
混合数据的多集群系统中数据价值与信息年龄的联合优化
2024-01-27 06:57陈前斌
电子与信息学报 2024年1期
罗 佳 陈前斌 唐 伦
①(重庆邮电大学网络空间安全与信息法学院 重庆 400065)
②(重庆邮电大学通信与信息工程学院移动通信技术重点实验室 重庆 400065)
1 引言
不同于传统无线传输技术主要关注传输速率或时延,视频直播等新兴移动互联网应用由于其业务性质对网络数据的时效性有了更精细化的需求,其亟需一种有效的性能指标去度量相关数据或信息的时效性。为进一步量化网络数据的时效性,越来越多的学者提出采用信息年龄(Age of Information,AoI)来衡量数据的新鲜度或及时性。AoI综合考虑数据的生成时间及传输时延。对于某个节点的AoI其关注对象是该节点最新收到的数据包,AoI被定义为该最新数据包自生成以来经过的时间[1]。
关于AoI的研究,文献[1]最早提出了AoI的概念。近年来,AoI逐渐被研究人员作为性能指标来衡量无线网络中的数据新鲜度。文献[2]基于搭载传感器的无人机网络,通过联合考虑感知时间、传输时间、无人机轨迹以及任务调度来实现AoI的最小化。文献[3]则进步一将无人机辅助的物联网与能量收集技术相结合,研究了相应的AoI优化问题。文献[4]基于具有功率约束的传感器物联网,研究了时变信道下中心控制器的AoI优化问题。文献[5]则针对AoI研究了数据传输时延为多个时隙的物联网环境下相应的在线优化问题。
关于视频直播的研究,相关文献主要关注直播的用户体验质量(Quality of Experience, QoE),QoE与视频质量和传输时延有关。例如,文献[6]在一个独立的5G测试环境中测试了上行视频传输在时延方面的性能,并指出合理的上下行配比能有效缓解视频直播应用在上行链路方面的数据拥堵。文献[7]将视频质量定义为与视频平均码率有关的对数函数,在满足时延约束的条件下最大化无线接入网中的视频质量。文献[8-10]也基于具体的网络模型给出了视频直播的QoE定义并进行优化。
现有研究通常将AoI作为单一指标来评估网络的数据新鲜度,然而,在某些应用中,也需考虑接收数据的价值。数据价值可以看作数据对于系统业务的重要程度,例如,在视频直播场景,对于一个以看重视频质量的消费群体为目标客户的直播活动,文献[7]中的视频码率可用于衡量视频的数据价值。对于利用边缘服务器实现机器学习的边缘智能场景,文献[11,12]则指出无线传输数据的不确定性及其信噪比可用于衡量该场景下机器学习训练数据的重要程度。另外,在对重要活动的直播中,可使用无线传感器来收集活动现场的实时环境数据,不同的环境数据具有不同的价值。在数据价值敏感的系统中,需在保证接收数据具有一定价值的同时提高数据的新鲜度。此外,现有关于视频直播的研究主要聚焦视频的QoE优化,而较少关注视频数据的AoI,作为同样对数据新鲜度要求较高的应用场景,视频直播同样需要关注对于AoI的优化。基于以上观察,本文的贡献主要有以下两个方面:
(1) 针对AoI的研究中数据价值考虑不足的问题,本文基于直播终端和无线传感器共同部署的视频直播系统,以直播终端为中心划分为视频数据与环境数据混合的多集群系统,利用环境数据需求的急迫性与视频码率构造了系统的数据价值等级划分,并建立关于时间平均数据价值和AoI的联合优化问题。
(2) 为实现有效的问题求解,本文将原问题的调度策略分解为相互关联的内外两层策略,同时,考虑到AoI的动态变化特性,提出一种基于深度强化学习的双层调度策略以克服原问题动作空间过大的问题。仿真结果则验证了本文所提方法的有效性。
2 系统模型和问题
对基于无线链路的视频直播系统,多个直播终端作为直播视频源需通过上行链路传输源视频到无线基站,基站利用连接的边缘服务器对源视频进行视频转码等处理操作从而向其覆盖范围内的各类终端消费者提供不同码率的直播服务,同时基站也需通过核心网将源视频传播至其他地理区域的终端以提供大范围的直播服务。本文主要考虑无线直播系统的第1个环节,即直播视频源终端到相应基站的上行传输链路。
具体来说,本文考虑一个针对重要活动的视频直播系统,一方面,单个基站需收集其覆盖范围内的直播源视频,为实现对同一重要活动的全方位直播,N个连接或配备摄像设备的直播终端在活动场馆的不同位置以不同视角对该活动进行直播,直播终端作为直播视频源通过上行链路传输源视频到基站。另一方面,为保证重要活动的实施效果,需在活动场馆的不同位置配备多个无线传感器从而采样收集多方位的环境相关数据,传感器作为无线终端也需通过上行链路将其采样的数据发送到基站并通过基站将数据发送到监控中心。系统一共有L(L >N)个带宽不同的上行无线信道,为保证视频直播的连续性,调度策略在每个时隙需为每个直播终端均分配1个上行信道。此外,还需为无线传感器分配回传其数据的上行信道,因此,每个时隙最多有L-N个信道可被分配用于进行传感器数据的上行传输,其中L-N ≤N。
在具体实施时,为了向监控中心提供及时且多方位的环境相关数据,将以上两类终端以直播终端为中心划分为大小相等的N个集群,每个集群包含的终端数用M表示,其中包含一个直播终端以及在其附近的M-1个无线传感器。具体的终端索引号用m表示,m=1对应集群中的直播终端,m(1<m ≤M)则对应集群中的无线传感器。为避免单个集群内(即同一位置附近)的无线传感器占用过多的信道资源,除了直播终端,集群n在时隙t最多可选择一个无线传感器上传其采样的环境相关数据。直播视频传输时可以视频时长为单位将视频数据分割为多个时长为z的视频数据包进行传输。对于不同的直播终端,其对视频码率选择的不同可使得各自视频数据包的大小存在差异,而对于同一直播终端,由于存在动态的码率自适应策略,其数据包大小在不同时隙也可能存在差异。对于直播视频,其数据包的视频码率划分为I个等级,i(i ∈{1,2,...,I})表示具体某个视频数据包的码率索引号,索引号越高对应的视频码率也越高。xi(xi ∈X)为对应的视频码率,X则为直播系统所支持的视频码率集合。因此,单个视频数据包大小为zxi。此外,上行传输所分配的信道具有不同的带宽和增益,对应的各终端上行传输速率也存在差异。 R表示系统支持的上行传输速率集合,Rl(Rl ∈R)则为信道l(l ∈{1,2,...,L})的上行传输速率。单位时隙时长为b,用dv表示单个视频数据包完成上行传输所需的时隙数,基于上述讨论可知
对于传感器数据的上传,由于并非所有传感器均在每个时隙接入无线信道进行上传,因此采用类似文献[13]的Will模型,即对于在时隙t分配到信道的传感器,其在时隙t之前采样的数据均被丢弃,仅上传在时隙t最新采样的数据,直到该数据完成上行传输才会释放被分配的信道。 Y表示传感器支持的环境数据包大小集合,|Y|=Y,j(j ∈{1,2,...,Y})表示环境数据包大小的索引号。yj(yj ∈Y)则为对应的数据包大小。用ds表示传感器数据完成上行传输所需的时隙数,因此有
φl,n,m(t)∈{0, 1}表示集群n内终端(包括直播终端和传感器)m在时隙t的信道l上的状态,如果终端(n,m)在时隙t被分配到信道l(l ∈{1,2,...,L})进行上行传输,则φl,n,m(t)=1,否则,φl,n,m(t)=0。当时,即终端(n,m)在时隙t占用无线信道进行上行传输,对于正在传输的数据包,用µn,m(t)表示其数据生成的时隙,νn,m(t)则表示该数据包完成上行传输所需的时隙数,因此有
其中,in(t)表示时隙t集群n正在传输的直播终端数据包对应的码率等级,jn,m(t)则表示时隙t传感器(n,m)(m ̸=1)正在传输的环境数据包大小的索引号。
2.1 信息年龄
由于对直播视频与现场环境数据的需求均看重数据的及时性或新鲜度,因此本文采用AoI作为系统性能的评估指标。AoI被定义为目标节点最新接收到的数据包自其生成以来所经过的时间,基于此,对于在时隙t基站已完成接收的来自终端(n,m)的最新数据包(并非正在传输的数据包),用表示其数据生成的时隙。Δn,m(t)表示基站在时隙t关于终端(n,m)数据包的AoI,则有Δn,m(t)=t-。如果终端(n,m)在时隙t完成了对应数据包的上行传输,则相应的AoI在时隙t+1需更新为νn,m(t)=t+1-µn,m(t),否则,AoI需更新为Δn,m(t)+1=t+1-。综上所述,Δn,m(t)的更新遵循如式(6)
因此,基站在时隙t关 于其接收数据的AoI可计算为
2.2 数据价值
除了用AoI衡量数据的新鲜度,还需考虑数据本身的价值。对于注重视频质量的直播系统,本文采用视频码率来衡量视频数据价值,视频码率等级越高其价值也越高。基站主要关注接收成功时视频数据包的码率等级,对于集群n,用In(t)表示基站在时隙t接收到对应直播视频数据包的码率等级,如果集群n的直播终端在时隙t完成其视频数据包的上行传输,则In(t)=in(t),否则,In(t)=0。因此,In(t)可由式(8)计算
类似的,传感器采样的环境数据也有不同的价值分级,设环境数据的价值分为F个等级,等级越高则表示价值越高。表示集群n的传感器m其数据包价值等级为f(f ∈{1,2,...,F})的概率,因此有
对于传感器(n,m)(m ̸=1),当时,用fn,m(t)表示其在时隙t传输的数据包所对应的价值等级,Fn,m(t)则表示基站在时隙t接收到对应环境数据包的价值等级,则有
综上,基站在时隙t关于其接收数据的价值可计算为
2.3 问题建模
在每个时隙的开始,基站需基于其调度策略将空闲信道分配给需要上传数据的终端。考虑数据价值和AoI存在相互影响的关系且两者性能的优化分别对应各自的最大化和最小化,因此,为实现系统数据价值和AoI的联合优化,本文采用时间平均的数据价值与AoI比值(Ratio of Data Value to AoI,RDVA)。RDVA可用于衡量系统在单位时隙的数据新鲜度下能传输的数据价值大小,更大的RDVA意味着相应数据具有较好的数据新鲜度和较高的数据价值。相应的优化问题可表述为
约束条件 C1表示为保证视频直播的连续性,调度策略在每个时隙需为每个直播终端均分配1个上行信道。约束条件 C2表示为避免单个集群的传感器占用过多信道资源,调度策略在每个时隙对任意集群n最多选择一个传感器上传其采样的环境数据包。约束条件 C3表示每个信道最多只能与一个终端配对。约束条件 C4则表示每个时隙最多有L-N个信道可被分配用于进行传感器数据的上行传输。
3 调度策略
因此,问题P1可等价地转化为如式(16)的减法形式
由于q*未知,所以问题P2仍难以求解。为便于求解,定义如式(17)变量q(t)代替问题P2中的未知量q*
其中,q(1)=0,参数q(t)的值取决于过往的调度决策。将q*替换为q(t),则问题P2可转化为
由于AoI的动态变化特性,问题P3可采用深度强化学习进行求解。调度策略的可行动作空间大小为(NM)!/(NM-L)!,可以看出,该优化问题具有较大的动作空间,从而使得相应的算法难以实现有效的求解。为应对这一挑战,本文将上述问题的调度策略分解为集群间的信道分配和集群内的链路选择,基于此,可形成一个由内外两层策略组成的分层调度策略。内外两层策略以集群为分界点进行划分,外层策略决定空闲信道分配到哪个集群,包括用于视频数据传输的信道分配和用于环境数据传输的信道分配,内层策略则用于做出链路选择决策,其主要决定集群内传感器与信道配对的情况。
3.1 外层策略
外层策略采用深度强化学习来实现集群间的信道分配,深度强化学习的智能体可通过与环境间的持续交互来学习最优策略。具体来说,本文采用被称为异步优势动作评价(Asynchronous Advantage Actor-Critic, A3C)的深度强化算法[15]。为表示方便,用i(t),j(t),f(t),µ(t)和Δv(t)分别表示相应的状态向量
基于此,时隙t的状态s(t)可表示为
考虑到每个直播终端均会保持不间断的上行数据传输,而传感器则可能会由于空闲信道的不足而暂时停止传输,因此,可合理假设该视频直播系统中的视频数据传输相比环境数据传输具有更高的优先级。为优先保证视频直播的流畅和稳定,可将传输速率最高的N个信道均分配给各集群的直播终端。各信道对应的传输速率按照信道索引号降序排列,即Rl ≥Rl+1(l ∈{1,2,...,L})。基于此,对于时隙t的策略动作a(t),外层策略的动作空间可划分为用于视频数据传输的集群间信道分配和用于环境数据传输的集群间信道分配两类动作,分别用av(t)和as(t)表示,即
南川区地处亚热带温润季风区,气候温和,雨量充沛,云雾多、日照少、绵雨久、湿度大。气候垂直分带明显,随标高的增加年平均气温降低,而降雨量增加。区内多年来年平均降雨量1434.50mm,历年最大年降雨量1534.8mm(1998年),大气降水季节分配极不均匀,最枯为一月,雨季为5、6、7、8四个月,具有降雨集中,多暴雨、雨强大的特点。24h最大降雨量达259mm,1h最大降雨量为113.2mm,10min最大降雨量为24.3mm。大量研究表明:泥石流的形成与区内的短时强降雨密切相关,强降雨为泥石流的形成提供了充分的降水条件[4],离沙沟泥石流最近的金佛山气象站区内多年月平均降雨量统计见表1。
A3C的目标是最大化累积折扣奖励函数,即状态价值函数,其计算公式为
其中,γ为折扣因子,Eπ{·}表示智能体采用策略π进行序贯决策时的期望值。A3C利用多核CPU来运行多个智能体,多核CPU的每个线程包含一个智能体以及相应的环境副本。每个时隙智能体均计算并保存关于神经网络参数的导数,每隔一定数目的时隙,每个智能体使用各自在该时段中的累计导数并以异步的方式更新全局共享的神经网络参数集。一个执行A3C算法的智能体包含两个部分:行动者(Actor)和评价者(Critic)。行动者为一个神经网络表示的策略,其基于当前时隙观察到的状态s(t)决定当前时隙的动作a(t)。评价者则为另一个神经网络,其基于智能体通过环境反馈得到的即时奖励对当前策略进行评估。对于一个特定的智能体,其行动者和评价者的详细情况如下
行动者:用θ表示策略参数,π(a|s,θ)为相应策略,表示状态为s、参数为θ时智能体执行动作a的概率。行动者使用策略梯度上升法对参数θ进行更新。假设策略关于θ可微,则时隙t关于θ的性能梯度计算为
其中,B(t)称为优势函数,其指示特定动作带来的结果与结果平均值之间的差值。∇θlnπ(a(t)|s(t),θ)称为资格迹。由于策略动作a(t)为离散向量,因此,行动者的神经网络可直接输出每个动作对应的概率π(a(t)|s(t),θ)。得益于与神经网络的结合,A3C可采用参数集为θ的神经网络来学习π(a(t)|s(t),θ)。相应的参数集θ则采用如式(30)的策略梯度上升法更新
其中,g ≥0为行动者神经网络的学习率。
评价者:评价者采用优势函数B(t)来评估行动者选择动作a(t)的优劣。优势函数B(t)包含一个和状态s(t)有关的基线函数,而状态价值函数Vπ(s(t))是该基线函数的最佳选择。在实际的学习过程中,通常采用状态价值函数的估计值。因此,评价者的目标是使用另一个参数集为θc的神经网络来近似估计状态价值函数Vπ(s(t))≈。优势函数B(t)可采用如式(32)公式计算
参数集θc采用如式(33)的方式更新
其中,gc ≥0为评价者神经网络的学习率。在一个时隙中,行动者首先利用其神经网络输出当前时隙的策略π(a(t)|s(t),θ),根据该策略选择动作a(t)并执行,环境返回即时奖励函数值r(s(t),a(t),s(t+1))给评价者。然后,评价者通过其神经网络计算估计状态价值函数V˜ (s(t),θc)并基于此计算出优势函数B(t)来评估当前时隙动作a(t)的优劣。随后,行动者和评价者分别对其神经网络求关于参数集的导数,并基于优势函数B(t)来更新相应的参数集θ和θc。
3.2 内层策略
当外层策略确定了信道在集群间的分配后,由于每个集群仅有一个直播终端,因此各个直播终端的信道配对情况已确定,内层策略需要做的则是决定集群内传感器与信道配对的情况。内层策略可通过设计组合调度策略来实现优化目标,该策略由分配空闲信道的每个集群的链路选择决策组成。在每个可调度的时隙t中,内层策略需选择使的期望值最大的调度决策组合。然而,由于数据包的传输时延可能不止1个时隙,即对于任意终端(n,m)有νn,m(t)≥1,因此,调度决策的执行可能不会立即降低下一个时隙的AoI,直接最大化的期望值不可行。注意到可以利用当前时隙t,νn,m(t)和µn,m(t)计算自时隙t开始完成上行传输所需的时隙数ηn,m(t),也就是离相应的AoI下次降低剩余的时隙数ηn,m(t)=νn,m(t)-t+µn,m(t)。为实现本文的优化目标,可将预计降低的AoI设计为与ηn,m(t)相关,假设传感器(n,m)(m ̸=1)经过时隙t的传输可将AoI在时隙t+1降低αn,m(t),αn,m(t)可采用如式(34)计算
其中,Δn,m(µn,m(t))为对应数据包传输完成后预计可减少的AoI。需要注意的是,如果相应数据包在时隙t没有完成上行传输,则在时隙t+1基站处的AoI实际上并没有减少,因此,αn,m(t)可看作一个虚拟的AoI减少量。基站处的AoI则需在随后的时隙t+2加上对应的偏置量δn,m(t+1)=αn,m(t)。如果相应数据包在时隙t完成了上行传输,则αn,m(t)=Δn,m(µn,m(t))为时隙t+1基站处实际的AoI减少量,偏置量为0。因此,偏置量可采用如式(35)计算
基于上述分析,可构造如式(36)的虚拟队列
如果传感器(n,m)(m ̸=1)在时隙t占用无线信道进行上行传输,对于基站接收数据包的价值等级Fn,m(t),其值在数据包传输过程中为0,仅在数据包传输完成的时隙µn,m(t)+νn,m(t)-1中才为fn,m(t)。需要注意的是,fn,m(t)在数据包传输过程中保持不变,因此,为了评估在相应调度时隙µn,m(t)中的调度策略,可构造一个等效变量从而在时隙µn,m(t)+1提前赋予其数据包的价值等级。该等效变量可采用如式(38)计算
可以看出,当t趋于无穷时,如式(39)成立
由于直播终端与内层策略无关,内层策略在每个时隙t进行决策时需选择能够使的值最大的策略组合。此外,由于各集群的链路选择决策相互独立,因此,对于任意集群n,为了最大化,内层策略可基于以下原则选择集群内的传感器m*与相应的空闲信道进行配对
基于以上对内外层策略的分析,每个集群的内层策略需嵌入到外层策略中,从而构成本文所提的双层调度(Two-layer Scheduling, TS)策略,算法1描述了相应策略的具体步骤。相比直接使用A3C求解问题P3,TS策略将神经网络对应的可行动作空间大小从(NM)!/(NM-L)!减少到N!N!/(2N-L)!,从而使基于A3C的调度策略能够对问题P3进行有效的求解。

算法1 求解问题 P3的TS策略
4 仿真结果
仿真设定z=0.5 s,,视频码率集合X={2,4,6,8}Mbps,速率集合R={250,300,350,400}Mbps,环境数据包大小集合Y={0.125,0.25,0.375,0.5}MB。环境数据价值等级数F=4,集群数量N=4、信道数量L=6,单位时隙时长b=1ms,概率值,和则通过随机函数生成。对于A3C智能体,行动者和评价者的神经网络均为具有3个隐藏层且每个隐藏层神经元数量为128的全连接神经网络,神经网络的学习率均为0.000 1,最大的训练回合数以及单位训练回合包含的时隙数分别为Tmax=6 000和T˜ =30。仿真主要将本文的TS策略与其他3种策略进行比较,贪心(Greedy)策略在每个时隙优先调度Δn,m(t)最大的终端。最大比率(Max-Ratio, MR)策略[5]则考虑了上行传输时延,在每个时隙优先调度χn(t)和ψn,m(t)中值最大的终端,其中,χn(t)和ψn,m(t)的计算采用如式(41)和式(42)
基于数据价值的最大比率(Max-Ratio with Data Value, MRDV)策略则在MR策略的基础上进一步考虑了数据价值,在每个时隙优先调度χn(t)中值最大的终端。图1给出了4种策略下时间平均RDVA分别随单位集群内终端数量M变化的结果。如图1所示,本文的TS策略在时间平均的RDVA性能上优于其他3种策略,主要有两个方面的原因,一方面,TS策略直接优化时间平均的RDVA,因此,相比只考虑了AoI的贪心策略和MR策略其得到的RDVA值更优;另一方面,虽然MRDV策略联合考虑了数据价值和AoI,然而其没有考虑到AoI的动态变化特性,因此,其在时间平均的RDVA性能方面不如基于A3C的TS策略。另外,可以看到RDVA的值随着单位集群内终端数量M的增加而减少,这是由于M的增加对应于单位集群中传感器数量的增加,而传感器数量的增加会减少每个传感器得到调度进行上行传输的机会。
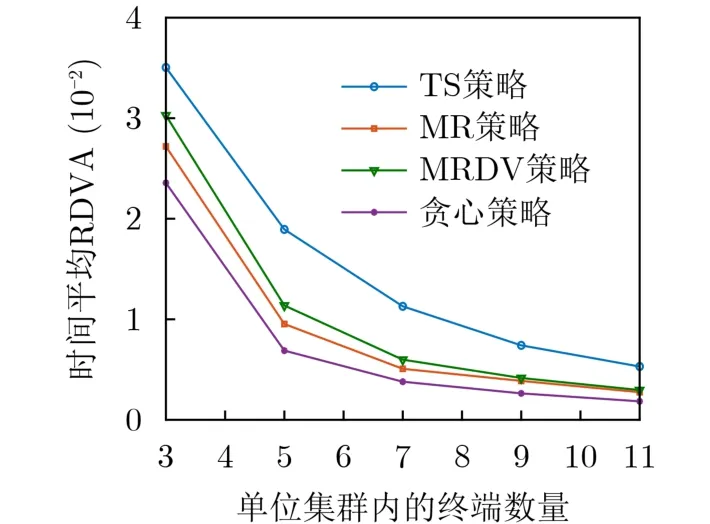
图1 单位集群内终端数量对时间平均RDVA的影响
对于数据价值和AoI的性能曲线,图2和图3给出相应性能随单位集群内终端数量M变化的结果。图2给出了时间平均的数据价值随M变化的结果。如图2所示,由于贪心策略和MR策略没有考虑系统的数据价值,因此其在数据价值方面类似于随机决策,所得到的时间平均数据价值在4种策略中也是最低的。对于MRDV策略,虽然其考虑了数据价值,然而AoI的动态变化会影响相应的调度决策从而影响接收数据价值的动态变化,因此,相比TS策略,MRDV策略则由于未考虑这种动态变化带来的影响而得到了较低的时间平均数据价值。另一方面,图3给出了时间平均AoI随单位集群内终端数量M变化的结果。可以看出,4种策略中TS策略能达到最优的时间平均AoI。贪心策略虽然考虑了预计数据传输完成能够减少的AoI,但忽略了数据本身传输时延对AoI的影响,因此,其在AoI方面的性能最低。MR策略和MRDV策略则是由于没有考虑AoI动态变化的影响,因此,其得到的时间平均AoI性能低于基于深度强化学习的TS策略。
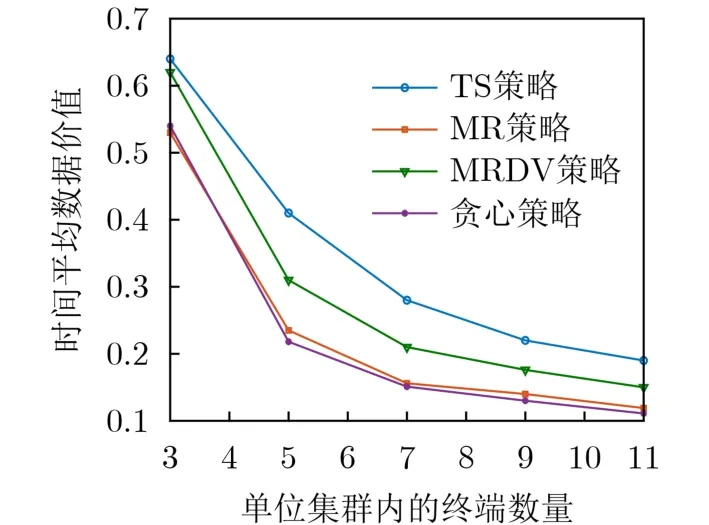
图2 单位集群内终端数量对时间平均数据价值的影响
5 结论
针对视频直播较少考虑AoI以及AoI的研究中数据价值考虑不足的问题,本文基于直播终端和无线传感器共同部署的视频直播系统研究了数据价值和AoI的联合优化问题。考虑到AoI的动态变化特性以及问题的有效求解,提出了一种基于A3C的双层调度策略,仿真结果表明,与其他策略相比,本文提出的调度策略可以降低时间平均的AoI并提高时间平均的接收数据价值。
猜你喜欢
铁道通信信号(2018年9期)2018-11-10
网络安全和信息化(2018年4期)2018-11-09
舰船电子对抗(2016年3期)2016-12-13
广西大学学报(自然科学版)(2016年5期)2016-11-12
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
华东理工大学学报(自然科学版)(2015年4期)2015-12-01
电子设计工程(2015年8期)2015-02-27
计算机工程(2014年10期)2014-06-07
现代防御技术(2014年6期)2014-02-28
深圳信息职业技术学院学报(2013年3期)2013-08-22
