
基于特征分析的HPC失败作业的检测和根因分析
2023-12-24 10:34危婷彭亮牛铁张宏海
数据与计算发展前沿 2023年6期
危婷,彭亮,牛铁,张宏海
中国科学院计算机网络信息中心,北京 100083
引 言
超级计算集群是由若干高性能计算节点共同构成的高性能计算(HPC)系统,被广泛应用于航空航天、石油勘探、气象预测、气候研究、仿真模拟、生物工程、工业设计等诸多行业领域。超级计算集群通常使用作业调度软件管理和运行基 于MPI(Message Passing Interface)、OpenMP等框架编写的并行计算作业。随着系统规模和计算量的增加,长时间不间断运行作业变得更具挑战性[1]。除了从硬件制造工艺、容错机制等方面提高系统可靠性,最大限度降低作业运行难度以外,如果可以在作业发生异常时预警甚至预判,并且在作业失败后快速定位根因,区分出是软件代码错误还是硬件瞬时故障所造成的,对减少计算资源浪费以及费用支出,帮助用户有针对性地进行优化,缩短调试时间,对提高计算效率有着十分重要的意义。
为了探索HPC 系统运行状态特征及其在失败作业和成功作业运行中的表现,本文分析了HPC系统的运行状态监测数据。本文定义:作业的应用特征即某种应用的作业运行时所在计算节点的资源监测指标的表现特征。本文结合实际需求,基于自研的计算集群监控系统[2-3],收集了中国科学院某超大型超级计算系统的CPU、Memory、I/O等运行状态监测数据以及计算作业信息;分析了HPC 系统计算作业应用特征与计算作业运行成败的关系;采用Isolation Forest 算法对作业的应用特征进行异常检测,并对作业是否失败进行预测;通过应用特征分析,同时结合日志和其他故障数据构建了HPC 作业失败根因图谱。
1 现有工作
国内HPC集群相关的研究,大多是关于作业的调度策略和方法,以及集群性能优化的研究。对于HPC作业异常(失败)检测的研究较少。
异常检测常用的算法是聚类算法。聚类算法是基于数据特征的分布来做的。聚类后某些聚类簇的数据样本量比其他簇少很多,而且这个簇里的数据特征分布和其他簇差异很大,会认为这些簇里的样本点就是异常点。比如BIRCH算法[4-5]、DBSCAN 算法[6-7]都可以在聚类的同时做异常点的检测。BIRCH 算法分类的结果依赖数据点插入顺序,聚类效果取决于簇直径和簇间距离的计算方法,且对高维数据聚类效果一般。DBSCAN 算法可以对任意形状的稠密数据集进行聚类,可以在聚类的同时发现异常点,但对数据集中的异常点不敏感。王蕾等[8]构建多维作业数据,并设置预设阈值,利用LOF 算法判定多维数据的离散点作为作业异常点。此研究的关键在于对阈值的预设,但是阈值需要根据历史分析自适应变化,这是难点。薛巍等[9]将I/O 阶段的特征数据与历史I/O 阶段特征数据进行聚类,判断I/O阶段的特征数据是否异常。此研究主要关注I/O 阶段的特征,对于异常作业检测来说并不全面。Wucherl 等[10]基于job log,通过logs 中的failed code 来标记作业的成功和失败,以此进行有监督的机器学习的分类研究,并对作业失败进行预测。此研究基于job log 的分析,log 包含的信息量比较全面,因此涉及大量日志的分析处理,工作量比较大。事实上,在对作业失败状态进行预测的时候,很难对输出的应用特征做标记,通常面对的很多都是无监督的异常数据筛选。Rakesh 等[11]基于作业失败和资源使用之间的关联关系,提出预测作业失败的模型,以触发事件驱动的检查点和避免浪费资源。另外,还基于用户历史的资源使用情况提出预测当前作业运行时间的模型,可以用来优化现有调度器的调度策略,提高调度效率。此研究强调资源争抢对资源利用效率和作业运行造成的影响。
本文的研究基于超大型超级计算系统的运行数据。集群上的作业以独占的方式运行在一个或者多个节点上,也就是说,同一个节点同一时间只执行一个作业。因此,作业运行时节点的运行状态,如资源的利用情况等,反映了作业的应用特征,能够作用并影响作业的运行,也能完全反映作业的运行状况。本文基于计算节点的CPU、Memory、I/O等监控指标的分析,提出采用无监督的Isolation Forest机器学习的算法实时监测作业的异常状态,并对作业失败进行预测。数值分析结果表明本文的方法对于预测短期作业和长期作业失败都具有较高的准确性。
2 预测模型
2.1 数据介绍
本文通过自研的监控系统采集了中国科学院某超大型超级计算系统的运行数据,包括:(1)作业信息。该超算系统使用Slurm 调度计算作业,因此,作业信息包括了用户名、作业名、提交时间、开始时间、结束时间、退出状态、作业运行节点名等。其中退出状态字段包含了作业脚本的退出码、exit()调用的返回码以及接收到的Linux信号[12]。该字段可被用于分析计算作业失败的具体原因。(2)作业所在节点的监测数据包括CPU、内存、Infiniband(简称IB)网络传输等。由于采集到的监测数据可以反映出计算作业在运行过程中对硬件资源的消耗情况,并且不同类型的计算作业展示出不同的消耗特征,因此将计算作业运行过程中所在计算节点的资源监测数据定义为应用特征数据。表1 展示了部分应用特征数据。为了避免对系统造成过多的负担,应用特征数据的采集时间间隔为30秒。

表1 应用特征参数介绍Table 1 Application feature parameters
截至2022年3月底,该超级计算集群完成的作业数大约在500 万左右,时间跨度从2019 年6月至2022 年3 月底。其中约82%的作业是完成(done)状态,12%的作业是失败(fail)状态,其他状态还包括内存溢出(out of Memory),大约占0.11%,超时(time out)占1.5%,被取消(cancelled)占4.7%。本文选取了退出状态字段较全面,即涵盖了done、fail、out of Memory、time out等退出状态的VASP应用作为分析对象。
VASP 是一个进行从源头模拟量子力学-分子动力学计算的模拟软件包。它是高性能计算集群用户常用的应用之一。VASP 应用计算量大、通信频繁,对计算集群的需求是高速网(需要通信、大量读写),但是其对内存要求比较低[13]。
2.2 数据分析
本文采集了VASP 应用的CPU、磁盘读写、内存使用、IB网络等数十项应用特征数据。通过对若干运行时长在0.5~40 小时的失败作业的应用特征数据分析,发现失败作业的内存使用量(Memory used)、I/O 等待占比(iowait)与成功作业存在差异。
如图1(a)所示,job1、job2 是失败作业,job3、job4是成功作业。可见失败作业的I/O等待占比表现出相当数量占比值较高的异常点,而成功作业的I/O 等待占比分布比较均匀。图1(b)显示,失败作业的内存使用量接近作业运行节点的内存总量(128GB),而成功作业的内存使用量在作业运行节点内存总量范围内。图1(c)显示,失败作业和成功作业其CPU 利用率相似,都是接近100%。
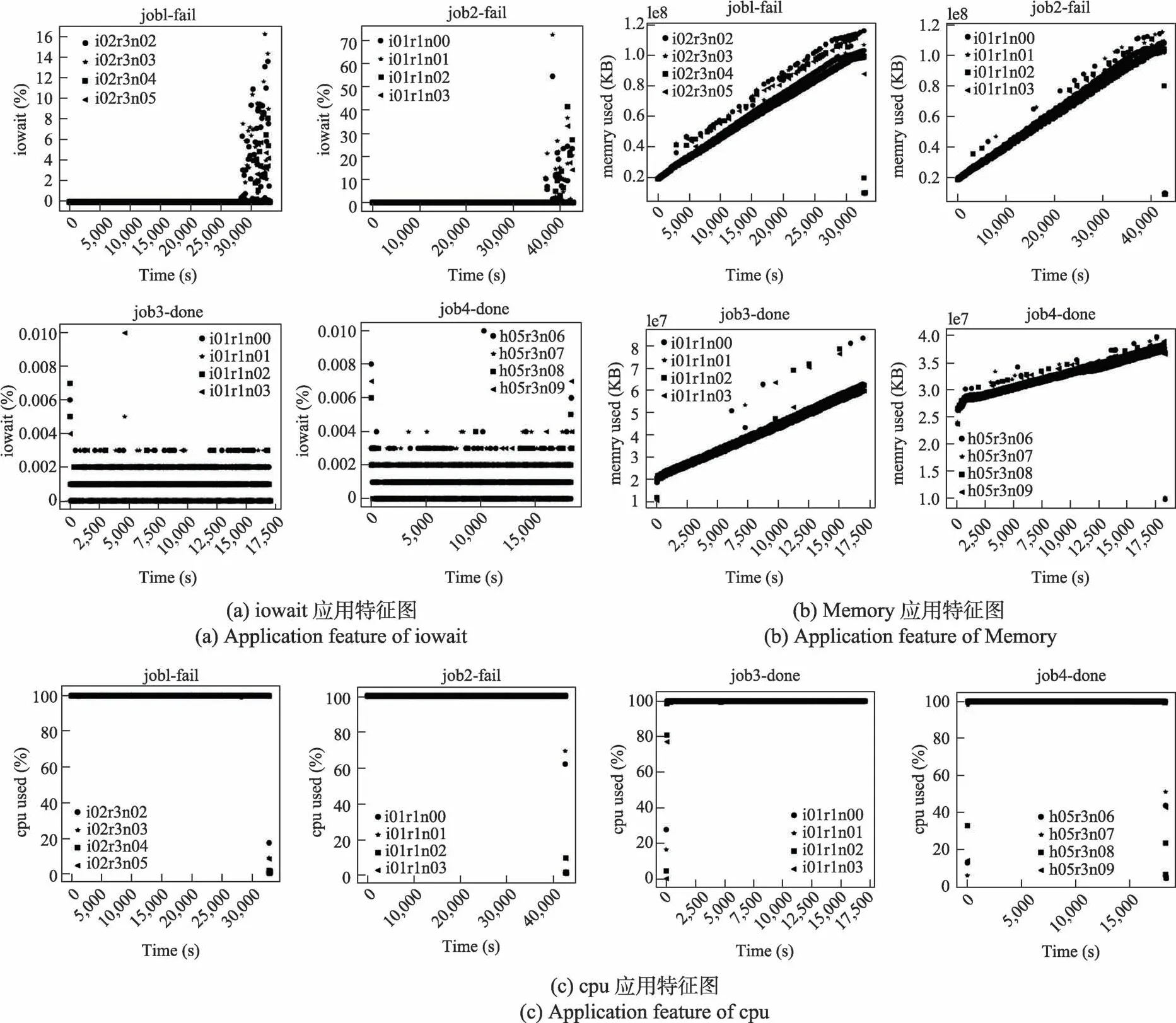
图1 应用特征分析图Fig.1 Analysis of application features
从图1 中可以看出,内存和I/O 资源是导致作业失败的直接原因。本文观测的高性能计算集群采用节点独占的形式调度和运行计算作业,作业之间不存在CPU、内存等节点内资源的抢占,但在同一节点上运行的多个计算作业进程将节点内可用内存消耗殆尽,以及与其他作业在对全局共享存储资源I/O 争抢,都可能导致计算作业因资源不足而异常退出。造成这个现象的原因很大可能是由于作业应用程序的不合理。
2.3 Isolation Forest模型
Isolation Forest将异常定义为容易被孤立的离群点,可以理解为分布稀疏且离密度高的群体较远的点。Isolation Forest不用定义数学模型也不需要有标记的训练。它使用了一套非常高效的策略。用一个随机超平面来切割数据空间,切一次可以生成两个子空间。之后再继续用一个随机超平面来切割每个子空间,循环下去,直到每个子空间里面只有一个数据点为止。直观上来讲,那些密度很高的簇是被切分很多次才会停止切割,但是那些密度很低的点很容易较早就停到一个子空间。
构造Isolation Forest的步骤如下:
(1)从训练数据中随机选择n个点样本作为subsample,放入树的根节点;
(2)随机指定一个维度,在当前节点数据中随机产生一个切割点p,切割点产生于当前节点数据中指定维度的最大值和最小值之间;
(3)以此切割点生成了一个超平面,将当前节点数据空间划分为2个子空间:把指定维度里小于p的数据放在当前节点的左孩子,把大于等于p的数据放在当前节点的右孩子;
(4)在孩子节点中递归步骤2和3,不断构造新的孩子节点,直到孩子节点中只有一个数据,无法再继续切割,或者孩子节点已达限定高度。如算法1所示。

算法1 Isolation Forest生成算法Algorithm 1 Isolation Forest generating algorithm
Isolation Forest 构造好之后,可以基于测试数据进行预测。PathLength记录x在每棵树的高度均值,计算方法如算法2所示。

算法2 Isolation Forest预测算法Algorithm 2 Isolation Forest prediction algorithm
2.4 作业失败预测
基于图1 的分析结果,本文选取Memory used、iowait 等待占比,另外加上CPU used 作为辅助项构成三维的应用特征向量,对失败作业的预测问题即变成对应用特征异常点的检测问题。
异常点检测就是要找到数据集中与大多数数据不同的数据。本文选择无监督的Isolation Forest算法。因为有监督学习算法适用于有大量的正向样本,也有大量的负向样本的情况,这样才能有足够样本让算法学习其特征。Isolation Forest 是无监督的算法,非常适用于很难进行标记的特征数据的筛选,比如本文中的iowait应用特征数据,只有占比少量的离散点;再者,Isolation Forest 算法具有线性时间复杂度,它不需要计算有关距离、密度的指标,可大幅度提升速度,减小系统开销。
本文选取若干运行时长为24~40 小时(长时)、12~16小时(中时)以及2~6小时(短时)的失败的VASP 作业,对其应用特征数据进行训练学习。本文想通过对各类时长作业的训练来观察算法对长时作业和短时作业的预测效果,因此将时长为12~16 小时的作业数据集全部作为训练集,其他的长时作业和短时作业数据集选择7:3的分配比例来分配训练集和测试集[14]。令数据集表示为D,训练集表示为S,测试集表示为T。根据文献[14],训练集S 和测试集T 的比例没有完美的解决方案。如果训练集S 包含绝大多数样本,虽然训练出的模型可能更接近整个数据集D 训练出的模型,但由于测试集T 太小,评估结果可能不够稳定准确;如果测试集T包含太多样本,则训练集S与整个数据集D差别更大,S训练出的模型与D 训练出的模型相比可能有较大差别,这样就降低了评估结果的保真性。因此,常见做法是将大约2/3~4/5 的样本用于训练,剩余样本用于测试。因此本文居中选取了7:3 的比例,如图2所示。

图2 训练集和测试集Fig.2 Training set and test set
对数据集使用如下的技术路线,如图3所示。
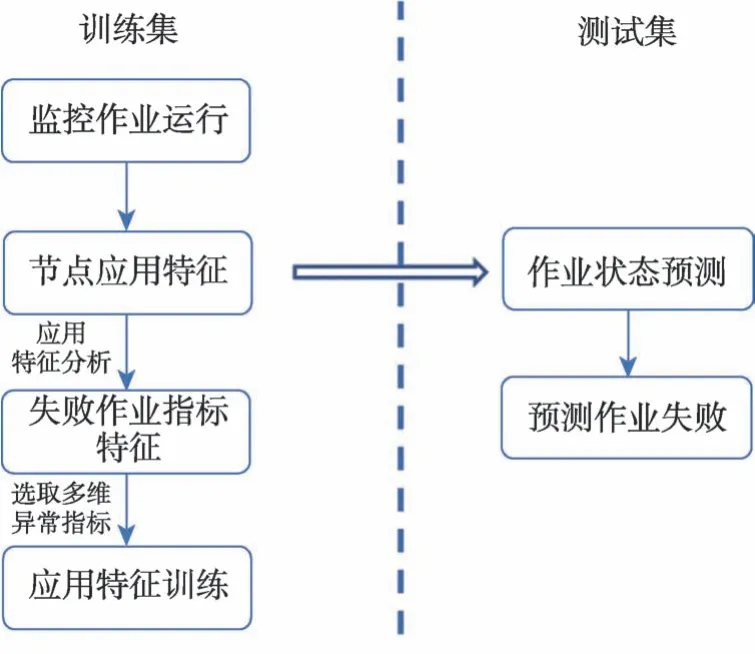
图3 作业失败预测的路线图Fig.3 Roadmap of job failure prediction
首先对作业样本进行清洗,并对样本进行标准化和归一化处理。基于对作业应用特征的分析,以及失败作业应用特征的特点,选用相关的应用特征作为异常指标,并使用Isolation Forest算法对数据集进行训练,对作业时长约为2~6小时的短时作业、作业时长超过30 小时的长时作业进行测试,如图4 所示。从图中可以看出,不论是短时作业还是长时作业,Isolation Forest 能够很好地将异常点检出。

图4 Isolation Forest检测应用特征异常点Fig.4 Anomaly detection of application features using Isolation Forest
本文探讨的应用特征异常检测问题,属于无监督的机器学习问题。对无监督的学习算法的评估,通常有两种:一种是基于数据本身的特点,结合具体的无监督学习种类,建立一些对于绝大部分算法来说都应该遵守的标准。因为不同种类的无监督算法的最终目标不一样。如聚类算法是为了找到数据里面的“自然的组结构”,而异常检测则只要找到极少数的异常点,对数据里面的组不感兴趣;第二种是人工制造标签。但人工标签只用来评估算法好坏,而不用来训练模型。而在有监督的学习里面,标签既用来训练模型,也用来评估算法好坏。
本文选择采用第二种方法,即人工制造标签来评估本文的isolation forest 算法。本文在测试集中给远离均值的应用特征数据打上异常标签。同时计算图4中测试集对应的混淆矩阵、详细得分以及ROC曲线,如表2和图5所示。

表2 Isolation Forest算法评估数据Table 2 Isolation Forest algorithm estimate parameters
图6中基于生产系统的真实监控数据,总结出以图谱的方式描述各信息间的因果联系。其中箭头方向代表根因的推理方向。基于图6,可以在有限的知识经验基础上总结出作业失败是由于节点本身故障导致的,还是用户作业程序导致的。由于图6 是基于现有的HPC 集群生产系统在一定时间内的数据,随着系统运行时间增加,相关信息收集如现象类别、根因信息可以详尽地继续补充进来。图6 可以帮助管理员更加快捷精准地定位问题,从而更加快速地解决问题,同时也能为解决用户质疑提供依据。

图5 Isolation Forest 算法ROC曲线Fig.5 Isolation Forest algorithm ROC curve
由图5 中ROC 曲线可以看出,4 个测试集的AUC 值接近1,算法的预测精度较高,分类效果比较好。
3 作业失败根因的探讨
基于对应用特征和预测作业失败的方法研究,本文对作业失败根因进行探讨。作业失败可能是由于应用程序的问题,如应用程序bug,也可能是作业程序的问题,导致分配资源不足,内存溢出等,还有可能是计算节点本身的问题,如操作系统或者文件系统错误、集群调度系统错误,或者节点的硬件故障等。本文通过对失败作业应用特征的分析,结合系统日志的分析,以及硬件故障和告警信息的分析,将相关收集的信息与根因定位形成图谱,如图6所示。
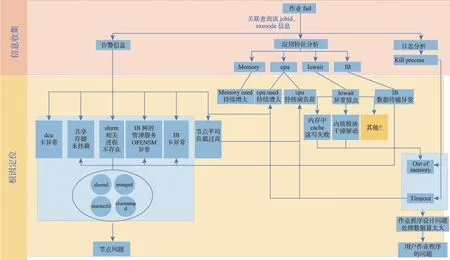
图6 作业失败根因图谱探讨Fig.6 Discussion of attribution graph on job failure
4 结 论
本文基于大规模HPC 集群生产系统的监控数据研究了HPC 集群系统作业应用特征与作业运行成败的关系。HPC作业失败,很大程度上是由于应用作业程序编写不当,造成作业运行过程中多个进程将节点内可用内存消耗殆尽,以及与其他作业在对全局共享存储资源的I/O 争抢,导致作业的进程被杀掉,作业失败退出,其表现在作业应用特征上,就是相关指标值出现异常高点。本文采用Isolation Forest算法对作业的应用特征进行异常检测,并对作业失败进行预测。通过数值分析发现,Isolation Forest 能够准确地检测出应用特征的异常点。
本文特别地将作业按照时长划分为长时、中时、短时3个范围的作业,并通过对3个范围的作业数据集的训练来预测长时、短时作业的失败,以观察算法的效果。本文对训练集和测试集的分配占比按照通常的7:3 分配,在后续工作中将进一步讨论和分析不同样本集的占比分配对作业失败预测的影响。
本文的研究对用户执行作业的安排以及系统调度程序的策略制定具有很好的参考意义。基于应用特征关联分析构造的根因图谱,可较好地融汇作业运行和资源使用情况的所有影响因子,并展现所有因子的因果关系。本文的研究能够帮助管理员定位作业失败的原因,为优化系统提供依据,同时能帮助用户消除对作业失败根因的质疑,为解决用户资源计费的纠纷提供依据,也为未来进一步工程化实现奠定基础。
本文的研究基于典型的VASP 应用,但对于其他不同的应用类型,其作业应用特征分析结果可能有所不同,因此选择的应用特征以及检测算法也可能不同。此外,随着系统运行,根因图谱将不断完善,对于应用特征关联关系推导以及作业失败根因的推导将基于更加智能的算法,这些都将是下一步的工作。
利益冲突声明
所有作者声明不存在利益冲突关系。
猜你喜欢
中国药学药品知识仓库(2022年9期)2022-05-23
高技术通讯(2021年5期)2021-07-16
军事运筹与系统工程(2019年4期)2019-09-11
当代陕西(2019年13期)2019-08-20
电子制作(2018年11期)2018-08-04
电子技术与软件工程(2017年18期)2018-01-28
中国卫生产业(2017年16期)2017-07-20
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
西南军医(2016年5期)2016-01-23
