
一类Stencil应用在众核NUMA架构的性能研究
2023-12-24 10:34高凌云勾文进刘夏真袁武张鉴陆忠华
数据与计算发展前沿 2023年6期
高凌云,勾文进,刘夏真,袁武*,张鉴,陆忠华
1.中国科学院计算机网络信息中心,北京 100083
2.中国科学院大学,北京 100049
3.华为技术有限公司,浙江 杭州 310053
引 言
模板计算(Stencil)被广泛应用于一类基于网格的科学计算中,例如计算流体力学、有限元分析、相场模拟等。模板计算中,每一个网格点的数据更新都会依赖其邻接网格,多维网格计算时将存在严重的访存不连续问题,导致较低的计算访存比,从而影响算法执行效率。因此,对模板计算的访存性能优化受到了科研人员的重视[1-3]。
高性能计算技术正处于由容量(capacity)计算向能力(capability)计算发展的阶段,有两方面特征:一是大规模并行计算,并行规模向数万核乃至全机不断扩展;二是异构计算,基于“CPU+加速器”的模式被当前主流超算平台所采用。一个新的趋势是,基于精简指令集的ARM 架构以其显著的低成本、高能效等优势受到了业内关注,例如富士通公司的A64FX[4]、“天河三号”采用的飞腾处理器[5],华为公司也于2019 年1 月发布了基于ARMv8-A架构的“鲲鹏920”处理器。
传统的SMP(对称多处理,Symmetrical Multi-Processing)架构由于总线的争用机制限制了计算核心数量和访存性能,NUMA(Non-Unified Memory Access,非统一内存访问)架构在一定程度上解决了SMP 架构的扩展性问题,每一个NUMA节点都有独立的内存控制器和缓存系统,多核计算时能较大提升访存效率、发挥机器性能,在ARM架构中被普遍采用。
本文基于鲲鹏平台,针对benchmark 程序以及典型模板应用软件开展了性能测试,并结合硬件架构和算法特点开展了性能分析。
1 鲲鹏920处理器
鲲鹏920处理器是基于ARMv8-A架构的服务器级芯片,采用了7nm的制造工艺和华为自研的Taishan v110微架构。鲲鹏920处理器有着较高的片上集成度,单CPU 可支持32 核、48 核、64核,并集成了IO 芯片,因此也被称为鲲鹏920 处理器片上系统。内存控制器使用的是8 通道DDR4(第4 代双数据率,Double Data Rate 4)的SDRAM(同步动态随机存取存储器,Synchronous Dynamic Random-Access Memory)控制器,内存模式采用NUMA架构,具有高带宽特性[6]。
1.1 组织结构
以鲲鹏920-6426芯片为例,包括了两个超级内核集群(Super Core Cluster,SCCL),一个超级I/O集群(Super I/O Cluster,SICL)。SCCL由8个内核集群(Core Cluster,CCL)组成,CCL 又包括4 个完整实现了ARMv8-A 架构的TaiShanV110处理器内核,组织架构如图1所示。

图1 鲲鹏920片上系统结构示意图[6]Fig.1 Kunpeng 920 SoC structure diagram
1.2 内存储系统
鲲鹏920 处理器的内核拥有私有的L1 Cache 与L2 Cache。L1 Cache 分为指令Cache(L1 I Cache)与数据Cache(L1 D Cache)两部分,均为64KB;L2 Cache 为512KB。L3 Cache 被处理器所有核心共享,大小为64MB,采用组相连结构,Cache line为128B。
1.3 NUMA架构
SMP 是最为常见的多CPU 系统,各处理器共享资源,处理器之间没有主从关系,对总线和内存的使用由操作系统统一调度,由于多CPU对内存的访问是同等的,所以也被称为UMA(Uniform Memory Access,统一内存访问)系统。SMP 的缺点在于其扩展性受制于总线、内存、IO 等资源,对于访存密集型算法,CPU 利用率较低。
为了克服SMP 因资源高度共享导致扩展性差的问题,NUMA 架构采用了层次化缓存系统、分层共享和持有资源的设计思想。拥有独立内存资源和I/O 资源的一组CPU 或者计算核心被称为NUMA 节点(Node),节点内一般由片上网络(on-chip network)互连,节点间由不同种类的通道进行互连。由于互连速度存在差异,CPU访问本地资源(Local)要远快于访问远程(Remote)资源。
鲲鹏920处理器支持NUMA架构,如图2所示。片上系统中,每个SCCL 都拥有独立的内存、I/O芯片,即成为一个NUMA节点。以2个鲲鹏处理器组成的计算节点为例,计算节点中共有4个SCCL,也就是有4个NUMA节点,鲲鹏处理器内核也可以访问其他SCCL 的内存和L3 Cache。芯片内部使用片上网络进行互连,芯片之间使用Hydra Interface相连。

图2 鲲鹏920片上系统NUMA结构示意图Fig.2 Schematic diagram of NUMA structure of Kunpeng 920 SoC
通过numactl工具可以查看当前系统中NUMA节点的数量,以及每一个NUMA节点核心数量与编号,并且会显示一个距离矩阵。
2 Benchmark测试
2.1 测试平台
本文使用华为公司的鲲鹏计算节点,配置有两颗鲲鹏920 处理器(以下称鲲鹏平台)。对比测试平台是中国科学院“元”级超算的计算节点与某搭载国产CPU的计算平台。其中“元”是基于x86 架构的计算平台。目前,该平台共部署CPU共计5,400核,共有270台刀片服务器,“元”平台中每台刀片服务器配置有两颗Intel E5-2680V2 处理器,每个处理器包括10 个计算核心(以下称Intel 平台);另外,本文选用“东方”先进计算平台,搭载了国产CPU,其中每个CPU包括32个计算核心(以下称国产平台),3个平台具体信息如表1所示。

表1 Intel Xeon E5-2680v2、鲲鹏920处理器与国产处理器参数列表Table 1 Intel Xeon E5-2680v2,Kunpeng 920 and domestic processor parameter list
2.2 基准测试程序
本节主要使用基准程序测试硬件的访存、点对点通信和聚合通信时延。STREAM[7]是一个测算内存带宽实际性能的基准程序,执行简单的数组运算,包括Copy、Scale、Add、Triad 4 种操作,数组大小是缓存的4 倍或者100 万个元素,以较大者为准。
OSU[8]是由Ohio State University开发的MPI通信效率测试微基准程序,可以测试不同通信模式下的MPI延迟。本文使用OSU测试了两个计算平台不同数据包和不同“距离”的点对点时延。
Perf[9]是Linux 系统内核自带的性能分析工具,其原理是对在Linux中产生的事件进行计数,CPU中有单独的硬件寄存器作为性能计数器。
2.3 访存带宽测试
使用STREAM 的Triad 操作,测试单节点访存带宽性能,结果如图3 所示。3 个平台在中等规模大小的数组进行实验时,性能远大于大规模数组,其访存实际上是对L3 Cache 的访问,数组规模没有超过其大小,故并不是对DRAM 的访问;鲲鹏平台在数据包大于128M时趋于稳定,带宽为277GB/s;Intel平台对应的数据分别是32M、53GB/s;国产平台对应的数据分别是64M、90GB/s。数据包从128M直至7.2G期间,鲲鹏平台的测试性能均优于Intel平台与国产平台;带宽稳定值是Intel 平台的约6 倍,是国产平台的约3.5倍。

图3 访存带宽对比测试Fig.3 Comparison test of access bandwidth
NUMA 架构很大程度上缓解了片上多核中存在的访存争用问题,鲲鹏920处理器是一个具有8 通道的高访存带宽处理器,在每个socket 有64 个计算核心的情况下仍能保持一个高访存带宽。
2.4 通信时延测试
使用OSU对鲲鹏平台和Intel平台分别测试了socket 内与跨socket 的点对点通信,结果如图4、图5所示。针对国产平台进行了NUMA节点内与跨NUMA 节点的点对点通信测试,结果如图6 所示。从实验结果看,数据包小于256KB时,鲲鹏平台的socket 内通信速度较快;数据包大于256KB 时,鲲鹏平台的socket 内与跨socket通信时延接近,且均好于Intel平台。国产处理器在数据包小于8KB时,NUMA节点内通信较快,在数据包大于8KB 后,NUMA 节点内和节点间的通信时延几乎没有差异。

图4 鲲鹏平台OSU点对点通信测试结果Fig.4 OSU point-to-point test results of Kunpeng920

图5 Intel平台OSU点对点通信测试结果Fig.5 OSU point-to-point test results of Intel

图6 国产平台OSU点对点通信测试结果Fig.6 OSU point-to-point test results of domestic CPU
针对聚合通信,分别选取了数据包大小为8B、1KB、1MB,测试了MPI_Allreduce 的通信时延,结果如图7 所示。从实验结果看,鲲鹏平台在大数据包和大核数时给更有优势。大核数时,Intel 平台跨越更多节点,聚合通信时延增长较快。鲲鹏920处理器支持了片上访存替代通信,进而实现了优化的聚合通信。
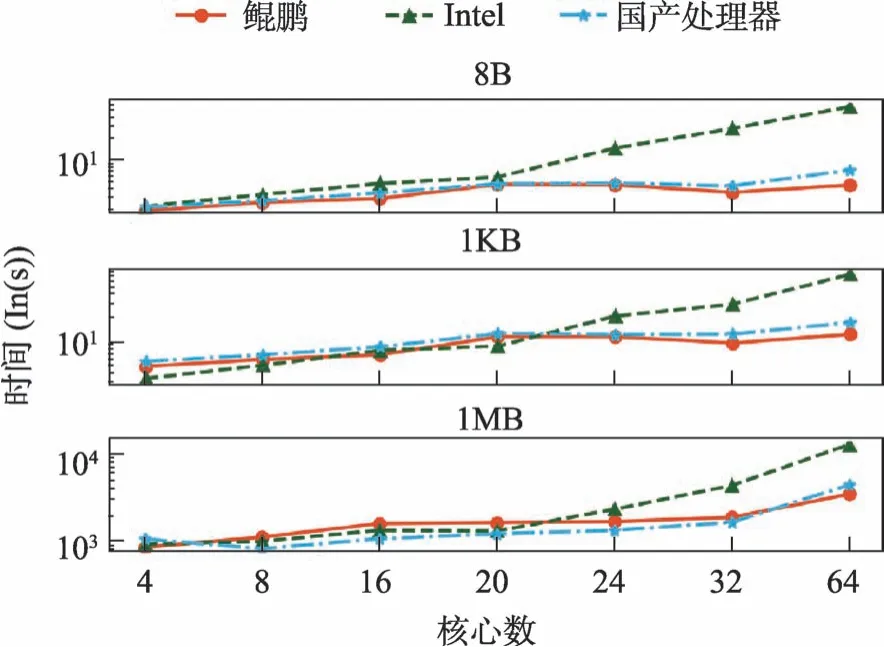
图7 AllReduce时延测试结果Fig.7 All_Reduce latency test results
3 高性能软件CCFD V3.0
CCFD V3.0 是课题组自主研发的高性能流体力学计算软件,开发语言为Fortran 90,使用MPI 1.0标准实现并行计算。该软件集成了国际上主流的高精度数值方法和先进湍流模拟技术,在异构并行计算方面开展了大量优化工作[10-11]。
3.1 CCFD V3.0核心算法分析
CCFD V3.0的计算热点主要是PDE(偏微分方程,Partial Differential Equation)方程离散和线性方程求解两部分。基于网格的PDE 方程离散天然具备模板计算算法特性,包括了对流项离散和粘性项离散,前者所使用的迎风格式需要对3个方向分别扫描,方程离散是一维偏置模板,后者一般使用中心格式,是一维对称模板。在线性方程求解中,CCFD V3.0包括了基于近似因子分解的LU-ADI、LU-SGS 等算法,具有占用内存小、计算速度快、稳定性好等特点,特别适合结构网格求解,该类算法是“Matrix-free”模式,无需装配系数矩阵,按特定方向依次扫描网格,并使用相邻点计算,因此也属于模板计算类型。
4 基于鲲鹏平台的性能分析
4.1 热点函数分析
对CCFD V3.0热点函数进行分析,使用性能分析工具Perf 对cpu-clock指标采样,结果如图8所示,计算热点是线性代数求解函数LU-SGS,占执行时间的44.68%。该结果符合LU-SGS 作为CCFD V3.0 的核心算法计算量大的特点。本文将会针对该函数进行研究分析。其他时间占比较高的函数为对流通量计算(Flux)、扩散通量项计算(VFlux)、湍流模型计算(Turbulent)、涡量计算(Vorticity)以及插值项计算(Muscl)。

图8 热点函数时间占比Fig.8 Hotspot function time proportion
4.2 应用性能测试
在单节点上分别测试了Hyflex标模[12]和M6标模,网格规模分别为5,150 万和2,020 万,在3个平台上分别进行运行测试,程序编译所使用的编译器为GCC,有关性能提升的编译选项保持一致,单步迭代耗时的对比如图9所示。
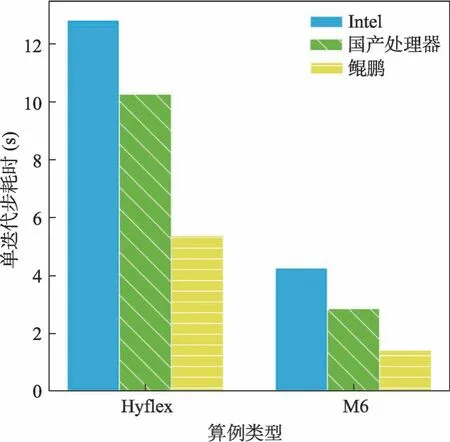
图9 单迭代步时间对比Fig.9 Comparison of the average single iteration time
鲲鹏平台、Intel平台以及国产平台的单节点性能的理论浮点性能分别为1331.2GFLOPS、896GFLOPS、320GFLOPS。其实测稳定访存带宽如图3 所示分别为277GB/s、53GB/s、90GB/s。从图9 中看到,CCFDv3.0 在国产平台上的性能是Intel 平台的约3 倍,国产平台的理论浮点性能、访存带宽分别是Intel 平台的1/3 和1.7 倍;CCFDv3.0在鲲鹏平台上的性能是Intel平台上的2~3倍,但鲲鹏单节点性能只有Intel的1.5倍,而影响性能的另一个主要部分是其访存带宽是Intel平台的5倍。可以看出,访存带宽对以Stencil为主要算法的访存密集型应用的实际性能产生了重要影响。
4.3 LU-SGS的Roofline模型
LU-SGS 方法是基于近似因子分解的GS 类方法,一般采用波阵面扫描的方式[13]进行推进,同一阵面的点没有依赖性。由算法1可知,该算法有典型的stencil特性,存在大量跨步访存且数据重用性低。

算法1 LU-SGS算法示意Alg.1 Schematic diagram of LU-SGS algorithm
拟建立Roofline[14]模型,探寻LU-SGS 方法在鲲鹏平台的优化空间。从相关文档可知,鲲鹏920 处理器理论峰值性能在单Socket 时为665.6 GFLOPS,双Socket 时为1331.2 GFLOPS。根据2.3 节中STREAM 测试结果,单Socket 持续带宽为140.278 GB/s,双Socket 为283.661 GB/s。由Perf 统计代码编译后的指令数量,计算强度约0.11(该结果未考虑缓存),再由PAPI[15]插桩测试浮点性能,最终绘制Roofline 如图10 所示。Roofline 模型将节点的持续峰值带宽、理论浮点性能以及在特定计算强度下的理论上可达到的计算性能结合在一起。

图10 鲲鹏920的Roofline模型Fig.10 Roofline model of Kunpeng 920
Roofline模型划分出了计算受限区域与访存受限区域,Roofline 模型的横轴为算法的计算强度,作为CCFDv3.0 中热点函数的LU-SGS 算法落在了访存受限区域,再从图9中的放大图中可以看出,在不改变算法的情况下,其在鲲鹏920上可达到的计算性能,即纵轴数值接近理论值,因此优化方向应关注访存部分,比如利用内存亲和性以及软件预取等方式。
5 结 语
鲲鹏920处理器依托众核NUMA架构,能够支持更多的计算核心,其单节点浮点性能相比Intel Xeon E5-2680v2 与国产处理器更有优势。内存子系统方面,鲲鹏920 处理器分别是Intel Xeon E5-2680v2与国产处理器的5倍和3倍。点对点通信方面,鲲鹏920 处理器的socket 内通信快于其他两个处理器,跨socket时在大数据包亦有优势。聚合通信方面,鲲鹏920处理器在大数据包和大核数时优于Intel Xeon E5-2680v2 及国产处理器。
相比GPU、申威处理器等异构处理器,鲲鹏920处理器属于通用CPU处理器,更有利于应用的移植和部署。CCFD V3.0 的通用算力版本无需修改就可以直接运行,并取得超出Intel Xeon E5-2680V2处理器2~3倍的运行效率。
致谢
感谢华为计算产品线HPC应用LAB的合作。
利益冲突声明
所有作者声明不存在利益冲突关系。
猜你喜欢
高技术通讯(2021年5期)2021-07-16
汽车观察(2021年11期)2021-04-24
当代陕西(2019年13期)2019-08-20
小哥白尼(军事科学)(2018年12期)2018-12-19
网络安全和信息化(2018年4期)2018-11-09
小哥白尼(军事科学)(2018年5期)2018-06-15
中华诗词(2017年3期)2017-11-27
测绘科学与工程(2014年5期)2014-02-27
深圳信息职业技术学院学报(2013年3期)2013-08-22
电子设计工程(2011年24期)2011-06-09
