
基于增量学习的深度人脸伪造检测
2023-12-24 10:34赵泽军范振峰丁博夏时洪
数据与计算发展前沿 2023年6期
赵泽军,范振峰,丁博,夏时洪*
1.中国科学院计算技术研究所,北京 100190
2.中国科学院大学,北京 100049
引 言
深度伪造起源于人脸合成技术,2015-2016年,美国程序员圈子开始利用此技术制作“换头”视频用于娱乐消遣。2017 年年底,Reddit 网站用户“Deepfakes”在网上发布了一段经过AI技术篡改的某女星的不雅视频,这一事件正式标志着人脸视频深度伪造技术的兴起[1]。此后,随着DeepFake 技术的不断发展,基于其技术的软件已经开始普及,如国外Facebook 公司出品的Face Swap Live 软件、国内陌陌公司出品的Zao软件等,其能自动快捷地合成人脸图像和视频,降低了伪造技术的门槛,使得个人可以轻易地篡改已有图像和视频中的内容,尤其是人脸,DeepFake 技术也逐渐从娱乐领域渗透到媒体、体育、政治等各领域。如2016 年,美国大选期间,特朗普支持者制作佩洛西的伪造视频扰乱选举秩序;2018 年,美国出现了前任总统辱骂时任总统的伪造视频;2022 年,俄乌冲突期间,互联网上出现了与两国总统发言不实的伪造视频[2]。鉴于人脸伪造技术带来的负面影响,先后涌现出大量的人脸伪造检测方法[3]。
伴随着深度学习的发展,伪造检测技术从传统的机器学习分类模式逐渐演变为利用各种关键特征的微小差异来进行真伪检测。现有的伪造检测技术主要包括但不限于以下4类:
(1)基于深度神经网络特征提取的方法。此类方法将真实样本和合成样本直接送入神经网络中进行有监督训练,期望网络学习到正负样本不同的内在分布,并通过一个二分类器输出预测结果。这类方法往往依赖于网络本身,特征提取能力强的网络通常有更好地分类结果,目前最流行的基础网络如ResNet[4]、CapsuleNet[5]、XceptionNet[6]以及EfficientNet[7]等已经被用于人脸伪造检测任务。这些方法在域内测试了良好的检测结果,但在域间测试检测性能大幅下降,表现为泛化性能的不足。因此,很多工作致力于提高网络的泛化性能,共同思路都是希望通过找到或者强化合成数据存在的伪造痕迹来进行判别。Yu 等[8]提出通过挖掘通道差分图像和频谱图像中的内在特征来改进网络的泛化能力;Liu 等[9]提出利用全局图像纹理信息来进行伪造检测的网络结构Gram-Net,并改善了泛化能力;杨少聪等[10]提出用多级特征全局一致性的方法提高了网络的泛化能力。这些工作推进了伪造检测技术的发展,但还不能较好地解决泛化能力不足的问题。
(2)基于图像上下文空间的检测方法。此类方法认为合成图像只是对图像中面部区域进行了篡改,而图像中其他部分(比如背景、躯干)并没有更改,理论上真实图像和合成图像内部存在着必然的不同,真实图像内部是连续的,而合成图像内部则是拼接而成,由此可进行真伪检测。Li 等[11]发现合成的人脸图像拥有一种融合边界,而真实图像没有这样的边界,提出了一种检测边界融合痕迹的Face-X-Ray 方法;Dang等[12]提出利用注意力机制来定位人脸图像中的伪造区域,并用其改进最后的分类任务;蒋小玉等[13]提出了将篡改区域定位、篡改边缘提取和真伪判别分类融为一体的三分支多任务学习框架,并加粗篡改边缘辅助最后的分类。基于图像上下文空间的检测方法对于只存在局部篡改的图像有较好检测性能,并且通常比直接用神经网络进行特征提取的方法具有更优的泛化性能,但是对于整体合成的图像,这类方法检测效果欠佳。
(3)基于视频时序信息的检测方法。视频的本质是帧的快速切换,现有的人脸伪造视频大多是对每一帧分别进行伪造和处理,再压缩编码制成最后的视频,因此相邻帧间通常会产生时空差异。Güera 等[14]提出了一种时间感知管道,该管道首先利用CNN(Convolutional Neural Network)提取帧级特征,随后将特征送入RNN(Recurrent Neural Network)中进行训练,最后用训练好的RNN进行判别;Amerini等[15]提出视觉流动向量场的概念,将帧间预测误差与长短期记忆(Long Short Term Memory,LSTM)网络结合起来,基于VGG-16得到了不错的检测结果;Masi 等[16]提出结合频率域特征和RGB 图像(RGB 三通道)特征的双分支网络,利用组卷积整合各分支特征并输入到LSTM 进行检测;Fei等[17]发现真实和合成视频中人脸运动的振幅有较大差异,利用InceptionV3 提取特征,结合LSTM 提取时序信息,取得了不错的检测效果。基于视频时序信息的检测方法,推进了人脸伪造检测技术的实用化,共同思路都是利用相邻帧间人物运动不一致、色彩与纹理不正常抖动等信息进行伪造检测。
(4)基于生理信号的检测方法。此类方法认为真实的人具有丰富的生理特征,比如心率、脉搏和眨眼等,而计算机合成的人往往不具备这些特征或者生理特征前后不一致。Li 等[18]针对人眼眨眼具有很强的时间依赖性,提出基于眨眼检测的方法鉴别伪造视频;Yang 等[19]提出了监测中心表情和头部姿势的方法;Matern等[20]提取眼睛、牙齿以及脸部轮廓等位置的特征来检测视频真伪;Ciftci等[21]提出监测脉搏信号的方法;Qi 等[22]提出利用心跳信号来检测视频中人物对象真实性的方法。基于生理信号的检测方法能够脱离视频载体(比如频率、像素等),利用人的持续生理信号进行真伪检测,在现有的方法中取得了具有竞争力的跨库测试准确率,但该方法对数据集的要求较高,且易受噪声和模糊影响,主要用于对重要人物的伪造视频检测。
由于DeepFake 技术在不断进步,不同伪造类型的数据也越来越多。现有方法在处理新的伪造类型时主要存在以下不足:1)在已知伪造类型的数据上检测能力优异,但在未知伪造类型的数据上检测能力欠佳,表现为泛化性能的不足;2)如果要求模型在新数据(未知伪造类型)上有较好的检测能力,需要使用旧数据(已知伪造类型)和新数据重新训练模型,这通常需要消耗较大的存储和计算资源,并且相对来说阻碍了模型实时学习新数据的能力。针对现实场景中不断出现的未知伪造类型的数据,本文提出一种人脸伪造检测的增量学习方法,简言之,本文的检测网络在面对新数据时不用重新训练模型,而是在原模型的基础上以增量学习的方式学习新数据,最终模型能以较低的训练代价在新旧数据上达到良好的伪造检测能力。
增量学习又称为连续学习(continual learning)或终身学习(lifelong learning),主要有以下特点:1)随着模型的更新,需要在新旧数据上同时保持良好的识别能力;2)计算能力与内存占用随着类别数的增加固定或者缓慢增长,原始的训练数据不允许再被访问;3)模型可以持续不断地学习新数据中的新知识。增量学习有多种实现方式,其出发点都是为了避免灾难性遗忘,过去几年里很多方法被提出以解决灾难性遗忘问题,主要包括但不限于以下几类:1)基于回放的方法。Rebuffi等[23]提出基于表征学习的增量分类器(iCaRL),其利用旧数据的代表性样本和所有的新数据一起训练,取得了不错的分类结果;Hu 等[24]提出了一个因果框架来解释类增量学习(class incremental learning)中的灾难性遗忘问题,并提出数据流中存在着增量动量效应,消除它有助于抵抗遗忘;2)基于正则化的方法。Li等[25]提出无遗忘学习策略LwF(Learning without Forgetting),即让旧模型先在部分新数据上预测,并将预测结果作为这部分数据的标签,然后将这部分数据视为旧数据与剩下的新数据一起投入训练,一定程度上缓解了灾难性遗忘问题;Kirkpatricka 等[26]提出一种可塑权重巩固(Elastic Weight Consolidation,EWC)的方法,即在损失函数中增加一个惩罚项来限制模型修改先前任务中的重要权重,以此来缓解遗忘问题;3)基于参数隔离的方法。Mallya等[27]提出一种PackNet的方法,该方法在训练新数据时固定旧数据的参数,以此来抵抗灾难性遗忘;Zhang 等[28]提出一种特征表示和分类器的解耦学习策略,即训练新数据时只更新分类器,避免了特征表示中的知识遗忘;Yan等[29]提出可动态扩展的增量学习方法DER(Dynamically Expandable Representation),即为新任务构建新的特征提取器,在训练时固定旧特征提取器的方法取得了具有竞争力的分类结果。Marra 等[30]提出将iCaRL[23]和真伪检测(真实图像/GAN(generative adversarial network)生成的图像)结合起来,取得了不错的检测结果,受此启发,本文在检测网络XceptionNet 的基础上引入了增量学习,模型在遇到新的伪造数据时以增量学习的方式动态地更新其网络结构,并挑选出代表性样本存储在“记忆”中,最终在新旧数据上保持良好的检测能力,如图1 所示,其中检测网络可以是人脸伪造检测领域任意流行的检测网络。Rössler等[31]发现在人脸伪造检测领域XceptionNet相比于其他网络具有更优的检测能力,所以本文的检测网络选择了XceptionNet。
本文主要有以下贡献:1)在已有的增量学习框架DER[29]上进行改进,使其适应人脸伪造检测任务;2)设计3 种分类学习系统,加强分类器的判别能力;3)在实验定义的FF++扩充集(包含4 种伪造人脸及相应的真实人脸)和ForgeryNet 扩充集(包含15 种伪造人脸及相应的真实人脸)上进行测试,结果显示本文方法提高了模型对检测不断出现的伪造样本的有效性,同时能以较低的计算代价达到与现有方法相当的检测能力。
1 本文方法
在传统场景中,所有类别的训练数据在一次训练中全部出现,而在增量学习场景中,新类别随着时间的推移不断出现,这正好与不断更新的伪造类型的应用场景相吻合,如图1 所示。本文选择了一种成功的增量学习算法DER,该算法通过动态地扩展特征提取器来保持模型在新旧类别上的特征提取能力,同时为旧类别设置代表性样本以便于未来的训练,其中,代表性样本是避免忘记旧类的关键。算法的主要参数是存储容量M,它表示可存放的代表性样本的个数,反映的是现实场景中受限的存储容量。另外,人脸伪造检测是一个二分类场景,增量学习是一个多分类场景,为了更好的结合二者,本文设计了3 种分类学习系统,以适应检测分类问题。
1.1 方法总览
本文将整个检测任务视为增量学习中的类增量学习任务。在类增量学习过程的时刻t-1,标签空间为,模型可以对每一个旧任务Yi中的所有类别进行很好的预测,每一个任务Yi都有一种形式,其中表示任务Yi中第k类的输入图像,表示任务Yi中第k类的输入标签;在时刻t时,模型观察到新任务Yt,此时标签空间为,本文希望模型在中对所有任务中的所有类别都有很好的预测。本文的方法主要分为以下两个阶段:
1)特征提取阶段。本文利用DER提出的可动态扩展的特征提取框架在新旧类别上提取特征,最后将这些特征连接起来作为分类器的输入。
2)分类器学习阶段。本文考虑了3 种分类学习方式使增量学习适应伪造检测场景,分别为二分类学习、多分类学习以及多分支学习,并将三者之一用于最后的真假人脸分类中。
1.2 特征提取阶段
增量学习算法DER 的整体框架如图2 所示。在特征提取阶段,对于每个新任务i,模型为该任务新建一个特征提取器Fi,为了快速自适应,Fi的权重参数继承自Fi-1。在时刻t时,所有旧任务的特征提取器组成旧特征提取器Φt-1,Φt-1和新特征提取器Ft组成超特征提取器Φt,其中,对于输入x,Φt提取的特征υ为:
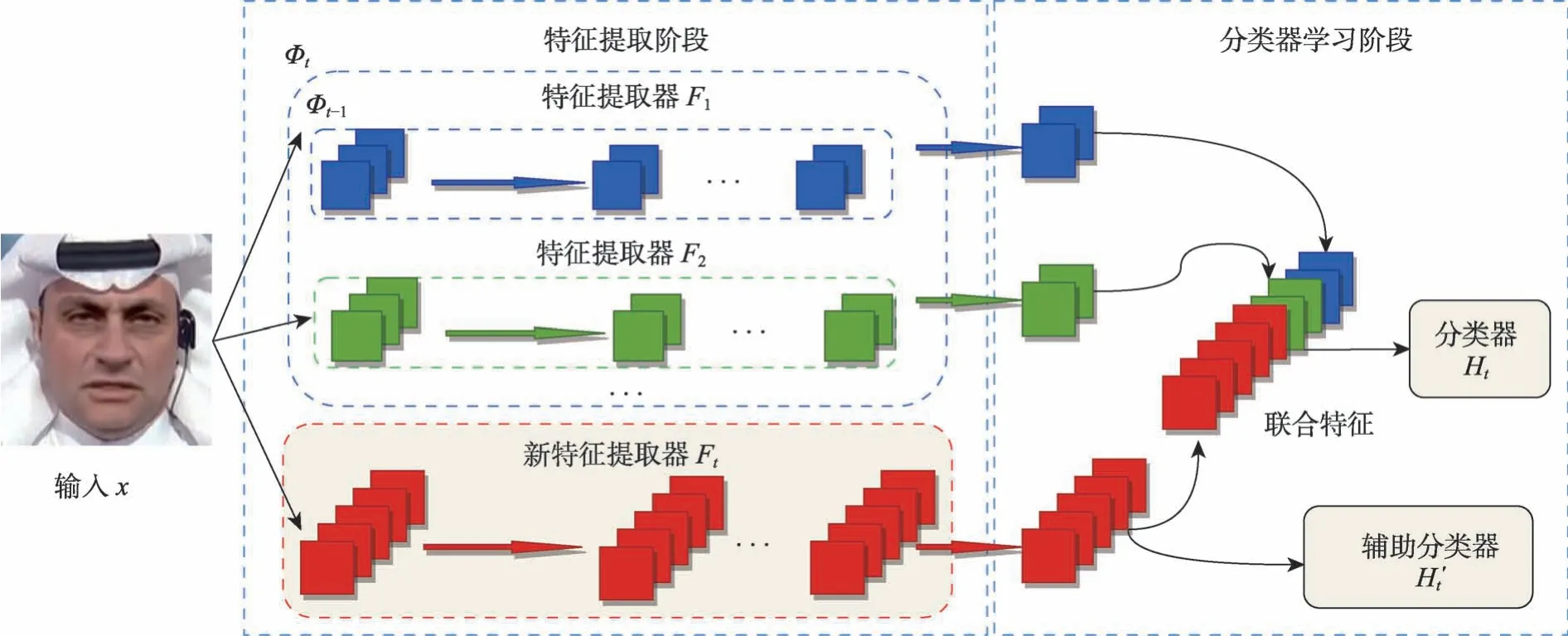
图2 DER[29]网络结构图Fig.2 DER[29]network structure
特征υ将输入到分类器中进行分类。为了减少灾难性遗忘,在时刻t时冻结了特征提取器Φt-1,因为它捕获了先前数据的内在结构。具体来说,时刻t时旧特征提取器Φt-1和批处理归一化的相关参数没有更新。
1.3 分类器学习阶段
增量学习算法DER的分类器学习阶段主要由分类器Ht以及辅助分类器H′t构成。在训练时,H′t被用来约束网络重点学习新任务的新特征,标签空间是|Yt|+1,包括时刻t时新任务Yt中的类别和所有的旧类别,其中所有旧类别被视为一个类别。对于时刻t时的输入x,H′t作如下预测:
随后式(2)将参与计算辅助损失LH′t。对于上一阶段得到的特征υ,分类器Ht作如下预测:
式(4)中,Ht的参数继承自Ht-1,以保留旧知识,Ht的输出维度不断更新,以匹配不断增加的类别数目,并对其新添加的参数进行随机初始化,其中͂,表示模型最后的预测类别。
为了将增量学习算法DER更好地应用到人脸伪造检测任务中,本文对DER 的分类器学习阶段进行改进,设计3种分类学习系统进行真假人脸图像的分类,其中三者之一将用于模型最后的分类,下文将对3 种分类学习系统作详细描述。
1.3.1 二分类学习
在二分类学习系统中,本文将整个问题视为二分类问题,结构如图3(a)所示。标签空间只有真/假两种标签,分别代表真实人脸和伪造人脸,由于在训练时只有真/假两种标签无法进行增量学习训练,所以本文根据不同伪造方法设计了多分类标签以辅助训练。具体来说,对于即将到来的新任务Yt,其形式为,其中表示时刻t中第k种伪造方法下的真实图像和伪造图像;表示时刻t中第k种伪造方法下的二分类标签;表示时刻t中第k种伪造方法下的多分类标签。在训练过程中,只有二分类标签参与了损失函数的计算,多分类标签只用于模型区分新类别和旧类别。二分类学习中,损失函数由二分类器的交叉熵损失LBC及辅助分类器的多分类交叉熵损失LH′t构成:
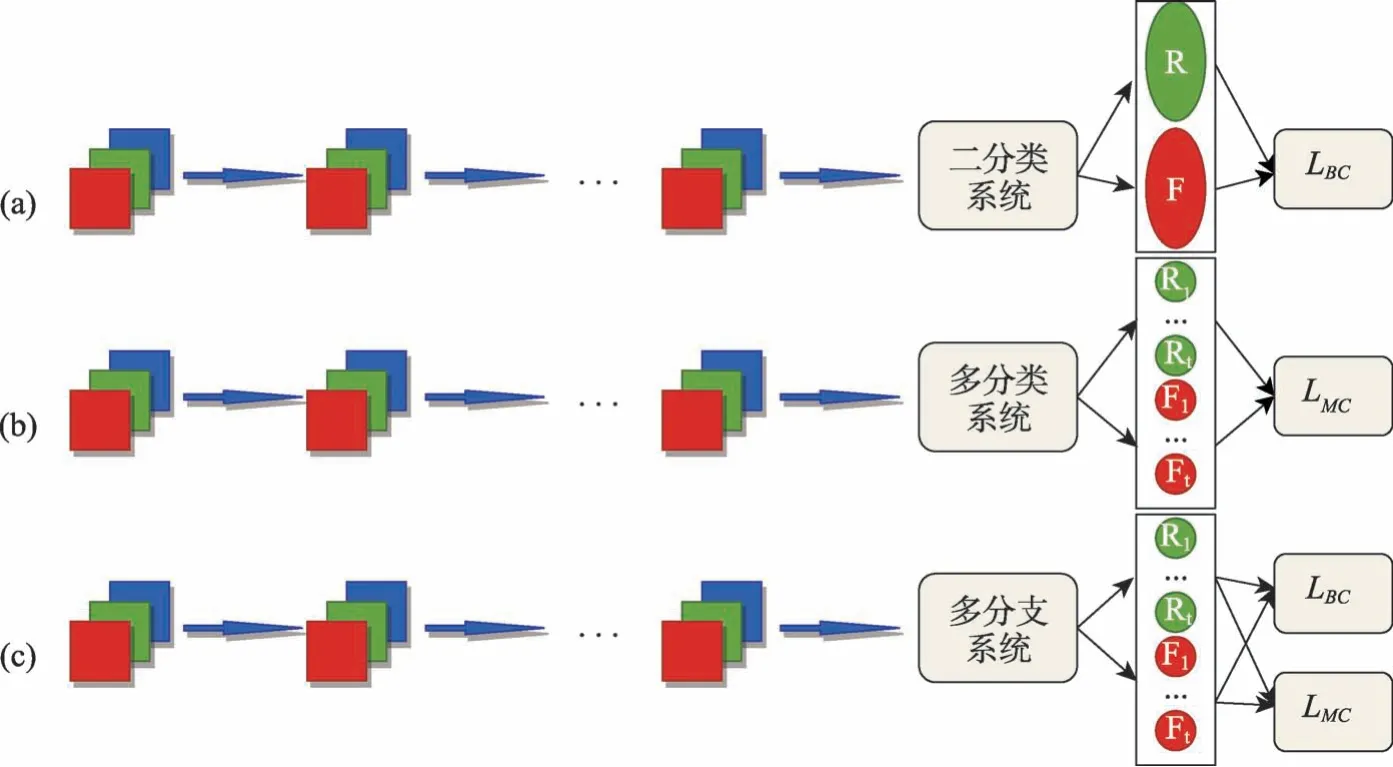
图3 分类学习系统.Fig.3 Classification learning system
其中,λa是控制辅助分类器效果的超参数。值得注意的是,在时刻t=1时,λa=0。
1.3.2 多分类学习
在多分类学习系统中,本文将整个问题视为多分类问题,结构如图3(b)所示,本文根据伪造方法的不同来对不同数据进行多分类。具体来说,对于即将到来的新任务Yt,其形式为,其中表示时刻t中第k种伪造方法下的真实图像和伪造图像,表示与之对应的多分类标签。本文将来自不同数据集下的真实图像视为不同的类别。在多分类学习中,损失函数由多分类器的交叉熵损失LMC及辅助分类器的交叉熵损失构成:
同二分类学习一样,λb是控制辅助分类器效果的超参数。
1.3.3 多分支学习
在多分支学习中,本文将二分类学习和多分类学习结合起来,利用多分类指导二分类,结构如图3(c)所示。同二分类学习,每一个输入图像都有两个标签,即二分类标签和多分类标签,不过它们都由一个多分类器管理。多分支学习是多分类学习的扩展,本文在式(6)的基础上增加了一个二分类损失约束,形成了多分支学习中的损失函数:
其中,λd是控制辅助分类器效果的超参数;λc则是平衡二分类损失和多分类损失的超参数。
2 实验设置
2.1 数据集
FaceForensics++数据集拥有来自YouTube的1,000 个真实视频及由4种伪造方法生成的4,000 个伪造视频。它由Rössler 等[31]所制作的FaceForensics数据集扩充而来,是目前伪造检测领域使用最多的数据集之一。4 种伪造方法分别 为DeepFakes[32]、Face2Face[33]、FaceSwap[34]、NeuralTextures[35]。其中DeepFakes 使用基于Encoder-Decoder 技术来交换源视频和目标视频的身份信息;FaceSwap 使用基于图形学的方法交换源视频和目标视频的面部区域;Face2Face 使用一种面部再现系统将源视频的表情传输到目标视频中;NeuralTextures使用基于GAN的以及神经纹理的方法修改了与口腔区域对应的面部表情。4种类型均在1,000个原始视频上生成对应的1,000 个假视频,并对真假视频均做了H.264 codec 压缩方式中的C0、C23、C40 压缩水平的压缩,总共包含超过180万张伪造图像。
ForgeryNet[36]为商汤科技在CVPR2021年公开发表的一个数据集,在数据规模(290 万张图像,221,247个视频)、操作(7个图像级方法、8个视频级方法)、扰动(36 个独立扰动及一些其他的混合扰动)方面是迄今为止最大的公开可用的深度人脸伪造数据集之一。它跨越了4 个任务:1)图像伪造分类,包括二分类(真/假)、三分类(真/伪造且更换人脸身份信息/伪造且不更换人脸信息)和n分类(真实数据和15种不同伪造方法生成的伪造数据);2)空间伪造定位,基于语义分割寻找图片中伪造区域;3)视频伪造分类,重新定义了视频级别的伪造分类,其中包含随机位置的操纵帧;4)时间伪造定位,输入一段视频,需要定位出伪造以及真实视频的时间片段用于定位被操纵的时间段。
在大量的人脸伪造公开数据集中,伪造数据的样本量往往远大于真实数据,这样的正负样本不平衡不利于本文实验。为了实验的有效性,由于FaceForensics++数据集已包含一种Real数据,本文在其c23版本基础上,新增了3种来自不同数据集的Real 样本,制备方法为随机选择该数据集下的10,000 张人脸图像,并将其随机对应到FaceForensics++数据集中余下的3 种伪造类型,即FaceForensics++数据集中的一种伪造类型数据和来自另外一个人脸数据集的真实数据构成一对,本文称其为一个任务,并将扩充后的数据集称为FF++扩充集;类似地,ForgeryNet 数据集也做同样处理,新增了14 种来自不同数据集的Real样本,本文称其为ForgeryNet扩充集。关于FF++扩充集及ForgeryNet扩充集的详细信息参见表1、表2。

表1 FF++扩充集Table 1 FF++expansion set

表2 ForgeryNet扩充集Table 2 ForgeryNet expansion set
2.2 评价指标
本文考虑了3 个评价指标来全面评估模型的伪造检测能力。在二分类学习中,采用ACC和AUC(Area Under roc Curve)来评估模型;在多分类学习中,采用ACC 和F1-Score 来评估模型。表3为在分类任务中常用到的混淆矩阵。

表3 混淆矩阵Table 3 Confusion matrix
2.2.1 ACC
ACC为Accuracy的简写,即准确率,指的是正确预测的样本数占总预测样本数的比值,它不考虑预测的样本是正例还是负例,反映的是模型算法的整体性能。计算方式为:
2.2.2 AUC
受试者操作特征(Receiver Operating Characteristic,ROC)曲线的横轴为假正类率(False Postive Rate,FPR),代表模型预测的真实样本中实际伪造样本占所有伪造样本的比例,计算方式如式(9);纵轴为真正类率(True Postive Rate,TPR),代表模型预测的真实样本中实际真实样本占所有真实样本的比例,计算方式如式(10)。AUC是一种用来度量分类模型好坏的标准,其值是处于ROC 曲线下方的那部分面积的大小,面积越大说明模型的分类性能越好。
2.2.3 F1-Score
F1-Score 又称为平衡F 分数(balanced F Score),它被定义为精准率(precision)和召回率(recall)的调和平均数,其中precision 计算公式如式(11),recall 计算方式为式(12)。F1-Score指标综合了precision 与recall 的结果,取值范围为0到1,越接近1代表模型
的分类能力越好,越接近0则代表模型的分类能力越差,其计算方式如式(13)。
2.3 超参数设置
在处理FF++扩充集时,本文按等时间间隔切出每个视频中的10 帧,然后使用Retinaface[48]检测出每一帧中的人脸并进行裁剪。对于每帧中检测到的多人脸情况,本文选择其中人脸面积最大的作为最后的训练样本,对于检测不到人脸的帧,则重新进行筛选。最后得到每种伪造类型及与之对应的真实数据下的10,000 张人脸图像,并按照7∶1∶2 的比例将其划分为训练集、验证集和测试集。在数据预处理阶段,为了不引入其他人为的噪声,本文只使用了随机水平翻转作为数据增强,最后网络的输入为256×256×3 的人脸图像。在处理ForgeryNet 扩充集时,本文直接使用了其中的图像级数据作为训练样本,除了不用将视频转化为帧外,其他数据预处理方法同FF++扩充集保持一致。在使用增量学习的XceptionNet实验中,训练阶段,本文使用SGD 优化器迭代模型5 代,学习速率为10-2(10-1、10-2、10-3在ForgeryNet 扩充集上的二分类平均准确率分别为94.21%、94.74%、91.98%),批大小设为128,momentum 为0.9,权重衰减值为0.0005。在训练阶段,新数据的数量要远大于旧数据,这会造成样本不平衡,为了解决这个问题,受Rebuffi 等[23]工作启发,本文选择herding selection 策略[49],选择距离该类样本中心最近的样本作为该类的代表性样本,新类的代表性样本和旧类的代表性样本构成一个新子集,子集中每个类别的样本数量一致,之后在新子集上进行微调训练。微调阶段,本文使用SGD 优化器迭代模型20代,批大小设置为128,momentum为0.9,权重衰减值为0.0005,采用warm-up学习率调整策略,初始学习速率为0.1,在第10 代衰减为10-2,直至训练结束。在使用传统Xception-Net的实验中,本文使用SGD优化器迭代模型15代,批大小设为128,momentum为0.9,权重衰减值为0.0005,初始学习速率为10-2,在第10 代衰减为10-3,并保持学习率为10-3直至训练结束。
3 实验结果与分析
本文的所有实验均是在FF++扩充集及ForgeryNet 扩充集上完成。实验环境采用的是Pytorch深度学习平台,所有实验均在2张NVIDIA GeForce RTX 3090上完成。
3.1 超参数λc、λd
为了便于后面的实验对比,本文首先测试了多分支学习中超参数λc、λd的最佳组合。在FF++扩充集上进行训练和测试,每次增量为1 个任务,共4个增量时刻,存储容量M设为2,048。本文固定λd=1,重点关注不同的λc给实验带来的影响,实验结果如表4 所示。结果表明,λc=1 在多分支学习中性能最好,所以,在后面的多分支系统中,本文选用λc=1、λd=1的组合。
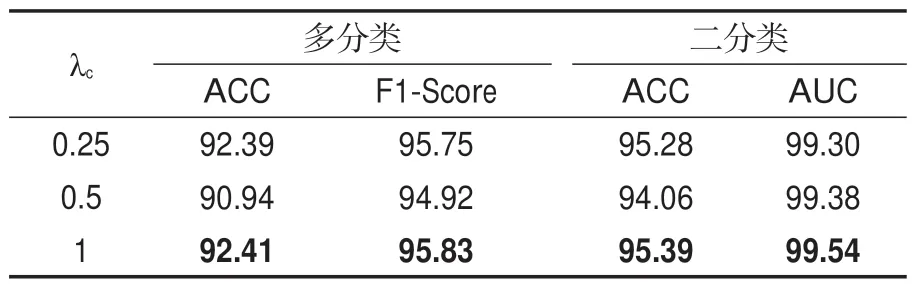
表4 FF++扩充集上多分支学习在不同λc下的评价指标结果Table 4 Results of multi-branch learning on FF++expansion set under different λc /%
3.2 分类学习系统
为了比较不同分类学习系统的伪造检测性能,本文在FF++扩充集和ForgeryNet 扩充集上进行训练和测试。在FF++扩充集上,每次增量为1 个任务,共4 个增量时刻,设置M为2,048;在ForgeryNet 扩充集上,每次增量为3 个任务,共5 个增量时刻,设置M为2,048。以3 种分类学习系统共有的评价指标ACC 作为评判标准,实验如果如表5所示。所以,本文选择多分支学习进行后面的实验。

表5 FF++扩充集和ForgeryNet扩充集在3种分类学习系统下的平均准确率Table 5 Average accuracy of the FF++expansion set and the ForgeryNet expansion set under the three classification learning systems /%
3.3 有效性
存储容量M是本文方法的关键,不同M往往对模型性能有较大影响。如表6所示,多分类准确率衡量模型对不同样本的适应能力,二分类准确率则衡量模型对真假样本的判别能力。当M设为0时,模型的多分类准确率为24.92%,二分类准确率为86.28%;当M设为1,024 时,模型的多分类准确率为88.16%,二分类准确率为93.02%。结果表明,提升M的值可以直接提升模型性能。当M设为无穷大时,模型的多分类准确率为93.91%,二分类准确率为95.99%,此时已达到模型性能瓶颈。所以,合理选取M的值可以在性能和计算及存储代价间达到较好的平衡。
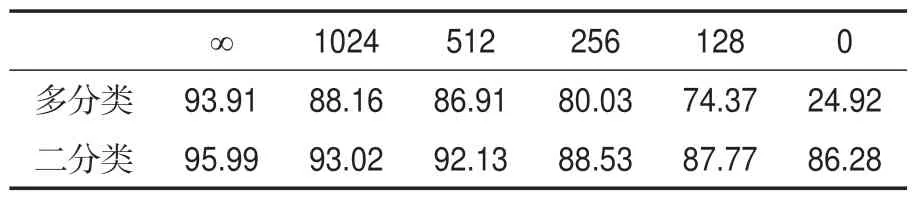
表6 FF++扩充集上不同存储容量下的平均准确率Table 6 Average accuracy under different memory budgets on the FF++expansion set /%
为了评估模型在新旧数据上的性能,在FF++扩充集以及ForgeryNet 扩充集上进行实验。对于FF++扩充集,设置其M为256,每次增量为1 个任务;对于ForgeryNet 扩充集,设置其M为1,024,每次增量为3 个任务,结果如表7 所示。可以发现在每个增量时刻模型对新旧任务都有良好的判别能力,虽然多分类指标呈现下降趋势,但二分类指标逐渐趋于稳定,这说明模型在增长过程中,已经学习到了伪造数据存在的共同“痕迹”,从而将真假样本正确地分开,同时也说明本文提出的利用多分类指导二分类方法的有效性。

表7 FF++扩充集和ForgeryNet扩充集上不同增量时刻下新旧样本的平均准确率Table 7 Average accuracy of new and old samples at different incremental moments on the FF++expansion set and the ForgeryNet expansion set /%
3.4 资源占用
在人脸伪造检测任务中,已有的伪造检测网络在面对新任务时,如果只在新任务上进行训练,则在旧任务上的表现通常会显著下降,这种现象被称为“灾难性遗忘”。本文通过在ForgeryNet扩充集上进行实验,比较了现有人脸伪造检测方法和本文方法的表现。实验设置为每次增加3个任务,共进行5个增量时刻。现有人脸伪造检测方法在每个增量时刻下只在新任务上进行训练,实验结果如图4(b~d)所示,结果表明,现有方法虽然在新任务上具有较好的判别能力,但在旧任务上的判别能力急剧下降;而本文方法在实验中能同时在新旧任务上保持良好的判别能力(其中M为256),实验结果如图4(a)所示。现有方法在新任务上训练时破坏了网络在旧任务上的权重,并且在新任务上训练时旧任务没有参与训练。因此,在实际场景中,通常需要重新训练模型以解决这种灾难性遗忘问题。本文比较了在ForgeryNet 扩充集上使用全部新旧数据重新训练的现有人脸伪造检测方法和本文提出的方法。实验首先将模型在ForgeryNet扩充集的前10个任务上进行了训练,后5个任务视为新任务,然后比较了本文方法和现有人脸伪造检测方法在检测准确率、存储占用和训练时间方面的表现。其中,本文方法使用的存储容量为256,存储占用只考虑训练数据占用的存储空间。实验结果如图5 和表8 所示。实验结果表明,本文方法在ForgeryNet扩充集的大部分任务上的检测结果与现有方法相近。最终,本文方法在平均ACC 方面达到了96.16%,虽然与现有人脸伪造检测方法相比,在检测准确率方面略有下降,但本文方法仅使用了70,256张训练数据和45分钟的训练时间,节省了接近3倍的存储和计算资源。

图4 ForgeryNet扩充集上本文方法与现有方法在不同增量时刻下的平均准确率Fig.4 Average accuracy of our method and the existing method on the ForgeryNet expansion set at different incremental moments

表8 ForgeryNet扩充集上本文方法和现有方法的平均准确率和计算代价Table 8 Average accuracy and computational cost of our method and the existing methods on the ForgeryNet expansion set

图5 ForgeryNet扩充集上本文方法与现有方法的平均准确率Fig.5 Average accuracy of our method and the existing methods on the ForgeryNet expansion set
3.5 适应性
在现实场景中,对于未公开的伪造方法,往往难以获取充足的训练数据,从而造成对这些伪造类型的检测困难。为评估本文方法在新伪造类型上的适应性,进行了针对训练数据匮乏的新伪造类型的比较实验,并与现有的人脸伪造检测方法进行对比。实验采用ForgeryNet 扩充集进行,其中前10个任务已完成训练,后5个任务被视为新任务,每个任务下每个类别仅包含100张训练数据。实验结果如表9所示,本文方法(M为256)在数据匮乏的新任务上的平均检测准确率优于现有方法,说明本文方法在新任务上具有更强的适应性。

表9 ForgeryNet扩充集后5个任务上本文方法和现有方法的检测准确率Table 9 The detection accuracy of our method and the existing methods on the last 5 tasks of the ForgeryNet expansion set /%
4 总 结
深度伪造检测是近年一个研究热点。现有工作大多利用伪造图像存在的某种特定“指纹”来进行图片或者视频的伪造检测。由于Deep-Fake 技术仍在不断进步,其合成的数据通常有较大的差异,因此,难以在一次训练中充分学习普遍有效的判别特征。针对这个问题,本文将增量学习引入到了伪造检测网络中,通过增量学习来强化和更新伪造检测网络,以保持对新出现的DeepFake合成技术的检测能力。本文采用可动态扩展的增量学习框架,并提出3种分类学习系统以适应伪造检测任务。实验结果表明,本文提出的人脸伪造检测方法通过增量学习的方式提高了模型对检测不断出现的伪造样本的有效性。此外,本文方法使用部分训练数据达到与使用全部数据训练的检测网络相当的检测准确率,在保证检测能力的前提下减少了大量计算代价。同时,在训练数据有限的情况下,本文方法在检测准确率上超过了现有方法。
在本文的方法中,当面对新出现的Deep-Fake 技术合成的伪造样本时,为了保持正负样本的平衡,需要加入相应的真实样本来结合训练,这无疑引入了不必要的训练数据,增加了训练负担。在未来的研究工作中,可以针对正负样本的平衡进行更多的考虑和设计。
利益冲突说明
所有作者声明不存在利益关系。
猜你喜欢
当代陕西(2022年6期)2022-04-19
少儿美术·书法版(2021年9期)2021-10-20
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·中考版(2019年9期)2019-11-25
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
动漫星空(2018年9期)2018-10-26
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
电信科学(2016年9期)2016-06-15
电子设计工程(2015年16期)2015-02-27
