
基于PMC-AE指数模型的中美科学数据管理政策量化评价
2023-12-18 07:31王丹丹董金金
现代情报 2023年12期
王丹丹 董金金

关键词: 科学数据管理; 政策评价; PMC-AE 指数模型
DOI:10.3969 / j.issn.1008-0821.2023.12.010
〔中图分类号〕G250 252 〔文献标识码〕A 〔文章编号〕1008-0821 (2023) 12-0111-11
科学数据是国家科技创新和社会经济持续发展的重要基础性战略资源。科学数据管理政策是加强科学数据管理、提高科学数据开放共享水平、释放科学数据价值的重要手段[1-3] 。各国(地区)政府、科研资助机构、科研机构和出版商等均出台了相应的政策, 对科学数据的管理与开放共享做出规定。我国在2018 年出台了《科学数据管理办法》, 并陆续发布了不同级别的科学数据管理政策, 但整体尚处于起步阶段, 与发达国家(地区)相比仍有较大差距[4] 。鉴于此, 本文构建了政策评价框架和指标体系, 通过PMC-AE 指数模型, 将文本内容分析和量化评价同时用于中美科学数据管理政策的评价, 针对两国科学数据管理政策量化评价结果,发现我国科学数据政策建设存在的问题以及与先进国家(地区)的差距所在, 并提出针对性建议, 为我国科学数据管理政策体系完善提供参考和借鉴。
1文献回顾
1.1科学数据政策研究回顾
当前, 涵盖“宏观—中观—微观” 3 个层面的科学数据管理政策体系已初步形成, 根据政策制定主体的不同, 可分为国际组织政策、国家政策、科研资助机构政策、科研机构政策以及出版商政策等。国外相关研究主要集中在科学数据管理政策实践与优化、政策目标与价值、政策阻碍和激励因素、政策影响力等方面[6-9] 。我国也在科学数据管理政策的制定和实施方面开展了一些探索性研究。陈大庆[10] 调查了英国科研资助机构的政策内容与执行情况, 为中国科研资助机构科学数据管理政策制定提出建议。秦顺等[11] 、李洋等[12] 对《科学数据管理办法》的体制机制、影响因素、利益相关主体、监督机制等进行研究, 提出推进政策落实的建议。周文能等[13] 梳理欧盟、英国、美國等的科学数据管理与共享政策实施情况, 给出了改进国家自然科学基金项目数据管理与共享政策的建议。马海群等[14] 、徐天雪[15] 基于层次分析和模糊综合评价法, 构建了科学数据管理政策评价指标体系并实施评价。
1.2科学数据政策评价梳理
定性分析是当前科学数据政策评价的主要方法, 学者对不同政策主体、政策结构、内容要素等进行对比和分析。彭琳等[16] 通过定性分析发现,中国科学院65 种被SCI 收录的期刊政策存在数据著作权归属、数据使用与许可协议等缺失的问题。王芳等[17] 分析政策发布主体、发展历程等, 基于生命周期下分析评价科学数据管理政策存在的问题。Hrynaszkiewicz I 等[18] 研究期刊数据政策的14 个特征, 提出了期刊数据政策的标准化实施框架。实证研究和文本量化分析逐渐成为新兴热点。HardwickeT E 等[19] 对《Cognition》的强制性开放数据政策进行调查和评价, 发现强制性开放数据政策可以提高数据共享的频率和质量。姜鑫[20] 对国外资助机构的16 项科学数据政策进行了文本分析, 针对国内资助机构提出政策制定建议。Si L 等[21] 构建了“政策工具—利益相关者—生命周期” 三维分析框架。宋大成等[22] 基于PMC 指数模型对国家层面的科学数据共享政策进行了量化评价。
1.3 PMC 指数模型应用发展分析
政策文本量化评价主要分为3 种: 一是针对政策文本结构特征的政策计量分析; 二是针对政策内容特征的内容量化分析; 三是面向政策语义特征的政策文本挖掘分析[23] 。PMC-AE 指数模型是面向政策内容特征的量化分析[23] 。PMC 指数模型遵循“变量选取应尽量全面” 的思想[24] , 学者们通过使用ROSTCM、Nvivo、R、Python 等工具提高了政策文本分析的效率, 运用社会网络分析和关键语义分析、LDA 算法等提高了模型构建和评价的客观性[25-28] ; PMC-AE 指数模型, 利用神经网络技术中的自编码器(Auto Encoder, AE)技术特性, 通过参数自学习的方式实现数据融合的特性, 从而更好地表现各指标间的关系, 更加准确客观表述评价结果, 它是对传统PMC 指数模型的加权求平均的计算方式的优化[29-30] 。
综上可见, 现有评价方法单一, 量化研究较少, 当前形势下对我国科学数据管理政策开展量化评价必要且重要, 尤其是利用计算机技术结合评价模型进行政策文本量化评价。
2评价模型构建
2.1评价指标体系构建
2.1.1政策样本选取与文本挖掘
指标体系构建的首要工作就是评价要素的选取, 共分为两步:
1) 政策文本收集。通过政务网站、专业文献,以及相关法律法规信息检索系统搜集办法、实施细则、通知、意见等, 遵照科学性、及时性和相关性原则分析筛选政策文本, 删除不相关、无实质内容的政策文本, 最后得到中美两国科学数据管理政策各64 项, 共128项。
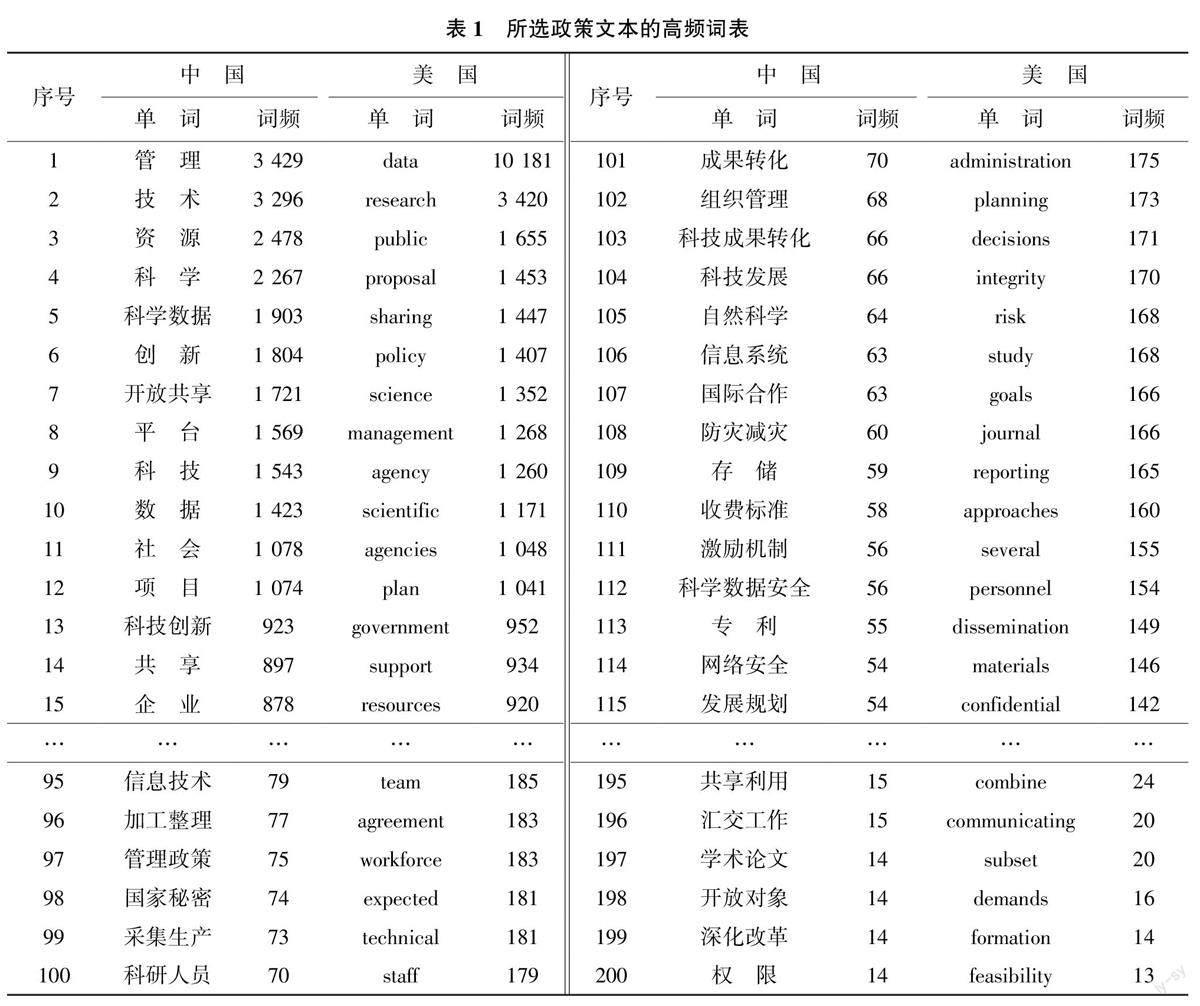
2) 政策文本分析与特征提取。将政策文本排列, 形成具备相同维度的大型二维矩阵, 表示为Wn×m , 其中n 为政策文本数量, m 为单个文本长度。对W 进行分词处理, 完成高频词提取和筛选,形成高频词库, 表示为F, 如表1 所示。
美国科学数据政策的主要高频词为数据、研究、公共、共享、管理、科学、机构、计划、提案、政府、组织、程序、过程、回顾、需求等, 体现美国科学数据管理工作的主体为机构、政府等, 通过制定计划、指南、提案、政策等对科研项目、科学数据进行管理和评价, 促进数据开放共享; 我国科学数据管理政策的高频词为管理、技术、资源、科学、科学数据、创新、开放共享、平台、数据、项目、科研设施与仪器等, 体现出我国科学数据管理政策关注的重点是管理内容、目的和政策意义。
2.1.2变量选取
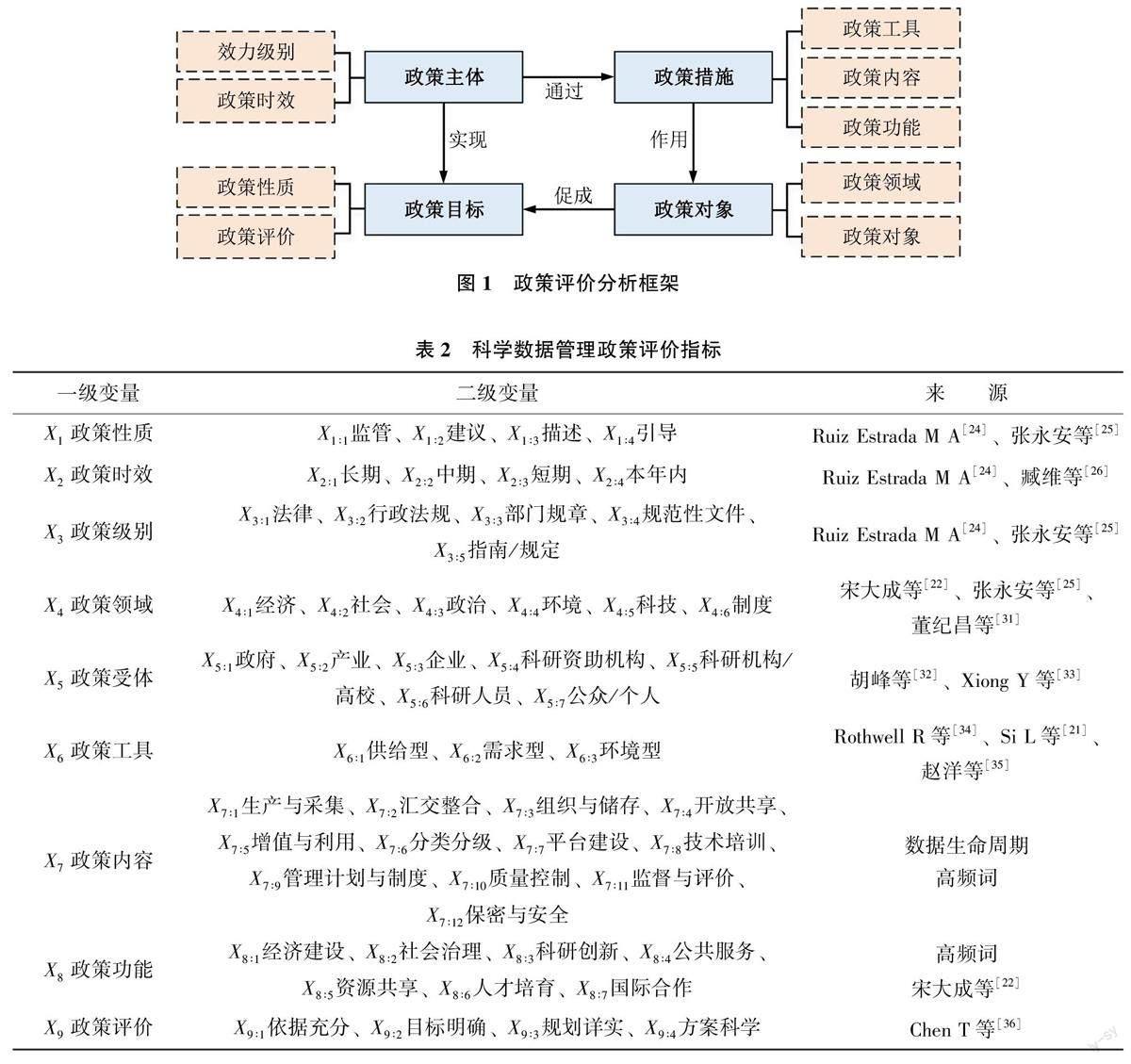
政策主体(效力级别、政策时效)通过一系列政策措施(政策工具、政策内容、政策功能)作用于政策对象(政策领域、政策受众), 从而促进政策目标(政策性质、政策评价) 的实现, 如图1、表2 所示。
政策主体方面, 主要考虑政策制定、执行、监管、评估各个环节, 根据政策发布时的机构层级、发布时间, 设置效力级别和政策时效作为一级指标要素。
政策对象方面, 主要考虑政策的作用领域和作用对象, 作用领域包括经济、社会、政治、环境、科技和制度等; 作用对象包括政府、产业、企业、科研院所、高校、科研人员及公众/ 个人, 设置政策领域和政策受众作为一级指标要素。
政策措施方面, 主要考虑对政策对象的所有要求、建议和规则等, 设置政策工具、政策内容以及政策功能作为一级指标要素。其中, 政策工具选取了供给型、环境型和需求型工具作为分类, 政策内容则依赖于政策本文的挖掘和分析; 政策功能考虑科学数据管理政策对数据共享的作用。
政策目标方面, 主要考虑科学数据管理工作带来的具体成效, 如科学数据中心的数量以及开放共享数据集的数量、质量和价值等, 设置政策性质和政策评价作为一级指标要素。
2.2 PMC-AE模型构建
将自编码器融入PMC 指数模型, 对多项评价结果进行数据融合处理, 使评价结果更客观、科学和准确[37] 。PMC-AE 指数模型构建, 第一步是数据准备, 即分析整个政策文本, 选出参评政策文本; 第二步是模型构建, 在PMC 模型的基础上,参考前人研究和文本挖掘构建评价指标体系, 对每项政策每个指标打分, 构成投入产出表, 通过AE数据融合计算出各项政策得分, 最后绘制曲面图,如图2 所示。
2.2.1多投入产出表构建
二级指标均使用二进制打分, 将待评价的政策文本进行分词处理并提取高频词, 形成对应的特征向量, 当政策文本中包含二级变量对应的关键词时, 则赋值为1, 否则为0, 如表3 所示。
2.2.2 PMC-AE结果计算
通过构建3 层神经网络, 使得输入节点数等于输出节点数, 隐藏层h 即为数据融合结果, 具体表示为:
通过增加神经网络层数对数据进行降维。经过训练后, 通过非线性结合构成h, h 又通过非线性结合构成Y, 且Y =X。h 和X 是经过非线性运算融合得到的, 而Y 是通过解码得到的, 从而可以认为h 是X 和Y 的非线性表达, 所以h 可以作为各项指标融合后的政策文本得分[23-24] 。根据研究所需, 输入层为各项政策二级指标得分, 隐藏层节点数为1, 数据融合后得到各项政策一级指标得分。
将PMC-AE 指数计算结果转化为PMC-AE 曲面, 以直观展现每项政策的优势与缺陷。PMC-AE曲面由3×3 的矩阵构成, 每项政策保留9 个一级变量结果, 具体表示为:
3实证与结果分析
3.1评价政策选取
基于政策评价框架, 考虑两国政策不同的发文时期、发布机构、效力级别等因素, 按照评价样本不低于总体样本10%的比例选取契合度高、发布时间和效力级别分布广泛、政策发布主体代表性较强的政策, 最终确定中美各7 项代表性政策作为评价样本, 如表4 所示。
3.2验证分析
3.2.1 PMC-AE评价结果
对政策文本进行处理, 根据输出的特征向量为二级变量赋值, 完成多输入产出表构建。
数据融合时, 设置PMC-AE 模型中的神经网络为3 层, 隐藏层节点数为1, 激活函数表示为:
对14项政策多投入产出表的评价结果融合计算得出PMC-AE 得分, 如表5 所示。
基于表5 的计算结果, 构建PMC-AE 矩阵,并绘制PMC-AE 曲面图, 在曲面图中露出的部分表示较高的得分, 凹陷部分表示较低得分, 在此,只展示P1 和P8 的曲面图, 如图3 所示。
3.2.2评价结果分析
对14 项政策量化评价, 政策得分由高到低的顺序分别是P9>P5>P8>P6>P4>P10>P13>P14>P7>P11>P12>P1>P3>P2, 结合得分情况, 将政策等级划分为4 个等级: Ⅰ级政策: 9 00 分以上, 包含P9、P5、P8 三项政策; Ⅱ级政策: 8 00 ~ 8 99 分,包括P6、P4、P10、P13、P14 和P7; Ⅲ级政策有P11、P12 和P1; Ⅳ级政策: 5 00~6 99 分, 有P3和P2。14 项政策与平均值在每个指标上的差距情况如图4 所示。
1) 单项政策分析
根据PMC-AE 指数和PMC-AE曲面结果, 按照政策等级对14 项政策逐一分析:
①Ⅰ级政策: P9 的PMC-AE 指数为9 67 分,排名第一, 该政策各指标的表现都很好。它是美国联邦数据战略从愿景到落地的关键政策, 其制定了科学数据管理的10 项原则和执行框架, 明确了从联邦机构、相关社区、全国的整体协作和融合发展路径, 确立了数据从收集、储存、管理、保护以及数据质量、自我评估、伦理框架、政策标准、管理工具、人员培训、数据库建设等20 项关键行动目标, 是美国科学数据管理最为完善的政策之一[38] 。
P5 的PMC-AE 指数为9 26 分, 排名第二, 它是我国目前科学数据管理最高级别政策。但在政策内容(X7)上缺少DMP 和管理技术培训的相关内容,原因之一是该政策属于国家层面的宏观指导性政策, 其指导对象广泛, 作用层面宽泛, 政策内容中缺少较为细节的设计, 另外对于科学数据的分类分级管理作出的指导有限。
P8 的PMC-AE 指数得分是9 19, 排在第三名, 它是美国OSTP 的《促进联邦资助科研成果获取的备忘录》(Increasing Access to the Results of Federally Funded Scientific Research), 其提出“年研发经费超过1 亿美元的机构” 必须提交数据管理计划, 使美国各科研机构科学数据进入“管理计划时代”, 但是没有制定详细的规划, 缺乏数据的治理和分类分级提出相关要求, 因此, 在政策內容(X7)上得分不高。
②Ⅱ级政策: P6 的PMC-AE 指数为8 98, 排名第四, 它主要用以规范中国科学院院属各单位及人员的科学数据管理工作, 提高科学数据开放水平, 促进科技创新效率。P6 所有维度的得分都高于平均值, 各个维度设计都相对完善, 政策改进可从政策领域(X4)和效力级别(X3)着手, 提升政策的带动作用, 增加对我国管理技术培训的相关内容, 促进我国科学数据管理走向标准化、制度化。
P4 的PMC-AE 指数得分为8.97, 排名第五,它是早期国家科学数据管理办法的尝试, 也是领域科学数据管理办法的代表。未达到Ⅰ级政策标准的主要原因在于其政策领域(X4)、政策功能(X8)方面的不足。但同时, 其最大优势在于能够发挥政策针对性强的优势, 更加细化政策受众(X5)、政策内容(X7); 未来要对主管部门的职责范围、科学数据的分类分级、数据处理、开放共享、合作交流中数据保密与安全等作出更细致的规定。
P10 的PMC-AE 指数为8.84 分, 排名第六, 它是美国NSF 针对P8 的响应政策。同P8 一致, 作为指向明确的政策, 其在相关定义的描述、政策规划方面都不多, 因此, 政策评价(X9)得分不高; 对比P8, 主要是NSF 的政策领域(X4)、政策受众(X5)更有针对性, 得分略低。
P13 的PMC-AE 指数为8 29 分, 排名第七, 它是美国USGS 的科学数据管理政策, USGS 开发了科学数据生命周期模型(SDLM), 并基于SDLM 制定了包括计划、获取、处理、分析、保存、出版/共享整个科学数据生命周期下的管理政策、DMP 指南、(元)数据标准、管理培训等一系列措施。但其政策针对性项, 政策受众(X5)得分不高, 政策功能(X8)发挥有限。
P14 的PMC-AE 指数得分为8.07 分, 排名第八, 它是美国能源部2014 年的《开放获取计划》(Public Access Plan), 其明确了开放获取的原则和框架、门户网站(PAGES)提交、保存数据以及相关管理职责。但该政策侧重于呼吁科研人员通过门户网站提交和管理数据, 政策内容(X7)没有针对数据分类分级、人员培训等相关内容, 因此得分不高。
P7 的PMC-AE 指数为8.04 分, 排名第九,它是针对大数据产业主管部门制定的综合性指导性政策。与P5 相比, 其在政策领域(X4)和政策功能(X8)方面有独特优势。但该政策专指性较强, 政策受众(X5)范围窄。虽然政策内容(X7)得分不低,但在数据生命周期内的数据生产、汇交、开放共享等方面的设计较为宏观, 缺乏管理技术培训、管理计划等内容。
③Ⅲ级政策: P11 的PMC -AE 指数得分是7.64 分, 排名第十, 它是美国NIH 的数据管理和共享政策。NIH 会根据联邦政策和自身要求及时更新政策。相比P4、P5 等国内政策, P11 更注重政策内容(X7)中生命周期各环节的相关要求, 在政策领域(X4)、政策受众(X5)方面针对性更强, 强调数据管理计划、数据研究过程的评价等内容。
P12 的PMC-AE 指数为7.44 分, 它是NIH 下的国家老龄研究所(National Institute on Aging, NIA)在2023 年1 月发布的专项政策。同P14 一样, 其政策领域(X4)、政策受众(X5)得分均不高, 也缺乏數据管理计划等内容。
P1 的PMC-AE 指数得分为7.38 分, 排名第十二, 它是我国进行科学数据共享的最早尝试和探索, 多项指标得分均低于平均值。原因在于该政策面向特定领域, 专指性较强, 受众和功能相对单一, 且发布时间早, 其政策设计方面还有很大改进空间。
④Ⅳ级政策: P3 是科学技术部针对专项项目的科学数据汇交办法, 其PMC-AE 指数得分为6.52 分, 排名第十三。科学数据汇交是科学数据管理工作中的重要环节, 主要针对专项项目制定汇交程序, 其各项指标的得分都不高。科学数据汇交是科学数据管理工作的第一步, 因此科学数据汇交应进一步规范汇交程序, 细化汇交流程, 并在科学数据汇交之时做好分类分级的相关工作, 制定分类分级标准和指南, 促进数据分类分级汇交和开放。
P2 的PMC-AE 指数为6.19, 它是专门为实现“十一五” 规划目标启动的科学数据平台开放共享的工作方案, 但是它只制定了各平台开放共享工作的总结报告编写提纲, 未制定更细致的标准。2018年, 科技部、财政部发布的《国家科技资源共享服务平台管理办法》进一步明确了管理职责, 扩大了平台管理范围, 为科学数据平台的管理与开放共享服务提出了更好的保障。
2) 评价结果讨论从政策分布和一致性等级看, 两国政策的国家级政策得分高于各部门和机构政策, 美国政策的得分整体高于我国, 美国的7 项政策处于前3 个等级, 而我国政策在4 个等级上均有分布, 且美国政策平均得分高于我国, 美国科学数据管理政策呈现“联邦政府—科研资助机构—科研机构” 和“数据战略—管理与开放计划—共享指南/ DMP 指南” 依次递减的特征; 国内科学数据管理政策基本呈“国务院—各部门—领域/ 区域” 和“管理办法—开放共享意见—专项政策” 依次递减的特征。总体看,科学数据政策指数随效力级别升高而升高, 随专指性增强而降低。中美两国政策差异的原因首先在于中美两国科学数据管理发展的时间差异, 美国科学数据管理起步早, 实践丰富; 其次, 中美两国的政策建设和管理模式不同, 我国是自上而下的政策制定、执行和管理模式, 而美国则是自上而下和自下而上同步发展, 全方位开展面向数据整个生命周期的政策的制定、执行。
两国政策的政策性质(X1)、效力级别(X3)、政策时效(X2)的平均值几乎一致, 说明两国政策的发布主体和政策目标差别不大, 也说明参评政策的选取具有一定可比性。政策功能(X8)、政策受众(X5)、政策领域(X4)的分差不高于0.06, 说明两国参评政策的对象差别不大, 政策发挥的功能也基本一致; 政策工具(X6)、政策内容(X7)和政策评价(X9) 的平均值差大于0.1, 其中政策内容(X7)指标分差达到了0.39, 说明我国科学数据管理政策内容还需要不断完善, 政策规划和目标需要进一步明确。
从政策得分与各指标关系来看, 我国政策均值为7.90 分, 美国政策均值为8.45 分, 总体的政策均值为8.18 分; PMC-AE 指数得分与“效力级别”“政策功能” “政策内容” 的关系较密切; 与“政策领域” “政策受众” “政策工具” 指标的关系一般密切; 与“政策时效” “政策评价” “政策性质”关系较小。就政策主体而言, 我国参评政策时效(X2)平均得分为0.73, 美国为0. 83, 说明我国科学数据管理政策发布的时间跨度小于美国; 两国政策的整体效力级别(X3)的平均分为0.6, 说明两国参评政策整体效力级别相等, 但我国只有P5 达到了行政法规级别, 说明我国科学数据管理政策整体效力级别偏低; 从各层级政策分布看, 我国政策的分布范围有限, 国务院政策较少, 各部门、机构政策不完善, 尤其科研资助机构和科研机构政策明显缺失, 而美国资助机构在政策制定和执行中起到了关键作用。
就政策对象而言, 两国参评政策的政策领域(X4)和政策受众(X5)的得分差异明显, 美国政策的政策受众(X5)与政策领域(X4)更加具体, 国内则更宽泛, 国内多是以部门为主的引导性的政策,政策受众多用“法人单位” “各级相关负责单位”等泛指, 而美国多机构专指性政策, 政策作用对象精确到具体项目。
就政策措施而言, 在政策工具(X6 )上, 美国政策对政策工具的使用较全面, 国内政策对政策工具的应用还不全面。由于各政策对象的差异, 政策功能(X8)在经济建设功能上表现较差。政策内容(X7)方面, 我国均值为1.02, 美国均值为1.42,两国分值差异较大。我国政策内容整体得分不高,科学数据管理计划、数据分类分级、数据质量等内容设计不完善。原因在于两国在政策内容的设置方面的差异, 我国是以科学数据汇交政策为切入点,逐步制定生命周期过程中的管理政策, 这样虽能很好地统领全局, 但会造成数据范畴模糊、分工不明确、管理界限不清晰、政策执行和更新效率不高等问题; 美国则倡导各资助机构、部门针对性管理并根据发展及时更新, 如NHS每4 年更新一次数据战略, NIH 会根据联邦政策和公共意见及时更新政策内容和管理制度。
就政策目标而言, 14 项政策分差不大, 说明科学数据管理政策的整體目标和管理范围宏大, 也有较为明确的部署。但政策性质(X1 )和政策评价(X9)中, 部分政策定义模糊, 管理界限不明确, 没有成熟的执行路线。
4结论
综上可见, 我国科学数据管理政策仍有较大完善空间, 具体如下:
首先, 在政策体系建设上, 我国应该加强中、微观层面的政策建设, 明确“国家级—省市/ 行业—机构” 不同层级政策的科学数据管理范畴和管理措施, 形成全层次、全领域的政策体系; 各层级要面向“数据安全” “开放共享” “创新与发展” 等制定建设目标和周期, 明确实现方法和路径; 政府牵头多方合作, 具体政策制定明确以“科学数据”为核心, 明确政策对象、服务对象、政策需求、行动路线、阶段性目标、政策落实方法等。
其次, 在政策内容设计上, 应细化政策分工,围绕科学数据生命周期制定更加详细的管理规定;相关部门在科学数据的管理计划、采集、汇交、保存、开放共享、利用增值、质量安全等方面分别建立更加明确的指南; 建立层次完善的评价考核机制, 完善自我审核、科学数据汇交时机构审核以及国家审查等各个环节的标准; 根据时代需求和国家战略部署及时调整和更新政策, 提升政策成效。
第三, 加强政策保障, 实现政策目标。发挥国家数据局的作用, 确定科学数据管理和治理的优先级别、治理路线和计划; 明确各利益群体职责、数据隐私和产权划分、数据分类分级整合等; 收集各方反馈意见、科学数据管理和共享需求, 制定政策标准化要素或者框架; 协调各方政策、标准和技术, 跟踪各领域、省市、机构的执行情况; 加强基础设施的供给能力, 加强数据平台的建设, 开发自动化工具, 制定统一标准, 提高平台的互操作性;构建实践社区, 通过社区形成基于社区的政策自我完善机制; 发挥好科研资助机构的作用, 设置相应研究课题, 支持对关键核心问题开展相关研究。
