
基于局部放电相位图谱和油中溶解气体信息融合的油纸绝缘缺陷识别方法
2024-01-04 01:20周远翔李永印陈健宁
绝缘材料 2023年12期
周远翔, 李永印, 陈健宁, 白 正
(1.新疆大学 电气工程学院 电力系统及大型发电设备安全控制和仿真国家重点实验室风光储分室,新疆 乌鲁木齐 830047;2.清华大学 电机工程与应用电子技术系电力系统及发电设备控制和仿真国家重点实验室,北京 100084)
0 引 言
随着深远海风电的持续开发,海上换流站面临气候恶劣、巡检不便的问题,对变压器等电力设备的安全可靠运行提出了新的挑战。沿面放电因其发展速度快、绝缘损伤大,被认为是造成高压设备损坏的重要原因之一[1]。不同类型的沿面缺陷劣化机理不同,其对应的局部放电特性也不相同,开展变压器局部放电模式识别对其绝缘状态评估及海上风电安全可靠送出具有重要意义[2-3]。
目前国内外学者已对单一信息源的局部放电相位(phase-resolved partial discharge,PRPD)图谱模式识别开展了广泛的研究,主要包括两类方法:一类是支持向量机(support vector machine,SVM)和概率神经网络(probabilistic neural network,PNN)等传统机器学习方法[4],此类模式识别方法需要依赖领域内的专家经验设计、处理、提取、组合某一方面或几方面的统计特征,存在一定的主观性,无法反映局部放电的全部特征,泛化性能较差,因此难以得到令人满意的分类效果[5];另一类是深度学习算法[6-7]和网络迁移学习方法[8-9],该类方法优于传统的参数统计方法,但由于模型的层数较深,训练所需数据量较大,一方面容易出现过拟合,另一方面对数据存储要求高,为边缘侧计算带来了挑战。
近年来,随着人工智能和传感技术的发展,采用信息融合的方法对高压设备绝缘缺陷进行模式识别成为未来电力系统智能化运维的发展趋势。王涤等[10]和黄亮等[11]分别提取了局部放电不同特征信息并输入到神经网络中进行识别,再利用Dempster-Shafer(D-S)证据理论融合不同分类器的分类结果,结果表明融合后的识别准确率高于只提取单类特征分类器的准确率,但其本质上还是对同一信息源的利用;艾嘉伟等[12]、耿伊雯等[13]和王磊等[14]等利用不同传感器进行联合诊断,充分综合了传统特高频(ultra-high frequency,UHF)、光电等测量方法的优势,结果表明多信息融合有利于提高电气设备局部放电模式识别的准确率。以上研究选取的缺陷类型主要有气隙、沿面、悬浮等,而不同类型缺陷的PRPD 图谱特征具有显著差异,通过传统的统计参数提取方法和简单的机器学习方法即可达到较高的分类准确率,但是其对同一类型缺陷的细分程度不足,在实际工程中难以根据测量与分类结果为缺陷尺寸识别、分级评估及故障定位提供有效指导,且需在现有的在线监测系统中部署额外的传感器。而油中溶解气体分析(dissolved gas analysis,DGA)作为油纸绝缘局部放电常用的化学检测法,不受电磁环境噪声的影响,利用电检测法与化学检测法对缺陷进行融合识别的研究鲜有报道。
本文综合局部放电常用的电检测法和化学检测法的优点,引入脉冲电流法和气相色谱法两种方法进行融合判别,提出了基于PRPD 图谱和DGA 数据信息融合的油纸绝缘缺陷识别方法。首先搭建局部放电及油中溶解气体分析试验平台,设计6 种电极模型,模拟变压器中不同电场不均匀系数的沿面局部放电典型缺陷,并采集PRPD 图谱和DGA 数据;然后分别使用卷积神经网络(convolutional neural network,CNN)及反向传播神经网络(back propagation neural network,BPNN)将两类信息源的数据进行分类;最后利用D-S证据理论将识别结果融合,得到最终的缺陷类别,并与PRPD、DGA单一判据模型及视觉几何群网络(Vgg)、残差网络(ResNet)、密集连接卷积网络(DenseNet)等深度卷积融合模型的识别结果进行对比,验证本文所提的信息融合模型的有效性。
1 试 验
1.1 样品制备
试验绝缘油样品选用克拉玛依KI25X 型绝缘油,其处理流程为:将变压器油抽入40℃真空滤油机中进行过滤、干燥和除气,充分去除油中颗粒物、水分等杂质,过滤后的变压器油满足DL/T 1096—2018 中的相关规定,随后将其装入经无水乙醇、去离子水充分洗净的干燥烧杯中,并放入真空干燥箱中干燥48 h 以上,采用SF-5 型微量水分测定仪测量水分,确保油中微水含量符合GB/T 7595—2017 的要求。试验绝缘纸板选用厚度为1 mm 的魏德曼纸板,油浸纸板的制作流程如下:首先将绝缘纸板统一放在温度为105℃、压强为100 Pa 的真空干燥箱中干燥48 h;然后在80℃环境下对绝缘纸板进行真空浸油,充分浸渍后自然冷却至室温;最后再转入真空干燥箱中干燥48 h 以上。在进行正式试验前,对油浸纸板进行理化测试,结果满足IEC 60641.2:2004的各项指标要求。
1.2 试验电极设计
本文设计并制作了6 种电极模型,对变压器中不同电场分布的沿面局部放电缺陷进行模拟,6 种缺陷模型及其电场分布仿真如图1所示。其中缺陷1为IEC 60243.1:2013推荐的柱板电极放电模型,柱电极的高度和直径均为25 mm;缺陷2 为球板电极放电模型,球电极直径为25 mm,其曲率半径等于球的半径,即12.5 mm;缺陷1、2对应变压器绕组之间、绕组对铁心或外壳等稍不均匀电场环境下的沿面爬电,电场不均匀系数分别为2.45、2.20;缺陷3、4是曲率半径分别为4 mm、0.7 mm 的电极模型,对应变压器中的金属尖端缺陷,电场不均匀系数分别为2.42、3.72;缺陷5、6 是曲率半径分别为0.1 mm、0.005 mm 的电极模型,对应变压器绕组塑性形变后产生的锋利金属突出物缺陷,电场不均匀系数分别为9.17、33.2[15-17]。6 种缺陷模型的高压电极与地电极之间为1 mm 厚的方形油浸纸板,在强垂直电场的作用下,既存在油纸界面上平行分量产生的沿面流注放电,又存在沿电极边缘垂直分量引起的油隙放电,6 类缺陷电场最大处均位于高压电极、油浸纸板和油的结合处。
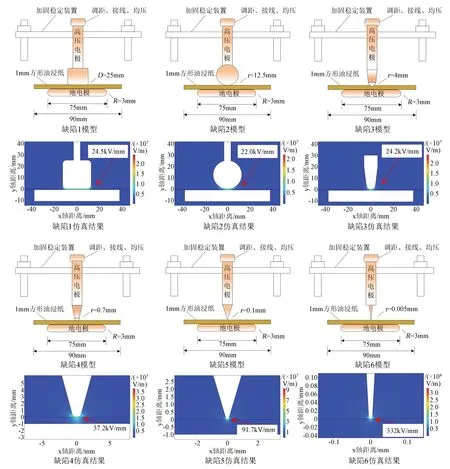
图1 6种缺陷模型及其电场分布Fig.1 Six defect models and their electric field distribution
1.3 试验平台搭建
1.3.1 局部放电试验平台
为获取6 种缺陷下油纸绝缘局部放电的PRPD图谱,搭建试验平台如图2 所示,该试验平台满足IEC 60270:2015 的局部放电测试标准[18]。试验电路包括三部分:电源、试样回路和信号采集。电源主要包括AFG 3011C 型可编程信号发生器和Trek model(50 kV/12 mA)型高压功率放大器,可编程信号发生器负责产生电压波形,高压功率放大器将产生信号按照固定增益1∶5 000 放大后加到样品上。试样回路中待测样品与耦合电容、测量阻抗直接并联,测量阻抗与耦合电容串联将脉冲电流信号转为电压信号。信号采集通过MPD600型局部放电测试仪从测量阻抗中采集局部放电信号,并将其传输至PC 端进行数据分析与处理。数字示波器用来监视高压功率放大器的出口电压。试验回路中所有设备引线端口做平滑处理,并清空周围金属器件。
在每次调整电路或更换缺陷模型后,需要对空载电路进行工频升压测试,保证回路升压至35 kV时无放电发生,且测试系统噪声小于8 pC。在正式试验前,需要进行预试验测量6 类缺陷的局部放电起始电压与击穿电压,最后确定6 类缺陷交流试验电压有效值分别为:缺陷1:19 kV±0.5 kV;缺陷2:20 kV±0.5 kV;缺陷3:18 kV±0.5 kV;缺陷4:17 kV±0.5 kV;缺陷5:16 kV±0.5 kV;缺陷6:15 kV±0.5 kV。
1.3.2 油中溶解气体分析试验平台
为获取6类缺陷下油纸绝缘在局部放电过程中的DGA 数据,使用GC 2002型气相色谱仪对油中溶解气体进行测量,该仪器的灵敏度能充分满足对油中≤1 µL/L 的H2和≤0.1 µL/L 的C2H2等烃类气体的检测需求。每次采集完PRPD 图谱后,将试样静置20 min[19],保证产生的气体充分溶解于变压器油中,取样及脱气方法参照GB/T 7252—2001 的规定,取油样的部位在油盒的中部。
2 数据预处理
2.1 PRPD图谱处理
2.1.1 PRPD图谱样本扩充
油纸绝缘局部放电是一个间歇性的过程,在试验过程中,放电较为剧烈时,10 pC 以上放电量的放电频次可达每秒几万次,而放电较为轻微时,放电仅为每秒几十次。为扩充PRPD 图谱样本,使用滑动窗口法[20]对原始数据进行剪裁,其过程为:假设某次试验共录制放电数据点数为100N,每张PRPD 图谱数据量为N,需要生成n张图谱(n>100)。滑动数据剪裁从第一个放电点开始,每N个放电点为一张图谱,下一张图谱的起点为上一个数据起点加上[99/(n-1)]N个放电点。例如,第一组数据为0~N个放电点,第二组数据为[99/(n-1)]N~[99/(n-1)+1]N个放电点,以此类推。
2.1.2 图谱灰度化
将图谱灰度化一方面是为了降低数据量,另一方面是相比于原始PRPD 图谱,灰度图具有信息集中、特征更为直观的优点。灰度化后的PRPD 图谱更标准、规范,便于卷积神经网络对其进行特征提取。根据2.1.1 得到的数据绘制不同放电次数的PRPD 灰度图。由于放电幅值、试验电压以及放电间歇性等方面的差异,不同缺陷局部放电的数据差距较大。为提高输入图谱的规范性,使模型对不同放电量级的数据均进行有效地识别,绘制同一缺陷不同放电次数的PRPD 图谱时均以统一值作为图谱的纵坐标最大值。
按照文献[21]的方法得到带参考电压波形的6类缺陷的PRPD 灰度图,部分图谱如图3 所示。由图3 可知,图谱具有典型的相位分布,工频相位正、负半周上放电幅值都在工频电压幅值附近。总体上,随着缺陷电场不均匀系数的增大,局部放电的幅值逐渐减小,放电也越集中。其中,柱板电极下放电图谱形状为兔耳型,且其最大放电量要略高于曲率半径为12.5 mm 的缺陷模型。5 种不同曲率半径的缺陷模型图谱大致为三角形,以电压峰值为中心展开分布。电极曲率半径的减小意味着与纸板垂直的纵向电场分量将得到加强,放电更加剧烈,油浸纸板的劣化将更加严重,甚至会导致绝缘纸板碳化并击穿。但是,不同电极结构下局部放电的放电量-相位分布特征相似度较高,图谱均为对称山丘状,在实际工程中难以利用其统计参数对不同电场不均匀系数的缺陷进行准确识别和有效预警。
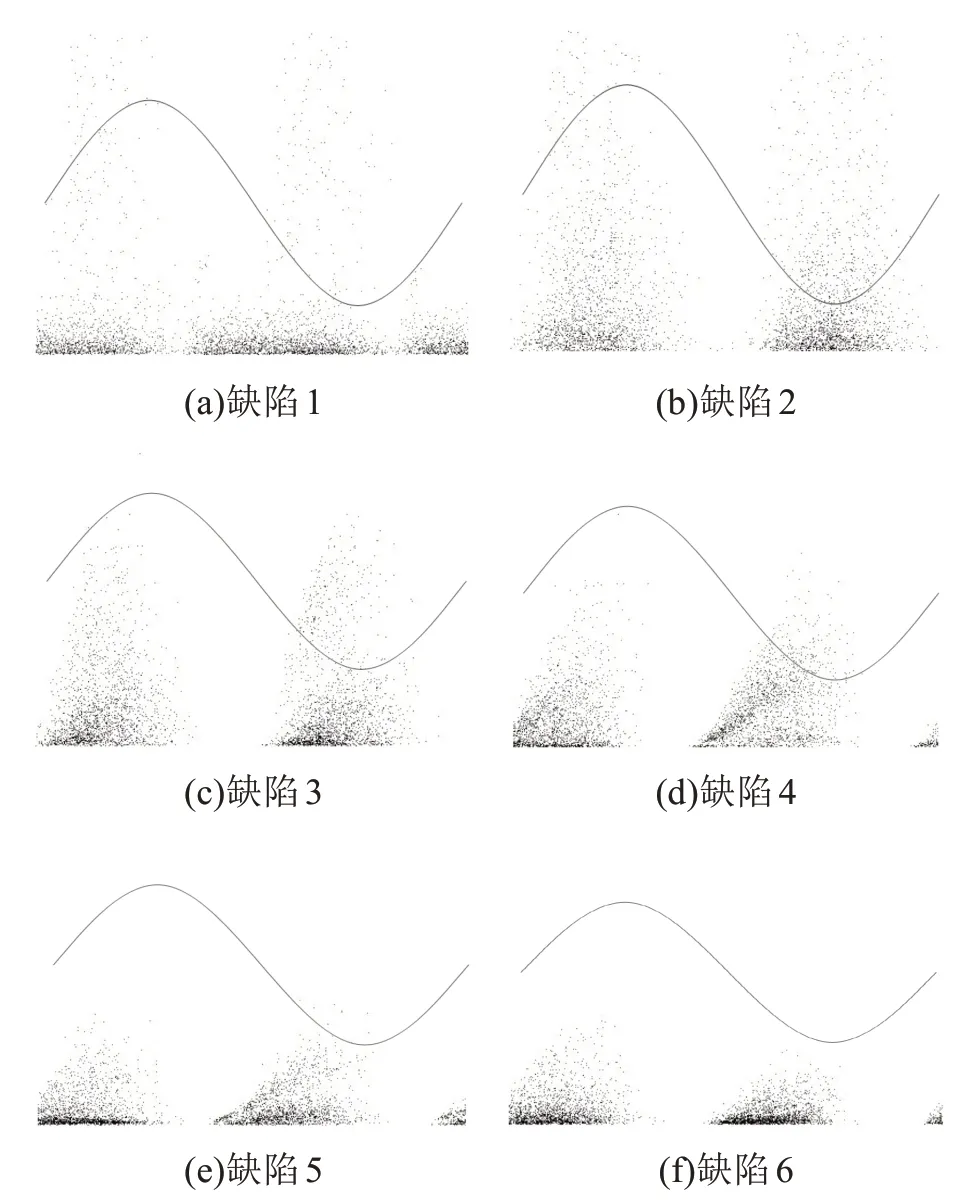
图3 6种缺陷类型的PRPD灰度图Fig.3 PRPD grayscale maps of six defect types
2.1.3 噪声模拟
实际工程中,变压器所处的电磁环境复杂,噪声来源多[22]。变电站常见的噪声包括设备刚启动时的电磁噪声、变压器冷却风机和油泵等运行时引起的机械噪声等。为使图谱数据符合实际工况,进而提高模型的泛化性能,在数据集中间等概率地对PRPD 图谱人工添加相位固定型噪声、区间型噪声和白噪声[23],添加不同噪声后缺陷2的PRPD灰度图如图4所示。
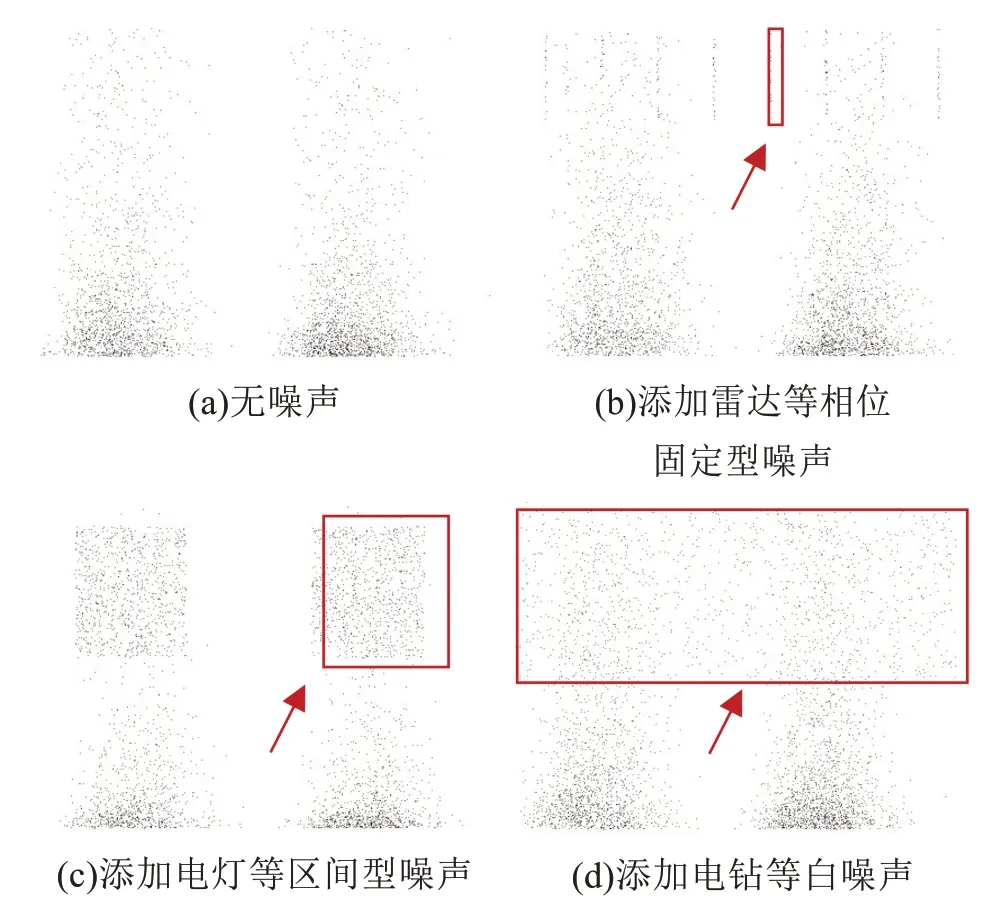
图4 添加不同噪声后缺陷2的PRPD灰度图Fig.4 PRPD grayscale map of defect 2 with different noise
2.2 DGA数据处理
2.2.1 DGA数据分析
变压器油中含有约3 000 种化学成分,这些化合物按照其结构可分为环烷烃、链烷烃和芳香烃3类[24],这些烃类化合物在电、热条件下会发生分解。对于油中溶解气体的分析,国内外学者建立了Doernenberg比值、IEC 比值、Rogers比值等气体比值故障诊断方法[25],这些传统方法使用不同的气体比值作为诊断依据,在实际工程中得到广泛应用,但目前只能区分高能放电、低能放电、过热等故障,对缺陷的类型及故障严重程度无法准确评估。
不同气体比值丰富了缺陷特征的筛选范围,但也增加了特征之间的冗余性[26],所以本文选择5 种差异性较大的气体比值作为样本特征,6 种缺陷放电后其中一次采样的数据如表1 所示,其中总烃(TCH)为CH4、C2H2、C2H4、C2H6含量之和,D 为CH4、C2H2、C2H4含量之和。
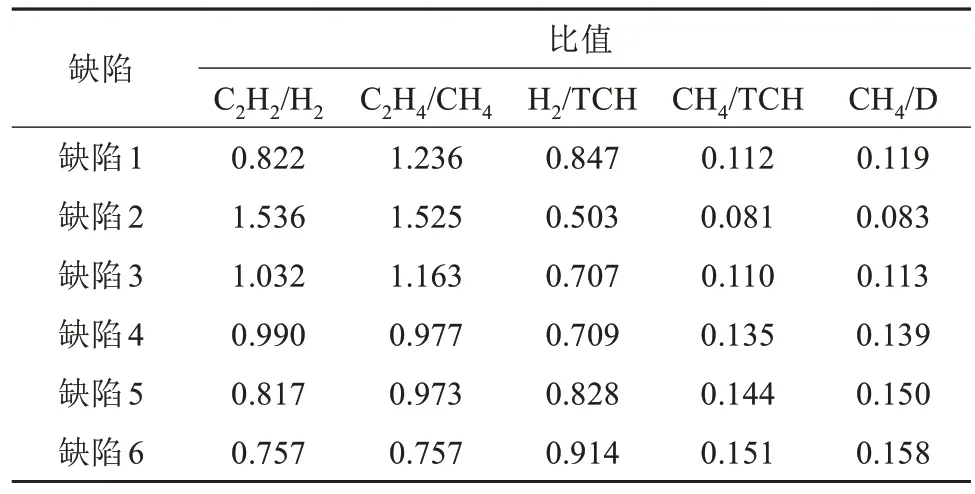
表1 6种缺陷模型的一组气体比值Tab.1 A set of gases ratio of six defect models
由表1 可知,除柱板电极(缺陷1)外,随着缺陷曲率半径的减小,5 种缺陷的气体比值都呈单调变化;曲率半径的减小意味着垂直纸板方向的放电加强,沿油纸界面上的流注放电将减弱,电场畸变更加严重,会加剧C-C 键、C-H 键断裂,促进变压器油分解为H2、CH4、C2H2等小分子,分解速度与分子量成反比,故C2H2/H2、C2H4/CH4的比值逐渐减小,而H2/TCH、CH4/TCH、CH4/D 的比值逐渐增大。柱板电极缺陷的产气特点与5种不同曲率半径的缺陷模型略有差别,特征气体为H2和C2H2。综上,不同电场不均匀系数的缺陷在放电时产气特性具有一定差异,可作为电检测法的补充,提高缺陷模式识别的准确率。
2.2.2 DGA数据样本扩充
为使不同缺陷下测得的DGA 样本量与PRPD图谱相匹配,提高样本的多样性,避免模型过拟合,需要对DGA 数据进行样本扩充。本文采用合成少数类过采样技术(synthetic minority over-sampling technique,SMOTE)[27]将DGA 样 本 量 扩 充 到 与PRPD 图谱一致。合成少数类过采样技术是在邻近的少数类样本之间进行随机线性插值合成新的少数类样本,从而实现不平衡数据集的均衡化。设样本集中少数类样本的集合为X={x1,x2,…,xn},其中xn表示第n个少数类样本的特征向量。具体步骤如下:
(1)对于DGA 数据中的每一个样本xn,以欧氏距离为标准计算它到同一类数据所有样本的距离,得到其k个近邻样本。
(2)随机选取这k个近邻样本中的l个样本(l<k),l的大小由采样比例决定。
(3)对于每一个随机选出的近邻样本xm,分别与原数据按照式(1)中随机线性插值的方法合成新样本。
式(1)中:xnew为新的少数类样本;δ为一个处于0~1之间的随机数。
3 模型搭建
3.1 神经网络搭建
本文采用二维卷积神经网络[28]对PRPD 图谱进行模式识别,其基本结构包括:输入层、卷积层、池化层、全连接层和输出层。卷积层将灰度化后的PRPD 图谱进行特征信息提取并形成新的特征子图,其卷积核本质是一种过滤器,用于获取图片的纹理、边沿等特征。池化层又被称为下采样层,作用是降低输出参数量,用更高层次的特征表示图像。全连接层作为分类器,接收经卷积及池化后提取的特征,通过参数学习将其映射到样本标记空间,最后经Softmax层将输出映射为6类缺陷的概率分布。本文搭建的卷积神经网络结构如图5 所示,其中包含1 个输入层,2 个卷积池化层、3 个全连接层和1个输出层。
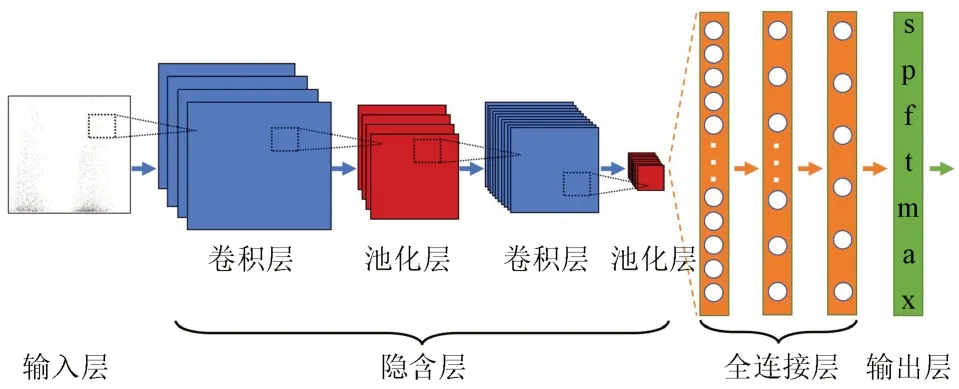
图5 卷积神经网络结构Fig.5 The structure of convolutional neural network
使用反向传播神经网络[29]对DGA 数据进行模式识别,该网络主要由输入层、隐含层、输出层构成,输入层输入的是2.2节得到的5种气体比值构成的特征向量,隐含层用于学习输入特征至输出向量的非线性映射关系,输出层经Softmax 激活函数将输出向量映射成6类缺陷的概率分布。
3.2 D-S证据理论
D-S 证据理论最早应用于专家系统中,是一种处理不确定信息的理论,主要由概率分配函数、置信函数、似然函数等构成[30]。本文利用D-S 证据理论将PRPD 图谱和DGA 数据的识别结果进行融合,结合多种测量手段联合识别的优势,从而实现比单一信息源更为准确的分类效果。具体融合步骤如下:
(1)建立辨识框架
D-S 证据理论中,由多个互斥命题组成的全部集合称为辨识框架。对于本文的模式识别问题,识别框架Ф为6 种缺陷类型,分别用A1、A2、A3、A4、A5、A6表示,如式(2)所示,不确定度为θ。
(2)设置基本概率分配(BPA)
识别框架Ф的幂集构成命题集合Ψ=2Ф={ø(空集),{A1},{A2},…,{A6},{A1∪A2},…,Ф},∀A⊆Ψ,若函数m满足式(3)条件,则m被称为基本概率分配(basic probability assignment,BPA),则m(A)是命题A的基本概率数,即支持A发生的概率。
本文以脉冲电流法和气相色谱法测得的数据经模式识别后的输出值作为2 个独立的证据,将其转换为满足D-S证据理论的BPA。识别框架上不同检测方法的识别结果BPA 计算过程如式(4)~(5)所示。
式(4)~(5)中:mi(Aj)为第i个证据中第j个类别的BPA;µij表示第i个证据输出第j类缺陷的隶属度,在本文中为第i个信息源分类模型经Softmax 输出的概率值;αi为第i个证据源的可靠系数,在本文中为第i个信息源分类模型的识别准确率;mi(θ)表示第i个证据不确定度的BPA的大小。
(3)证据合成
证据合成实际上是多个证据作正交运算,对于PRPD 图谱及DGA 数据的BPA 合成计算方法如式(6)所示。
式(6)中,K为归一化因子。通过式(6)合成PRPD图谱及DGA 数据的BPA,输出结果即为PRPD 图谱和DGA数据信息融合得到的结论。
(4)决策
由步骤(3)计算D-S 证据融合后的所有BPA值,通过以下3个规则判断其缺陷类型:
为其输出BPA 的最大值,即规则I 将最大值的BPA作为输出。
规 则II:m(Amax1)>m(θ),规 则II 说 明 最 大 的BPA值需大于不确定度θ的BPA值。
规则III:m(Amax1)-m(Amax2)>ε,m(Amax2)为融合后BPA 的次大值,ε为阈值,本文取ε=0.4。规则III 说明只有两类识别方法融合后的BPA 差异足够大时才将其输出。
为避免D-S证据组合规则在处理高度冲突或完全冲突的证据时产生与常理相悖的结果,若出现不能同时满足规则I、II、III 的情况时,仍将PRPD 图谱的BPA 作为输出,具体基于信息融合的局部放电模式识别算法流程如图6所示。
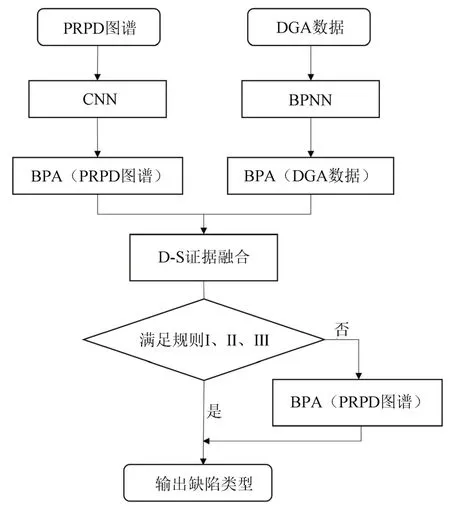
图6 PRPD和DGA信息融合流程图Fig.6 The flow chart for information fusion of PRPD and DGA
3.3 网络训练
由试验获取6类缺陷的PRPD图谱和DGA数据经预处理后,每类缺陷得到2 700 张PRPD 图谱和2 700条DGA数据,其中80%数据用于训练,20%数据用于测试。
在服务器中搭建相应的神经网络进行模型训练和测试。在卷积神经网络训练过程中,使用交叉熵作为损失函数评估训练误差,采用随机梯度下降法对参数进行更新,训练次数为240 次。每次迭代遍历训练集中所有图片,每个训练周期进行60次迭代,共进行4 个周期。初始学习率设置为0.001,每经过一个周期下降50%。在反向传播神经网络训练过程中,中间隐含层的神经元激活函数设置为tanh,学习步长为0.001,迭代次数也为240次。本文采用的深度学习框架为Pytorch,编程语言为Python3.9。
4 结果与讨论
4.1 基于单一信息源的缺陷识别
4.1.1 基于PRPD图谱的缺陷识别
对于PRPD 图谱单一信息源的缺陷识别,为提高模型性能,需要对卷积池化层数、全连接层数和输入维度等参数进行寻优。
首先,分别建立卷积池化层数为1、2、3、4,全连接层数固定为1 的卷积神经网络,研究不同卷积池化层数对卷积神经网络识别准确率的影响,结果如图7 所示。由图7 可知,随着卷积池化层数的增加,模型的识别准确率呈现先上升后下降的趋势;其中,以2 层的卷积神经网络表现最佳。当卷积池化仅有1 层时,网络参数规模较小,难以拟合PRPD 图谱的深层特征;当卷积池化层数高于2层时,模型识别的过程中出现了过拟合现象,识别准确率出现下降的趋势。
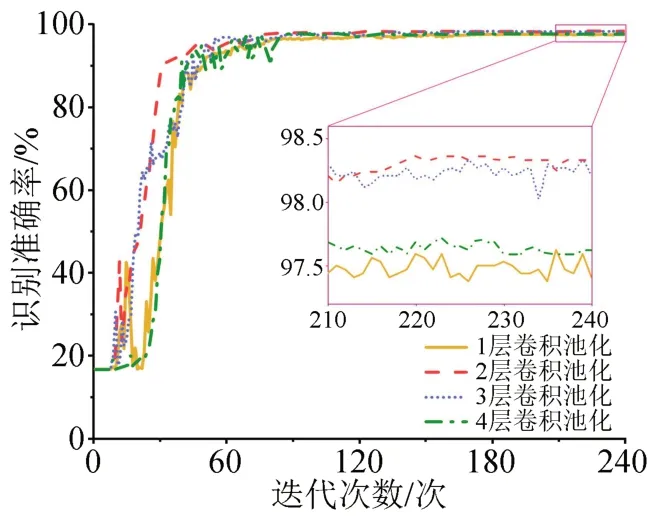
图7 不同卷积池化层数对卷积神经网络识别准确率的影响Fig.7 Effect of different of convolution pooling layers on the recognition accuracy of convolutional neural network
保持2 层卷积池化层不变,建立全连接层数分别为1、2、3、4 的卷积神经网络,研究不同全连接层数对卷积神经网络识别准确率的影响,结果如图8所示。由图8 可知,全连接层为3 时,卷积神经网络的识别准确率最高。随着全连接层数的增加,训练后期的识别准确率趋于稳定。因此,后文统一采用卷积池化层为2 层、全连接层为3 层的卷积神经网络作为PRPD 图谱的分类模型。其中,第1 个卷积层共有4个卷积核,第2个卷积层共有16个卷积核,卷积核大小均为3×3;2 个池化层均采用最大值池化;3个全连接层的单元数分别为96、24、6。
选取输入分辨率分别为8×8、16×16、32×32、64×64 的PRPD 图谱对卷积神经网络进行训练与测试,得到不同输入维度下识别准确率随迭代次数的变化如图9所示。由图9可知,输入维度为32×32、64×64时,PRPD 图谱信息得到较好的保留,识别准确率达到98.2%以上。当输入维度为8×8时,PRPD 图谱在压缩过程中信息损失较大,模型难以对图谱进行准确的特征提取。随着图谱分辨率增加,识别准确率有一定提升,但同时模型训练与测试所需的存储设备和计算资源要求也会成平方级地增加。因此,提高局部放电模式识别准确率、降低PRPD 图谱存储分辨率对提高电力系统的运行可靠性、降低运维成本具有重要意义。

图9 不同输入维度对卷积神经网络识别准确率的影响Fig.9 Effect of different input dimensions on the recognition accuracy of convolutional neural network
4.1.2 基于DGA特征向量的缺陷识别
分别建立隐含层为1、2、3 的反向传播神经网络,研究隐含层数对DGA 数据识别准确率的影响,网络各层神经元数量如表2 所示,识别结果如图10所示。
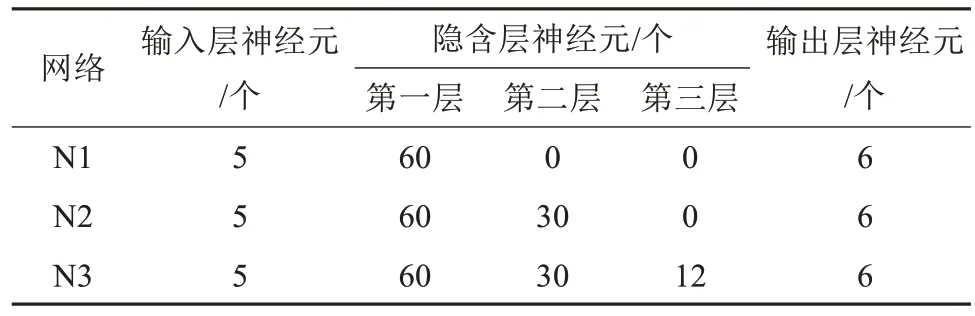
表2 不同隐含层数的反向传播神经网络参数配置Tab.2 Parameter configuration of BPNN with different hidden layers
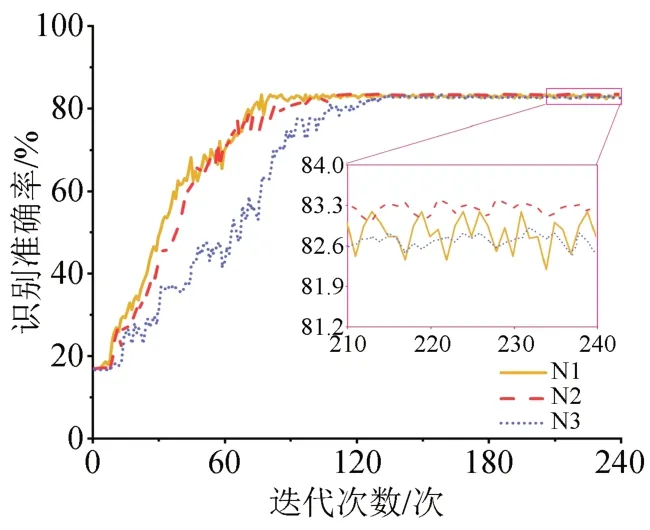
图10 不同隐含层数对反向传播神经网络识别准确率的影响Fig.10 Effect of different hidden layers on the recognition accuracy of BPNN
由图10 可知,三个网络的识别准确率介于82.35%~83.33%之间,其中N2 网络表现最优。由于N1 的隐含层数只有1 层,神经元个数少,模型非线性程度低,无法对样本空间中不同缺陷类别数据进行有效区分,因此经过240 次迭代后其识别准确率波动仍然较为明显;而N3 网络参数规模较大,在本数据集中时较N2 更易出现过拟合,模型识别准确率较低。因此,后文统一采用隐含层数为2 层的反向传播神经网络作为DGA特征向量的分类模型。
4.2 基于PRPD-DGA信息融合的缺陷识别
由上文可知,在低输入维度下,基于PRPD 图谱或DGA特征向量单一信息源的缺陷识别误诊率高,难以满足人工智能与传感技术日益发展的背景下电力系统对设备运行可靠性的要求,因此本文提出一种基于PRPD 图谱和DGA 数据信息融合的CNNBPNN 模型,两种模式识别方法融合可实现油纸绝缘沿面放电典型缺陷的电检测法与化学检测法的优势互补。
4.2.1 基于PRPD-DGA融合模型的纠错机制
在PRPD 图谱输入维度为32×32 并融合DGA特征向量的条件下,选择一组缺陷2 的D-S 证据融合前后的BPA 来说明所构建模型的纠错机制。通过D-S 证据理论融合前后的概率计算结果如表3 所示。由表3 可知,根据DGA 单一判据的分类结果是正确的,而根据PRPD 图谱单一判据的分类结果出现错误。根据PRPD 图谱单一判据模型被判为缺陷3 的概率最大,为0.445 0,且判为缺陷2 的概率也较大,为0.379 5。而根据DGA 单一判据模型的识别结果判为缺陷2 的概率最大,此时两种分类模型识别结果出现了分歧。通过D-S 证据融合后,判为缺陷2 的概率最大,为0.714 1,判为缺陷3 的概率为0.190 6,输出结果满足决策的3个判决规则,同时不确定度降低至0.010 3。由此可知,当PRPD 图谱单一判据模型在缺陷识别中出现误判时,加入DGA数据进行联合诊断能纠正基于PRPD 图谱单一判据模型的错误,同时提高了信息融合模型的识别准确率和识别结果的置信程度。
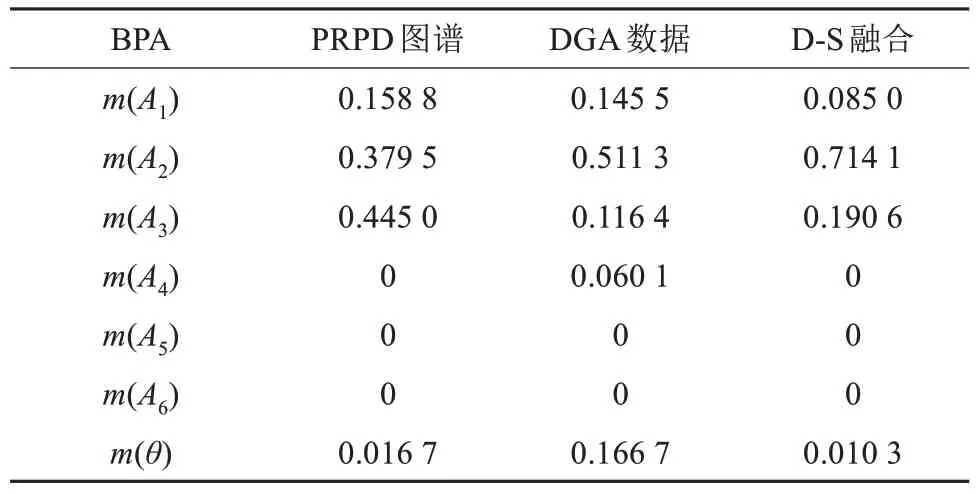
表3 一组缺陷2的D-S证据融合前后的BPATab.3 A set of BPA of defect 2 before and after D-S evidence fusion
4.2.2 不同PRPD图谱输入维度的影响
为对比本文的信息融合方法在PRPD 图谱不同输入维度下6 类缺陷识别准确率的提升效果,将PRPD 图谱在不同输入维度下的识别结果分别与DGA 识别结果融合,不同PRPD 图谱输入维度下三种基于不同判据的模型识别准确率如图11 所示。由图11 可知,D-S 证据理论较好地融合了PRPD 判据和DGA 判据的优势,在不同PRPD 图谱输入维度下,6 类缺陷的识别准确率均有不同程度的提升。当PRPD 图谱输入维度分别为8×8、16×16、32×32时,融入DGA 特征向量的CNN-BPNN 模型识别准确率为93.21%、97.53%、99.17%,较PRPD 图谱单一判据的模型识别准确率分别提升了4.81%、2.78%、0.84%,同时节约了计算资源和存储空间,有利于在实际工程中应用。

图11 不同PRPD图谱输入维度下三种不同判据模型的识别准确率对比Fig.11 Comparison on recognition accuracy of three different criterion models under different input dimensions of PRPD spectrum
4.2.3 不同神经网络融合模型的影响
为验证本文所提CNN-BPNN模型的优越性,将Vgg16、ResNet18、DenseNet121 等深度卷积神经网络对PRPD 图谱分类后,与DGA 特征向量识别结果进行D-S 证据融合,不同神经网络融合模型的识别准确率及模型大小如表4 所示。由表4 可知,CNNBPNN 模型的识别准确率较Vgg16-BPNN、ResNet18-BPNN、Dense Net121-BPNN 等深度卷积神经网络融合模型分别提高了0.16%、0.87%、0.99%。由于6 种缺陷的二维PRPD 图谱具有一定规律性,特征较为显著,参数过多、结构复杂的深度卷积神经网络在训练过程中易出现过拟合,Vgg16-BPNN 等深度卷积网络融合模型表现略逊于参数较少的CNN-BPNN 模型。此外,CNN-BPNN 模型更轻量,文件大小仅为0.69 MB,较深度卷积融合模型至少节约40倍的内存空间。
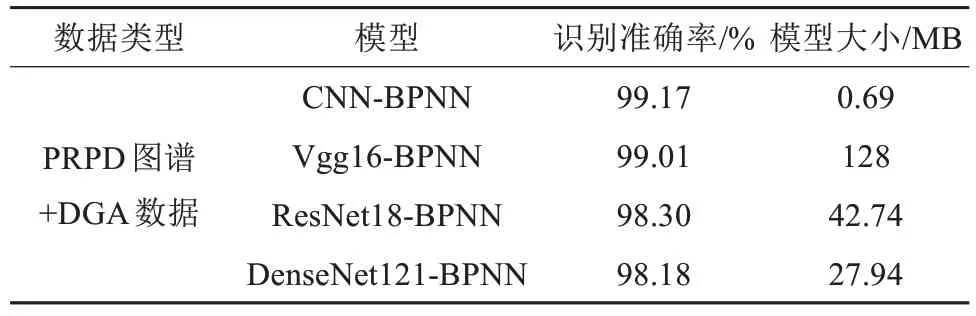
表4 不同神经网络融合模型的识别准确率Tab.4 The recognition accuracy of different neural network fusion models
5 结 论
(1)当PRPD 图谱或DGA 特征向量的单一判据模型识别结果出现误判时,基于D-S 证据理论的PRPD-DGA 信息融合方法可有效纠正错误输出,降低分类结果的不确定度,进而增强了缺陷识别结果的置信程度。
(2)CNN-BPNN 模型可有效融合局部放电的电气物理信息和化学产物信息,当PRPD 图谱输入维度为8×8、16×16、32×32时,融入DGA特征向量的模型识别准确率分别为93.21%、97.53%、99.17%,较基于PRPD 图谱单一判据的模型识别准确率分别提升了4.81%、2.78%、0.84%,既提高了缺陷识别准确率,又降低了数据存储要求。
(3)CNN-BPNN 模型较Vgg16-BPNN、ResNet 18-BPNN、DenseNet121-BPNN 等深度卷积神经网络融合模型识别准确率分别提高了0.16%、0.87%、0.99%,且网络参数大幅减少,抑制了模型的过拟合,并降低了模型的存储占用空间,更利于在电力系统智能化运维中应用。
猜你喜欢
东北水利水电(2022年6期)2022-06-28
康复(2022年31期)2022-03-23
北京航空航天大学学报(2021年9期)2021-11-02
少先队活动(2020年12期)2021-01-14
电子制作(2019年11期)2019-07-04
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中成药(2017年3期)2017-05-17
领导科学论坛(2016年9期)2016-06-05
小天使·五年级语数英综合(2015年4期)2015-04-20
