
基于Sentinel-2时序影像的地块尺度灌溉耕地提取
2023-11-29 02:20周亚男汪顺营
节水灌溉 2023年11期
王 琰,周亚男,汪顺营
(河海大学水文水资源学院,南京 211100)
0 引 言
灌溉是提升粮食产量的最主要条件之一,灌溉农业的单产水平是雨养农业的2.5 倍[1]。此外,灌溉消耗了近80%的人类用水[2],实际灌溉面积和灌溉空间范围之间有着很强的不确定性,这也进一步导致了在估计灌溉实际用水时的不确定性。准确掌握灌溉耕地的数量和空间分布等信息,对国内国际的粮食安全、水资源管理甚至气候变化领域都有重要的现实意义。然而,传统的灌溉数据统计方法通常要耗费大量的时间和人力,不仅效率不高、精度低,且可获取的范围有限。随着科技的发展,遥感、GIS 等更加高效的技术手段有着覆盖范围大、探测周期短、成本低等优点,已广泛应用于农田地物识别研究中[2]。
在遥感提取灌溉耕地的方向上,学者们的研究大致有以下几种方法:第一种是基于指数的方法,通过各类指数从土壤湿度、干旱程度等各方面判断地块是否进行灌溉。例如Deines 等人[8]开发了两个新的组合指数AGI 和WGI,尝试将湿度信息和绿度指数相结合来扩大灌溉状态的差异,在测试中该指数与传统指数相比具有更高的重要性,可将该指数应用于其他农业地区灌溉耕地的分类。但基于指数的方法需要依赖大量的现有统计数据用于数学模型分析与验证,对于一些缺少相关资料的地区难以使用该方法建立指数,因此该方法能够应用的范围有限;第二种是基于机器学习的方法,机器学习作为一门源于人工智能和统计学的学科,是当前数据分析领域重点研究方向之一,分类问题及其算法是机器学习的一个重要分支。如Ketchum 等人[9]建立了各类土地覆盖的地理空间数据库,基于谷歌地球引擎使用Landsat 卫星图像以及气候、气象、地形数据来训练随机森林分类器并预测土地类型,绘制了30 m 分辨率的灌溉地图IrrMapper。但各类别的机器学习算法都有各自擅长的领域和难以克服的缺陷,没有一种算法可以解决所有问题,此外,数据降维、特征选择等因素会对分类算法的发展产生很大的影响,因此在实际应用中,应该结合实际进行比较和选择适当的分类算法以达到更高的分类精度;第三种是空间分配的方法,Zhu 等人[10]估计出每个像素的灌溉潜力,并提出一种中国灌区的空间分配模型,将格网内灌溉潜力最高的像素识别为灌溉像素,再把所有灌溉像素进行组合以获得整个研究区的灌溉地图。这种空间分配的方法主要是通过构建一定的分配规则后将像素识别为灌溉,但其中建立分配规则的依据通常是一些影响灌溉耕地空间分布的特征量,由于这些特征量过于依赖样本数据,所以在很大程度上影响了结果的准确性;还有一些其他方法,例如朱秀芳等人[11]利用降水、实际蒸散发和潜在蒸散发数据提出了雨养指示线的概念,以此来表征耕地受灌溉可能性的大小,为灌溉耕地制图提供了指示意义强的灌溉特征参量。杨永民等人[12]使用水云模型实测土壤水分数据,利用散射系数的时序变化探测灌溉信号,提取实际灌溉面积。但这种使用非遥感数据的方法所制作的地图尺度较小,在制作大范围灌溉地图方面有所欠缺。
综上所述,学者们研究所用的数据大多是中低分辨率的多源卫星影像及气候数据,制作的国内外灌溉产品多为大尺度。然而有研究表明,以地块为单元的农业遥感分析更符合农业生产的应用,而传统基于像元的遥感分析方法往往会受到椒盐噪声的干扰,使地块的基本形态遭到破坏,因而分类精度有限,所以本文以地块尺度展开研究是核心要点之一。此外,在耕地较为精细、破碎的农田区域,单时相卫星影像所做出的地图往往达不到所需精度[13],而时序遥感提供了大量的高质量、连续的地表信息,也方便进行多源数据融合和分析,所以一直是遥感研究的热门领域[14],故本文使用了2020年3-10月的Sentinel-2高分辨率时间序列影像,这在获取连续的高质量研究区相关地表信息方面具有一定优势。同时本文还运用了机器学习中的XGBoost模型进行灌溉耕地的训练和预测,通过使用集成了机器学习、时序遥感、以地块为尺度这3个特点的创新思路来探究该方法应用于灌溉耕地提取的潜力,并进行对比验证以证明该方法的必要性。经验证,本文的方法可实际应用于灌溉耕地的调查与监测,同时为该方向后续的研究提供了参考。
1 研究区和试验数据
1.1 研究区概况
研究区是一个以南普拉特河为主要水源的农业灌溉集中区,有良好的灌溉数据基础,它位于美国科罗拉多州东北部,这里气候温和干燥,年平均温度在10~20 ℃左右,以丘陵为主,主要农作物有玉米、小麦等。这里的农田大部分依靠灌溉,灌溉系统主要通过地下水和河流水源来进行,常用的灌溉方法包括喷灌、滴灌、漫灌等,灌溉面积仅次于加利福尼亚、德克萨斯和爱达荷,居全国第四位(见图1)。
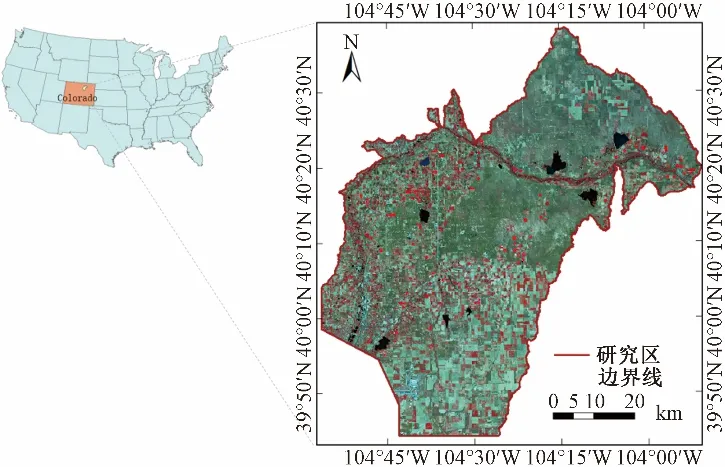
图1 研究区示意图Fig.1 Schematic diagram of the study area
1.2 数据及预处理
1.2.1 Google地图影像
研究选用Google 地图影像来提取研究区的农田地块。Google 地图影像具有3个可见光波段、且其空间分辨率为1 m,能够精细地描述研究区的农业种植场景。
1.2.2 Sentinel-2影像
本文的主要数据源是高分辨率多光谱成像数据哨兵2 号(Sentinel-2)卫星,地面分辨率分别为10 m、20 m 和60 m。本研究下载了2020 年3 月4 日至10 月25 日共48 幅L1C 级的遥感影像,使用欧空局(ESA)发布的插件Sen2cor 对这些影像进行大气校正,生成L2A 级产品数据,并在ENVI 中对影像进行云掩膜。
1.2.3 灌溉样本数据 CIL
研究选用2020 年的科罗拉多灌溉耕地数据集(Colorado Irrigated Lands, CIL)来训练和验证所提出的识别模型。灌溉耕地数据集以矢量多边形的形式提供了灌溉耕地的空间分布,并记录了作物类型、灌溉方式、灌溉面积等信息(见表1)。
灌溉耕地数据集为模型训练和验证提供了足够的正样本。首先将灌溉耕地数据集CIL空间连接到研究区耕地地块专题图FP 上,然后计算FP 上落入每个耕地地块P 内的灌溉面积A;当A 大于地块P 总面积的70%时,我们认为地块P 为灌溉正样本。接着,在耕地地块专题图FP 上,从非灌溉样本地块中随机选取与灌溉正样本相等数量的地块,作为负样本集。最后,研究共获得2 000 个地块灌溉样本,并按照2∶2∶6 的比例,将其划分为训练集、验证集和测试集。
2 研究方法
本文研究流程如图2 所示,主要包括以下内容:利用Google地图影像进行耕地地块的提取与修正,并结合经过预处理的Sentinel-2 时序数据集进行空间映射及地块特征处理,得到地块时序特征数据集后,结合灌溉样本,利用XGBoost模型训练预测灌溉耕地,最后对分类展开分析与评价。

图2 研究流程图Fig.2 Research flow chart
2.1 耕地地块提取
地块提取参考了Wang 等人[20]提出的边界语义融合深度卷积网络,该方法的核心是将具有准确空间定位的浅层边界特征与用于类别识别的深层语义特征相结合进行地块识别,从而预测出整个研究区的耕地地块并进行修正。图3展示了模型预测出的耕地地块结果,结果表明,即使在农田分布密集的地区,模型也可以精确提取出耕地的精细边界,并且对河流、建筑等干扰地物有着良好的辨别能力[图3(a)、图3(b)],这为本研究灌溉耕地提取提供了空间约束。
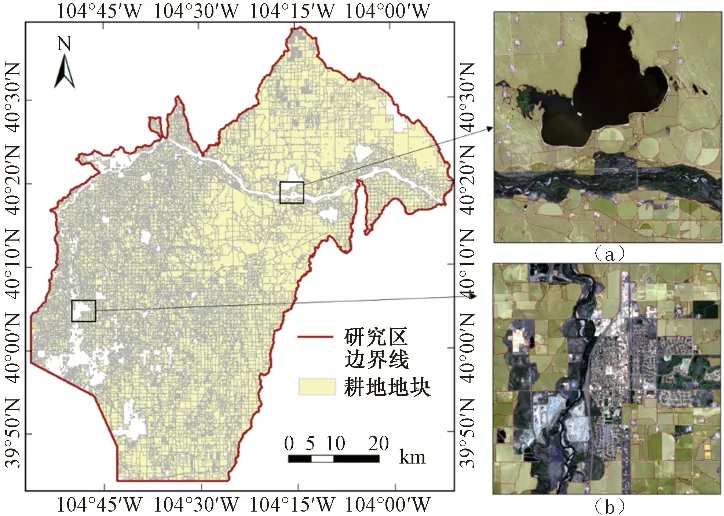
图3 耕地预测结果Fig.3 Farmland prediction results
2.2 特征构建与组合
对48景Sentinel-2数据基于地块单元进行分区统计,分别获取每一期影像中b2~b8、b8a、b11~b12 共10 个波段的均值、中值、标准差及众数作为特征变量,用于遥感分类的候选变量。为了比较采用不同光谱特征下的灌溉耕地识别精度,设计了11 种不同的组合方式如表2 所示,意在对比均值、中值、标准差、众数这4类光谱特征及不同种类之间的相互组合在灌溉耕地识别上的不同效果,优选出其中精度最高的特征组合方式对研究区进行灌溉耕地识别。

表2 不同特征类型组合方式Tab.2 Combination of different feature types
2.3 灌溉耕地提取模型
本研究使用的是XGBoost 算法,由Chen 等人[21]在2016 年提出,这是一种基于集成学习原理Boosting 的机器学习方法,除了有精度高、速度快的优点,XGBoost 算法还可以对影像缺失值进行处理[22]。它以CART 决策树作为基分类器,充分利用了多核CPU 并行计算的优势,大幅度提高了模型的运算速度和预测分类精度[23],基模型为:
式中:xi是第i个样本的预测值;fk(xi)是第k棵树对数据集中第i个样本的计算分数;F是所有树的集合。
并定义XGBoost目标函数为:
式中:N为样本的数量;为损失函数;为正则化项。
损失函数衡量模型与数据的吻合程度,正则化项衡量模型的复杂性。对目标函数的泰勒展开式进行整合、重组,转化为与预测残差相关的多项式,得到叶节点最优权重和目标值最优解分别为:
2.4 精度评价指标
在机器学习的分类任务中,常用的精度评价指标有很多,本研究中使用的指标共5 种(以下公式中,TP 指真正例(True Positive),TN 指真反例(True Negative),FP 指假正例(False Positive),FN 指假反例(False Negative)),相关指标定义详见文献[24]。
(1)总体精度(Overall Accuracy - OA)。总体精度衡量的是分类正确的比例,计算公式如下:
(2)F1分数(F1_Score)。F1是精确率和召回率的调和均值,同时考虑了查准率和查全率,F1值越大认为学习器的性能越好,计算公式如下:
(3)精确率(Precision)。精确率又叫查准率,是指被预测为正样本的所有样本中预测正确的占比,代表对正样本结果的预测准确程度,计算公式如下:
(4)召回率(Recall)。召回率又叫查全率,是指在实际为正的样本中被预测为正样本的概率,计算公式如下:
(5)Kappa 系数(Kappa Coefficient)。Kappa 系数综合考虑了分类器预测结果与实际情况之间的差异和随机误差,可以衡量分类器在各类别上的分类能力是否超过了随机选择的水平,计算公式如下:
式中:po也就是总体分类精度;pe是所有类别分别对应的实际与预测数量的乘积的总和除以样本总数的平方。
3 结果与分析
3.1 精度分析
3.1.1 特征组合精度分析
本研究中,在地块尺度下利用11 种特征组合进行灌溉耕地的识别,得到不同组合方式下的识别精度(表3)。结果表明,包含了均值、中值、标准差这三类光谱特征的组合8获得了最高精度0.850 3,对灌溉耕地的识别最有利。由组合1、2、3可知单个变量的加入对提升分类精度影响不大,从组合11的精度表现可以看出众数的参与会导致分类精度下降,在灌溉耕地的分类中应避免输入该特征以降低被误分类的可能。基于此,在提取灌溉耕地时可将均值、中值、标准差输入模型,以提高识别精度,准确地提取特征并分类,同时也保证了模型的泛化能力和稳定性。
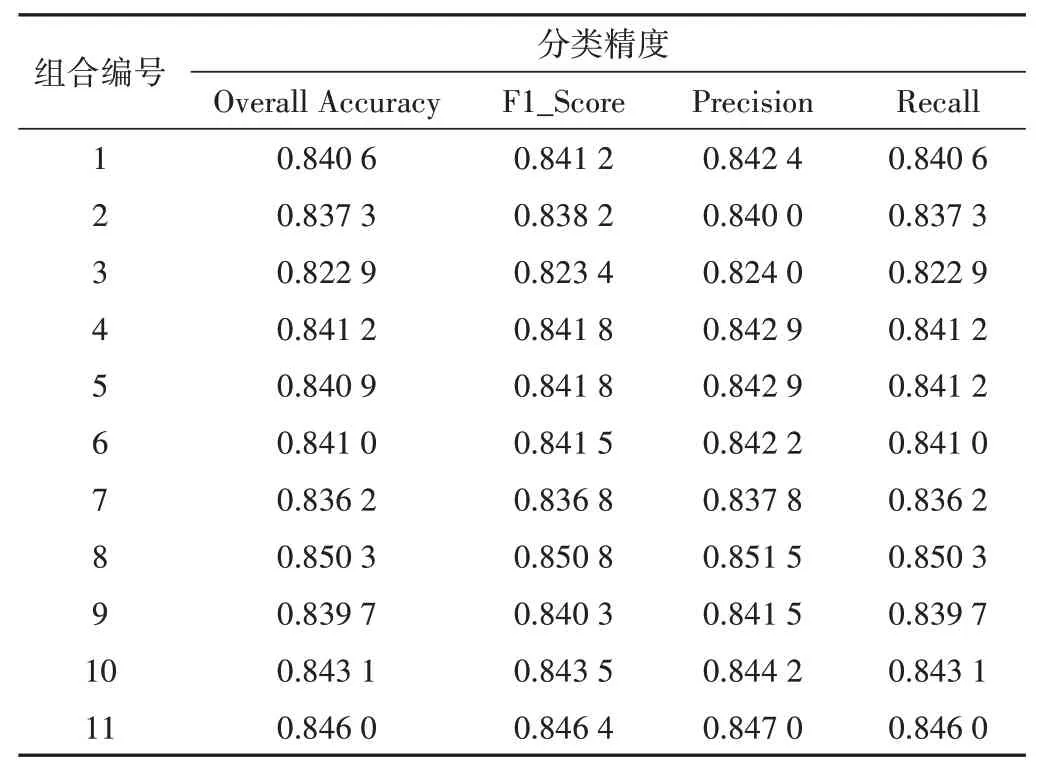
表3 各组合不同指标下的分类精度Tab.3 Classification accuracy under different indicators of each combination
3.1.2 时相敏感性分析
从时间维度来探究灌溉耕地识别精度的变化规律,将不同长度时间序列遥感影像数据以月为单位输入模型,数据长度等差增长,将完整的时间序列进行分割,得到了不同时间节点的灌溉耕地识别情况。
图4 中精度总体呈逐渐上升趋势,当加入4 月和5 月的特征时,精度增长幅度最大,此时正是农作物迅速生长的季节,后续继续加入特征时增长幅度逐渐趋于平缓,是由于农作物于9、10月份完全成熟进入了收获期。再结合研究区当地自然条件,5 月前和9 月后的天气多为寒潮及大范围降雪[24],积雪的覆盖不利于影像的识别,这也是导致精度不高的原因之一。综上得出下列结论:对灌溉耕地提取较为敏感的时相集中在农作物生长季的中后期,该时相的遥感影像用于提取灌溉耕地可获取较高的制图精度。
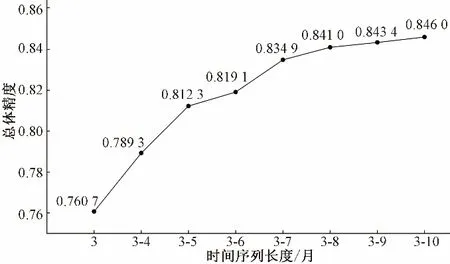
图4 不同时序长度下总体精度变化图Fig.4 Overall accuracy variation chart under different time series lengths
总体来看,灌溉耕地识别的最佳时间与作物的生长阶段特征关系明显,在成熟期作物出现较为独特、明显的特征后识别精度将会大幅度提升,而当作物早期特征不明显时,应使用完整的生长序列提取灌溉耕地以保证识别精度。从3月份到5月份精度迅速增加,分类精度提升效果明显,说明这一时期的数据含有较多信息量。继续增加时间长度,可以看到精度仍不断上升,证明时间序列长度的增加可以有效提升分类精度,作物在8月份之后可以达到84%以上的精度,是一个比较理想的水平。当使用完整时间序列长度的数据时,识别精度最高,可见随着时间序列长度的增加,特征数量也随之增加,识别精度能够达到最高水平。
以上结果表明,与传统的单时相影像相比,结构化的时间序列影像数据不仅可以降低天气对识别的影响,同时还蕴含了更多的特征信息,有利于灌溉耕地的提取。
3.2 灌溉耕地提取结果
根据3.1.1 节的结论,将精度最高的特征组合8 放入模型生成研究区灌溉耕地空间分布图,并给出该模型的混淆矩阵,对精度进行评价,同时还使用特征重要性这一评价标准对每个特征要素在模型预测中的作用进行了评估。
3.2.1 灌溉耕地空间分布
由图5可知,南北两端灌溉耕地的规模很小,多数分布于研究区的中西部地区及东北部。灌溉耕地靠近南普拉特河以及一些水库,是由于美国西半部干旱缺水,所以在许多河干、支流上兴建了大型的引水工程用于农业灌溉,靠近河流便于获取水源进行输水,依靠灌溉手段才能更好地发展农业。例如,在该州的艾尔伯特县和沙拉摩亚县,大量种植玉米、小麦和大豆等灌溉作物。模型提取出的灌溉耕地大量聚集在研究区的最左侧边缘,因为这里靠近科罗拉多河流域,在这片流域内有许多重要的灌溉水源,如科罗拉多河的支流莫阿布河、弗拉格斯塔夫河、汉尼拔河等,这些河流的水源较为充足,可以为灌溉作物提供足够的水资源。
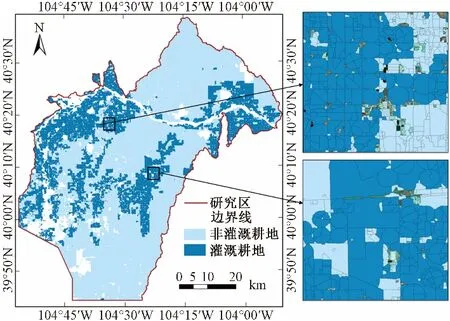
图5 研究区灌溉耕地预测结果Fig.5 Prediction results of irrigated farmland in the research area
3.2.2 精度评价
此次分类模型各项表现如表4所示,Kappa系数达到0.69,显示出了相对较高的一致性水平,总体精度达到85.03%,意味着模型能够正确地分类大部分样本,其中灌溉耕地分类精度为86.76%,非灌溉耕地分类精度为82.30%。综上,该分类模型在整体上表现良好,并且在灌溉耕地和非灌溉耕地的分类任务上都有着有优异的表现,各项精度指标均优于Zhu 等人[10]的研究。

表4 灌溉耕地分类混淆矩阵Tab.4 Classification confusion matrix of irrigated farmland
3.2.3 特征及重要性评价
(1)最佳特征变量。优选出20 个表现最好的特征变量如图6 所示,其中包含了10 个均值特征、7 个标准差特征、3 个中值特征,0个众数特征,可以看出均值和标准差对提升整体分类精度的影响较大。在众多特征变量中,5 月13 日影像b8波段的标准差、8 月21 日影像b1 和b3 波段的均值的特征重要性远高于其他特征变量,在分类中起到重要作用。
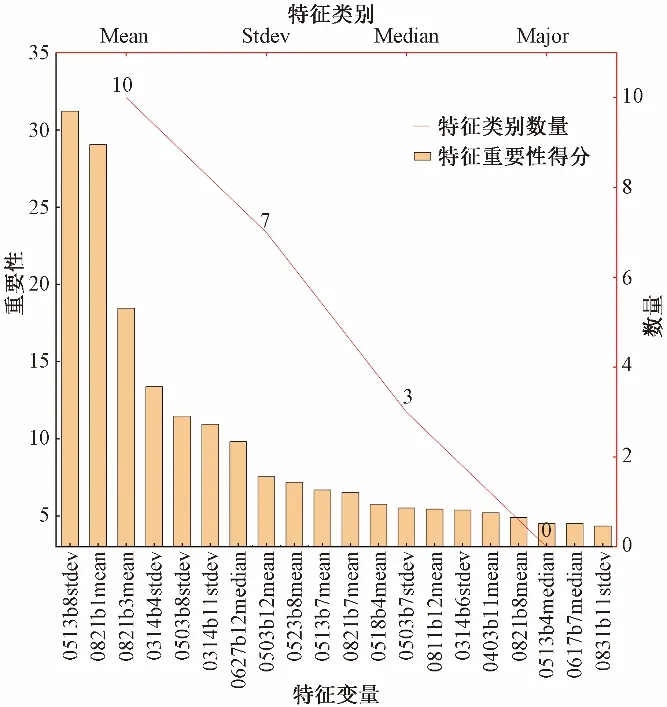
图6 组合8前20个最佳特征变量Fig.6 Combining the top 20 best feature variables of 8
(2)时序特征。即使是相同类型的特征变量在不同时相也会具有不同的敏感性,图7中每一期影像的特征重要性都由均值、中值、标准差这三类变量共同组成,但其在灌溉耕地识别中的作用截然不同。在美国,玉米、大豆等主要农作物的物候期一般集中在4-11 月,从图7 可以明显看出有利于识别的遥感影像集中在5-9月,而该时间段正是农作物的生长期及成熟期,此结论与3.1.2 节相符。也有部分影像的重要性为0,可能是这几期影像云量较大范围较广,覆盖了整个研究区,使用这些重要性较低的特征变量进行制图对分类精度的提升可能没有作用甚至起到副作用,所以在进行灌溉制图前有必要进行特征的选择工作。
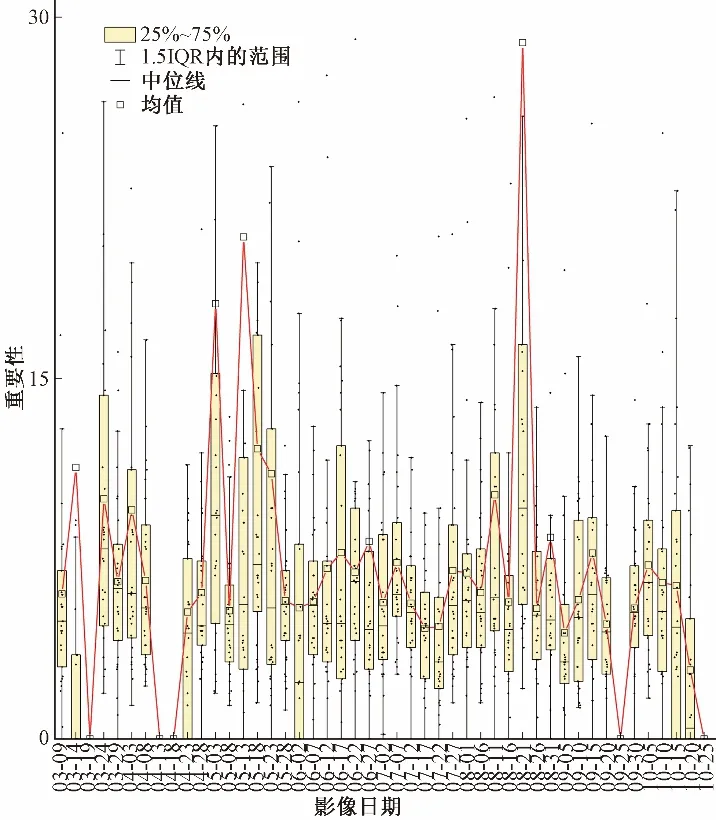
图7 时序特征重要性Fig.7 Importance of temporal features
(3)不同类型特征的重要性。从图8可以看出,均值变量在分类中的重要性最高,对灌溉耕地的识别最有帮助;标准差的重要性略低于均值,但总体重要性得分也高;比起均值和标准差,中值这一类型的特征变量在参与分类任务时的作用较小,但对灌溉耕地和非灌溉耕地的分类也具有一定影响。

图8 特征类别重要性Fig.8 Importance of feature categories
4 讨 论
4.1 分类方法对比
本文利用高分辨率Google 影像,结合研究区耕地的形态特征,利用边界语义融合深度卷积网络提取当地的耕地边界,该方法与常规模型进行地块分割或提取的方法相比,对本文农业灌溉集中区的耕地提取更加精细,鲜少有错提、漏提的现象,为后续耕地分类提供了良好的基础。在使用时序遥感影像方面,与单时相遥感影像相比,本文充分考虑科罗拉多州地区作物种植类型及耕地类型复杂多样的特点,通过综合多类型、多时相的特征变量提升分类精度。在分类模型选择方面,和常用的随机森林方法相比,本文选择的XGBoost分类方法已被证实有速度快、精度高等优点,且对于本实验采用的光学数据源由于云的覆盖导致的特征信息缺失的部分,XGBoost分类方法能对缺失值进行相关处理[22],因此该方法更适用于本研究。
4.2 分类结果不确定性分析
由于研究区内作物种植类型及耕地类型的多样性,使分类工作成为一个很大的挑战,分类过程中引入的一些误差会导致分类结果的不确定性,具体内容如下:
(1)地块提取的工作仍有一定的进步空间,由于影像的质量的问题,还是存在一定的地块错分、漏提的现象,这也进一步导致了在耕地识别时发生错误的可能性。
(2)不同类型耕地上种植的作物可能由于生长期相近,导致有相似的特征信息,这不利于区分耕地类型。
(3)光学遥感影像易受天气影响,当云雾或水汽等遮挡时会导致图像质量下降或无法成像,导致在特征构建时有缺失现象,会在一定程度上影响模型分类精度。
4.3 问题与展望
由于Sentinel-2 易受天气影响的原因,在后续的工作中,考虑增加Sentinel-1 等微波数据以多源数据融合的方式进一步展开研究,利用微波遥感渗透力强、全天候工作的优势,以提高分类精度。此外还可构建物候、纹理、地形等特征解决“同物异谱”或“异物同谱”的现象,通过更多的特征组合方式建立更加精确的灌溉耕地提取模型。在算法方面,数据降维、特征选择等因素会对分类算法产生很大的影响,可以结合实际对比择优使用更加稳定、精确的模型,选择适当的分类算法以达到更高的分类精度。
5 结 论
本文以美国科罗拉多州南普拉特河流域的农业灌溉集中区为研究区,综合利用高分辨率遥感影像和Sentinel-2 时间序列影像开展地块尺度的灌溉耕地提取,分析不同时相和不同特征组合情况下的识别精度,探究了XGBoost模型在时序遥感灌溉耕地提取中的应用潜力,得出以下结论:
(1)相比于传统基于像元的遥感灌溉提取,本文基于地块的提取方法不会破环地块基本形态,在耕地情况破碎、复杂的区域也能够实现灌溉耕地的精确提取,且长时间序列的影像蕴含更丰富的特征信息,为灌溉耕地的提取提供了有力的支撑,结合XGBoost机器学习模型,此次分类总体精度高达85.03%;
(2)在特征的构建与组合中,不同类型的光谱特征表现不同,精度表现最好的是均值、标准差、中值这三类光谱特征的组合,Kappa 系数达到0.69,其中灌溉耕地分类精度为86.76%,非灌溉耕地分类精度为82.30%;
(3)从时相敏感性分析结果可知,对灌溉耕地和非灌溉耕地的区分较为敏感的时相集中在农作物生长季的中后期,其分类精度随着时序长度的增加而不断提高。
本研究利用高分辨率影像的光谱特征进行灌溉耕地的识别,为灌溉制图提供了研究思路,对准确掌握灌溉耕地的数量和空间分布等信息有重要的现实意义,将来有望广泛应用于大区域乃至全球灌溉耕地空间产品研制。
猜你喜欢
中国化肥信息(2022年8期)2022-12-05
今日农业(2022年13期)2022-11-10
北京测绘(2021年12期)2022-01-22
今日农业(2021年14期)2021-11-25
云南农业(2021年10期)2021-10-22
云南农业(2021年9期)2021-09-24
云南农业(2021年8期)2021-09-06
云南农业(2021年3期)2021-04-24
电子制作(2018年11期)2018-08-04
测绘科学与工程(2016年5期)2016-04-17
