
基于极大熵的Web服务资源个性化推荐方法
2023-11-07 12:09杨柳青
计算机与现代化 2023年9期
杨柳青,王 冲
(1.玉林师范学院教育技术中心,广西 玉林 537000;2.桂林电子科技大学商学院,广西 桂林 541004)
0 引 言
在互联网技术发展环境下,无论是企业还是个人都开始广泛应用计算机Web 服务,随之带来是Web服务资源成倍增长的问题[1]。在海量的Web 服务资源中,如何根据用户的个性化需求,向其推送合适的服务资源[2],成为当前重点研究问题。现有的资源推荐方法存在资源推荐准确性较差的问题,难以满足个性化推荐要求。
文献[3]提出的推荐方法以用户复合情绪标签为核心,针对用户的不同情绪设计相应的情绪标签,再按照情绪标签来搜索相关的信息资源,计算情绪标签与资源对应情绪标签的相似度,得到个性化推荐结果。但是,该方法耗费时间较长。文献[4]深入分析传统资源推荐方法存在的问题,设计了改进型资源推荐方法,采集用户行为数据,以及用户对资源的具体评分,为每个用户打上相应的兴趣标签,根据兴趣标签计算用户相似度,参考相似用户的资源喜好,生成针对目标用户的推荐方案,但是,该方法计算复杂度较高。文献[5]以提升服务资源推荐质量为目标,根据用户交互行为,建立个性化推荐基础框架,依托于用户需求偏好,得到最终资源推荐结果,还应用了模糊聚类原理划分了用户群,结合交互反馈结果进行资源推荐服务的更新,但是,该推荐方法在应用过程中极易面临用户数据稀疏问题。
本文以提升Web 服务资源推荐质量为目标,参考上述文献提出推荐方法的优势,建立以极大熵为核心的个性化推荐方法。以用户兴趣为依据,设计Web服务资源评分分类的概率预测模型,结合约束条件输出最终个性化推荐结果。
1 基于极大熵的Web服务资源个性化推荐方法设计
1.1 提取用户隐式行为特征
为了更好地描述用户兴趣特征,以历史操作记录为基础,对用户隐式行为特征进行分析[6]。用户隐式行为特征的提取,可以从用户特征、商品特征、交互特征3 个方面入手[7]。针对用户特征进行深入分析,可以清晰地观测到Web 用户的独特需求,用户特征分析方法如图1(a)所示,以此为基础可以明确用户对Web服务资源的下载过程,获取与资源下载相关的用户行为,再通过统计学得出用户的相关特征。资源收藏到资源下载之间的转换率,是衡量用户特征的关键指标[8],转换率越低表明用户具有“挑剔”的特点。
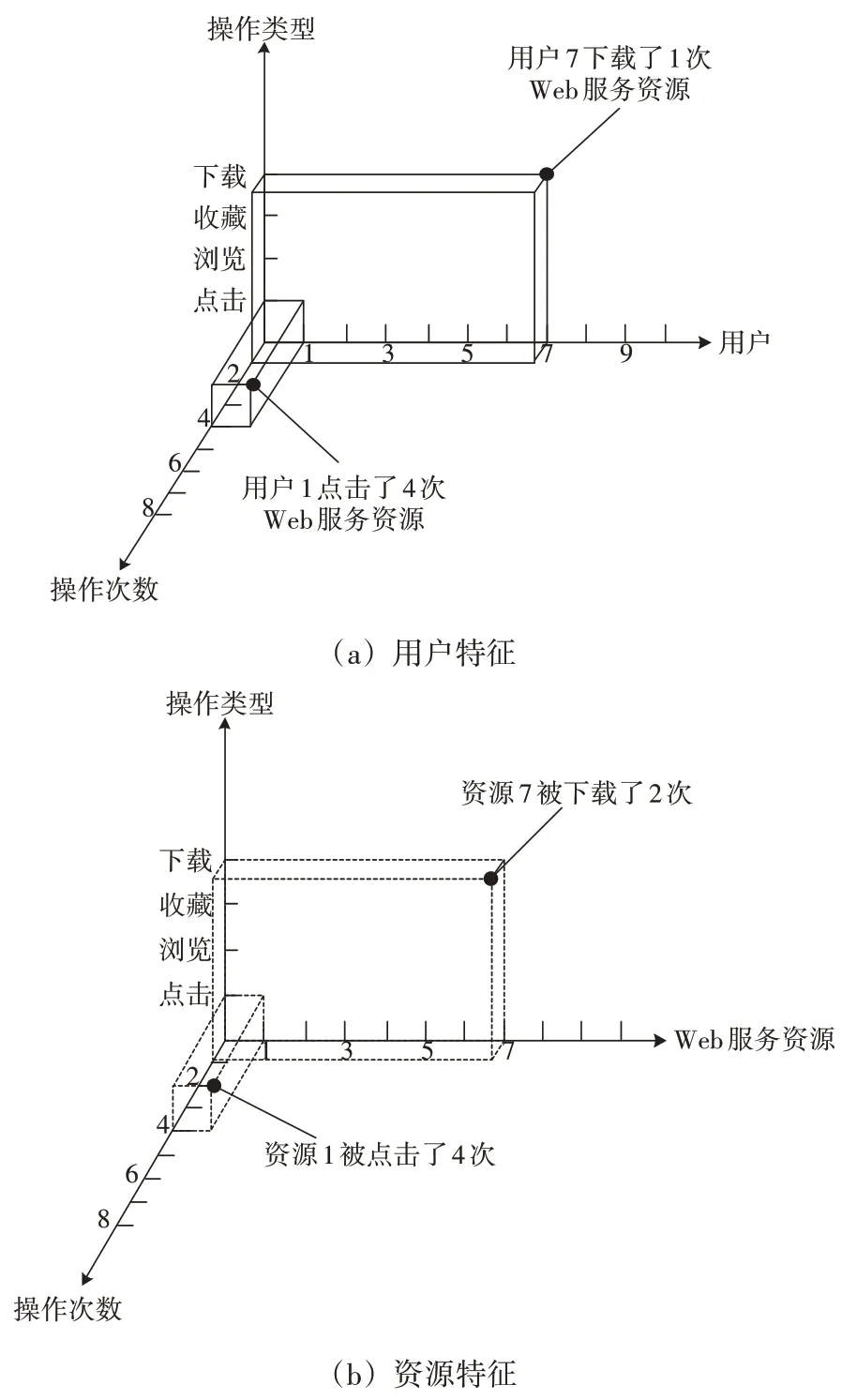
图1 用户特征与资源特征示意图
图1(b)为Web 服务资源特征,从资源自身角度入手,提取用户隐式行为特征。简单来说,资源利用率越高表明其竞争力越高。与用户特征和资源特征不同的是,交互特征作为一个桥梁,直观呈现出特定用户与特定商品之间的关联性,在历史操作信息中交互特征的相关行为最少,但是其所包含的信息重要程度最高。
汇总所有用户隐式行为特征构建基础特征集合,再提取出与时间间隔相关的特征[9]。通过特征筛选、特征组合的处理方式,将具有较高区分度且可以发挥不同组合分类效果的特征提取出来,建立高阶特征子集,达到提升提资源推荐精度的目的。本文以Tree Ensemble Model S 树为基础,将每一个特征看作一个建树分类条件进行特征筛选,实际建树模式如图2所示。

图2 特征项建树示意图
Tree Ensemble Model S 树的输入为高阶特征子集中的特征项[10],并应用CAR-T 分类器建立基函数进行计算。每个特征项计算结束后,就生成一棵树,树内叶子结点与用户隐式行为特征相对应。建树过程中,针对每个节点设置合适的阈值,将大于阈值的特征划分为右子节点,反之则放置于树左侧,这棵树即为特征组合规则。运用图2 所示的建树模式,对高阶特征子集内所有特征项进行计算,得到组合筛选后的特征集合。
1.2 构建Web用户兴趣矩阵
以用户隐式行为特征为基础,利用协同过滤算法聚类Web 服务资源[11],确保后续个性化资源选取工作的顺利进行。由于用户隐式行为特征会受到社区的影响发生直接变化,也就是说用户行为与社区之间存在强关联[12],本文采用协同过滤方法挖掘用户与社区之间的联系。从线下数据入手,获取Web 用户群信息、Web 服务资源信息以及资源评分信息,并通过图3 所示的用户- Web 服务资源二部图,表现特定用户与特定资源之间的联系。

图3 用户- Web服务资源二部图
根据二部图明确用户与Web服务资源之间的关联,根据用户对某项资源的评分,可以设置兴趣权值,以此来描述用户的偏好。依托于用户、项目关系图,建立邻接矩阵[13]。
其中,E表示邻接矩阵,e表示资源与用户之间的关联度,a表示用户数量,b表示服务资源总数。
用户的行为特征会受到其他用户的影响[14],而主要的影响方式包括评论和回复2 项内容。用户之间评论影响关系I(i,j)、回复影响关系U(i,j)计算公式分别为:
其中,i、j表示2 个用户,I表示评论影响值,U表示回复影响值,l表示资源评论,L表示评论总数,p表示资源回复,P表示回复总数,H表示用户i受到用户j评论影响次数,G表示用户i受到用户j回复影响次数。
根据公式(2)和公式(3)得出的评论和回复影响值,可以清晰地看出用户对其他用户行为的影响,再融合影响参数,得到用户影响关系矩阵:
其中,λ表示评论影响参数,θ表示回复影响参数,M表示用户影响关系矩阵。结合用户影响关系,更新初始用户兴趣矩阵,重构为新的Web用户兴趣矩阵,将其作为下一步极大熵资源个性化选取算法的输入内容。
1.3 设计极大熵服务资源选取算法
为了避免个性化推荐结果偏离用户要求,本文设计极大熵服务资源选取算法,预先设置一个独立性假设条件[15],只需要考虑特征之间是否满足该条件,实现服务资源的选取,不需要参考其他数据。因此,本文针对用户对资源的评分,建立一个预测函数:
其中,r表示用户,g表示资源,s表示资源符合用户要求的概率,D表示预测函数,X表示用户行为特征,y表示分类结果。当概率计算结果高于设定阈值,表明该Web服务资源是用户所需的资源。
实际操作过程中,设置一个训练数据集,并从中选取一个样本进行计算。定义一个特征函数[16],分析样本特征和与用户兴趣矩阵之间的联系,再应用最大熵计算原理,将公式(5)所示的条件概率表示为:
其中,Z表示归一化因子,φ表示特征权重因子,T表示特征函数的重要程度,exp表示指数函数。
考虑到特征函数是以用户隐式行为特征为基础,也就是构成函数的主要特征类型,包括用户特征、资源特征以及交互特征,对于每一类型的特征设置相应的权值参数[17],实现条件概率计算过程的简化。最大熵服务资源选取算法的参数学习,本质上是要计算出最大特征权重,本文利用迭代优化的计算原理,设计参数更新公式为:
其中,d表示迭代次数,C表示常数,A表示经验分布下特征函数期望值,B表示理论模型下特征函数期望值。
其中,常数取值为最大特征数量。当前后2 次迭代计算结果的差值过小,表明此时参数更新结果满足收敛要求。根据满足收敛要求的最优参数,完成条件概率计算,按照条件概率结果分析该Web 服务资源是否为用户所需的资源,完成服务资源选取。
1.4 生成个性化资源推荐结果
运用最大熵算法进行Web 服务资源选取后,需要选取合理的特征约束条件[18]。本文对预测资源评分分类的影响因素进行研究,提出资源推荐的约束条件,包括用户属性和资源评分矩阵2项内容。
其中,用户属性约束条件的建立,是由于Web 用户群涵盖多种人群,不同人群的兴趣爱好差异较大[19]。因此,人群自身属性直接影响了用户行为[20]。本文提出在资源推荐过程中,根据用户年龄、职业等属性,对用户群体进行划分,并保证每个子群体具有同样的属性特征。
而资源推荐过程中,资源评分矩阵约束条件的建立是以用户自身兴趣为基础[21]。根据用户兴趣矩阵,对每一项特征进行训练[22]。在训练集合中,确保特征的经验期望值和模型期望值相同,具体表达式为:
其中,k表示用户属性集,N表示特征在训练集合,n表示训练样本,ψ表示属性,η表示预测概率,μ表示特征。
汇总用户评分矩阵与用户基本属性,构成训练集合,将已有的资源评分作为输入条件,计算出用户对其他Web 服务资源的选择概率值[23],从中选定概率值最大的资源作为最终推荐结果。具体个性化推荐整体模型如图4所示。

图4 个性化推荐整体模型图
2 实验与性能分析
2.1 数据集
个性化推荐方法设计完成后,为了证明其可行性,需要进行实验。考虑到本文研究内容主要针对Web 服务资源推荐问题,选取Movie Lens 站点作为数据采集中心。它是一种基于标签的数据集,由美国Minnesota 大学计算机学院的GroupLens 项目组建立,该项目组是一个非盈利性的实验组织。此数据集描述了5 星内电影的无限制标记,用于提供用户推荐。采集站点内850 名用户对1650 个电影项目的评分信息,充当实验所需的数据集。
以最大熵为基础建立的个性化资源推荐方法,主要环节是建立用户选择资源的概率预测模型。因此,实验开始之前,针对实验数据集中的评分信息进行统计,从项目的角度得出图5 所示的电影项目评分次数统计结果。

图5 电影项目评分次数统计图
为了避免数据单一问题,在Google Dataset Search(https://toolbox.google.com/datasetsearch)数 据库选择1200条数据进行评分,得出图6所示图书数据的统计结果。

图6 图书数据评分次数统计图
根据图5 与图6 所示的数据统计结果,绘制相应的社区网络,并将其放置于SQL Server 数据库内,作为资源个性化推荐方法实验基础。
2.2 参数分析
由于最大熵资源选取算法的应用属于自适应学习模式,在Movie Lens 数据集中包含138493 个用户的20000263个评级和465564 个标签,涉及27278个电影。用户是随机抽取得到的,并且每个所选用户至少对20 部电影进行了评分。每个用户只有一个ID,不涉及其他私人信息。参数分析过程中,随机选取Movie Lens 数据集中30 个待推荐资源和1 名用户,设置不同的适应度参数和特征取值参数,分别记录不同条件下向用户推荐的资源,再计算用户下载资源数量与总推荐资源数量之比,明确资源推荐准确率变化情况,参数取值的影响结果如表1所示。

表1 实验参数对准确率的影响
根据表1 可知,分别设置近邻个数为10、20 和30,对比不同步近邻个数条件下,参数变化对准确率的影响。通过分析可知,当λ=0.1,θ=1.0时,资源推荐准确率最高,达到了0.74、0.95 与0.89。而其他参数条件下,资源推荐准确率都比较低,因此,本次实验将参数设置为λ=0.1,θ=1.0。
2.3 推荐方法性能分析
2.3.1 Web服务前端性能评测
为了进一步验证本文方法的Web 服务资源个性化推荐效果,以IE网站为例,根据Baidu的page speed对其Web 服务前端性能进行评测。该评测最终结果的得分是所有指标评分的加权算数平均值。评测的总分为100 分制,分为3 个等级,低于50 分为差,50~89 分为较差,90 分以上为优。对IE 网站的Web 服务前端性能进行评测,最终的评测结果为46 分,该网站Web 服务前端性能差。通过的测试(评测结果为优)指标结果如表2所示。

表2 通过测试的指标结果
以上结果表明,本文方法能够有效获取Web 服务前端性能识别结果,对Web 服务资源具有较好的推荐效果。
2.3.2 推荐序列对比
为了得出本文设计推荐方法的应用性能,随机选定一个用户以及50 个待推荐资源,进行资源推荐实验,针对选定的资源进行排序,并保持资源顺序不变,应用本文提出的Web 服务资源个性化推荐方法,向该用户进行资源推荐。此外,采用基于本体推理的推荐方法、基于智能计算的推荐方法,获取资源推荐结果。将3 种方法的资源推荐结果以推荐序列的形式呈现出来,形成图7所示的推荐序列对比图。
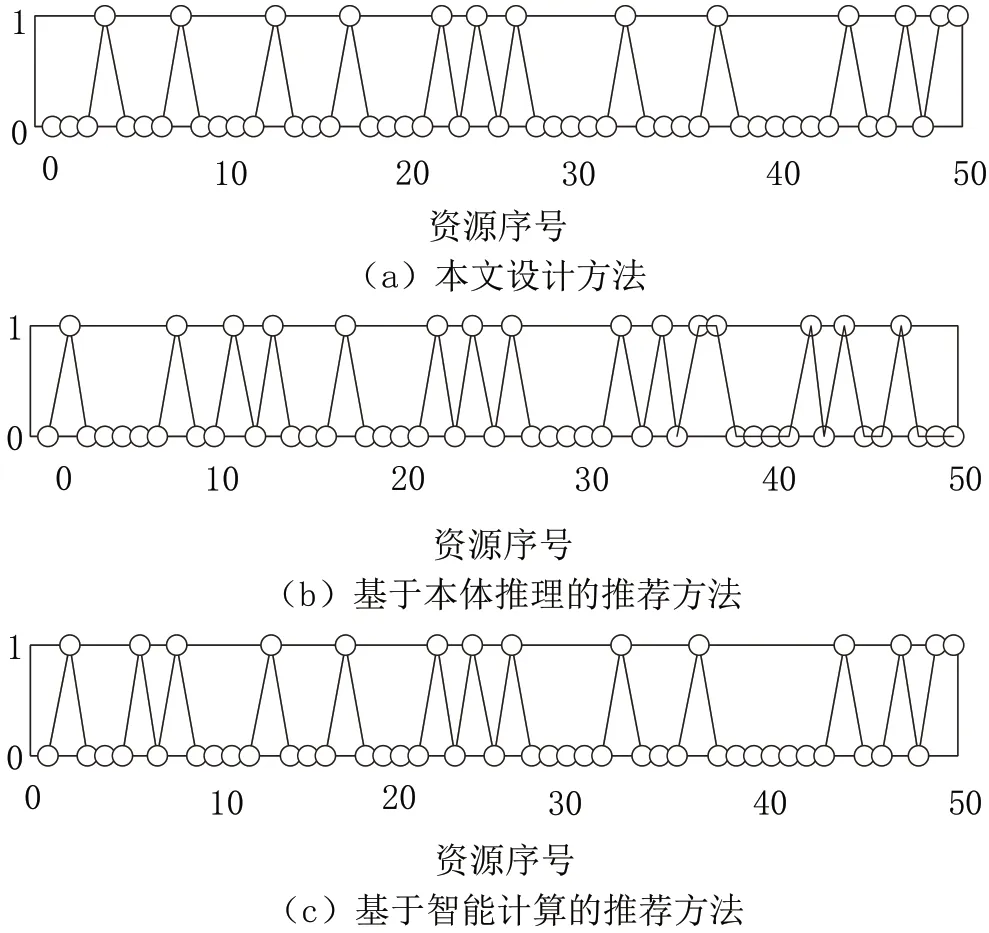
图7 不同方法的资源推荐序列对比图
资源推荐序列示意图中,纵轴由0 和1 这2 项构成,0 表明该资源未向用户推荐,1 表明该资源已经推荐给用户。对比推荐结果可知,3 种方法生成的推荐序列存在部分差别,表明不同方法的资源推荐性能具有差异性。
2.3.3 F-Measure值对比
深入分析资源推荐问题可以发现,该问题的解决包括推荐和不推荐2 种情况,在推荐方法性能分析过程中,可以将其当作分类问题来看待。因此,本文实验选定F-Measure 值作为基于极大熵的Web 服务资源个性化方法性能评价指标,其计算公式为:
其中,P表示准确率,R表示召回率。根据F-Measure值计算结果可知,其计算值越高表明该方法推荐质量越高。
为了准确地呈现出本文提出方法的优越性,运用3 种方法进行6 组推荐实验,分别将待推荐资源数量设置为50、100、200、300、500、1000,根据推荐结果得出图8所示的不同方法的F-Measure值对比图。

图8 不同推荐方法的F-Measure值对比图
根据图8可知,本文设计的资源推荐方法平均FMeasure 值为0.92,而其他2 种推荐方法的平均FMeasure 值分别为0.51、0.59。综上所述,以最大熵原理为基础的资源个性化推荐方法,使得F-Measure 值提升了41个百分点与33个百分点,运用本文提出的个性化推荐方法,可以更好地把握用户心理,实现用户满意度的提升。
为了进一步验证本文方法的资源推荐精准度,在Google Dataset Search 数据集上验证采用文献[3]方法、文献[4]方法以及本文方法的资源推荐精准度,得到结果如表3所示。

表3 Google Dataset Search数据集上资源推荐精准度
分析表3 可知,当图书数据量为50 GB 时,文献[3]方法的资源推荐精准度为68.21%,文献[4]方法的资源推荐精准度为58.21%,本文方法的资源推荐精准度为99.62%;当图书数据量为200 GB 时,文献[3]方法的资源推荐精准度为59.25%,文献[4]方法的资源推荐精准度为66.26%,本文方法的资源推荐精准度为97.88%;当图书数据量为300 GB 时,文献[3]方法的资源推荐精准度为52.91%,文献[4]方法的资源推荐精准度为52.12%,本文方法的资源推荐精准度为96.21%。本文方法的资源推荐精准度远远高于其他方法,表明本文方法的资源个性化推荐效果较好。
为了对不同数据集上的资源推荐效果进行验证,采用Movie Lens 数据集作为实验对象,得到的不同资源推荐精准度结果如表4所示。

表4 Movie Lens 数据集上资源推荐精准度
分析表4 可知,数据量为50 GB 时,文献[3]方法的资源推荐精准度为68.76%,文献[4]方法的资源推荐精准度为60.32%,本文方法的资源推荐精准度为98.23%;数据量为300 GB 时,文献[3]方法的资源推荐精准度为78.36%,文献[4]方法的资源推荐精准度为78.36%,本文方法的资源推荐精准度为99.32%。综合表3 与表4 结果可知,本文方法在Google Dataset Search数据集、Movie Lens数据集上都具有较高的资源推荐精准度,表明了本文方法具有较高的推荐效果。
3 结束语
本文针对资源个性化推荐问题进行了研究,参考传统资源推荐方法,提出以最大熵为核心的Web资源推荐方法。通过特征约束权重值的建立,再计算用户对某项推荐服务资源的使用概率,将预测值较高的资源推荐给用户,确保该方法资源质量的提升。本文研究的个性化推荐方法在未来还可以进行完善,从改进资源选取算法入手,实现资源选取训练时间的缩短[24-27]。
猜你喜欢
传感器世界(2023年5期)2023-08-03
文苑(2020年4期)2020-05-30
当代陕西(2020年24期)2020-02-01
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
新闻传播(2018年12期)2018-09-19
网络安全和信息化(2018年3期)2018-03-03
自然资源情报(2017年4期)2017-11-26
数学小灵通·3-4年级(2017年9期)2017-10-13
汽车与新动力(2016年6期)2017-01-04
