
基于深度学习的人体行为检测方法研究综述
2023-11-07 12:08沈加炜陆一鸣陈晓艺钱美玲陆卫忠
计算机与现代化 2023年9期
沈加炜,陆一鸣,陈晓艺,钱美玲,陆卫忠,3,4
(1.苏州科技大学电子与信息工程学院,江苏 苏州 215009;2.苏州科技大学天平学院,江苏 苏州 215009;3.苏州科技大学苏州智慧城市研究院,江苏 苏州 215009;4.苏州科技大学苏州市虚拟现实智能交互及应用技术重点实验室,江苏 苏州 215009)
0 引 言
随着智能监控设备在学校、商场、交通和其他人群密集的地方被广泛部署,智能监控设备为人们的日常生活带来了安全保障,从而对它的需求也在不断提高。但是一些需要解决的问题和挑战也随之而来,比如如何在错综复杂的环境下对视频数据中的人类行为进行精确检测是一个难点。人体行为检测的核心是结合机器学习、深度学习等算法对视频中人出现的行为进行分类检测,是视频理解的关键技术,也是近年来国内外学者对计算机视觉领域研究的热点[1-8]。
要对人的行为进行准确检测首先需要对人的行为有一定的了解和认识,从而顺利检测出异常事件。研究者可以采集到的视频图像数据已经伴随着智能拍摄设备的发展变得更加多样化[9-17]。用于捕捉行为数据的视频图像类型已经从USCD 等黑白监控数据集[18]变为手势识别数据集[19],从UCF101这个单纯的行为检测数据集[20]更进一步发展为内容中携带着距离信息的RGB-D 数据集[21]。先前的人体行为检测方法已经跟不上数据集多样化、规模化的迅速发展,这对新检测方法提出了更高的技术要求。大多数传统的行为检测方法采用人工提取特征的方式[22],大致可以分为3 个步骤:1)在检测器的帮助下从视频图像中找到兴趣点,如时空兴趣点、运动图等特征;2)使用运算器对兴趣点周围空间特征进行建模,如局部特征聚合描述法;3)将这些提取好的特征送入分类器中得到分类结果,如支持向量机。上述3 个步骤的过程一方面识别精度不是很高,另一方面它们的模型效率也十分低。相比之下,近年来发展迅速的深度学习在目标检测和语音识别等领域应用广泛。基于深度学习的算法模型在处理数据时会模拟人脑[23],通过提取从低级特征到高级特征的有效行为特征,实现了对智能视频监控中出现的行为动作的非线性描述,该方法可以很好地解决深度学习中数据量大、计算需求高的问题,比传统算法更适合视频图像中行为检测。除此之外,国家出台发布的一系列关于“智慧园区”“智慧工厂”等安防工程和智能产业的发展政策也体现了我国对人工智能技术产业这方面的高度关注,并且智能安防领域的投入也会进一步扩大。因此基于深度学习的人体行为检测方法不仅体现了人工智能在社会公共安全领域的应用价值,而且可以进一步提高我国居民社会的生活质量,对经济发展具有重要意义。
本文的目的是对基于深度学习方法的人体行为检测方法进行论述,组织结构可分为如下4个部分:
1)行为检测数据集的简介:选取4 种目前常见的公开数据集并对数据集的内容进行分析。
2)行为检测研究的进展:对目前与深度学习结合的行为识别检测方法进行分析,并总结模型的基本流程。
3)基于深度学习的人体行为检测方法:针对4 种基于深度学习的行为识别检测方法(循环神经网络、三维卷积神经网络、残差网络和双流卷积神经网络)进一步进行分析。
4)现存问题分析和未来方法发展趋势的展望:从模型检测方法存在的局限性和行为人肢体语言的复杂性方面阐述行为检测方法存在的研究难点,同时展望人体行为检测的未来发展趋势及对其进行改良的方法。
1 行为检测数据集简介
目前为了便于验证相关算法的可行性,国内外研究人员搜集整合了多个人体行为数据集供下载使用。本文将常用的人体行为识别检测公共数据集根据其特点和获取方式分为4 类:真实场景数据集、多视角数据集、通用数据集和特殊数据集。本文将涉及的行为检测数据集介绍如表1所示。

表1 行为检测数据集介绍
1)真实场景数据集。
真实场景的数据集,例如好莱坞、UCF 体育等[24-25]主要是从电影或[25]视频采集得出。UCF 体育数据集是由Rodriguez等人从BBC、YouTube等处搜集得来,其中涵盖了广泛的场景类型和视角,从不同的视角拍摄,总共有101 种行为和150 个视频的子数据集。可以把其中动作类别大致分为5 类:人和人之间的互动、人和物体的交互、人在户外的运动、乐器的演奏和人体动作。好莱坞数据集是由Laptev 等人[24]从69部好莱坞电影中收集得来,共有3669个视频,其中包含了12个动作类别:奔跑、散步、殴打、接吻、站立、握手、接听电话、坐下、互拥、进食、驾车、下车。上述介绍的数据集中存在着不规则性的视角、广泛性的行为和多样性的背景的共同规律。
2)多视角数据集。
多视角的数据集,例如PETS、MuHAVi 等数据集[26-27],主要是面向当视角发生变化时行为却不发生变化的标准数据集。MuHAVi 数据集是由来自英国工程和物理科学研究委员会的Singh 等人[27]收集得来,数据集内共有952个视频,其中包含了8个视角的17 种行为:正常行走、醉后行走、跪地行走、来回走、行走摔倒、跨越栏杆、来回挥手、涂鸦、打拳、快速跑步、摔碎物品、看管车辆、向后摔倒、上下楼梯、原地跳跃、脚踢物体、弯腰捡物。PETS数据集是由来自欧盟赞助的Ferryman 等人从现实生活当中收集得来,数据集内共有22个视频,其中包含了4个汽车的不同视角。该数据集主要是针对汽车四周出现的人体行为状况进行收集,根据收集到的视频内容可以将这些样本用于行为预测、目标检测等方面。
3)通用数据集。
通用的数据集,例如KTH、Weiz-Man 等数据集[28-29],主要采集于实验人员在固定场景下的执行动作。KTH数据集是由Schuldt等人[28]收集得来并于2004 年在网上公开发布。该数据集内一共有599 个视频,背景单一固定。主要针对室内、室外、不同衣着、不同放大倍率4种不同背景下的6种动作:正常行走、慢速行走、快速行走、原地跳跃、鼓掌、摇手。Weiz-Man 数据集是由Gorelick 等人[29]收集得来并于2005年在网上公开发布。该数据集内一共有93个视频,视角固定且分辨率低。主要包含了行走、快跑、跳远、侧跳、原地跳、开合跳、挥手、挥双手、弯腰、蹲下这10种不同的行为。
4)特殊数据集。
特殊的数据集,例如WARD、UCF-Kinect 等数据集[30-31],主要通过现代科技(传感器、Kinect 相机等)来捕捉人体行为。WARD 数据集是由美国加州大学伯克利分校的Yang等人[30]通过在人体上放置运动传感器搜集得来。数据集内共有1298 个实验样本,其中记录了20 个实验对象在手腕、脚踝和腰部绑着无线传感器时的13 种日常行为:上楼梯、下楼梯、向左转、向右转、站立、端坐、顺时针转圈、逆时针转圈、快速奔跑、原地跳跃、平躺、前进和推轮椅。UCF-Kinect数据集是由Ellis 等人[31]采集得来,数据集中包含了15 个关节点的坐标方向,共1280 个数据样本。该数据集主要利用OpenNI平台和Kinect传感器对16位青少年实验对象的16 种行为进行记录:向前走、向后走、向左平移、向右平移、攀爬、躲避、搏击、奔跑、跳远、向左扭身、向右扭身、保持平衡、行走、上楼梯、下楼梯和踢腿。
2 行为识别检测
2.1 基于深度学习的人体行为识别检测研究现状
最早开始对人体行为进行检测研究的是1997 年由美国国防高级项目研究局赞助的视觉监控项目组,这项研究旨在对公共场合的场景进行智能监控[32]。国外对人体行为检测的研究自此开始,陆续展开[33-38],其中就有来自波士顿大学和佛罗里达大学的计算机视觉实验室。与国外率先开展的研究相比,中国的相关研究起步虽然较晚,但随着智能监控的迅速发展,已经开展了一系列的研究。在深度卷积神经网络在计算机视觉任务中取得成功之前,各种传统行为检测(手工提取特征)是比较流行的方法。这些手工制作的特征通常提取颜色、纹理或边缘信息,如最广泛的手工特征之一是定向梯度直方图(HOG)。此外,大多数现有的基于手工制作的方法要么采用通道特征,要么采用可变形部件模型作为基础模型学习机制。它们被输入到经过训练的行人检测器中进行预测(分类)。由于现实世界中的行人出现在不同的尺度上,输入的图像首先被调整为不同的尺度,然后检测器被应用在每个尺度上以获得预测。传统的手工提取特征在预测准确性方面是可取的,但这些方法过于繁琐,消耗大量的人力和物力以及繁琐的操作步骤且易受人为因素影响。其中来自中国科学院的Zhang 等人[39]将GMM 方法和K-Means 方法相结合对目标对象的行为进行分类,进一步建立了异常行为分类的数据集。为了做出一个更优的异常行为检测系统,香港中文大学的Li 等人[40]在模型特征提取的时候融入了人体骨骼点的几何数据,大大提升了检测效率和精度。
伴随着计算机的迅速发展,计算资源的计算力和计算速度也逐渐成熟。近年来,多种类的基于深度学习的行为预测模型方法发展迅速,许多学者和他们所在的研究机构将卷积神经网络等深度学习方法用于视频图像的行为分类算法研究。相关研究进展如表2所示。

表2 基于深度学习的行为检测方法的研究分析
2.2 行为识别检测流程
正常对人体行为进行检测一般有3 个步骤:跟踪目标及精确检测、提取模型所需特征和利用模型进行识别。
1)跟踪目标及精确检测。
目标跟踪主要负责在指定的背景环境中定位到感兴趣的位置和类别。它是行为分析和检测的基础,目前常用跟踪方法有基于目标轮廓的跟踪、基于模型的跟踪、基于特地特征的跟踪和基于选定区域的跟踪。而目标检测的任务是在找到兴趣点之后更进一步确认它们的类别和位置坐标。如何快速稳定准确地定位目标是它的研究核心,目前常用的目标检测方法有帧差法、背景差法和光流法。
2)提取模型所需特征。
特征提取主要负责用特征向量的形式来表达图像中被提取出来的数据,方便接下来的进一步分析解读。目前常用的可提取的特征有时空特征、运动特征、外形特征以及上述两两结合的混合特征。
3)利用模型进行识别检测。
行为识别检测负责将未知行为特征数据和已知行为特征数据进行比对,通过二者的比对来对未知行为进行分类,相似度高为同一类,反之则不是同一类。其算法内涵可以看成时变数据的分类问题。目前常用行为识别检测方法有利用状态空间和利用模板匹配的方法。
3 基于深度学习的人体行为检测
特征提取的方法在传统意义上可以大致分为2个部分:一是基于人体骨架动作几何信息;二是基于时间和空间二者结合在一起的兴趣点提取。这些方法中的行为特征一般是通过肉眼观察或手工设计辅助工具来提取。但是传统的人工特征在处理不同的复杂场景(如光照和遮挡)时并不通用,而基于深度学习的方法可以很好地解决这个问题,使得特征提取的学习效率更好。基于深度学习的人体行为检测方法将视频图像中包含的特征提取出来,进行端对端的自学习,进而训练模型实现行为的分类。本文对目前常见的基于深度学习的4 种人体行为检测方法(基于循环神经网络的检测方法、基于三维卷积神经网络的检测方法、基于残差网络的检测方法和基于双流卷积神经网络的检测方法)的流程进行了概括,如图1所示。
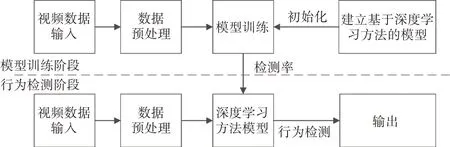
图1 基于深度学习的人体行为检测方法流程图
3.1 基于循环神经网络的检测方法
传统的神经网络在深度学习领域由于其独立的输入输出取得了良好的进展,但随着针对性更强的进一步深入研究,该神经网络在表示外界声音和动态图像等信息时,会丢失部分有价值的信息从而导致整体和部分被割裂无法学习。因此,引入循环神经网络来解决上述问题,其网络结构如图2 所示。基于循环神经网络的行为检测方法是针对输入视频数据中人员动作间的时间相关性,高效处理视频帧与视频帧之间的时间特征,但是由于速度的提高损失了一定的精确度。其中,Xt∈Rx表示t时刻的输入;Ht∈Rh表示t时刻隐藏层的输出,假设该层有h个神经元;Ot∈Ro表示t时刻的预测输出。针对可能出现的梯度消亡问题并加以解决,目前的行为预测研究中一般是对普通RNN 进行变体建模,如Hao 等人[14]提出的长短时注意力机制RNN模型-LSTM,其在UCF101数据集上取得了88.9%的识别准确率,具体单元结构如图3所示。

图2 循环神经网络结构

图3 LSTM单元结构图
基于循环神经网络的方法不仅可以将前一刻出现的信息及时捕捉,而且在下一刻的应用计算中可以有效利用。这样能够很好地连接2 个相邻帧之间的人体行为的时序特征从而提高在建模时的效率,但该方法的识别准确率还有待进一步提高。Donahue 等人[44]将CNN与LSTM相结合,提出了长时递归卷积神经网络(Long-term Recurrent Convolutional Network,LRCN)。输入是单独的图片或视频中的一帧,通过对视频数据进行特征提取,得到一个定长向量,用于表示数据特征,然后将其放到LSTM 中学习,最后得到视频数据的行为特征,实现对目标行为的检测,在UCF101 数据集上获得了82.92%的平均检测率。虽然在时域动态的特征建模和学习这2 个方面RNN 的表现令人满意,但传统的循环神经网络的时间序列会随着算法序列增大,解决不了长时依赖的问题,进一步还可能会导致梯度消亡。
3.2 基于残差网络的检测方法
在综合学习中,可以利用残差进行基础模型构建来达到模型的高准确性。在统计学中,实际计算值与估算值之间的差距就是残差。而在深度学习中,也可以利用各层残差的拟合特性提高深度神经网络的性能。图4 为残差网络的基本结构。传统上为了解决梯度存在的问题会初始化并正则化数据,但这样做也加深了网络深度导致模型性能不高等问题。相比之下,使用残差使得训练一个有效解决梯度问题的深度网络变得容易。通过将网络梯度流从后网络层连接到前网络层,可以提高网络性能,从而加强行为检测。

图4 残差网络基本结构

图5 双流卷积神经网络结构图
图4 中,输入x是F(x)的残差,F(x)是经过第一层线性变换并激活后的输出。如果学习的特征为H(x),残差F(x)=H(x)-x,则原始学习特征为F(x)+x。图4 中表示在残差网络中第二层进行线性变化激活前,F(x)加入了该层输入值x后再激活后输出。此外,Feichtenhofer 等人[68]将残差网络和图像识别相结合,发现在面向小规模数据集时利用残差网络的2D卷积神经网络的识别效果很优秀,但在处理大规模数据集时不如3D残差神经网络。
残差网络中的残差包含了图像的信息,图像信息的优点是可以原样传递下去。而图像的详细信息又被用另一个恒等的残差保存了下来,从而在卷积层层面上有利的东西就很少。但对于一些深度较深的网络而言,它们训练残差网络时存在梯度爆炸和梯度消失的问题,就会造成传输的信息丢失。残差网络可以针对上述这些问题使输入信息绕道传到输出即跳跃链接信息。这样不仅带来了传递信息时的稳定性,也缓解了由于增加网络深度带来的梯度消失问题,同时也简化了模型学习的难度。
3.3 基于双流卷积神经网络的检测方法
日常生活中的视频信息可以由空间和时间2 个部分组成,在视频中的表面信息如人体、环境等是空间部分,而一对视频帧之间存在的信息如目标物体和捕捉仪器之间的动态变化则是时间部分。双流卷积神经网络方法的特点在于它可以得到2 个CNN 网络的预测结果,其中一个是RGB 图像,而另一个是光流场内含信息图像。分别将这2 种信息输入到一个CNN 网络中之后,再融合它们的预测结果,从而达到更优的结果。
Ji 等人[69]认为双流卷积神经网络结构应该由2个深度网络组成,因此作者提出了一种基于双流网络结构的行为检测方法,分别负责处理时间流卷积神经网络时间和空间流卷积神经网络空间维度。先将图像序列信息从视频帧和视频帧之间的光流信息计算得出,接着将视频帧进行时间特征的叠加,再将RGB图像内的空间特征利用空间流卷积神经网络提取出来,最后把这2 个网络的预测结果融合得到最终结果,取得了88.0%的精确度。Feichtenhofer 等人[70]在TSN 基础上做了优化提出STResNet 方法,针对不同尺度的时间信息采取相应的方法行为识别,在时域上进行了扩展得到了更加优异的结果关系。基于双流卷积神经网络的检测方法结构图如5所示。
卷积神经网络有2 个特点:参数共享和局部感知。参数共享的结构与生物神经网络的结构相似,它降低了网络背景下的模型复杂程度,减少了权重量,从而使得在面对如放缩、平移旋转等简单变化时抗干扰能力强。而且卷积神经网络跳过了对海量样本复杂特征进行提取这一步,直接将原始图像输入进去,从而提高了模型的学习效率。相比静态图像分类,视频的时序成分为行为识别检测提供了额外的线索(运动信息),并且会对视频中的每帧图像进行同步数据增强[68]。局部感知即卷积神经网络不需要在底层就感知图像信息中的每一个像素,而只需要感知局部像素,感知完毕后再在更高层上总括这些局部信息。每一层与每一层之间的神经单元只有部分相连即局部连接,这种连接的方式使得将要输入到已经学习完毕的卷积核中的空间局部模式可以产生最强的响应力。但是双流网络提取到的时序动作特征不是很全面,只能提取前后帧的时序动作特征,因此CNN 对于视频序列的时序特征学习效果不是很好。
3.4 基于三维卷积神经网络的检测方法
基于双流卷积神经网络的检测方法在针对视频中行为信息的识别效率是十分高的,通过让模型学习前后帧运动信息中包含的特征,计算出每2 帧的密集光流后将密集光流图像序列输入。该方法虽然识别率较高,但需要对视频中的光流图像信息进行预处理,而且训练时2 个网络是独立运作的,这样就导致了时间成本的增加且无法达到实时性的效果。
为了解决普通神经网络中出现的参数膨胀,研究者们提出了卷积神经网络,即CNN。整个行为识别检测的全连接神经网络过程中,它在卷积的前向计算过程加入了权重,而且是用非线性函数来表示的卷积层面输出结果。目前,大多数学习单帧图像的CNN特征都是基于二维的卷积神经网络。但这类方法忽略了帧与帧之间的内在联系,在特定的情况下会将关键信息丢失,因此基于三维的卷积神经网络成为新的选择,这种对视频中关键特征信息有保护作用的三维卷积神经网络是重要的人体行为检测方向之一。三维卷积神经网络的结构如图6 所示。目前为了减少计算量,使得三维卷积神经网络结构简单,主流的有C3D 算法[71],该方法将卷积核变小,精简了网络结构;I3D 算法[72],该方法将光流的切片和堆叠在一起的多个RGB 帧包含在2个3D网络中;P3D算法[73],该方法利用RESNET 方法构将网络构建出来,并且利用残差、并行和串行的方法将小卷积核连接起来;R(2+1)D[74]算法,该方法将三维卷积分成先执行的2D 空间卷积和其次执行的1D 时间卷积,使得时空信息处理的非线性化提升。Ji 等人[69]首先针对传输中的视频数据内的动态信息进行跟踪捕捉,对图像视频数据中存在的时空特征进行有效提取,并在此研究基础上提出了基于三维卷积神经网络的行为识别检测。接着对硬连接层生成的光流通道、梯度通道和灰度通道进行卷积和下采样操作。最后将所有通道信息串联起来,实现最终的行为表示。该网络在UCF101 数据集获得了85.2%的准确率。三维卷积神经网络的优点是提取视频中出现的时空特征很方便,但相对于二维卷积神经网络的网络结构参数量较大较复杂[75],在数据量没有达到一定样本的时候使用该模型易产生过拟合的问题。

图6 三维卷积神经网络结构
3.5 不同算法类别之间的性能差异
本文选取几种典型的算法在3个具有一定难度系数并且视角变化多、背景混杂强的数据集(UCF-101数据集、KTH数据集和Kinect数据集)上的表现,分析它们的优势和存在的不足之处。这3 个数据集得到业界的认可,不同算法类别在数据集上的表现见表3。
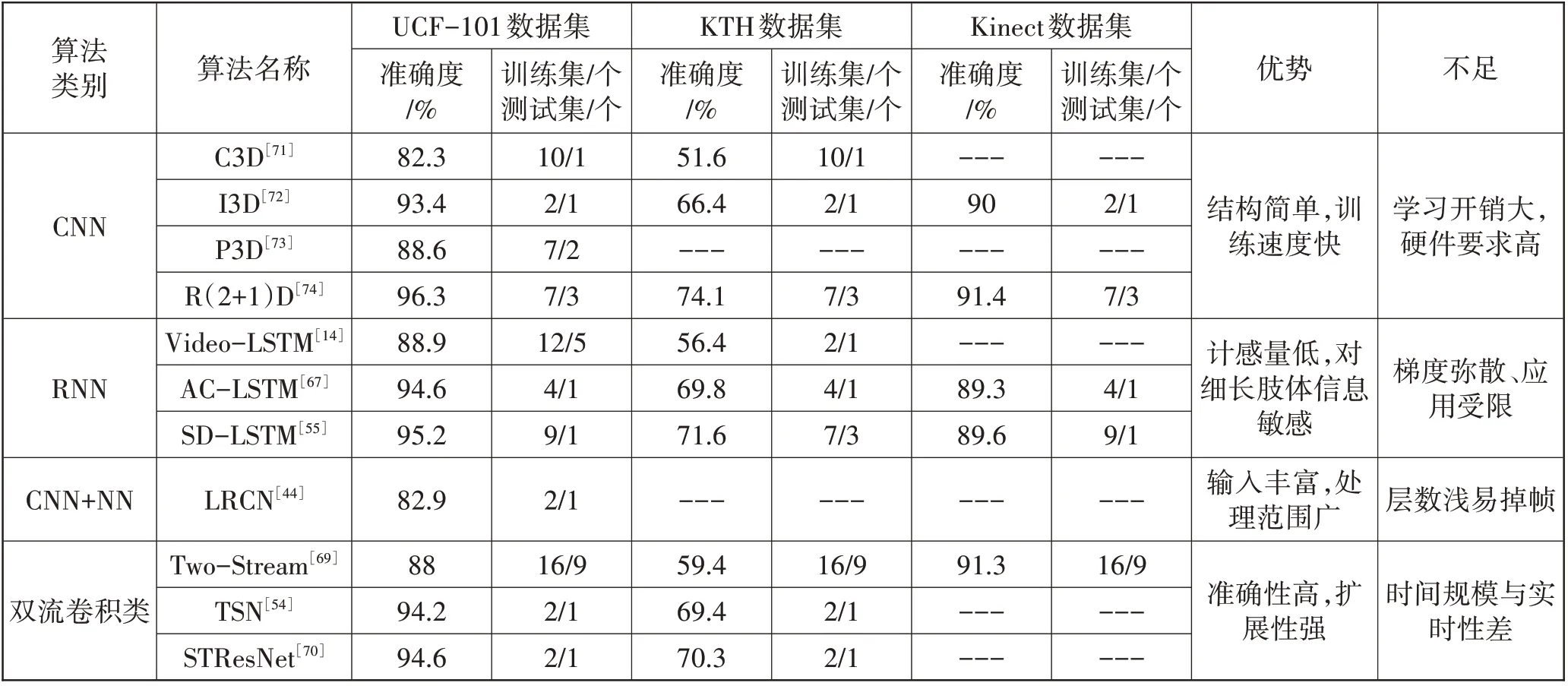
表3 不同算法类别在数据集上的表现
4 发展趋势与现存问题分析
人体行为检测是一个多学科的研究领域,涉及许多技术层面,被广泛应用。其发展趋势一方面是相关技术的发展,如深度学习方法,另一方面是实际应用需求的变化,如大规模监控环境中的群体行为识别检测。
4.1 发展趋势分析
1)数据采集的大数据化趋势。
随着不断进步的技术,采集的数据形式由简单的二维RGB 图像到后来复杂度提升的三维图像序列和四维RGBD 图像序列,从单一视角和固定环境到多变人体的姿势视角和环境照明和其他采集条件。许多新的人体运动传感设备不断涌现使从多个来源和多种方式收集人体运动数据成为可能。此外,大数据采集和数据的自我标注将是行为识别检测领域的研究趋势之一。用于训练的行为数据的质量和规模对行为算法的结果有很大的影响,特别是在应用深度学习方法时,这进一步加强了识别算法的数据依赖性,导致加大了对大数据采集的需求。2)行为检测发展趋势。
目前行为检测发展趋势可以大致分为:①高层次人体行为理解研究:目前,虽然在单一的行为检测方面取得了突破性进展,但非刚性的人体和高水平的复杂特征问题仍然是难以克服的困难。此外,对人类行为的理解还局限于简单行为和标准姿势的识别和分析,如何优化行为检测算法,实现对人类行为的高度理解和描述,是当前研究的一个挑战。②结合注意力机制的群体行为检测研究:在现实生活中,人类活动不仅仅由单个人独立完成,更多是取决于群体活动。因此,如何将单一的个体特征扩展到用群体特征表示也是一个重点。大部分情况下,深层网络比浅层网络更有效,而使用注意力机制可以使网络结构往更深层次选择关注位置,产生更具分辨性的特征表示。在原有的网络基础上加入注意力机制,产生更有效的高级特征,便于群体的行为识别。③结合语音信息的识别研究:人类行为识别检测中的行为检测和分析将不仅仅是一项理论研究,而是要在网络、算法和感知方面进一步接近社会的实际需求,进行更广泛的研究。此外,人类的语音信息内容丰富,但容易受距离和环境的影响,而现阶段的行为理解研究仅限于具体的姿势识别,一旦姿势视角发生变化,机器没办法迅速调节。如何将相对独立的语音和视觉2 个部分有效结合在一起分析,从而促进机器学习理解实现更好的行为识别检测,将是未来的趋势和挑战。
3)模型性能与算法效率并行的趋势。
目前建立多特征融合的行为识别检测模型和更复杂的表示模型比单一特征表示模型的识别效果更好,但行为识别检测算法的模型的复杂程度越高,不可避免地带来算法效率变低的问题。所以从发展的角度来看,将低延迟的高性能算法和特征融合的模型两者并行提高是符合技术发展的必然趋势。
4.2 现存问题及研究难点
近年伴随着人工智能技术的发展,异常行为检测也取得了很多成就,而异常行为检测的主流趋势就是针对人体的行为检测。虽然目前有很多利用机器学习方法的人体行为识别检测技术,但从整体上看,仍有许多研究难点有待解决。
1)实地具体部署困难。由于不同年龄、不同性别和不同心理等不可控因素的影响,并且人体行为具有高复杂性从而无法准确预判下一步,这就对智能设备的算力水平提出更高的要求,同时较高的复杂度也给实时检测带来了难题。所以在大范围监控环境的应用需求下,如何保证模型识别精度的同时降低其群体识别的复杂度,具有较高的研究价值。
2)缺少大规模的数据库。人体行为预测的训练需要大量标签完整的数据,但是由于多样的环境和人体行为动作类别并且拍摄角度受限,导致了现实中对多变场景内的样本采集变得相对困难,从而导致样本数量的缺少,无法进行高效的训练。即使提出使用无监督对抗网络的方法来对有标签的数据集进行调整,从而降低对人工标签的依赖性,但是无监督或半监督的发展还不够成熟,在训练过程中会出现各种问题,所以如何在样本数据减少的同时,还能继续保持模型算法的高性能和准确,仍需要进一步探索。
3)受限于硬件的水平。基于深度学习的行为检测方法由于受到使用工具GPU 和CPU 处理器等硬件条件的限制,没有办法直接将整个视频或者多个连续视频输入到算法模型当中进行特征提取,不能达到实际应用的要求。只能利用视频中出现的连续帧当中包含的冗余信息来替代整个视频,这样可能会导致关键信息的缺失而且无法将运动信息很好区分开。所以如何根据现有设备提高识别精度,并且是否可以利用手机等小型设备辅助人体行为检测可能是未来的研究热点。
4)跨场景适应力差。目前的行为识别检测模型大多是在指定的场景下进行训练,场景单一化。当场景发生变化时,模型需要迁移到新的场景中重新进行训练,增加了大量的时间成本和人力成本。而且行为预测旨在准确判断安全隐患和保护人员安全,当下很多算法只做到了事后检测,没有办法准确事前预测。因此对于如何在模型中融入环境信息,在实时视频流中遏制可能存在的安全问题的领域研究还需要进一步的深入。
5 结束语
人体行为检测最初的研究是从简单的人体行为信息分析开始,接着伴随着科学技术的不断发展,逐渐开始了对特定性行为和非特定性行为进行识别检测,最后发展到从更高层次角度对提取出来的行为信息进行分析。
从目前的研究现状来看,对人体行为检测方法的发展在理论研究的层面停滞过久,未来在算法、网络、感知等方面还需要努力适应人体行为的实际需要,继续深入研究。从目前的发展趋势来看,基于深度学习的识别方法无疑是一种非常有效的人体行为检测手段,很有前途并保持研究热点。相信随着科学技术的不断进步,未来的人体行为检测会更加地方便实用、抗干扰能力强、应用广泛,并且可以与智慧建筑、智能工厂和智慧园区建设等社会领域相融合,在社会公共安全等方面发挥重要作用。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
小哥白尼(趣味科学)(2022年1期)2022-04-26
大科技·百科新说(2021年10期)2021-12-31
北京航空航天大学学报(2021年9期)2021-11-02
基层中医药(2021年5期)2021-07-31
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
电子制作(2019年11期)2019-07-04
特别健康(2018年3期)2018-07-04
北京航空航天大学学报(2018年1期)2018-04-20
