
新一代静止气象卫星对浙江省金丽温高速公路低能见度识别的研究
2023-10-23 05:18梁晓妮任晨平王志陈仲瑜柳婧宋建洋
气候与环境研究 2023年5期
梁晓妮 任晨平 王志 陈仲瑜 柳婧 宋建洋
1 浙江省气象服务中心,杭州 310017
2 中国气象局公共气象服务中心,北京 100081
1 引言
能见度是表征大气透明程度的重要物理量,与人类社会生产生活息息相关,当能见度过低时,会造成航班延误、公路封闭、交通事故增多。目前,对低能见度出现的原因和预报模拟已经有了大量的工作。常军等(2007)对河南省45年的大雾日数进行分析研究,发现存在2~4年、8~10年和19~22年的周期变化。宗晨等(2019)利用连续的地面观测数据分析研究了江苏省夏季浓雾的时空分布特征及影响因子。朱承瑛等(2018)对江苏省2013~2016年出现的4个强浓雾个例进行分析,得出了雾爆发增强的各种时间特征及微物理特征,并给出了爆发增强的本质及爆发增强的触发因子。王博妮等(2016)探讨了江苏省沿海高速公路的浓雾过程的气候特征、气象要素阈值以及主要的环流背景,万齐林等(2004)研究了小地形动力作用对雾的重要影响。张利娜等(2008)、何立富等(2006)、张礼春等(2013)对大雾、浓雾过程的物理成因和环流特征进行了研究。吴兑等(2006)对珠江三角洲地区气溶胶云造成的空气质量和能见度下降问题进行了研究。
而大雾有效服务的前提是对雾的准确监测,常规的监测方法是通过布设站点进行人工或仪器自动观测,不仅耗费大量的人力物力,而且观测站点的密度也难以满足交通部门需要,气象卫星观测资料具有覆盖范围广、时空分辨率高的特点,使得其在监测雾的生消动态方面具有独特的优势。
刘年庆等(2007)使用风云1D的1、2、4、6、7、10这6个通道组合的支持向量机方法对大雾的判识正确率评分为74%。史达伟等(2018)利用几种有监督机器学习算法,针对连云港大雾天气背景下的特强浓雾特征建立了诊断模型,其中LSVM(线性支持向量机) 算法对于特强浓雾的诊断模型测试效果最好,但算法可理解度较低、复杂度较高,不如CART(决策树)算法易于使用。李亚春等(2000)利用低层云雾与陆地及洋面在长波红外通道和短波红外通道上亮温的差异,来识别夜间的低层云雾,取得了一定的效果。李文娟等(2017)利用可见光和红外通道双通道阈值相结合,基本可以滤除海区、地表、冷云、厚云,在此基础上,结合自动站相对湿度 92% 的阈值设定,滤除低湿区,进一步细判识雾区,识别效果优于固定阈值,TS评分(Threat Score)达到62。王坚红等(2019)利用FY-3A(风云三号A星)资料进行夜间大雾低能见度分布反演计算, 认为反演的低能见度区范围及强度合理。并运用美国LAPS(局地分析与预报系统),与FNL(Final Operatinal Global Analysis)再分析资料多要素反演数据进行多源要素融合分析,结果表明融合效果对单来源资料反演的大雾低能见度分布有较好的改善。刘健等(1999)探讨了用气象卫星的可见光和红外探测通道分析云和雾中粒子大小分布的可行性,分析出具有通道3反射率小值的云中大粒子区与可降水区间存在有一定的关系,以及具有通道3反射率大值区与大雾覆盖区之间具有良好对应性。刘建朝和周毓荃(2011)选用风云静止卫星反演的云光学厚度、云顶温度、云顶高度、云有效粒子半径作为特征分量,以Micaps (气象信息综合处理系统)1 h雨量资料作为是否降水的类别标签,建立预测降水与非降水的分类模型,降水类的预测准确率在40%~60%,非降水类的预测准确率在90%以上。王宏斌等(2018)利用葵花8号静止卫星的3.9 µm与11.2 µm通道亮温差和3.9 µm伪比辐射率开展中国地区夜间雾的等级识别,结果表明识别1000 m以下雾的击中率HR、虚警率FAR和KSS(Hanssen-Kuiper Skill Score)评分平均值分别是0.71、0.27和0.44;能见度小于500 m的击中率HR、虚警率FAR和KSS评分平均值分别是0.78、0.25和0.53。
本文将结合地面观测和FY-4(风云四号)卫星观测数据,选取利用机器学习分类算法,进行浙江省能见度识别,并将结果插值到高速公路沿线交通站,针对高速公路大雾进行识别检验。
2 所用数据处理和评估方法简介
2.1 所用数据及处理
浙江省金丽温高速公路金华段上布设有两个交通气象站(图1),本文选取离这两个站点最近的7个常规气象站(金华、永康、武义、缙云、义乌、东阳和兰溪)和FY-4卫星数据,进行机器学习分析。

图1 浙江全省常规气象站和金丽温高速金华段交通气象站分布Fig. 1 Distribution of meteorology observation stations in Zhejiang and traffic meteorological sations of Jinhua section of Jinliwen Expressway
气象站数据选取2014~2018年上述7个气象站5年的逐小时气象要素,包括降雨量、风速、风向、相对湿度、气温、最高气温、最低气温、小时最高最低温差、水汽压、最大风速、前1 h最大风速、本站气压、露点温度、最大风风向、10 m风速、10 m风向、前24 h最高最低温差、前6 h最高最低温差共18 h观测要素值。对缺测值和异常值进行了修正,分别得到43824个有效数据样本。
FY-4卫星数据选取2018年全年中国区域的4 km分辨率的13个通道的逐小时数据,分别为0.47 µm、0.65 µm、0.83 µm、1.37 µm、1.61 µm、2.22 µm、3.72 µm、6.25 µm、7.1 µm、8.5 µm、10.8 µm、12 µm、13.5 µm这13个通道数据,其中可见光通道2个,红外通道11个,水平分辨率为4 km的数据,并利用定标表进行定标。利用反距离权重插值到地面7个气象站点所在位置,获得7个气象站的FY-4卫星13个通道的全年数据。由于仅有1年的数据,因此将7个气象站的数据合并进行机器学习训练,得到61320条有效数据。
本文将能见度划分为4个等级进行分类学习训练,分别为小于500 m,大于500 m且小于1000 m,大于等于1000 m且小于10000 m和大于等于10000 m共4个等级(表1)。

表1 依据能见度大小进行4个等级分类Table 1 Four classifications based on visibility
由于这4个分类数据存在不均衡的情况,因此采用过采样和欠采样的方法对不均衡样本进行重新处理。其中过采样的算法采用SMOTE(Synthetic Minority Oversampling Technique)算法,欠采样算法采用随机欠采样函数(random under sampler)。
SMOTE过采样算法不是简单的复制已有的数据,而是基于距离度量的方式计算两个或多个稀有类样本之间的相似性。其基本原理是在近邻少数类样本间进行线性差值,合成新的样本。具体为:假设过采样倍数为N,首先从每个少数类样本的K个同类最近邻中随机选择N个样本,然后将每个少数样本分别与选中的N个样本按照公式(1)合成N个少数类新样本,最后将新样本添加至原始训练集中,形成新的训练样本集。
其中,i=1, 2, …,N,rand[0,1]表示0到1之间的一个随机数,xnew表示合成的新样本,x表示少数类样本,y[i]表示x的第i个近邻样本(王超学等,2014)。通过上述处理,气象站数据的4个分类的样本数分别为1500、3000、7000和10000,卫星数据的样本数分别为500、1000、3000和7000。
2.2 评估方法简介
本文将采用3种评估方法对各能见度识别模型效果进行评估分析,3种方法分别为准确率评分法、分类报告方法、ROC(Receiver Operating Characteristic)曲线方法。
首先对于一个简单的二分类问题,会出现4种情况:如果一个实例是正类并且被预测为正类,则为真正类(TP),如果实例是负类却被预测为正类,则为假正类(FP),相反地,如果实例是负类被预测为负类,则为真负类(TN),若为正类被预测为负类,称为假负类(FN)。
准确率Acy评分法定义为
其中,P为所有正类,N为所有负类。准确率评分法具有一定的局限性,尤其在不平衡数据集中,张晓龙等(2007)发现大数据样本的得分会稀释小数据样本的得分,因此本文还将采用分类报告(如表2)评估结果效果。

表2 二分类问题的分类报告Table 2 Classification report of binary classification problems
准确率Acy、精确率Pre、负正类率FPR和召回率Rre(也即真正类率TPR的计算公式如下:
F1值是精确率和召回率的平均。精确率、召回率和F1值这3个量较准确率更多地考虑了对小数据样本的评估,因而可作为算法评估的又一重要指标。
Drummond and Holte(2004)、Clearwater andStern (1991)、Caruana and Niculescu-Mizil (2004)分析认为ROC曲线具有更客观的评价能力,其以FPR为横坐标,以TPR为纵坐标,因此本文还利用了这一评价方法对模型进行评分。
3 能见度与其他气象要素关系分析及数据预处理
利用随机森林算法对前述降雨量、风速、风向、相对湿度、气温、最高气温、最低气温、小时最高最低温差等18个变量的特征重要性进行排序,通过计算发现7个气象站的排序结果基本一致,以金华站为例(图2),从图上可以看到,相对湿度、小时最低气温、前24 h温差、前6 h温差、气温等几个变量的特征重要性较高。

图2 金华站18个气象变量的特征重要性排序Fig. 2 Importance ranking of the 18 meteorological variables at Jinhua station
计算7个气象站的能见度与上述18个气象要素的相关系数,所得结果基本一致,表3显示为金华站的结果。

表3 金华站能见度与18个气象要素的相关系数Table 3 Correlation coefficient between visibility and the 18 meteorological factors at Jinhua station
从表3中可以看到相对湿度、气温、风速、最高气温、最低气温、最大风速、前1 h最大风速、本站气压、前6 h最高最低温差和10 m风速与能见度的相关系数均大于0.38,且超过了0.001的显著性检验。
图3绘制了金华站2014~2018年能见度的日变化情况,可以看出能见度有着较为明显日变化,白天能见度好于夜间,能见度最大值出现在14:00(北京时间,下同)左右,最低值出现于凌晨05:00前后。通过对不同范围能见度出现频次的统计(图4a、图4b),也说明了这一规律,低能见度出现的频次均出现在后半夜。

图3 2014~2018年金华地区能见度及其相关系数最高的10个气象因子的日变化Fig. 3 Daily variation of visibility and ten meteorological factors with the highest visibility correlation coefficient in Jinhua region from 2014 to 2018

图4 2014~2018年金华地区(a)500~1000 m、(b)200~500 m能见度出现频次的日变化Fig. 4 Daily variation of visibility frequency (a) from 500 to 1000 m and (b) from 200 to 500 m in Jinhua region from 2014 to 2018
相对湿度、气温、风速等要素与能见度相关系数最大,其与能见度的日变化也密切相关。一般而言,白天气温高,相对湿度小,夜间气温下降,相对湿度增大。而温度越高,混合层高度越高,则大气对流运动越强烈,越有利于大雾扩散;相对湿度则影响微粒粒径,当相对湿度较大时,粒子粒径明显增大(白永清等, 2016),根据米散射理论(Bohren and Huffman, 2008)散射效率增大,大气透明度降低,能见度变差。而对于风速而言,在没有明显天气系统影响下,一般由于温度不均匀导致夜间风力变大,对于平流雾、锋面雾及混合雾需要一定的风速维持。
根据以上分析结果,最终模型选择特征重要性和相关系数比较大的10个变量进行机器学习。这10个变量分别是相对湿度、气温、风速、最高气温、最低气温、最大风速、前1 h最大风速、本站气压、前6 h最高最低温差和10 m风速。
4 运用气象站数据进行大雾识别模型建立及效果分析
选取6种机器学习算法进行模型训练,分别是逻辑回归(LR)、线性判别(LDA)、K近邻算法(KNN)、决策树(CART)、高斯贝叶斯(NB)、支持向量机(SVM)。同时将数据以8:2的比例分离为训练数据集和评估数据集,在训练模型中采用了10折交叉验证方法。分别对7个气象站进行机器学习训练,所得结果相差不大,均以金华站结果为例,如图5显示了金华站的6种机器学习方法的得分,基本反映了整体情况。

图5 金华站6种机器学习方法训练集准确率得分比较Fig. 5 Comparison of training set scores of six machine learning methods at Jinhua station
由图5的箱线图可以看到训练集评估得分较高的机器学习方法是SVM,最高得分0.797分,平均得分0.795分。由于SVM方法模拟效果较好,以SVM方法为代表将训练好的模型计算金华站的评估数据集的精确率、召回率和F1值,计算结果如表4,从表中可以看到SVM方法对各分类数据都具有较好的学习效果,尤其是在分类标签为0的分类,即能见度小于500米的分类中精确率和召回率的得分也较高。
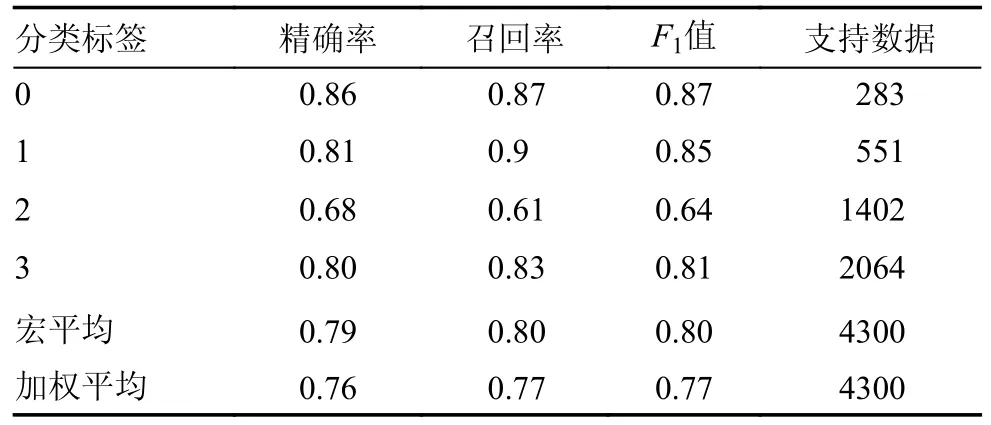
表4 金华站SVM方法的能见度评估数据集分类报告Table 4 Classification report of evaluation data set of visibility using SVM method by weather station model at Jinhua station
绘制金华站SVM算法的ROC曲线,同时将kernel参数设置为RBF(径向基核函数)。图6中给出了每一分类的ROC曲线,且area为计算的AUC指标,AUC指ROC曲线下的面积与单位面积的比,值越大预示着具有较好的性能。

图6 金华站SVM方法的ROC曲线Fig. 6 ROC (Receiver Operating Characteristic) curve of SVM(Support Vector Machine) method at Jinhua
从图6我们也可以看到与表4类似的结果,SVM方法对4个分类的性能排序为第一分类优于第二分类优于第四分类优于第三分类,也就是对能见度小于500 m和能见度在500 m到1000 m之间的性能是最佳的,且其AUC值也最大,说明SVM方法不仅能预测出低能见度事件同时漏报事件也较少,这在实际应用中是比较可靠的结果。
5 运用新一代静止气象卫星数据进行大雾识别模型建立及效果分析
采用与气象站机器学习训练相同的算法和评估方法,如图7为6种机器学习算法的准确率得分比较,图8a–8c分别对应为KNN、CART和SVM算法的ROC曲线。

图7 FY-4卫星6种机器学习方法训练集准确率得分比较Fig. 7 Comparison of training set scores of the six machine learning methods of Fengyun-4 satellite

图8 FY-4卫星(a)SVM算法、(b)CART算法、(c)KNN算法的ROC曲线Fig. 8 ROC curve of (a) SVM method, (b) CART method, and (c)KNN (K-Nearest Neighbor algorithm) method about Fengyun-4 satellite
从图7可以看到KNN算法效果最好,平均得分0.77,其次是CART和SVM,分别对这3种算法再绘制ROC曲线,如图8a–8c。从ROC曲线中看到SVM算法的效果最好,且对第一和第二分类的学习效果是最好的。
再对评估数据集计算SVM方法的分类报告数据,如表5,也可以得到与ROC曲线所示基本一致的结论。对第一分类和第二分类的精确率和召回率的计算结果好于第三分类和第四分类,这将非常有助于对高速公路上大雾、浓雾天气的识别和短临预警。

表5 卫星SVM方法的能见度评估数据集分类报告Table 5 Classification report of evaluation data set of visibility using SVM method by satellite model
从以上分析可以看到,FY-4卫星对低能见度天气也具有较好的机器学习能力,与地面气象站的结果基本一致,能较好地弥补地面气象站不足的问题,可作为低能见度天气识别的有效补充。
上述结果将13个通道的数据都加入了机器学习进行训练,但从卫星各通道数据的重要性排序结果上看(图略),在白天和夜间,不同通道对能见度识别结果的贡献是不一样的。下一节将选取特征重要性更高的要素并结合地面观测和卫星数据分时段建立大雾识别模型,进一步讨论识别效果。
6 结合地面数据和卫星通道数据分时段建立大雾识别模型
结合地面观测数据和卫星通道数据分白天和夜间两个时段建立大雾识别模型。首先,运用随机森林算法对所有要素进行重要性排序,如图9可见,在白天时段特征重要性较高的前14个要素分别是:相对湿度、最低气温、气温、前6 h最高最低温差、最高气温、本站气压、前1 h最大风速、通道4、通道9、通道10、通道11、通道5、通道13和通道1。夜间时段特征重要性较高的前14个要素分别是相对湿度、最高气温、前6 h最高最低温差、气温、本站气压、最低气温、通道9、前1 h最大风速、最大风速、通道10、通道4、通道13、通道8、通道11等。

图9 结合(a)白天、(b)夜间地面观测和卫星通道数据的特征重要性排序Fig. 9 Importance ranking of ground observation and satellite of (a) day time and (b) night time variables
通过查看卫星各通道数据,发现卫星数据几个通道的特征重要性与通道的数据质量有较大关系。在两个可见光通道中,通道1的数据质量好于通道2,所以在白天的特征重要性中,只有通道1的排序较靠前,对于通道4、通道9、通道10、通道11、通道13几个通道数据,其缺测和异常值均较少,因而在白天和夜间的重要性排序中均排名较前。
选取白天和夜间时段特征重要性较高的不同要素建立各自的识别模型,如图10a和图10b的箱线图,白天时段的识别模型效果最好的KNN算法准确率平均得分可达0.83,夜间时段建立的识别模型效果最好的也是KNN算法,准确率平均得分为0.825。

图10 结合地面观测站和卫星数据建立能见度(a)白天、(b)夜间识别模型的6种方法比较Fig. 10 Comparison of training set scores of the six machine learning methods of combining ground and satellite (a) day time and (b) night time data
综合来看,结合地面观测和卫星通道数据建立的识别模型均优于单独数据源建立的识别模型。
7 对浓雾和强浓雾的识别分析
基于实况的短临预警中,高速公路交通管理部门更关注浓雾和强浓雾,本文将能见度再细分为500~1000 m、200~500 m和0~200 m 3个等级进行识别模型的建立。由于特强浓雾(能见度小于50 m)出现较少,对应的数据难以支持机器学习所需要的数据量,因此没有对0~200 m范围内的数据再进行细分。
图11a为利用地面观测数据所做的识别结果得分,图11b为利用卫星通道数据所做的识别结果得分,图11c为结合地面和通道数据所做的识别结果得分。仅地面站数据建立的识别模型中,效果最好的是SVM方法,平均准确率为0.72,仅卫星数据建立的识别模型中,效果最好为SVM方法,平均准确率为0.65;LR方法、LDA方法和KNN方法平均准确率基本一致,约为0.63。结合地面站和卫星数据建立的识别模型中,效果最好为KNN方法,平均准确率为0.88,优于仅地面站和仅卫星通道数据建立的识别模型。

图11 (a)地面观测站、(b)通道数据、(c)地面站和通道数据建立浓雾识别模型的6种方法比较Fig. 11 Comparison of training set scores of six machine learning methods of dense fog recognition with (a) ground observation,(b) satellite data, and (c) ground and satellite data
8 利用机器学习模型对高速公路上的大雾天气识别检验
利用pickle方法分别将地面气象站学习结果和FY-4卫星数据学习结果进行模型序列化和反序列化加载,选取金丽温高速金华段的大雾天气进行模拟。针对气象站模型采取交通站观测数据(该设备能见度观测上限为2000 m)代入7个气象站SVM模型并平均的结果,针对卫星数据采取反距离权重的方法插值到交通站所在经纬度并代入SVM模型的结果,结合地面和卫星数据的模型采用KNN模型。
2019年1月18日凌晨到上午金丽温高速金华段出现了一次较明显的大雾天气,对这一次大雾天气过程进行识别结果如表6所示。

表6 气象站和卫星模型对金丽温高速金华段2019年1月18日一次大雾过程识别结果Table 6 Recognition results of a heavy fog on Jinhua section of Jinliwen Expressway in 18 January 2019 by weather station and satellite model
从表6可以看到,站点识别和卫星识别结果互有好坏,但基本都能够反映出一次低能见度过程,对过程的开始和结束也能较好把握。
利用站点资料和卫星资料能把大雾天气过程识别出来,同时气象站识别和卫星识别结果能较好的互为补充,也就是其中一种方法若识别出现了大雾可以认为实际情况也很可能出现了大雾。同时,与前文分析结果相一致的是,结合地面观测和卫星通道数据建模的大雾识别效果一般略好于单一数据模型的识别效果。但是3种模型的结果都不能很好的把大雾开始的时次反映出来,对大雾结束以后的反映基本可信。
9 小结和讨论
从文中结果可以看到,单独利用气象观测站的数据和利用FY-4卫星通道数据建立的机器学习识别模型对低能见度能进行一定程度的识别,其中支持向量机(SVM)方法的建模效果普遍较好。再进一步结合地面观测数据和通道数据建立识别模型,效果优于单一数据建模,一般以KNN算法效果较好,白天时段的准确率得分为0.83,夜间时段的准确率得分为0.825,且在对浓雾、强浓雾的识别中,也是结合地面和通道数据的KNN算法识别效果更好,准确率得分可达0.88。对于以上结果,我们可以梳理出以下几个结论:
(1)利用高速公路附近气象站数据、卫星通道数据,可以进行能见度识别建模,这很大程度解决了高速公路沿线气象观测站少的问题;
(2)FY-4卫星在辐射成像通道数量和时空分辨率上都是我国最领先的静止卫星,利用FY-4通道数据建模识别大雾,具有覆盖范围广,信息量丰富,时空分辨率高等诸多优势,对于没有地面观测尤其是没有能见度观测的区域,可以利用FY-4卫星在时空观测上的优势,对高速公路上的大雾监测起到有效补充。
(3)机器学习算法相比于天气学方法、统计模型等具有高效、泛化能力强等特点,能够较好的处理大气非线性运动,在实时业务中,可以省去天气形势分析、气象要素阈值调整等环节,机器学习算法的高度非线性变换能力(陈永义等, 2004; 陈锦鹏等, 2021)能够依靠数据的内在函数关系完成结果输出,因此特别需要做好输入变量选择和清洗的预处理工作。
(4)文中的模型识别结果均显示在500 m以下的浓雾阶段准确率更高,反映了浓雾发生时,低能见度与湿度、气温、温差、风速等的强相关关系,对于影响高速公路运行和安全的浓雾及以下的识别结果更具参考意义,可对高速交通部门和运营单位的管控调度提供参考依据。
由于目前用于机器学习训练的样本还不是很多,尤其是FY-4卫星仅使用了2018年一年的数据,导致对浓雾、大雾事件缺乏真实的训练样本支持,因而下一步还可以获取更多的样本进行训练,以提高模型识别效果。文中针对金丽温高速公路选取距离相近的气象观测站点进行机器学习,但是浙江省大雾多发区地形复杂多变,如浙江沿海地区也是大雾多发区,有必要针对不同的地形特征,再按照地形划分建立全省不同地形的能见度识别模型,建立覆盖全省范围的大雾识别模型,可以更好地把握大雾生消的时空演变过程。
猜你喜欢
山花(2022年5期)2022-05-12
环球时报(2022-05-05)2022-05-05
趣味(语文)(2019年3期)2019-06-12
百科探秘·航空航天(2017年10期)2017-11-08
中国交通信息化(2016年6期)2016-06-06
小学阅读指南·低年级版(2016年5期)2016-05-14
海洋气象学报(2016年3期)2016-02-28
气象研究与应用(2016年4期)2016-02-27
气象研究与应用(2016年4期)2016-02-27
