
基于拍卖多智能体深度确定性策略梯度的多无人车分散策略研究
2024-01-27 06:56郭宏达娄静涛杨珍珍徐友春
电子与信息学报 2024年1期
郭宏达 娄静涛 杨珍珍 徐友春
(陆军军事交通学院 天津 300161)
1 引言
多无人地面车辆(Multiple Unmanned Ground Vehicles, Multi-UGVs,下文简称多无人车)具有容错性强、自适应好、载荷丰富等诸多优势,适合复杂环境中执行各种任务,目前在运输[1]、救援[2]、勘察[3]、作战[4]等多领域中发挥着越来越重要的作用。分散作为多无人车的具体应用,现也逐步在日常军事作战中推广,如遇敌情分散隐蔽、同时到达各点完成既定任务等等。
多无人车分散问题本质上是一种轨迹规划问题,其目的是使无人车在没有预先分配分散点的情况下,自主分配分散点,按照规划的轨迹行驶到所分配的分散点。解决多无人车分散问题的方法较多,现主流是使用常规方法,将分散问题分解为多个阶段,再逐一解决,以达到分散的目的。王平等人[5]提出了一种基于蜂群与A*混合算法的3维多智能体规划方法,避障性能大幅度提高,整体路径更为优化,并满足同时到达、时序到达等要求,但其只适用于智能体规模较小的情况,且算法相对复杂。董程博等人[6]提出一种多目标点同时到达约束下的规划设计方法,由匈牙利算法实现最优目标分配,防撞算法给出速度分段矩阵,不仅解决了现有等长轨迹规划法导致的跟踪轨迹复杂性问题,也优化了同时到达多目标点的时间,但算法是时间连续的,目前在工程上不能实现,可用性不强。赵明明等人[7]将拍卖算法和区间一致性算法相结合,提出不确定信息下多智能体同时到达的控制方法,实现到达多目标的时间上趋于一致,但其对通信要求较高,适用性不强。
近年来机器学习发展尤为迅速,为解决多无人车分散问题提供了一个比较新的解决思路。机器学习不仅保留了常规算法的优势,还可实现参数无需调整、自适应的目标[8],其中,深度强化学习以易扩展、效率高的绝对优势,成为完成分散任务的首选。DDPG(Deep Deterministic Policy Gradient)算法[9]适用于连续状态-动作空间,能够在复杂环境根据自身状态输出连续动作。作为DDPG在多智能体方向的扩展MADDPG算法[10],最初在多无人机领域应用较多[11,12],近期也开始运用于无人车领域[2]。MADDPG采用“集中式训练,分布式执行”的框架,应用于多智能体的协同围捕、竞争等场景,解决了不稳定环境中路径规划的问题。在智能体数量较少的情况下,算法的规划效果比较好,但当数量多、动作复杂时,算法的收敛速度明显下降,精度不高的缺陷也逐渐被放大,而且随着集群体量的增大,算法的适用能力下降。另外MADDPG存在训练时间较长,奖励函数对迭代结果影响大,算法整体效率不高等不足。
本文针对多无人车路径规划过程中训练时效性及奖励函数存在的问题,提出了一种基于拍卖多智能体深度确定性策略梯度(AUction Multi-Agent Deep Deterministic Policy Gradient, AU-MADDPG)
算法,以解决多无人车分散问题。算法主要基于MADDPG现有框架,在迭代过程中,每次从环境调取状态信息时,采用拍卖算法对分散点进行分配,确保过程中总路径保持最短;整体优化奖励函数,按照回合是否结束将训练划分两个阶段,定义不同的奖励函数,防止重复计算已到达分散点无人车的奖励,降低奖励函数的冗余值,大幅提升最优路径规划的概率。
2 问题描述与建模
本文的目标为在多无人车运行环境下,利用各车状态及环境信息(车速、障碍等)直接控制无人车动作(加速度、转向),并平稳、快速地到达各分散点。
2.1 多无人车分散问题描述
多无人车分散场景为:多辆无人车呈固定队形分布在含有规则或不规则障碍的战场环境中,当发生空袭或其他袭击时,为保证装备有生力量,各无人车需要通过协同,完全自主并迅速地驶向各隐蔽分散点。
图1表示3辆无人车分散到3个分散点的示意图。黑色表示战场环境中规则、不规则的正障碍、负障碍,紫色为各分散点。
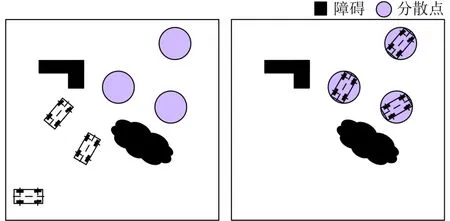
图1 多无人车分散场景示意图
多无人车分散成功的条件是:(1)无人车中心与分散点中心距离小于固定值ϵ(ϵ >0),则认为无人车到达分散点;(2)每辆无人车均到达一个分散点;(3)每个分散点上最多有一辆无人车。
在分散过程中还需要满足以下约束要求:(1)无人车行驶过程中不与其他无人车以及障碍物发生碰撞;(2)分散任务在固定时间内完成,并且尽可能总时间最短。
2.2 无人车模型构建
为了简化多无人车运动规划问题,本文将运动环境设置在2维空间中。在同构多无人车系统中,每辆车运动学参数均相同。对无人车进行运动学建模时,单个无人车遵循车辆运动学模型。
无人车模型参数有:无人车在坐标系中的位置(x,y)、航向角(φ)、速度(u),输入为加速度(a)、角速度(ω)。各值约定以及模型的定义如图2所示。

图2 无人车运动学模型
无人车i看作为一个半径为ri的圆形智能体,目标是一个半径为rk圆形分散点,Dik是无人车i与其目标之间的距离。无人车j看作与无人车i运动学相同的智能体,半径是rj,与无人车i的距离为Dij。无人车i的位置为Pi=[xi,yi],速度为ui,角速度为ωi,航向角为φi(表示速度与x轴正方向的夹角),目标速度角为αi(表示以无人车i为原点,无人车i到其目标的方向为正建立极坐标系时,i速度方向与极坐标正方向夹角),无人车i的通信距离Lci(通信范围在以其中心为圆心,半径为Lci的圆内)。在通信范围内,无人车i可以获取有关其他无人车和障碍物的信息,将通信范围内其他无人车和障碍物的集合(i的观测值)作为环境信息。无人车i的运动模型可表示为
设下一时刻无人车i的位置为,航向角为,航向角速度为,移动时间间隔为 Δt,则无人车i在下一时刻的状态为
无人车在行驶过程中受到的运动学约束为
其中,ωmin为顺时针最大角速度,ωmin<0;ωmax为逆时针最大角速度,ωmax>0。amin为倒车最大加速度,amin<0;amax为前进最大加速度,amax>0。
另外,由于无人车机械因素,运动过程中还需满足
Δφmin为顺时针运动的最大角度,Δφmin<0; Δφmax为逆时针运动的最大角度,Δφmax>0 。Δumin为倒车最大速度,Δumin<0 ;Δumax为前进最大速度,Δumax>0。
2.3 分散模型构建
2.3.1 状态空间构建
对于无人车i,状态空间是局部环境的观测信息,状态空间是否完备直接影响着算法能否收敛。根据多无人车分散的特点,无人车i状态空间由自身信息sAi和环境信息sEi组成。
建立极坐标系时,将无人车i视为原点,其与目标之间的方向视为正方向。自身信息sAi包含无人车i距离分散点相对位置、无人车i半径、目标速度角、速度、航向角以及分散点半径。无人车自身信息表示为sAi=(Dik,ri,αi,ui,φi,rk)。
环境信息sEi包含无人车i与相邻无人车j之间的距离,无人车j的速度、航向角以及半径。如果无人车i的通信范围内没有其他无人车,则Dij=0,uj=0,φj=0。表示为sEi=(Dij,uj,φj,rj)。
综上,无人车i状态空间设计为:si=(sAi,sEi)。分散模型的状态空间S表示为S={s1,s2,...,sN},N为无人车数量。
2.3.2 动作空间构建
无人车的运动由加速度和航向角速度决定。为了更为精确地表示无人车加速度和航向角速度,本文基于势场理论,利用无人车与分散点之间的引力、无人车之间的斥力,分析整体受力情况,进而计算出无人车的加速度和航向角速度。动作空间具体表示过程如下:
(1)计算无人车i在位置[xi,yi]、时间t处的合力。若[xgi,ygi]为无人车i的目标位置,则标准化引力分量表达式为
相邻无人车j对无人车i的标准化斥力的分量可表示为
因此,无人车i的合力表示为
其中Ni表示无人车i的相邻无人车集合,σij是碰撞参数,表示每个相邻无人车或障碍对无人车i排斥的影响程度,取值范围为[0,1]。
(2)根据合力计算加速度ai、航向角速度ωi其中,ka为加速度控制参数,kω为航向角速度控制参数,ψi为的方向角,ψ=,为ψi在[xi,yi]位置对时间的导数值。综上,无人车i的动作空间设定为acti=(ai,ωi)。
2.3.3 目标函数构建
确定了状态空间和动作空间,下面就需要对多无人车分散这个过程进行建模。
多无人车分散的目的是有效地将无人车规划到分散点,同时避开复杂环境中的障碍物及其他无人车。对于所有无人车,分散模型目标函数为
目标函数表示无人车最终到达对应的分散点,所有无人车行驶总路径最小时的策略,π表示所有无人车的策略集,Li为无人车i行驶的路径长度。约束条件如式(10)所示,Pki为无人车i(i=0,1,...,n)所到达的分散点,ε >0为预定义的距离参数,默认无人车与分散点距离不大于ε时,分散成功;另外,还需满足防碰撞约束,也就是在任何时候无人车i与无人车(或障碍物)j距离大于两车(或车与障碍物)的半径和。
根据目标函数(9)及约束条件(10),将多无人车分散问题转化成了最优策略π的求解问题。基于MADDPG深度强化学习算法框架,策略πµ需满足的条件为
对于n个无人车,µ={µ1,µ2,...,µn}是多无人车路径规划的确定性策略集分别为策略网络参数集和价值网络参数集,θµ′和ϕQ′分别是目标策略网络参数集和目标价值网络参数集。
对于无人车i,策略网络参数通过最小化成本函数来更新,成本如式(12)所示,其中acti和是无人车i在当前和下一个时刻的动作,是多无人车在当前和下一时刻的联合空间,Ri是无人车i的即时奖励,和分别是无人车i的价值函数和目标价值函数,γ是折扣因子。无人车i的价值网络参数通过梯度下降进行更新,计算公式为
其中 ,µi为策略网络,D是经验回放池,包括DA和DE,元素是(s,s′,a1,...,an,R1,...,Rn)。在DE中,无人车i的动作由策略网络获得,记为acti=µi(si);而在DA中,将无人车i规划到对应分散点,动作表示为acti=(ai,ωi)。
3 多无人车分散算法设计
多无人车分散任务要求将系统内有序排列或杂乱无章的无人车以最短总路径运行到达各分散点,并确保在行驶过程中不与任何障碍物及其他无人车发生碰撞。
现阶段多无人车分散所使用的MADDPG算法存在耗时大、易陷入局部最优的问题,主要原因是在训练时各车先随机到达分散点,总路径未必最短,最后导致训练和执行过程中的耗时明显增加。另外MADDPG对多无人车分散过程中的奖励函数考虑并不全面,使得最后得到的路径并非全局最优。本文从这两个问题入手,提出了AU-MADDPG算法,在训练过程中,首先对分散点进行分配,确保总路径最短;设置奖励函数时,不仅考虑对碰撞的惩罚,还考虑与目标点距离,与规划路径距离等诸多因素,利用贡献率将各因素合理分配,最后达到最优规划的目的。
3.1 分散点分配
分散点分配是将各分散点分配给各无人车,确保每个分散点最多有1台无人车,并且每个无人车均有1个分散点。分散点分配是无人车分散任务的基础,其决定着能否实现总路径最短,达到分散任务的要求。本文主要基于拍卖算法[13],每台无人车投标竞拍对各分散点的最短行驶距离,系统按照总路径最短原则为各车指定分散点,最终完成分散任务[14]。
拍卖方法主要分为3个过程:分散点拍卖、各无人车竞拍和分散点分配。
分散点拍卖:系统将需要分散的各分散点拍卖出去。
无人车竞拍:作为投标方的各无人车按照自身到各分散点的距离竞拍适合自己的目标点。
分散点分配:系统根据最终的投标结果将各分散点分配给指定无人车,为路径规划提供参考。
从各车投标分散点的路径矩阵L出发,经过多次迭代可求解出完成无人车分散最短总路径的分散点分配矩阵F。拍卖算法求解流程为
(1) 系统拍卖各个分散点;
(2) 各无人车作为投标方通过计算得到距离各分散点的距离l,生成路径矩阵L
(3) 系统比较L中的元素,选出数值最大的元素,并将其置为0;
(4) 经过置0后,若L为对角矩阵,转到步骤(5);若L中的某一行或者某一列有且仅有1个非零的元素,那么系统就将该元素所在的行与列其他所有元素的值都置为0;然后转到步骤(3);
(5) 系统按照得到的距离矩阵L,将分配矩阵F对应L中非零元素位置的值设为1,其他元素对应值设为0,可得出最终分散点优化分配矩阵F
3.2 奖励函数优化
路径规划根据各车的位置及分散点,设计出适合的路径,为各无人车的控制模块提供参考。奖励函数是深度强化学习最为重要的组成模块,直接影响着多无人车规划问题的结果。MADDPG算法只是将是否到达目标点和是否碰撞纳入奖励函数范围,对运行过程考虑得并不充分。本节主要是对奖励函数进行优化,将多种约束进行有效整合,使规划的路径最优。
从流程角度看,可以将奖励函数分为两个阶段,回合结束阶段以及无人车行驶阶段。
阶段1。在回合结束阶段(若无人车到达分散点或与障碍物、其他无人车碰撞时,回合结束),令和分别表示无人车i到达其目标和发生碰撞时的奖励函数,具体设置如下
阶段2。当无人车i在行驶过程中还未到达目标或没有碰撞时,本文设置4个非稀疏奖励函数来表示即时奖励,具体表达式为
3.3 分散算法流程设计
AU-MADDPG算法由4个网络构成,actor网络与目标actor网络输出动作,critic网络与目标critic网络估计动作Q值,经验回放池存储探索数据,奖励函数输出动作奖励。本文以单无人车为底层,采用集中式训练、分布式执行的算法训练框架,基于AU-MADDPG算法,解决多无人车分散问题。
训练以及测试流程框架如图3所示。训练过程中,多无人车与环境进行交互,得到经验并存入经验回放池。达到最小片段后,每次取出最小片段的经验值,更新actor网络、critic网络及对应的目标网络的参数。测试过程中,将无人车部署在环境中随机位置,调用已训练的网络,对多无人车分散的训练效果进行验证。
综上对传统算法的改进,基于AU-MADDPG算法的流程图如图4所示。
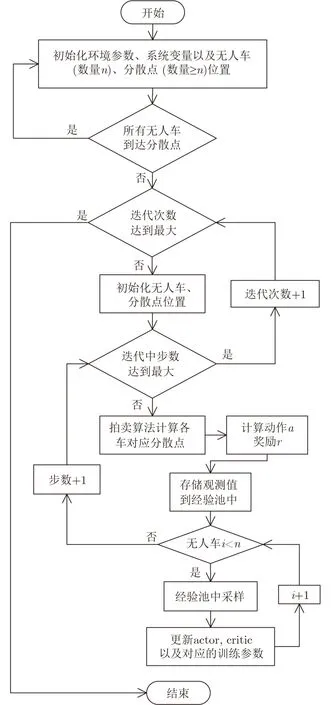
图4 多无人车分散算法流程图
4 仿真实验与分析
为验证提出的AU-MADDPG算法,本节以3辆无人车为例进行多无人车分散策略研究。基于所提算法训练各网络,分析方法的有效性,并分别与其它深度强化学习算法以及常规算法作对比,验证所提算法的优越性。
4.1 训练环境及参数设置
深度强化学习中训练的第1步往往是不可预测的,对于无人车平台来说危险隐患较大,因此好的仿真环境对于无人车实验平台的安全性非常重要。无人车在仿真程度高且体系完整的环境中训练也可以显著增强其在真实实验中的有效性。
本文采用的仿真环境为Open AI的多智能体强化学习环境(Open AI Multiagent Particle Environment, MPE)。多智能体强化学习环境,简称小球环境,主要用于MADDPG等深度强化学习算法的训练[10]。在ROS中,无人驾驶功能由多个包协同完成:通过接收到感知信息以及其他车的状态信息,得到最优路径,利用模型预测控制算法对无人车的加速度、方向盘转角进行控制。该自动驾驶功能已经在实验中进行充分测试,与仿真环境中的响应完全相同,从而证明了模型的有效性。
算法在Python 3.5中编译,使用Open AI gym 0.10.5、tensorflow1.8.0和numpy 1.14.5生成、训练神经网络。测试使用的ROS版本只兼容Python2,要使算法在ROS环境中生效,需要通过Rospy库与ROS通信(订阅和发布主题)。仿真环境如图5所示。在ROS中搭建该环境的主要优点是便于直接将算法移植到无人车平台(无人车平台也基于ROS),防止由于编译环境的不同使运行结果产生偏差。

图5 训练环境
AU-MADDPG算法在MPE环境中进行训练,策略网络、价值网络和对应的目标神经网络均有2个隐藏层,每个隐藏层单元数为64。训练环境集成在ubuntu 16.04系统中,硬件为16 GB RAM和2.3 GHz处理器(i7-11800H CPU, RTX3060 GPU)。训练过程中实时记录每次迭代的奖励值、耗时以及规划出的总路径等,并与MADQN算法、传统MADDPG算法进行对比。仿真中算法训练迭代次数为105,各超参数设置如表1所示。
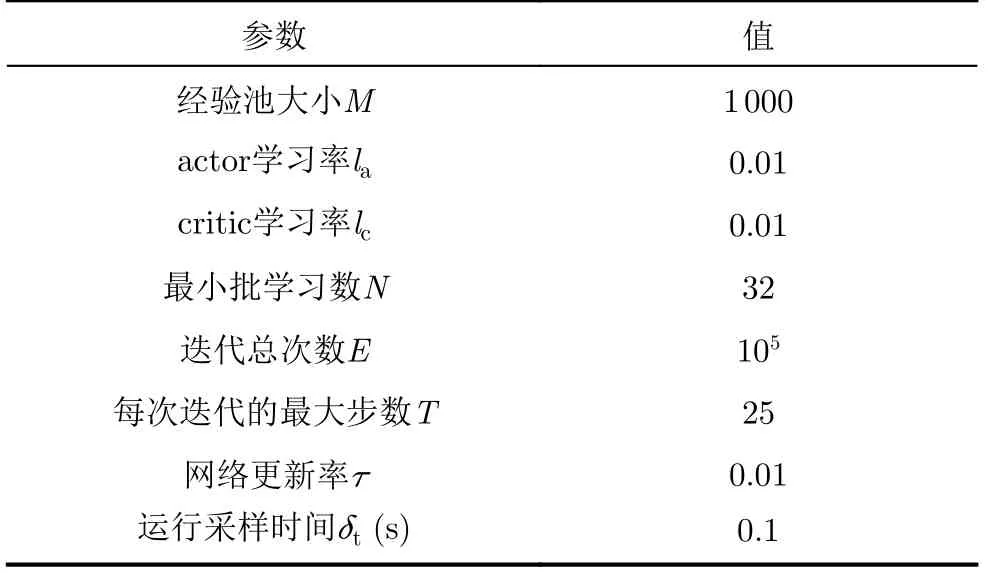
表1 AU-MADDPG算法参数设置
深度强化学习不需要额外的数据集,这是与其他机器学习相比最为突出的优势,因此受到了越来越广泛的关注。深度强化学习的衡量标准主要有两个:一是奖励曲线的变化情况。相同的迭代次数,若奖励曲线能更快地趋于平稳,则说明有更快的收敛速度。二是训练后无人车的表现情况。训练一定次数后多无人车的表现越好(如奖励值越高、总路径越短等等),训练的效果也就越好。实验中具体比较奖励曲线和各无人车的奖励值、规划时间、总路径等参数。
4.2 有效性分析
为验证算法的有效性,分别基于AU-MADDPG算法、传统MADDPG算法、多智能体深度Q学习(MADQN[15])进行路径规划仿真实验,分散示意图如图6所示。图6(a)、图6(b)为无障碍环境;图6(c)为越野环境,黑色为不规则障碍物;图6(d)为城市环境,黑色表示规则建筑物。为了验证算法的适用性,确保无人车在环境中任何状态下均能非常好地进行路径规划、完成分散任务,在每一次训练和测试开始时,无人车和分散点均处于随机位置。为了降低训练和测试的偶然性,仿真中采用多次迭代的方法(无障碍环境、越野环境、城市环境各训练105次,测试100次),将结果进行统计对比,验证所提出方法的有效性。运行后各车轨迹如图7所示。

图6 分散环境示意图

图7 不同算法下多无人车分散轨迹
图7可以很直观地看出,MADQN算法规划的路径较为曲折,拐点较多,初始点到分散点间的路径未达到最短。主要原因为算法基于的DQN只有1个Q网络,每次选择最大Q值对应的动作,未对动作进行评价,导致总的路径不一定为最优。传统MADDPG算法规划的路径大部分为直线,但路径多有交叉,且所有无人车路径总长度未达到最短。由于算法架构中包含两个actor网络和两个critic网络,每次actor输出动作后,critic均会做出评价,保证了输出结果最优,因此规划的路径大多为直线;算法中分散点分配是随机的,故所有无人车路径总长度未必最短。AU-MADDPG算法规划的路径均为直线,并且规划的总路径最短。原因有二:一是基于拍卖算法,每次规划均对分散点进行分配,确保总路径最优;二是优化了奖励函数,确保奖励函数最大时得到的路径为最优。
图8为3种深度强化学习算法随训练迭代次数的增加,奖励值变化的对比图。奖励值较高,则算法在当前状态下选择较优加速度及航向角速度的概率值就越大。从图中可以看出:(1)AU-MADDPG算法平均奖励值明显高于其它两种算法,这是由于采用了综合奖励函数,算法能够有效避免陷入局部最优。(2)AU-MADDPG算法收敛速度比传统MADDPG算法、MADQN算法更快,大约在4 000次左右便可趋于平稳,传统算法要在10 000次后趋于平稳,而且随着迭代次数的增加,平均奖励函数仍在缓慢上升,MADQN算法在35 000次迭代后才趋于平稳,但奖励函数值波动比较大。MADDPG框架中存在4个网络对动作进行预测和评估,提高了输出动作的准确性,而MADQN只有1个Q网络进行预测,存在过估计问题,因此MADQN波动较大;而在AUMADDPG算法中,每次迭代时均对分散点进行了分配,减少了传统算法对分散点探索的过程,因此所提出的算法平均奖励较为平稳,而传统算法则为缓慢上升。
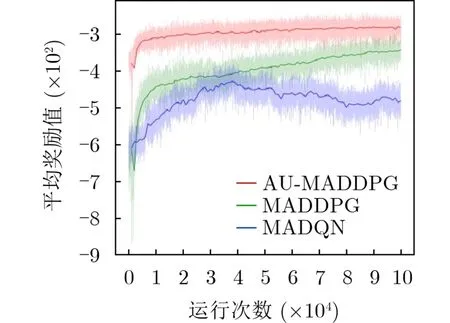
图8 算法平均奖励
4.3 性能对比分析
4.3.1 与深度强化学习算法性能对比
表2为3种算法在训练后分别测试100次的路径长度统计。由表可知,MADQN算法在路径总长度、最长路径和最短路径上均远大于其他两种算法,可见MADQN算法在最优规划上明显不足。AUMADDPG算法的最长路径、最短路径稍大于传统MADDPG算法,主要是因为每次迭代的初始位置是随机的,AU-MADDPG算法所对应的最长、最短最优路径有可能会大于传统MADDPG算法,但差距不会过大。在无障碍环境中,AU-MADDPG算法在测试100次后路径的总长度比传统算法少了34.959,缩短了14.5%,其他两种环境与无障碍环境情况相似,足可证明AU-MADDPG算法的最短路径规划上优于传统算法。
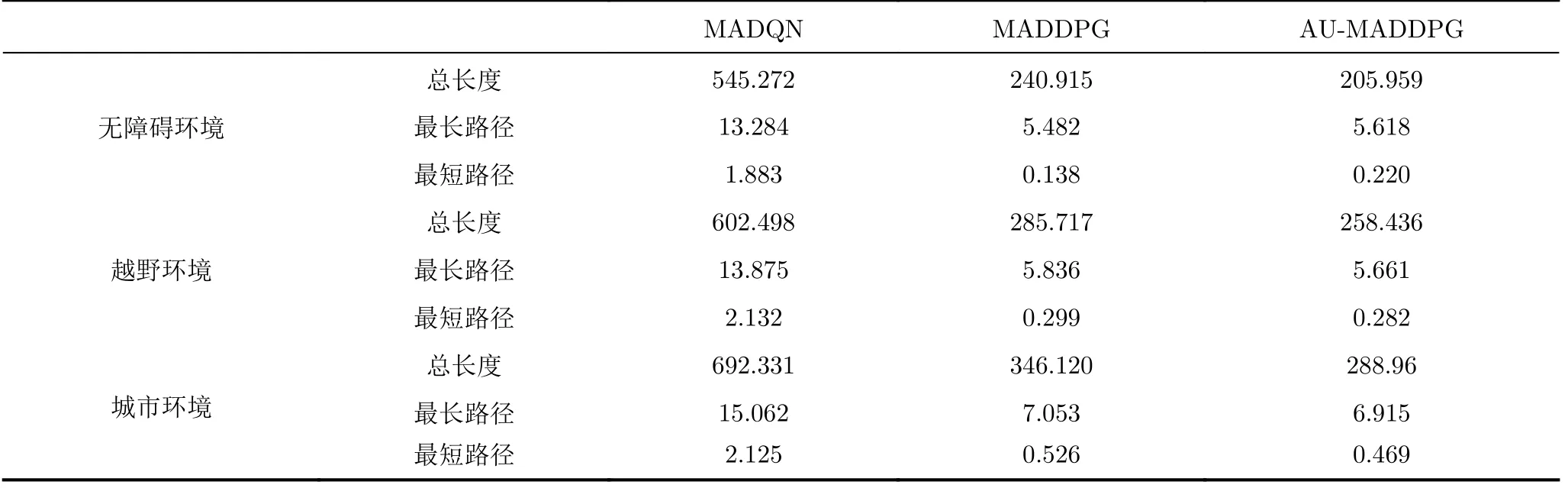
表2 测试100次路径长度对比
表3分别为3种算法训练过程中前40 000次、测试100次的耗时,图9、图10分别为在无障碍环境中随训练、测试次数的增加,算法耗时累计的情况,其他两种环境与该两图相似,本文不再表述。不管是训练过程中,还是在测试过程中,MADQN算法的耗时均远大于传统MADDPG算法、AUMADDPG算法,主要是因为MADQN适用于离散空间,而对于多智能体深度强化学习环境的连续空间,运用MADQN算法时需要对环境进行离散化,致使消耗了一定的时间。表3中后两种算法训练、测试过程中消耗时间相差不多,AU-MADDPG算法由于框架中引入拍卖算法,每次训练、测试时都可实现最优规划,使路径长度短于传统MADDPG算法,在一定速度情况下,训练耗时减少3.96%,测试耗时减少1.82%。
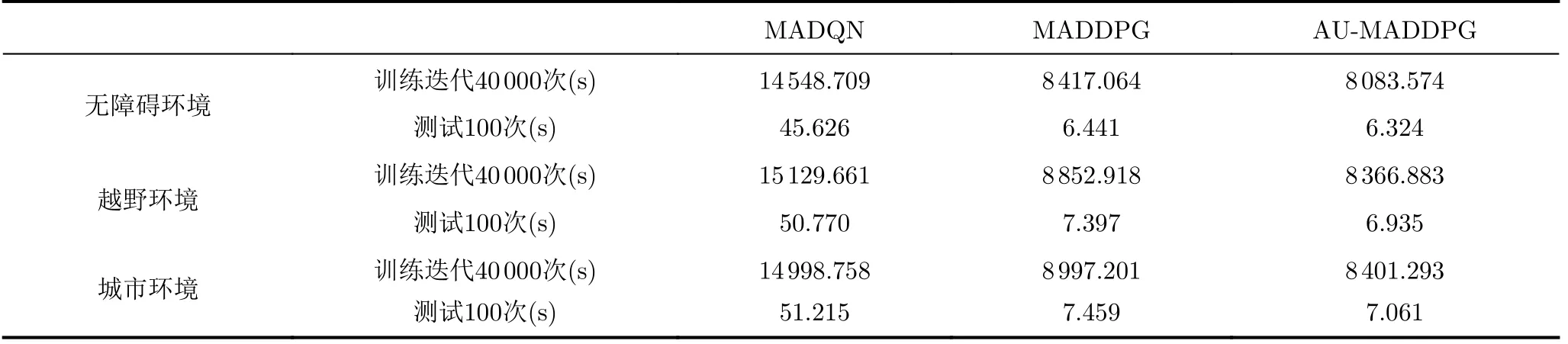
表3 算法耗时对比

图9 训练过程中耗时

图10 测试过程中耗时
4.3.2 与传统算法单方面优化性能对比
AU-MADDPG算法相比于传统MADDPG算法主要在两方面进行了改进--引入拍卖算法和优化奖励函数。为了进一步验证所提出算法的具体影响因素,将MADDPG算法分别只引入拍卖算法和只优化奖励函数,并在无障碍环境中进行105次训练、100次测试,结果如表4所示。
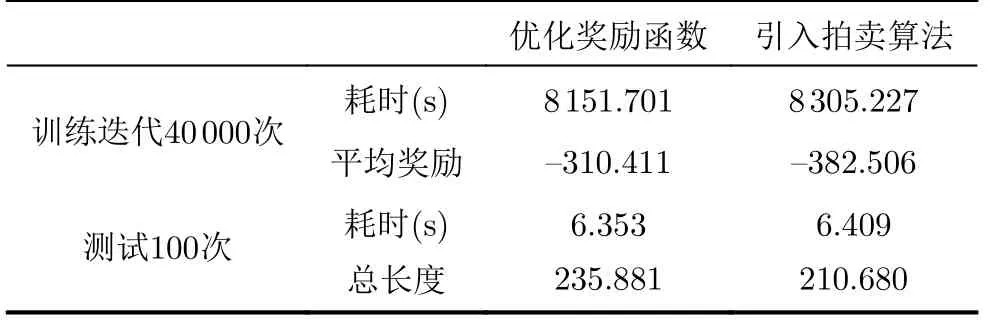
表4 MADDPG单方面优化性能
在无障碍环境中,表4中的性能分别与表2、表3以及图8中的MADDPG、AU-MADDPG算法作对比,可以明显看出:MADDPG单方面优化的各项性能结果均在MADDPG与AU-MADDPG之间,(1)在训练耗时和测试耗时方面,两种优化方面都有一定程度的缩短,而优化奖励函数与AU-MADDPG算法结果较为接近,表明耗时方面,优化奖励函数起到了主导作用;(2)路径总长度方面,引入拍卖算法与本文所提出的算法相差较小,表明此时拍卖算法起到了主导作用;(3)平均奖励方面,优化奖励函数较引入拍卖算法提高了18.85%,与AUMADDPG算法持平,此时起到了主导作用。
4.3.3 与常规算法性能对比
本文提出的算法在性能上不仅优于一般的深度强化学习方法,相较于常规算法也有非常大的提升。近年来,利用遗传算法解决多无人车路径规划问题的研究越来深入[16,17]。本文在图6(c)地图中使用遗传算法对多无人车分散进行路径规划,所规划的路径如图11所示。

图11 基于遗传算法的多无人车分散路径
图11与图7(c)越野环境进行比较,可明显看出,不管是单车路径长度,还是所有车路径的总长度,AU-MADDPG算法均短于遗传算法。另外,从表5测试100次的结果与表2、表3中越野环境测试数据对比来看,AU-MADDPG算法的耗时仅为遗传算法的1/10,而总路径长度较遗传算法缩短了47.95%,充分体现了AU-MADDPG算法的优越性。

表5 遗传算法测试结果
5 结束语
本文提出了AU-MADDPG算法,目的是基于深度强化学习,根据已定义的奖励函数计算出所有无人车的加速度及航向角速度,并拟合最优规划路径,解决多无人车分散问题。
(1)在单车模型的基础上构建多无人车分散模型,结合深度强化学习算法,借助无人车与分散点间的引力、多无人车间的斥力计算出各无人车动作。
(2)算法将传统MADDPG进行优化,引入拍卖算法,在训练和测试的每次迭代之前将分散点分配,提高算法训练及测试速度;将多个约束考虑到奖励函数之中,把多约束问题转化为奖励函数设计问题,提高了最优规划概率。
(3)通过仿真实验对提出的算法进行时效性和有效性验证,并与传统MADDPG、MADQN及遗传算法进行比较。实验结果表明所提出的算法(a)规划路径的总长度大幅度缩短,且降低了行驶过程中发生碰撞的概率;(b)训练、测试耗时明显缩短,训练效率提升较大;(c)平均奖励值进一步增大,提高了最优规划的概率,且不易陷入局部最优。
综上,所提出的算法在训练耗时、平均奖励以及最短路径上具有绝对的优势,效果明显优于其它算法,更适合解决多无人车分散问题,可作为此类问题的通用解决方案。
本文在训练及测试算法时,只利用了仿真环境,还未应用于实车。当然,在实车应用上,有许多条件与仿真存在一定的差异,如车辆模型的拟合度、通信延迟等等,此将作为下一步研究的重点方向。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化·中考版(2021年3期)2021-07-22
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
小哥白尼(军事科学)(2019年2期)2019-04-17
小哥白尼·趣味科学画报(2019年12期)2019-02-28
领导决策信息(2018年50期)2018-02-22
商周刊(2017年5期)2017-08-22
岷峨诗稿(2017年4期)2017-04-20
新高考(英语进阶)(2017年12期)2017-02-26
