
基于Landsat 8 OLI 的东圳水库水质参数反演研究
2024-01-16 12:40陈文惠张忠婷
科学技术创新 2024年1期
何 欢,陈文惠*,张忠婷
(福建师范大学 地理科学学院,福建 福州)
引言
“十四五”重点流域水环境综合治理规划提出以饮用水水源地为重点,加大污染防治和富营养化防控力度,因此要对水源地水质进行实时监测,促进水资源规划、管理和保护。传统水质监测通过布设采样点实测,准确性高,但时空上不连续,无法对断面进行实时监测[1]。而遥感数据时空分辨率高、易获取、数据全面,可以反映空间分布和动态变化,弥补了传统方法的不足。
国内外学者针对海洋、湖泊等不同水域、利用不同数据、算法构建模型反演水质参数[2]。水质参数是监测水质的重要指标。其中,Chl-a 可以表征藻类生物的生物量[3];浊度反映泥沙含量,也是富营养化指标[4];COD 可以反映有机污染程度。目前,统计回归模型应用广泛,但精度较低,随着机器学习的发展,该类模型被广泛应用于水质参数反演[5,6]。近年来,莆田市高度重视东圳水库水环境综合治理工作,需要对水库水质进行常规监测。Landsat 8 遥感影像易获得,重访周期短,可以对水质进行实时监测,所以本文以东圳水库为研究区,根据Landsat 8 波段反射率与实测的Chla、浊度、COD 的相关性,构建传统回归模型、BP 神经网络模型和XGBoost 模型,选择最优模型反演并分析。
1 研究区概况
东圳水库位于福建省莆田市区延寿溪中游,库心坐标为118.954°E,25.485°N。集防洪、灌溉、供水等效益于一体,是当地的“大水缸”和生命线工程。水库面积约10 平方公里、库容量达4.35 亿立方米,年平均供水量3 亿多立方米。目前,该水库还存在污染和富营养化情况,需要进行水质监测。
2 数据源及预处理
选择与采样时间同步或准同步的4 景Landsat 8卫星影像数据,完整覆盖东圳水库。对数据进行辐射定标和大气校正,经校正的影像去除了大气衰减的影响,绿地、水体等地物的波谱曲线趋于正常,并利用水体指数MNDWI 提取水库边界。根据野外手持GPS 记录坐标,采样点如图1 所示,提取每个采样点对应影像前7 个波段的反射率,结合实验室理化分析得出水质参数浓度。其中,Chl-a 浓度范围为1.81~27.82μg/L,浊度浓度范围为1.86~16.1NTU,COD 浓度范围为2~5.9 mg/L。本实验选取83 组数据训练模型,另外41 组用于检验模型精度,为保证模型的稳定性,每月按比例随机选取一定数量的样本,避免样本过度集中在一两个月的情况。

图1 采样点位分布图
3 模型构建及对比
3.1 统计回归模型构建
模型构建的前提是筛选出与水质参数浓度相关性较高的波段或波段组合。当水体中水质参数发生变化时,水体的反射光谱也会随之改变。由于水体信息较弱,所以通过波段组合增强信息。本研究采用皮尔逊相关系数法,来描述水样水质参数浓度与各因子之间的相关性,值越大说明相关性越强。为了筛选适合本研究区的因子,通过文献总结,将b1 ~ b7 各个波段反射率以加、减、乘积、比值等不同方式进行组合,对3 种水质参数分别统计了1 266 个因子。其中,相关系数大于0.5 或小于-0.5 的,Chl-a 共有783 个,浊度共有592 个,COD 共有289 个。
在筛选出的波段组合中,选取4 个相关性最高的因子作为自变量,实测数据作为因变量分别构建线性、二次多项式、幂指数等统计回归模型,对比各个模型的拟合效果,筛选最优模型。构建的统计回归模型,如表1 所示,因为筛选了潜在特征因子,且采样点相对较多,统计回归模型R2均大于0.8。

表1 Chl-a、COD、浊度的统计回归模型
3.2 BP 神经网络、XGBoost 模型构建
BP 神经网络由Rumelhart 等[7]提出,按误差反向传播算法训练的多层前馈式网络,在自适应、自学习、容错性等方面有很大优势,可以更好地处理非线性关系,目前被广泛应用于水质参数反演。
XGBoost 算法是一种梯度提升树算法,通过迭代构建多个决策树模型,不断校正预测误差,以提升模型的性能,并引入正则化项和高效的分裂策略,以防止过拟合并提高模型的泛化能力,同时通过梯度提升和二阶导数信息来加速模型训练,最终通过多棵树模型集成来提高预测模型准确性。其目标函数如下:
其中,第一项为损失函数,用于描述模型的拟合程度;第二项是正则项,用于控制模型的复杂度,以防止模型过拟合。其公式如下:
式中:γ 、λ 为正则系数;T、ω 分别为末端叶子节点的个数、权重。损失函数泰勒展开为:
因此,目标函数简化为:
其中,yi为 样本i 的真实值;为前t-1 棵决策树对样本i 的预测值;gi、hi分别为损失函数l 关于x 的一阶导数、二阶导数。
通过调参寻优的过程,使得目标函数的值最小,即模型训练完成。本文以遥感影像7 个波段的反射率作为输入因子,水质参数浓度作为输出因子,分别构建BP 神经网络模型和XGBoost 模型。
4 精度验证
为获取最优水质参数反演模型,使用平均绝对误差(MAE)、均方根误差(RMSE)对模型进行精度检验,计算方法如下:
5 结果与分析
5.1 模型精度对比分析
统计回归模型在先筛选潜在特征再建模的情况下,拟合度和精度都有了较大提高,其中,COD 的模型效果最好,R2均大于0.9,MAE 均小于1,说明模型能较好地解释数据的变异性且平均误差较小;Chl-a 和浊度的R2均在0.8~0.9 之间,个别实测值与预测值相差较多;通过调节BP 神经网络模型隐含层的神经元个数、迭代次数、误差阈值、学习率等,使效果最好并趋于稳定,实测值与预测值之间的误差都较小,相比于统计回归模型,BP 神经网络模型拟合度更高,精度也明显提高,说明反演效果相对更好。但是,该模型也存在一定的局限性,包括容易陷入局部极小值、过拟合等。所以,考虑到过拟合的情况,本实验构建了XGBoost 模型,使用贝叶斯优化算法寻找模型的最佳超参数组合。从表2 可以看出,模型的R2有所下降,但MAE 在0.05~0.09 之间、RMSE 在0.07~0.13 之间,说明模型的误差更小,为了保证水质参数反演的准确性,R2在合理范围时,较低MAE 和RMSE 的模型可能更好。

表2 BP 神经网络模型和XGBoost 模型结果对比
5.2 各水质参数结果对比
基于2023 年9 月17 日获取的遥感影像,选择最优模型分别对东圳水库3 个水质参数进行反演,反演结果如图2 所示。从图中可以看出,库心的Chl-a、浊度、COD 浓度都偏低,但是出入水口、岸边、正下方(岭下村附近),人口密度相对较大,易受人为活动影响且库区岸线曲折较窄导致水质参数浓度整体偏高。根据Carlson 和Simpson 的分类标准[8],水体Chl-a 浓度在2.6~20g/L 、20~56g/L分别属于中、富营养水体,可以看出2023 年9 月东圳水库西部相较于东部Chl-a 浓度更高,整体存在一定程度的富营养化。浊度浓度整体小于10NTU,沿岸浓度稍微高一点,个别异常值出现在边界处。COD 浓度总体较低,根据地表水环境质量标准,东圳水库的COD 含量处于Ⅰ类水质标准。研究区水质良好且整体浓度趋于一致,空间差异性较小,说明通过遥感影像对水质参数进行反演,可以较好地反映其空间分布情况。
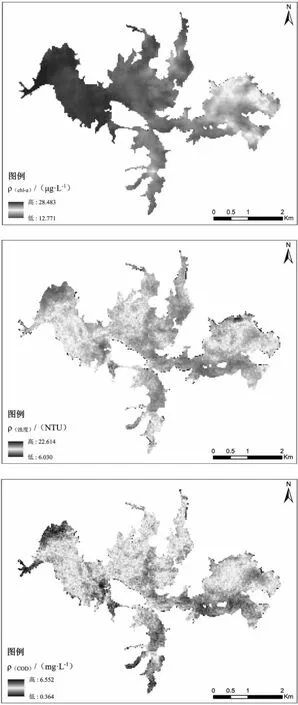
图2 Chl-a、浊度、COD 的XGBoost 模型反演结果
6 结论与讨论
基于Landsat 8 遥感影像,构建了东圳水库3 种水质参数的统计回归模型、BP 神经网络模型、XGBoost 模型,并选择最优模型进行反演,主要结论如下:
(1) 本文通过波段组合变换后,3 种水质参数分别以相关性最高的因子进行构建统计回归模型,模型拟合度和精度均有所提高。
(2) BP 神经网络模型效果优于统计回归模型,但存在过拟合现象。XGBoost 模型能有效避免模型过拟合,拟合能力较强,且误差较小,精度更高,适合用于本研究区的水质参数反演。
(3) 东圳水库水质参数浓度值整体上分布较为均匀且波动较小,部分区域出现高值,与沿岸和上游的人类活动有关。
虽然遥感反演水质参数,可以动态监测水质情况,但是水域环境复杂以及影像的误差,各种因素相互影响,建模需要考虑更多的因素。同时,机器学习算法众多,还需考虑如何选择出适合研究区的算法、对算法进行优化以及避免出现过拟合等问题。
在下一步研究中,可以将高光谱的波谱分析与水质参数的机理结合起来,深入分析不同季节适合的反演模型,为大型水库构建更准确的模型,也为水质监管提供技术支持。
猜你喜欢
中国三峡(2022年6期)2022-11-30
中等数学(2022年5期)2022-08-29
供水技术(2022年1期)2022-04-19
云南化工(2021年6期)2021-12-21
河南水利年鉴(2020年0期)2020-06-09
酒·饮料技术装备(2018年1期)2018-04-28
石油地球物理勘探(2017年4期)2017-12-18
石油地球物理勘探(2017年2期)2017-11-23
河南水利年鉴(2017年0期)2017-05-19
河南农业大学学报(2014年2期)2014-04-14
