有更高的自由度。另外,与时间平滑相比,线性正则化器为时间嵌入提供了更好的几何意义,提升了模型性能。文献[57]基于四阶张量的Tucker 分解提出TuckERTNT模型,通过引入几种正则化约束,从不同方面协调所提出的分解。与CP 分解相比,该模型不要求实体、关系和时间戳的嵌入维度方面保持一致,具有更高的灵活性。文献[58]将RESCAL 推广到时序/情景知识图谱中,Tree 和ConT 作为RESCAL 对情景张量的新推广,通过引入稀疏情景张量时间的潜在表示,ConT总体上获得了优异的性能。
3.3 时间外推补全方法
时间外推补全方法旨在对未来的事实进行预测,本节模型能够预测发生事实可能发生的时间。文献[59]提出了一种基于新出现事实的随时间演化的深度学习架构Know-Evolve,该架构可以在多关系环境中随时间高效地学习非线性进化的实体表示,动态进化网络将吸收新的事实并基于它们最近的关系和时间行为更新相关实体的嵌入。文献[60]提出了递归事件网络(RE-NET),其是一种预测未来相互作用的自回归结构。具体来说,RE-NET使用循环事件编码器对过去的事实进行编码,并使用邻域聚合器对相同时间戳的事实连接进行建模,由以往事实时间序列的概率分布来预测即将发生的事实。为了从已知事实中推理出更加准确的时序事实,文献[61]提出了一种基于时间感知复制生成机制的模型CyGNet,该模型既可以从整个实体词汇表中预测未来的事实,又能够识别重复的事实,并参考过去的已知事实相应的预测未来的事实。时序知识的表示和推理是一项充满挑战性的任务,CyGNet 在解决这类问题上提出了新的思路和方法,并通过链接预测验证了方法的有效性。TKG实际上是对应于不同时间戳的KG序列,然而每个KG中的所有并发事实都表现出结构依赖性,时间上相邻的事实携带信息的顺序模式。为此,文献[62]提出一种用于TKG推理的递归进化网络模型RE-GCN,它通过捕获并发事实之间的结构依赖关系和跨时间相邻事实的信息顺序模式来学习实体和关系的进化表示。具体来说,其利用GCN 的消息传递框架捕获并发事实间的结构依赖性,并通过堆叠多层GCN 获取跨时间相邻事实的信息顺序模式。
3.4 小结
第3 章主要介绍了时序知识图谱补全的3 大类方法,即时间内嵌补全方法、时间外嵌补全方法以及时间外推补全方法。表2从类别、模型方法、推理设置、图谱的建模方式、算法思想五方面对TKGC的代表性模型进行对比总结。
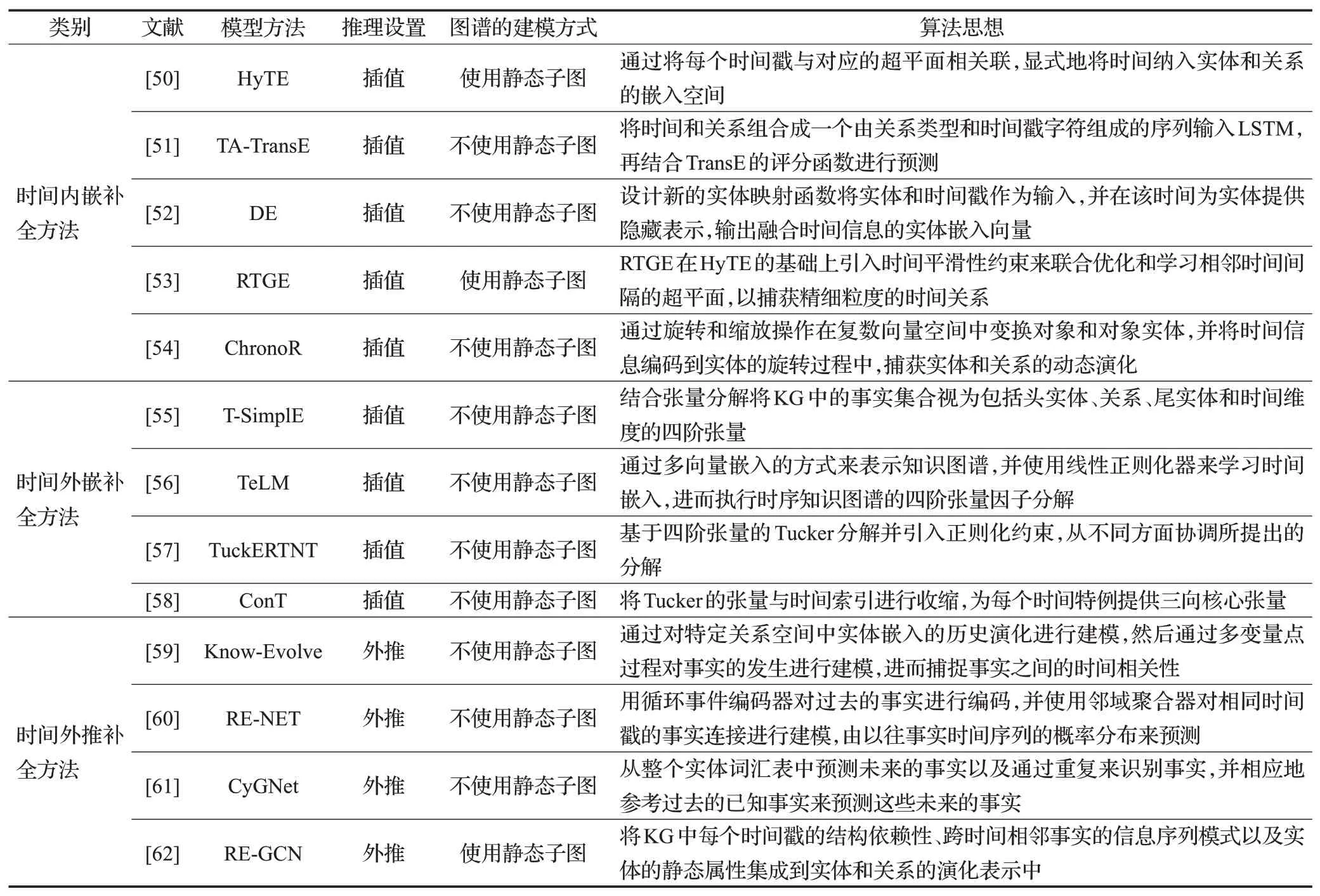
表2 时序知识图谱补全模型总结Table 2 Summary of temporal knowledge graph completion model
4 多模态知识图谱补全
近年来,互联网的高速发展累积了大量包含文本、图像、视频、音频等在内的多模态数据,多模态知识图谱是人工智能领域研究的热点问题。在静态知识图谱的基础之上,多模态知识图谱融入了包含多种模态的实体以及多模态实体间的关系。目前,知识图谱已广泛应用于处理文本数据,然而现有的KG表示学习方法大多只考虑KG的结构信息,忽略了实体的图像、视频、音频等多模态数据,充分利用实体的文本描述、图像等多模态信息来扩充实体和关系的语义信息在知识图谱补全任务中发挥着重要作用[63]。现有MKGC 方法主要集中在结合文本、图像两种模态信息的研究上,本章重点介绍KG 中融入实体的文本描述、图像等模态信息的知识表示学习补全方法,以多模态知识图谱构建的视角,将其分为基于特征的补全方法和基于实体的补全方法。
4.1 基于特征的补全方法
基于特征的补全方法是将文本、图像等多模态信息作为实体的辅助特征来丰富知识的类型。为充分利用实体图像中的视觉信息,文献[64]首次提出基于图像的知识表示学习模型IKRL,该模型首先利用神经图像编码器为实体的所有图像构建嵌入表示,然后再使用基于注意力的方法将图像信息进行聚合,最后通过TransE的方法来预测实体间的关系。为了充分利用三元组的结构信息以及实体的描述信息,文献[65]提出了描述嵌入的知识表示学习模型DKRL,其利用连续词袋模型(CBOW)和深度卷积神经网络模型(CNN)这两种编码器来建模实体描述的语义信息,并结合TransE来学习实体和关系的嵌入表示。文献[66]提出了一种利用文本和图像两种不同类型的外部多模态表示方法,该方法在IKRL 的基础上融入了实体的文本表示,并引入了考虑KG 实体多模态表示的附加能量函数。具体来说,对于结构、视觉、语言三者的知识表示及其组合分别定义一个特定的能量函数,KG 三元组的最终能量函数为三者的子能量函数总和。
4.2 基于实体的补全方法
基于实体的补全方法是将文本、图像等不同模态的信息视为结构化的关系三元组,而不是事先预定的特征。为充分利用KG中的文本、图像、数值等多种数据类型,文献[67]提出了多模态知识图谱嵌入模型MKBE,其是第一个在统一模型中使用不同类型信息的方法,该模型将这些不同类型的信息视为结构化知识的关系三元组,而不是预定特征。其核心思想是利用不同的神经编码器来处理观察到的数据,并与关系模型结合起来学习实体和多模态数据的嵌入。为联合学习结构知识和多模态知识,文献[68]提出了一种新的多模态知识表示学习模型TransAE,该模型首先分别学习文本和图像的特征向量,然后将文本和图像的特征向量输入到多模态自动编码器并结合TransE 模型学习实体和关系的表示,最终获取联合结构知识和多模态知识的表示。为探讨丰富的视觉上下文信息在KG表示学习中的作用,文献[69]提出了一种关系敏感的多模态嵌入模型RSME。具体来说,RSME 由三个门结构和一个基本的KG 嵌入模型ComplEx 组成,过滤门在数据集级别去除噪声,并且对于每个KG实体,仅保持与其他图像具有最高平均相似度的图像,遗忘门来调整图像到实体嵌入的融合率,融合门将结构嵌入和图像嵌入的投影结合起来,从而达到当时最先进的性能。为缓解训练过程中不同模态信息间的相互干扰,文献[70]提出一种用于多模态知识图谱补全的模态分裂表示学习和集成推理框架MoSE。具体来说,为减轻模态间的干扰,该模型首先通过学习每个模态的模态分割关系嵌入,并非单个模态间的共享,然后在推理阶段对这些嵌入表示进行模态分割预测,最后利用各种集成方法将预测与不同权重相结合,实现动态建模不同模态的重要性。为解决不同KGC任务和模态表示需要对模型架构进行更改,且不同模态间存在信息矛盾的问题,文献[71]提出一种用于统一多模态KGC混合变换器MKGformer,其使用粗粒度预引导交互模块和细粒度相关感知融合模块的多级融合,分别预减少模态间异质性和减轻不相关视觉信息的噪声,该模型可以有效地对描述性文本和图像的多模态表示进行建模,达到了目前最先进的性能。
4.3 小结
第4章主要介绍了多模态知识图谱补全的2大类方法,即基于特征的补全方法以及基于实体的补全方法。表3从类别、模型方法、多模态数据类型、算法思想四方面对MKGC的代表性模型进行对比总结。
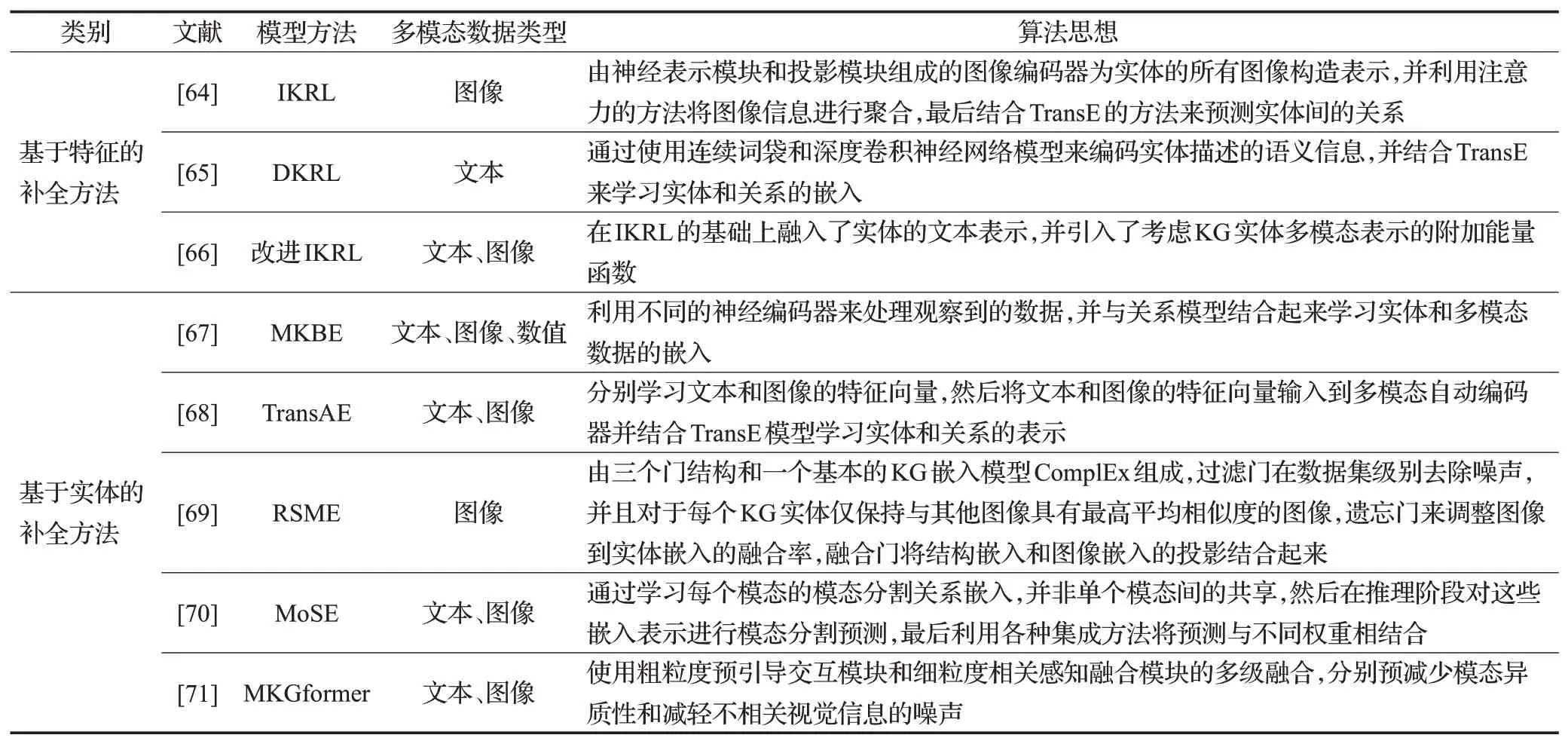
表3 多模态知识图谱补全模型总结Table 3 Summary of multimodal knowledge graph completion model
5 知识图谱补全常用数据集及评价指标
目前,链接预测任务通常用作评测KGC 模型的指标,KGC研究领域的基准数据集是从世界知名KG中抽样获得的。静态知识图谱补全研究领域常用的数据集信息如表4所示,包括:WN18RR、WN11分别是WordNet知识库的子集;FB15k-237、FB13 分别是Freebase 知识库的子集;YAGO3-10是YAGO知识库的一个子集。
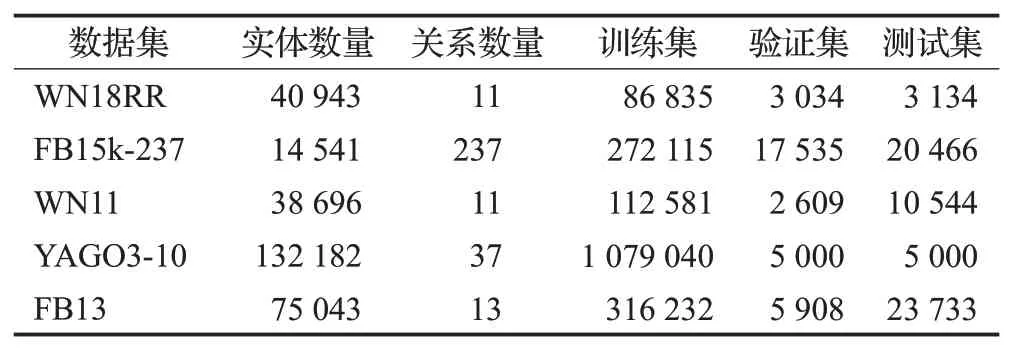
表4 静态链接预测数据集统计Table 4 Dataset statistics for static link prediction
目前,时序知识图谱补全研究领域的基准数据集主要来自YAGO、Wikidata[72]、GDELT[73]、ICEWS[74]四大数据库,数据集具体信息如表5所示。其中,YAGO、Wikidata中的事实基于时间区间,GDELT、ICEWS中的事实基于时间点。
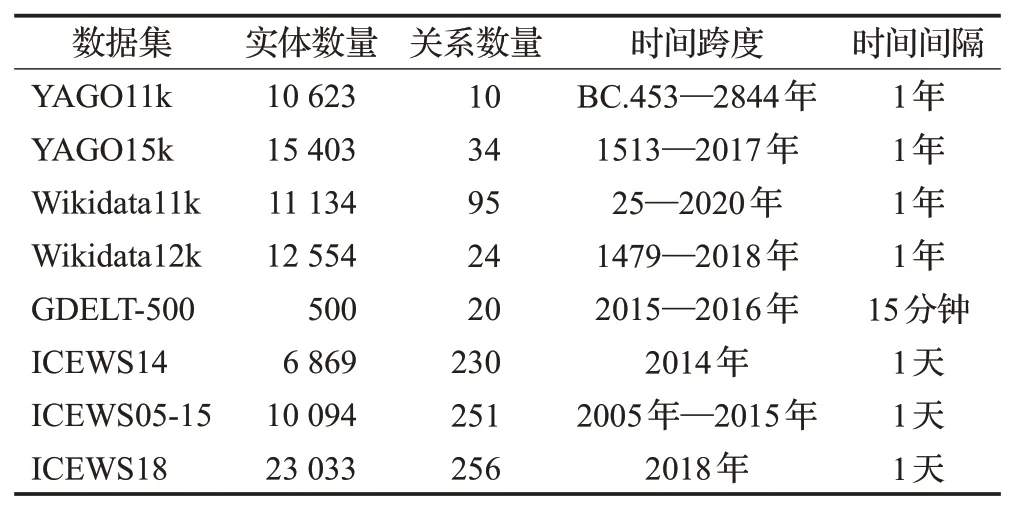
表5 时序链接预测数据集统计Table 5 Dataset statistics for temporal link prediction
目前,多模态知识图谱补全领域的常用数据集具体信息如表6 所示,包括:WN18-IMG 是WN18 的扩展数据集,每个实体有10幅图像;FB15K-237-IMG是Freebase知识库的一个子集,每个实体也有10幅图像;WN9-IMG是WN18的子集。
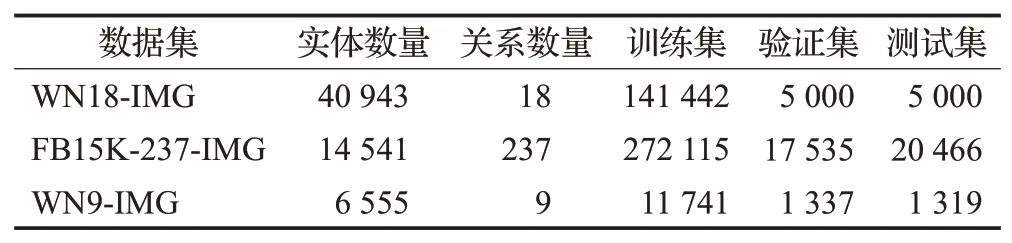
表6 多模态链接预测数据集统计Table 6 Dataset statistics for multimodal link prediction
为验证相关KGC模型在链接预测任务中的实体预测和关系预测效果,通常划分为训练集Ttrain、验证集Tvalid和测试集Ttest三类,并采用以下三类指标进行评价。
(1)平均排序(mean rank,MR):MR 表示在测试集Ttest中正确事实的平均排序得分,MR的数值越小,说明KGC模型的链接预测效果越好。
(2)平均倒数排序(mean reciprocal ranking,MRR):MRR 表示在测试集Ttest中正确事实的平均排名倒数,MRR的数值越大,说明KGC模型的链接预测效果越好。
(3)Hits@n:Hits@n表示在测试集Ttest中得分排名前n的正确事实所占的比率,Hits@n的数值越大,说明KGC 模型的链接预测效果越好。通常n的取值为1、3、10。
为了加深对静态知识图谱补全、时序知识图谱补全、多模态知识图谱补全代表性方法的理解,对这些方法的实验进行对比、分析和总结[61,71]。其中,静态知识图谱补全模型在WN18RR和FB15K-237上的链接预测结果如表7 所示;时序知识图谱补全模型在ICEWS18 和ICEWS14上的链接预测效果如表8所示;多模态知识图谱补全模型在FB15K-237-IMG和WN18-IMG上的链接预测结果如表9所示。
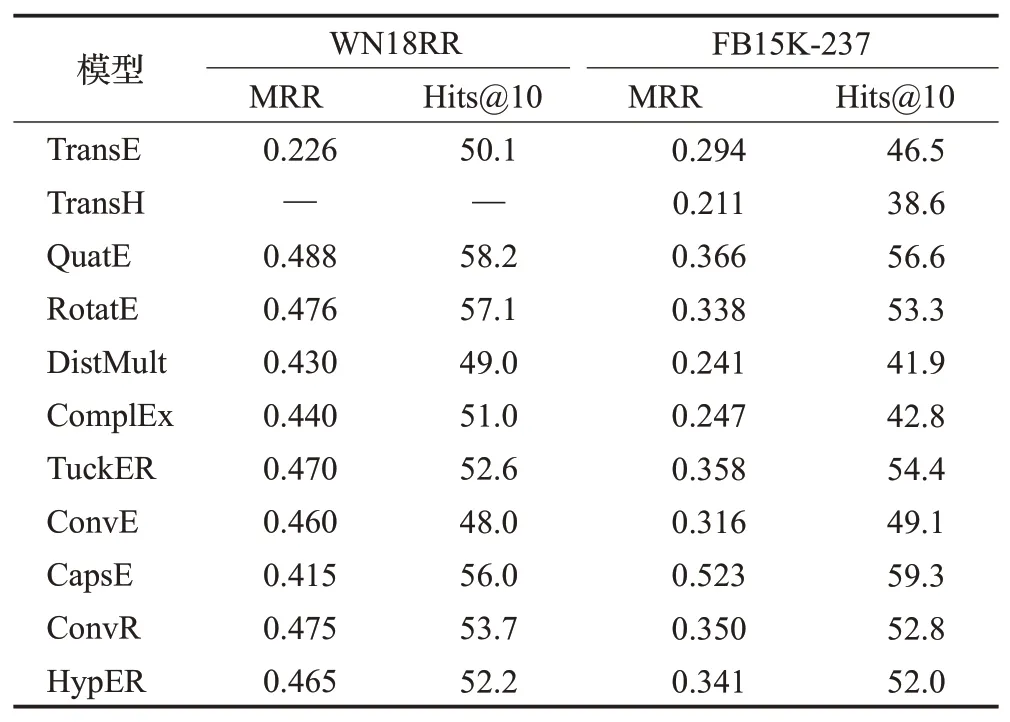
表7 WN18RR和FB15K-237链接预测结果Table 7 Link prediction effects on WN18RR and FB15K-237
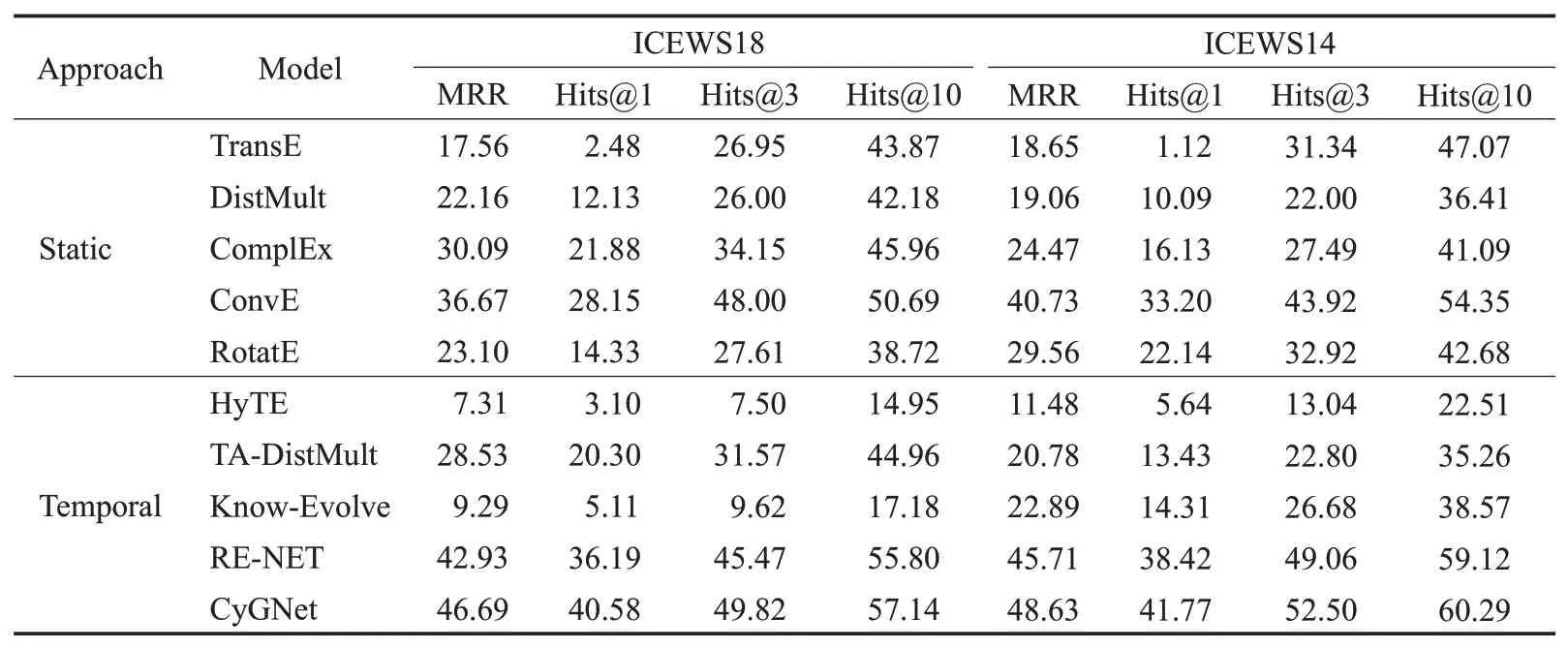
表8 ICEWS18和ICEWS14链接预测结果Table 8 Link prediction effects on ICEWS18 and ICEWS14
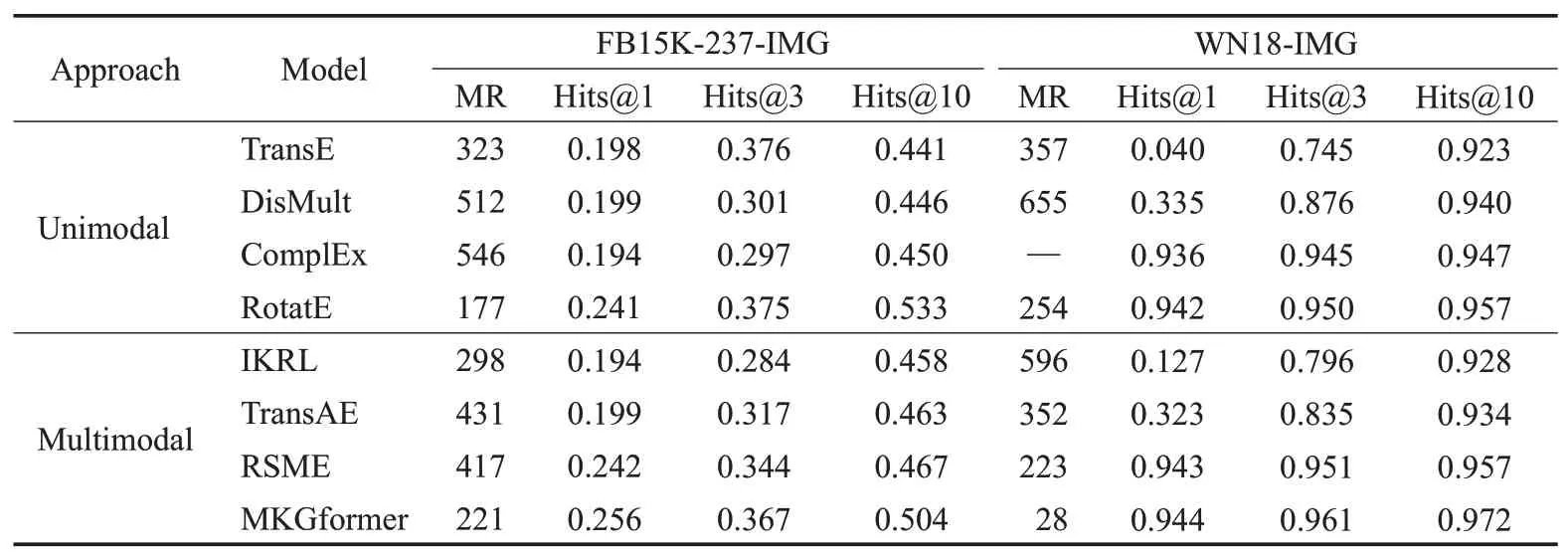
表9 FB15K-237-IMG和WN18-IMG链接预测结果Table 9 Link prediction effects on FB15K-237-IMG and WN18-IMG
从表7 可以看出,在进行链接预测实验时,当采用WN18RR作为实验数据集测试MRR时,QuatE、RotatE、TuckER、ConvR、HypER 相较于TransE 的效果较好,其中QuatE的效果最好;当测试Hits@10时,QuatE、RotatE、CapsE 的效果相较于其他模型更好,其中QuatE 的效果最好;当采用FB15K-237作为实验数据集测试MRR时,CapsE、QuatE、TuckER 性能较好,其中CapsE 的效果最好;当测试Hits@10 时,CapsE、QuatE、RotatE、ConvR、HypER的效果相较于其他模型较好,其中CapsE的效果最好。综上所述,CapsE、QuatE、RotatE 的方法值得借鉴,在今后的研究中可以在这三种方法上进行拓展,不断提升链接预测的效果。
从表8 可以看出,在进行链接预测实验时,当采用ICEWS18作为实验数据集测试MRR时,CyGNet、RE-NET的效果相较于其他模型更好,其中CyGNet效果最好;当测试Hits@1、Hits@3、Hits@10 时,CyGNet、RE-NET、ConvE 整体上体现出较好的性能,其中CyGNet 效果最好。当采用ICEWS14作为实验数据集,无论是测试MRR,还是测试Hits@1、Hits@3、Hits@10,CyGNet、RE-NET整体上均体现出较好的性能。综上所述,CyGNet 和RE-NET方法在时序知识图谱补全中值得推广,今后的研究可以在其基础上拓展,以得到更好的链接预测效果。
从表9 可以看出,在进行链接预测实验时,当采用FB15K-237-IMG作为实验数据集测试MR时,MKGformer、RotatE 的效果相较于其他模型更好,其中RotatE 效果最好;当测试Hits@1、Hits@3、Hits@10时,MKGformer、RotatE、RSME整体上体现出较好的性能,其中MKGformer效果最好。当采用WN18-IMG 作为实验数据集测试MR 时,MKGformer、RSME 的效果相较于其他模型更好,其中MKGformer效果最好;当测试Hits@1、Hits@3、Hits@10 时,MKGformer、RSME、RotatE 整体上体现出较好的性能,其中MKGformer 效果最好。综上所述,MKGformer 和RSME 方法在多模态知识图谱补全中值得推广,MKGformer是目前MKGC研究中最先进的方法。
需要注意的是,上述方法受模型结构、嵌入向量维度、学习率以及训练集大小等因素的影响,不存在性能绝对优异的模型,即使相同的模型也可能会表现出较大的性能差异,需根据应用中的实际情况权衡内存和性能间的联系,上述的指标仅供参考。
6 未来研究展望
随着智慧化信息时代的到来,以数据为支撑的KG规模将会越发庞大。从知识图谱构建的角度来看,通过人工设计、半自动或全自动地从不同类型数据资源中获取知识,不断增加的KG规模在图谱信息的完整程度以及数据质量方面存在相当大的挑战,提升KG的完整性具有重要意义。近年来,研究者们主要集中在静态知识图谱的研究上,对于时序知识图谱、多模态知识图谱仍缺乏足够多的研究。静态知识图谱中默认其中的事实一直是正确的,但事实上,随着时间的变化,知识图谱中的许多事实信息会发生改变。例如,第45 任美国总统特朗普的任期在2017 年1 月20 日至2021 年1 月20 日,事实三元组可以表示为(美国,总统,特朗普),而现任总统拜登的任期从2021 年1 月20 日至今,在不同的时间段里,三元组的正确性会发生改变,如若询问“美国总统是谁?”的问题时,忽略时间信息的因素,可能导致错误的结果。多模态知识图谱在静态知识图谱的基础上构建了融合文本、图像、视频等多种模态下的实体以及实体间的语义关系,为知识表示学习提供重要的文本或图像信息,目前的一些工作已证实其在知识表示与推理领域发挥的重要作用。为此,研究包含时间信息和多模态信息的知识图谱补全工作具有十分重要的意义。接下来将从以下五个方面展望知识图谱补全研究。
6.1 可解释性
基于知识表示学习的方法通过表示向量的形式进行计算,并且可以很好地与深度学习模型集成,具有更高的效率以及可扩展性,但存在可解释性差的问题。然而,基于规则的推理是准确和可解释的,但由于搜索空间巨大,在图谱上利用规则学习的搜索效率低下。在静态知识图谱补全研究中,不少研究者[75-76]通过将嵌入和规则学习结合在一起,利用彼此的优势来弥补两者之间的短板,提升了嵌入学习的可解释性。然而,在时序知识图谱补全和多模态知识图谱补全方面还未有研究者涉及两者间的相互结合,因此,在探索规则学习及时间信息、多模态信息同时编码到实体和关系的嵌入学习值得深思。
6.2 负采样策略
从未观察到的三元组事实中抽取负例三元组的方法来生成负样本,更加有助于实体和关系的嵌入学习。Yang等人[77]证明了负采样与正采样同样重要,同时考虑负采样可确定优化目标并减少真实图形数据中估计值的方差。静态知识图谱补全方法中通过采用不同的采样策略来保证预测准确性的手段,例如:随机采样、过滤采样,概率采样等。这些采样方法相对固定,生成的负例三元组很容易被区分。随后,研究者提出更有效的负采样策略,基于生成对抗性网络的负采样策略[17]。由于添加了时间维度信息、多模态信息,鲜有研究者在时序知识图谱补全和多模态知识图谱补全上有关负采样策略的研究,如何权衡事实和时间戳、事实和多模态信息之间的复杂联系是一项极具挑战性的任务。
6.3 融合多源信息
相对于时序知识图谱补全研究而言,静态知识图谱补全方法中利用实体类型[78]、实体描述[79]、实体属性[80]等多源信息来扩展实体和关系的语义信息,提升预测的准确性,但现有时序知识图谱补全方法中主要依赖实体描述来建立已知实体和未知实体的联系。在时序知识图谱研究中,Li等人[62]通过实体类型将语义信息与实体联系起来,实现更加真实的表示学习。因此,在时序知识图谱补全的研究方法中通过融合多源信息来扩充实体和关系的语义信息在后续的研究工作中值得探索。
6.4 长尾实体学习
大多数构建的知识图谱存在长尾类型的实体,即出现频率很少的实体和关系。无论是静态还是时序、多模态知识图谱的表示学习,过少的训练样本难以建模长尾实体的语义信息,时序知识图谱的数据稀疏问题更加严重,控制这些图的演化的动态可能是高度非平稳的[81]。为此,有效地解决时序、多模态知识图谱的长尾实体类型问题具有一定的研究意义。
6.5 问答和推荐领域
基于知识图谱的问答和推荐是近年来研究的热点,一个较为完备的知识图谱是问答和推荐任务中的基础,知识图谱补全技术在构建知识图谱的过程中也是不可或缺的。不少研究者通过将知识图谱补全方法应用到问答任务中进行推理补全,依托知识图谱的推荐系统通过学习图谱中的实体和关系嵌入向量,再根据这些低维嵌入向量去学习用户和项目的特征向量,进而完成推荐任务,有效解决了数据稀疏性问题。但目前的大多数问答和推荐任务局限于静态知识图谱研究,对于引入时序知识图谱和多模态知识图谱的研究在问答和推荐领域具有重要意义。
猜你喜欢
山西大学学报(自然科学版)(2021年1期)2021-04-21
少先队活动(2020年12期)2021-01-14
中国外汇(2019年18期)2019-11-25
五邑大学学报(自然科学版)(2019年3期)2019-09-06
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
领导科学论坛(2016年9期)2016-06-05
计算机工程与设计(2015年1期)2015-12-20
