
基于BERT模型的糖尿病在线健康社区命名实体识别*
2023-12-21 04:52梁宇进符传山陈劲松
吉首大学学报(自然科学版) 2023年5期
梁宇进,符传山,陈劲松,陈 铭,周 跃,徐 倩,
(1.吉首大学计算机科学与工程学院,湖南 吉首 416000;2.吉首大学医学院,湖南 吉首 416000;3.医学信息研究湖南省普通高等学校重点实验室(中南大学),湖南 长沙 410013)
国际糖尿病联盟(International Diabetes Federation,IDF)最新公布的全球糖尿病地图数据[1]显示:2021年全球20~79岁糖尿病患病者达到5.37亿,患病率为10.50%,预计到2030年,这一数字将增至6.43亿,患病率达11.3%;2021年中国20~79岁糖尿病患者超过1.41亿,患病率为11.2%,预计到2030年,这一数字将超过1.74亿,患病率高达13%,排名全球第一.糖尿病的高患病率和高医疗费用会给全世界带来巨大的卫生资源压力和经济负担.在线健康社区依托其强大的互联网平台、丰富的医疗资源和健康咨询等优势,可以为糖尿病患者提供疾病管理和信息咨询服务.此外,它还保存了大量的病例信息、医学知识和处方信息[2-3].因此,识别在线健康社区中相关的医学实体,有助于更好地为患者提供个性化的医疗和健康信息服务,以及决策参考和情感支持[4].
在线健康社区中的医学实体识别,是利用自然语言处理技术对健康社区文本进行医学实体提取和分类,为进一步挖掘和识别用户信息需求主题及提取用户特征奠定基础[5].精确识别医学实体已成为在线健康社区文本挖掘领域的研究热点之一.苏娅等[6]针对在线医疗问答信息,采用机器学习模型条件随机场(Conditional Random Field,CRF),在好大夫问答数据集上成功地实现了在线问答文本中的医疗实体识别.然而,基于机器学习方法进行识别需要投入大量的人工和时间成本.Wang等[7]对健康社区问答文本进行实体标注,并采用双向长短期记忆网络(Bidirectional Long-Short Term Memory,BiLSTM)与CRF的组合模型(BiLSTM-CRF)进行训练,以实现糖尿病相关实体的识别和提取.然而,由于BiLSTM-CRF模型在上下文语境中的语义识别能力有限,实体识别效果仍存在局限性.近年来,基于Transformer的双向编码器表征 (Bidirectional Encoder Representations from Transformers,BERT)模型作为一种具有更强的上下文长距离语义学习能力的预训练模型,在电子病历[8-10]和生物医学[11-12]的命名实体识别中得到了广泛应用.
目前,糖尿病在线健康社区文本实体识别存在歧义、无法准确识别上下文语义和语料不规范等问题[11].为了解决这些问题,笔者拟采用规范标注语料库,并从患者-患者交流型的“甜蜜家园”采集数据,构建BERT-BiLSTM-CRF模型进行医学命名实体识别,以期为糖尿病患者提供个性化医疗服务.
1 数据采集及预处理
“甜蜜家园”(https:∥bbs.tnbz.com)是目前中国最专业、最活跃的糖尿病患者-患者交流社区之一.本研究选取“甜蜜家园”健康社区近10年的相关数据进行模型训练.数据采集和预处理过程主要分为4个步骤:(1)数据采集.利用Python编程语言爬取“甜蜜家园”健康社区的数据,并将其保存为csv文件格式.(2)数据清洗.对网站文本数据中的表情符、换行符等无关字符进行清洗和预处理,并将数据保存为JSON文件格式.(3)文本标注.参考阿里云“天池”医疗数据集中的糖尿病分类标准,在医学专家指导下,由2位医学专业学生使用Doccano注释工具对健康社区文本中的实体分类作标注.标注的类别包含疾病(DIS)、临床表现(FEA)、药物(DRU)、检验(IND)、身体部位(BOD)和情绪(EMO).(4)数据分割.将标注好的数据按照9∶1比例分为训练集和测试集,并将JSON格式的文件转录为BIO形式.BIO形式的标注采用三元标记集{B,I,O},其中B表示实体开始位置,I表示实体内部位置,O表示不属于实体的词.实体分类情况见表1.

表1 实体分类
2 基于BERT的BiLSTM-CRF模型构建
2.1 BERT-BiLSTM-CRF模型概述
实体识别模型BERT-BiLSTM-CRF包含3层:(1)BERT字向量层.这层使用预训练的BERT模型生成字级别的词向量,得到文本输入的语义表示.(2)BiLSTM层.词向量通过BiLSTM层进行语义编码,捕捉文本中上下文信息,并生成更丰富的特征表示.(3)CRF层.使用CRF层对BiLSTM层输出特征序列进行标注,滤筛出一些不符合标注规则的实体,并输出概率最大的标签序列.BERT-BiLSTM-CRF模型结构如图1所示.

图1 BERT-BiLSTM-CRF模型结构Fig. 1 Structure Diagram of BERT-BilSTM-CRF Model
2.2 BERT预训练层构建字向量
BERT模型采用遮蔽语言模型和下一句预测来捕捉文本中句子和单词的上下文语义.从结构上看,BERT是将多个Transformer编码器堆叠在一起进行特征提取.每个Transformer编码器由Self-Attention层和前馈神经网络层组成.Self-Attention是Transformer的核心机制,通过查询(query)、键(key)和值(value)之间的注意力权重,使每个单词都能够对其他单词进行加权聚合,这样就可以捕捉到每个单词与上下文的关系,并将这种关系编码成上下文向量表示.注意力机制的表达式为

2.3 BiLSTM层进行语义编码
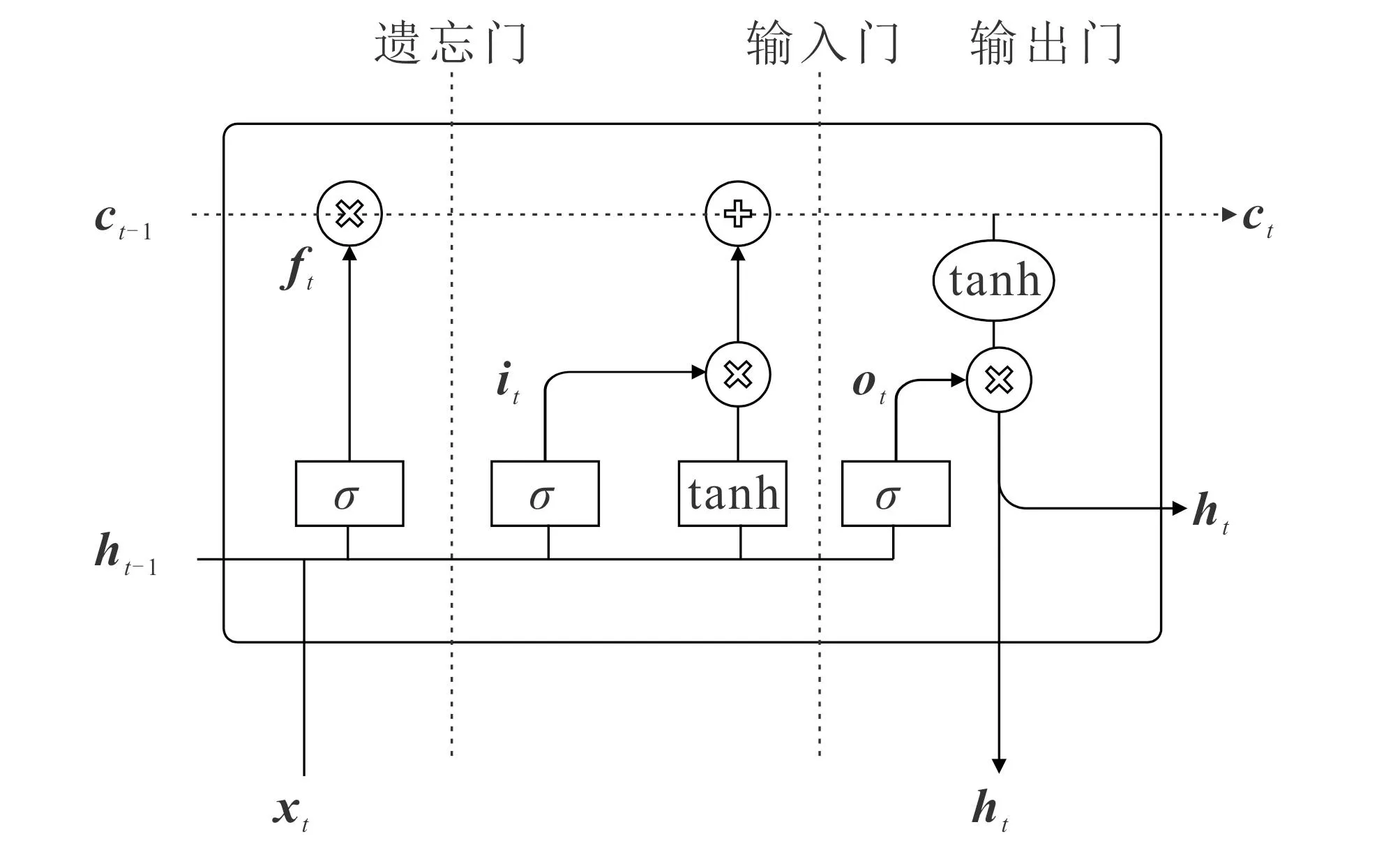
图2 BiLSTM模型结构Fig. 2 BiLSTM Model Structure
长短期记忆网络(Long-Short Term Memory,LSTM)是一种非线性动态模型,已在模式识别领域广泛应用.LSTM的核心结构包括遗忘门、输入门、输出门和记忆门.LSTM通过输入门和遗忘门的功能,实现对信息的筛选和传递,将有用的信息传递到下一个时间步,并通过记忆cell的输出和输出门的输出相乘而得到整个结构的输出.然而,LSTM模型的单向性限制其同时处理上下文的信息.为了解决这个问题,引入BiLSTM.BiLSTM的主要思想是针对每个单词序列使用正向和反向的LSTM,并将它们的输出在同一时间点进行组合,以获得更全面的上下文信息.因此,在每个时间点上,同时存在前向和后向的信息.这种结构(图2)可以更好地捕捉到上下文之间的关系,提供更丰富的语义信息.
正向LSTM层的表达式为

2.4 CRF优化标签序列
CRF是一种判别式模型.用建模输入序列和输出标签之间的条件概率分布来提高标注任务的准确性,与BiLSTM模型结合可以获得更准确的标签序列.当观测序列X=(x1,x2,…,xn)时,预测序列Y=(y1,y2,…,yn),于是得到分数函数
其中:tk为转移特征,依赖于当前和前一位置;sl为状态特征,依赖于当前位置;λk,μl为相应函数的权重.预测序列Y产生的条件概率为

在训练过程中,通过似然函数可计算出有效合理的预测序列.Y序列是当似然函数为
3 实验阶段
3.1 实验环境及相关参数
基于BERT-BiLSTM-CRF模型对“甜蜜家园”数据集进行实体识别的具体流程(图3)如下:
Step1读取和加载训练文本,使用BERT中文预训练模型词典vocab.txt进行词表构建.
Step2调用相关工具类的函数进行多维张量构建,将文本转换为BERT模型可以接受的输入格式.
Step3定义学习率、隐藏层大小等相关参数,并开始每一轮的训练(epoch).
Step4在每一轮epoch中,通过传入参数shuffle=False来遍历随机打乱的训练数据,以保持数据的顺序性.
Step5评估模型的性能,在每个epoch结束后计算模型在训练集上的损失,以及其他评估指标(如准确率、召回率等).如果损失值不再下降或训练过程中达到了设定的最大patience计数,就提前结束训练,避免过拟合.
Step6输出训练评估结果.

图3 训练任务流程Fig. 3 Flowchart of Training Task
下面是涉及的一些关键代码:
(1)使用哈工大讯飞实验室的中文预测训练模型进行词嵌入和模型构建:
pretrain_model_name='hfl/chinese-roberta-wwm-ext'
BertModel.from_pretrained(pretrain_model_name)
(2)将双向的BiLSTM和CRF层进行初始化:
self.LSTM=nn.LSTM(self.embedding_dim,self.hidden_dim,num_layers=self.rnn_layers,bidirectional=True,batch_first=True)
self._dropout=nn.Dropout(p=self.dropout)
self.CRF=CRF(num_tags=self.tagset_size,batch_first=True)
self.Liner=nn.Linear(self.hidden_dim*2,self.tagset_size)
(3)字嵌入传播并返回张量值,保证其是连续的:
embeds=self.word_embeds(sentence,attention_mask=attention_mask).last_hidden_state
hidden=self._init_hidden(batch_size)
lstm_out,hidden = self.LSTM(embeds,hidden)
lstm_out=lstm_out.contiguous().view(-1,self.hidden_dim*2)
d_lstm_out=self._dropout(lstm_out)
l_out=self.Liner(d_lstm_out)
lstm_feats=l_out.contiguous().view(batch_size,seq_length,-1)
(4)使用Adam优化器进行优化:
optimizer=torch.optim.Adam(model.parameters(),lr,weight_decay)
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer,mode="max",factor=0.5,patience=10)
实验环境为1台i5-8250u处理器和1台MX150显卡的笔记本电脑,运行Windows10操作系统.实验使用Microsoft Visual Studio Code编辑器新建一个Python项目文件夹,并在Anaconda中创建一个基于Pytorch的深度学习虚拟环境.实验的参数设置见表2.采用梯度裁剪技术,以防止训练过程中出现梯度爆炸或梯度消失等问题.训练过程中使用Adam优化器,并引入早停机制.为了避免过拟合现象,设置Dropout为0.5.

表2 实验参数设置
数据训练集采用精确率(Precision,P)、召回率(Recall,R)、调和平均(F1)作为模型质量和性能的评价指标:
其中:XTP为真阳性样本(正确预测为正例的样本数);XFP为假阳性样本(错误预测为正例的样本数);XFN为假阴性样本(错误预测为负例的样本数);P衡量模型预测为正例的样本中有多少正确的正例;R衡量模型正确预测为正例样本在真实正例中的比例;F1平衡精确率和召回率,更全面地评估模型的性能.在评估模型时,计算每个类别的P,R和F1,并将其各自的平均值作为整体性能指标.
3.2 实验结果及模型评估
按照实体标准分类原则,糖尿病社区文本模型的训练评估结果见表3.从表3可知,6个分类的精确率、召回率和调和平均差别不大且稳定在较高水平(P=90.83%,R=76.30%,F1=82.93%).高精确率说明BERT-BiLSTM-CRF模型对在线健康社区中正样本的识别率较高,且不容易将负样本错误识别为正样本.召回率相对较低,表明该模型将一部分社区文本中的正样本错误地识别为负样本.调和平均的良好表现说明,该模型对社区文本中的6大类命名实体拟合程度较高.综上,BERT-BiLSTM-CRF模型在糖尿病患者-患者健康社区文本命名实体识别中具有较好的识别效果,可以用于此类文本的训练和预测.

表3 糖尿病社区文本模型训练评估结果

图4 交叉熵损失值曲线Fig. 4 Cross-Entropy Loss Curve
交叉熵损失值(loss)结果如图4所示.BERT-BiLSTM-CRF模型训练较完整,验证集的loss值和训练集的loss值相差不大,且随着epoch值的增加而逐渐减小.这符合对BERT这类模型训练的预期效果.模型的拟合程度较理想,说明模型可以在训练中逐渐学习到文本中的特征和模式,完成糖尿病社区文本的命名实体识别任务,且达到预期效果.
实验发现,Ⅰ型糖尿病社区专栏文本中混杂了Ⅱ型糖尿病社区专栏文本的内容,而Ⅱ型糖尿病专栏文本中也混杂了Ⅰ型糖尿病社区专栏文本的内容.为了处理这种情况,笔者对这2个专栏的文本数据使用相同的模型进行了预测.Ⅰ型和Ⅱ型专栏词频统计见表4.

表4 Ⅰ型和Ⅱ型专栏词频统计
词频统计是指识别出的每一类实体数量占所有实体数量的百分比.社区文本的词频统计结果为:疾病占26%,临床表现占13%,药物占16%,检验占8%,身体部位占15%,情绪占22%.这些词频统计结果由Python和matplotlib生成.预测数据显示:在糖尿病健康社区中,患者之间交流较多且关注度较高的话题是疾病和情绪,分别占26%和22%,这说明患者最关心的是自身的健康状况,病情对大多数患者的情绪及心理状态产生了影响;检验和临床表现的话题占比较低,分别占8%和13%,这符合一般患者对专业检验指标不太了解的客观事实.词频统计数据显示:专业检验指标的高频词主要集中在血糖水平,占检验总数的80%以上;药物方面的高频词是胰岛素,占比高达90%.由此可见,患者更加关注的是血糖水平关联的并发症及药物的种类和剂量.这些话题都与个人生活状态和质量密切相关[13-14].
4 结语
笔者选择Ⅰ型糖尿病和Ⅱ型糖尿病2个专栏作为数据集进行BIO数据集标注,构建了BERT-BiLSTM-CRF模型完成实体识别.实验结果表明,该模型的精确率为90.83%,召回率为76.30%,F1达到82.93%,且从loss曲线上看,模型的训练符合预期目标.通过梯度裁剪和调整学习率,可以有效避免梯度爆炸、梯队消失和抖动震荡等问题,使模型处于较平缓的学习训练状态,获得较好的识别效果.研究结果显示,糖尿病患者-患者的在线健康社区中,患者关注高的话题与疾病、情绪和心理相关,他们最关心的是自身健康状况,而检验、临床表现等话题涉及较少.这说明患者对检验指标认知度较低(仅关注血糖水平的变化).药物方面的高频词是胰岛素,这表明患者比较关注胰岛素的使用及相关剂量.
值得注意的是,本研究数据样本中的Ⅰ型糖尿病和Ⅱ型糖尿病专栏的文本信息存在重复内容,这可能会对实验结果造成一定的误差.下一步笔者考虑剔除重复内容,对这2类文本分别进行预测,以期获得更好的拟合效果.此外,笔者还将进一步分析不同类型实体的关联性和语义关系,并调整实验参数,以训练出更好的模型用于实体识别.
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
中国外汇(2019年18期)2019-11-25
制造技术与机床(2019年10期)2019-10-26
电子制作(2018年18期)2018-11-14
知识经济·中国直销(2018年8期)2018-08-23
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
